
ElasticSearch(全)
Elastic Stack
Elastic Stack是一套构建在开源基础之上,可以让我们安全可靠地采集任何来源、任何格式的数据,并且实时地对数据进行搜索、分析和可视化工具链。
ELK技术栈
从上面这段定义可以看出Elastic Stack的几个特点:采集、转换、搜索、分析、可视化,这些功能分别由ElasticSearch、Kibana、Beats、Logstash这几个组件来实现。
数据搜索
- 精准查询
查询数据表中name等于张三的数据
select * from user where name = ‘张三’
- 模糊查询
查询数据表中name中包含张三
select * from user where name like ‘%张三%’
- 关联查询
查询数据表中任何列中可能包含张三的数据
select * from user where name like ‘%张三%’ or address like ‘%张三%’ or ……..
- 搜索查询
想要查询任何列跟张三有关系的数据,张哥 三叔 张三哥哥
当你不确定查询条件时,我们会使用搜索
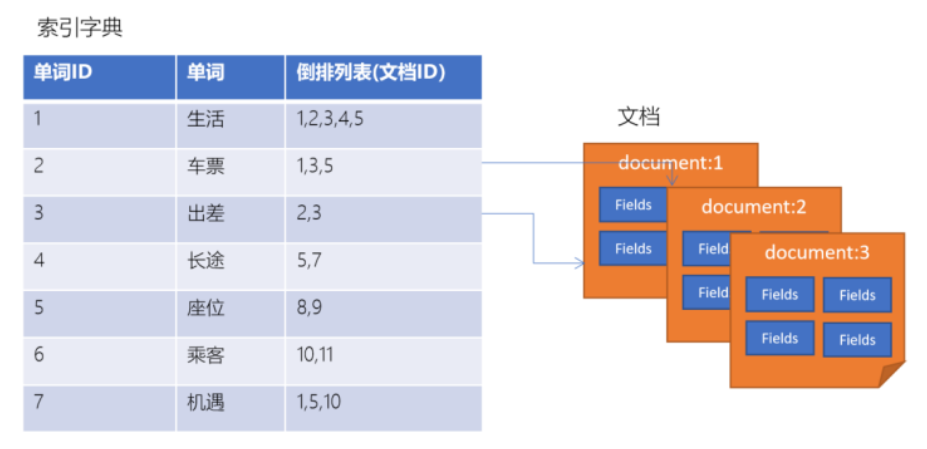
全文检索
全文检索是指:
通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数
用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
类似于通过字典中的检索字表查字的过程(想象一下百度搜索)
- 通过一个程序扫描文本中的每一个单词,针对单词建立
倒排索引,并保存该单词在文本中的位置、以及出现的次数
用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
类似于通过字典中的检索字表查字的过程
搜索引擎
Lucene是一种高性能的全文检索库,在2000年开源,最初由大名鼎鼎的Doug Cutting(道格·卡丁)开发。Lucene不是一个完整的全文检索引擎,它只是提供一个基本的全文检索的架构。
ElasticSearch
Elasticsearch是Elastic Static的核心是基于Lucene的搜索服务器,可以用Elasticsearch来存储我们的文档数据,利用Elasticsearch强大的搜索和分析功能为我们的网站提供支持,ElasticSearch是分布式搜索引擎和大数据实时分析引擎,可以实时分析计算数据并得出结果,还可以通过Kibana的各种图表将分析结果可视化。
基于Lucene的分布式全文检索引擎, 比较出名的两个 :
- ElasticSearch
- 海量数据存储和处理
- 大型分布式集群(数百台规模服务器)
- 处理PB级数据
- 小公司也可以进行单机部署
- 开箱即用
- 简单易用,操作非常简单
- 快速部署生产环境
- 作为传统数据库的补充
- 传统关系型数据库不擅长全文检索(MySQL自带的全文索引,与ES性能差距非常大)
- 传统关系型数据库无法支持搜索排名、海量数据存储、分析等功能
- Elasticsearch可以作为传统关系数据库的补充,提供RDBM无法提供的功能
- Solr
- solr 单独纯粹做查询的效率高于 ES
- 如果写入的频次和读取的频次都比较多, 采用ES的效率要高于Solr
- ElasticSearch 和 Solr 都是基于Lucene开发的
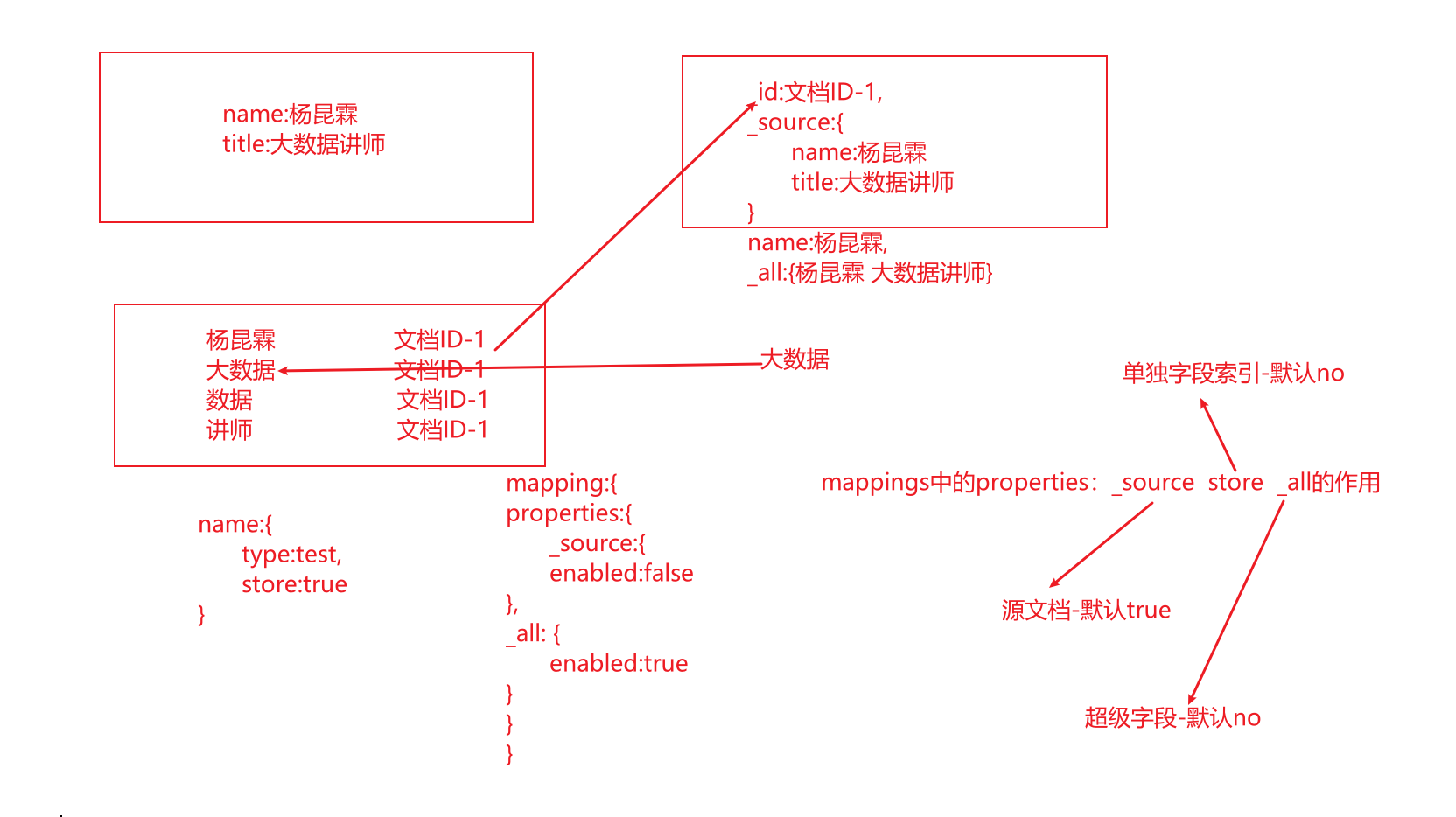
ES核心概念
ES基本概念
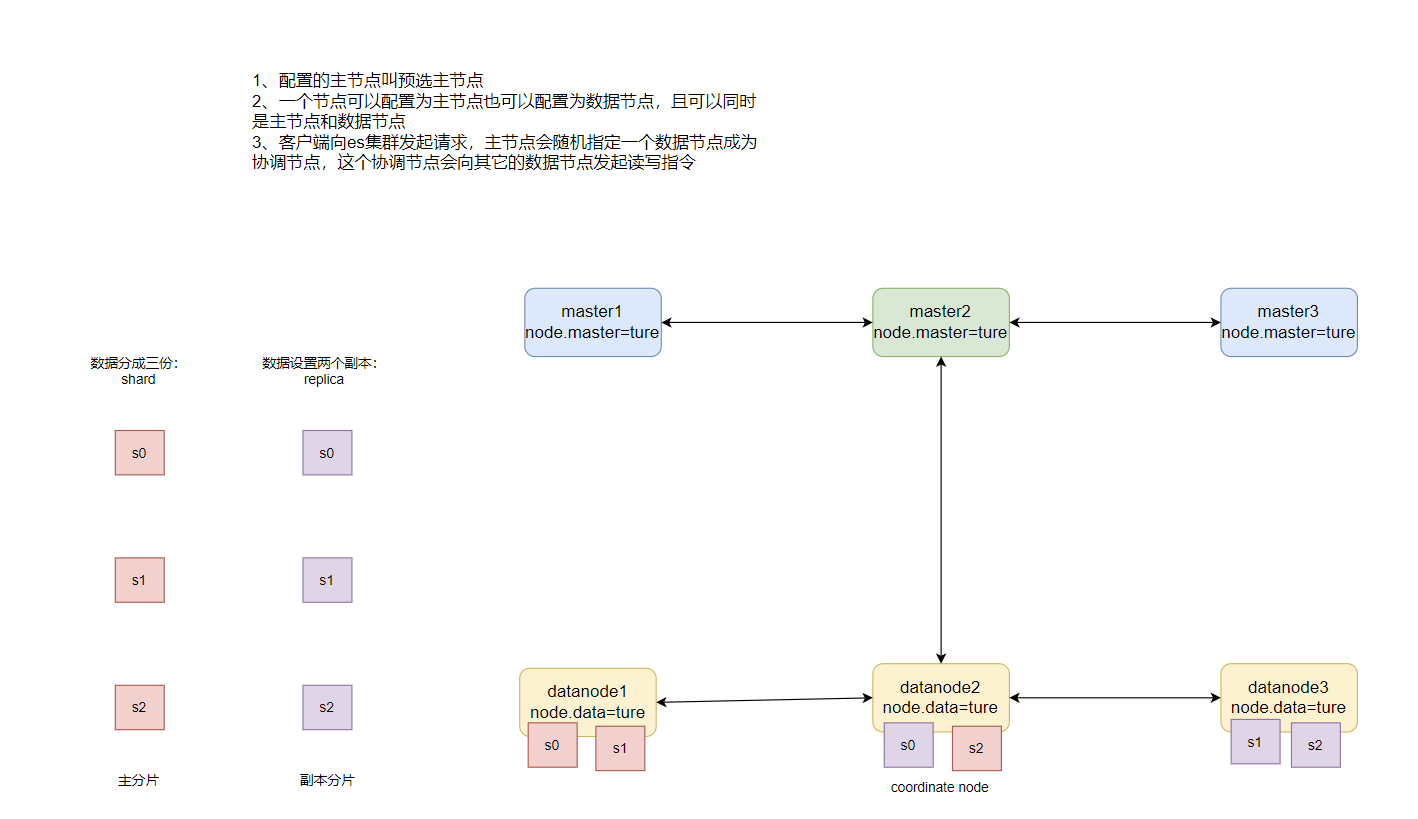
- 节点(Node)
