
大数据集群环境搭建
一、VMware的安装
注意:本文档演示的是12版本的,所有版本都是一样的!
First step: 运行“VMware_workstation_full_12.5.2.exe”(或者其他版本)

Second step:引导页面,直接点击下一步
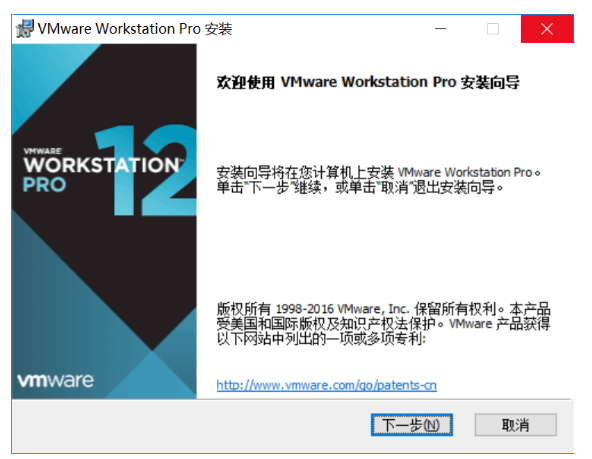
Third step: 同意许可,然后继续点击下一步
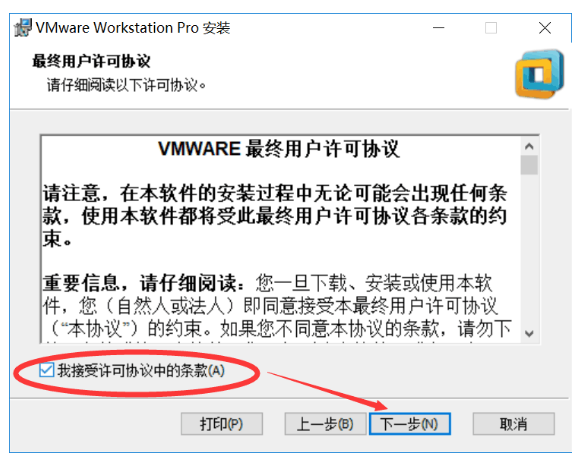
Forth step: 选择VMware安装位置,然后点击下一步
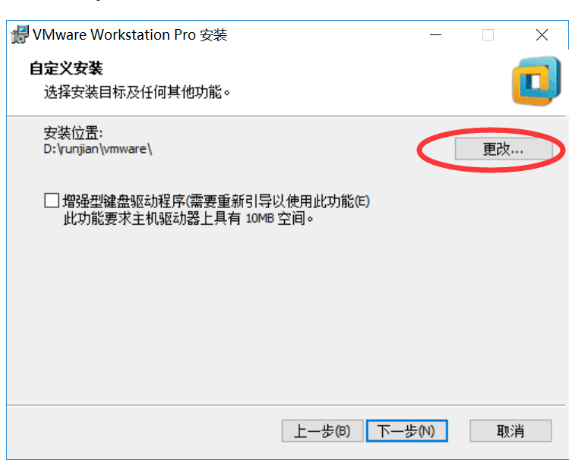
Sixth step: 用户体验设置,建议全部取消勾选,然后点击下一步
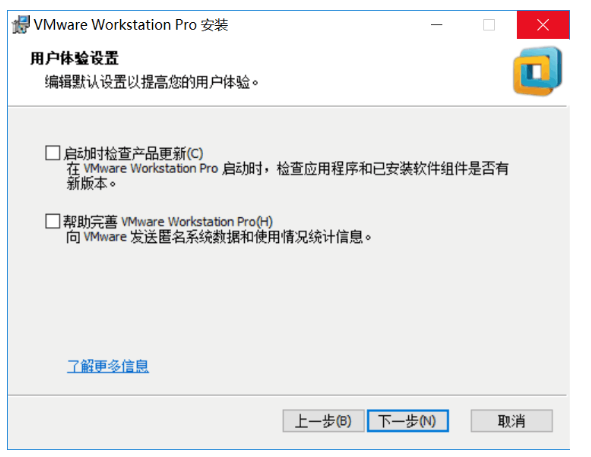
Fifth step: 根据个人喜好选择,然后点击下一步
Seventh step: 点击安装
Eighth step: 等待安装完成,然后点击许可证
Ninth step: 自己在百度搜索一个vmware12密匙,粘贴复制,然后点击输入
Last step: 安装完成
二、虚拟机安装操作
创建虚拟机
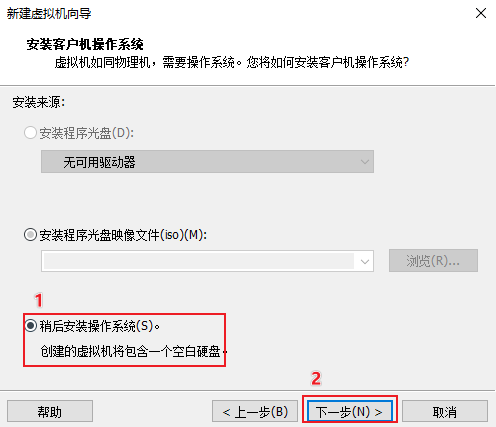
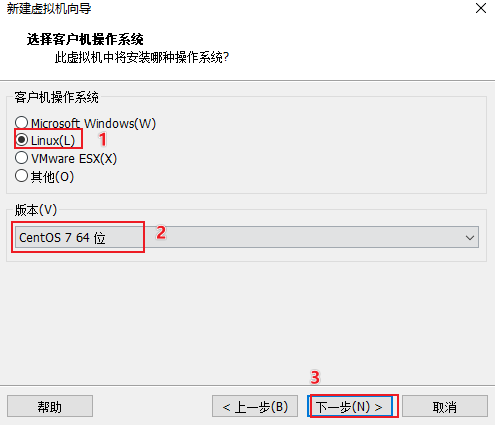
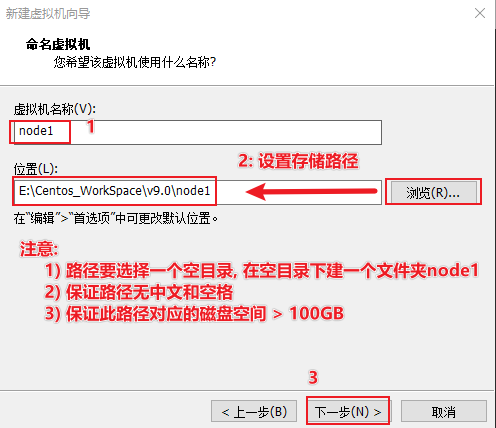
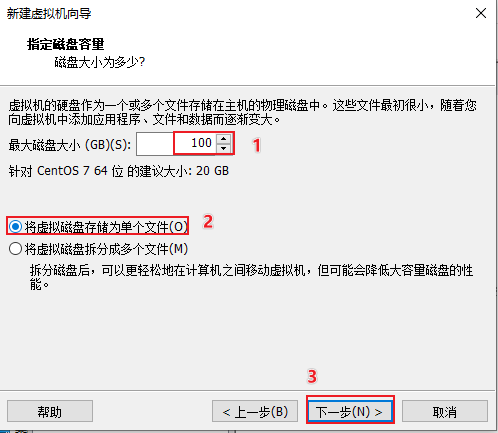
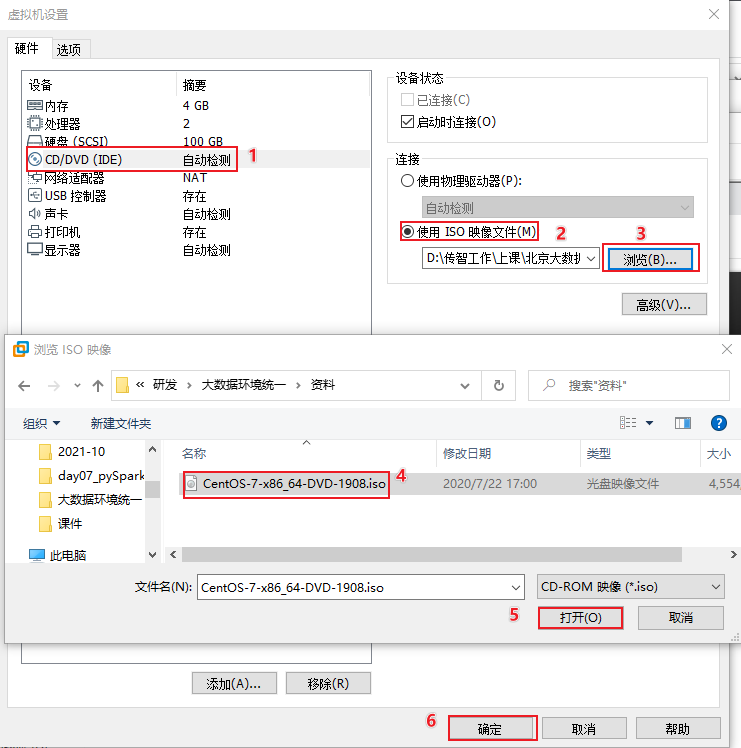
添加linux的iso镜像文件
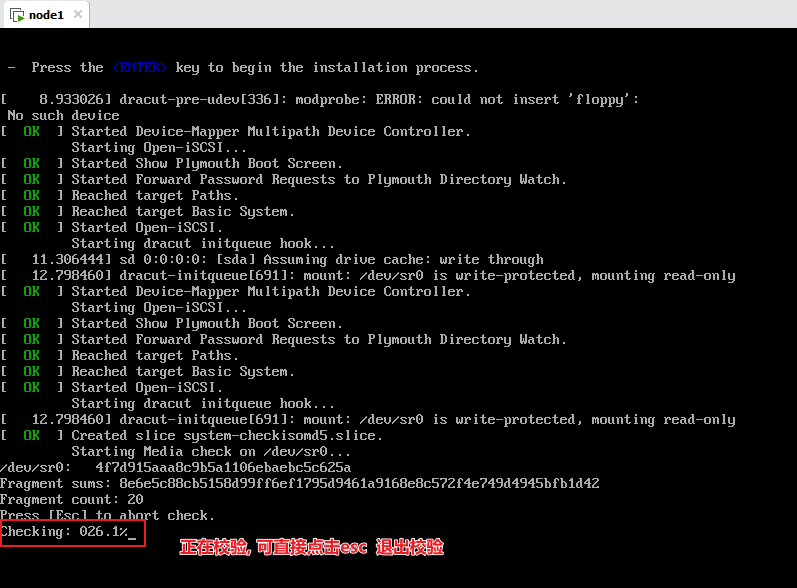
开启虚拟机, 进行安装
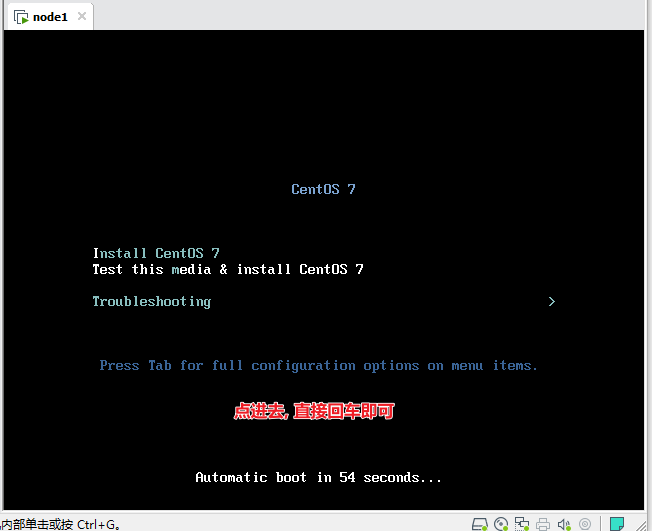
正在校验, 可直接选择esc退出, 或者等待一会也是OK的
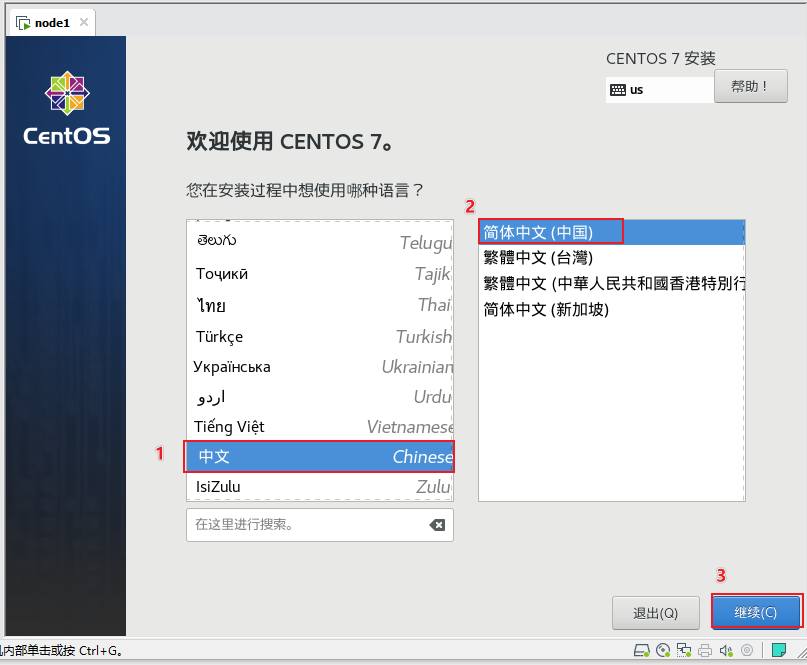
直到出现以下界面,开始选择语言:

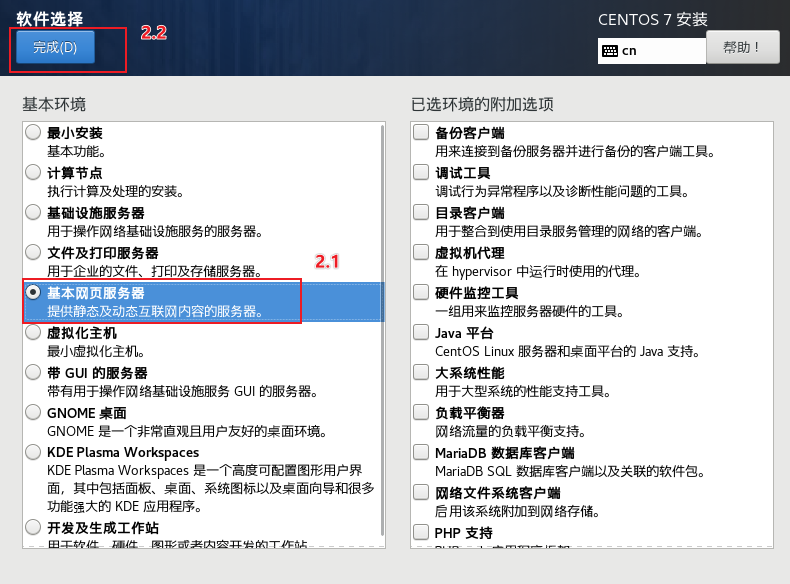
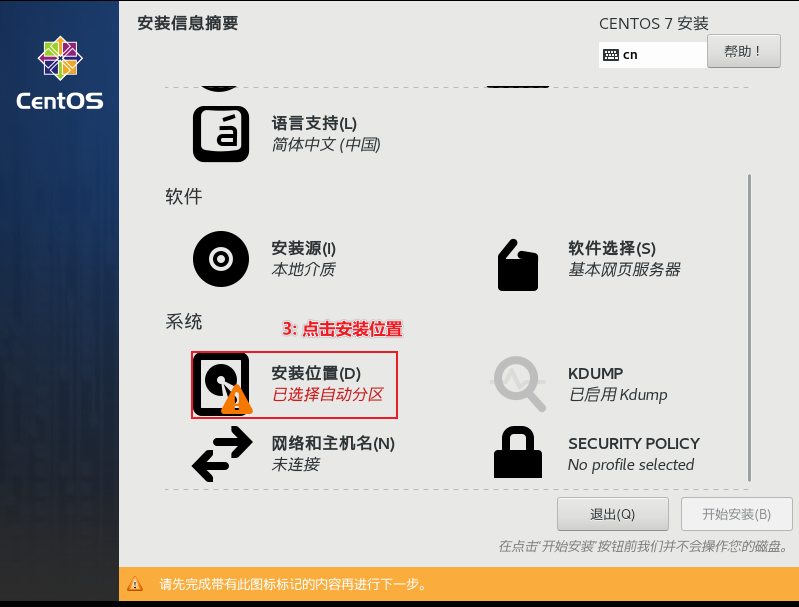
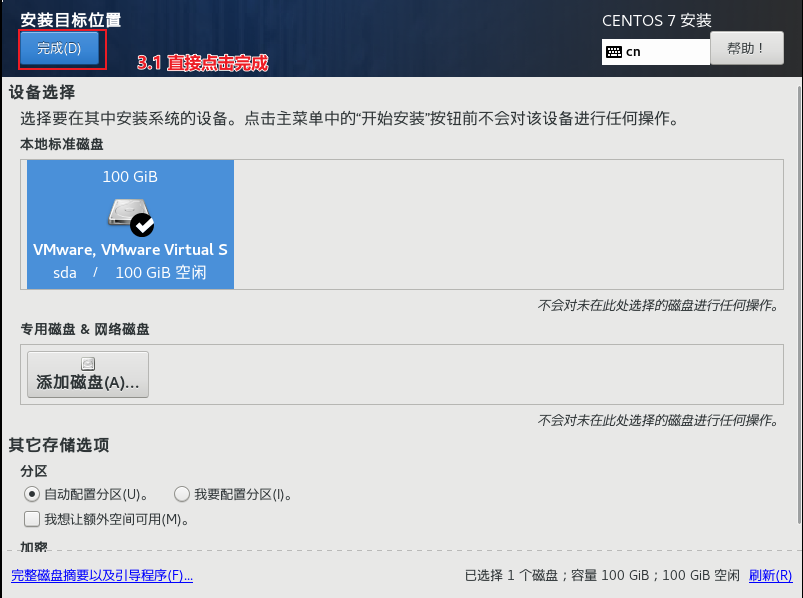
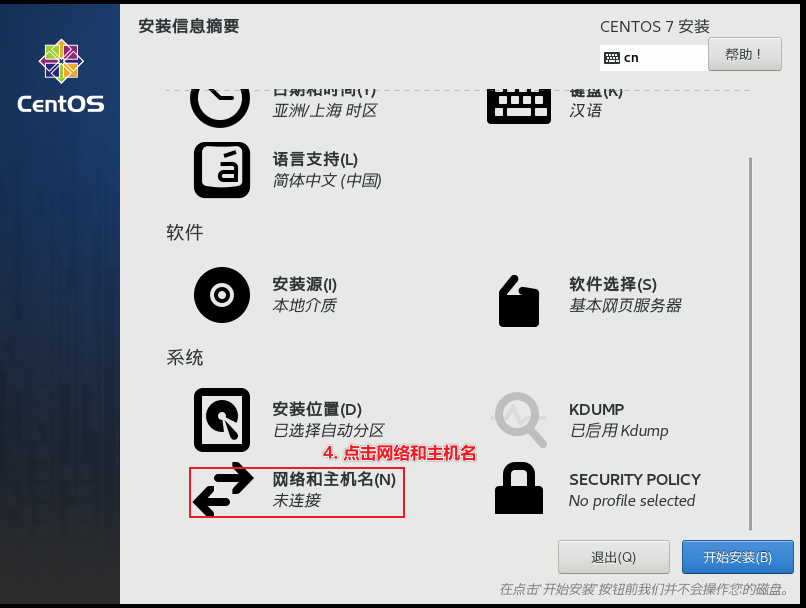
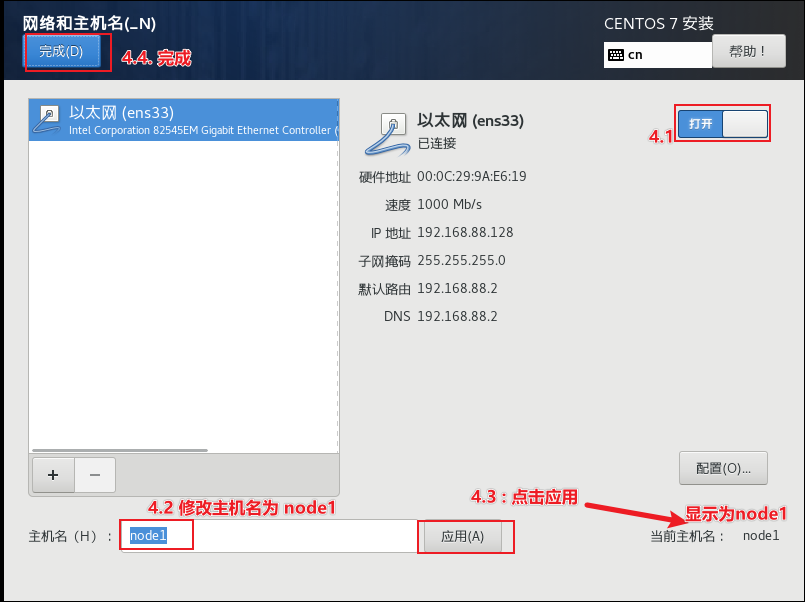
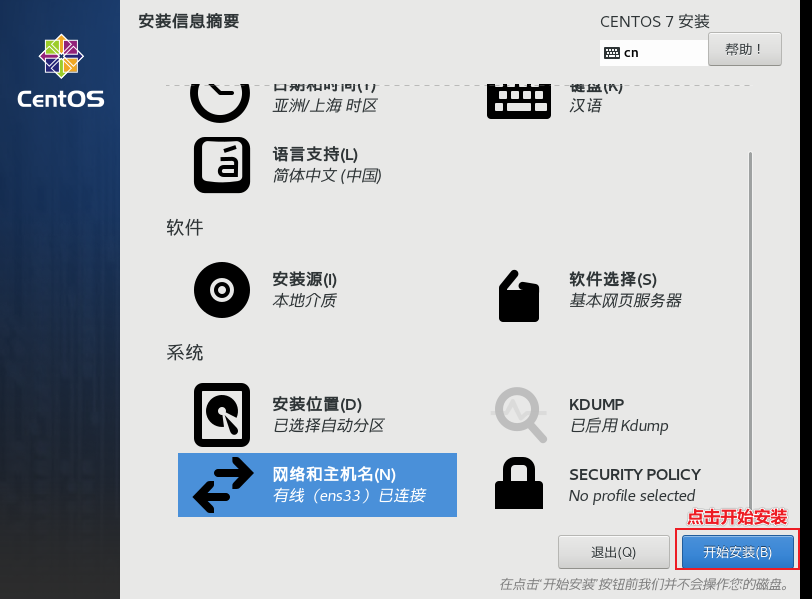
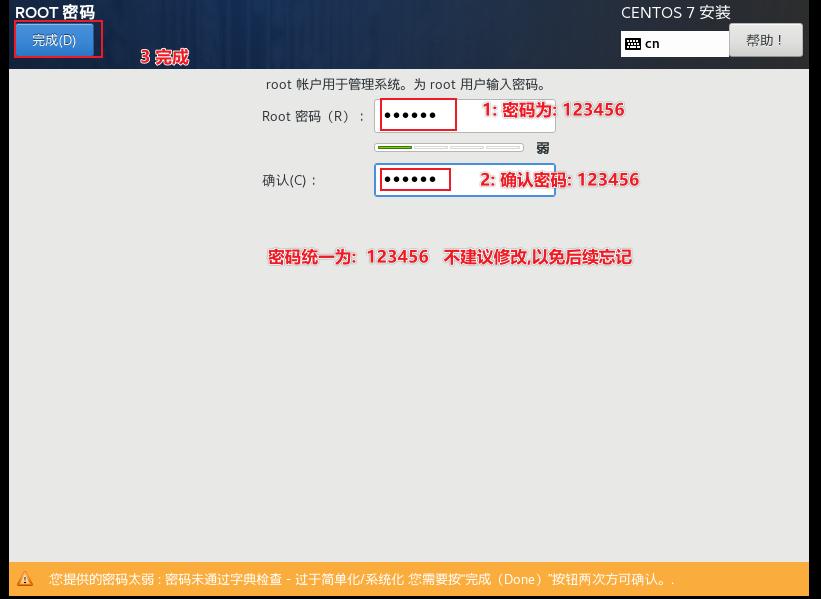
结束后 , 点击重启, 然后进入系统, 到此, 虚拟机搭建工作结束
登录, 进入系统


