
HBase(全)
:happy:实时计算基础
内容:
1、NoSql数据库(Hbase)
2、Kafka大数据领域最火最常用的消息队列
3、Spark StructuredStreaming(结构化流)
:happy:HBase基础内容
- HBase基础简介
- HBase集群搭建
- HBase数据模型
- HBase基于shell操作
- HBase基于Python操作
HBase产生背景
计算机时代
传统的关系型数据库管理系统(Relational Database Management System,RDBMS)早在20世纪70年代已经出现,并且帮助无数的公司和机构实现了给定问题的解决方案,时至今日,RDBMS仍旧非常有用。
实现增删改查
- mysql(百万)
- oracle(千万)
互联网时代
RDBMS在设计和实现商业应用方面扮演了一个不可或缺的角色(至少在可预见的未来仍旧如此)。只要用户需要保留用户、产品、会话、订单等信息,就会采用一些存储后端为前端应用服务器提供持久化数据的服务。这种结构非常适合有限的数据量,但对于数据急剧增长的情况,这种结构就显得力不从心了。
数据量和业务量飞速增长,出现了很多RDBMS的优化方案:
- 数据分区
- 读写分离
- 数据仓库(不常用的东西放仓库)
冷热分离:把冷数据和热数据分开存储,根据使用频率提供不同的方案
大数据时代
海量数据的存储
- 2003年,Google发表论文:”The Google File System”(GFS即:HADOOP HDFS前身)
海量数据的分析
- 2004年,Google发表论文:”MapReduce: Simpliied Data Processing on Large Clusters”(即:HADOOP MAPREDUCE前身)
海量数据的交互
- 2006年,Google发表论文:”BigTable: A Distributed Storeage System for Structured Data” (即:HADOOP DATABASE-HBASE前身)
HBase是一款适用于大规模数据存储的分布式、KV型,NoSQL数据库。拥有高效的随机查询能力和海量的吞吐能力
它基于Master-Slave模式,以主节点带领一群从节点,从而构建分布式集群,提供分布式数据存储能力。
HBase应用场景
- 对象存储
不少的头条类、新闻类的新闻、网页、图片存储在Hbase之中, 一些病毒公司的病毒库也是存储在Hbase中- 时序数据
HBase之上有openTSDB模块, 可以满足时序类场景的需求timestamp- 推荐画像
用户画像, 是一个比较大的稀疏矩阵, 蚂蚁金服的风控就是构建在Hbase之上- 时空数据
主要是轨迹, 气象网格之类, 滴滴打车的轨迹数据主要存在Hbase之中, 另外在所有大一点的数据量的车联网企业, 数据也是存储在HBase- CubeDb OLAP
kylin 一个cube分析工具, 底层的数据就是存储在Hbase之中, 不少客户自己基于离线计算构建cube存储在hbase之中, 满足在线报表查询的需求- 消息/订单
在电信领域、银行领域, 不少的订单查询底层的存储, 另外不少通信、消息同步的应用构建HBase之上- Feeds流
典型的应用就是xx朋友圈类型的应用, 用户可以随时发布新内容, 评论、点赞- NewSQL
之上有Phoenix的插件, 可以满足二级索引, SQL的查询, 对接传统数据需要SQL非事务的需求- 其他
存储爬虫数据
海量数据备份
短网址
………..
1 | Use Apache HBase™ when you need random, realtime read/write access to your Big Data. |
HBase发展
下面是一个HBase随时间发展的简短概述:
- 2006年11月∶Google发布BigTable论文。
- 2007年2月∶HBase 宣布在Hadoop项目中成立。
- 2007年10月∶HBase第一个“可用”版本(Hadoop 0.15.0)。
- 2008年1月∶Hadoop成为Apache的顶级项目,HBase成为Hadoop的子项目。
- 2008年10月∶HBase0.18.1发布。
- 2009年1月∶HBase0.19.0发布。
- 2009年9月∶HBase0.20.0发布,性能有明显提升。
- 2010年5月∶HBase成为Apache的顶级项目。
- 2010年6月∶HBase 0.89.20100621,第一个开发版本。
- 2011年1月∶HBase 0.90.0发布,稳定性和持久性有所提升。
- 2011年年中∶HBase 0.92.0发布,支持协处理器和安全控制。
HABES很成熟
HBase的特点
强一致性读/写: HBASE不是“最终一致的”数据存储 , 它非常适合于诸如高速计数器聚合等任务
自动分块: HBase表通过Region分布在集群上,随着数据的增长,区域被自动拆分和重新分布
自动RegionServer故障转移
Hadoop/HDFS集成: HBase支持HDFS开箱即用作为其分布式文件系统
MapReduce : HBase通过MapReduce支持大规模并行处理,将HBase用作源和接收器
Java Client API: HBase支持易于使用的 Java API 进行编程访问
Thrift/REST API
块缓存和
布隆过滤器: HBase支持块Cache和Bloom过滤器进行大容量查询优化运行管理: HBase为业务洞察和JMX度量提供内置网页。
HBase vs RDBMS
RDBMS:关系型数据库(MYSQL)
HBASE:非关系型数据库
- 数据逻辑组织形式都是table
- HBASE本身是不支持SQL语句的(phoenix)
- HBASE本身不怎么支持ACID(原子性、一致性、持久性、隔离性)
| HBase | RDBMS | |
|---|---|---|
| 结构 | 1. 以表形式存在 2. 支持HDFS文件系统 3. 使用行键(row key) 4. 原生支持分布式存储、计算引擎 5. 使用行、列、列族和单元格 |
1. 数据库以表的形式存在 2. 支持FAT、NTFS、EXT、文件系统 3. 使用主键(PK) 4. 通过外部中间件可以支持分库分表,但底层还是单机引擎 5. 使用行、列、单元格 |
| 功能 | 1. 支持向外扩展 2. 使用API和MapReduce、Spark、Flink来访问HBase表数据 3. 面向列蔟,即每一个列蔟都是一个连续的单元 4. 数据总量不依赖具体某台机器,而取决于机器数量HBase不支持ACID(Atomicity、Consistency、Isolation、Durability) 5. 适合结构化数据和非结构化数据 6. 一般都是分布式的 7. HBase不支持事务,支持的是单行数据的事务操作不支持Join |
1. 支持向上扩展(买更好的服务器) 2. 使用SQL查询 3. 面向行,即每一行都是一个连续单元 4. 数据总量依赖于服务器配置 5. 具有ACID支持 6. 适合结构化数据 7. 传统关系型数据库一般都是中心化的 8. 支持事务 9. 支持Join |
HBase vs HDFS
HDFS:分布式文件存储系统
HBASE:分布式数据库
- HBASE有自己的文件格式
| HBase | HDFS |
|---|---|
| 1. HBase构建在HDFS之上,并为大型表提供快速记录查找(和更新) 2. HBase内部将大量数据放在HDFS中名为「StoreFiles」(HFile)的索引中,以便进行高速查找 3. Hbase比较适合做快速查询等需求,而不适合做大规模的OLAP应用 |
1. HDFS是一个非常适合存储大型文件的分布式文件系统 2. HDFS它不是一个通用的文件系统,也无法在文件中快速查询某个数据 |
HBase vs Hive
HIVE:构建数据仓库的工具(把SQL语句转化为MAPREDUCE任务的工具)
| HBase | Hive |
|---|---|
| 1. 是一种面向列存储的非关系型数据库。 2. 用于存储结构化和非结构化的数据 3. 适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。 4. 基于HDFS 5. 数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理 6. 延迟较低,接入在线业务使用,面对大量的企业数据,HBase可以实现单表大量数据的存储,同时提供了高效的数据访问速度 |
1. 数据仓库工具 2. Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询 3. Hive适用于离线的数据分析和清洗,延迟较高 4. Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行 |
总结一下:
- RDBMS:少量数据下的业务系统用的数据库,通常支持事务
- HDFS:海量数据下的存储
- Hive:海量数据的分析
- HBase:海量数据的随机访问,基于HDFS的
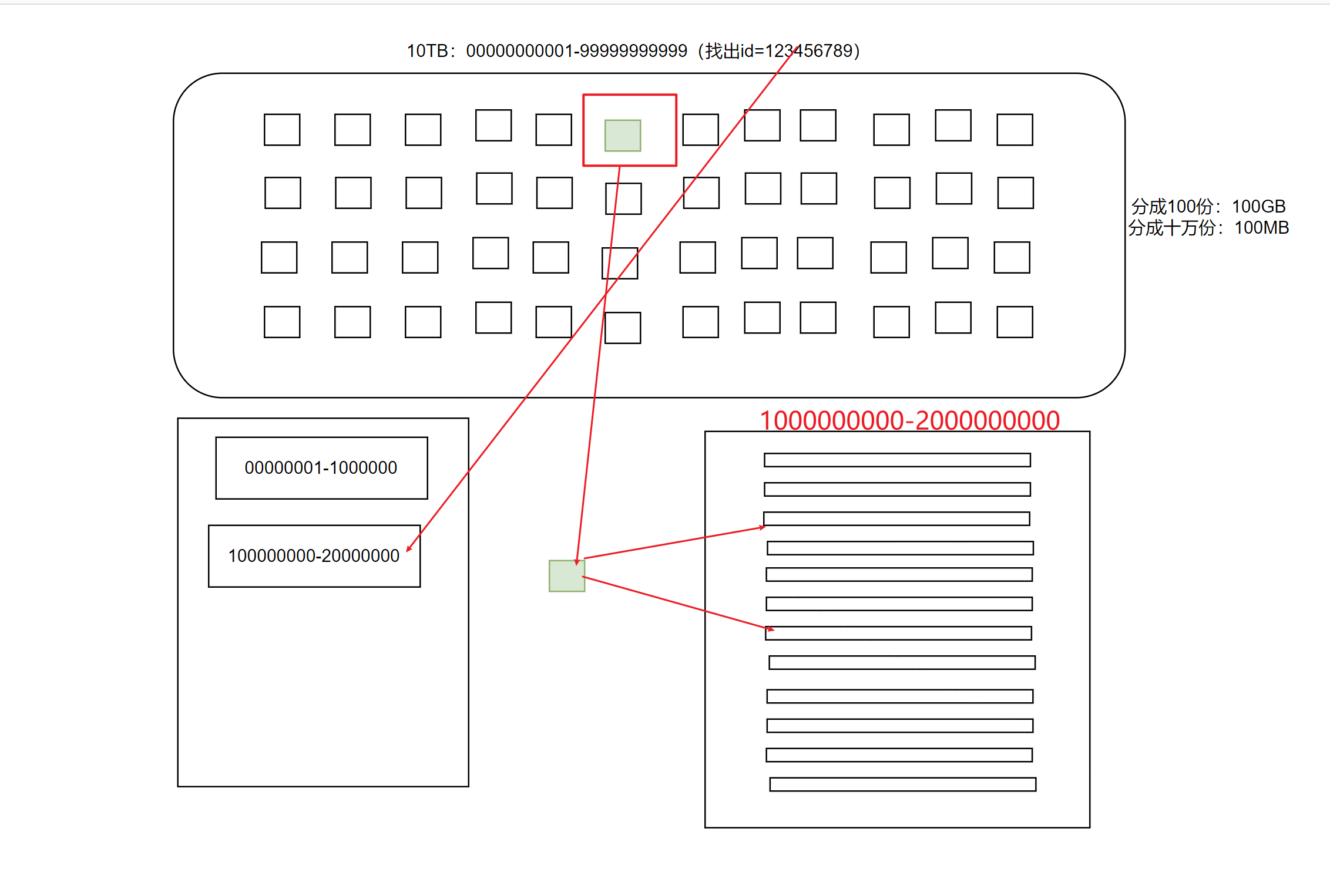
思考:怎么从10TB的数据中快速查找到我们想要的数据?