运行了单个实例的ES主机称为节点,它是集群的一个成员,可以存储数据、参与集群索引及搜索操作。节点通过为其配置的ES集群名称确定其所要加入的集群。
- 集群(cluster**)**
ES可以作为一个独立的单个搜索服务器。不过,一般为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
一个集群会有多个节点组成,一个节点就是一个ES服务实例,通过配置cluster.name=‘’加入集群
- node.master=ture(默认为ture)-候选主节点,只有成为候选主节点的实例才能参与投票选举
- 主节点:负责索引的添加、删除,跟踪其它节点的正常运行,对数据分片的分配,收集集群中各节点的状态信息等
- node.data=ture(默认为ture)数据节点:负责对数据的增、删、改、查、聚合等操作,数据的查询和存储,对机器的io cpu memory要求比较高,一般选择
高配置的机器作为数据节点- 协调节点:其本身不是通过配置来设置,用户的请求会随机分发给一个节点,该节点就成为了协调节点,负责分发客户端的读写请求、收集结果
集群每个节点既可以是候选主节点也可以是数据节点
- 分片(Shard)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。降低单服务器的压力,构成分布式搜索,提高整体检索的效率(分片数的最优值与硬件参数和数据量大小有关)。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
4)副本(Replica)
副本是一个分片的精确复制,每个分片可以有零个或多个副本。副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
副本数不能大于节点数
ES数据架构
Elasticsearch与数据库的类比
es7之后就没了type
| 关系型数据库(比如Mysql) | 非关系型数据库(Elasticsearch) |
|---|---|
| 数据库Database | 索引Index |
| 表Table | 类型Type |
| 数据行Row | 文档Document |
| 数据列Column | 字段Field |
| 约束 Schema | 映射Mapping |
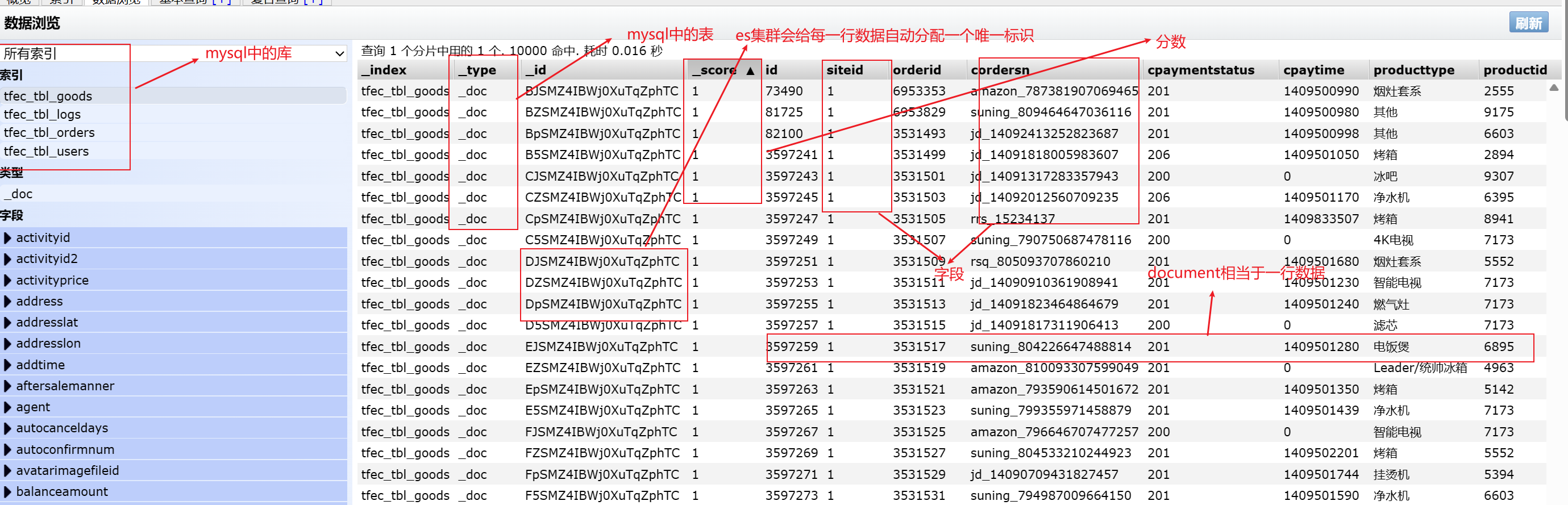
- 索引(index)
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。索引相当于SQL中的一个数据库。
- 类型(Type)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。类型相当于“表”。
- 文档(Document)
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。相当于mysql表中的row。
- 映射(Mapping)
映射是定义文档及其包含的字段如何存储和索引的过程。

| 一级分类 | 二级分类 | 具体类型 |
|---|---|---|
| 核心类型 | 字符串类型 | string,text,keyword |
| h | 整数类型 | integer,long,short,byte |
| h | 浮点类型 | double,float,half_float,scaled_float |
| h | 逻辑类型 | boolean |
| h | 日期类型 | date |
| h | 范围类型 | range |
| h | 二进制类型 | binary |
| 复合类型 | 数组类型 | array |
| f | 对象类型 | object |
