
Kafka(全)
:happy:消息队列
什么是消息队列
- 队列:是一种先进先出的数据结构
- 消息队列:是由生产者将数据从一端放入消息队列,由消费者按顺序从另一端进行取出使用
消息队列的应用场景
消息队列在实际应用中包括如下四个场景:
- 应用解耦:多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败;
- 异步处理:多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间;
- 限流削峰:广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况;
- 消息驱动的系统:系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理
消息队列的两种模式
点对点模式
- 每个消息只能被一个消费者消费,一个生产者相当于对应一个消费者
- 消息被消费之后就删除
- 一对一
发布订阅模式
- 每个消息可以被多个消费者消费
- 消息被消费后不会被删除
- 一对多
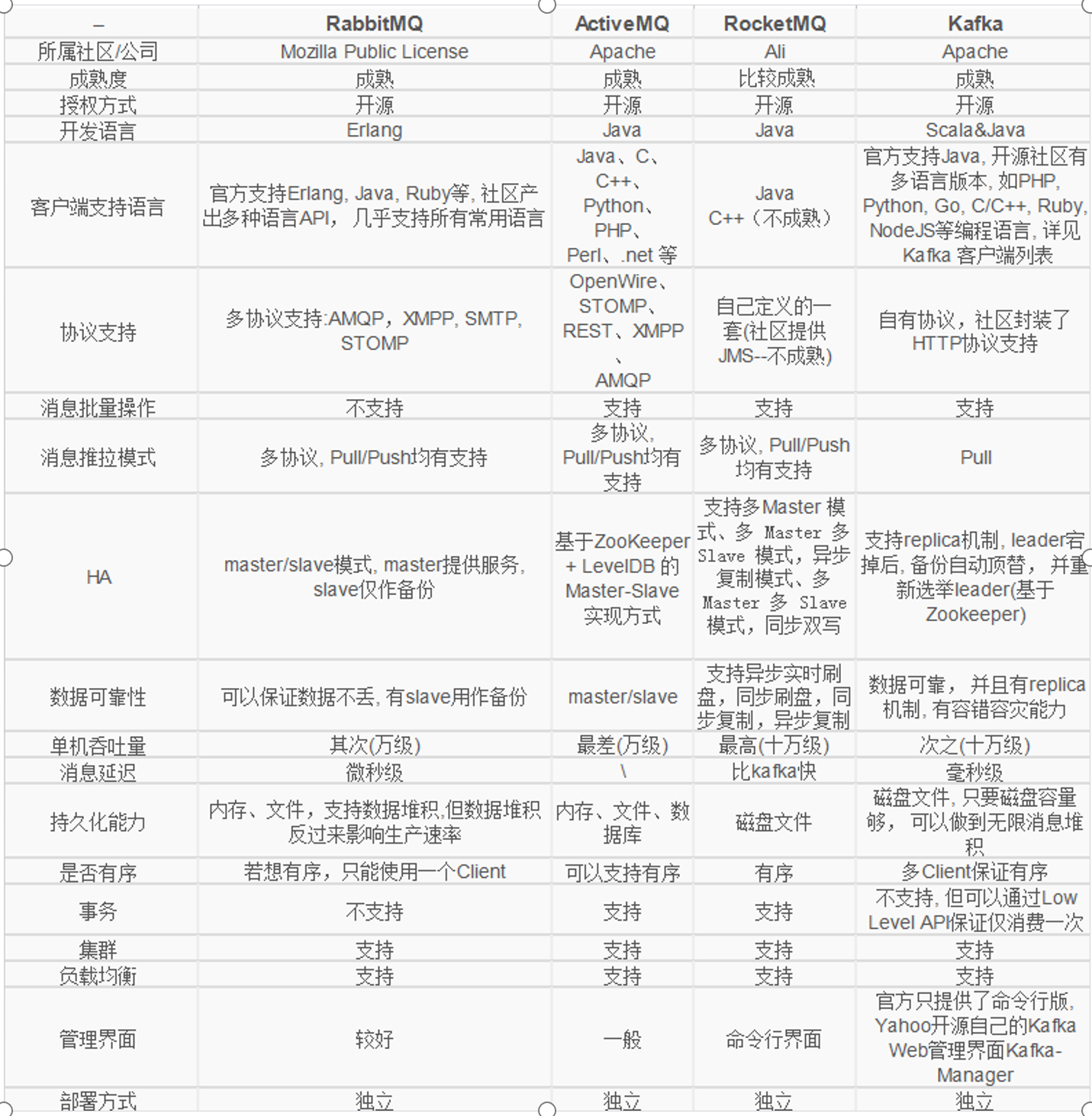
常见的消息队列产品
:happy:Kafka的简介
Kafka的基本介绍
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
- 开源-免费、使用广
- 分布式-可横向扩展
- 事件流和数据管道-实时消息处理
- 流数据分析
- 数据整合
- 去中心化(没有master)
特点:
- 并发性:分布式, 分区
- 可靠性: 副本和容错等
- 可扩展性: kakfa消息传递系统轻松缩放, 无需停机
- 耐用性: kafka使用分布式提交日志, 这个意味着消息会尽可能快速的保存在磁盘上, 因此它是持久的
- 性能: kafka对于发布和订阅消息都具有高吞吐量, 即使存储了许多TB的消息, 他也爆出稳定的性能- kafka非常快: 保证零停机和零数据丢失
Kafka的使用场景
- 基本上消息队列的使用场景都能满足
- 在日志采集方面使用比较多(配合flume)
- 大数据领域的消息总线
:kissing:Kafka的基本架构
Kafka的基础构架