- 先对数据进行切分,将对应的数据放到对应数据块
- 放到的过程中会进行排序
- 再对数据块排序好的数据进行二分查找
:grin:HBase安装部署
HBase是运行在HDFS上的
所以HBase部署的前提必须得先启动HDFS
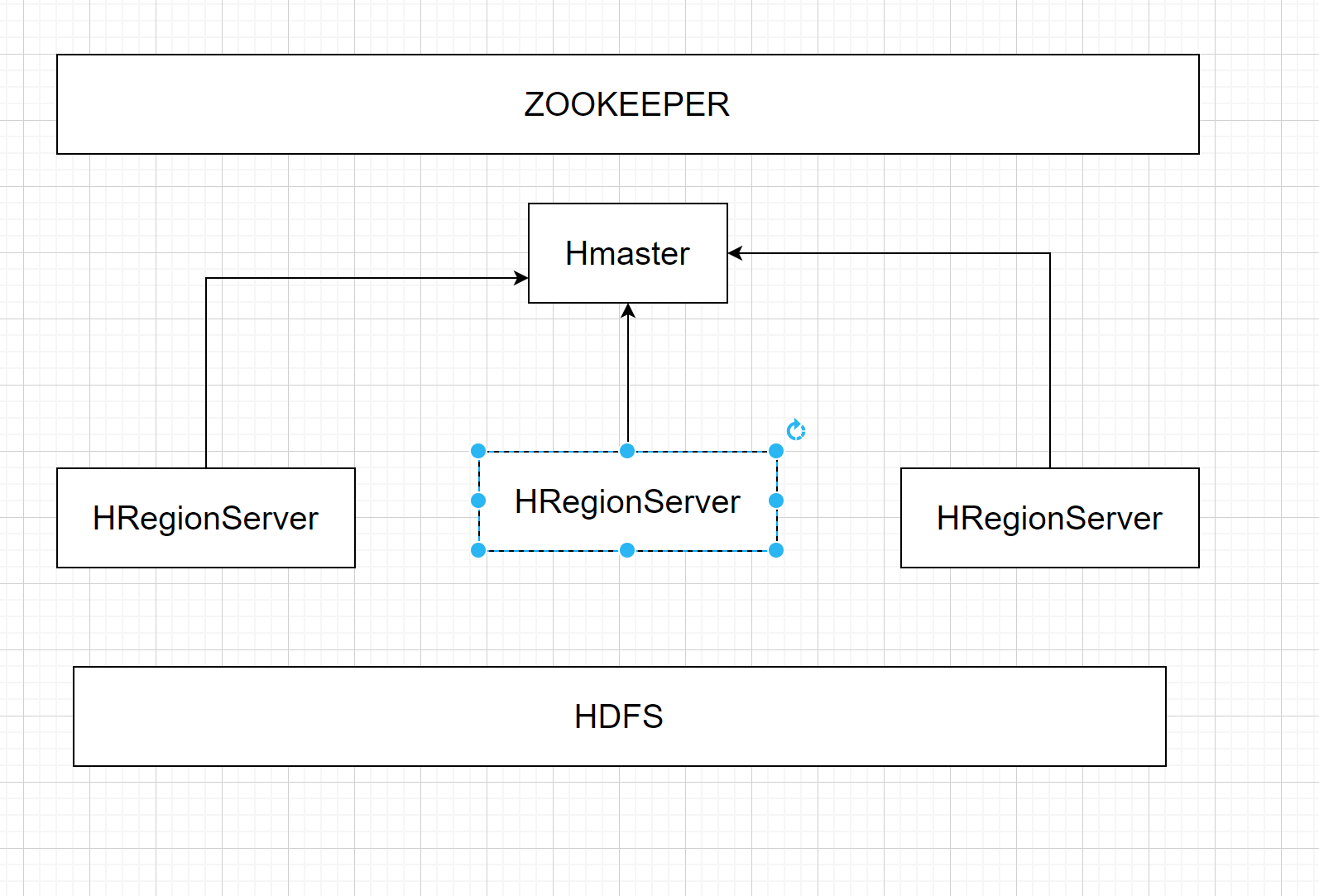
通常一个HBase集群需要:
- HDFS集群(存储数据)
- zookeeper集群(存储相关的元数据)
- HMaster主节点
- HRegionServer从节点
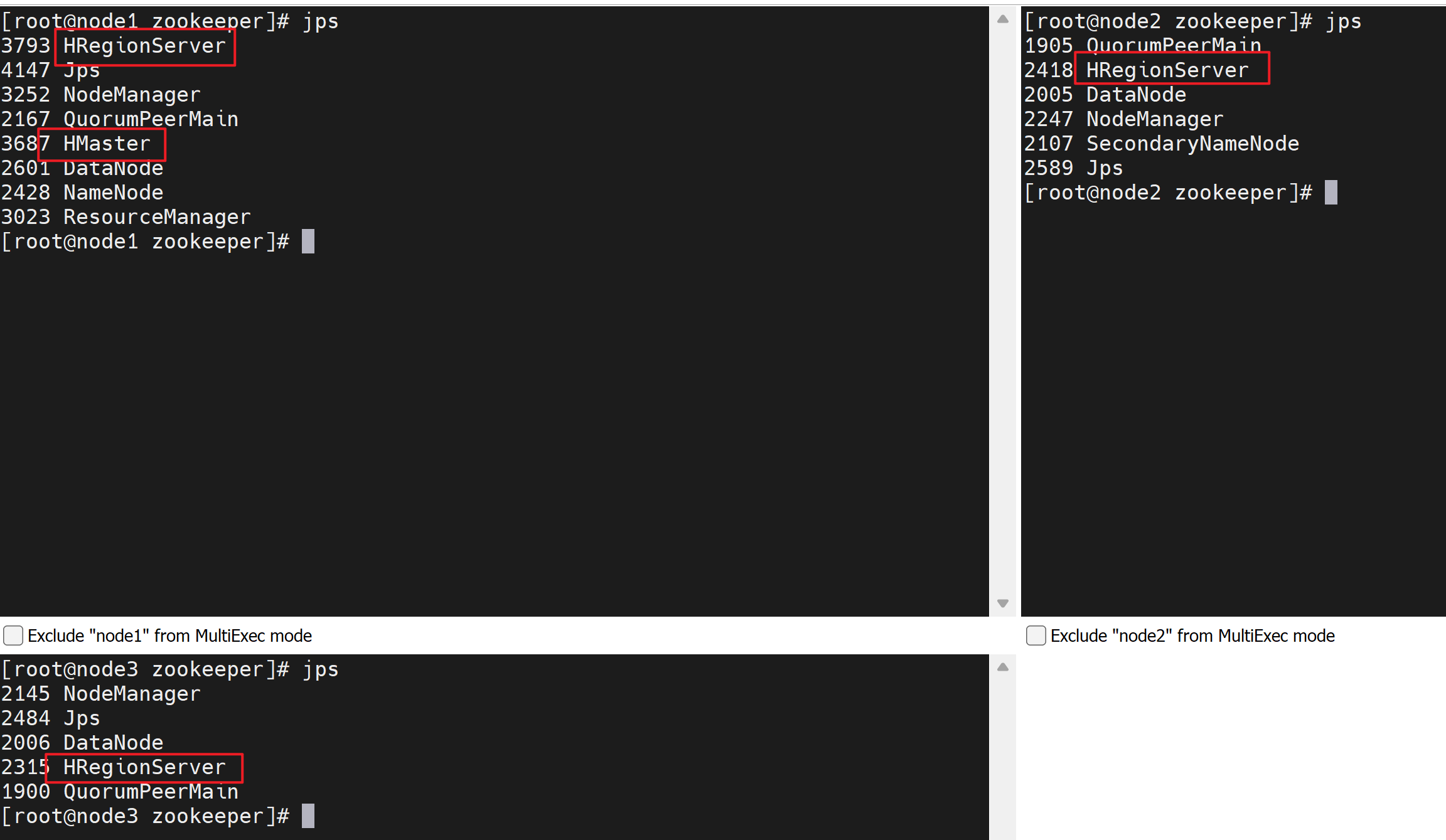
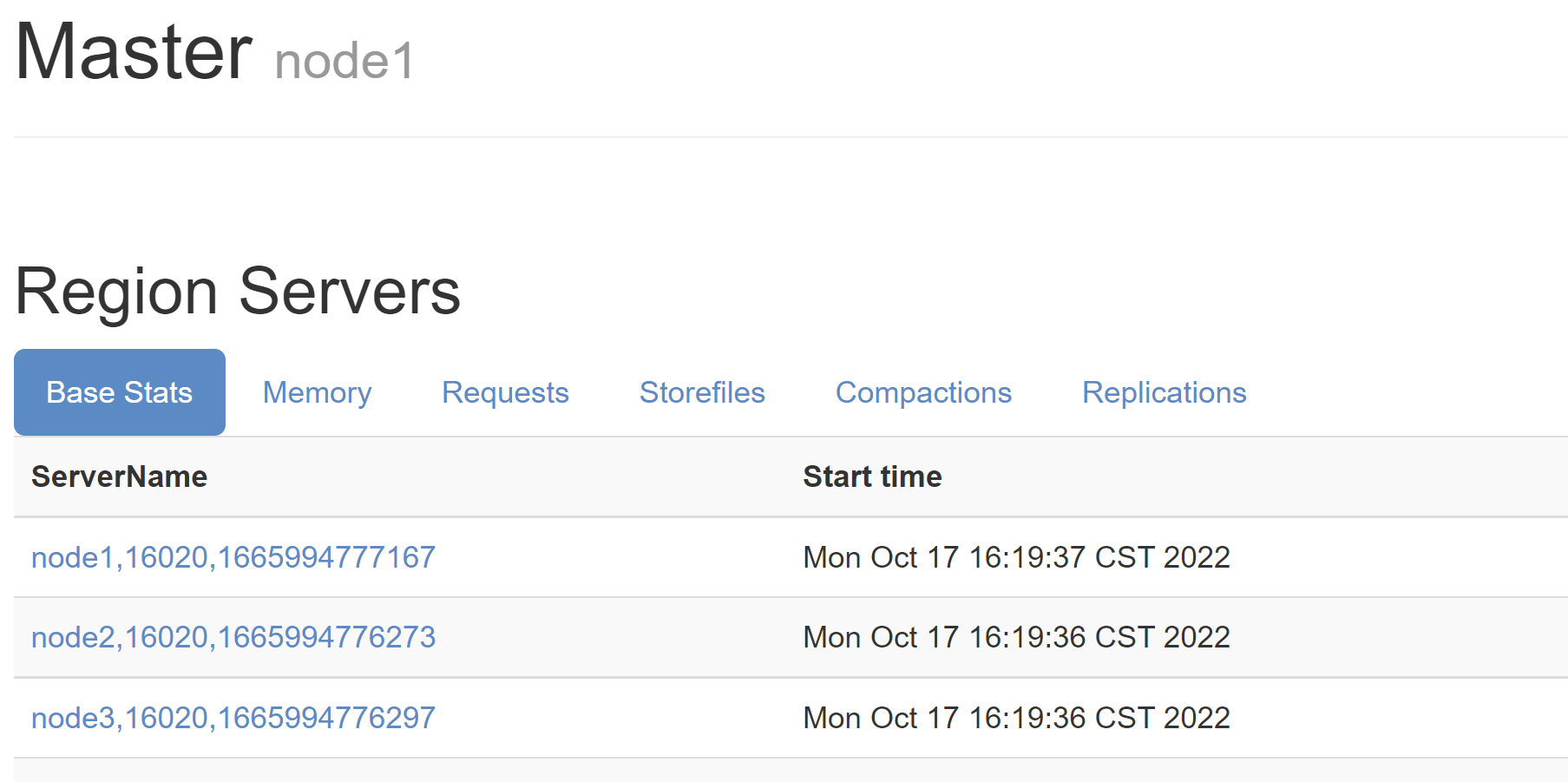
集群规划
| 节点 | 进程 |
|---|---|
| node1 | NameNode、DataNode、zk、Hmaster、HRegionServer |
| node2 | DataNode zk、HRegionServer |
| node3 | DataNode zk、HRegionServer |
安装部署
1、上传安装程序包
1 | 用我们的shell客户端即可 |
2、解压
1 | tar -zxvf 程序包 -C /export/server |
3、修改配置文件
- hbase-env.sh
1 | 加载JDK路径 |
- hbase-site.xml
1 | <configuration> |
regionservers
1
2
3
4增加regionserver的节点
node1
node2
node3
4、分发安装程序和配置文件
1 | scp -r hbase-2.1.0/ node2:`pwd` |
5、编辑环境变量
1 | 注意 三个节点都需要配置 |
注意配置完环境变量之后需要加载
1 | source /etc/profile |
6、启动
- 启动zk
1 | bin/zkServer.sh start |
- 启动HDFS
1 | start-all.sh |
- 启动HBase
1 | start-hbase.sh |
web(默认端口16010):
:kissing:HBase数据模型
HBase是一款KV型、分布式、列式存储的NoSql数据库
所以HBase的数据存储是以列为单位的
常见的存储类型主要分为:
- 行式存储
- 列式存储
行式存储
比如:常见的关系型数据库:MySql数据库中的表、CSV、EXCEL文件
| name | sex | addr |
|---|---|---|
| yangkunlin | 男 | 河南商丘 |
| 莫文蔚 | 女 | 河南安阳 |
| 周杰伦 | 男 | 河南郑州 |
数据以行为单位进行存储,将确定的行划分到确定的文件中进行保存

列式存储
以列为存储单位,将不同的列划分到不同的文件中进行保存

行列对比
列式存储的优势
- 针对单独列CRUD(增删改查)效率高
- 不需要遍历每行的所有列
- 单独操作指定列即可
- 针对不同的列可以使用不同的压缩算法
- 大多数情况下,每一列的数据类型是不同的
- 不同数据类型适用的压缩算法也不一样
- 针对不同的列建立不同的索引
- 对指定的列进行排序即可
列式存储的劣势
- 可读性差,学习成本高,不像行式数据存储结构好理解
- 整行操作CRUD都不如行式存储,数据分散在不同的文件,修改一行需要修改所有文件
- 支持事务难,也是因为数据分散在不同的文件中,事务需要对整体数据进行操作,列越多,复杂度越高
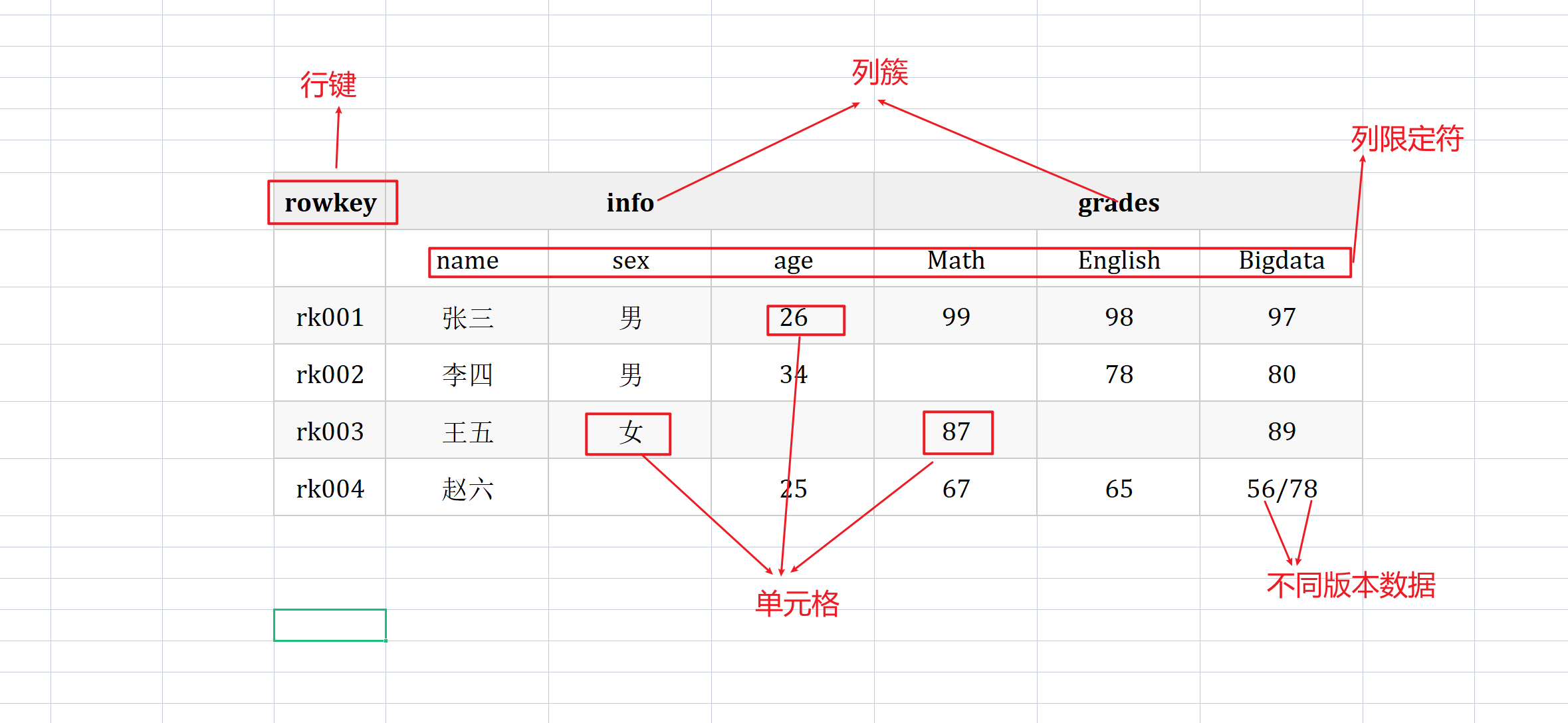
HBase表结构
HBase也是通过表(Table)的形式进行逻辑上组织数据的
| rowkey | info | info | info | grades | grades | grades |
|---|---|---|---|---|---|---|
| name | sex | age | Math | English | Bigdata | |
| rk001 | 张三 | 男 | 26 | 99 | 98 | 97 |
| rk002 | 李四 | 男 | 34 | 78 | 80 | |
| rk003 | 王五 | 女 | 87 | 89 | ||
| rk004 | 赵六 | 25 | 67 | 65 | 56/78 |
- 每个表由行和列组成
- 每一行有一个行键(rowkey),每个列的值与rowkey相关联
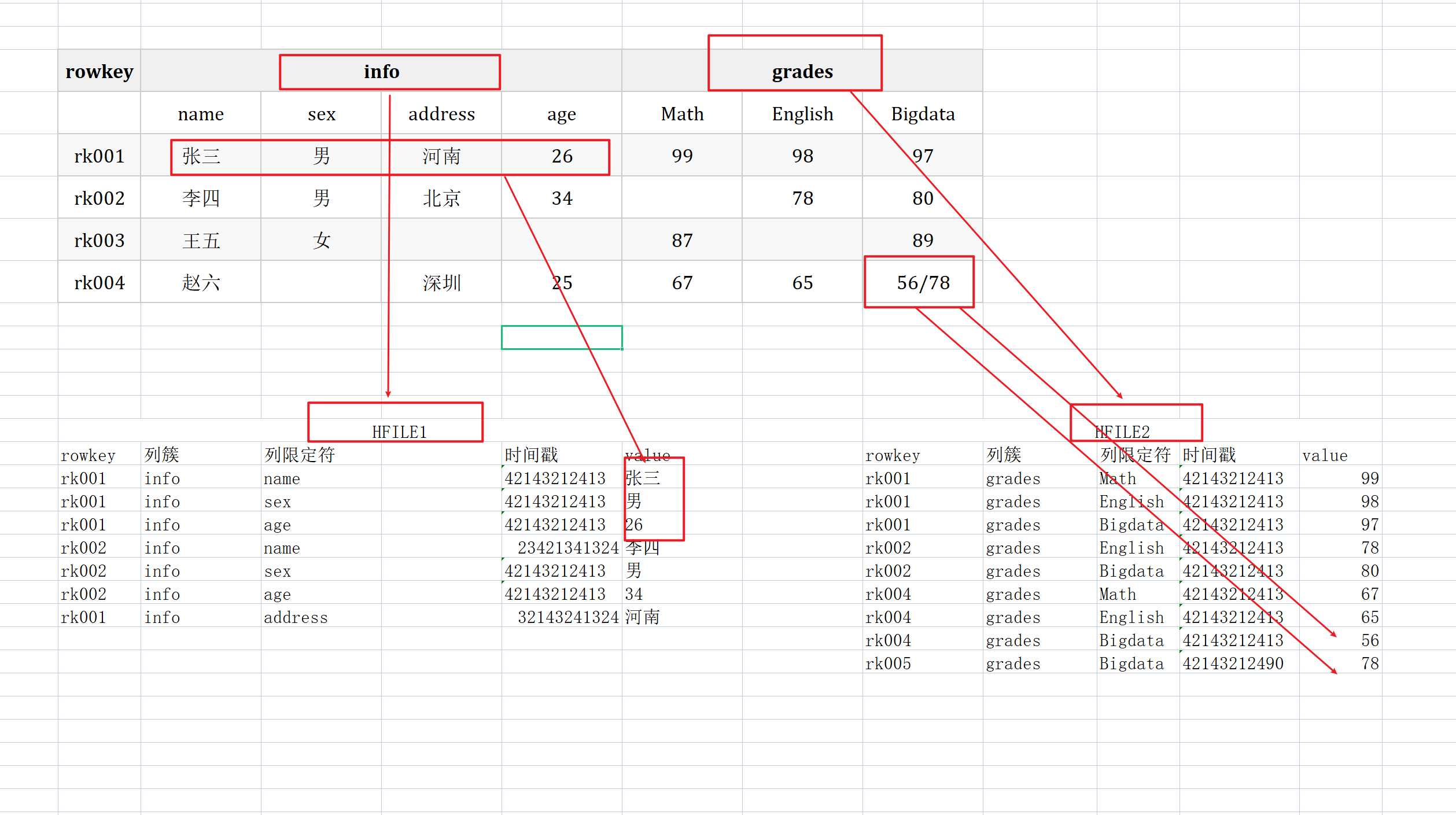
HBASE中的唯一索引 - 每个列都是由Column Family(列簇)和 Column Qualifier(列限定符)组成,例如:info: name,info: age 。建表时,只需声明列簇,而列限定符无需预先定义。列簇是HBase的基本存储单元,
每个列簇都是一个单独存储的文件叫做HFile - 列族(column family-CF):一个table有许多个列族,列族是列的集合,属于表结构,也是表的基本访问控制单元。
- 列标识(column qualifier-CQ):每个记录可以动态添加, Column Family:Column Qualifier形式标识
- timestamp时间戳,用来标识数据的不同版本,如果插入数据时不指定,HBase会默认添加,值为写入HBase时的时间
- 单元格(Cell): 单元格是行、列族和列限定符的组合,包含一个值和一个时间戳,
数据以二进制存储
逻辑视图
方便查看使用的数据形式
物理视图
实际存储组织的数据形式
HBase的KeyValue