| f | 嵌套类型 | nested |
| 地理类型 | 地理坐标类型 | geo_point |
| d | 地理地图 | geo_shape |
| 特殊类型 | IP类型 | ip |
| t | 范围类型 | completion |
| t | 令牌计数类型 | token_count |
| t | 附件类型 | attachment |
| t | 抽取类型 | percolator |
bit:比特
byte:一个字节=8bit -2^7^ ~2^7^-1
short:两个字节=16bit -2^15^ ~ 2^15^-1
integer:四个字节=32bit
long:八个字节=64bit
ES集群架构
一个ES集群可以有多个节点构成,一个节点就是一个ES服务实例,通过配置集群名称cluster.name加入集群。
候选主节点:只有是候选主节点才可以参与选举投票,也只有候选主节点可以被选举为主节点。
主节点:负责索引的添加、删除,跟踪哪些节点是群集的一部分,对分片进行分配、收集集群中各节点的状态等,稳定的主节点对集群的健康是非常重要。
数据节点**:**负责对数据的增、删、改、查、聚合等操作,数据的查询和存储都是由数据节点负责,对机器的CPU,IO以及内存的要求比较高,一般选择高配置的机器作为数据节点。
协调节点:其本身不是通过设置来分配的,用户的请求可以随机发往任何一个节点,并由该节点负责分发请求、收集结果等操作,而不需要主节点转发。这种节点可称之为协调节点,集群中的任何节点都可以充当协调节点的角色。每个节点之间都会保持联系。
集群中单个节点既可以是候选主节点也可以是数据节点
ES安装部署
参考自己整理过的文章:ElasticSearch6.0.1及Azkaban3.8部署
配置普通用户
- 首先必须创建一个普通用户
- 然后把es所在的目录所有者设置为这个普通用户
配置es环境
修改系统配置
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties 2>&1 >> $KAFKA_HOME/kafka-server.log &
nohup /home/es/elasticsearch-7.10.2/bin/elasticsearch 2>&1 &
nohup :守护进程
& : 后台运行
2>&1 : 2-系统错误信息 1-系统信息 >&输出重定向
>> :追加写入
bin/elasticsearch -d
安装可视化插件:elasticsearch-head
安装IK分词器
配置VSCode

RestFul API
REST,表示性状态转移(representation state transfer)。简单来说,就是用URI表示资源,用HTTP方法(GET, POST, PUT, DELETE)表征对这些资源的操作。
URI:uniform resource indentify 统一资源标识符
URL:uniform resource locate 统一资源定位符 是URI的一个子集
- 一个动作配置一个接口
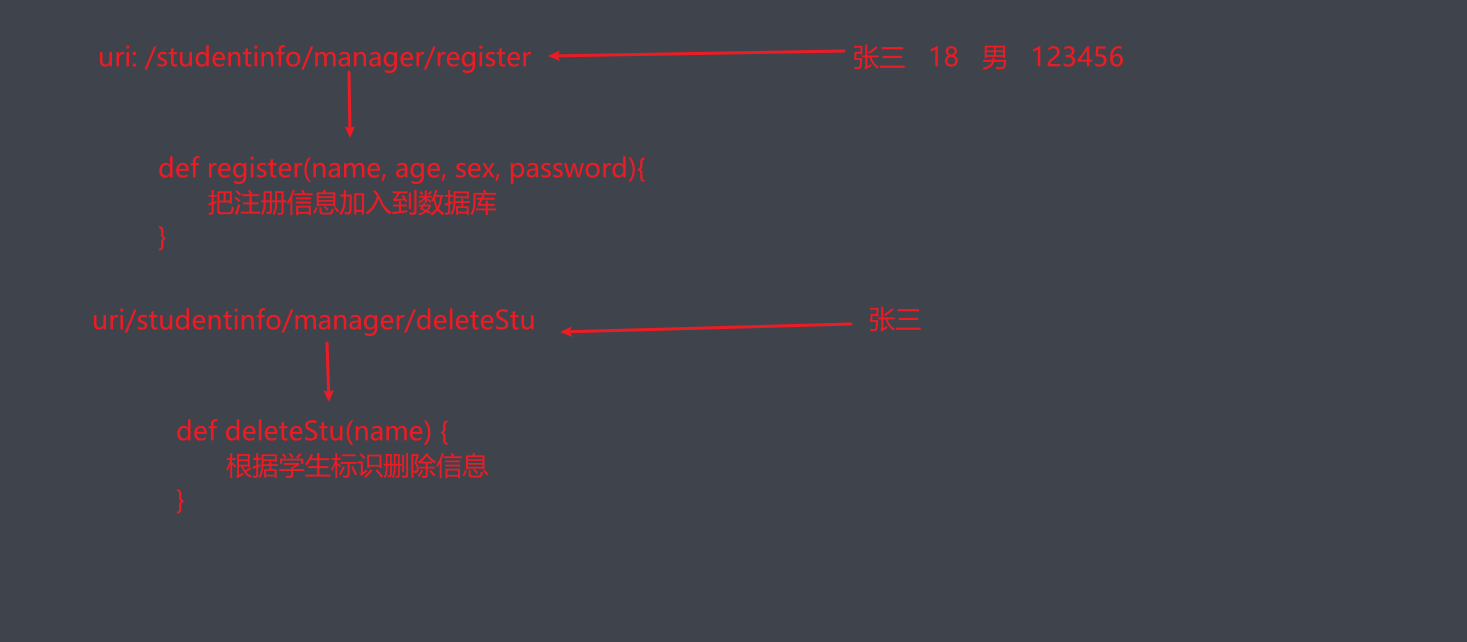
- 使用http方法类型判断执行的操作类型
GET - SELECT
POST - UPDATE
PUT - INSERT
DELETE - DELETE
ES操作使用(Kibana)
- 创建索引
1 | PUT /my-index |
- 指定副本、分片数量
1 | // 创建指定分片数量、副本数量的索引 |
- 字段类型