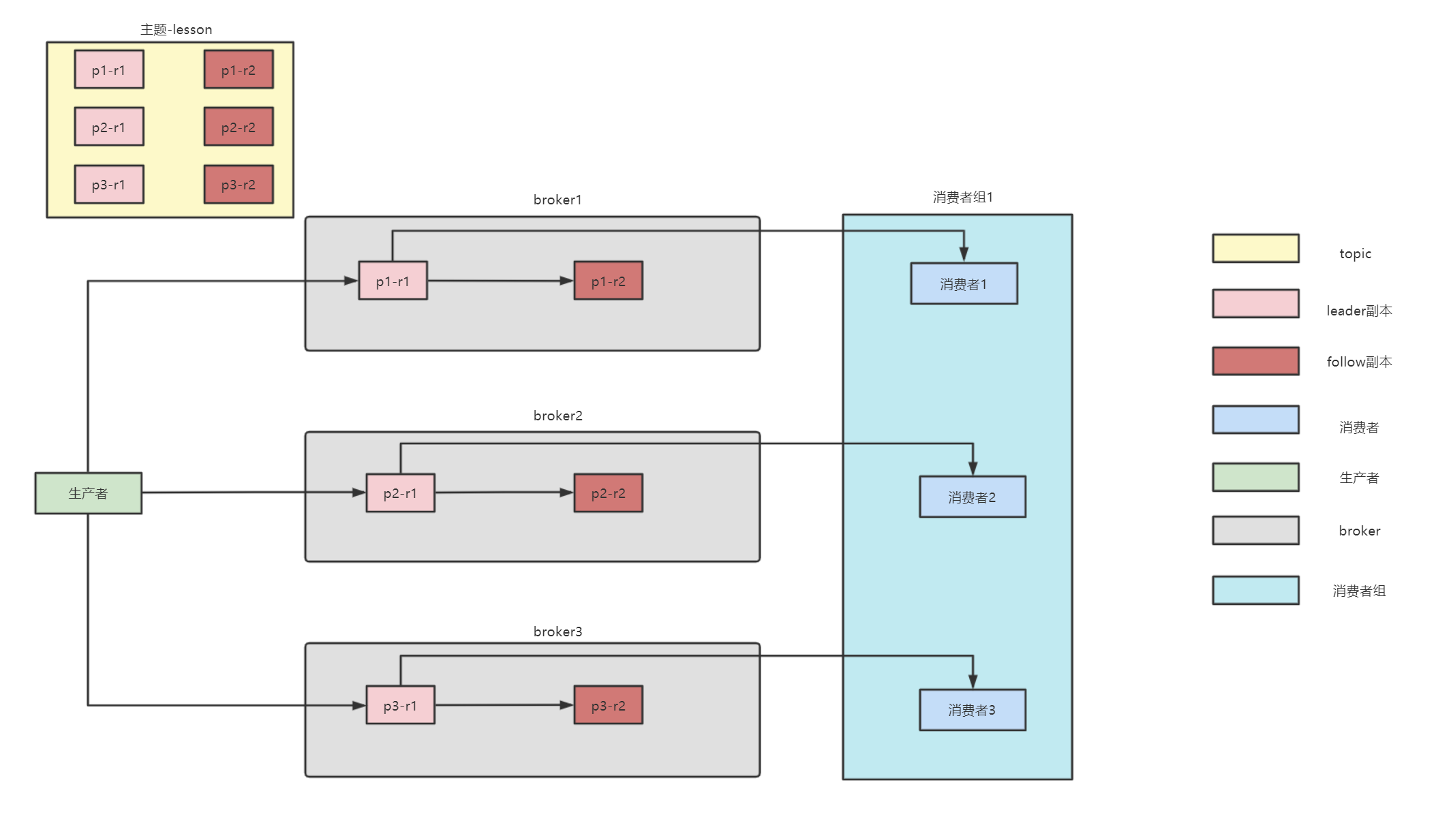
- 生产者-producer:负责生产消息(谁往Kafka中生产消息谁就是生产者)
- 消费者-consumer:负责消费消息(谁从Kafka中消费消息谁就是消费者)
- 运行实例-broker: Kafka实际工作的进程
- 主题-topic:一类消息的集合,消息往哪放从哪取相当于数据库中的表
- 分区-partition:数据的分区
- 副本-replica:数据的副本
- 主副本-leader replica:实际负责数据读写的副本,生产者和消费者都与这个副本进行交互的
- 从副本-follower replica:负责从主副本上同步数据,实现数据备份,保证数据可靠性
- 消费者组-consumer group:多个消费者的集合
- AR:ALL REPLICA所有副本的集合,等于ISR+OSR
- ISR: In Sync Replica数据同步成功的副本(实际可用的副本)
- OSR: Out of Sync Replica数据同步不成功的副本(不可用的副本)
:grin:Kafka的集群搭建
参考:安装部署文档
kafka集群需要zookeeper集群(Kafka3.0可以独立运行不再需要zookeeper)
:grin:Kafka的shell命令
启动集群
1 | 三个节点分别执行 |
创建Topic
1 | 创建1副本3分区 |

1 | 创建3副本3分区 |
注意:已经创建过的topic不可重复创建

模拟生产消费
1 | 启动一个模拟生产者 |
查看Topic列表
1 | bin/kafka-topics.sh --list --zookeeper node1:2181 |
查看Topic详情
1 | bin/kafka-topics.sh --describe --zookeeper node1:2181 --topic test |
删除Topic
1 | bin/kafka-topics.sh --delete --zookeeper node1:2181 --topic test |
修改Topic
1 | 修改分区数量 |

注意:topic的副本是不可修改的

:happy:Kafka tools
安装程序在提供的前期资料里
:grin:Kafka基准测试
1分区1副本