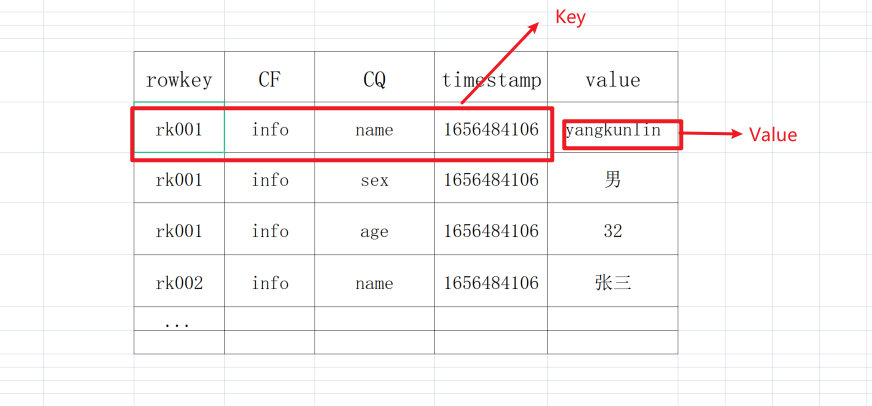
key是由行键、列簇、限定符、时间戳组成value就是一个具体的值
:grin:HBase的shell命令
进入shell客户端
1 | hbase(main):001:0>hbase shell |
查看集群状态
1 | hbase(main):001:0>status |
查看帮助
1 | hbase(main):001:0>help |
查看所有表
1 | hbase(main):001:0> list |
创建表
1 | 语法:create '表名', 'CF1', 'CF2' |
查看表信息
1 | desc 'user' |
向表中插入数据
1 | 语法:put '表名', 'rowkey', '列簇:限定符', '待插入的值' |
如果对已经存在的数据(cell),重复put,那么数据会更新(追加了一条新的数据 只是时间戳是最新并没有覆盖原来数据)
查询数据
1 | 1、通过rowkey进行查询 |
过滤器的查询地址:http://hbase.apache.org/2.2/devapidocs/index.html
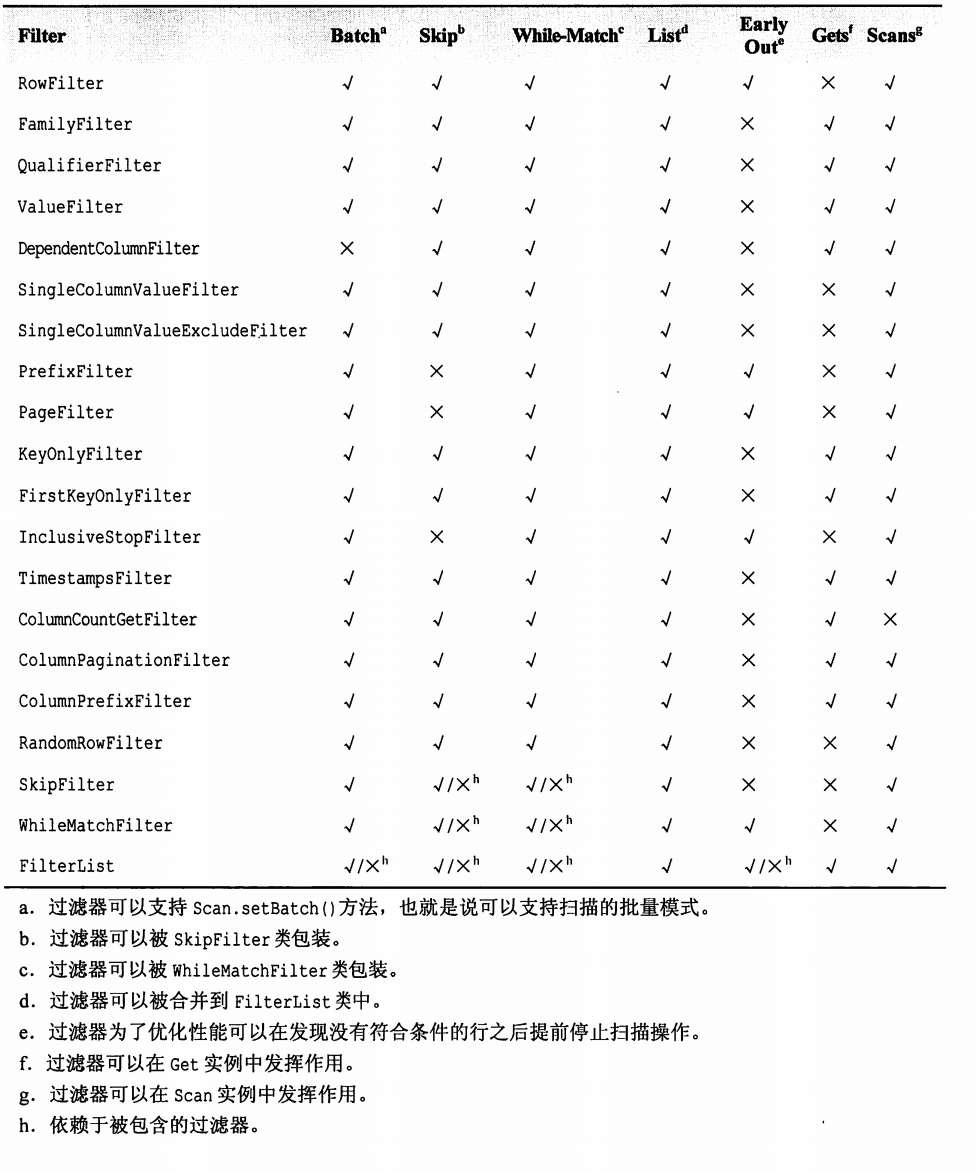
比较过滤器(comparison filter)
直接继承自CompareFilter类。
- 行过滤器(RowFilter)
- 列族过滤器(FamilyFilter)
- 列名过滤器(QualifierFilter)
- 值过滤器(ValueFilter)
- 参考过滤器(DependentColumnFilter)
专用过滤器
直接继承自FilterBase类,同时更以用于特定的使用场景。
- 单列值过滤器(SingleColumnValueFilter)
- 单列排除过滤器(SingleColumnValueExcludeFilter)
- 前缀过滤器(PrefixFilter)
- 分页过滤器(PageFilter)
- 行键过滤器(KeyOnlyFilter)
- 首次行健过滤器(FirstKeyOnlyFilter)
- 包含结束的过滤器(InclusiveStopFilter)
- 时间戳过滤器(TimestampsFilter)
- 列分页过滤器(ColumnPaginationFilter)
- 列前缀过滤器(ColumnPrefixFilter)
- 随即行过滤器(RandomRowFilter)
附加过滤器
不依赖过滤器本身,但却可以应用于其他过滤器上面。
- 跳转过滤器(SkipFilter)
- 全匹配过滤器(WhileMatchFilter)
FilterList
使用多个过滤器共同限制返回到客户端的结果。
自定义过滤器
当过滤器处理一行数据时,过滤器中各方法的逻辑流程。
更新删除数据
1 | 1、更新数据值 |
注意:
1、deleteall 是在 hbase 2.0版本后出现的, 在2.0版本之前, 只需要使用delete这个命令即可完成所有的删除数据工作,
2、delete删除数据时候, 只会删除最新版本的数据, 而deleteall 直接将对应数据的所有的历史版本全部删除
清空删除表
1 | 清空表 |
管理命令
1 | 1) status 显示服务器状态,例如:status 'node01' |
高级用法
用户不用初始化计数器,当用户第一次使用计数器时,计数器将被自动设为0,也就是说当用户创建一个新列时,计数器的值是0.第一次增加操作会返回1,或增加设定的值。
1 | create '表名', '列簇1', '列簇2' |
触发器和存储过程
- 存储过程:是一组为了完成特定功能(动作)的SQL语句集合
- 目的是为了将常用或复杂的工作预先用SQL语句写好并用一个特定的名称存储起来
- 调用时call 存储过程的名称
- 触发器和存储过程是一样的,但是不需要每次调用执行,根据提前设定的某个动作自动触发
允许将一部分计算放到数据存放端(regionserver),减少网络通讯开销,提高计算性能
- observer
- region-observer
- regionserver-observer
- master-observer
- wal-observer
Observer 协处理器类似于关系型数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server端调用。通常可以用来实现下面功能:
权限校验:在执行 Get 或 Put 操作之前,您可以使用 preGet 或 prePut 方法检查权限;
完整性约束: HBase 不支持关系型数据库中的外键功能,可以通过触发器在插入或者删除数据的时候,对关联的数据进行检查;
二级索引: 可以使用协处理器来维护二级索引。
- endpoint
Endpoint 协处理器类似于关系型数据库中的存储过程。客户端可以调用 Endpoint 协处理器在服务端对数据进行处理,然后再返回。
以聚集操作为例,如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,然后在客户端上遍历扫描结果,这必然会加重了客户端处理数据的压力。利用Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出来,仅仅将该 max 值返回给客户端。之后客户端只需要将每个 Region的最大值进行比较而找到其中最大的值即可。
作业
- 创建一个表,名称为test,有2个列族,分别是:info和data
info列版本设置为5,data列版本设置为3