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 简单类型 | text | 需要进行全文检索的字段,通常使用text类型来对应邮件的正文、产品描述或者短文等非结构化文本数据。分词器先会将文本进行分词转换为词条列表。将来就可以基于词条来进行检索了。文本字段不能用于排序、也很少用于聚合计算。 |
| keyword | 使用keyword来对应结构化的数据,如ID、电子邮件地址、主机名、状态代码、邮政编码或标签。可以使用keyword来进行排序或聚合计算。注意:keyword是不能进行分词的。 | |
| date | 保存格式化的日期数据,例如:2015-01-01或者2015/01/01 12:10:30。在Elasticsearch中,日期都将以字符串方式展示。可以给date指定格式:”format”: “yyyy-MM-dd HH:mm:ss” | |
| long/integer/short/byte | 64位整数/32位整数/16位整数/8位整数 | |
| double/float/half_float | 64位双精度浮点/32位单精度浮点/16位半进度浮点 | |
| boolean | “true”/”false” | |
| ip | IPV4(192.168.1.110)/IPV6(192.168.0.0/16) | |
| JSON分层嵌套类型 | object | 用于保存JSON对象 |
| nested | 用于保存JSON数组 | |
| 特殊类型 | geo_point | 用于保存经纬度坐标 |
| geo_shape | 用于保存地图上的多边形坐标 |
- 创建测试索引
1 | PUT /job_idx |
- 查看索引
1 | 查看所有索引 |
- 删除索引
1 | delete /job_idx |
- 指定分词器创建索引
1 | PUT /job_idx |
- 添加数据
1 | PUT /job_idx/_doc/29097 |
- 修改数据
1 | POST /job_idx/_update/29097 |
- 删除数据
1 | DELETE /job_idx/_doc/29097 |
- 批量导入数据
1 | 使用Elasticsearch中自带的bulk接口来进行数据导入 |
- 查看索引状态
1 | GET _cat/indices?index=job_idx |
- 根据ID检索数据
1 | GET /job_idx/_search |
- 根据关键词搜索
1 | // 单字段搜索 |
- 分页搜索
1 | GET /job_idx/_search |
ES操作使用(Curl)
最原始的一种方式,搭建完ElasticSearch就能即刻开箱使用,内网环境必备技能。
东西很多,先抓最主要的东西:
- 查看ElasticSearch中的全部索引(查看有多少表)
curl -u elk http://192.168.88.161:9201/_cat/indices?v
- 查看指定索引的全部field(查看某张表的字段)
curl -XGET -u elk http://192.168.88.161:9201/testindex/_mapping?pretty
- 根据field进行条件过滤(根据字段进行过滤)
curl -XGET "http://192.168.88.161:9201/testindex/_search" -H 'Content-Type: application/json' -d ' { "query": { "bool": { "must": [ { "match": { "mchnt_id": "1" } }, { "match": { "mchnt_name": "利耶尼亚" } } ] } } }'
1 | 查看集群状态 |
注意事项
为什么直接写IP?因为没有配置hosts。