三、SecureCRT使用
CRT安装
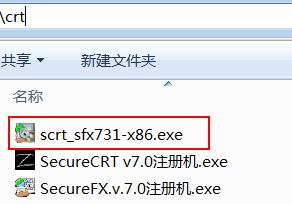
步骤1:安装“scrt_sfx731-x86.exe”
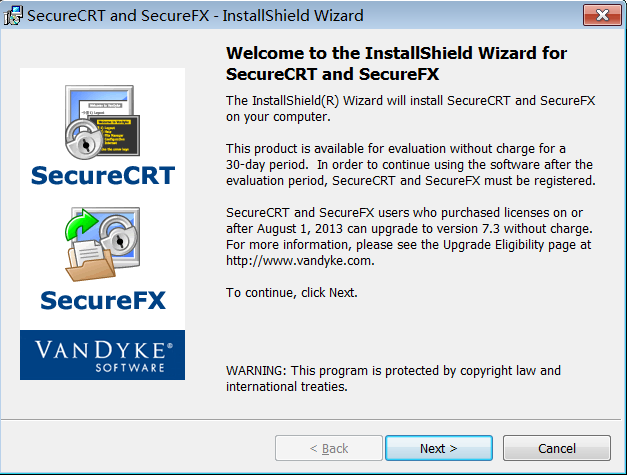
步骤2:欢迎页面
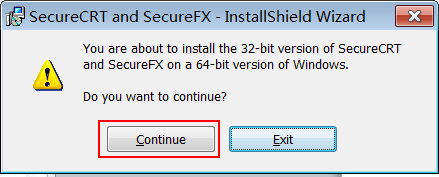
步骤3:如果是64位操作系统,存在此提示。
步骤4:同意许可
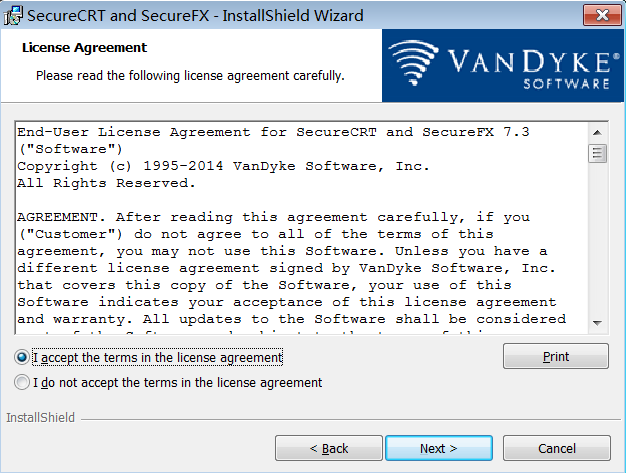
步骤5:选择配置文件是否共享(默认)
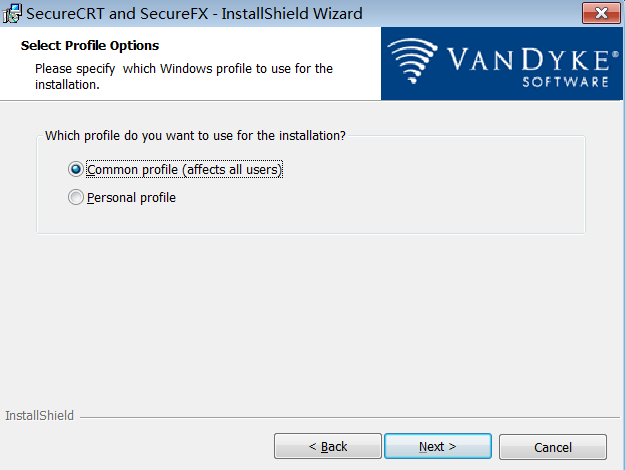
步骤6:安装类型,自定义
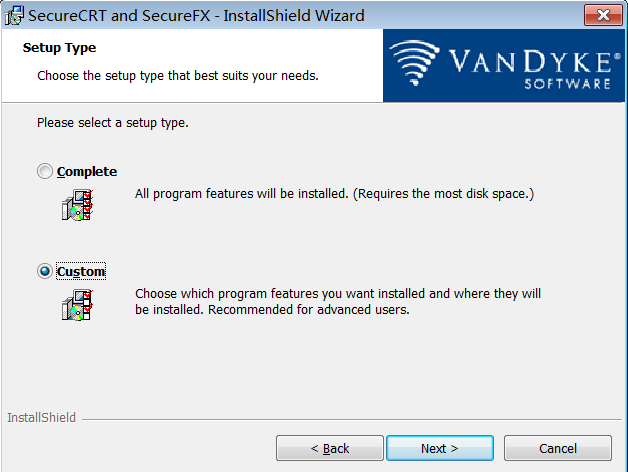
步骤7:选择安装路径
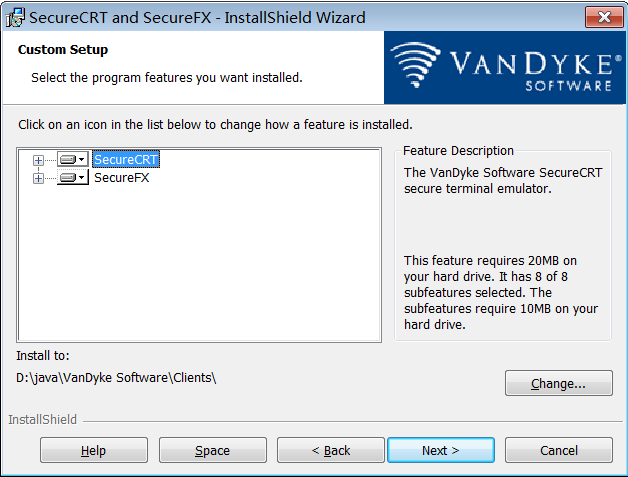
步骤8:快捷方式(默认)
步骤9:开始安装
步骤10:完成
激活
- 步骤1:将对应的激活程序拷贝到安装目录下
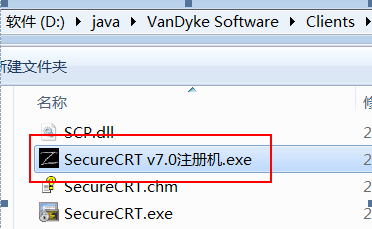
- 步骤2:以“管理员”运行“SecureCRT v7.0注册机.exe”激活程序,打补丁
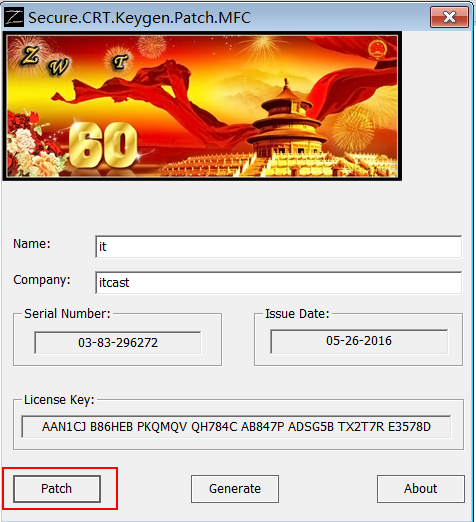
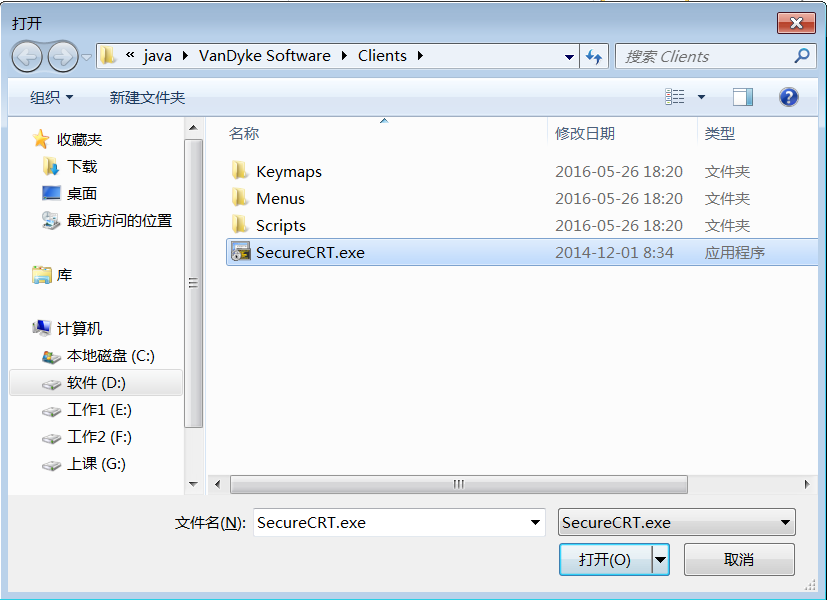
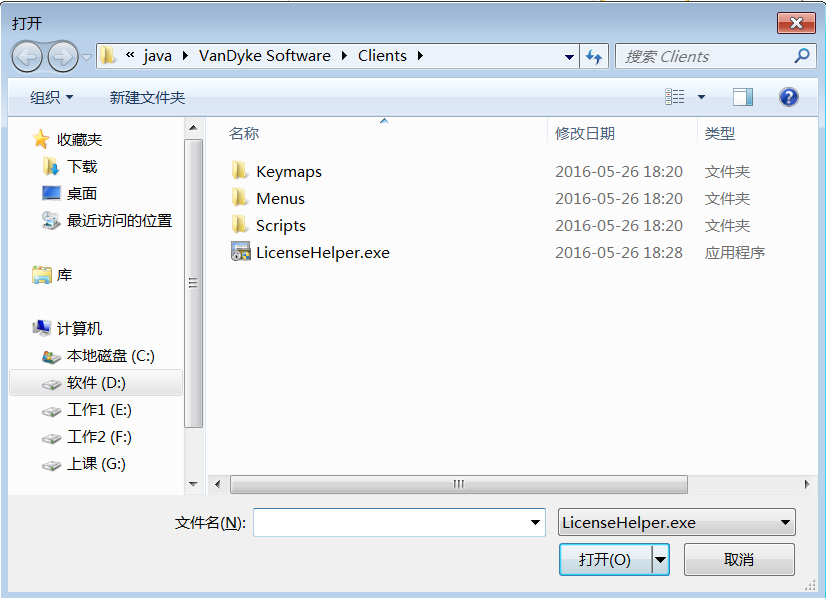
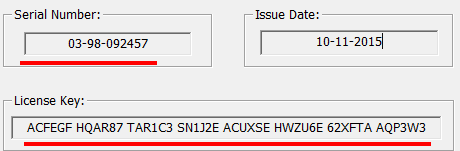
- 步骤3:生成序列号
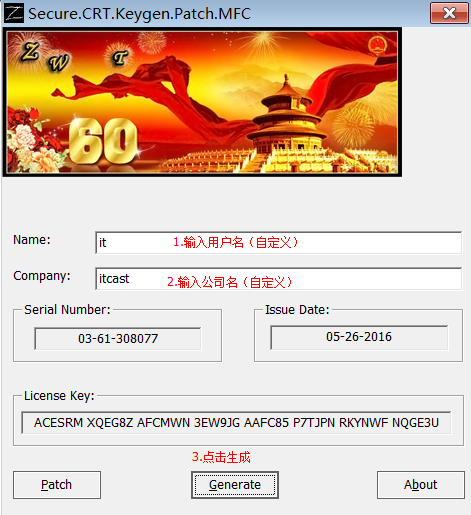
- 步骤4:运行程序,“SecureCRT 7.3”,并输入激活码
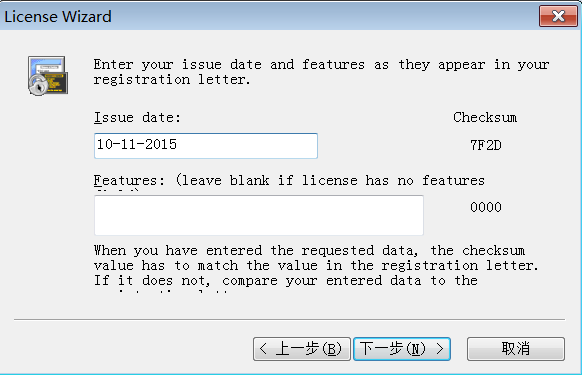
1)不输入任何内容,下一步
2)点击输入详情选项
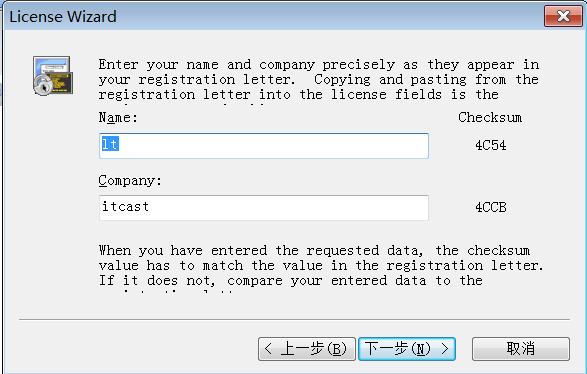
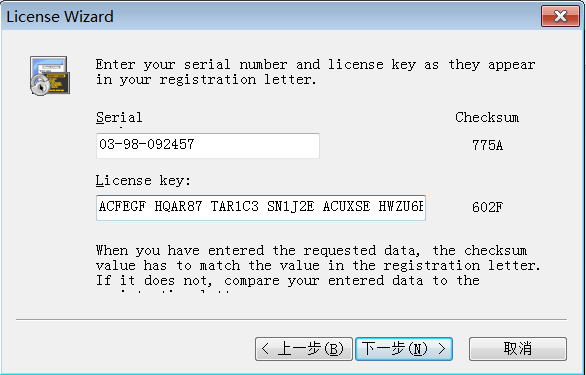
3)输入详细内容

连接
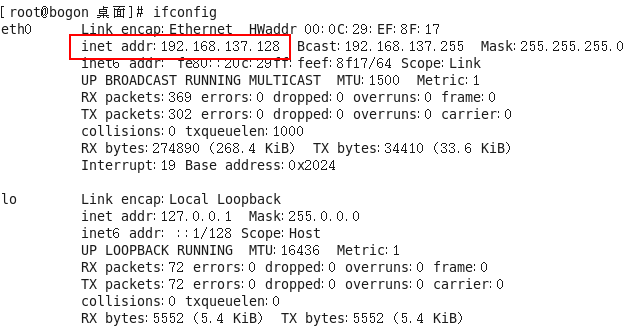
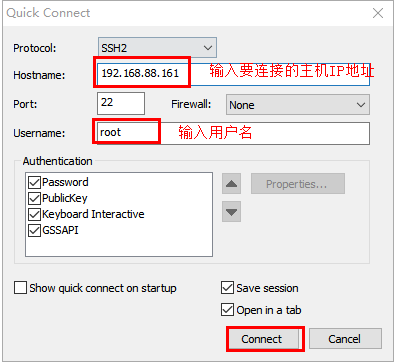
- 步骤1:登录linux成功之后,输入“ifconfig”查询ip地址
步骤2:运行“SecureCRT.exe”进行连接
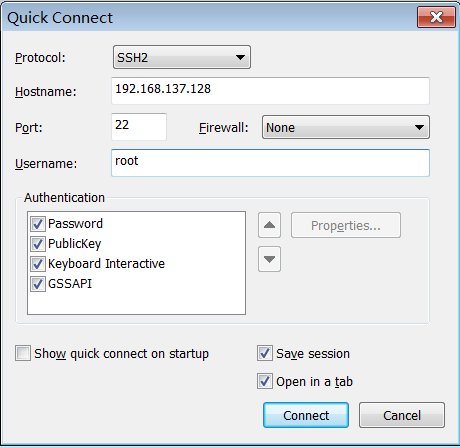
步骤3:保存当次连接
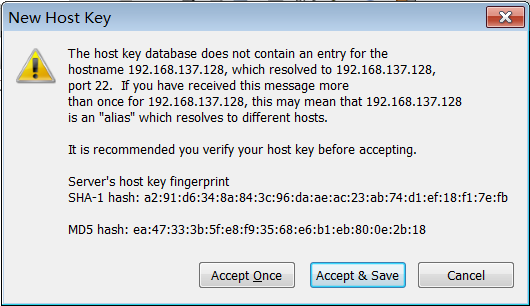
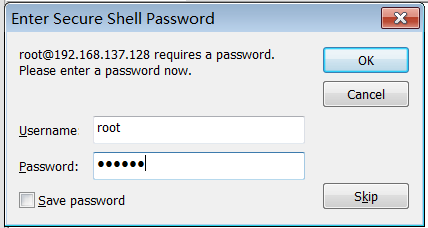
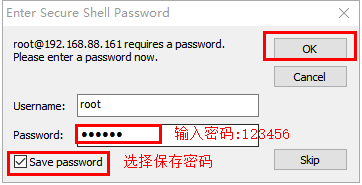
步骤4:输入密码并连接
常见设置
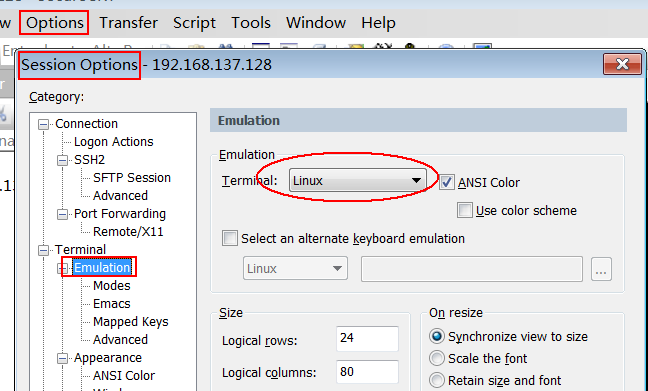
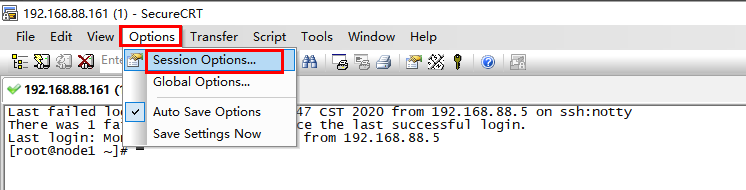
设置操作窗口“背景黑色”。运行“SecureCRT 7.3”
修改后结果
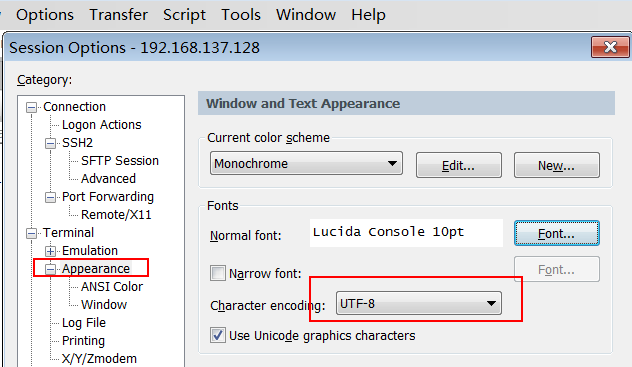
设置操作窗口“字体”和“字符集”
四、虚拟机卸载
安装cclear:切换语言

