算法公式推导
Latex公式语法传送门
机器学习
ID3是采用信息增益作为特征选择度量,而C4.5采用信息增益率、CART基尼指数。
信息熵:
$$
Ent(D^v) = -\sum_{i=1}^{k}p_i\log_{b}(p_i)
$$信息增益(信息熵 - 条件熵):
$$
g(D,A)=H(D)-H(D|A)
$$
即:
$$
Gain(D,a) = Ent(D) - \sum_ {v=1}^{V}{\frac{\left| D^{v} \right|}{\left| D \right|}Ent(D^{v})}
$$信息增益率 (信息增益/特征熵):
$$
\begin{aligned}
\text{Gain_Ratio}(D, a) &= \frac{\text{Gain}(D, a)}{IV(a)} \
\end{aligned}
$$
其中,特征熵可以这样理解就是只在本特征(列)中求不同类型特征的熵:
$$
IV(a)=-\sum_{v=1}^{V}\frac{\left|D^{v}\right|}{|D|}\log_{2}\frac{|D^{v}|}{|D|}
$$基尼值(Cart分类树):
$$
Gini(D) = \sum_{k=1}^{|y|} \sum_{k’ \neq k} p_k p_{k’} = 1 - \sum_{k=1}^{|y|} p_k^2
$$基尼指数:
$$
Gini(D,a) = 1 - \sum_{v=1}^{V}{\frac{\left| D^{v} \right|}{\left| D \right|}Gini(D^{v})}
$$
基尼指数增益:(基尼指数增益最大需要基尼指数最小):
$$
Gain(D,a)=Gini(D) - Gini(D,a)
$$
其中$Gini(D)$是总样本的基尼指数。
Cart回归树:
$$
\operatorname{Loss}(y, f(x))=(f(x)-y)^{2}
$$
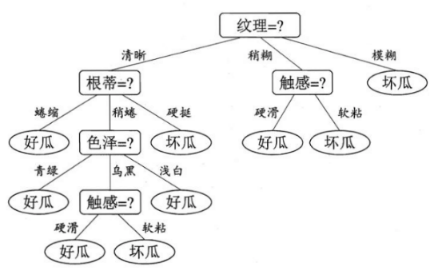
给定如下样本(六个特征列、一个标签列)分别构建ID3、C4.5、Cart树:

ID3决策树
根据信息熵公式:
$$
H = -\sum_{i=1}^{k}p_i\log_{b}(p_i)
$$总样本17个,好瓜8个,坏瓜9个
总的信息熵为:
$$
Ent(D) = -(\frac{8}{17}log_{2}{\frac{8}{17}}+\frac{9}{17}log_{2}{\frac{9}{17}}) = 0.998
$$
因为是需要按照每个特征的信息增益来构建决策树的,所以需要求出每个特征对应的信息增益:

色泽为青绿(对应上图,只举例一个图):
$$
Ent(D^{青绿}) = -(\frac{3}{6}log_{2}{\frac{3}{6}}+\frac{3}{6}log_{2}{\frac{3}{6}}) = 1
$$
色泽为乌黑时:
$$
Ent(D^{乌黑}) = -(\frac{2}{6}log_{2}{\frac{2}{6}}+\frac{4}{6}log_{2}{\frac{4}{6}}) = 0.918
$$
色泽为浅白时:
$$
Ent(D^{浅白})= -(\frac{1}{5}log_{2}{\frac{1}{5}}+\frac{4}{5}log_{2}{\frac{4}{5}}) = 0.722
$$
最终属性色泽的信息增益计算结果为:
$$
Gain(D,色泽) = Ent(D) - \sum_{v=1}^{3}{\frac{\left| D^{v} \right|}{\left| D \right|}Ent(D^{v})}= 0.998 - (\frac{6}{17}\times1.000+\frac{6}{17}\times0.918+\frac{5}{17}\times0.722)=0.109
$$
通过相同的公式我们可以再计算出:
根蒂:$Gain(D,根蒂)=0.143$
敲声:$Gain(D,敲声)=0.141$
纹理:$Gain(D,纹理)=0.381$
脐部:$Gain(D,脐部)=0.289$
触感:$Gain(D,触感)=0.006$
纹理属性的信息增益最高,因此它被选为第一个划分的属性
注意:在求纹理中具有模糊特征的信息增益,0 好瓜,3 坏瓜,$H(模糊)=0$,直接标记为坏瓜
接着按照上述步骤求其余特征信息增益,构建ID3决策树:
C4.5决策树
信息增益率公式:
$$
GainRatio(D,a) = \frac{Gain(D,a)}{IV(a)}
$$
其中:
$$
IV(a)=-\sum_{v=1}^{V}\frac{\left|D^{v}\right|}{|D|}\log_{2}\frac{|D^{v}|}{|D|}
$$
$IV(a)$ 称为属性 $a$ 的固有值(Intrinsic Value),其取值随着属性的数量增多而增大,这样就能够很好的降低属性取值数目多带来信息熵大的影响。