为什么是9201端口?这是在ElasticSearch安装目录下的config配置文件中配置的,可以自己定义。
若集群未添加用户安全认证,“-u elk” 或 “- -user elk” 可以缺省,回车后也无需输入密码。
若ElasticSearch 集群添加了用户安全认证功能,curl 命令中的 “-u elk” 代表以 elk 用户访问 elkSearch 集群,也可以修改为 “- -user elk”,命令回车后需要输入密码。
如果碰到什么问题,及时参考官方文档,ElasticSearch社区太有活力了!
ES评分模型
Elasticsearch是基于Lucene的,所以它的评分机制也是基于Lucene的。在Lucene中把这种相关性称为得分(score),确定文档和查询有多大相关性的过程被称为打分(scoring)。
ES最常用的评分模型是 TF/IDF和BM25,TF-IDF属于向量空间模型,而BM25属于概率模型,但是他们的评分公式差别并不大,都使用IDF方法和TF方法的某种乘积来定义单个词项的权重,然后把和查询匹配的词项的权重相加作为整篇文档的分数。
在ES 5.0版本之前使用了TF/IDF算法实现,而在5.0之后默认使用BM25方法实现。
- Term Frequency(TF)词频:即单词在该文档中出现的次数,词频越高,相关度越高。
- Document Frequency(DF)文档频率:即单词出现的文档数。
- Inverse Document Frequency(IDF)逆向文档频率:与文档频率相反,简单理解为1/DF。即单词出现的文档数越少,相关度越高。
- Field-length Norm:文档越短,相关性越高,field长度,field越长,相关度越弱
TF/IDF模型是Lucene的经典模型,其计算公式如下:
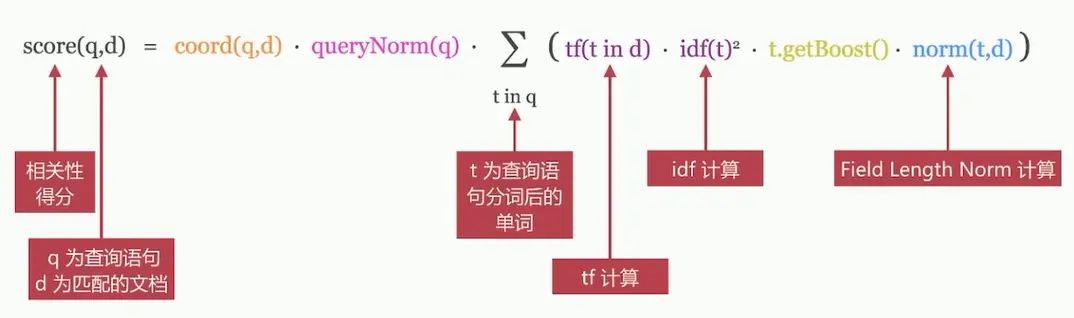
BM25 模型中BM指的Best Match,25指的是在BM25中的计算公式是第25次迭代优化,是针对TF/IDF的一个优化,其计算公式如下:

- 通过执行计划查看打分过程
1 | GET /job_idx/_search |
ES编程实现
- 创建虚拟环境
1 | conda create -n es_env python==3.7.13 |
- pycharm连接远程环境
- python操作es
1 | class JobClazz(): |
1 | from elasticsearch import Elasticsearch |
- 高亮显示
1、负责公司产品销售线索和机会挖掘
1、负责公司产品销售线索和机会挖掘
ES读写流程
写入ES
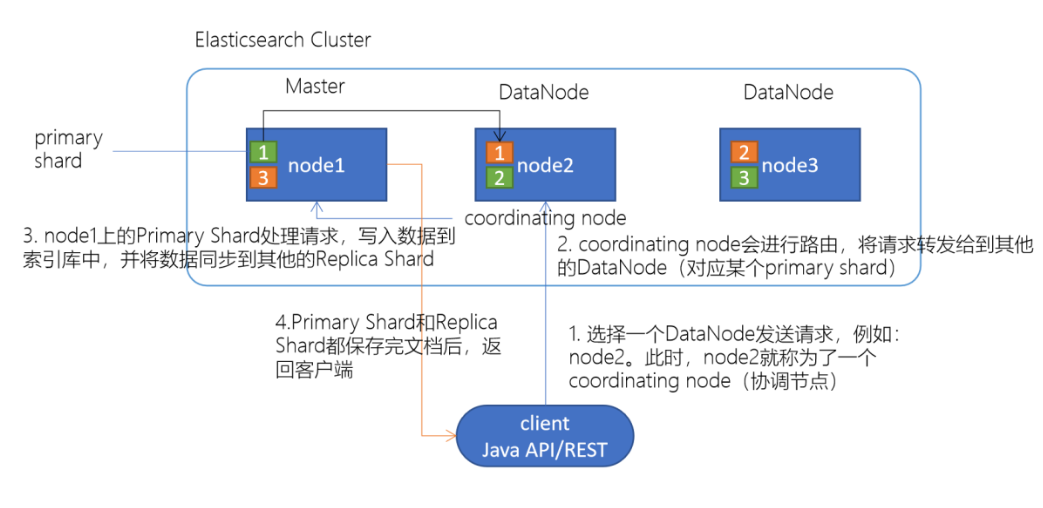
- 客户端选择一个DataNode(node2)节点,发起写入请求,此时node2就是一个协调节点
- 协调节点会进行路由(hash(routing) % num of primary shard)routing默认每个document的id
- 对到对应的主分片处理写入请求,将数据写入到index中(将数据保存在_source字段,根据分词构建倒排索引)
- 副本分片从主分片同步数据
- 当主分片和副本分片数据都写入成功将结果返回给客户端
检索ES
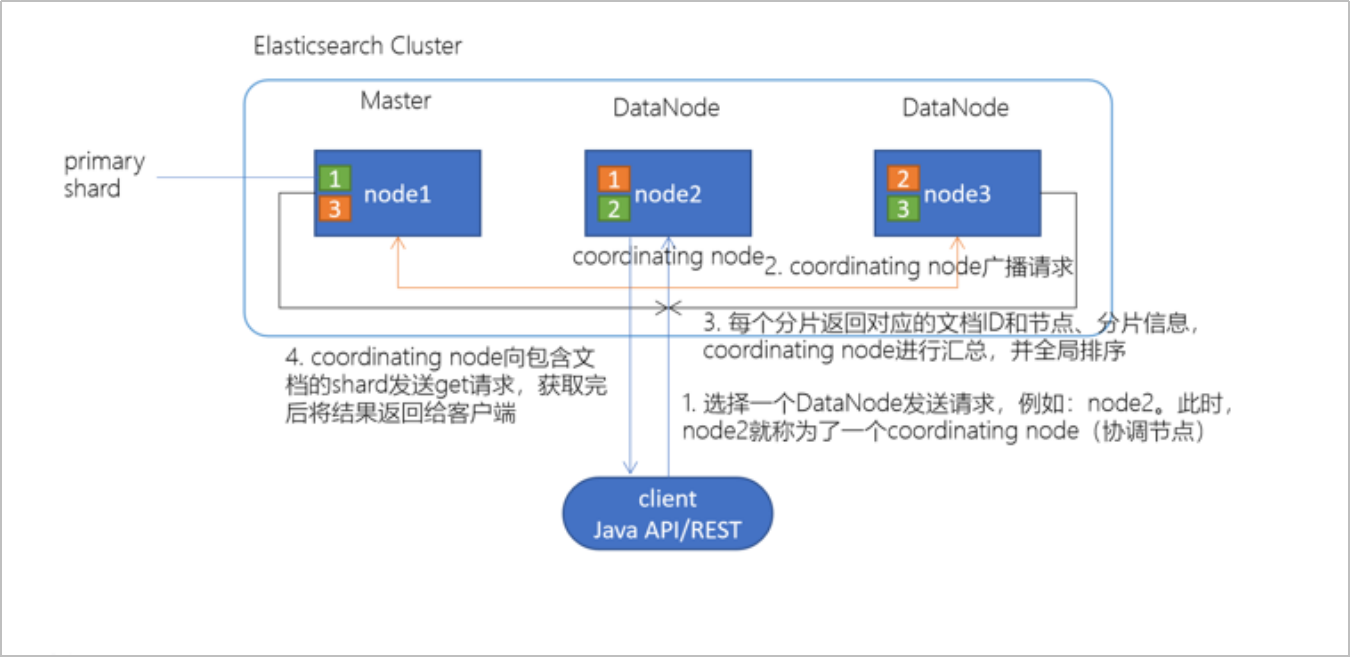
- 客户端选择一个DataNode(node2)节点,发起查询请求,此时node2就是一个协调节点
- 协调节点将查询请求进行广播
- 每个节点会对每个分片(多个文件,每个文件对应一个倒排索引)根据倒排索引进行查询,将查询的文档ID、分数、分片信息返回给协调节点