1 | 创建测试用的topic |
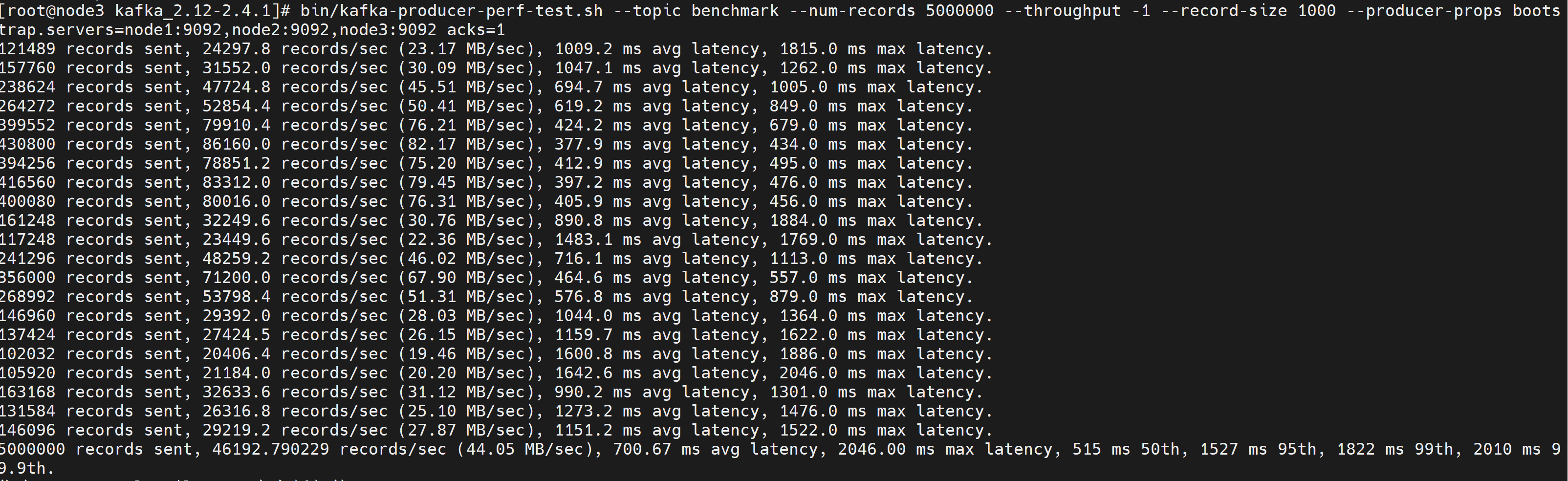
1 | bin/kafka-consumer-perf-test.sh --broker-list node1:9092,node2:9092,node3:9092 --topic benchmark --fetch-size 1048576 --messages 5000000 |

3分区1副本
1 | 创建测试用的topic |
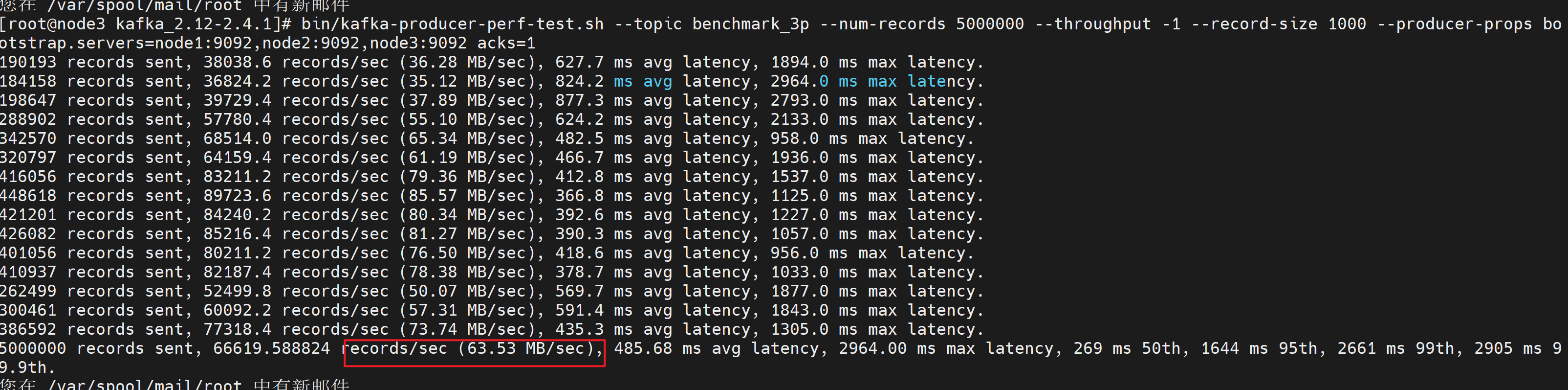
1 | bin/kafka-consumer-perf-test.sh --broker-list node1:9092,node2:9092,node3:9092 --topic benchmark_3p --fetch-size 1048576 --messages 5000000 |

注意:这个主题是有三个分区,但是我们只启动了一个消费者,只能三个分区依次消费(一个时刻只能消费分区)
:grin:kafka-python API使用
安装库
需要安装kafka-python
1 | pip install kafka-python -i https://pypi.tuna.tsinghua.edu.cn/simple |
生产者代码
1 | # coding:utf8 |
消费者代码
1 | # coding:utf8 |
- Kafka不能保证消费者消费数据整体有序
- 只能保证单个分区内的数据有序

:kissing:Kafka高级
Kafka的数据位移
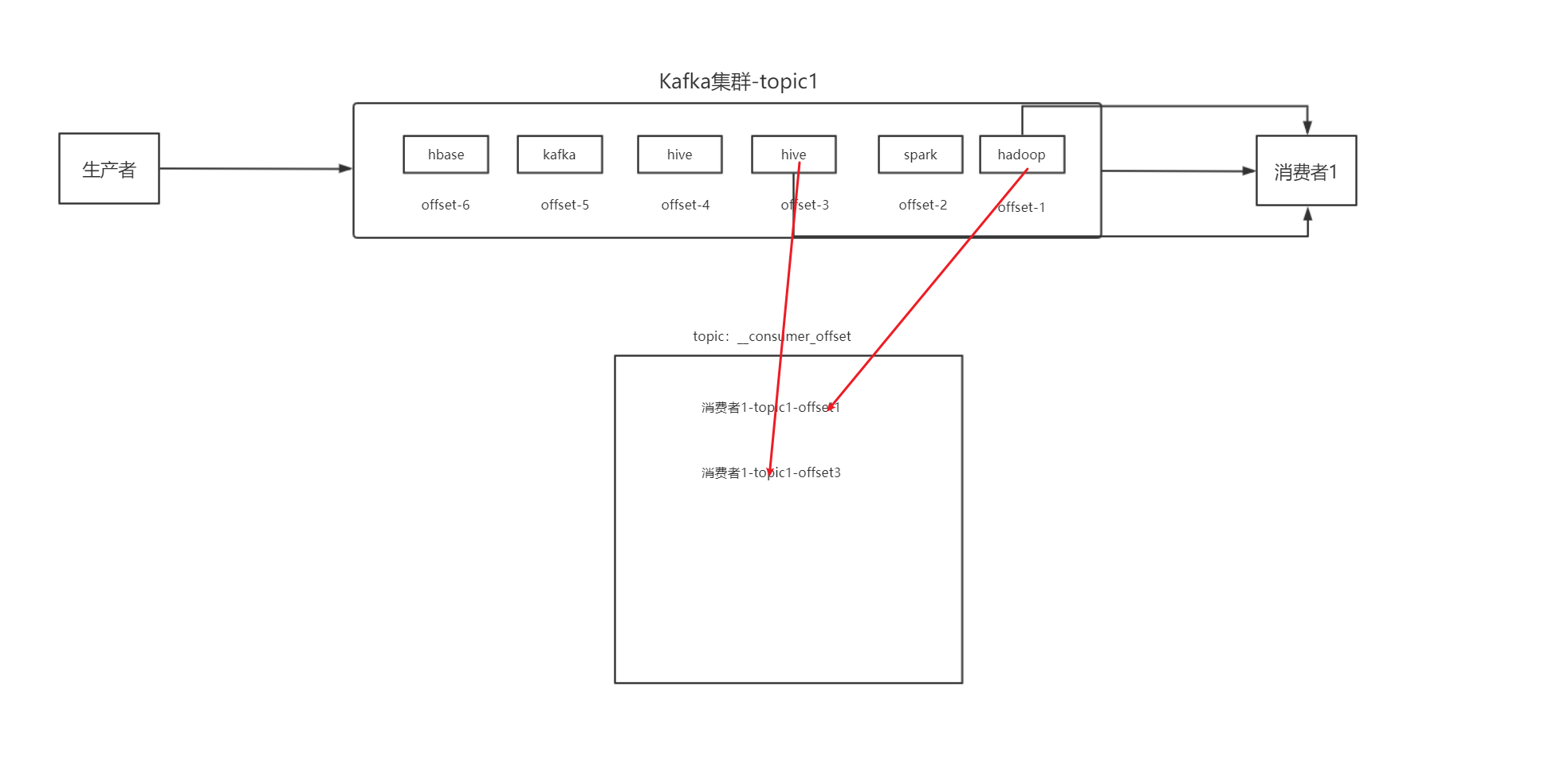
- 偏移量-生产者在把数据放进消息队列时,每个数据会附带一个offset
- 位移-消费者在从消息队列中消费数据时,会记录当前消费到什么位置offset
- 对于消费者消费的位移是保存在Kafka内置的topic:__consumer_offset中的
Kafka数据被消费之后是不会自动删除的
达到保存时间,默认是7天,参数在server.properties配置文件中
log.retention.hours=168(单位小时)
不同的消费者可以同时消费同一个主题,但是同一个消费者会不会重复消费呢?