关闭VMware所有的服务
打开服务:win+r : 输入 services.msc
关闭所有的VMware的服务

打开卸载程序, 卸载VMware
控制面板–> 卸载程序—>删除VMware
使用cclear清除注册表
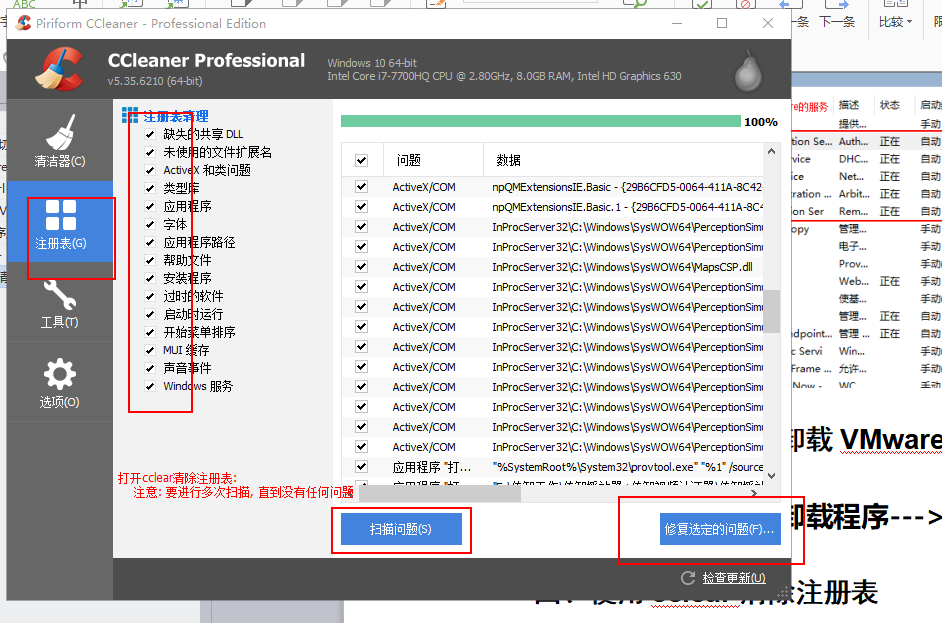
打开服务: services.msc
查看VMware服务有没有:
如果有:
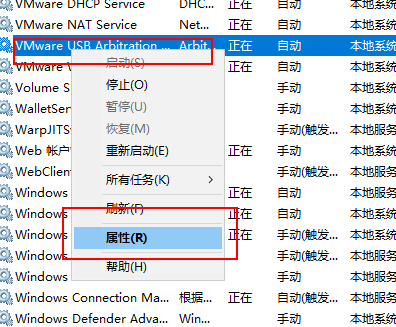
查看服务的名称:
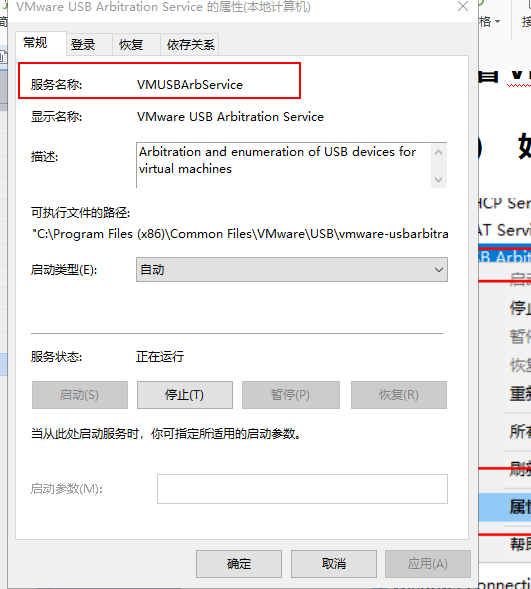
复制服务名称:打开cmd(管理员打开)
输入名称: sc delete 服务名称
注意: 需要删除所有的vmware服务
此时: 建议再次运行cclear: 查看有没有新的注册表出现: 如果有, 继续干掉
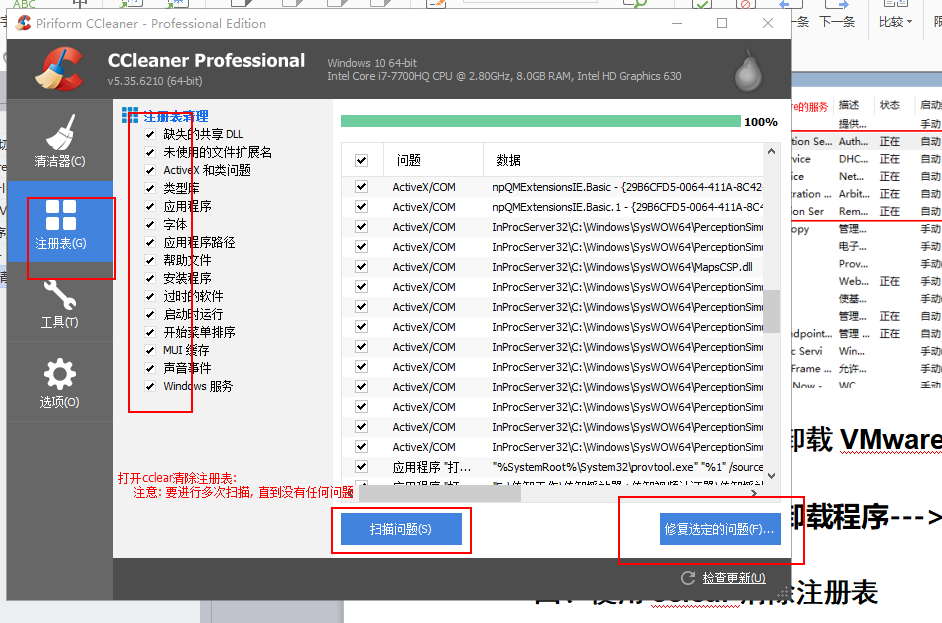
五、大数据环境配置统一
三台虚拟机创建
第一种方式:通过iso镜像文件来进行安装(不推荐)
第二种方式:直接复制安装好的虚拟机文件(强烈推荐)
在课程资料里边已经提供了一个安装好的虚拟机node1(注意,为了大家以后环境的统一,尽量使用课程资料中提供的已经安装好的虚拟机!!!!!!),我们需要根据这个虚拟机克隆出另外两台虚拟机出来,注意,步骤如下:
- 使用VMware加载资料中虚拟机node1
2)克隆第二台虚拟机,注意克隆虚拟机的时候,虚拟机必须是关闭状态
右键点击node1
下一步
下一步
创建完整克隆,下一步
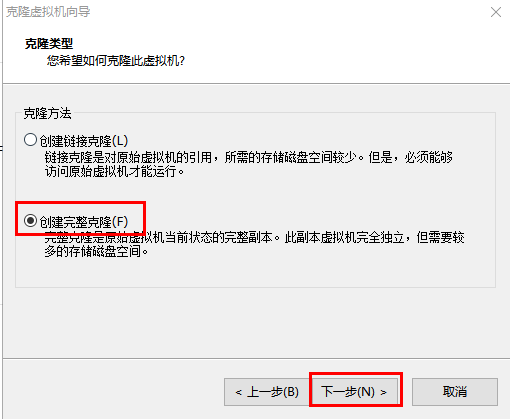
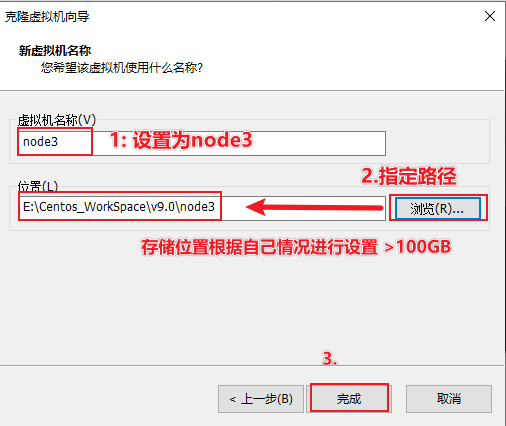
指定虚拟机名字和存放位置,三台虚拟机的存放路径尽量在一起,不在一起也没关系
等待克隆完毕
关闭
- 克隆第三台虚拟机,通过node1虚拟机克隆,克隆方式是一样的,注意修改虚拟机的名称和存放位置。
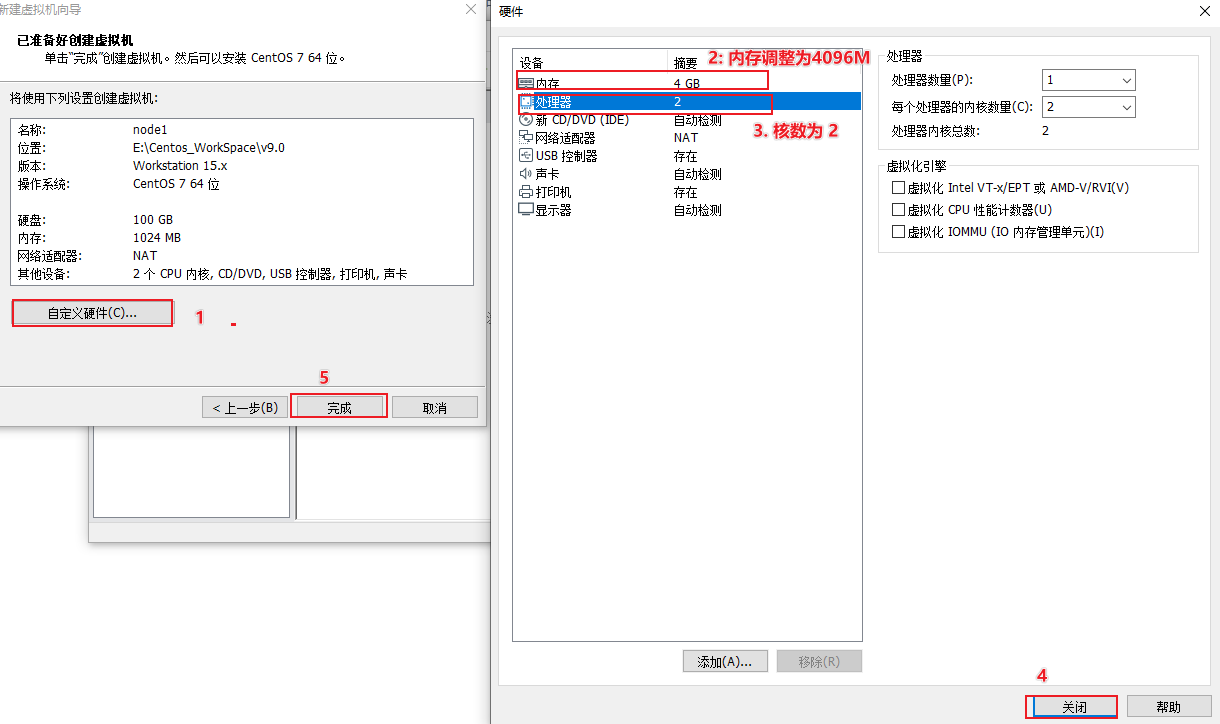
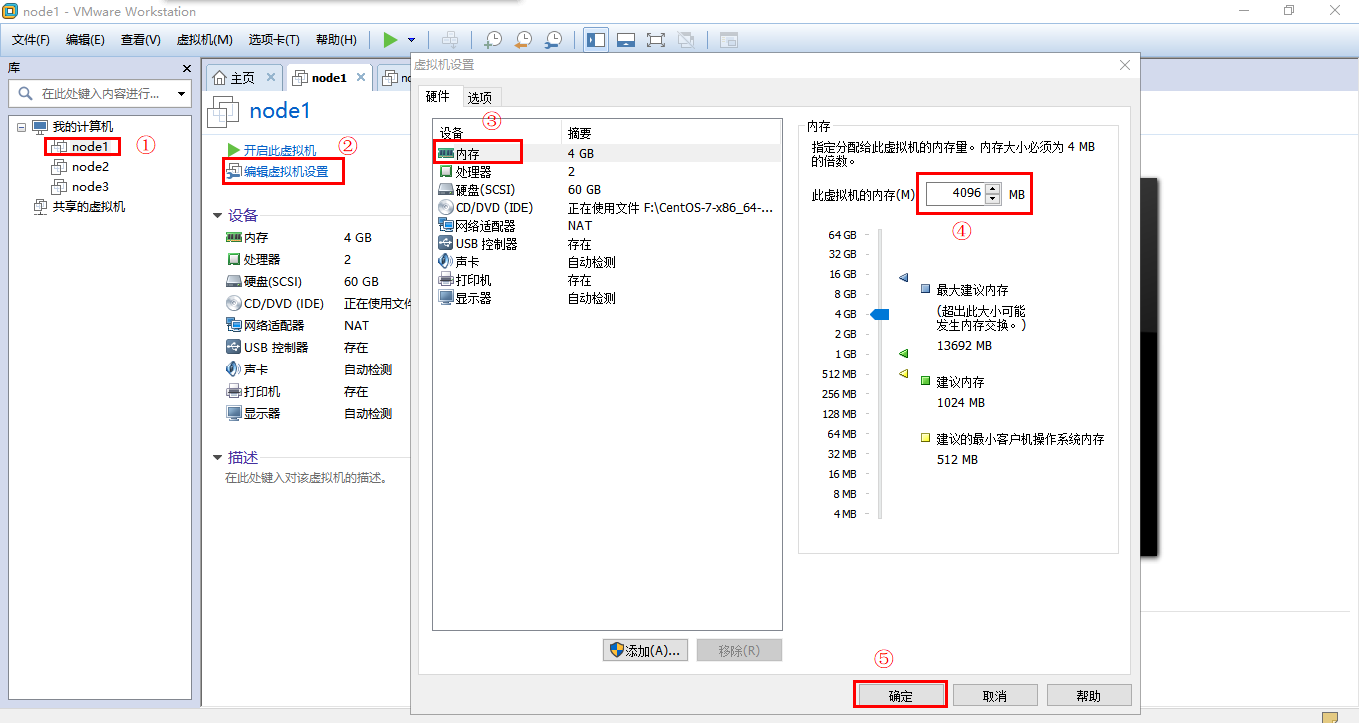
设置三台虚拟机的内存和CPU核数设置
三台虚拟机再加上windows本身, 需要同时运行4台机器, 所以在分配的时候,, 每台虚拟机的内存为: 总内存 ÷ 4,比如电脑总内存为16G,则每台虚拟机内存为4G。
下面是以node1为例对内存进行配置:
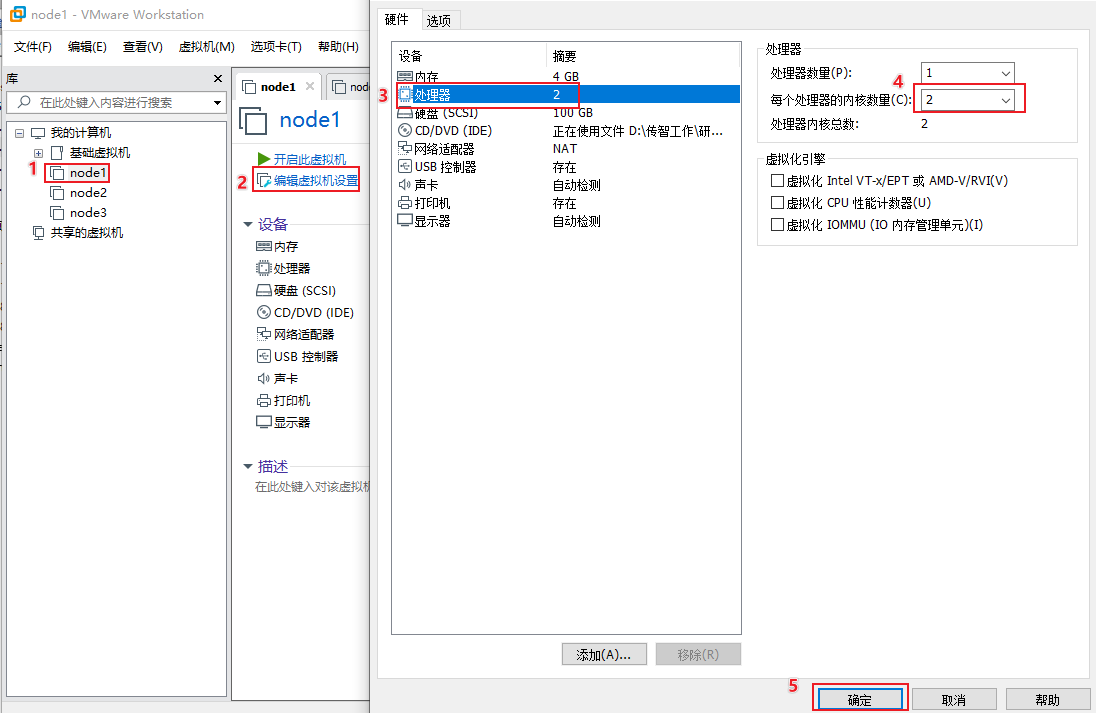
CPU核数, 建议每个服务器设置为2核即可, 保证能够更加流畅运行
配置MAC地址
node2和node3都是从node1克隆过来的,他们的MAC地址都一样,所以需要让node2和node3重新生成MAC地址,生成方式如下:
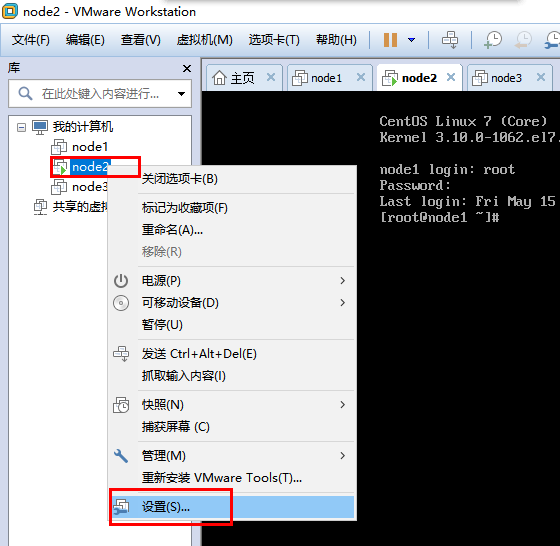
1、配置node2的MAC地址
1)使用VMware打开node2
2)右键点击node2,选择设置
3)生成新的MAC地址
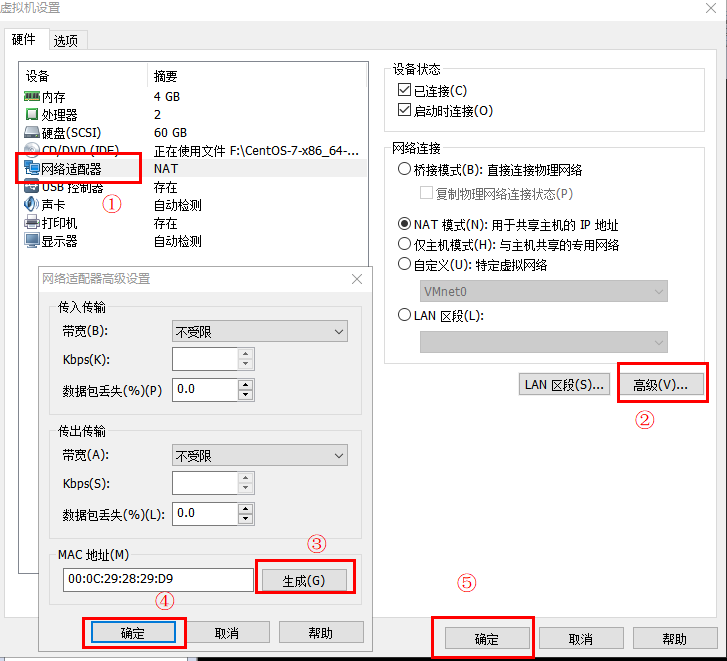
- 配置node3的MAC地址
node3的配置方式和node2相同,不再重复
配置IP地址
三台虚拟机的IP地址配置如下:
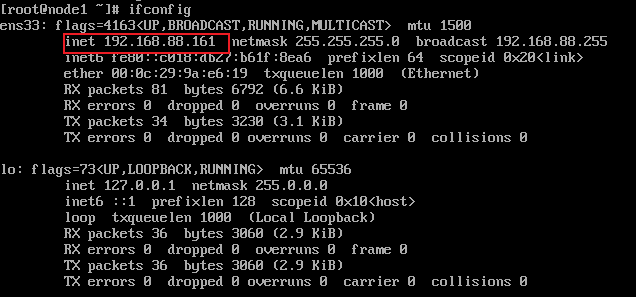
node1: 192.168.88.161
node2 192.168.88.162
node3: 192.168.88.163
1:配置node1主机IP
- 修改ip配置文件,设置IP地址
| vim **/etc/sysconfig/network-scripts/**ifcfg-ens33 |
|---|
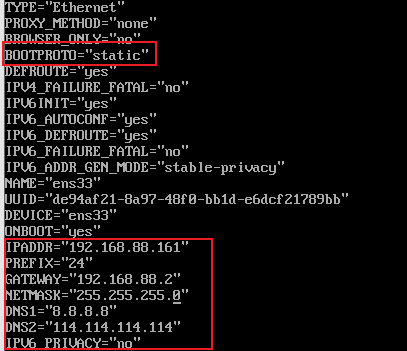
| TYPE=”Ethernet” PROXY_METHOD=”none” BROWSER_ONLY=”no” BOOTPROTO=”static” DEFROUTE=”yes” IPV4_FAILURE_FATAL=”no” IPV6INIT=”yes” IPV6_AUTOCONF=”yes” IPV6_DEFROUTE=”yes” IPV6_FAILURE_FATAL=”no” IPV6_ADDR_GEN_MODE=”stable-privacy” NAME=”ens33” UUID=”dfd8991d-799e-46b2-aaf0-ed2c95098d58” DEVICE=”ens33” ONBOOT=”yes” IPADDR=”192.168.88.161” PREFIX=”24” GATEWAY=”192.168.88.2” NETMASK=”255.255.255.0” DNS1=”8.8.8.8” DNS2=”114.114.114.114” IPV6_PRIVACY=”no” |
|---|
- 重启网络服务
| systemctl restart network # 重启网络服务 |
|---|

- 查看ip地址
| ifconfig |
|---|
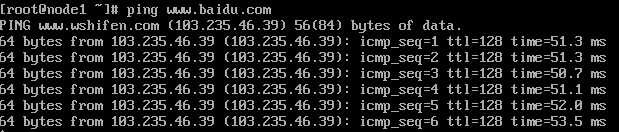
- 测试网络连接
| ping www.baidu.com |
|---|
2:配置node2主机IP
- 修改ip配置文件,设置IP地址
| vim **/etc/sysconfig/network-scripts/**ifcfg-ens33 |
|---|
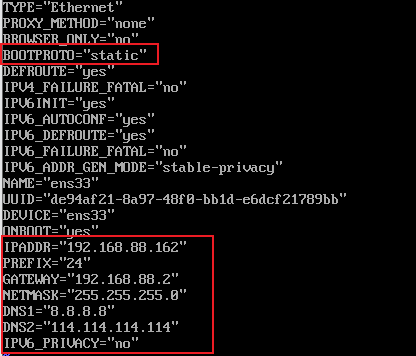
| TYPE=”Ethernet” PROXY_METHOD=”none” BROWSER_ONLY=”no” BOOTPROTO=”static” DEFROUTE=”yes” IPV4_FAILURE_FATAL=”no” IPV6INIT=”yes” IPV6_AUTOCONF=”yes” IPV6_DEFROUTE=”yes” IPV6_FAILURE_FATAL=”no” IPV6_ADDR_GEN_MODE=”stable-privacy” NAME=”ens33” UUID=”dfd8991d-799e-46b2-aaf0-ed2c95098d58” DEVICE=”ens33” ONBOOT=”yes” IPADDR=”192.168.88.162” PREFIX=”24” GATEWAY=”192.168.88.2” NETMASK=”255.255.255.0” DNS1=”8.8.8.8” DNS2=”114.114.114.114” IPV6_PRIVACY=”no” |
|---|
- 重启网络服务
| systemctl restart network # 重启网络服务 |
|---|
- 查看ip地址
| ifconfig |
|---|
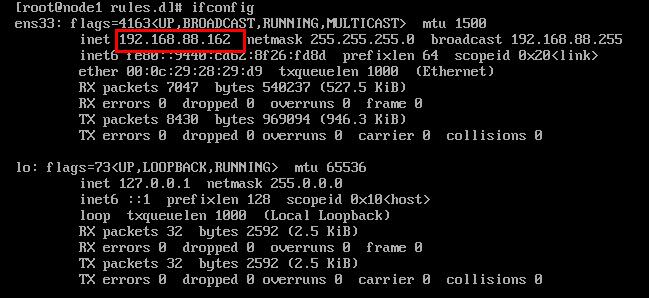
- 测试网络连接
| ping www.baidu.com |
|---|

2:配置node3主机IP
node3主机IP的配置方式和node2一样,将其IP地址设置为:192.168.88.163,在这里不再重复。
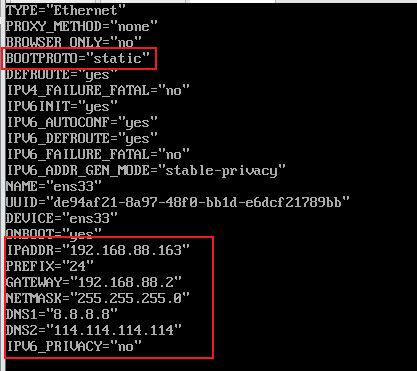
| TYPE=”Ethernet” PROXY_METHOD=”none” BROWSER_ONLY=”no” BOOTPROTO=”static” DEFROUTE=”yes” IPV4_FAILURE_FATAL=”no” IPV6INIT=”yes” IPV6_AUTOCONF=”yes” IPV6_DEFROUTE=”yes” IPV6_FAILURE_FATAL=”no” IPV6_ADDR_GEN_MODE=”stable-privacy” NAME=”ens33” UUID=”dfd8991d-799e-46b2-aaf0-ed2c95098d58” DEVICE=”ens33” ONBOOT=”yes” IPADDR=”192.168.88.163” PREFIX=”24” GATEWAY=”192.168.88.2” NETMASK=”255.255.255.0” DNS1=”8.8.8.8” DNS2=”114.114.114.114” IPV6_PRIVACY=”no” |
|---|
使用CRT连接三台虚拟机
1、建立连接
2、参数配置
3、设置主题,颜色和仿真
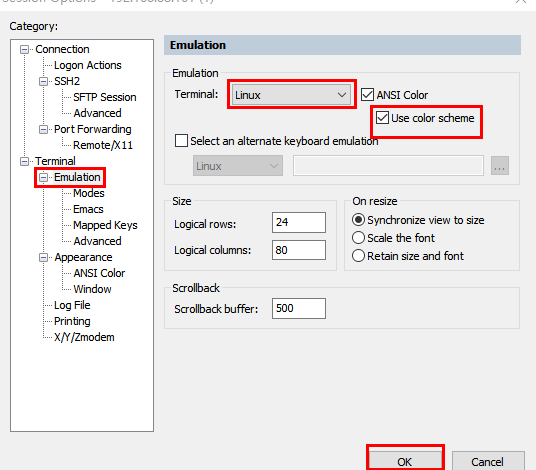
其他两台基本类似
设置主机名和域名映射
- 配置每台虚拟机主机名:
分别编辑每台虚拟机的hostname文件,直接填写主机名,保存退出即可。
| vim /etc/hostname |
|---|
第一台主机主机名为:node1.itcast.cn
第二台主机主机名为: node2.itcast.cn
第三台主机主机名为: node3.itcast.cn
- 配置每台虚拟机域名映射
分别编辑每台虚拟机的hosts文件,在原有内容的基础上,填下以下内容:
注意:不要修改文件原来的内容,三台虚拟机的配置内容都一样。
| vim /etc/hosts |
|---|
| 192.168.88.161 node1 node1.itcast.cn 192.168.88.162 node2 node2.itcast.cn 192.168.88.163 node3 node3.itcast.cn |
|---|
配置后效果如下:

关闭三台虚拟机的防火墙和Selinux
- 关闭每台虚拟机的防火墙
在每台虚拟机上分别执行以下指令:
| systemctl stop firewalld.service #停止firewall systemctl disable firewalld.service #禁止firewall开机启动 |
|---|
关闭之后,查看防火墙状态:
| systemctl status firewalld.service |
|---|