1 | create 'test', {NAME => 'info', VERSIONS => 5}, {NAME => 'data', VERSIONS => 3} |
- 向test表插入5条数据,rowkey以rk001开头
向info列族插入2个列,分别是name和age
向data列族插入2个列,分别是address和tel
1 | put 'test', 'rk001', 'info:name', '张三' |
- 扫描test表的全部数据以及info列族的数据(要求中文正常显示),并计算test表有多少条数据
1 | scan 'test' |
- 删除rk003的数据
1 | deleteall 'test', 'rk003' |
- 清空、关闭并删除表
:grin:HBase的Python操作
准备工作
- 启动HBase ThriftServer
1 | 找到一台HBase服务器,安装相关依赖 |
- 安装HappyBase库
1 | Python操作HBase的库使用HappyBase,基于Thrift协议连接HBase的ThriftServer进行操作 |
代码实现
1 | # coding:utf-8 |
:grin:HBase批量操作数据
HBASE集群之间数据的迁移、备份
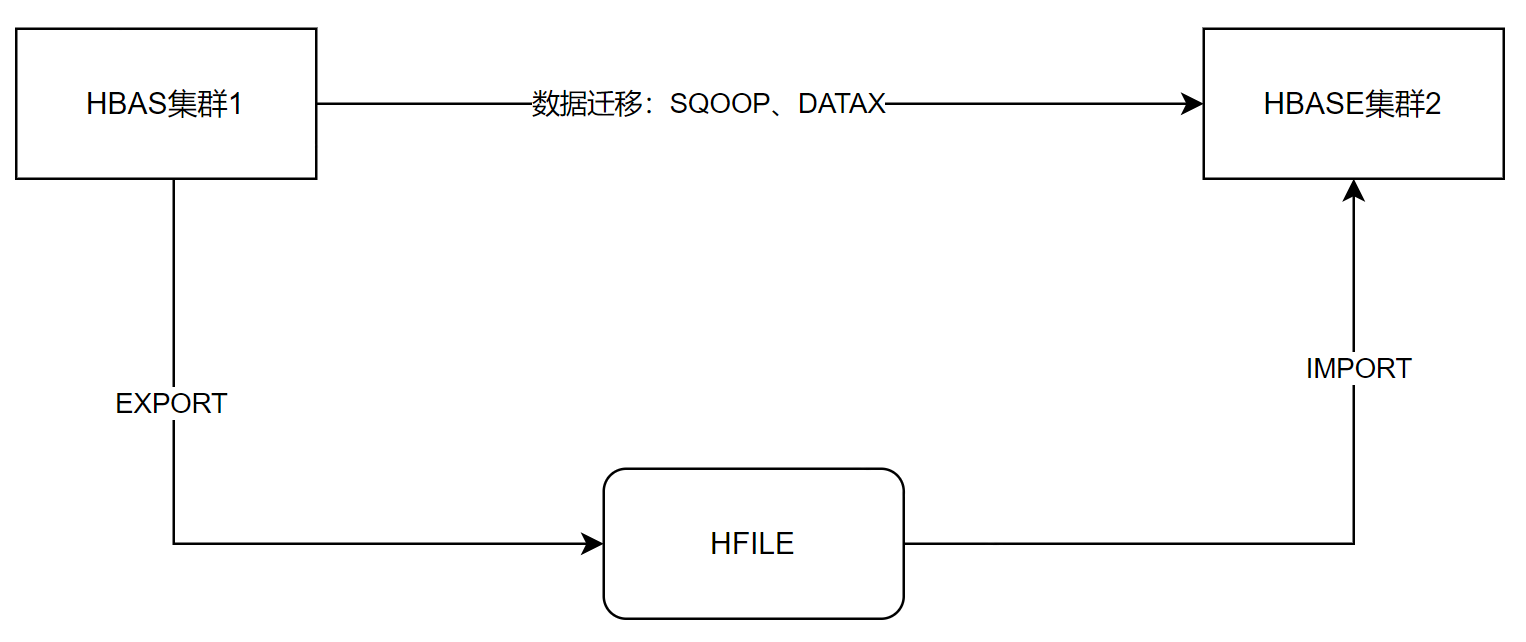
Import数据导入
- 用法
1 | hbase org.apache.hadoop.hbase.mapreduce.Import '表名' HDFS数据文件路径 |
- 文件
hbase特有的格式文件,是从hbase中导出的
- 前提
1、文件要上传至HDFS
- 创建目录
2
hadoop fs -put part-m-00000_10w /data/hbase/import2、表要存在,且列簇信息要一致
3、因为生成mapreduce任务,所以必须启动Yarn集群
1 | 执行import导入数据 |
Export数据导出
- 用法
1 | hbase org.apache.hadoop.hbase.mapreduce.Export '表名' HDFS路径 |
1、创建HDFS目录
2、执行命令
注意:导出数据时文件目录不可以提前创建
总结
Import与Export是一对命令,需要配合使用,常用于HBase数据库的备份、迁移:
Export将数据从HBase中HFlie文件导出至HDFS->生成HBase专属的文件,不是我们平时查看的文本文件(该文件包含数据本身和相关的元数据)
Import将HDFS上的专属文件导入至HBase->生成HBase的存储格式文件HFlie
Bulk Load操作
HBase的数据最终是需要持久化到HDFS。HDFS是一个文件系统,那么数据可定是以一定的格式存储到里面的。例如:Hive我们可以以ORC、Parquet等方式存储。而HBase也有自己的数据格式,那就是HFile。Bulk Load就是直接将数据写入到StoreFile(HFile)中,从而绕开与HBase的交互,HFile生成后,直接一次性建立与HBase的关联即可。使用BulkLoad,绕过了Write to WAL,Write to MemStore及Flush to disk的过程
使用HBase内置的ImportTSV工具可以将外部TSV格式文件(默认制表符分隔\t,或者自定义分隔符的其他格式数据文件也可)
- TSV:制表符分隔文件(’\t’)
- CSV:分隔符分隔文件(可以自定义分隔符)
特点:
1、操作简单不需要写代码加载外部文件,可以直接使用命令行操作
2、使用Bulk Load会绕过 Write to WAL,Write to MemStore及Flush to Disk,直接将数据写入HFlie,所以会更高效
- 用法
1 | hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="分隔符" -Dimporttsv.columns=列映射 '表名' HDFS路径 |
- 案例
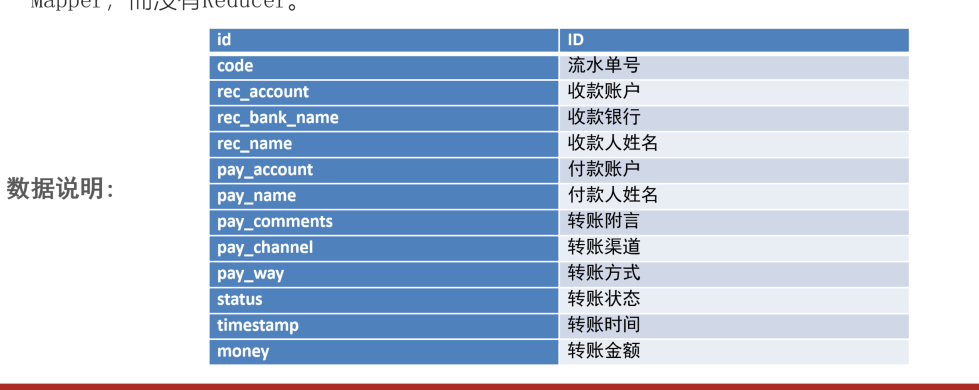
1 | 样例数据 |
表设计
- Rowkey使用数据的第一列ID
- CSV文件的其余列,都放入C1列簇
操作
- 创建表
1
create 'BANK_RECORD', 'C1'
- 上传文件至HDFS
1
2
3
4
5
6
7
8
9
10创建目录
hadoop fs -mkdir -p /data/hbase/bank_record
上传文件
hadoop fs -put bank_record.csv /data/hbase/bank_record
执行导入操作
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.columns=HBASE_ROW_KEY,C1:code,C1:rec_account,C1:rec_bank_name,C1:rec_name,C1:pay_account,C1:pay_name,C1:pay_comments,C1:pay_channel,C1:pay_way,C1:status,C1:timestamp,C1:money 'BANK_RECORD' hdfs://node1:8020/data/hbase/bank_record
-前置命令 hbase org.apache.hadoop.hbase.mapreduce.ImportTsv
-分隔符 -Dimporttsv.separator=","
-列映射 -Dimporttsv.columns rowkey对应哪一列,就在哪个位置填HBASE_ROW_KEY作业