针对如下数据构建C4.5决策树:
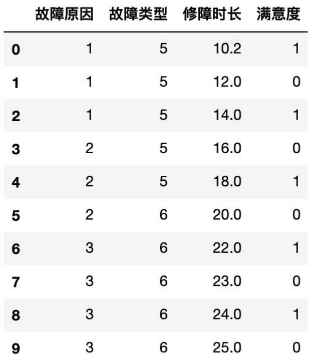
其中满意度为目标值(标签值),当采用故障原因作为分裂属性时可以得出:
$$
Ent(D) = -(\frac{5}{10}log_{2}{\frac{5}{10}}+\frac{5}{10}log_{2}{\frac{5}{10}}) = 1
$$
对于三种类型的故障有:
$$
Ent(D^{故障原因1}) = -(\frac{2}{3}log_{2}{\frac{2}{3}}+\frac{1}{3}log_{2}{\frac{1}{3}}) = 0.918
$$
$$
Ent(D^{故障原因2}) = -(\frac{2}{3}log_{2}{\frac{2}{3}}+\frac{1}{3}log_{2}{\frac{1}{3}}) = 0.918
$$
$$
Ent(D^{故障原因3}) = -(\frac{2}{4}log_{2}{\frac{2}{4}}+\frac{2}{4}log_{2}{\frac{2}{4}}) = 1
$$
得出故障原因的信息增益为:
$$
Gain(D,故障原因) = 1 - (\frac{3}{10}\times0.918+\frac{3}{10}\times0.918+\frac{4}{10}\times1)=0.049
$$
故障原因的特征熵为:
$$
IV(故障原因) =-(\frac{3}{10}\times1og_{2}{\frac{3}{10}}+\frac{3}{10}\times1og_{2}{\frac{3}{10}}+\frac{4}{10}\times1og_{2}{\frac{4}{10}})=1.571
$$
因此求得故障原因的信息增益率为:
$$
GainRatio(D,故障原因) = \frac{Gain(D,故障原因)}{IV(故障原因)/特征熵}=\frac{0.049}{1.571}=0.031
$$
连续型变量信息增益
将连续型变量从小到大排序,取相邻两个值的重点作为分裂点,进行二分类。计算不同中点的信息增益,取使信息增益 最大 的分割点作为最终划分。
10.2、12、14、16、18、20、22、23、24、25,取相邻两个值的中点,如10.2和12,中点即为11.1,因此可以求得:
$$
Ent(D^{小于11.1}) = -\sum_{k=1}^{2}{p_{k}log_{2}{p_{k}}} = -\frac{1}{1}log_{2}{\frac{1}{1}}=0
$$
$$
Ent(D^{大于11.1}) = -(\frac{4}{9}log_{2}{\frac{4}{9}}+\frac{5}{9}log_{2}{\frac{5}{9}}) = 0.991
$$
最终修障时长在11.1为切分点时的信息增益为:
$$
Gain(D,时长11.1) =1 - (\frac{1}{10}\times0+\frac{9}{10}\times0.991)=0.108
$$
接着计算中点为13切点时的信息增益….
取使信息增益 最大 的分割点作为最终划分。
CART分类树
CART(Classification and Regression Tree)对于二分类问题采用基尼指数。
CART算法不管连续型还是离散型变量都采用二叉树模式进行分裂。公式如下:
$$
Gini(D) = \sum_{k=1}^{\left| y \right|}\sum_{k^{‘}≠k}^{}{p_{k}p_{k^{‘}}}=1- \sum_{k=1}^{\left| y \right|}p_{k}^{2}
$$
对于属性 $a$ 的的基尼指数为:
$$
Gini(D,a) = 1 - \sum_{v=1}^{V}{\frac{\left| D^{v} \right|}{\left| D \right|}Gini(D^{v})}
$$
对于属性 $a$ 的的基尼指数增益为(基尼指数增益最大需要基尼指数最小):
$$
Gain(D,a)=Gini(D) - Gini(D,a)
$$
通过计算选择基尼指数增益最大的变量(基尼指数最小)进行分裂,以如下数据为例:
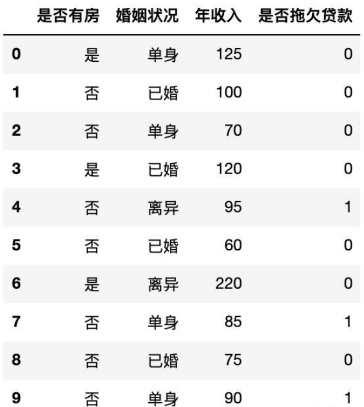
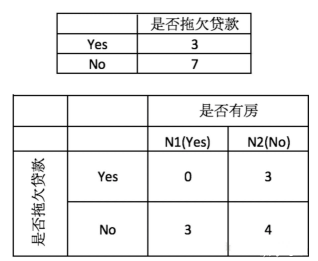
其中总样本的基尼指数为:
$$
Gini(D) =1- \sum_{k=1}^{2}p_{k}^{2}=1 - \left( \frac{3}{10} \right)^{2} - \left( \frac{7}{10} \right)^{2} = 0.42
$$
以是否有房为属性进行分裂时左右叶节点样本子集的基尼指数为:
是否有房左节点
$$