- 关闭每台虚拟机的Selinux
1)什么是SELinux ?
1)SELinux是Linux的一种安全子系统
2)Linux中的权限管理是针对于文件的, 而不是针对进程的, 也就是说, 如果root启动了某个进程, 则这个进程可以操作任何一个文件。
3)SELinux在Linux的文件权限之外, 增加了对进程的限制, 进程只能在进程允许的范围内操作资源
2)为什么要关闭SELinux
如果开启了SELinux, 需要做非常复杂的配置, 才能正常使用系统, 在学习阶段, 在非生产环境, 一般不使用SELinux
SELinux的工作模式:
enforcing 强制模式
permissive 宽容模式
disabled 关闭
- 关闭SELinux方式
编辑每台虚拟机的Selinux的配置文件
| vim **/etc/selinux/**config |
|---|
Selinux的默认工作模式是强制模式,配置如下:
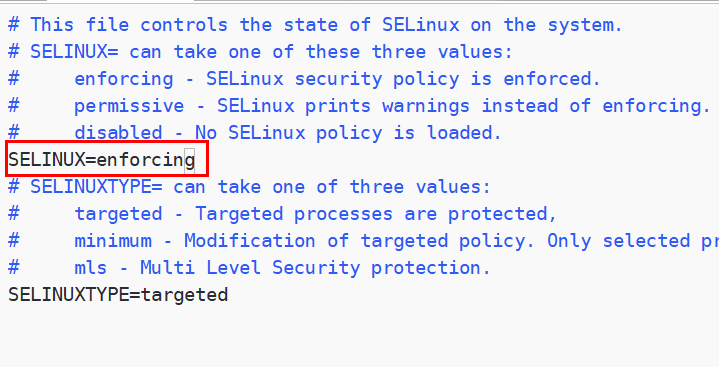
将Selinux工作模式关闭:

- 分别重启三台虚拟机
| reboot |
|---|
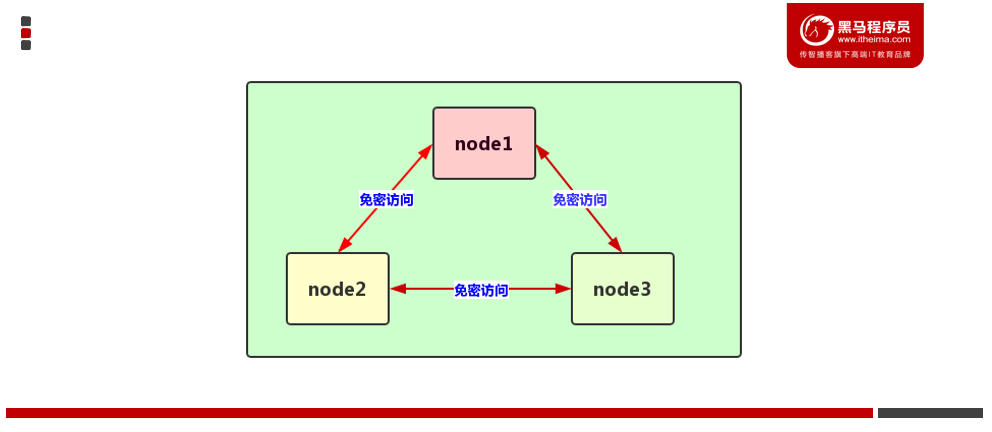
三台机器机器免密码登录
1、为什么要免密登录
Hadoop 节点众多, 所以一般在主节点启动从节点, 这个时候就需要程序自动在主节点登录到从节点中, 如果不能免密就每次都要输入密码, 非常麻烦。
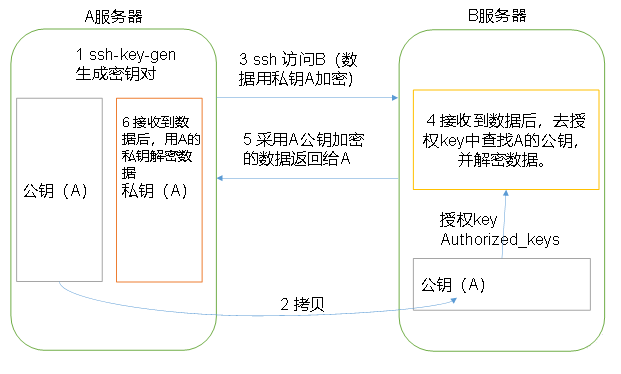
2、免密 SSH 登录的原理
1. 需要先在 B节点 配置 A节点 的公钥
2. A节点 请求 B节点 要求登录
3. B节点 使用 A节点 的公钥, 加密一段随机文本
4. A节点 使用私钥解密, 并发回给 B节点
5. B节点 验证文本是否正确
3、实现步骤
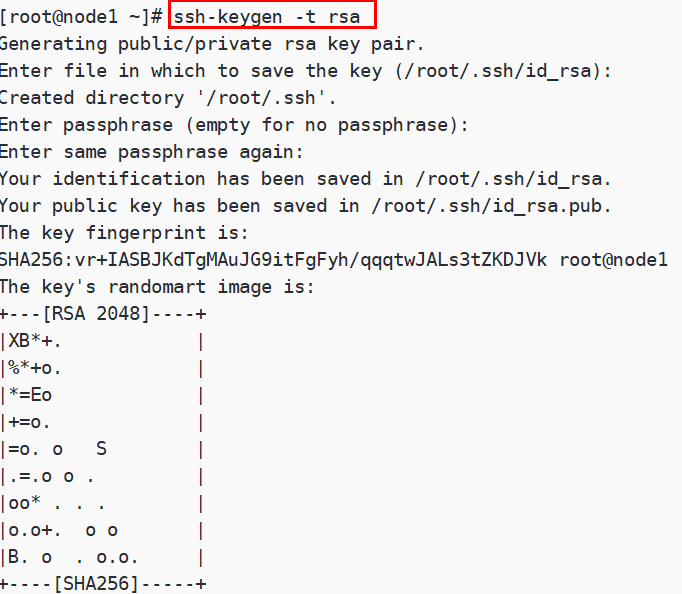
第一步:三台机器生成公钥与私钥
在三台机器执行以下命令,生成公钥与私钥
| ssh-keygen -t rsa |
|---|
执行该命令之后,按下三个回车即可,然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥),默认保存在/root/.ssh目录。
第二步:拷贝公钥到同一台机器
三台机器将拷贝公钥到第一台机器
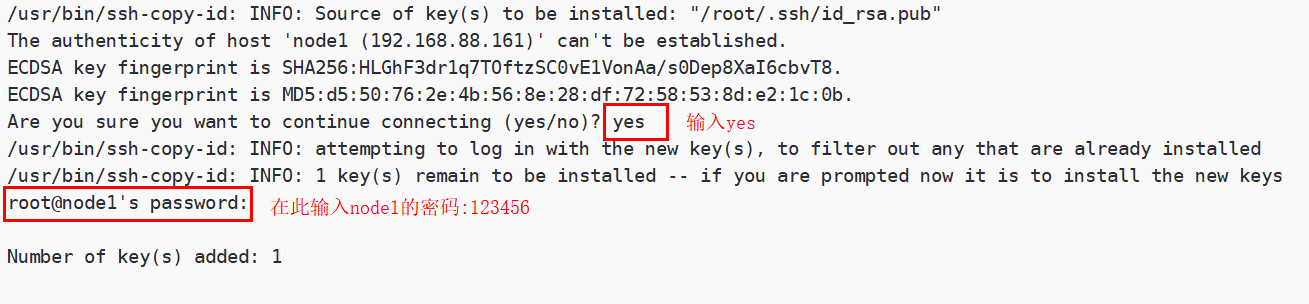
三台机器执行命令:
| ssh-copy-id node1 |
|---|
在执行该命令之后,需要输入yes和node1的密码:
第三步:复制第一台机器的认证到其他机器
将第一台机器的公钥拷贝到其他机器上
在第一台机器上指行以下命令
| scp **/root/.ssh/authorized_keys node2:/root/.**ssh scp **/root/.ssh/authorized_keys node3:/root/.**ssh |
|---|
执行命令时,需要输入yes和对方的密码
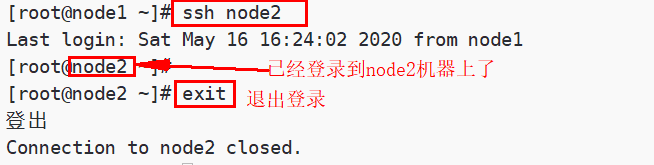
第三步:测试SSH免密登录
可以在任何一台主机上通过ssh 主机名命令去远程登录到该主机,输入exit退出登录
例如:在node1机器上,免密登录到node2机器上
| ssh node1 exit |
|---|
执行效果如下:
三台机器时钟同步
为什么需要时间同步
因为很多分布式系统是有状态的, 比如说存储一个数据, A节点 记录的时间是1, B节点 记录的时间是2, 就会出问题
时钟同步方式
方式一:通过网络进行时钟同步
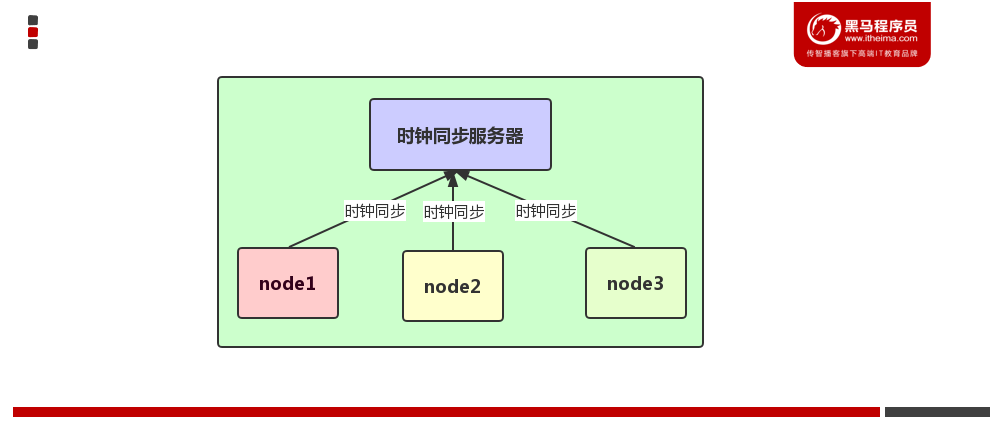
通过网络连接外网进行时钟同步,必须保证虚拟机连上外网
- 启动定时任务
| crontab -e |
|---|
随后在输入界面键入以下内容,每隔一分钟就去连接阿里云时间同步服务器,进行时钟同步
| ***/**1 * * * * /usr/sbin/ntpdate -u ntp4.aliyun.com; |
|---|
方式二:通过某一台机器进行同步
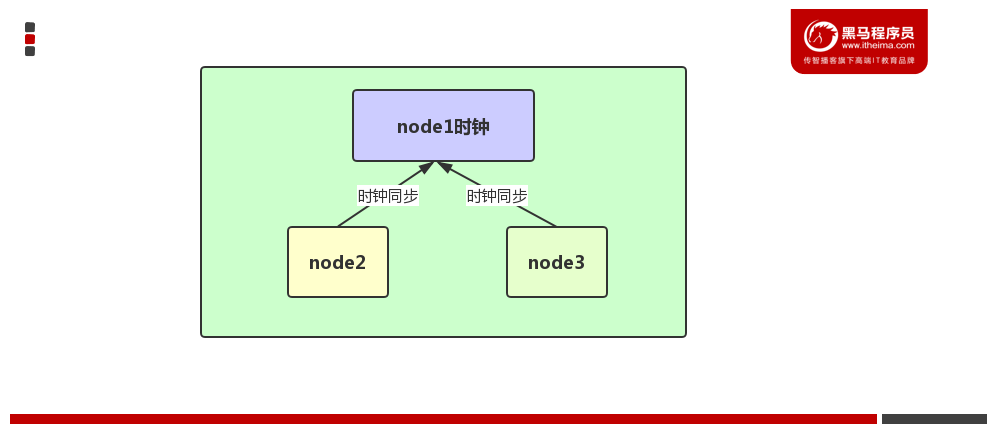
以192.168.88.161这台服务器的时间为准进行时钟同步
第一步:在node1虚拟机安装ntp并启动
安装ntp服务
| yum **-**y install ntp |
|---|
启动ntp服务
| systemctl start ntpd |
|---|
设置ntpd的服务开机启动
| #关闭chrony,Chrony是NTP的另一种实现 systemctl disable chrony #设置ntp服务为开机启动 systemctl enable ntpd |
|---|
第二步:编辑node1的/etc/ntp.conf文件
编辑node1机器的/etc/ntp.conf
| vim **/etc/**ntp.conf |
|---|
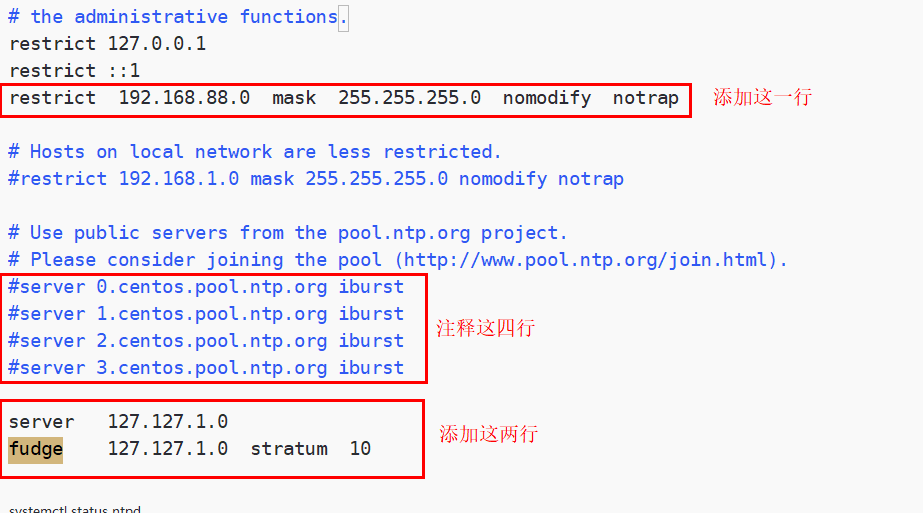
在文件中添加如下内容(授权192.168.88.0-192.168.88.255网段上的所有机器可以从这台机器上查询和同步时间)
| restrict 192**.168.88.0 mask 255.255.255.**0 nomodify notrap |
|---|
注释一下四行内容:(集群在局域网中,不使用其他互联网上的时间)
| #server 0.centos.pool.ntp.org #server 1.centos.pool.ntp.org #server 2.centos.pool.ntp.org #server 3.centos.pool.ntp.org |
|---|
去掉以下内容的注释,如果没有这两行注释,那就自己添加上(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
| server 127.127.1.0 fudge 127.127.1.0 stratum 10 |
|---|
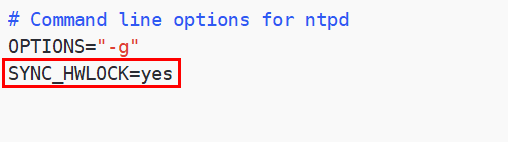
配置以下内容,保证BIOS与系统时间同步
| vim **/etc/sysconfig/**ntpd |
|---|
添加一行内容
| SYNC_HWLOCK=yes |
|---|
重启ntp服务
| systemctl restart ntpd |
|---|
第三步:另外两台机器与第一台机器时间同步
另外两台机器与192.168.88.161进行时钟同步,在node2和node3机器上分别进行以下操作
| crontab -e |
|---|
添加以下内容:(每隔一分钟与node1进行时钟同步)
| */1 * * * * /usr/sbin/ntpdate 192.168.88.161 |
|---|
虚拟机软件安装
Linux上安装MySQL(node1)
注:需要连接互联网,在线 mysql 的安装包,5.6 的版本大约 86M , 仅需在node1安装即可
MySQL在线下载安装

- 查看 CentOS 是否自带的 MySQL,如果已经安装需要卸载。如果没有找到,则表示没有安装。

如果查询到有内容: 使用 rpm -e –nodeps 要卸载名称
例如:
rpm -e –nodeps mysql-libs-5.1.73-8.el6_8.x86_64
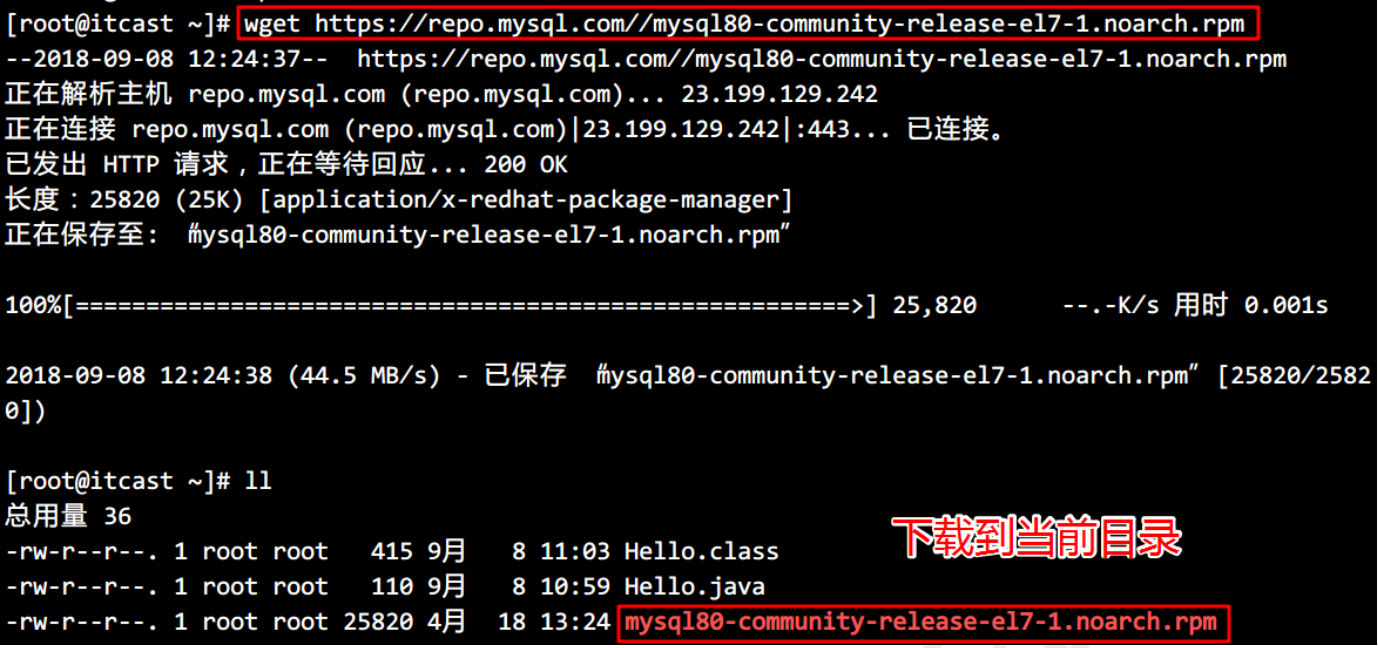
- 在线获取 CentOS7 的 mysql 的 rpm 安装文件,直接执行如下命令:
wget https://repo.mysql.com//mysql80-community-release-el7-1.noarch.rpm
这条语句只是下载了一个 rpm 文件,25K 大小
- 执行安装命令:
| rpm -ivh mysql80-community-release-el7-1.noarch.rpm |
|---|

- 得到两个配置文件,在/etc/yum.repos.d 目录下。
4.1) mysql-community.repo 用于指定下载哪个版本的安装包
4.2) mysql-community-source.repo 用于指定下载哪个版本的源码
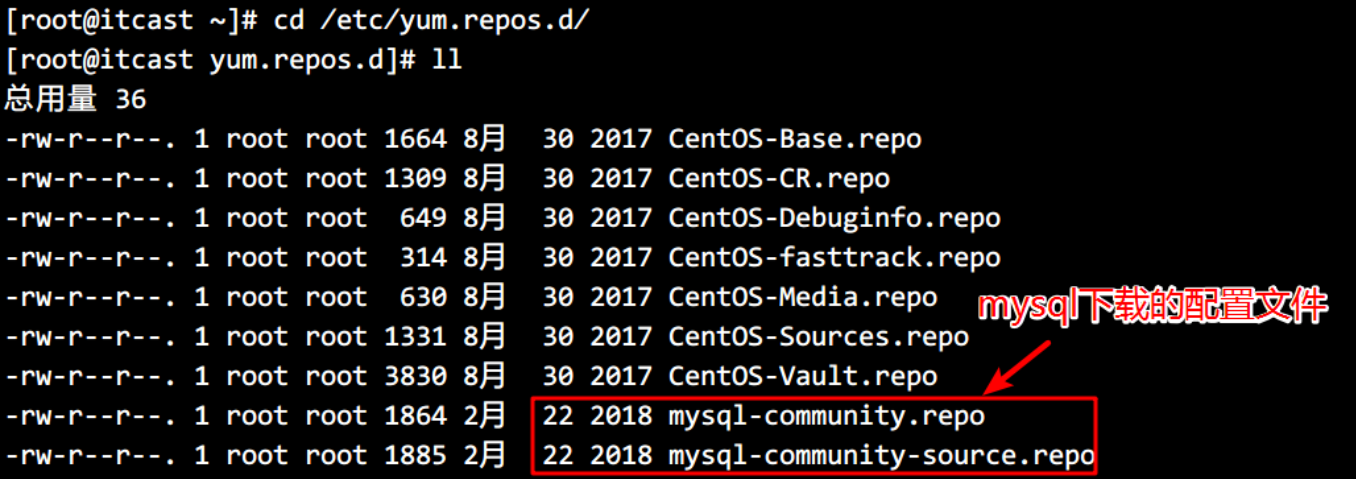
- 修改 MySQL 的下载配置文件
进入目录命令:
| cd /etc/yum.repos.d |
|---|
编辑配置文件命令:
| vim mysql-community.repo |
|---|
我们下载 MySQL 5.6,把 5.6 下的 enabled 设置为 1,表示下载。

把 MySQL8 的下载关闭,将 enabled 设置为 0
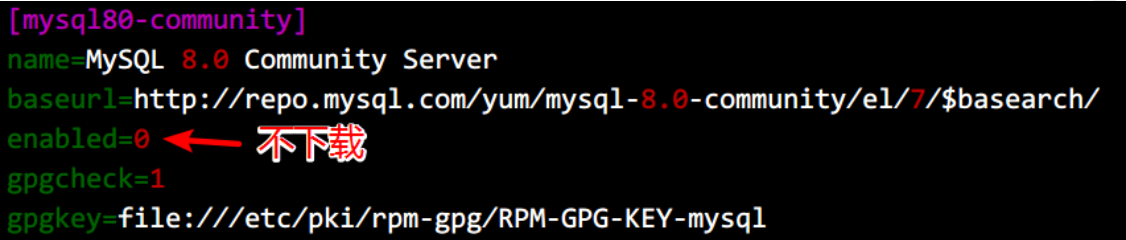
保存修改退出。
- 在当前目录/etc/yum.repos.d 下执行下面的命令,开始在线下载:客户端,服务器端,开发的工具包。
在线下载安装命令介绍:yum(全称为 Yellow dog Updater, Modified)
作用:用于自动从服务器上下载相应 的软件包,自动安装,并且自动下载它的依赖包。
yum( Yellow dog Updater, Modified)是一个基于 RPM 包管理,能够从指定的服务器自动下载 RPM 包并且 安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载、安装。
语法说明