使用ImportTsv,将课程资料中的:
WATER_BILL.TSV导入到HBase,WATER_BILL表中
1 | 如果是制表符文件(分隔符是\t)-Dimporttsv.separator参数默认不需要写,如果写了-Dimporttsv.separator="\t"就会报错 |
- 使用Export工具,将BANK_RECORD表,导出到HDFS作为数据文件
- 使用Import工具,将第二步导出的数据文件,导入到HBase,BANK_RECORD2中
:kissing:HBase高级原理
HBase高可用
高可用离不开ZK
Zookeeper:分布式一致性协调服务,字面意思动物园管理员,Hadoop生态圈里都是小动物
在一个HBase集群中,zk扮演着重要的角色:
- 保存Master和RegionServer相关的元数据
- 协调选举Active Master节点
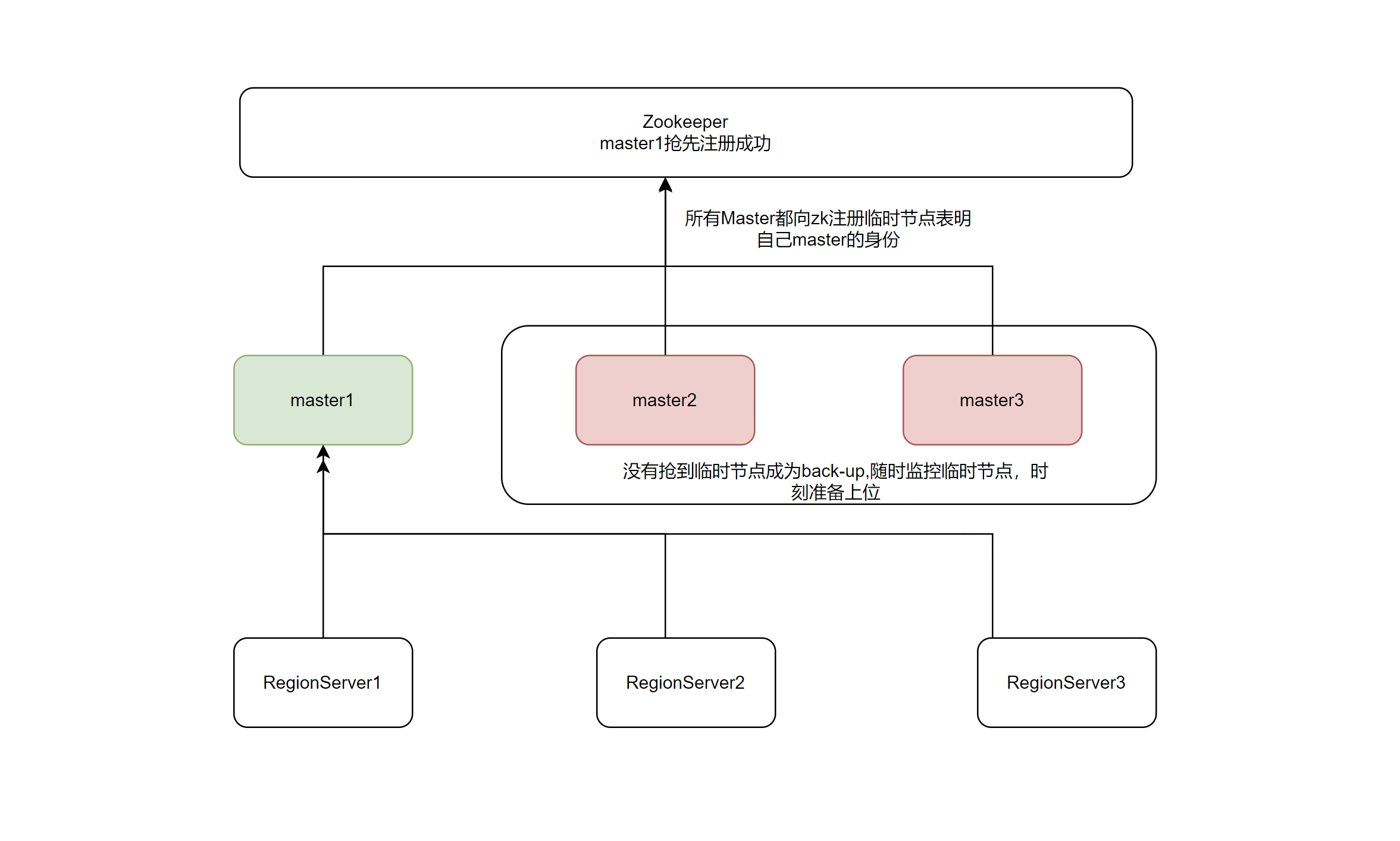
1、hbase集群启动,所有的master节点,都向zk进行注册
2、第一个注册成功的master进程,顺利上位成为master节点
3、master节点向zk请求regionserver的信息,并接管regionserver
4、其它备份的master节点会时刻监控zk上临时节点
5、如果master节点发生宕机,其它备份节点向zk进行注册,成功的成为新的master节点
6、新的master节点从zk中获取元数据接管regionserver
7、宕机的节点恢复后,成为备份节点,随时等待上位
配置高可用
快捷方式
高可用可以不做任何配置,直接找一台机器启动master即可
1 | 启动master |
配置文件方式
- 在conf文件夹下创建backup-masters 文件
2
touch backup-masters
- 将备用的master节点添加进行
2
3
node2
node3
- 将backup-masters分发到其它节点
2
scp backup-masters node3:`pwd`
- 重新启动HBase
2
3
start-hbase.sh
注意:backup-masters这个配置文件只对start-hbase.sh启动脚本生效
HBase架构
Master的作用:管理者
- 监控RegionServer , 处理RegionServer故障转移
1 | regionserver是有可能出现故障的,当rs出现故障时,master会将原rs的任务转移到新的rs |
- 处理元数据的变更 , 处理region的分配或移除
1 | master会与zk保持通信,时刻更新元数据信息 |
- 在空闲时间进行数据的负载均衡
1 | 平衡regionserver间的工作 |
- 通过Zookeeper发布自己的位置给客户端
1 | 维护自己与临时节点的关系,告诉zk我还活着呢,如果默认时间内(默认是15s可配置),zk就认为master已宕机 |
RegionServer的作用:大头兵
- 处理分配给它的Region , 负责存储HBase的实际数据
- 刷新缓存到HDFS , 维护HLog(WAL)
- 执行压缩 , 负责处理Region分片和HFile的合并
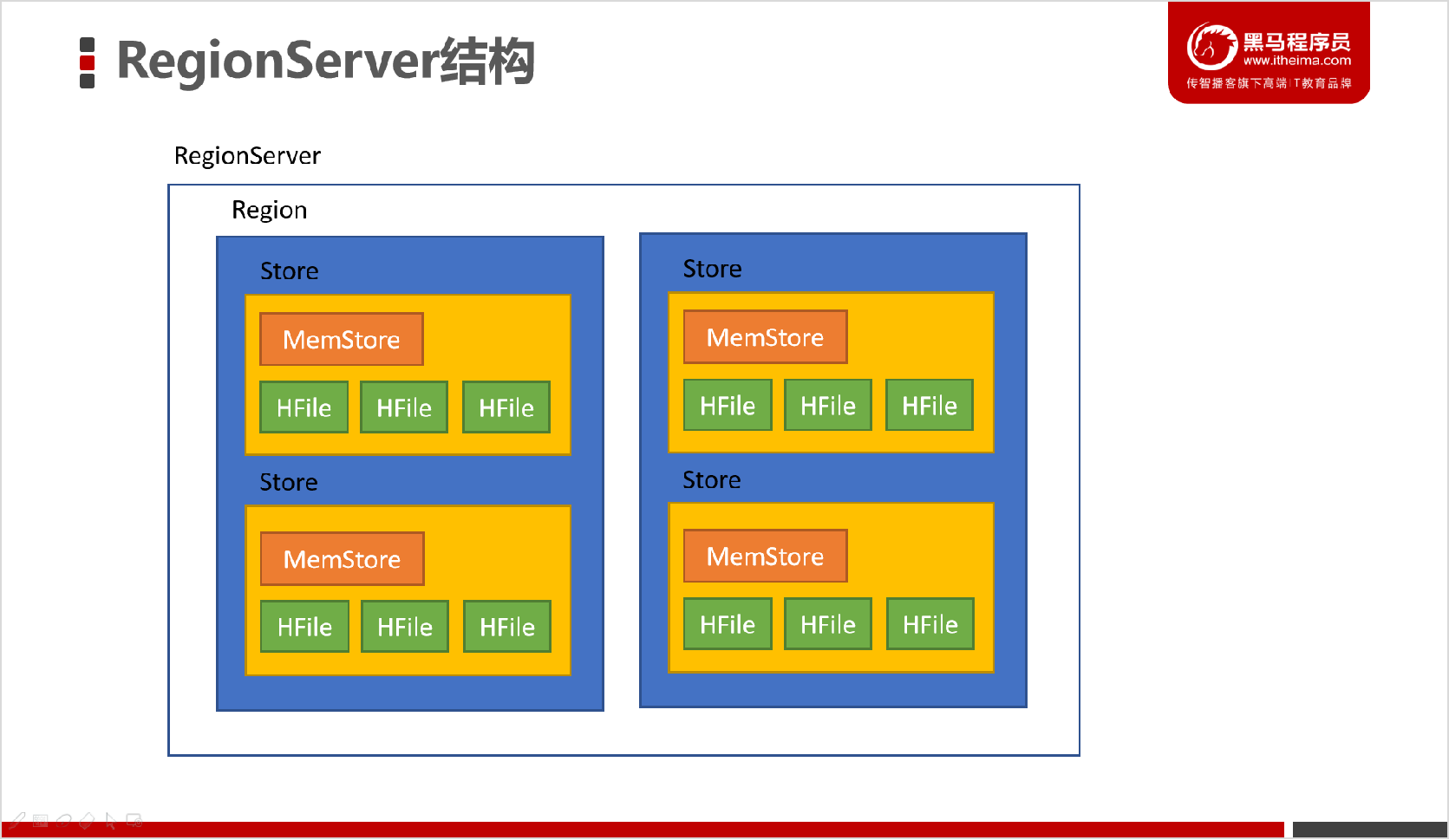
- regionserver就是从节点
- 一个rs有多个region(区域)
- 一个region有多个store(逻辑概念,一个列簇对应一个store)
- 一个store有一个memstore(内存区域)
- 一个store有多个HFile
Region

region总结:
1、类似于HDFS中的Block块
- HDFS的数据存在Block中
- HBase的数据存在Region中
2、由RegionServer进行管理
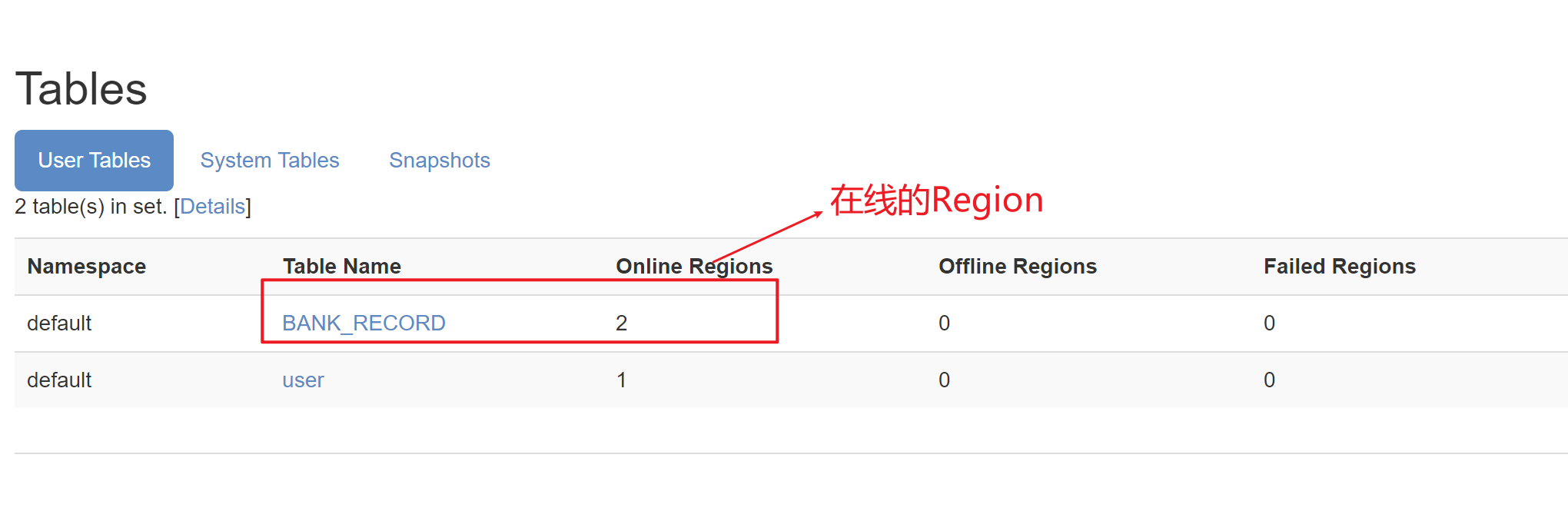
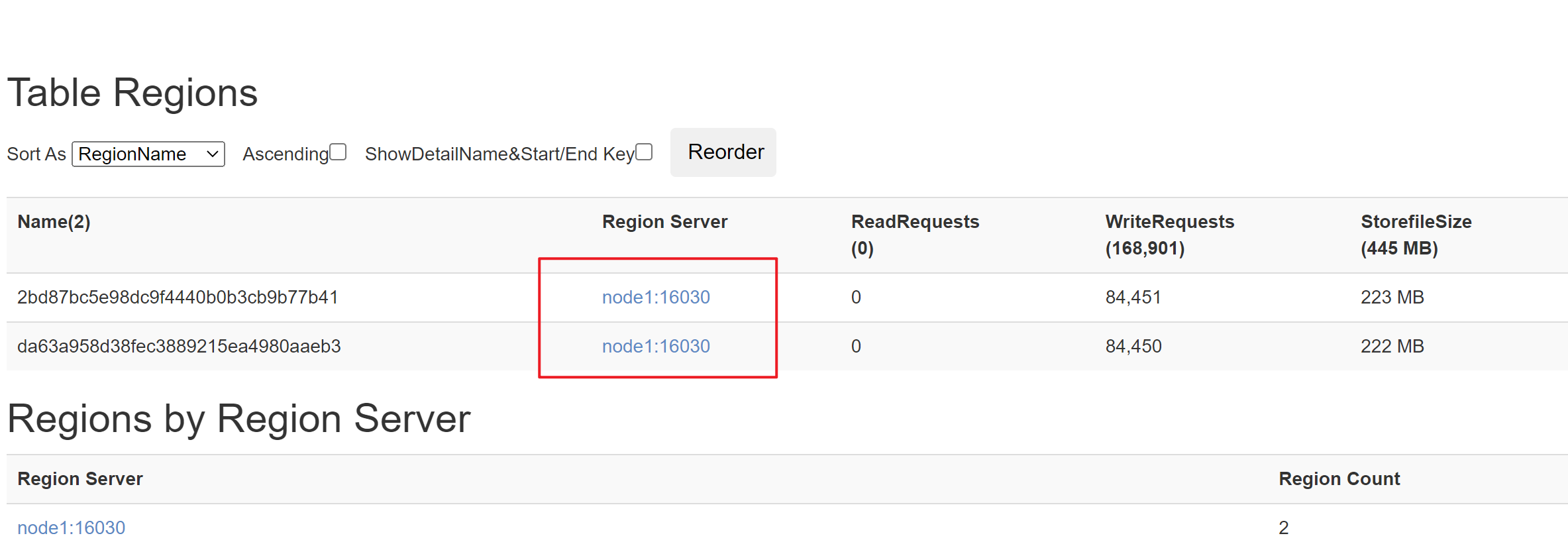
问题:哪些数据应该放到哪一个region中
根据rowkey进行分配
Rowkey与Region的关系
猜想:
1、先往第一个region中写数据,满了再写第二个,依此类推
2、轮询写,平均分配数据给所有的region
3、每个region都有自己的数据范围,根据rowkey的值所在的数据范围,将数据落在相应的region
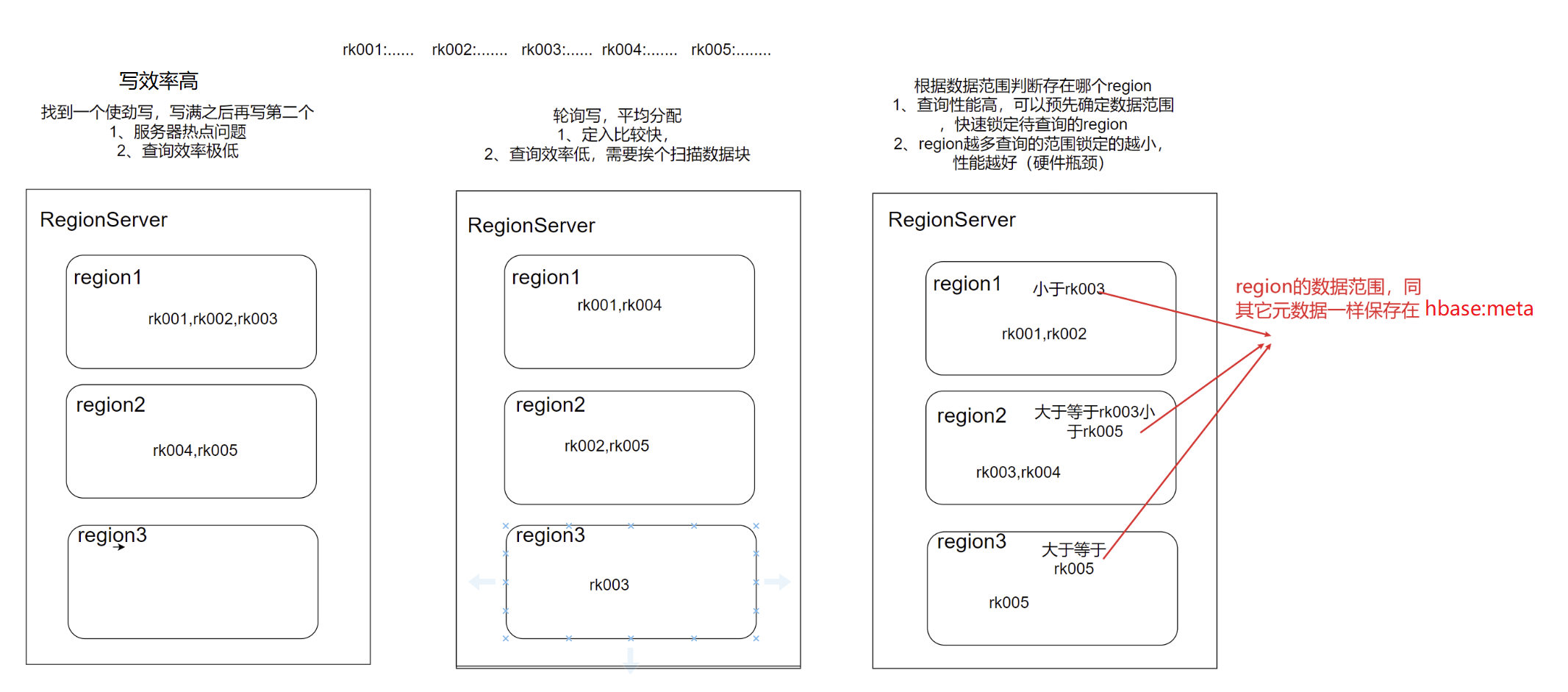
因为region采用根据rowkey划分数据范围进行数据保存的策略,所以才有了Hbase随机查询高性能的能力
当我们有10TB的数据,10W个region,一个region有100MB的数据,当查询一条数据时,根据数据范围已经排除了99.9999%的数据了
所以:只要region范围划分的合理和rowkey设计的好,hbase单条查询的性能无敌
region范围的确定原则
region的范围是左闭右开的区间(包头不包尾)
region1:无穷小~300
region2:300~400
region3:400~500
region4:500~600
region5:600~无穷大
数据:
| 学号 | 姓名 | 班级 | 所在region |
|---|---|---|---|
| 133 | 张三 | 一班 | region1 |
| 256 | 李四 | 三班 | region1 |
| 689 | 王五 | 四班 | region5 |
| 36790 | 赵六 | 二班 | region2 |