- 协调节点汇总(排序)每个数据节点发来的文档信息发送get(根据ID)请求,获取最终结果返回给客户端
准实时索引实现
- 溢写到文件系统缓存
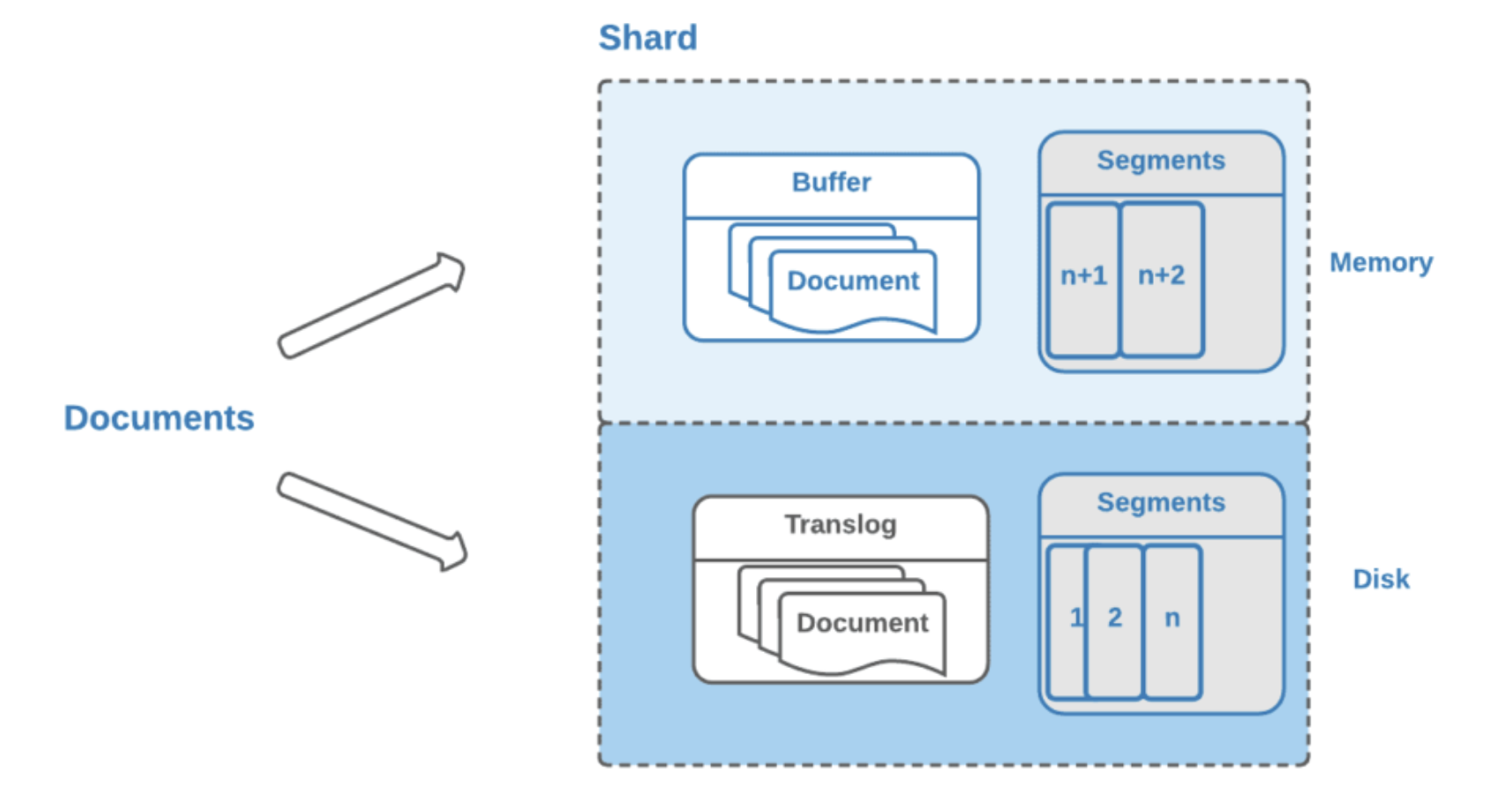
当数据写入到ES分片时,会首先写入到内存中,然后通过内存的buffer生成一个segment(每个segment对应一个倒排索引),并刷到文件系统缓存中,数据可以被检索(注意不是直接刷到磁盘)
ES中默认1秒,refresh一次
- 写translog保障容错
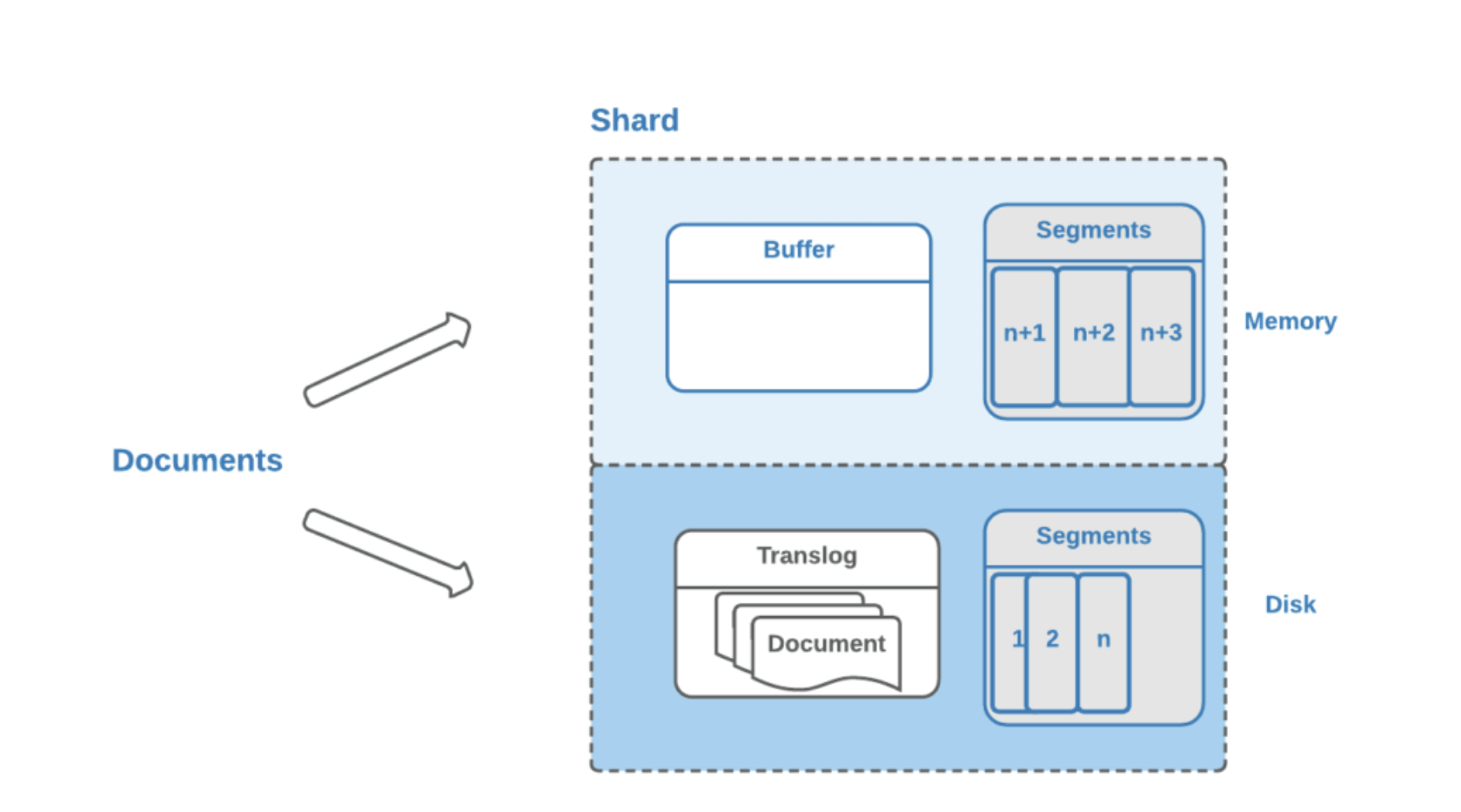
在写入到内存中的同时,也会记录translog日志,在refresh期间出现异常,会根据translog来进行数据恢复
等到文件系统缓存中的segment数据都刷到磁盘中,清空translog文件
- flush到磁盘
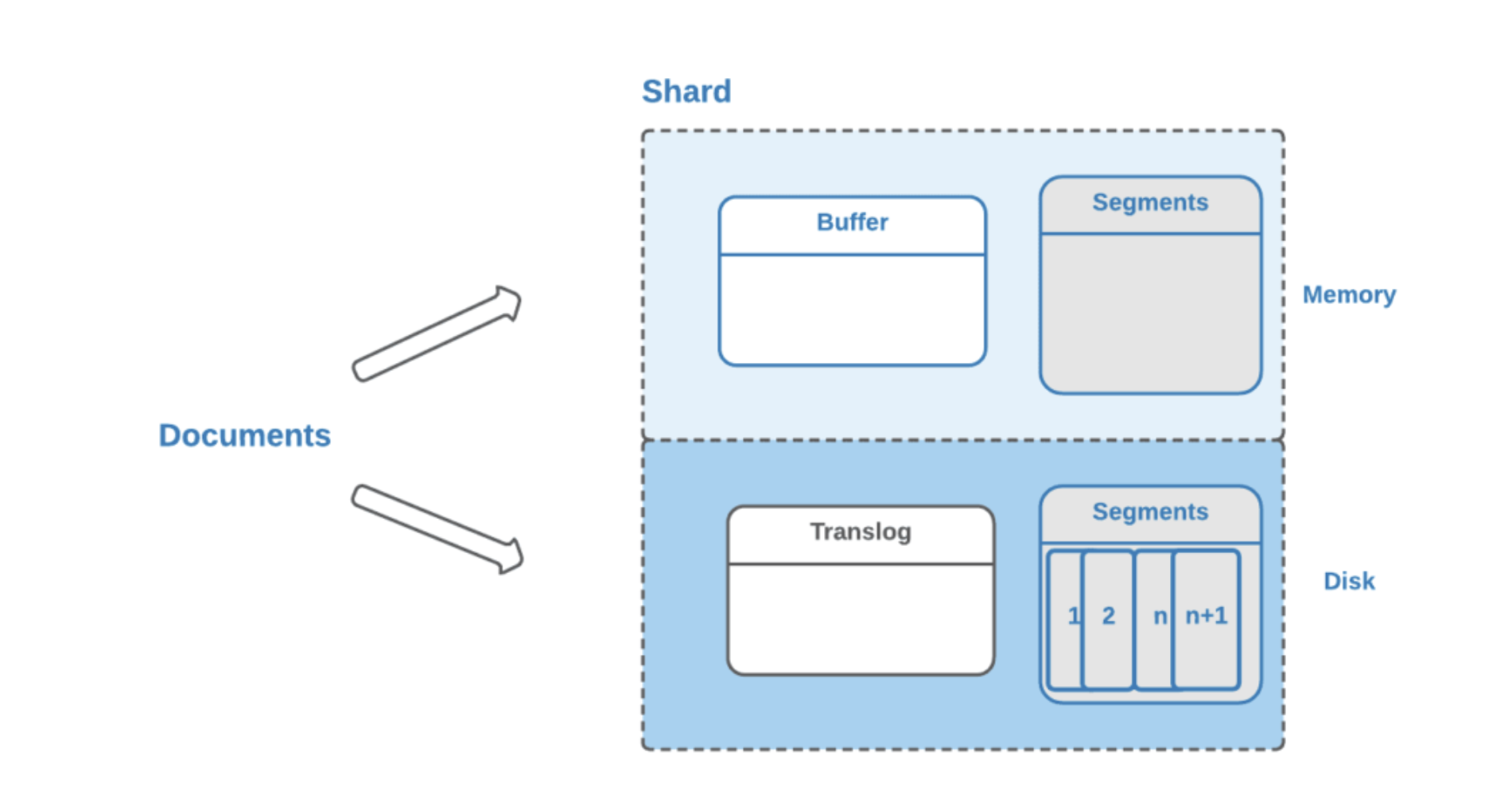
ES默认每隔30分钟会将文件系统缓存的数据刷入到磁盘
- segment合并
Segment太多时,ES定期会将多个segment合并成为大的segment,减少索引查询时IO开销,此阶段ES会真正的物理删除(之前执行过的delete的数据)
ES支持SQL
- Elasticsearch SQL特点:
- 本地集成
- Elasticsearch SQL是专门为Elasticsearch构建的。每个SQL查询都根据底层存储对相关节点有效执行。
- 没有额外的要求
- 不依赖其他的硬件、进程、运行时库,Elasticsearch SQL可以直接运行在Elasticsearch集群上
- 轻量且高效
- 像SQL那样简洁、高效地完成查询
- SQL与Elasticsearch对应关系
SQL Elasticsearch column(列) field(字段) row(行) document(文档) table(表) index(索引) schema(模式) mapping(映射) database(数据库) Elasticsearch集群实例
- Elasticsearch SQL语法
1 | SELECT select_expr [, ...] |
- 查询数据
1 | -- 分页查询 |
案例实现
- 创建索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36PUT /order_idx/
{
"mappings": {
"properties": {
"id": {
"type": "keyword",
"store": true
},
"status": {
"type": "keyword",
"store": true
},
"pay_money": {
"type": "double",
"store": true
},
"payway": {
"type": "byte",
"store": true
},
"userid": {
"type": "keyword",
"store": true
},
"operation_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"store": true
},
"category": {
"type": "keyword",
"store": true
}
}
}
}- 导入测试数据
1
curl -H "Content-Type: application/json" -XPOST "up01:9200/order_idx/_bulk?pretty&refresh" --data-binary "@order_data.json"