进行在线下载安装 mysql 命令
yum -y install mysql-community-client mysql-community-server mysql-community-devel
这里需要比较长的时间,要从互联网上下载 86M 左右的内容
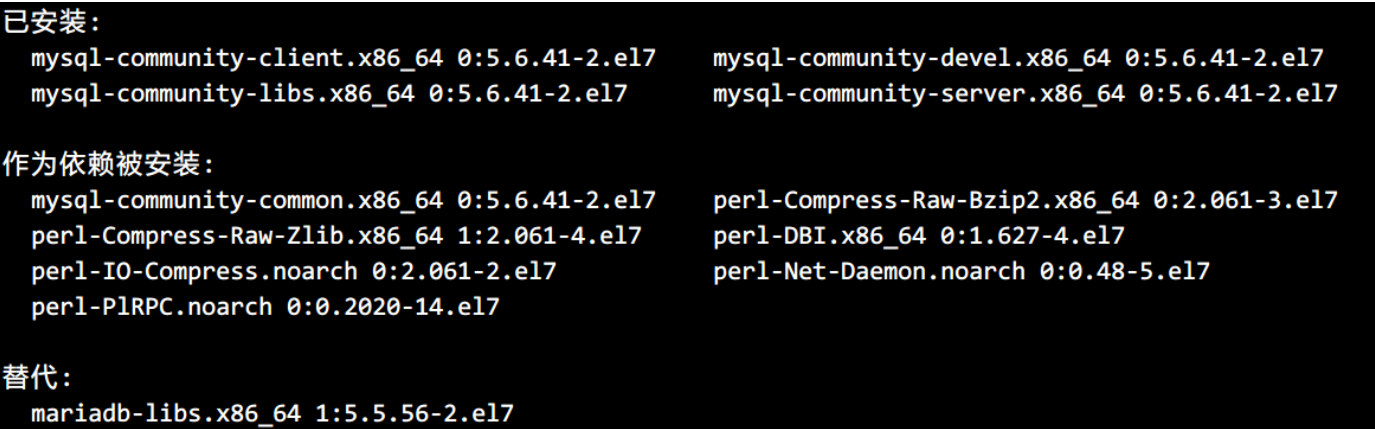
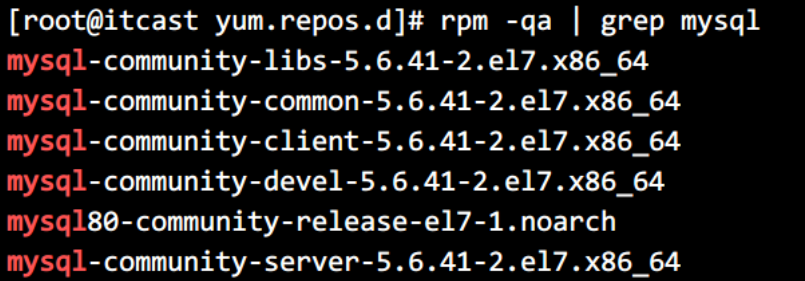
- 使用 rpm 命令,可以查询到 mysql 已经安装好的包
启动MySQL服务并登陆
- 启动 mysql 的服务
| systemctl start mysqld |
|---|
- 将 mysql 加到系统服务中并设置开机启动
| systemctl enable mysqld |
|---|
- 登录 mysql,root 用户默认没有密码
| mysql -uroot |
|---|
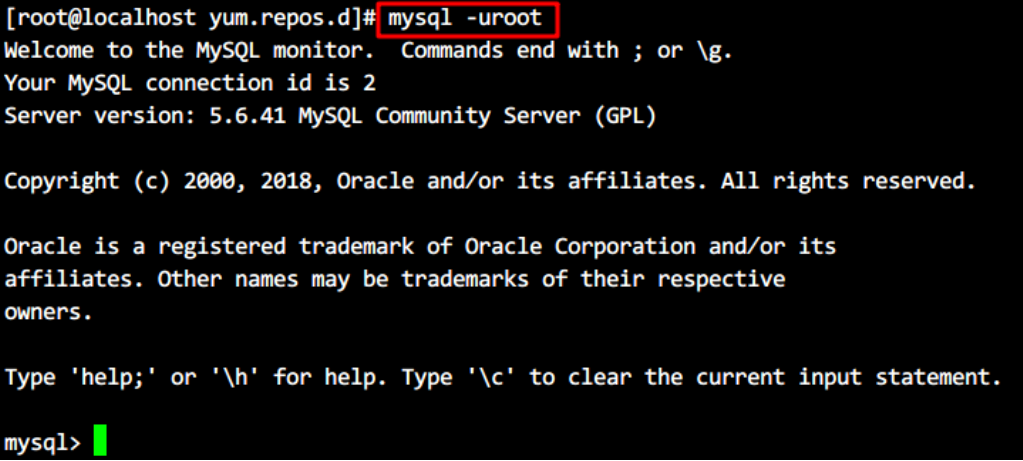
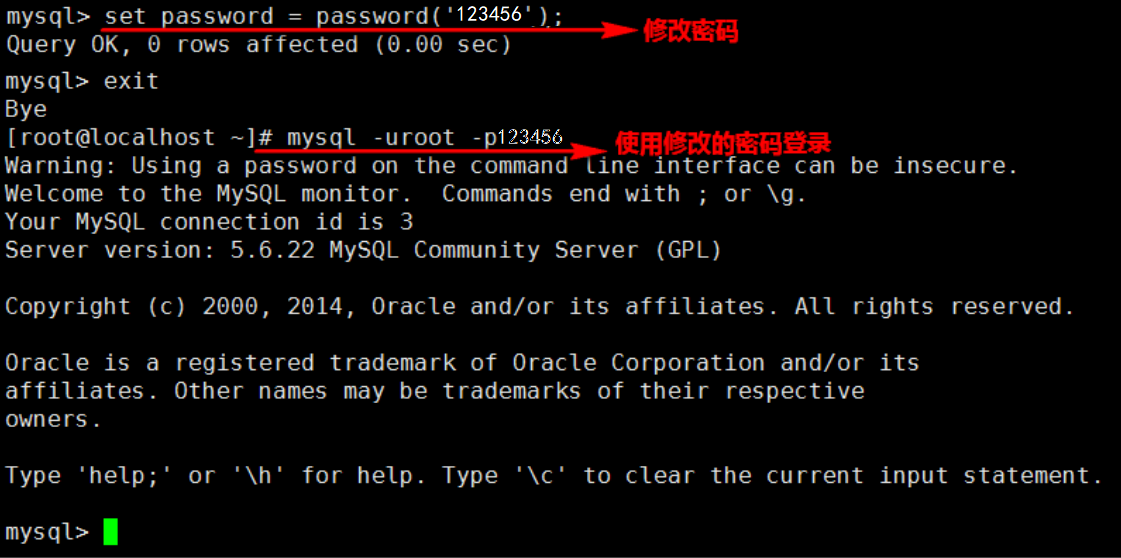
- 在 mysql 中修改自己的密码 : 此处设置为 123456
| set password = password(‘123456’); |
|---|
设置远程访问权限
- 开启 mysql 的远程登录权限,默认情况下 mysql 为安全起见,不支持远程登录 mysql,所以需要设置开启,并且刷新权限缓存。远程登录 mysql 的权限登录 mysql 后输入如下命令:
| grant all privileges on *.* to ‘root‘@’%’ identified by ‘123456’; flush privileges; |
|---|

- 确保防火墙已关闭

客户端windows连接linux中mysql
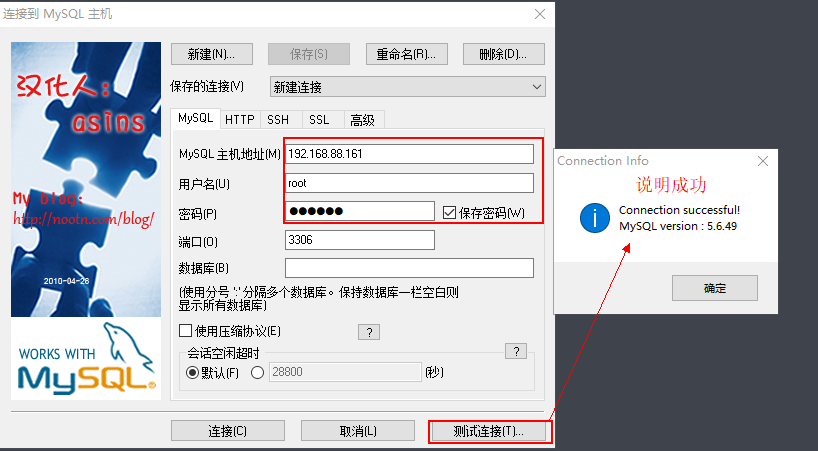
到此mysql安装全部结束
注意:如果希望删除卸载 mysql 执行如下命令
| yum -y remove mysql-community-client mysql-community-server mysql-community-devel |
|---|
JDK安装(所有节点安装)
JDK 是个绿色软件,解压并且配置环境变量即可使用, 三个节点都需要安装的
JDK安装步骤
- 在虚拟机中创建两个目录
| mkdir -p /export/software 软件包放置的目录 mkdir -p /export/server 软件安装的目录 |
|---|
进入 /export/software 目录, 上传jdk的安装包: jdk-8u241-linux-x64.tar.gz
解压压缩包到/export/server目录下
| tar -zxvf jdk-8u241-linux-x64.tar.gz -C /export/server |
|---|
查看解压后的目录,目录中有 jdk1.8.0_144 为 jdk 解压的目录
- 配置 jdk 环境变量,打开/etc/profile 配置文件,将下面配置拷贝进去。export 命令用于将 shell 变量输出为环境变量
| 第一步: vi /etc/profile 第二步: 通过键盘上下键 将光标拉倒最后面 第三步: 然后输入 i, 将一下内容输入即可 #set java environment JAVA_HOME=/export/server/jdk1.8.0_65 CLASSPATH=.:$JAVA_HOME/lib PATH=$JAVA_HOME/bin:$PATH export JAVA_HOME CLASSPATH PATH 第四步: esc键 然后 :wq 保存退出即可 |
|---|
- 重新加载环境变量:
| source /etc/profile |
|---|

- 配置jdk是否安装成功
| java -version |
|---|

- 将jdk分发给node2和node3
| cd /export/server/ scp -r jdk1.8.0_65/ node2:$PWD scp -r jdk1.8.0_65/ node3:$PWD |
|---|
- 在node2和node3配置jdk的环境变量
| scp -r /etc/profile node2:/etc/ scp -r /etc/profile node3:/etc/ 分别在node2和node3重新加载环境变量 source /etc/profile |
|---|
- 测试node2和node3 是否安装成功


六、Zookeeper集群安装
Zookeeper集群搭建指的是ZooKeeper分布式模式安装。通常由2n+1台server组成。这是因为为了保证Leader选举(基于Paxos算法的实现)能过得到多数的支持,所以ZooKeeper集群的数量一般为奇数。
Zookeeper运行需要java环境,所以需要提前安装jdk。对于安装leader+follower模式的集群,大致过程如下:
- 配置主机名称到IP地址映射配置
- 修改ZooKeeper配置文件
- 远程复制分发安装文件
- 设置myid
- 启动ZooKeeper集群
如果要想使用Observer模式,可在对应节点的配置文件添加如下配置:
peerType=observer
其次,必须在配置文件指定哪些节点被指定为Observer,如:
server.1:node1:2181:3181:observer
这里,我们安装的是leader+follower模式
| 服务器IP | 主机名 | myid的值 |
|---|---|---|
| 192.168.88.161 | node1 | 1 |
| 192.168.88.162 | node2 | 2 |
| 192.168.88.163 | node3 | 3 |
第一步:下载zookeeeper的压缩包,下载网址如下
http://archive.apache.org/dist/zookeeper/
我们在这个网址下载我们使用的zk版本为3.4.6
下载完成之后,上传到我们的linux的/export/software路径下准备进行安装
第二步:解压
在node1主机上,解压zookeeper的压缩包到/export/server路径下去,然后准备进行安装
| cd **/export/**software tar **-**zxvf zookeeper.tar.gz -C /export/server/ cd /export/server/ ln -s zookeeper/ zookeeper |
|---|
第三步:修改配置文件
在node1主机上,修改配置文件
| cd /export/server/zookeeper/conf/ cp zoo_sample.cfg zoo.cfg mkdir -p /export/server/zookeeper/zkdatas/ vim zoo.cfg |
|---|
修改以下内容
| #Zookeeper的数据存放目录 dataDir**=/export/server/zookeeper/zkdatas # 保留多少个快照 autopurge.snapRetainCount=3 # 日志多少小时清理一次 autopurge.purgeInterval=1 # 集群中服务器地址 server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:**3888 |
|---|
第四步:添加myid配置
在node1主机的/export/server/zookeeper/zkdatas/这个路径下创建一个文件,文件名为myid ,文件内容为1
| echo 1 > **/export/server/zookeeper/zkdatas/**myid |
|---|
第五步:安装包分发并修改myid的值
在node1主机上,将安装包分发到其他机器
第一台机器上面执行以下两个命令
| cd /export/server/ scp -r /export/server/zookeeper-3.4.6/ node2:$PWD scp -r /export/server/zookeeper-3.4.6/ node3:$PWD |
|---|
第二台机器上建立软连接, 并修改myid的值为2
| cd /export/server/ ln -s zookeeper-3.4.6/ zookeeper echo 2 > **/export/server/zookeeper/zkdatas/**myid |
|---|
第三台机器上建立软连接, 并修改myid的值为3
| cd /export/server/ ln -s zookeeper-3.4.6/ zookeeper echo 3 > **/export/server/zookeeper/zkdatas/**myid |
|---|
第六步:三台机器启动zookeeper服务
三台机器分别启动zookeeper服务
这个命令三台机器都要执行
| **/export/server/zookeeper/bin/**zkServer.sh start |
|---|