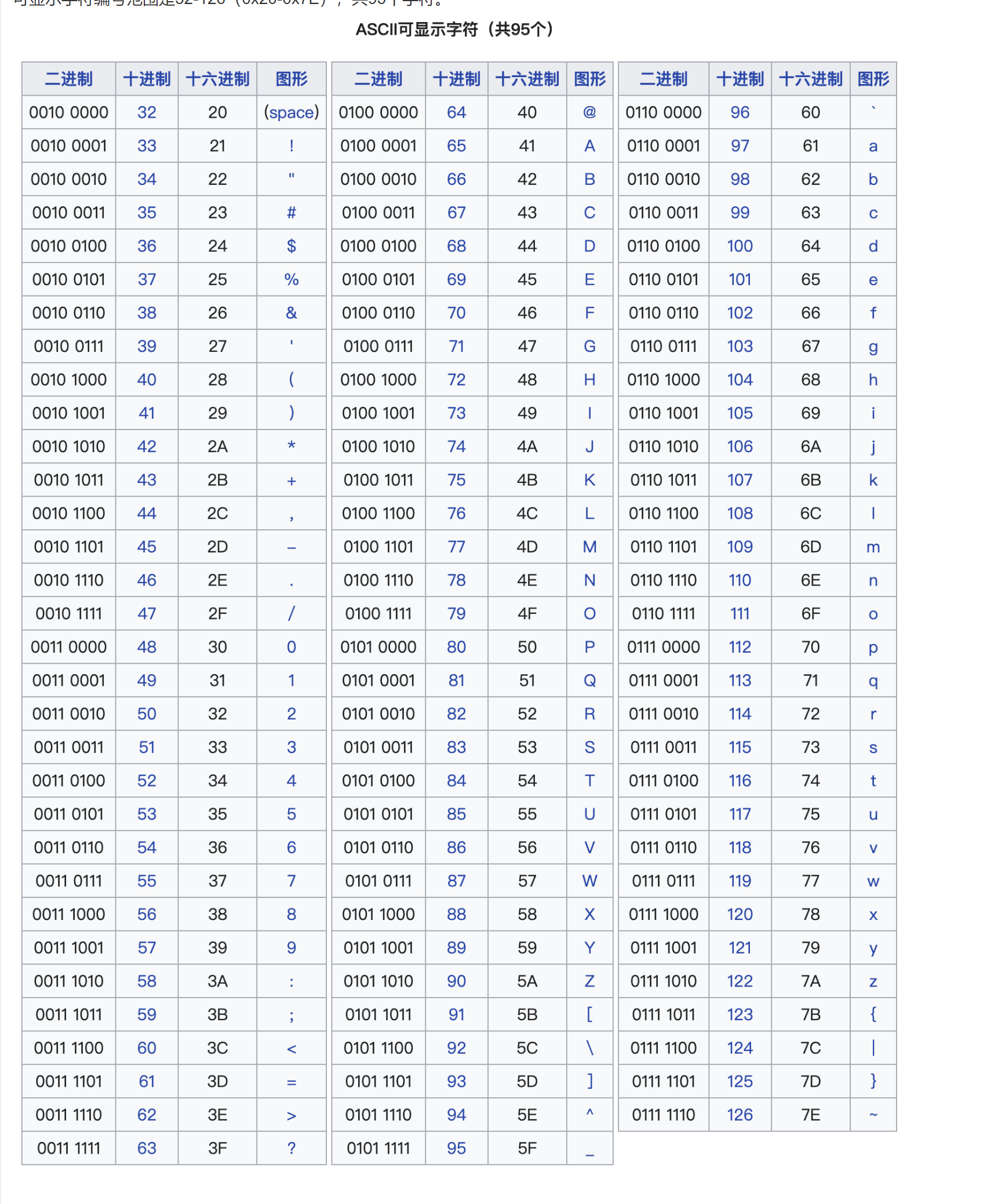
注意:
HBase中排序是根据字符顺序比较的:从左至右依次比较
300<36790<400
rk360这个应该在什么范围,根据ASCII编码应该落在大于600区间
补充:字符串比较是根据ASCII编码进行比较的
Store
- 每个region中包含多个store
- 每个store包含数据的内存区域memstore和数据的硬盘区域HFlie
- store是一个逻辑概念对应一个列簇
Memstore
- 数据写入时,首先写入内存(内存中不安全)
- 数据会有内存中进行排序
- 当数据达到阀值时,数据会从内存中flush到硬盘文件(HFlie)中,数据已排序
HFile
- 数据从内存中生成HFile作为持久化储存的文件
WAL预写日志
数据写入时会先写入wal(在HDFS上),同时把数据再写入内存区域
- 主要用来保证数据的可靠性
HBase的工作原理
数据的读取
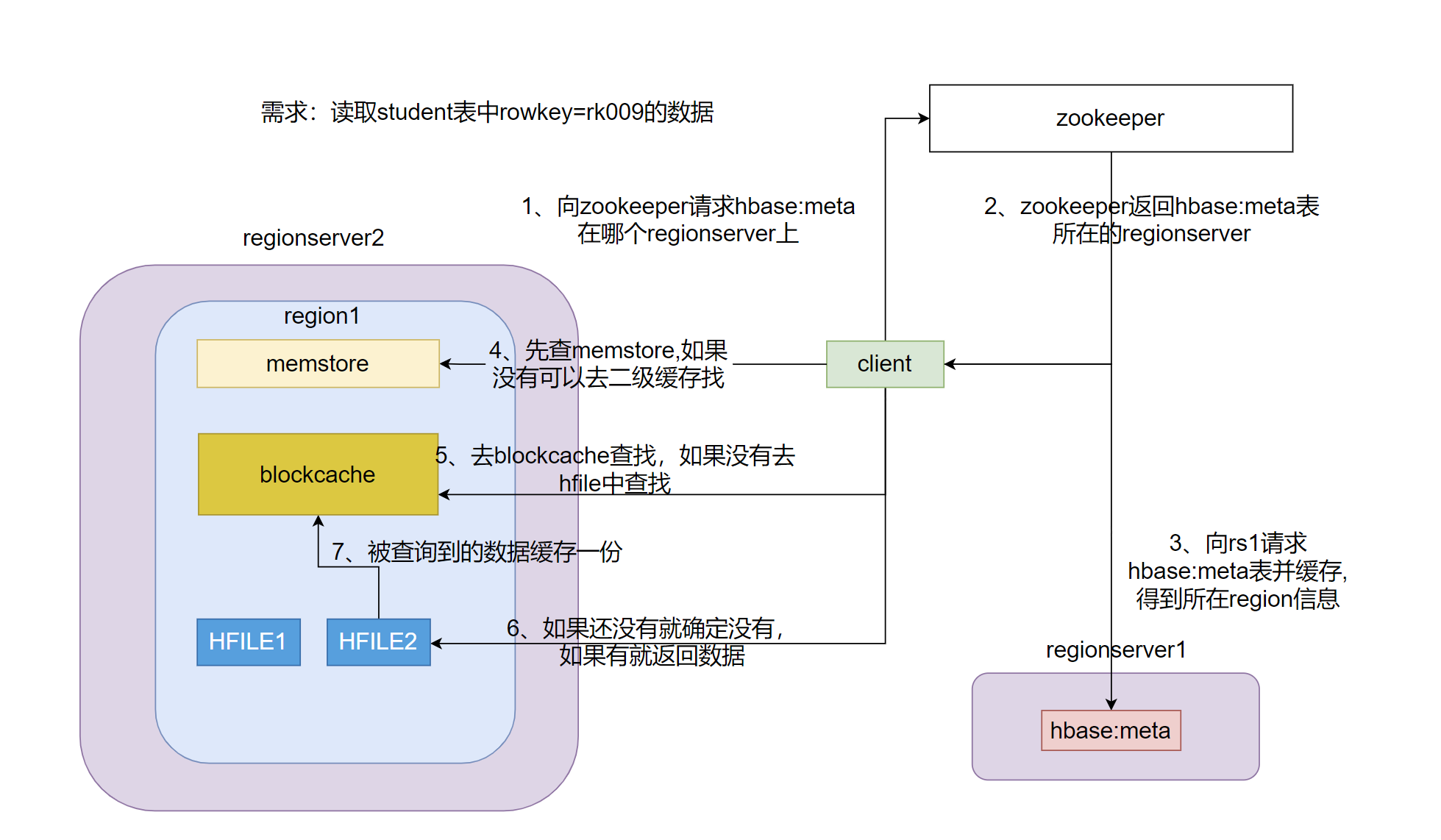
1、向zk发起hbase:meta表所在位置的请求
2、根据zk返回的信息获取hbase:meta元数据信息并缓存在客户端
3、根据元数据信息找到所要查询的rowkey所在的region和这个region所在rs
4、去该region中的memstore中查询数据如果没有去二级缓存
5、二级缓存blockcache中查询,如果没有去hfile中查找
6、如果查询到数据返回给客户端同时往blockcache中缓存一份
数据的写入
客户端流程
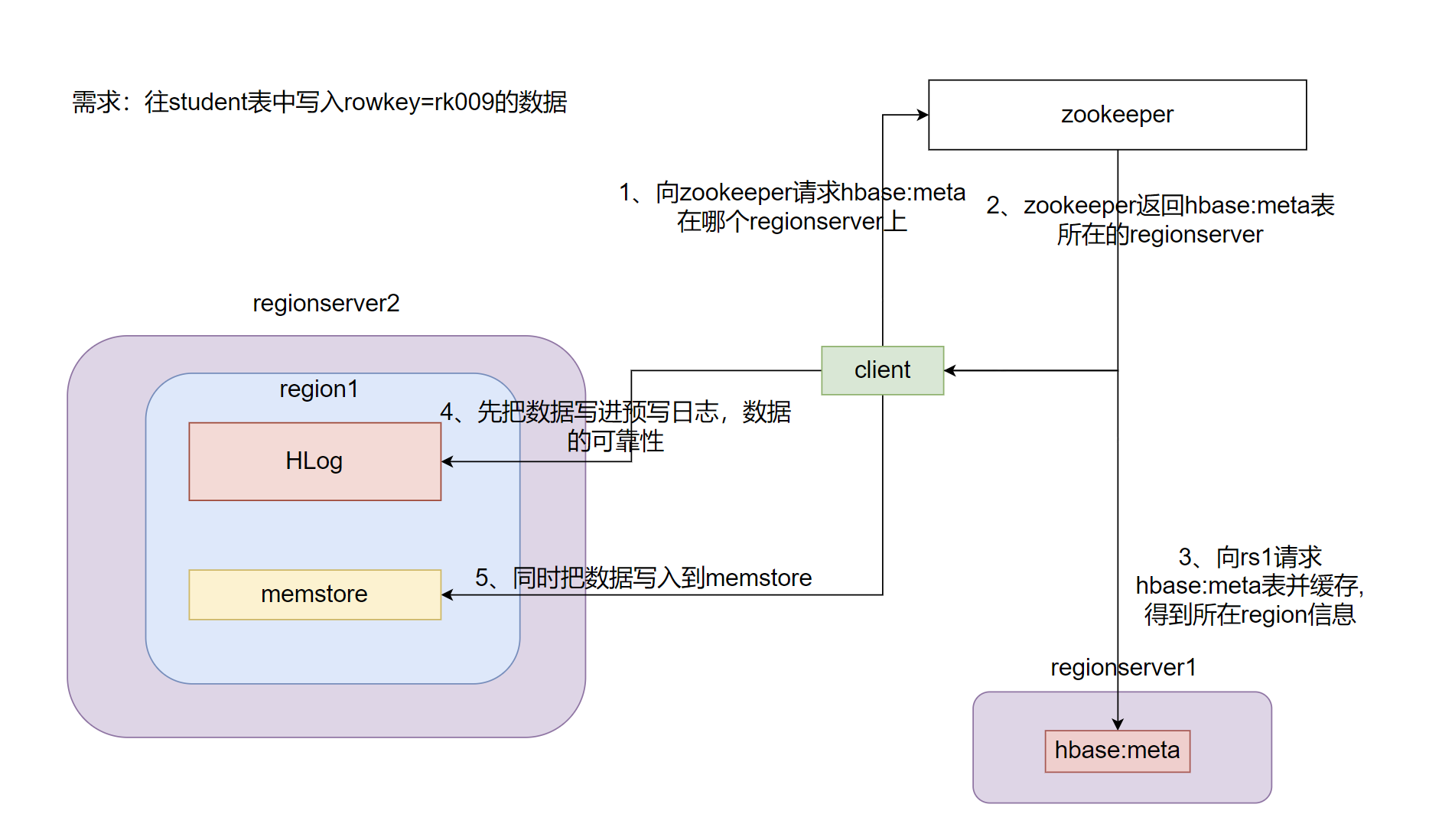
1、向zk发起hbase:meta表所在位置的请求
2、根据zk返回的信息获取hbase:meta元数据信息并缓存在客户端
3、根据元数据信息找到所要写入的rowkey所在的region和这个region所在rs
4、先向预写日志中写入数据
5、再把数据写入到memstore并排序
服务端流程
1、当memstore中数据达到阈值(大小或时间)会把数据flush到hdfs中
2、一次flush会生成一个HFILE文件
问题:
- 不同HFILE文件中的数据是无序
- HFILE文件越来越多性能下降
内存溢写
- 手动执行
2
flush '表名'
- 当memstore中的数据达到阈值(默认128Mb或1小时)时,会将数据flush到硬盘中
2
3
4
5
6
7
8
9
10
11
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
<source>hbase-default.xml</source>
</property>
<property>
<name>hbase.hregionserver.optionalcacheflushinterval</name>
<value>3600000</value>
<source>hbase-default.xml</source>
</property>
文件合并
- minor合并(小合并)
- major合并(大合并)
这两种合并机制都需要重新读写以IO开销来换取读性能的提高
minor合并
- Minor Compaction操作只用来做部分文件(默认是3-10个)的合并操作,不做任何删除数据、多版本数据的清理工作
- Minor Compaction是一种轻量化的合并操作,过程一般较快,而且IO相对较低
触发条件:
1 | 1、在打开Region或者MemStore时会自动检测是否需要进行Compact(包括Minor、Major) |
major合并
- Major Compaction操作是对Region中每个Store下的所有StoreFile执行合并操作,最终的结果是整理合并出一个文件
- 是一种重量级合并操作,较大的IO消耗
- 可以自动执行,但是一般手动执行较多,会删除过期数据和其他版本的数据(不同时间戳的)
触发条件:
1 | 1、手动触发:可以自动执行,但是一般手动执行较多 |
In-Memory合并
HBase2.0之后新增的特性
主要解决:
1、不管是minor还是major都会消耗IO,增加开销
2、合并时都会进行排序,region中的内存区域本身就是用来排序的,可以多积攒一些数据排序合并之后再flush到硬盘文件中
注意:内存占用增加,建议最少32G以上的硬件才采用这个新机制
- 1、未开启In-Memory时,原来memory中的数据达到阀值会flush到硬盘,而开启之后会先将数据刷新到一个pipeline的内存管道中,作为一个segment存在
- 2、Memstore不停地将数据刷新到pipeline生成segment
- 3、当pipeline中积攒足够多的segment后,将其排序合并,flush到硬盘生成一个大号的HFile
在pipeline中的合并策略
- basic(基础型)
- Basic compaction策略不清理多余的数据版本,无需对cell的内存进行考核
- basic适用于所有大量写模式
- eager(饥渴型)
- eager compaction会过滤重复的数据,清理多余的版本,这会带来额外的开销
- eager模式主要针对数据大量过期淘汰的场景,例如:购物车、消息队列等
- adaptive(适应型)
- adaptive compaction根据数据的重复情况来决定是否使用eager策略
该策略会找出cell个数最多的一个,然后计算一个比例,如果比例超出阈值,则使用eager策略,否则使用basic策略
2
3
4
5
6
7
8