- 生产者在生产数据的时候会生成对应的offset,也就是当前数据的offset
- 消费者在消费数据的时候会记录当前已消费数据的offset,也就是当前数据的offset
Kafka的分片与副本机制
- 分片:对于分布式的系统,可以将大规模的数据分开存储,比如hdfs上会把数据分成不同的block分别存储在不同的datanode上,即提高了存储能力又降低了复杂度,同时可以提高数据处理的并发能力
- 副本:对于分布式的系统,数据分散保存出现风险的机率高,有一个节点出现问题,数据就不完整了,所以可以利用副本的机制提高容错
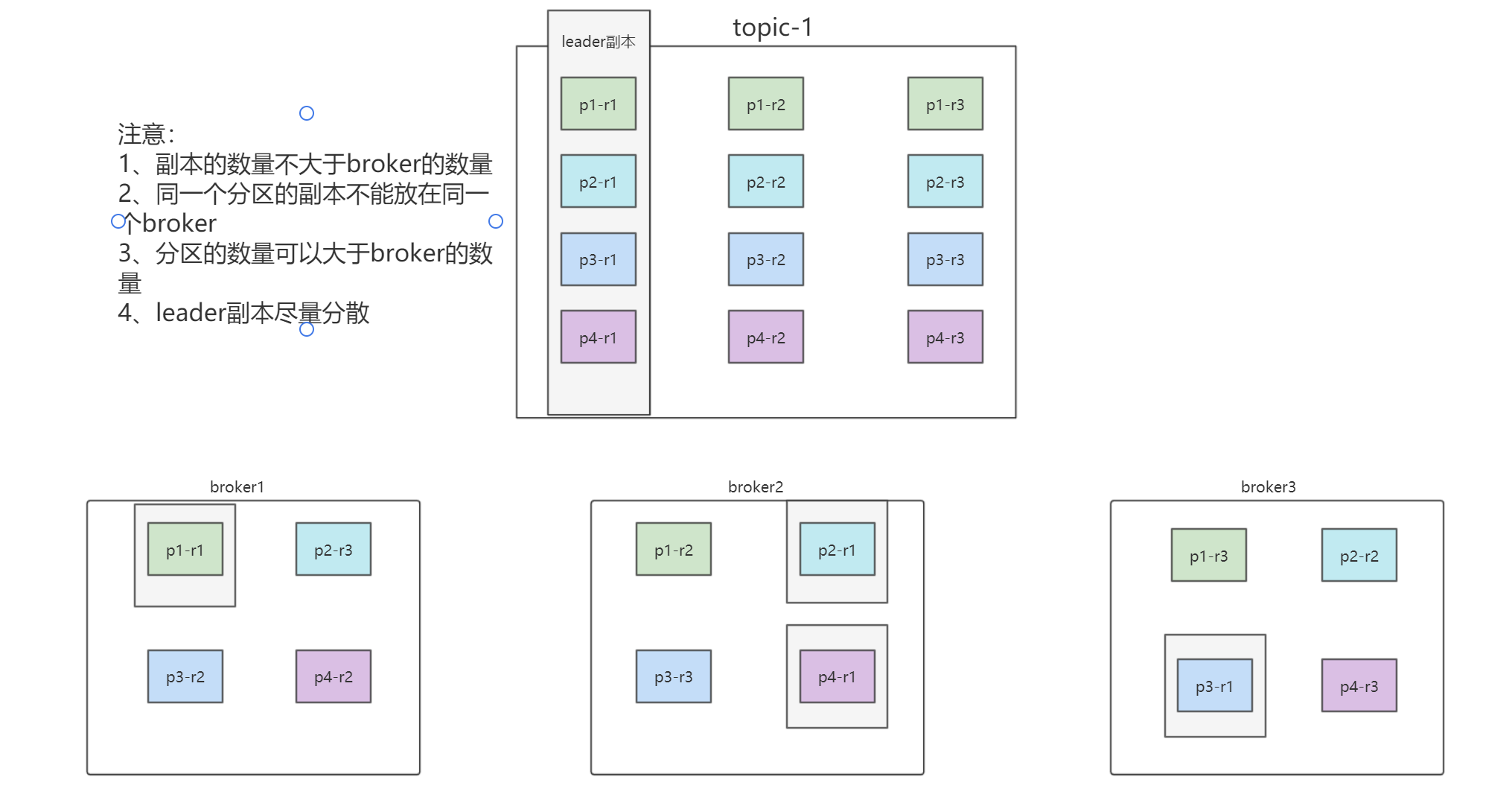
- 在Kafka中一个主题可以有多个分区,分区的数量建议是broker数量的N倍,可以更好的利用硬件资源,提高并行效率
- 一个分区可以设置多个副本,建议副本数不超过3个,即可以满足数据的容错,又不会太过影响性能
- 副本在broker数量满足的情况下会尽量分布在不同的broker上
- 副本之间会通过内部机制选举一个Leader副本,剩下的是follow副本,数据会首先写入Leader副本,其它follow副本会自动从Leader上同步数据
- 一般情况下Kafka集群也就是3、5、7台就够了,可以搭建多个Kafka集群
数据写入成功的标志应该是什么?是写入Leader还是Follow同步数据完成?