三台主机分别查看启动状态
| **/export/server/zookeeper/bin/**zkServer.sh status |
|---|



七、hadoop集群搭建
上传重编译后的hadoop包并解压
| cd /export/software/ rz 上传 解压操作 tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -C /export/server/ 添加软连接: cd /export/server/ ln -s hadoop-3.3.0/ hadoop |
|---|
Hadoop安装包目录结构
解压hadoop-3.3.0-Centos7-64-with-snappy.tar.gz,目录结构如下:
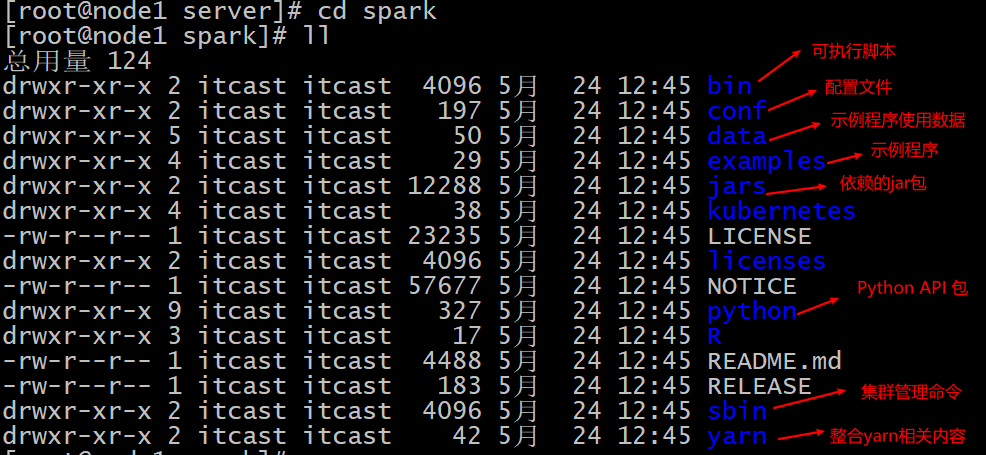
bin:Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。
etc:Hadoop配置文件所在的目录,包括core-site,xml、hdfs-site.xml、mapred-site.xml等从Hadoop1.0继承而来的配置文件和yarn-site.xml等Hadoop2.0新增的配置文件。
include:对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。
lib:该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。
libexec:各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。
sbin:Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
share:Hadoop各个模块编译后的jar包所在的目录,官方自带示例。
Hadoop配置文件修改
Hadoop安装主要就是配置文件的修改,一般在主节点进行修改,完毕后scp下发给其他各个从节点机器。
hadoop-env.sh
文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
| cd /export/server/hadoop/etc/hadoop/ vim hadoop-env.sh 添加: 在54行 export JAVA_HOME=/export/server/jdk1.8.0_241/ #文件最后添加: 在第 439行下 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |
|---|
core-site.xml
hadoop的核心配置文件,有默认的配置项core-default.xml。
core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
| cd /export/server/hadoop/etc/hadoop/ vim core-site.xml 在文件的configuration的标签中添加以下内容: <property> <name>fs.defaultFS</name> <value>hdfs://node1.itcast.cn:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop</value> </property> <!– 设置HDFS web UI用户身份 –> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!– 整合hive –> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> |
|---|
hdfs-site.xml
HDFS的核心配置文件,有默认的配置项hdfs-default.xml。
hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
| cd /export/server/hadoop/etc/hadoop/ vim hdfs-site.xml 在文件的configuration的标签中添加以下内容: <!– 指定secondarynamenode运行位置 –> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2.itcast.cn:50090</value> </property> |
|---|
mapred-site.xml
MapReduce的核心配置文件,有默认的配置项mapred-default.xml。
mapred-default.xml与mapred-site.xml的功能是一样的,如果在mapred-site.xml里没有配置的属性,则会自动会获取mapred-default.xml里的相同属性的值。
| cd /export/server/hadoop/etc/hadoop/ vim mapred-site.xml 在文件的configuration的标签中添加以下内容: <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> |
|---|
yarn-site.xml
YARN的核心配置文件,有默认的配置项yarn-default.xml。
yarn-default.xml与yarn-site.xml的功能是一样的,如果在yarn-site.xml里没有配置的属性,则会自动会获取yarn-default.xml里的相同属性的值。
| cd /export/server/hadoop/etc/hadoop/ vim yarn-site.xml 在文件的configuration的标签中添加以下内容: <!– 指定YARN的主角色(ResourceManager)的地址 –> <property> <name>yarn.resourcemanager.hostname</name> <value>node1.itcast.cn</value> </property> <!– NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:”” –> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!– 是否将对容器实施物理内存限制 –> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!– 是否将对容器实施虚拟内存限制。 –> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!– 开启日志聚集 –> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!– 设置yarn历史服务器地址 –> <property> <name>yarn.log.server.url</name> <value>http://node1.itcast.cn:19888/jobhistory/logs\</value> </property> <!– 保存的时间7天 –> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> |
|---|
workers
workers文件里面记录的是集群主机名。主要作用是配合一键启动脚本如start-dfs.sh、stop-yarn.sh用来进行集群启动。这时候workers文件里面的主机标记的就是从节点角色所在的机器。
| vim workers 清空内容后, 添加以下内容: node1.itcast.cn node2.itcast.cn node3.itcast.cn |
|---|
scp同步安装包
| cd /export/server scp -r hadoop-3.3.0/ node2:$PWD scp -r hadoop-3.3.0/ node3:$PWD 分发后, 需要在node2和node3上分别创建软连接 cd /export/server/ ln -s hadoop-3.3.0/ hadoop |
|---|
在node1上进行了配置文件的修改,使用scp命令将修改好之后的安装包同步给集群中的其他节点。
Hadoop环境变量
3台机器都需要配置环境变量文件。
| vim /etc/profile #HADOOP_HOME export HADOOP_HOME=/export/server/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile |
|---|
Hadoop集群启动、初体验
启动方式
要启动Hadoop集群,需要启动HDFS和YARN两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。
hadoop namenode -format
单节点逐个启动
在主节点上使用以下命令启动HDFS NameNode:
$HADOOP_HOME/bin/hdfs –daemon start namenode
在每个从节点上使用以下命令启动HDFS DataNode:
$HADOOP_HOME/bin/hdfs –daemon start datanode
在node2上使用以下命令启动HDFS SecondaryNameNode:
$HADOOP_HOME/bin/hdfs –daemon start secondarynamenode
在主节点上使用以下命令启动YARN ResourceManager:
$HADOOP_HOME/bin/yarn –daemon start resourcemanager
在每个从节点上使用以下命令启动YARN nodemanager:
$HADOOP_HOME/bin/yarn –daemon start nodemanager
如果想要停止某个节点上某个角色,只需要把命令中的start改为stop即可。
脚本一键启动
如果配置了etc/hadoop/workers和ssh免密登录,则可以使用程序脚本启动所有Hadoop两个集群的相关进程,在主节点所设定的机器上执行。
hdfs:$HADOOP_PREFIX/sbin/start-dfs.sh
yarn: $HADOOP_PREFIX/sbin/start-yarn.sh
停止集群:stop-dfs.sh、stop-yarn.sh
同时还提供了完整的一键化脚本:
start-all.sh 和 stop-all.sh
启动后的效果
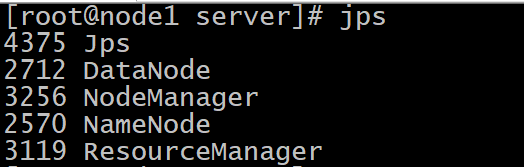
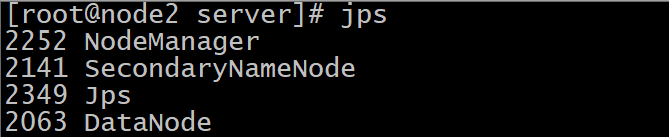
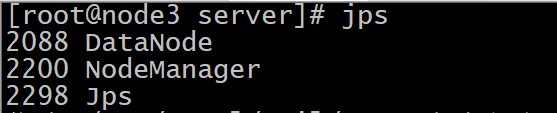
集群web-ui
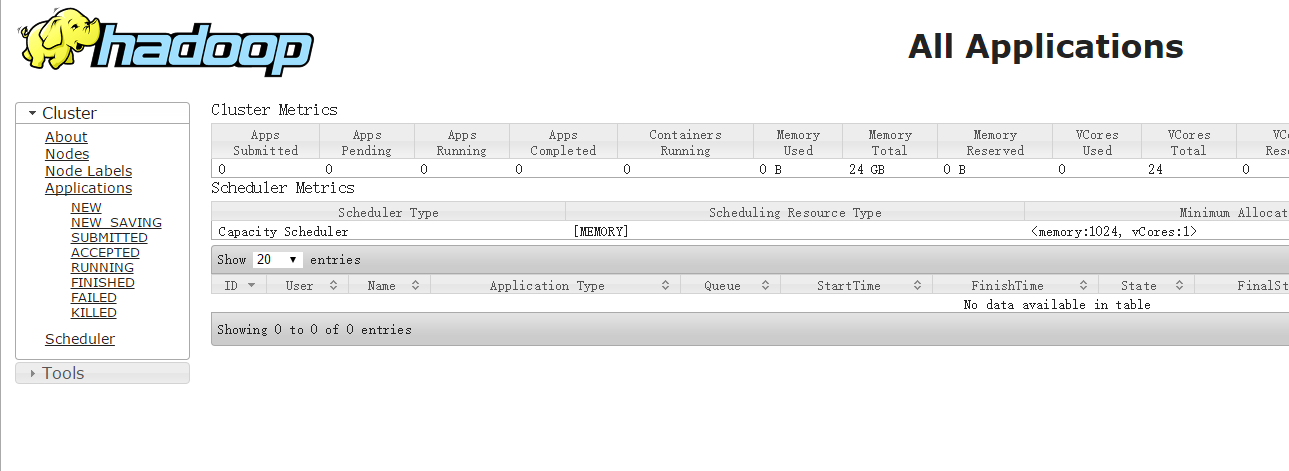
一旦Hadoop集群启动并运行,可以通过web-ui进行集群查看,如下所述:
NameNode http://nn_host:port/ 默认9870.
ResourceManager http://rm_host:port/ 默认 8088.
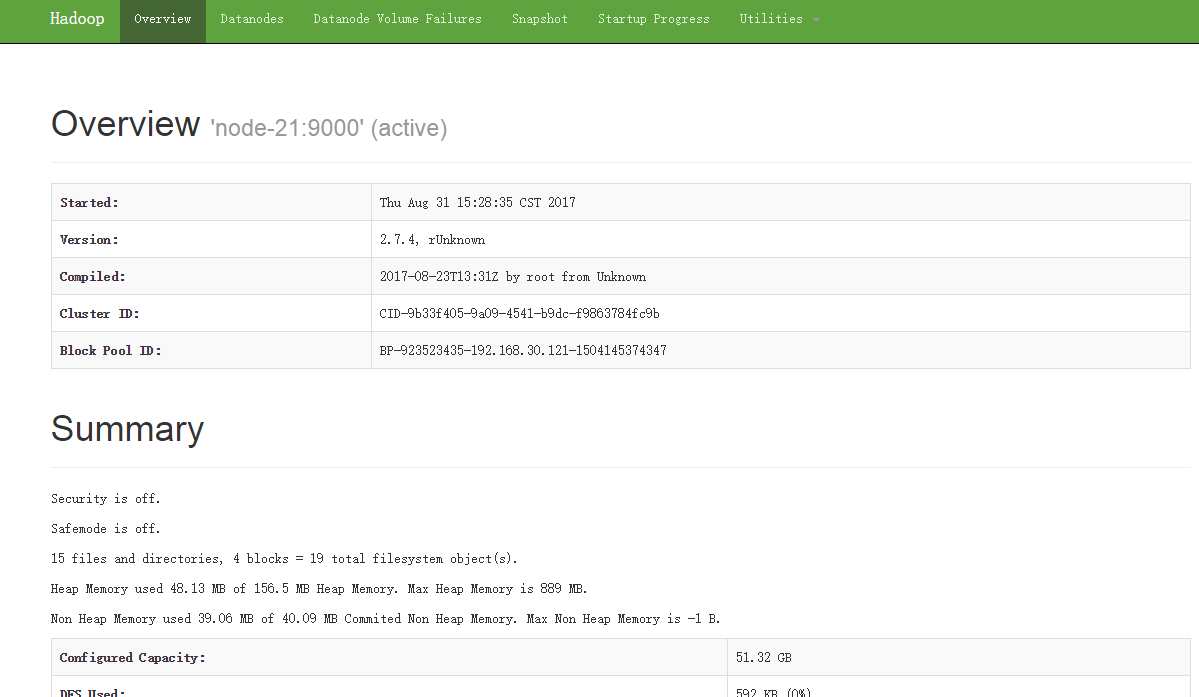
MapReduce jobHistory
JobHistory用来记录已经finished的mapreduce运行日志,日志信息存放于HDFS目录中,默认情况下没有开启此功能,需要在mapred-site.xml中配置并手动启动。
修改mapred-site.xml
cd /export/servers/hadoop-3.3.0/etc/hadoop
vim mapred-site.xml
MR JobHistory Server管理的日志的存放位置
| <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> |
|---|
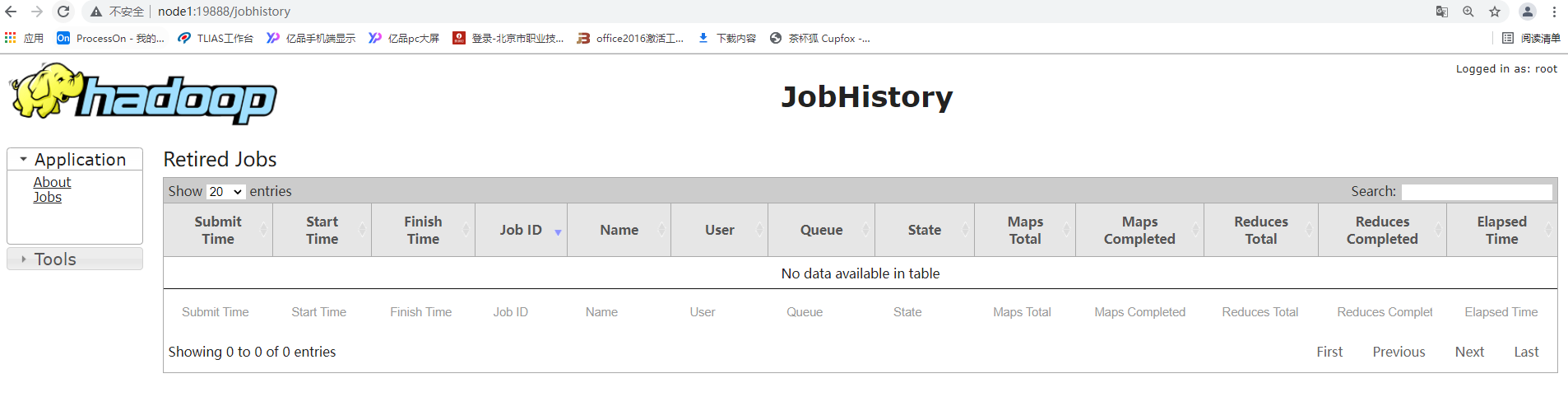
查看历史服务器已经运行完的Mapreduce作业记录的web地址,需要启动该服务才行
| <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> |
|---|
分发配置到其他机器
cd /export/servers/hadoop/etc/hadoop
scp -r mapred-site.xml node2:$PWD
scp –r mapred-site.xml node3:$PWD
启动jobHistoryServer服务进程
mapred –daemon start historyserver
如果关闭的话 用下述命令
mapred –daemon stop historyserver
页面访问jobhistoryserver
八、Hive安装操作
Hive metastore远程模式安装部署
课程中采用远程模式部署hive的metastore服务。在node1机器上安装。
注意:以下两件事在启动hive之前必须确保正常完成。
- 选择某台机器提前安装mysql,确保具有远程访问的权限。
- 启动hadoop集群 确保集群正常健康
Hadoop中添加用户代理配置
| #修改hadoop 配置文件 etc/hadoop/core-site.xml,加入如下配置项 <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> |
|---|
上传安装包 并解压
| tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /export/server/ cd /export/server/ ln -s apache-hive-3.1.2-bin/ hive # 解决Hive与Hadoop之间guava版本差异 cd /export/server/hive/ rm -rf lib/guava-19.0.jar cp /export/server/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar lib/ |
|---|
修改配置文件hive-env.sh
| cd /export/server/hive/conf cp hive-env.sh.template hive-env.sh vim hive-env.sh # 修改一下几处内容: 第48行 export HADOOP_HOME=/export/server/hadoop export HIVE_CONF_DIR=/export/server/hive/conf export HIVE_AUX_JARS_PATH=/export/server/hive/conf/lib |
|---|
添加配置文件hive-site.xml
| vim hive-site.xml 添加以下内容: <configuration> <!– 存储元数据mysql相关配置 –> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1.itcast.cn:3306/hive3?createDatabaseIfNotExist=true&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!– H2S运行绑定host –> <property> <name>hive.server2.thrift.bind.host</name> <value>node1.itcast.cn</value> </property> <!– 远程模式部署metastore metastore地址 –> <property> <name>hive.metastore.uris</name> <value>thrift://node1.itcast.cn:9083</value> </property> <!– 关闭元数据存储授权 –> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> </configuration> |
|---|
上传MySQL驱动
| #上传mysql jdbc驱动到hive安装包lib下 mysql-connector-java-5.1.32.jar |
|---|
初始化元数据
| cd /export/server/hive/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表 |
|---|
创建hive存储目录
| hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse |
|---|
metastore 的启动方式
| cd /export/server/hive #前台启动 关闭ctrl+c ./bin/hive –service metastore #前台启动开启debug日志 ./bin/hive –service metastore –hiveconf hive.root.logger=DEBUG,console #后台启动 进程挂起 关闭使用jps+ kill -9 nohup ./bin/hive –service metastore & nohup ./bin/hive –service hiveserver2 & |
|---|
Hive Client、Beeline Client
第一代客户端Hive Client
在hive安装包的bin目录下,有hive提供的第一代客户端 bin/hive。使用该客户端可以访问hive的metastore服务。从而达到操作hive的目的。
使用下面的命令启动hive的客户端:
/export/server/hive/bin/hive
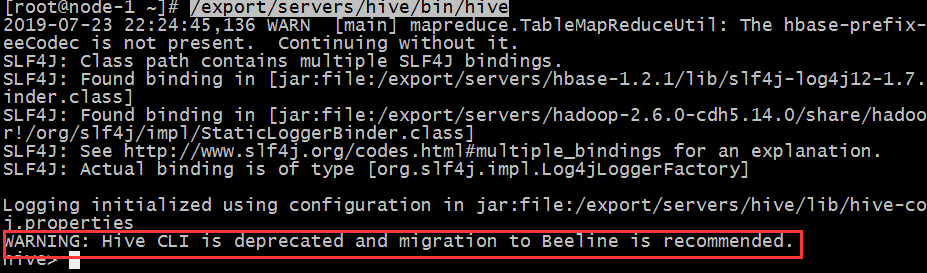
可以发现官方提示:第一代客户端已经不推荐使用了。
第二代客户端Hive Beeline Client
hive经过发展,推出了第二代客户端beeline,但是beeline客户端不是直接访问metastore服务的,而是需要单独启动hiveserver2服务。
在hive运行的服务器上,首先启动metastore服务,然后启动hiveserver2服务。
nohup /export/server/hive/bin/hive –service metastore &
nohup /export/server/hive/bin/hive –service hiveserver2 &
使用beeline客户端进行连接访问。
/export/server/hive/bin/beeline
beeline> ! connect jdbc:hive1://node1:10000
Enter username for jdbc:hive1://node1:10000: root
Enter password for jdbc:hive1://node1:10000: *******(任意)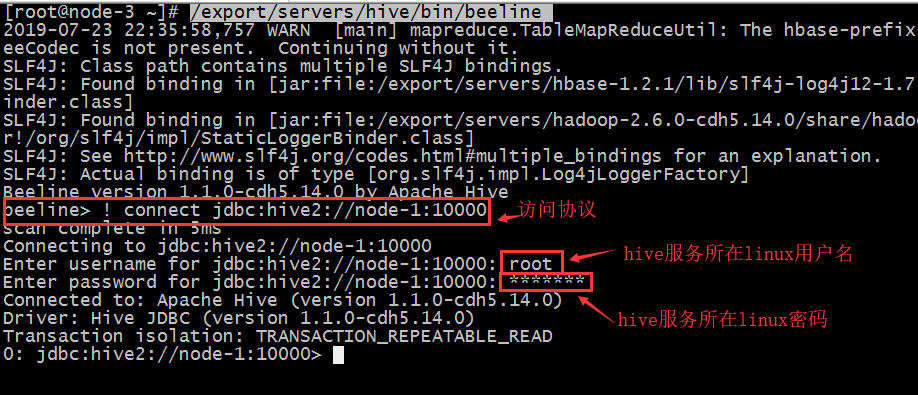
说明: 在其他的节点想要连接hive, 只需要有hive的beeline的客户端即可
九、Spark部署安装
Spark Local 模式搭建文档
在本地使用单机多线程模拟Spark集群中的各个角色
安装包下载
目前Spark最新稳定版本:目前Spark最新稳定版本:3.1.x系列
https://spark.apache.org/docs/3.1.2/index.html
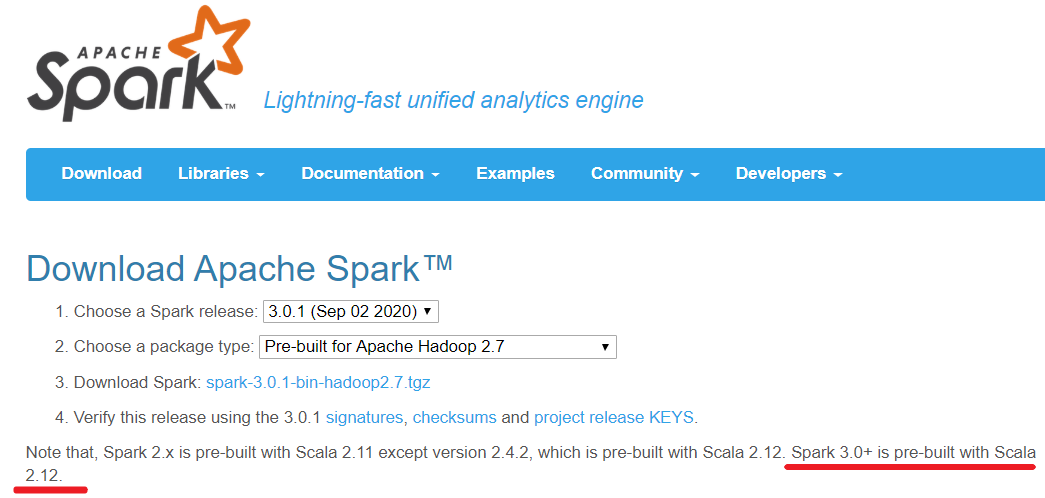
★注意1:
Spark3.0+基于Scala2.12
http://spark.apache.org/downloads.html
★注意2:
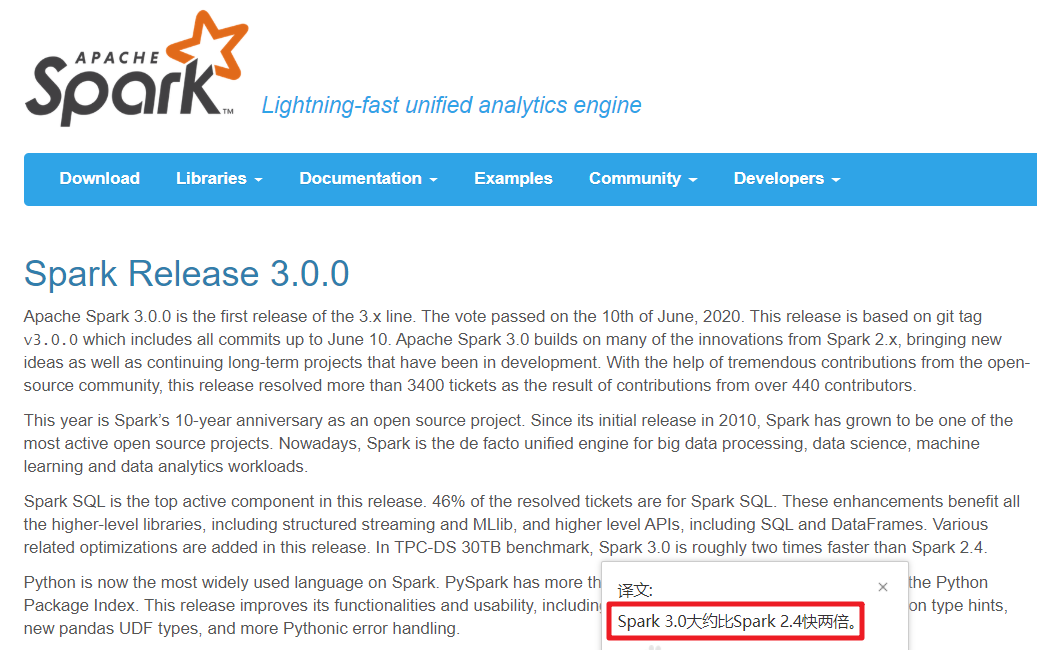
目前企业中使用较多的Spark版本还是Spark2.x,如Spark2.2.0、Spark2.4.5都使用较多,但未来Spark3.X肯定是主流,毕竟官方高版本是对低版本的兼容以及提升
http://spark.apache.org/releases/spark-release-3-0-0.html
将安装包上传并解压
说明: 只需要上传至node1即可, 以下操作都是在node1执行的
cd /export/software rz 上传  解压: tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server/ 解压: tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server/  更名: (两种方式二选一即可, 推荐软连接方案) cd /export/server 方式一: 软连接方案: ln -s spark-3.1.2-bin-hadoop3.2 spark 方式二: 直接重命名: mv spark-3.1.2-bin-hadoop3.2 spark 更名: (两种方式二选一即可, 推荐软连接方案) cd /export/server 方式一: 软连接方案: ln -s spark-3.1.2-bin-hadoop3.2 spark 方式二: 直接重命名: mv spark-3.1.2-bin-hadoop3.2 spark  |
|---|
目录结构说明:
测试
Spark的local模式, 开箱即用, 直接启动bin目录下的spark-shell脚本
| cd /export/server/spark/bin ./spark-shell |
|---|
说明:
sc:SparkContext实例对象:
spark:SparkSession实例对象
4040:Web监控页面端口号

●Spark-shell说明:
1.直接使用./spark-shell
表示使用local 模式启动,在本机启动一个SparkSubmit进程
2.还可指定参数 –master,如:
spark-shell –master local[N] 表示在本地模拟N个线程来运行当前任务
spark-shell –master local[*] 表示使用当前机器上所有可用的资源
3.不携带参数默认就是
spark-shell –master local[*]
4.后续还可以使用–master指定集群地址,表示把任务提交到集群上运行,如
./spark-shell –master spark://node01:7077,node02:7077
5.退出spark-shell
使用 :quit
PySpark环境安装
同学们可能有疑问, 我们不是学的Spark框架吗? 怎么会安装一个叫做PySpark呢?
这里简单说明一下:
PySpark: 是Python的库, 由Spark官方提供. 专供Python语言使用. 类似Pandas一样,是一个库
Spark: 是一个独立的框架, 包含PySpark的全部功能, 除此之外, Spark框架还包含了对R语言\ Java语言\ Scala语言的支持. 功能更全. 可以认为是通用Spark。
| 功能 | PySpark | Spark |
|---|---|---|
| 底层语言 | Scala(JVM) | Scala(JVM) |
| 上层语言支持 | Python | Python\Java\Scala\R |
| 集群化\分布式运行 | 支持 | 支持 |
| 定位 | Python库 (客户端) | 标准框架 (客户端和服务端) |
| 是否可以Daemon运行 | No | Yes |
| 使用场景 | 生产环境集群化运行 | 生产环境集群化运行 |
若安装PySpark需要首先具备Python环境,这里使用Anaconda环境,安装过程如下:
下载Anaconda环境包
安装版本:https://www.anaconda.com/distribution/#download-section
Python3.8.8版本:Anaconda3-2021.05-Linux-x86_64.sh
安装Anaconda环境
此环境三台节点都是需要安装的, 以下演示在node1安装, 其余两台也是需要安装的
cd /export/software rz 上传Anaconda脚本环境  执行脚本: bash Anaconda3-2021.05-Linux-x86_64.sh 执行脚本: bash Anaconda3-2021.05-Linux-x86_64.sh  不断输入空格, 直至出现以下解压, 然后输入yes 不断输入空格, 直至出现以下解压, 然后输入yes  此时, anaconda需要下载相关的依赖包, 时间比较长, 耐心等待即可…. 此时, anaconda需要下载相关的依赖包, 时间比较长, 耐心等待即可….  配置anaconda的环境变量: vim /etc/profile ##增加如下配置 export ANACONDA_HOME=/root/anaconda3/bin export PATH=$PATH:$ANACONDA_HOME/bin 重新加载环境变量: source /etc/profile 修改bashrc文件 sudo vim ~/.bashrc 添加如下内容: 直接在第二行空行添加即可 export PATH=~/anaconda3/bin:$PATH 配置anaconda的环境变量: vim /etc/profile ##增加如下配置 export ANACONDA_HOME=/root/anaconda3/bin export PATH=$PATH:$ANACONDA_HOME/bin 重新加载环境变量: source /etc/profile 修改bashrc文件 sudo vim ~/.bashrc 添加如下内容: 直接在第二行空行添加即可 export PATH=~/anaconda3/bin:$PATH |
|---|
说明:
| profile 其实看名字就能了解大概了, profile 是某个用户唯一的用来设置环境变量的地方, 因为用户可以有多个 shell 比如 bash, sh, zsh 之类的, 但像环境变量这种其实只需要在统一的一个地方初始化就可以了, 而这就是 profile. bashrc bashrc 也是看名字就知道, 是专门用来给 bash 做初始化的比如用来初始化 bash 的设置, bash 的代码补全, bash 的别名, bash 的颜色. 以此类推也就还会有 shrc, zshrc 这样的文件存在了, 只是 bash 太常用了而已. |
|---|
启动anaconda并测试
注意: 请将当前连接node1的节点窗口关闭,然后重新打开,否则无法识别
输入 python -V启动:  |
|---|
base: 是anaconda的默认的初始环境, 后续我们还可以构建更多的虚拟环境, 用于隔离各个Python环境操作, 如果不想看到base的字样, 也可以选择直接退出即可
执行: conda deactivate  |
|---|
但是当大家重新访问的时候, 会发现又重新进入了base,如何让其默认不进去呢, 可以选择修改.bashrc这个文件
| vim ~/.bashrc 在文件的末尾添加: conda deactivate 保存退出后, 重新打开会话窗口, 发现就不会在直接进入base了 |
|---|
Anaconda相关组件介绍[了解]
Anaconda(水蟒):是一个科学计算软件发行版,集成了大量常用扩展包的环境,包含了 conda、Python 等 180 多个科学计算包及其依赖项,并且支持所有操作系统平台。下载地址:https://www.continuum.io/downloads
- 安装包:pip install xxx,conda install xxx
- 卸载包:pip uninstall xxx,conda uninstall xxx
- 升级包:pip install upgrade xxx,conda update xxx
**Jupyter Notebook:**启动命令
| jupyter notebook |
|---|
功能如下:
- Anaconda自带,无需单独安装
- 实时查看运行过程
- 基本的web编辑器(本地)
- ipynb 文件分享
- 可交互式
- 记录历史运行结果
修改jupyter显示的文件路径:
通过jupyter notebook –generate-config命令创建配置文件,之后在进入用户文件夹下面查看.jupyter隐藏文件夹,修改其中文件jupyter_notebook_config.py的202行为计算机本地存在的路径。
IPython:
命令:ipython,其功能如下
1.Anaconda自带,无需单独安装
2.Python的交互式命令行 Shell
3.可交互式
4.记录历史运行结果
5.及时验证想法
Spyder:
命令:spyder,其功能如下
1.Anaconda自带,无需单独安装
2.完全免费,适合熟悉Matlab的用户
3.功能强大,使用简单的图形界面开发环境
下面就Anaconda中的conda命令做详细介绍和配置。
- conda命令及pip命令
conda管理数据科学环境,conda和pip类似均为安装、卸载或管理Python第三方包。
| conda install 包名 pip install 包名 conda uninstall 包名 pip uninstall 包名 conda install -U 包名 pip install -U 包名 |
|---|
(2) Anaconda设置为国内下载镜像
| conda config –add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config –set show_channel_urls yes |
|---|
(3)conda创建虚拟环境
| conda env list conda create py_env python=3.8.8 #创建python3.8.8环境 activate py_env #激活环境 deactivate py_env #退出环境 |
|---|
PySpark安装
三个节点也是都需要安装pySpark的
方式1:直接安装PySpark
安装如下:
| 使用PyPI安装PySpark如下:也可以指定版本安装 pip install pyspark 或者指定清华镜像**(对于网络较差的情况)**: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark # 指定清华镜像源 如果要为特定组件安装额外的依赖项,可以按如下方式安装(此步骤暂不执行,后面Sparksql部分会执行): pip install pyspark[sql] |
|---|
截图如下:

[安装]方式2:创建Conda环境安装PySpark
#从终端创建新的虚拟环境,如下所示 conda create -n pyspark_env python=3.8  #创建虚拟环境后,它应该在 Conda 环境列表下可见,可以使用以下命令查看 conda env list #创建虚拟环境后,它应该在 Conda 环境列表下可见,可以使用以下命令查看 conda env list  #现在使用以下命令激活新创建的环境: source activate pyspark_env 或者 conda activate pyspark_env #现在使用以下命令激活新创建的环境: source activate pyspark_env 或者 conda activate pyspark_env  如果报错: CommandNotFoundError: Your shell has not been properly configured to use ‘conda deactivate’.切换使用 source activate #您可以在新创建的环境中通过使用PyPI安装PySpark来安装pyspark,例如如下。它将pyspark_env在上面创建的新虚拟环境下安装 PySpark。 pip install pyspark #或者,可以从 Conda 本身安装 PySpark: conda install pyspark 如果报错: CommandNotFoundError: Your shell has not been properly configured to use ‘conda deactivate’.切换使用 source activate #您可以在新创建的环境中通过使用PyPI安装PySpark来安装pyspark,例如如下。它将pyspark_env在上面创建的新虚拟环境下安装 PySpark。 pip install pyspark #或者,可以从 Conda 本身安装 PySpark: conda install pyspark  |
|---|
[不推荐]方式3:手动下载安装
将spark对应版本下的python目录下的pyspark复制到anaconda的
Library/Python3/site-packages/目录下即可。
请注意,PySpark 需要JAVA_HOME正确设置的Java 8 或更高版本。如果使用 JDK 11,请设置-Dio.netty.tryReflectionSetAccessible=true,Arrow相关功能才可以使用。
扩展:
| conda虚拟环境 命令 查看所有环境 conda info –envs 新建虚拟环境 conda create -n myenv python=3.6 删除虚拟环境 conda remove -n myenv –all 激活虚拟环境 conda activate myenv source activate base 退出虚拟环境 conda deactivate myenv |
|---|
初体验-PySpark shell方式
前面的Spark Shell实际上使用的是Scala交互式Shell,实际上 Spark 也提供了一个用 Python 交互式Shell,即Pyspark。
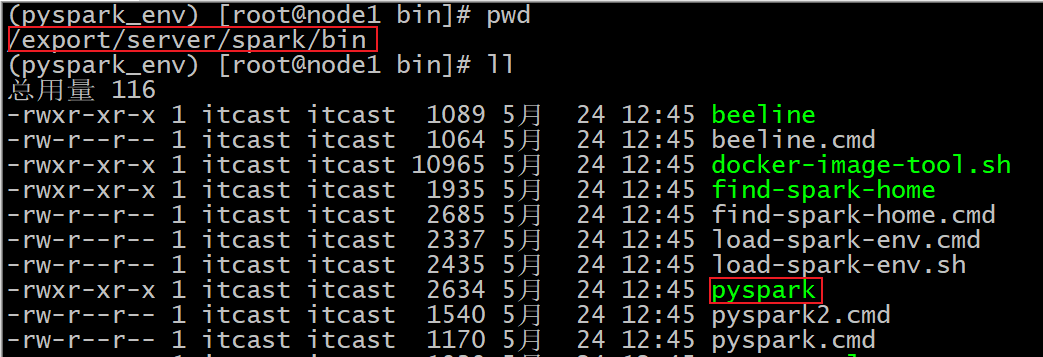
| bin/pyspark –master local[*] |
|---|
Spark Standalone集群环境
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
| 节点 | 主节点(master) | 从节点(worker) | 历史服务(history server) |
|---|---|---|---|
| node1 | 是 | 是 | 是 |
| node2 | 否 | 是 | 否 |
| node3 | 否 | 是 | 否 |
修改配置文件
说明: 直接对local模型下的spark进行更改为standalone模式
【workers】
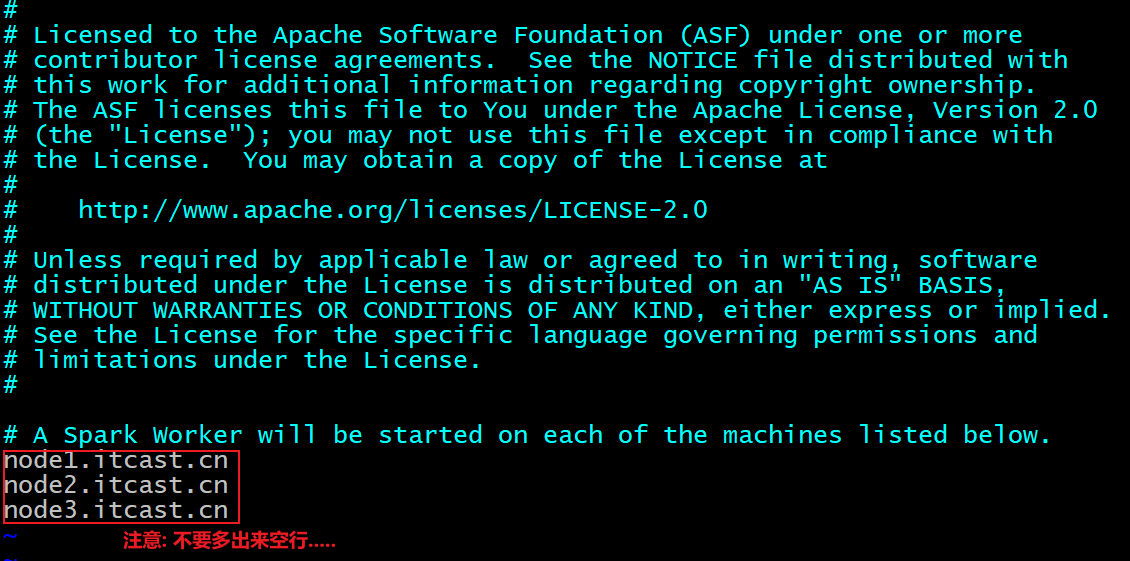
| cd /export/server/spark/conf/ cp workers.template workers vim workers 添加以下内容: node1.itcast.cn node2.itcast.cn node3.itcast.cn |
|---|
【spark-env.sh】
| cd /export/server/spark/conf cp spark-env.sh.template spark-env.sh vim spark-env.sh 增加如下内容: JAVA_HOME=/export/server/jdk1.8.0_241/ HADOOP_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop/ YARN_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop/ export SPARK_MASTER_HOST=node1.itcast.cn export SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=2 SPARK_WORKER_MEMORY=2g SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 SPARK_HISTORY_OPTS=”-Dspark.history.fs.logDirectory=hdfs://node1.itcast.cn:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true” |
|---|
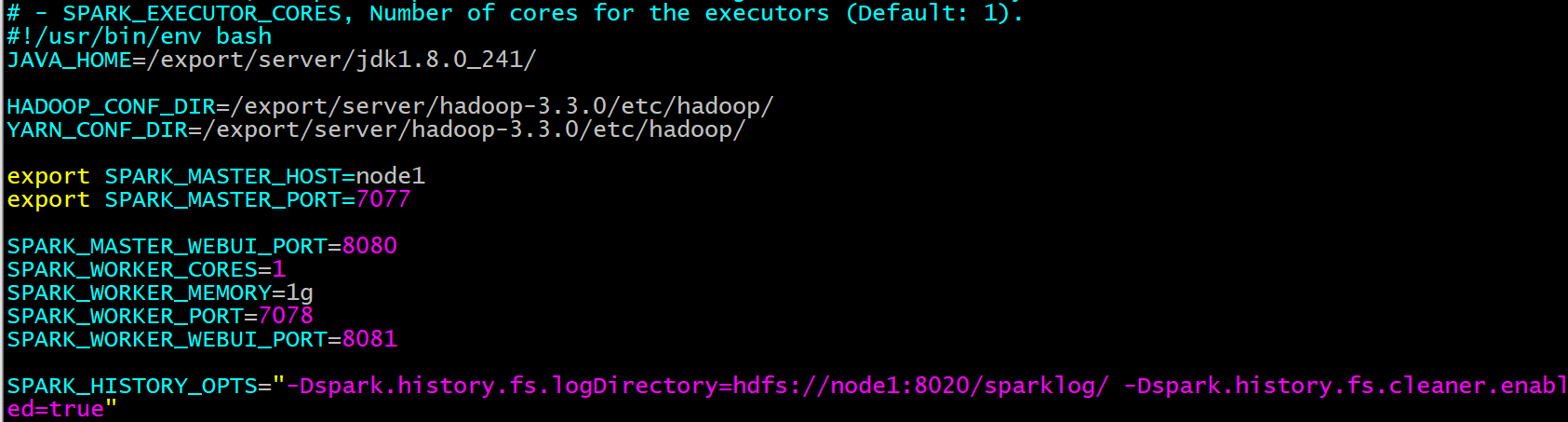
注意:
Jdk,hadoop, yarn的路径, 需要配置为自己的路径(可能与此位置不一致)
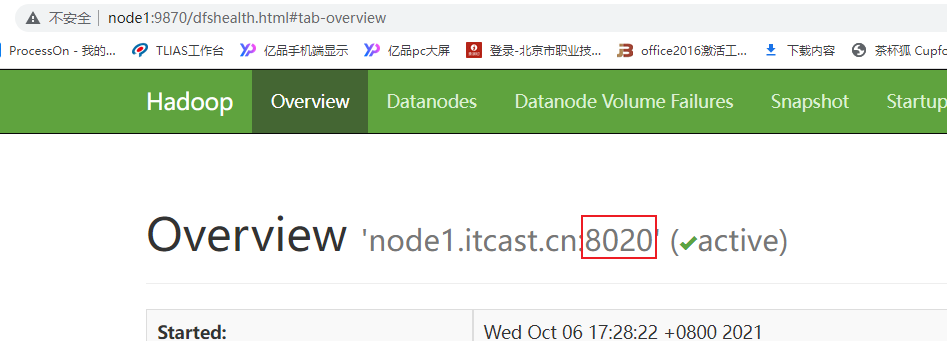
History配置中, 需要指定hdfs的地址, 其中端口号为8020或者9820, 大家需要参考hdfs上对应namenode的通信端口号
【配置spark应用日志】
| 第一步: 在HDFS上创建应用运行事件日志目录: hdfs dfs -mkdir -p /sparklog/ 第二步: 配置spark-defaults.conf cd /export/server/spark/conf cp spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf 添加以下内容: spark.eventLog.enabled true spark.eventLog.dir hdfs://node1.itcast.cn:8020/sparklog/ spark.eventLog.compress true |
|---|
其中HDFS的地址, 8020 还是9820 需要查看HDFS的界面显示