<property>
<name>hbase.hregion.compacting.memstore.type</name>
<value>none|basic|eager|adaptive</value>
<source>hbase-default.xml</source>
</property>
2、在创建表的时候指定
create "test_memory_compaction", {NAME => 'C1', IN_MEMORY_COMPACTION => "BASIC"}
Region分裂
当region中的数据逐渐变大之后,达到某一个阈值(默认10G),会进行裂变,一个region等分为两个region,并分配到不同的RegionServer,原本的Region会下线,新Split出来的两个Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。
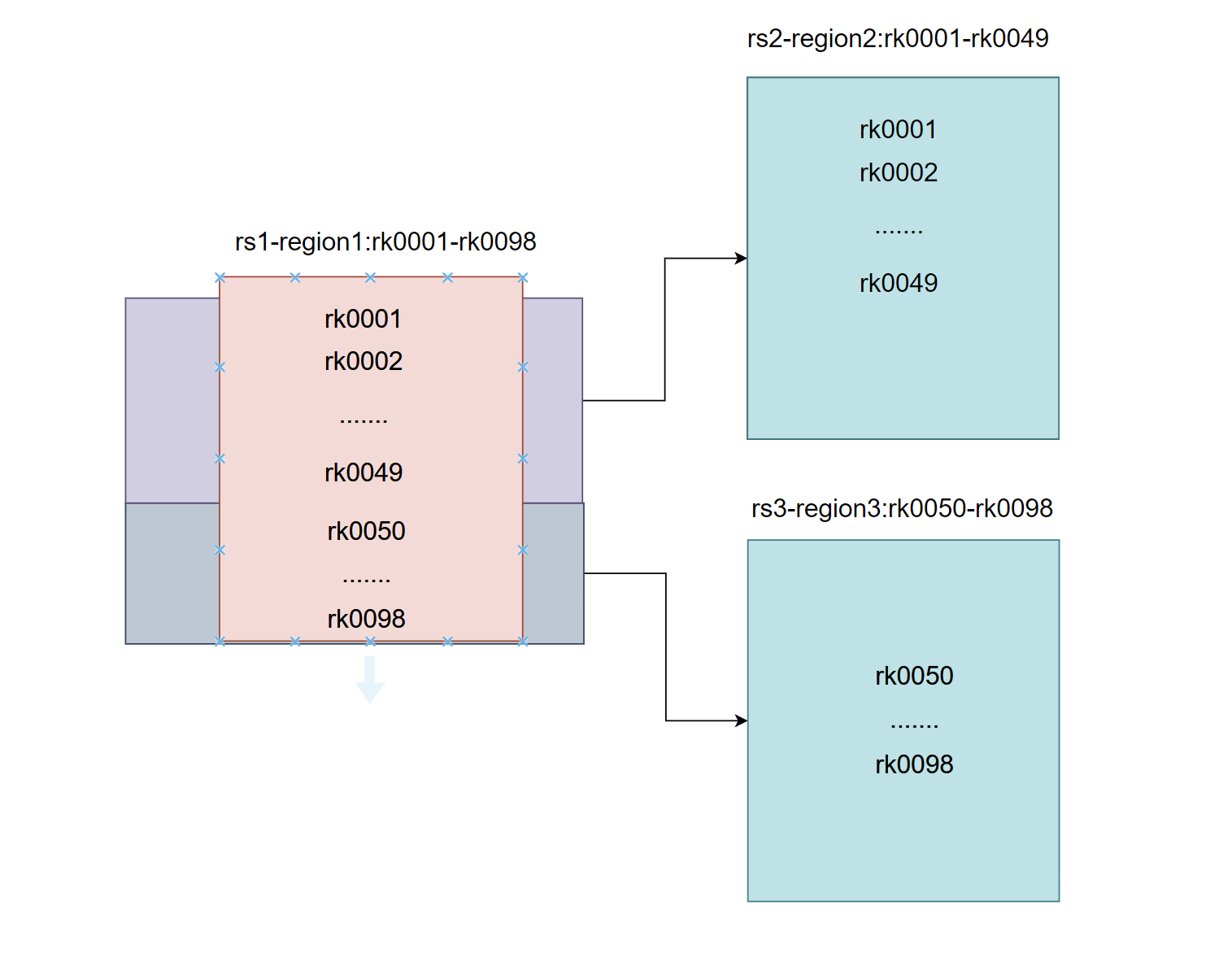
触发条件
1、自动分区
当store file的大小大于如下公式得出的值的时候就会split,公式如下:
Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”) R为一个table在同一个region server中region的个数。
2
3
4
5
6
<name>hbase.hregion.max.filesize</name>
<value>10737418240</value>
<final>false</final>
<source>hbase-default.xml</source>
</property>
- 如果初始时R=1,那么Min(128MB,10GB)=128MB,也就是说在第一个flush的时候就会触发分裂操作
- 当R=2的时候Min(512MB,10GB)=512MB ,当某个store file大小达到512MB的时候,就会触发分裂
- 如此类推,当R=9的时候,store file 达到10GB的时候就会分裂,也就是说当R>=9的时候,store file 达到10GB的时候就会分裂
split 点都位于region中row key范围的中间点
2、手动分区
2
3
4
create 't1', 'c1', {SPLITS => ['10', '20', '30', '40', '50', '60', '70', '80', '90', '100']}
根据16进制字符进行划分,从0至f进行30等分
create 't2', 'c1', {NUMREGIONS => 30, SPLITALGO => 'HexStringSplit'}
思考:region越来越多,会不会发生数据倾斜
RegionServer工作机制
region管理
- 任何时刻,一个region只能分配给一个region server
- Master记录了当前有哪些可用的region server,以及当前哪些region分配给了哪些region server,哪些region还没有分配。当需要分配的新的region,并且有一个region server上有可用空间时,master就给这个region server发送一个装载请求,把region分配给这个region server。region server得到请求后,就开始对此region提供服务。
上线
regionserver上线时会在zookeeper上(/hbase/rs)的目录内注册代表自己的znode
master与zookeeper通信发现新上线的regionserver,并获取regionserver的信息(IP、主机名、内部region的信息等)
regionserver待master分配工作
下线
- regionserver下线后会与zookeeper失联
- master与zookeeper通信得知regionserver下线了,会等待一会(默认15s,zookeeper本身有默认连接超时),仍没有重连回来
- 认定该regionserver下线,master将其从zookeeper上清除
- 并将原来regionserver的工作(主要就是管理region)分配给其它的regionserver
Master工作机制
上线
- 从zookeeper上获取唯一一个代表active master的锁,用来阻止其它master成为active master
- 一般hbase集群中总是有一个master在提供服务,还有一个以上的‘master’在等待时机抢占它的位置。
- 扫描zookeeper上的server父节点,获得当前可用的region server列表
- 和每个region server通信,获得当前已分配的region和region server的对应关系
- 扫描.hbase:meta表获取region的集合,计算得到当前还未分配的region,将他们放入待分配region列表
下线
由于master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结
- 无法创建删除表
- 无法修改表的schema
- 无法进行region的负载均衡
- 无法处理region 上下线
- 无法进行region的合并
- 唯一例外的是region的split可以正常进行,因为只有region server参与
表的数据读写还可以正常进行
因此master下线短时间内对整个hbase集群没有影响。
:boom:HBase的表结构设计
HBase在HDFS上的目录
HBase的数据存储在哪呢?