如何保证数据不丢失
生产者端
数据写入:
- 数据成功写入leader
- follow成功从leader同步数据
数据在写入leader之后有三种选择,取决于ack的值:
当ack=0时,生产者将数据写入leader后,就不管了,此时直接认定写入成功,写性能最高
当ack=1时,生产者将数据写入leader后,等待leader反馈,leader告诉生产者写入成功了,生产者才离开认定ok
当ack=-1时,生产者将数据写入leader后,会多等待一会,等leader反馈成功加上follow同步数据成功才离开认定ok
安全性:
- ack=0几乎没有安全性,但是写入性能是最好的
- ack=1有一定的安全性,能够确保数据成功写入leader,但是不确保副本同步数据成功,如果leader发生故障会造成数据丢失
- ack=-1安全性棒棒的,但是写入性能相对较低
在Kafka中:
- 所有副本统称为AR
- 同步数据正常的副本统称为ISR : In-Sync Replicas副本同步队列
- 同步数据不正常的副本叫OSR :Out-Of-Sync Replicas
写入的模式:
- 同步:顺序执行,写入一条等待反馈,再写下一条
- 异步:先将数据写入缓冲区,批量写入Kafka等待反馈
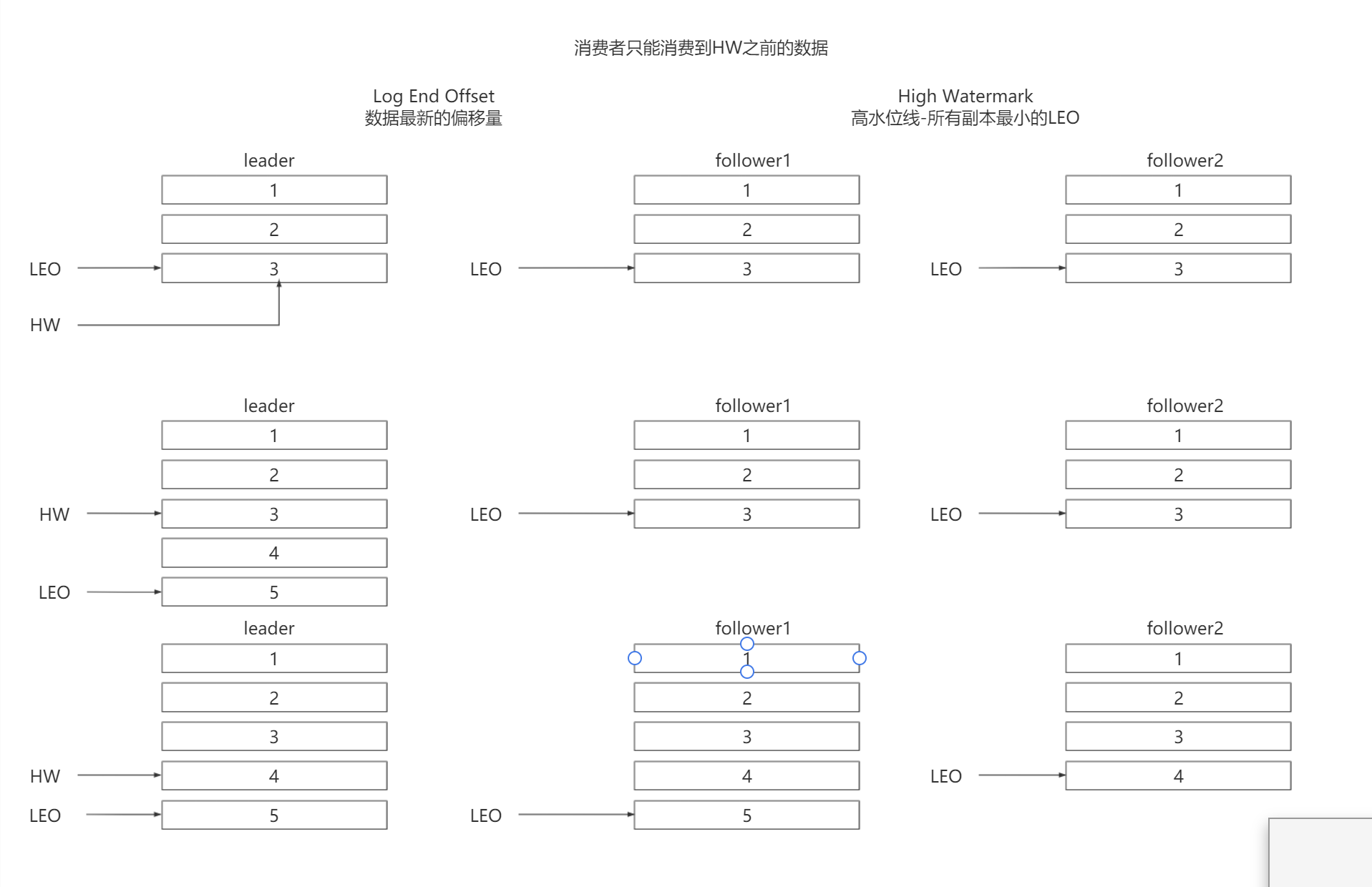
数据复制的过程,通过HW机制保证消费数据可靠性(只考虑ISR队列):
消费者端
消费靠提交offset,记录消费数据的位置
- 如果消费数据成功后再提交offset,可能会重复消费数据
- 如果先提交offset再消费数据,可能会少消费数据
Kafka的数据存储
存储位置
1 | 在config/server.properties内 |
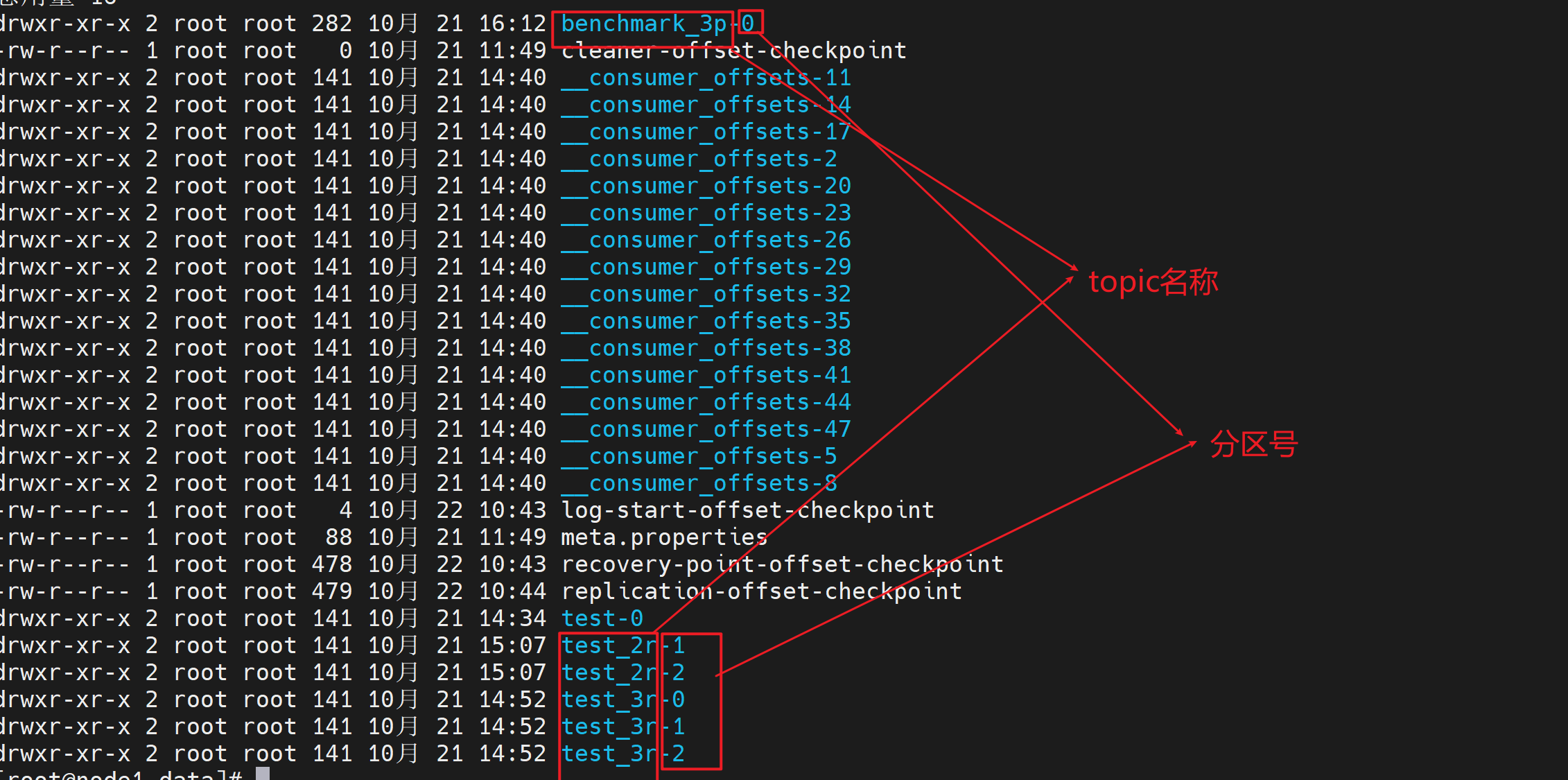
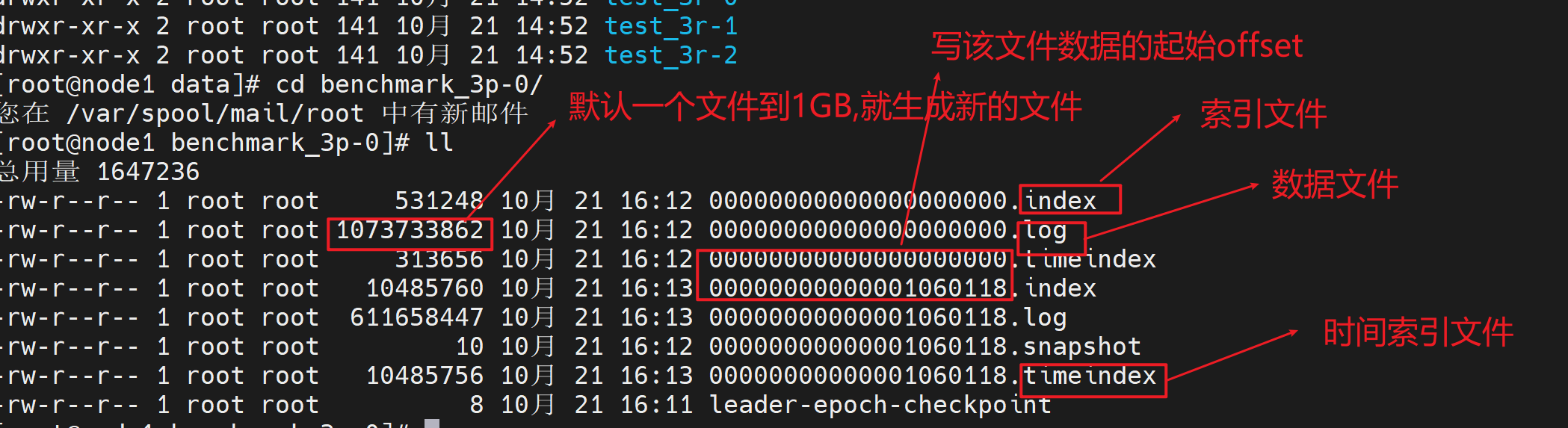
Kafka是怎样实现高吞吐的?
Kafka官方给出的性能指标能达到500MB/S(写入硬盘的指标),Kafka在写入数据时会预先找一块连续的磁盘空间顺序写入
- 根据log的文件名称就能快速定位某个offset数据在哪个文件
- Kafka默认,每写满1GB的.log文件后,就切换下一个文件