【log4j.properties】
cd /export/server/spark/conf cp log4j.properties.template log4j.properties vim log4j.properties ## 改变日志级别  |
|---|
分发到其他机器
将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:
| cd /export/server/ scp -r spark-3.1.2-bin-hadoop3.2/ node2:$PWD scp -r spark-3.1.2-bin-hadoop3.2/ node3:$PWD ##分别在node2, 和node3中创建软连接 ln -s /export/server/spark-3.1.2-bin-hadoop3.2/ /export/server/spark |
|---|
启动spark Standalone
- 启动方式1:集群启动和停止
在主节点上启动spark集群
cd /export/server/spark sbin/start-all.sh    sbin/start-history-server.sh sbin/start-history-server.sh  |
|---|
在主节点上停止spark集群
| /export/server/spark/sbin/stop-all.sh |
|---|
- 启动方式2:单独启动和停止
在 master 安装节点上启动和停止 master:
| start-master.sh stop-master.sh |
|---|
在 Master 所在节点上启动和停止worker(work指的是slaves 配置文件中的主机名)
| start-slaves.sh stop-slaves.sh |
|---|
- WEB UI页面
| http://node1:8080/ |
|---|
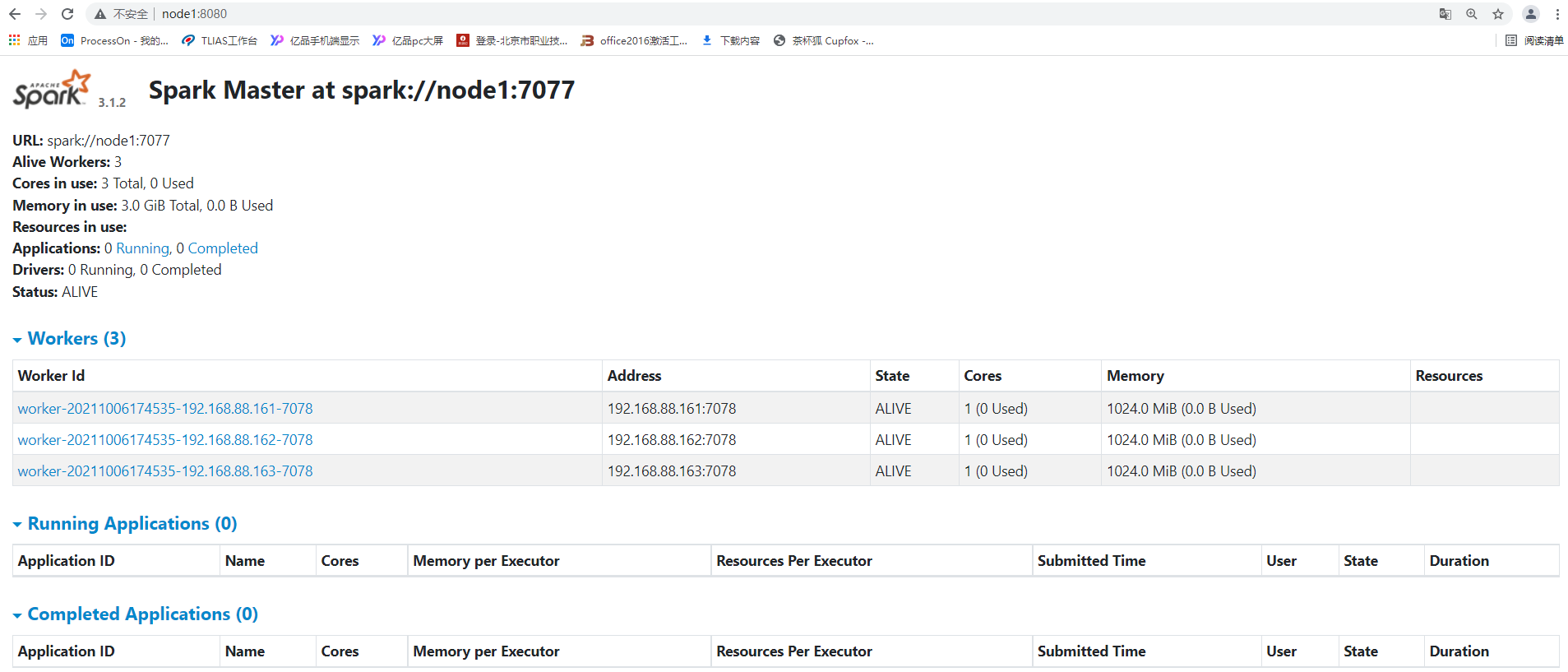
可以看出,配置了3个Worker进程实例,每个Worker实例为1核1GB内存,总共是3核 3GB 内存。目前显示的Worker资源都是空闲的,当向Spark集群提交应用之后,Spark就会分配相应的资源给程序使用,可以在该页面看到资源的使用情况。
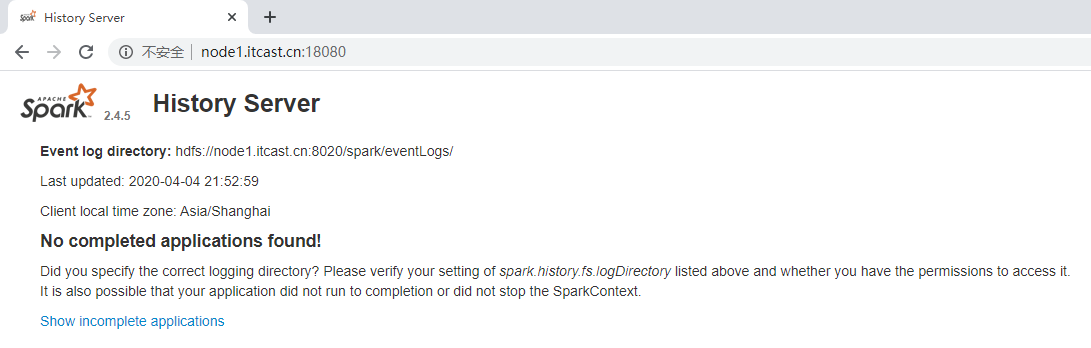
- 历史服务器HistoryServer:
| /export/server/spark/sbin/start-history-server.sh |
|---|
WEB UI页面地址:http://node1:18080
连接集群
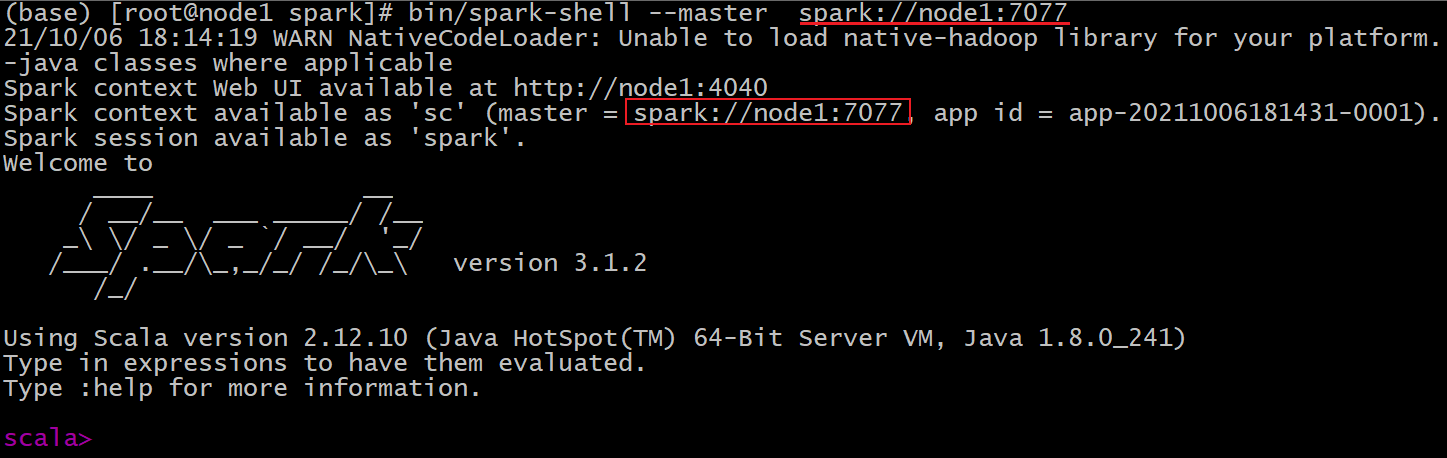
【spark-shell 连接】
| cd /export/server/spark bin/spark-shell –master spark://node1:7077 |
|---|
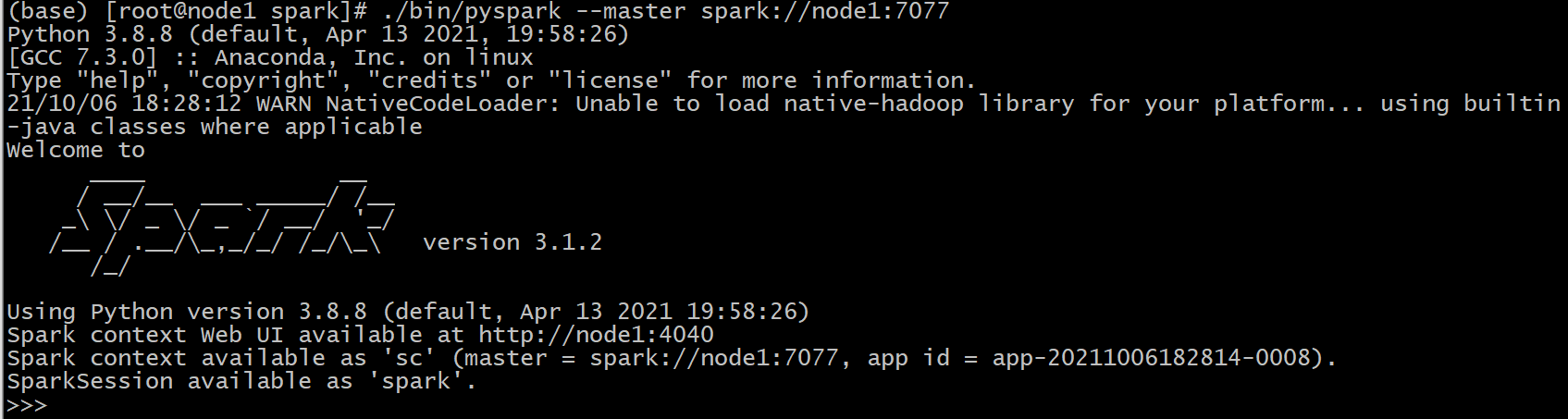
【pyspark 连接】
| cd /export/server/spark ./bin/pyspark –master spark://node1:7077 |
|---|
Spark Standalone HA 模式安装
多master模式 其中一个为active节点, 另一个为standby状态
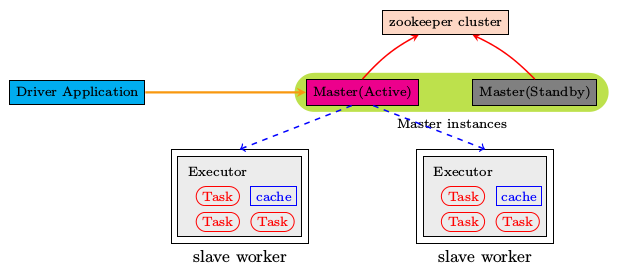
注意: HA模式需要依赖于zookeeper进行协助管理
修改配置
| cd /export/server/spark/conf vim spark-env.sh 注释或删除MASTER_HOST内容: # SPARK_MASTER_HOST=node1.itcast.cn 增加以下配置: SPARK_DAEMON_JAVA_OPTS=”-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url= node1.itcast. cn:2181,node2.itcast.cn:2181,node3.itcast.cn:2181 -Dspark.deploy.zookeeper.dir=/spark-ha” |
|---|
说明函数说明:
spark.deploy.recoveryMode:恢复模式
spark.deploy.zookeeper.url:ZooKeeper的Server地址
spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。包括Worker、Driver、Application信息。
配置分发
| cd /export/server/spark/conf scp -r spark-env.sh node2:$PWD scp -r spark-env.sh node3:$PWD |
|---|
启动集群
| 首先启动zookeeper服务: 三个节点都需要启动 zkServer.sh status –查看状态 zkServer.sh stop –停止命令 zkServer.sh start –启动命令 接着在node1启动spark集群 cd /export/server/spark ./sbin/start-all.sh 最后在node2上单独启动一个master cd /export/server/spark ./sbin/start-master.sh |
|---|
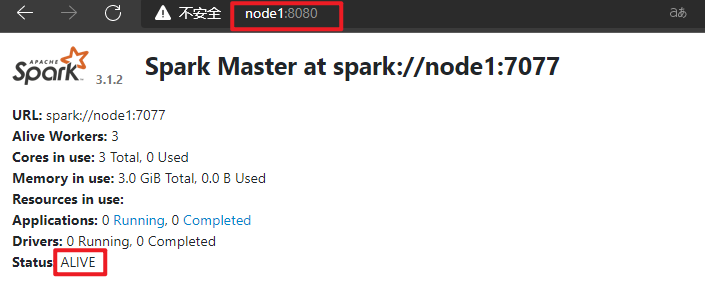
查看WebUI
-
默认情况下,先启动Master就为Active Master,如下截图所示:
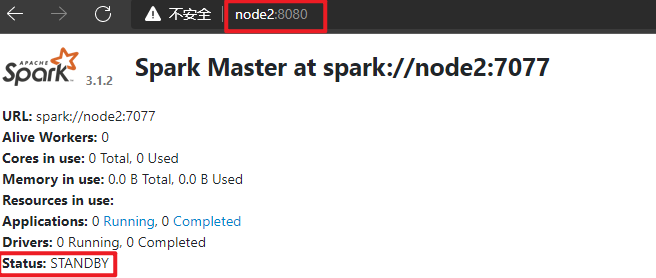
Spark on YARN 环境搭建
修改spark-env.sh
| cd /export/server/spark/conf vim /export/server/spark/conf/spark-env.sh 添加以下内容: HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop YARN_CONF_DIR=/export/server/hadoop/etc/hadoop 同步到其他两台 cd /export/server/spark/conf scp -r spark-env.sh node2:$PWD scp -r spark-env.sh node3:$PWD |
|---|
修改hadoop的yarn-site.xml
node1修改
| cd /export/server/hadoop/etc/hadoop/ vim /export/server/hadoop/etc/hadoop/yarn-site.xml 添加以下内容: <configuration> <!– 配置yarn主节点的位置 –> <property> <name>yarn.resourcemanager.hostname</name> <value>node1.itcast.cn</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!– 设置yarn集群的内存分配方案 –> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>20480</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <!– 开启日志聚合功能 –> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!– 设置聚合日志在hdfs上的保存时间 –> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!– 设置yarn历史服务器地址 –> <property> <name>yarn.log.server.url</name> <value>http://node1.itcast.cn:19888/jobhistory/logs\</value> </property> <!– 关闭yarn内存检查 –> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration> |
|---|
将其同步到其他两台
| cd /export/server/hadoop/etc/hadoop scp -r yarn-site.xml node2:$PWD scp -r yarn-site.xml node3:$PWD |
|---|
Spark设置历史服务地址
| cd /export/server/spark/conf vim spark-defaults.conf 添加以下内容: spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:9820/sparklog/ spark.eventLog.compress true spark.yarn.historyServer.address node1.itcast.cn:18080 |
|---|
设置日志级别:
cd /export/server/spark/conf vim log4j.properties 修改以下内容:  |
|---|
同步到其他节点
| cd /export/server/spark/conf scp -r spark-defaults.conf log4j.properties node2:$PWD scp -r spark-defaults.conf log4j.properties node3:$PWD |
|---|
配置依赖spark jar包
**当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,**设置属性告知Spark Application应用。
| hadoop fs -mkdir -p /spark/jars/ hadoop fs -put /export/server/spark/jars/* /spark/jars/ |
|---|
修改spark-defaults.conf
| cd /export/server/spark/conf vim spark-defaults.conf 添加以下内容: spark.yarn.jars hdfs://node1.itcast.cn:8020/spark/jars/* |
|---|
同步到其他节点
| cd /export/server/spark/conf scp -r spark-defaults.conf root@node2:$PWD scp -r spark-defaults.conf root@node3:$PWD |
|---|
启动服务
Spark Application运行在YARN上时,上述配置完成
启动服务:HDFS、YARN、MRHistoryServer和Spark HistoryServer,命令如下:
| ## 启动HDFS和YARN服务,在node1执行命令 start-dfs.sh start-yarn.sh 或 start-all.sh 注意:在onyarn模式下不需要启动start-all.sh(jps查看一下看不到worker和master) ## 启动MRHistoryServer服务,在node1执行命令 mapred –daemon start ## 启动Spark HistoryServer服务,,在node1执行命令 /export/server/spark/sbin/start-history-server.sh |
|---|
- Spark HistoryServer服务WEB UI页面地址:
| http://node1:18080/ |
|---|
提交测试
先将圆周率PI程序提交运行在YARN上,命令如下:
| /export/server/spark/bin/spark-submit \ –master yarn \ –conf “spark.pyspark.driver.python=/root/anaconda3/bin/python3” \ –conf “spark.pyspark.python=/root/anaconda3/bin/python3” \ /export/server/spark/examples/src/main/python/pi.py \ 10 |
|---|
运行完成在YARN 监控页面截图如下:
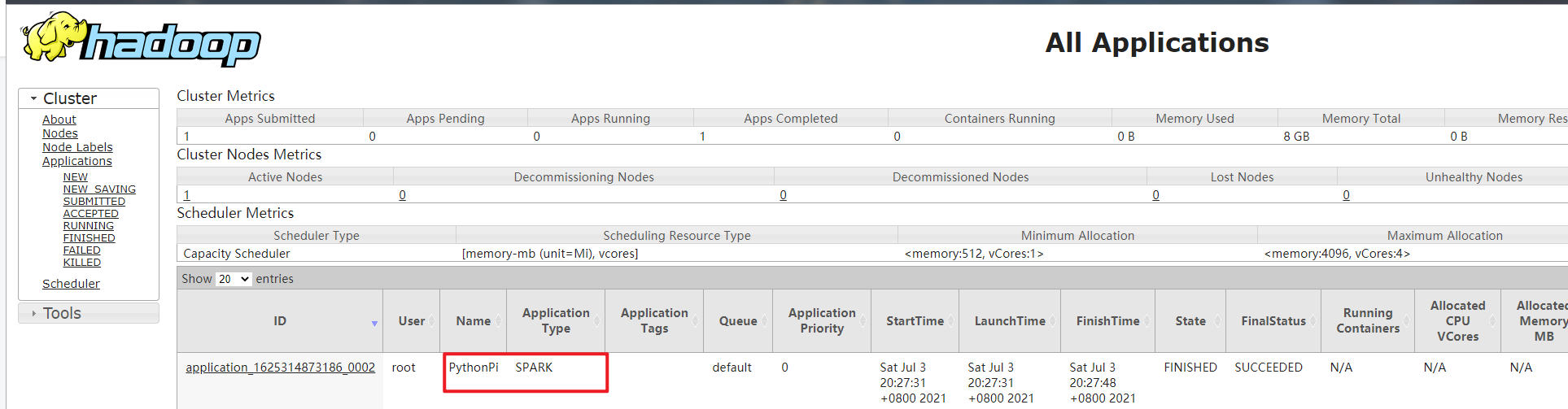
设置资源信息,提交运行pi程序至YARN上,命令如下:
| /export/server/spark/bin/spark-submit \ –master yarn \ –driver-memory 512m \ –executor-memory 512m \ –executor-cores 1 \ –num-executors 2 \ –queue default \ –conf “spark.pyspark.driver.python=/root/anaconda3/bin/python3” \ –conf “spark.pyspark.python=/root/anaconda3/bin/python3” \ /export/server/spark/examples/src/main/python/pi.py \ 10 |
|---|
当pi应用运行YARN上完成以后,从8080 WEB 页面点击应用历史服务连接,查看应用运行状态信息。
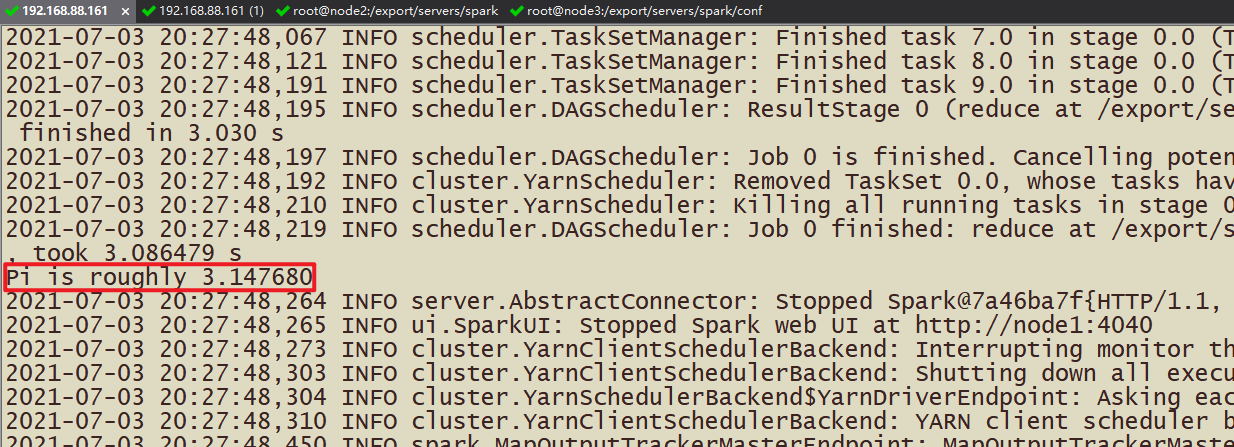
第七章 SparkSQL与Hive整合
SparkSQL整合Hive步骤
第一步:将hive-site.xml拷贝到spark安装路径conf目录
node1执行以下命令来拷贝hive-site.xml到所有的spark安装服务器上面去
| cd /export/server/hive/conf cp hive-site.xml /export/server/spark/conf/ scp hive-site.xml root@node2:/export/server/spark/conf/ scp hive-site.xml root@node3:/export/server/spark/conf/ |
|---|
第二步:将mysql的连接驱动包拷贝到spark的jars目录下
node1执行以下命令将连接驱动包拷贝到spark的jars目录下,三台机器都要进行拷贝
| cd /export/server/hive/lib cp mysql-connector-java-5.1.32.jar /export/server/spark/jars/ scp mysql-connector-java-5.1.32.jar root@node2:/export/server/spark/jars/ scp mysql-connector-java-5.1.32.jar root@node3:/export/server/spark/jars/ |
|---|
第三步:Hive开启MetaStore服务
(1)修改 hive/conf/hive-site.xml新增如下配置
| 远程模式部署metastore 服务地址 <?xml version=”1.0”?> <?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?> <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://node1.itcast.cn:9083</value> </property> </configuration> |
|---|
2: 后台启动 Hive MetaStore服务
前台启动:
| bin/hive –service metastore |
|---|
后台启动:
| nohup /export/server/hive/bin/hive –service metastore 2>&1 >> /var/log.log & |
|---|
完整的hive-site.xml文件
| <configuration> <!– 存储元数据mysql相关配置 –> <property> <name>javax.jdo.option.ConnectionURL</name> <value> jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!– H2S运行绑定host –> <property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> </property> <!– 远程模式部署metastore 服务地址 –> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> <!– 关闭元数据存储授权 –> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!– 关闭元数据存储版本的验证 –> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> </configuration> |
|---|
第四步:测试Sparksql整合Hive是否成功
- [方式1]Spark-sql方式测试
先启动hadoop集群,在启动spark集群,确保启动成功之后node1执行命令,指明master地址、每一个executor的内存大小、一共所需要的核数、mysql数据库连接驱动:
| cd /export/server/spark bin/spark-sql –master local[2] –executor-memory 512m –total-executor-cores 1 或 bin/spark-sql –master spark://node1.itcast.cn:7077 –executor-memory 512m –total-executor-cores 1 |
|---|
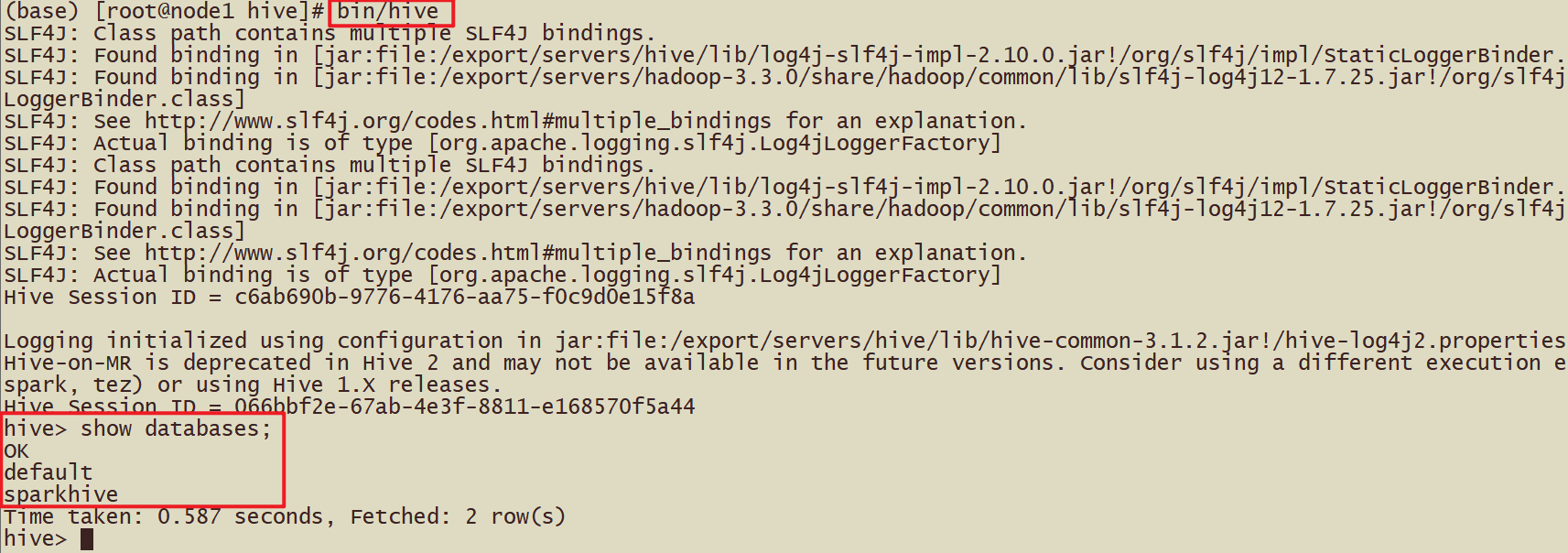
执行成功后的界面:进入到spark-sql 客户端命令行界面
查看当前有哪些数据库, 并创建数据库
| show databases; create database sparkhive; |
|---|
看到数据的结果,说明sparksql整合hive成功!
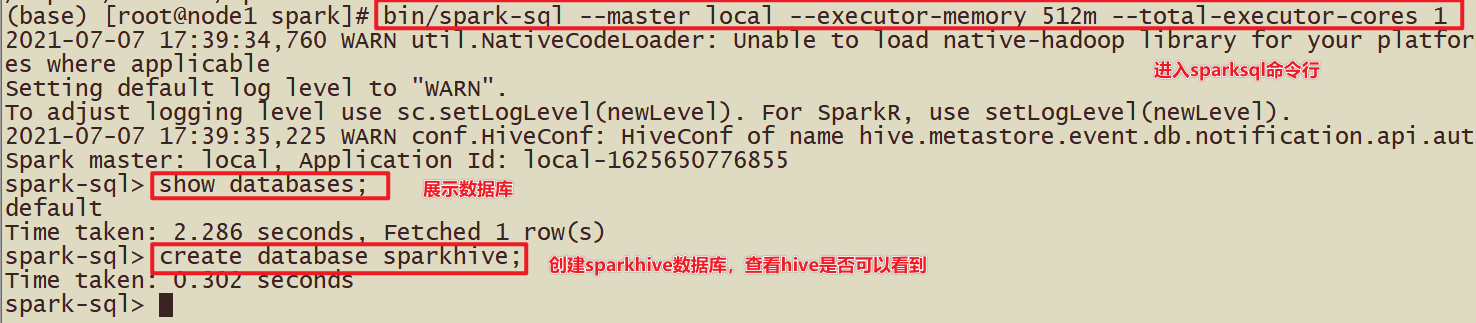
注意:日志太多,我们可以修改spark的日志输出级别(conf/log4j.properties)
注意:
在spark2.0版本后由于出现了sparkSession,在初始化sqlContext的时候,会设置默认的spark.sql.warehouse.dir=spark-warehouse,
此时将hive与sparksql整合完成之后,在通过spark-sql脚本启动的时候,还是会在那里启动spark-sql脚本,就会在当前目录下创建一个spark.sql.warehouse.dir为spark-warehouse的目录,存放由spark-sql创建数据库和创建表的数据信息,与之前hive的数据息不是放在同一个路径下(可以互相访问)。但是此时spark-sql中表的数据在本地,不利于操作,也不安全。
所有在启动的时候需要加上这样一个参数:
--conf spark.sql.warehouse.dir=hdfs://node1:9820/user/hive/warehouse
保证spark-sql启动时不在产生新的存放数据的目录,sparksql与hive最终使用的是hive同一存放数据的目录。如果使用的是spark2.0之前的版本,由于没有sparkSession,不会出现spark.sql.warehouse.dir配置项,不会出现上述问题。
**Spark2之后最后的执行脚本,**node1执行以下命令重新进去spark-sql
| cd /export/server/spark bin/spark-sql \ –master spark://node1:7077 \ –executor-memory 512m –total-executor-cores 1 \ –conf spark.sql.warehouse.dir=hdfs://node1:9820/user/hive/warehouse |
|---|
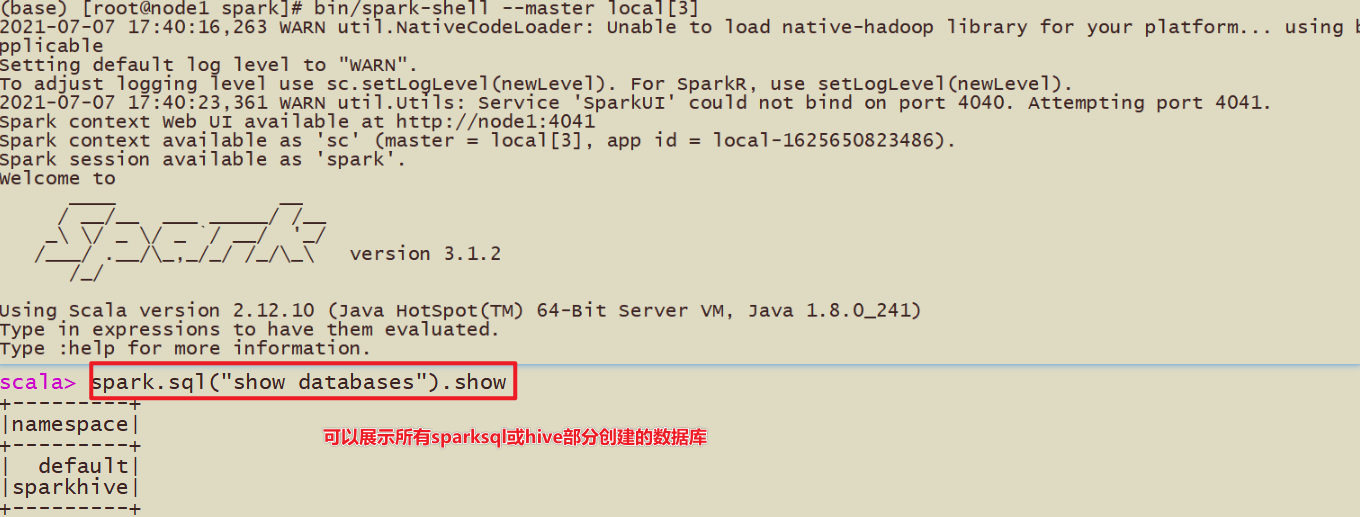
- [方式2]PySpark-Shell方式启动:
| bin/spark-shell –master local[3] spark.sql(“show databases”).show |
|---|
如下图:
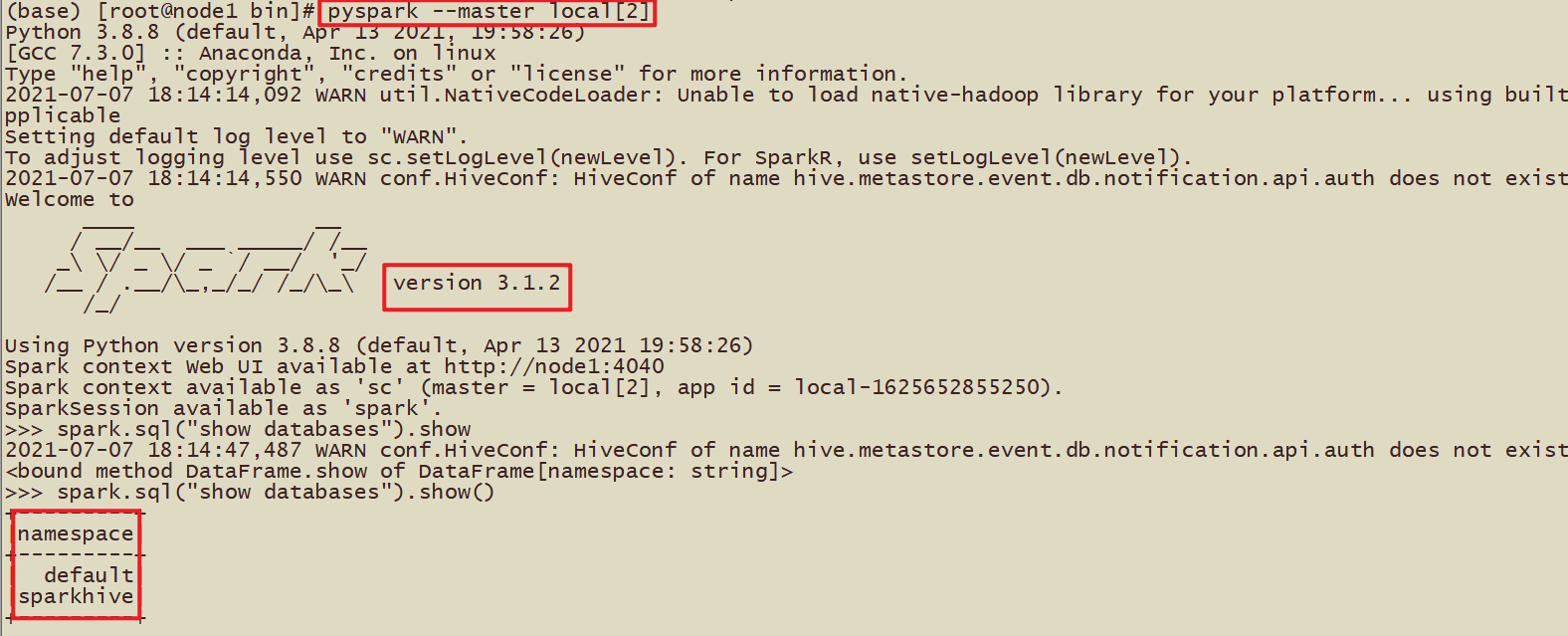
- [方式3]PySpark-Shell方式启动:
| bin/pyspark –master local[2] spark.sql(“show databases”).show |
|---|
PyCharm整合Hive
操作准备
●原理
Hive表的元数据库中,描述了有哪些database、table、以及表有多少列,每一列是什么类型,以及表的数据保存在hdfs的什么位置
执行HQL时,先到MySQL元数据库中查找描述信息,然后解析HQL并根据描述信息生成MR任务,简单来说Hive就是将SQL根据MySQL中元数据信息转成MapReduce执行,但是速度慢
使用SparkSQL整合Hive其实就是让SparkSQL去加载Hive 的元数据库,然后通过SparkSQL执行引擎去操作Hive表
所以首先需要开启Hive的元数据库服务,让SparkSQL能够加载元数据
●API
在Spark2.0之后,SparkSession对HiveContext和SqlContext在进行了统一
可以通过操作SparkSession来操作HiveContext和SqlContext。
SparkSQL整合Hive MetaStore
默认Spark 有一个内置的 MateStore,使用 Derby 嵌入式数据库保存数据【上面案例】,但是这种方式不适合生产环境,因为这种模式同一时间只能有一个 SparkSession 使用,所以生产环境更推荐使用 Hive 的 MetaStore
SparkSQL 整合 Hive 的 MetaStore 主要思路就是要通过配置能够访问它,并且能够使用 HDFS保存WareHouse,所以可以直接拷贝Hadoop和Hive的配置文件到Spark的配置目录。
使用SparkSQL操作集群Hive表
如下为HiveContext的源码解析:
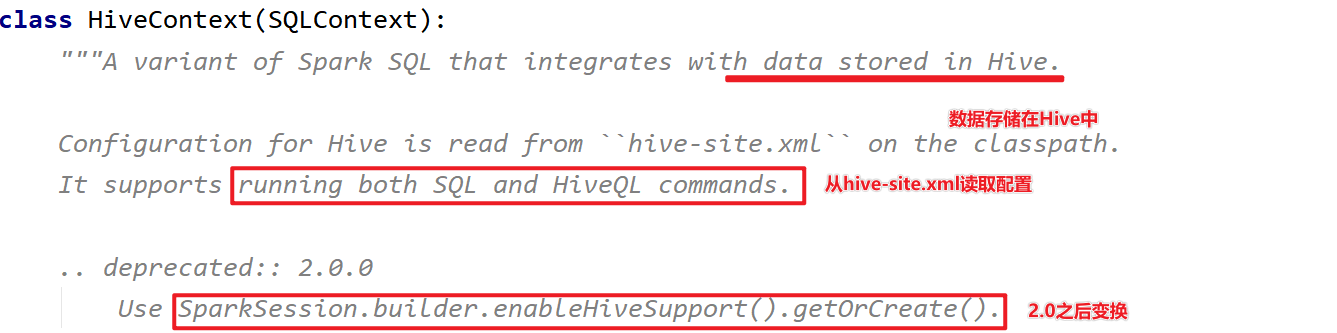
在PyCharm中开发应用,集成Hive读取表的数据进行分析,构建SparkSession时需要设置HiveMetaStore服务器地址及集成Hive选项:
范例演示代码如下:
| # -*- coding: utf-8 -*- # Program function: from pyspark.sql import SparkSession import os os.environ[‘SPARK_HOME’] = ‘/export/servers/spark’ PYSPARK_PYTHON = “/root/anaconda3/envs/pyspark_env/bin/python” # 当存在多个版本时,不指定很可能会导致出错 os.environ[“PYSPARK_PYTHON”] = PYSPARK_PYTHON os.environ[“PYSPARK_DRIVER_PYTHON”] = PYSPARK_PYTHON if _name_ == ‘main‘: # _SPARK_HOST = “spark://node1:7077” ** _SPARK_HOST = “local[3]” ** _APP_NAME = “test” ** spark = SparkSession.builder \ .master(_SPARK_HOST) \ .appName(_APP_NAME) \ .enableHiveSupport() \ .getOrCreate() spark.sparkContext.setLogLevel(“WARN”) #PROJECT_ROOT = os.path.dirname(os.path.realpath(file)) # 获取项目根目录 # print(PROJECT_ROOT)#/export/pyfolder1/pyspark-chapter03_3.8/main #path = os.path.join(PROJECT_ROOT, “data\\edge\\0_fuse.txt”) # 文件路径 # 查看有哪些表 ** spark.sql(“show databases”).show() spark.sql(“use sparkhive”).show() spark.sql(“show tables”).show() # 创建表 ** spark.sql( “create table if not exists person (id int, name string, age int) row format delimited fields terminated by ‘,’”) # 加载数据, 数据为当前目录下的person.txt(和src平级) ** spark.sql(“LOAD DATA LOCAL INPATH ‘/export/pyfolder1/pyspark-chapter03_3.8/data/student.csv’ INTO TABLE person”) # 查询数据 ** spark.sql(“select** * from person “).show() print(“===========================================================”) import pyspark.sql.functions as fn spark.read \ .table(“person “) \ .groupBy(“name”) \ .agg(fn.round(fn.avg(“age”), 2).alias(“avg_age”)) \ .show(10, truncate=False) spark.stop() |
|---|
运行程序结果如下:

 微信
微信 支付宝
支付宝