- 统计不同支付方式的的订单数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18-- SQL方式
GET /_sql?format=txt
{
"query": "select payway, count(*) as order_cnt from order_idx group by payway"
}
-- DSL 方式
GET /order_idx/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "payway"
}
}
}
}
目前Elasticsearch SQL还存在一些限制。例如:目前from只支持一个表、不支持JOIN、不支持较复杂的子查询。所以,有一些相对复杂一些的功能,还得借助于DSL方式来实现。
ES整合HIVE
搭建离线数仓
将Mysql中的业务数据导入至Hive:
用户表:tbl_users 950
订单数据表:tbl_orders 120125
订单商品表:tbl_goods 1
行为日志表:tbl_logs 376983
通过sqoop建表
- 创建用户表
1 | create-hive-table 创建一个Hive表, 读取mysql的表结构, 使用这个结构来创建Hive表 |
- 订单表
1 | /export/server/sqoop/bin/sqoop create-hive-table \ |
- 商品表 \001 \x01
1 | /export/server/sqoop/bin/sqoop create-hive-table \ |
- 日志表
1 | /export/server/sqoop/bin/sqoop create-hive-table \ |
sqoop导入数据
- 用户数据
1 | direct 直接导出模式 会加快导出速度 使用关系型数据库自带的导出工具(mysql 会使用mysqldump命令) |
- 订单数据
1 | /export/server/sqoop/bin/sqoop import \ |
- 商品数据
1 | /export/server/sqoop/bin/sqoop import \ |
- 行为日志
1 | /export/server/sqoop/bin/sqoop import \ |
HIVE写入ES
把Hive数据导入ES 要借助一个工具,es-hadoop 是一个jar 工具也有版本号, 要跟Elasticsearch的版本对应, 当前用的是7.10的ES es-hadoop也要用7.10版本的es-hadoop,使用ES-Hadoop 既可以和Hadoop相关组件交互, 也可以和Spark之间进行交互。
hive数据导入ES步骤
- ① 把es-hadoop的jar包放到hdfs上,当前的虚拟机是放到了/libs/es-hadoop/这个目录下
- ② 在hive的命令行里执行
1 | add jar hdfs:///libs/es-hadoop/elasticsearch-hadoop-7.10.2.jar; |
- ③ 创建一个外部表
1 | create external table XXX (...) |
- ④ 查询hive 表的数据,插入到上面创建的外部表中
1 | insert overwrite table 外部表 select 字段 from hive表; |
问题:集群告警
解决方案:修改副本数为0
1 | .es集群告警的问题,可以通过命令解决,官方解决方式,测试后确认无法通过配置文件方式解决: |
问题:数据重复
解决方案:开启upsert模式
- ‘es.write.operation’ = ‘upsert’
- 使用upsert模式, 需要指定id