消费的流程
稀疏索引
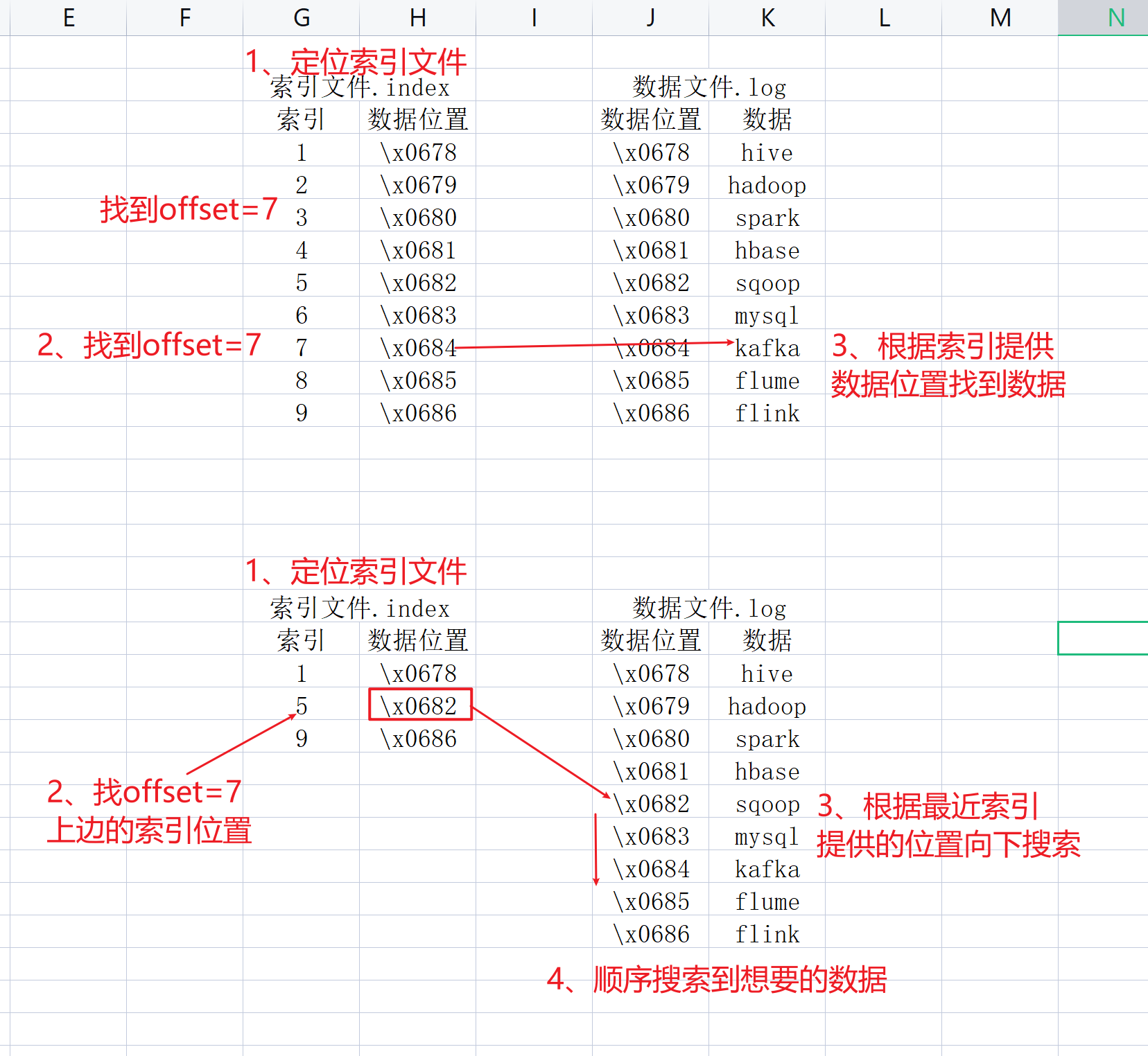
需求:找到offset=1060299这个数据
1、定位索引文件00000000000001060118.index
2、通过二分查找快速定位到对应索引区间,比如向上最近的位置:1060200
3、根据这个最近的索引位置到数据空间中向下搜索
4、顺序搜索到想要的数据offset=1060299
生产者的分发策略
内置的分区器
分区器负责决定当数据来时,这个数据被分发至哪个分区

指定分区发送
通过send方法指定分区转发
1 | furture = producer.send( |
练习:现在我们有三个分区,需要三个分区转发数据的比例为2:3:5
1 | # 指定三个分区的比例为2:3:5 |
指定key分发数据
1 | furture = producer.send( |
指定分区的优先级大于指定key
消费者的负载均衡
消费者组与分区
1 | bin/kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list |