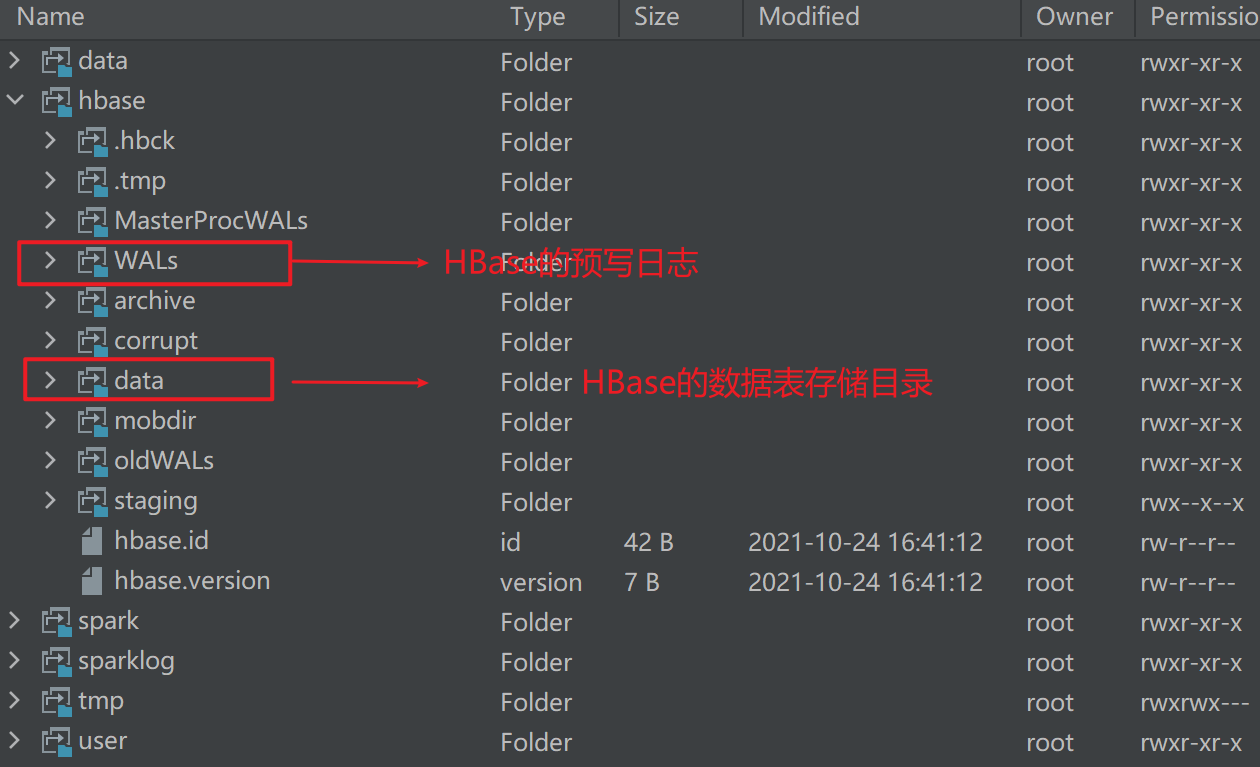
data目录:
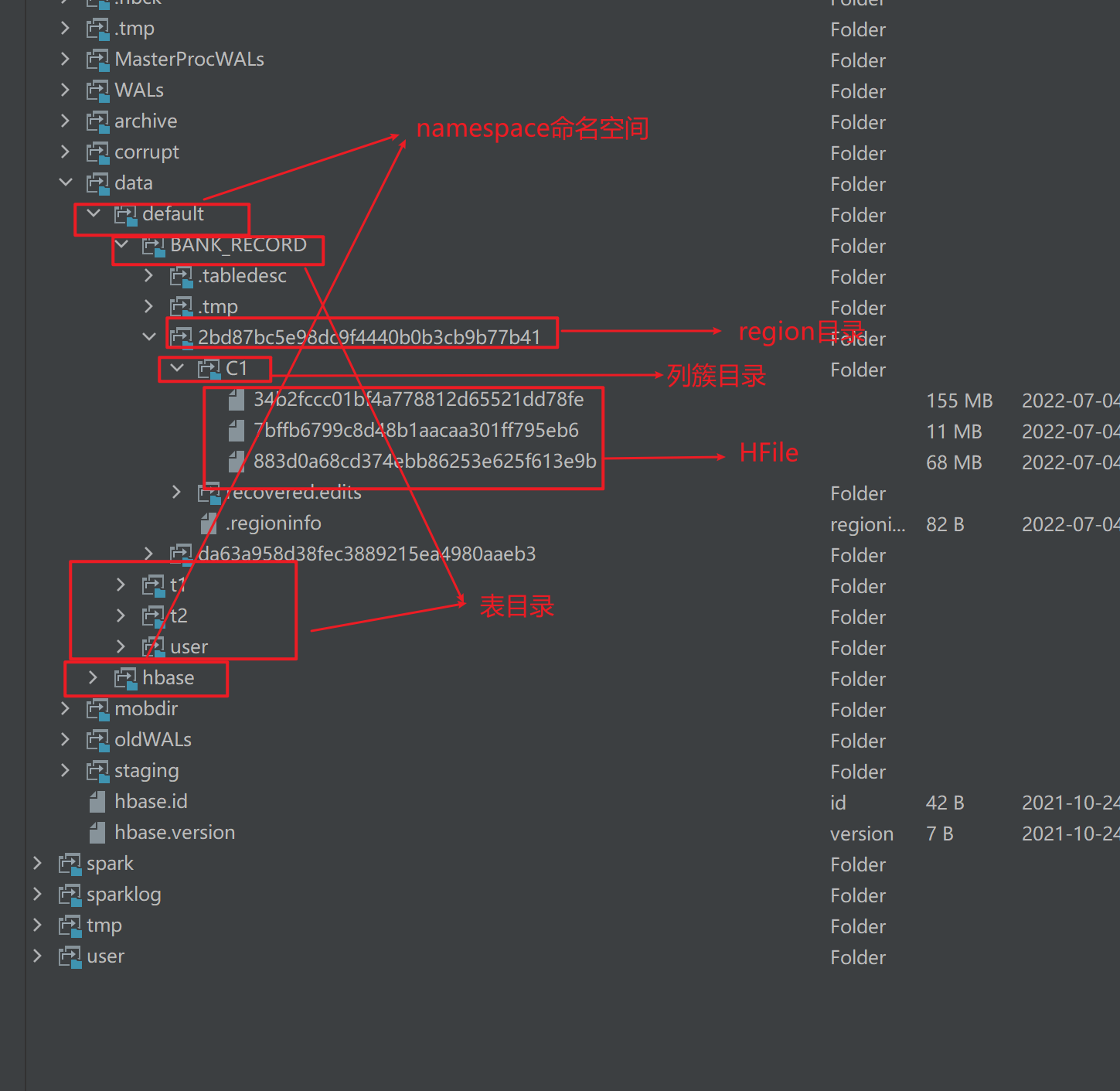
NameSpace命名空间
Hbase像很多数据库一样,通过命名空间来支持多库划分
- 一般我们会将不同业务域的表划分到不同的namespace中
- 不同的namespace在HDFS上是不同的数据文件夹
- 自带两个namespace
- default,默认的库,如果不指定,创建的表都会在这个命名空间下
- hbase,内置的库,不要动它
操作
1 | 1. 创建命名空间 : create_namespace ‘DAY02_SPACE’ |
注意:
hbase没有像mysql那样use ‘数据库’的概念,如果使用自建的namespace,在操作该表时必须使用全称,比如’DAY02_SPACE:MSG’和’MSG’,后者是在’default’命名空间下
1 | 创建命名空间 |
1 | 插入数据 |
1 | 禁用表 |
HBase列簇的设计
- 列簇的数量越少越好
- 多列簇对应多个文件,会带来更多的文件合并,更多的IO开销
- 如果业务上确实需要对不同的列进行操作,可以适当增加列簇,但是原则上基于HBase的操作应该是围绕rowkey进行的,而不是玩多个列
HBase的压缩算法
为什么要使用压缩算法
- 节省存储空间
- 节省网络传输的成本(大数据领域最后的瓶颈往往都在IO上)
常用的三种压缩算法:
| 压缩算法 | 压缩后占比 | 压缩 | 解压缩 |
|---|---|---|---|
| GZIP | 13.4% | 21 MB/s | 118 MB/s |
| LZO | 20.5% | 135 MB/s | 410 MB/s |
| Zippy/Snappy | 22.2% | 172 MB/s | 409 MB/s |
操作
1 | 查看压缩算法信息 |
rowkey设计
官方建议原则:
- 使用递增行键/时序数据(
不建议)
如果ROWKEY设计的都是按照顺序递增(例如:时间戳),这样会有很多的数据写入时,负载都在一台机器上。我们尽量应当将写入大压力均衡到各个RegionServer- 避免rowkey和列的长度过大
在HBase中,要访问一个Cell(单元格),需要有ROWKEY、列蔟、列名,如果ROWKEY、列名太大,就会占用较大内存空间。所以ROWKEY和列的长度应该尽量短小
ROWKEY的最大长度是64KB,建议越短越好- 使用Long等类型比String类型更省空间
long类型为8个字节,8个字节可以保存非常大的无符号整数,例如:18446744073709551615。如果是字符串,是按照一个字节一个字符方式保存,需要快3倍的字节数存储- 保证ROWKEY的唯一性
设计ROWKEY时,必须保证RowKey的唯一性
由于在HBase中数据存储是Key-Value形式,若向HBase中同一张表插入相同RowKey的数据,则原先存在的数据会被新的数据覆盖。
预分区设计
如果不预先分区会有什么问题?
- 集群就需要自己进行分区,会占用集群资源
- 有可能数据发生倾斜
提前分区的目的:
- 提前分好的region能够覆盖全部数据
- 保证数据尽量平均分布
场景1:我的rowkey全是数字,问怎么分区
按数字分[1,2,3,4,5,6,7,8,9]
1 | create 't2', 'c1', {SPLITS => ['1', '2','24','26', '27', '3', '4', '5', '6', '7', '8', '9']} |
场景2:我的rowkey全是小写字母,问怎么分区
按小写字母分[a,b,c,…..,z]
场景3:我的rowkey是手机号,问怎么分区
按数字划分,把手机号反过来保存
场景4:我的rowkey完全没有规则
加盐(hash、random)
:cry:HBase的调优实践
通用调优
HBase底层数据存储依赖HDFS,HDFS的性能很重要
NameNode元数据,推荐使用SSD
- 元数据大小比较小
- 元数据会被频繁使用
从HDFS取出来数据,要经过NameNode的元数据,如果NameNode的元数据过多,以及磁盘缓慢
从元数据中索引出具体的block块,就延迟比较高
对于HBase这种,动辄毫秒级别的响应来说,NameNode缓慢100ms就对HBase影响很深。
就跟系统盘C盘用SSD一样,感觉反应快很多
定时备份NameNode上的元数据 每小时或者每天备份,如果数据极其重要,可以5~10分钟备份一次。 备份可以通过定时任务复制元数据目录即可
为NameNode指定多个元数据目录
可以用多个硬盘在逻辑上绑定为1个硬盘,让元数据使用
硬盘也是分布式的,一起干活,效率高
也就是常见的RAID
机械硬盘耍个6块组RAID,体验不输于SSD
设置dfs.namenode.name.dir.restore为true,允许尝试恢复之前失败的dfs.namenode.name.dir目录,在创建checkpoint时做此尝试,如果设置了多个磁盘,建议允许
NameNode节点配置为RAID1(镜像盘)结构
RAID12个硬盘互为备份,安全
Linux系统
开启文件系统的预读缓存可以提高读取速
sudo blockdev –setra 32768 /dev/sda (尖叫提示:ra是readahead的缩写)
/dev/sda 就是你用的硬盘的盘号,根据你系统的硬盘去做动态修改
最大限度使用物理内存
sudo sysctl -w vm.swappiness=0swappiness,Linux内核参数,控制换出运行时内存的相对权重
swappiness参数值可设置范围在0到100之间,低参数值会让内核尽量少用交换,更高参数值会使内核更多的去使用交换空间默认值为60(当剩余物理内存低于40%(40=100-60)时,开始使用交换空间)对于大多数操作系统,
设置为100可能会影响整体性能,而设置为更低值(甚至为0)则可能减少响应延迟
调整ulimit上限, 默认值为比较小的数字
$ ulimit -n 查看允许最大进程数
$ ulimit -u 查看允许打开最大文件数
HDFS调优
1.dfs.namenode.handler.count,默认10
NameNode处理的线程数量,默认10是保守使用
在企业中,可以根据服务器的真实CPU核心数来修改
一般建议设置为CPU核心数的1~4倍’
比如,CPU32核,这个数值可以设置为:32~128
2.dfs.replication HDFS的副本数量 默认是3,
3是确保性能和安全一个比较稳妥的数值
为了安全可以加高
为了性能可以降低(最低建议是2,如果降低到2HDFS性能会提升很多,建议在有数据备份的情况下设置为2)
3.dfs.blocksize HDFS的block块大小
如果,是HBase专用的HDFS,那么这个块的大小,建议比:Memstore的刷新上限大小,大1MB即可
比如Memstore的刷新上线是128MB,我们这个参数可以设置为130MB
可以确保一个HFile可以吃满一个block(尽量减少block的数量)
也就是尽量不让HFile跨越多个Block存在。
4.dfs.datanode.max.transfer.threads DataNode最大的可操作性文件数
HBase一般会操作较多的文件,可以适当改大一点,默认4096 可以改2倍 改10000可
dfs.image.transfer.timeout 操作数据的延迟超时时间
大量负载下,相应缓慢,就有可能超过timeout被宕机,被封杀掉socket通讯
适当改大点
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
MapReduce开启压缩的参数
可以优化我们在执行HBase 的 IMport、Export、ImportTsv等MR任务的性能。


内存调优

Zookeeper调优
zookeeper.session.timeoutHBase和ZK通讯的超时设置
如果Master卡住了(正常但是CPU压力大),超过一段时间没有和ZK通讯
会被ZK踢掉。一段时间就是这个timeout的具体值
包括RegionServer也会受到这个时间的限制。
可以在高负载下,设置的大一些,比如1分钟,2分钟
 微信
微信 支付宝
支付宝