- ‘es.mapping.id’ = ‘id’ 可以选择数据中, 没有重复数据的字段, 做为_id
- 如果不指定es.mapping.id,es会默认自动生成一个不重复的数据作为_id
问题:索引不刷新
解决方案:修改refresh
1 | PUT ec_tbl_orders/_settings |
ES整合SPARK
spark 整合 ES , 先把ES-Hadoop的jar包放到 spark的jars目录下
1 | /root/anaconda3/envs/pyspark_env/lib/python3.7/site-packages/pyspark/jars |
- Spark读取ES代码
1 | spark.read.format('es').option() |
- 必选参数
1 | es.resource 读取的index名称 |
- 可选参数
1 | es.index.auto.create (default yes) |
注意
python操作es
- from elasticsearch import Elasticsearch (pip安装对应版本依赖)
- es = Elasticsearch(hosts=‘up01:9200’)
sql操作es
- 本地原生支持
- 目前不支持join操作
es读写流程
- 写入数据
- 客户端发送写入请求协调节点(随机选择)
- 协调节点根据数据的routing(_id)计算hash值,并根据主分片的数量进行路由
- 找到对应主分片将数据写入保存并创建倒排索引
- 副本分片从主分片上同步数据
- 当数据保存完毕后由协调节点向客户端返回结果
- 读取数据
- 客户端发送读取数据的请求给协调节点
- 协调节点对读取请求进行广播
- 所有分片都会进行数据查询
- 将查询结果(文档ID、分片信息、分数等)在协调节点上进行汇总(全局排序)
- 按照汇总的结果向对应的分片发送get请求获取数据并返回给客户端
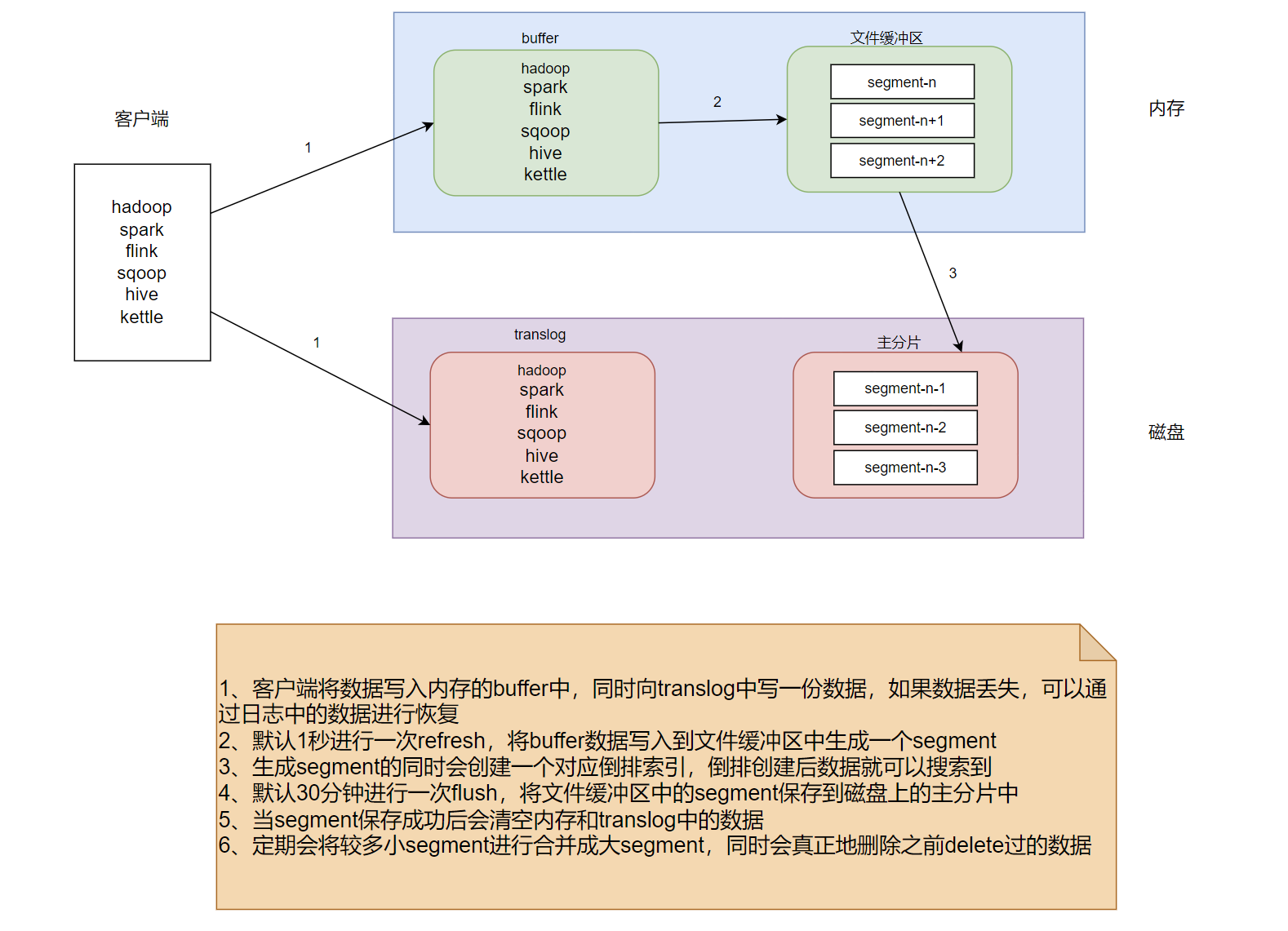
- 索引实现
- 数据首先写入内存的buffer中,同时会写一份数据到磁盘上translog中,用来保证数据的安全
- 默认1秒进行一次refresh,将内存buffer中的数据写入到文件缓冲区生成一个segment,同时生成对应的倒排索引
- 默认30分钟进行一次flush,将文件缓冲区中的segment刷新到磁盘上进行持久化保存,同时清空内存和translog中持久化后的数据
- 由于segment会生成很多小文件,会定期进行小segment合并成大segment,同时会将之前delete过的数据做真正物理上的删除
- 写入数据
es整合hive
- 上传elasticsearch-hadoop.xx对应的版本jar包至hdfs
- 在当前hive会话 add jar jar的路径(只在当前会话生效)
- 使用hive创建一个映射es的外部表,create external table 表名(schema) sorted by “xxxx” tblproperties(key=value)
- hive->es : insert overwrite 外部表 from hive表
es整合spark
- 需要将elasticsearch-hadoop.xxx.jar放到pyspark运行环境下
- sparkSession.read.format(‘es’).option(‘es.nodes’, xxx).option(‘es.resource’, xxxx).option(‘es.read.field.include’, xxxx)
- sparkSession.write.format(‘es’)
 微信
微信 支付宝
支付宝