1 | bin/kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --group mygroup --describe |
场景一:三个分区,一个消费者组里有一个消费者
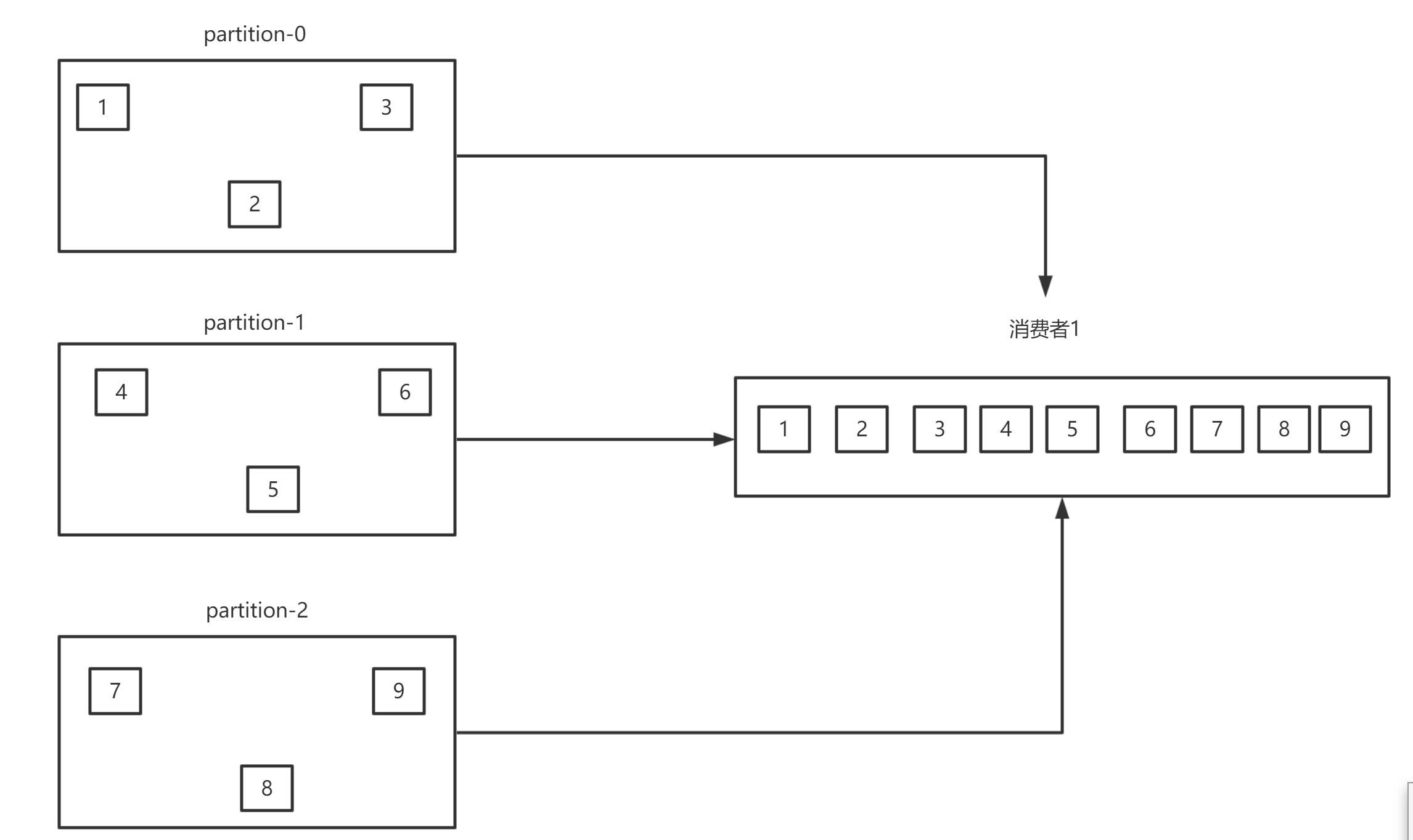
所有的分区都由这个一个消费进行消费

场景二:三个分区,一个消费者组里有四个消费者
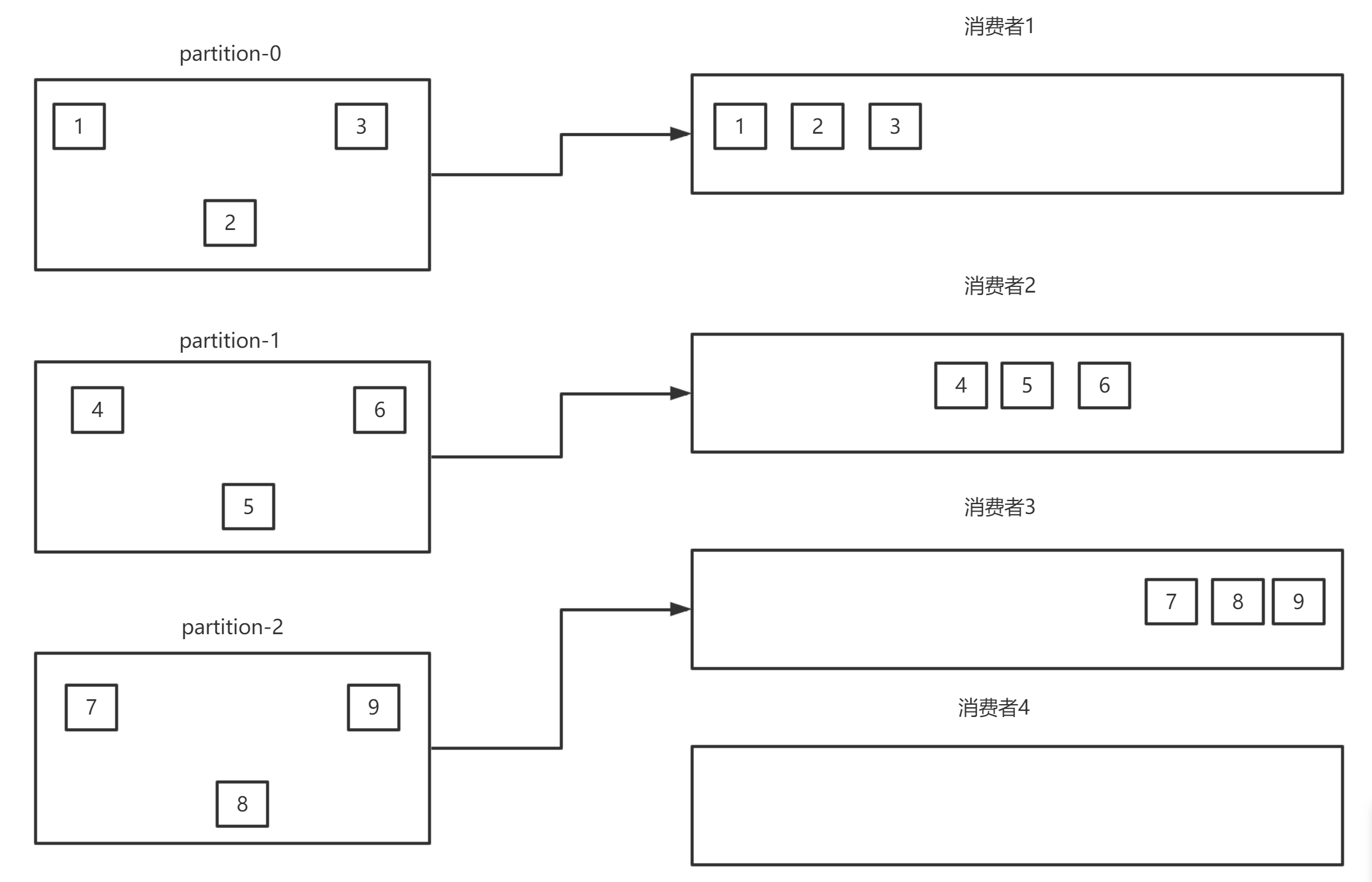
规则:同一个分区只能分配给一个消费者组内的一个消费者消费- 划分分区时最好保证消费者的数量与分区相等
- 当消费者数据大于分区数量时,肯定有消费者空闲

场景三:三个分区,两个消费者组分别有四个消费者
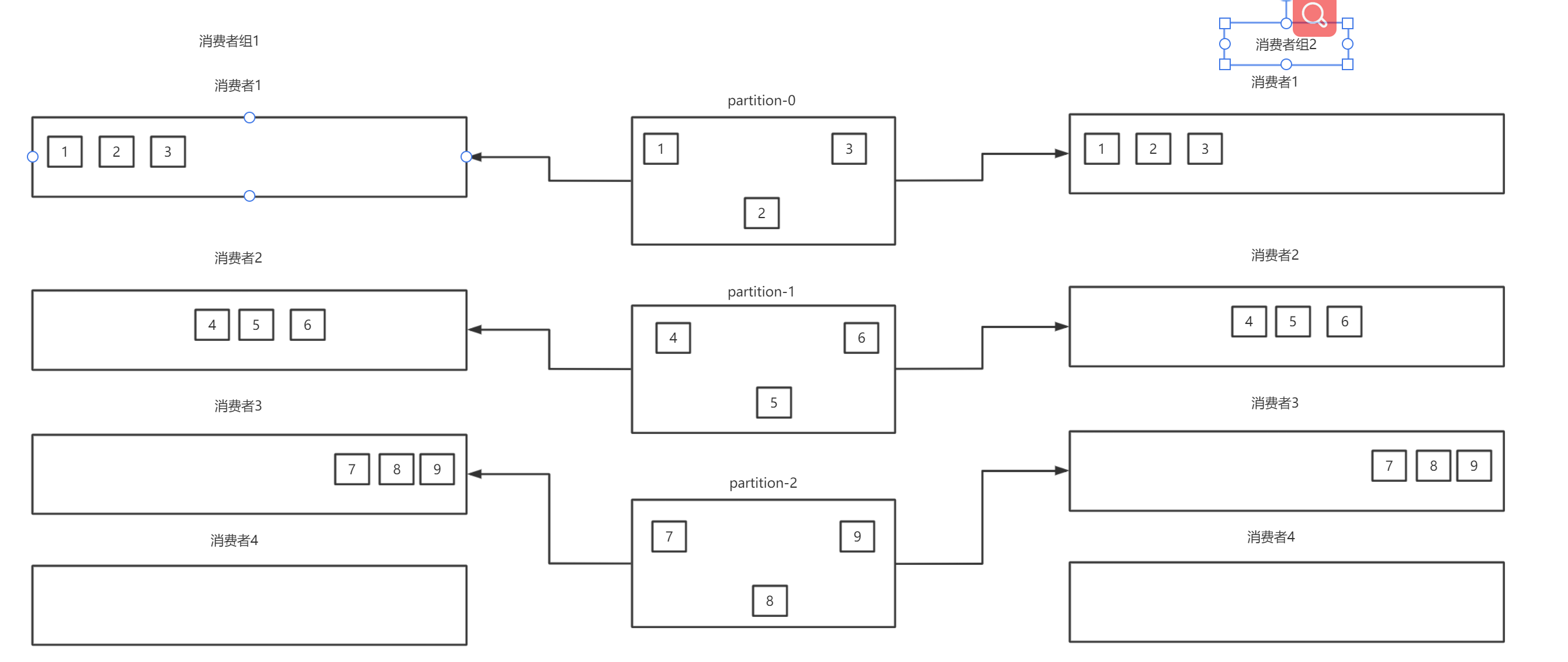
数据的堆积

LAG='LOG-END-OFFSET' - 'CURRENT-OFFSET'
:happy:kafka-eagle安装使用
查看安装文档
 微信
微信 支付宝
支付宝