Gini(D^{是否有房左节点}) = 1- \sum_{k=1}^{\left| y \right|}p_{k}^{2}=1- \left( \frac{0}{3} \right)^{2} - \left( \frac{3}{3} \right)^{2} = 1
$$
是否有房右节点
$$
Gini(D^{是否有房右节点}) = 1- \sum_{k=1}^{\left| y \right|}p_{k}^{2}=1- \left( \frac{3}{7} \right)^{2} - \left( \frac{4}{7} \right)^{2} = 0.4898
$$是否有房的基尼指数为:
是否有房
$$
Gini(D,是否有房) = 1 - \sum_{v=1}^{V}{\frac{\left| D^{v} \right|}{\left| D \right|}Gini(D^{v})} =1-\frac{7}{10}\times0.4898-\frac{3}{10}\times0= 0.343
$$
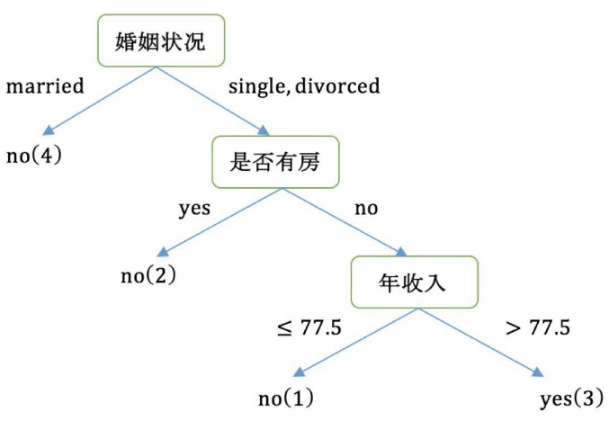
有多个值的特征构建决策树
这里因为CART树是
标准的二叉树,所以对于多个特征需要按照不同的类型分配,求出最大的基尼系数(基尼指数最小)。比如婚姻状况有三个取值嘛,已婚、未婚、离婚。
可以这样划分{married} | {single,divorced}类型1
也可以{single} | {married,divorced}类型2
还可以{divorced} | {single,married}类型3
当分组为{married} | {single,divorced}时基尼指数增益(总样本基尼指数-样本特征基尼指数)
$$
Gain(D,婚姻状况)=0.42 - \frac{4}{10}\times0-\frac{6}{10}\times[1-\left( \frac{3}{6} \right)^2-\left( \frac{3}{6} \right)^2]=0.12
$$
当分组为{single} | {married,divorced}时:
$$
Gain(D,婚姻状况)=0.42 - \frac{4}{10}\times[1-\left( \frac{2}{4} \right)^2-\left( \frac{2}{4} \right)^2]-\frac{6}{10}\times[1-\left( \frac{1}{6} \right)^2-\left( \frac{5}{6} \right)^2]=0.053
$$
当分组为{divorced} | {single,married}时
$$
Gain(D,婚姻状况)=0.42 - \frac{2}{10}\times[1-\left( \frac{1}{2} \right)^2-\left( \frac{1}{2} \right)^2]-\frac{8}{10}\times[1-\left( \frac{2}{8} \right)^2-\left( \frac{6}{8} \right)^2]=0.02
$$
根据婚姻状况属性来划分根节点时取基尼指数增益最大的分组作为划分结果,
也就是{married} | {single,divorced}为婚姻状况的最佳分裂节点
CART回归树
整体流程可以大致分为三步,
第一步划分左右子集,第二步计算左右子集平均值,第三步求左右子集方差和,取最小为最优分裂点。
对于一个变量 $j$ 可以按照取值 $s$划分为左右两个子集:
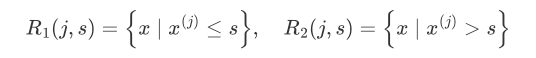
通过计算可以得出每个子集的平均值 $\hat{c}_m$:
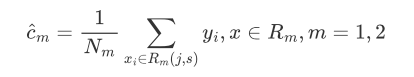
通过使用平方误差最小准则计算出左右子集的平均误差和最小时 ,$j$ 变量的分裂点 $s$为最佳分裂点:
$$
m(s) = min_{(j,s)}[\sum_{x_{i}\in R_{1}(j,s)}{(y_{i}-c_{1}})^2+\sum_{x_{i}\in R_{2}(j,s)}{(y_{i}-c_{2}})^2]
$$

其选择二叉树分裂节点时的方法和计算基尼指数时一致,因此当x以1.5作为分割点时:
$$
c_1=5.56, c2 = \frac{1}{9}(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9.0+9.05)=7.5
$$
二叉树左侧,右侧平均值为$c_1=5.56,c_2=7.5 $,计算两个子集平方误差的和为:
$$
m(1.5)= \sum_{x_{i}\in R_{1}(j,s)}{(y_{i}-c_{1}})^2+\sum_{x_{i}\in R_{2}(j,s)}{(y_{i}-c_{2}})^2
$$
$$
m(1.5) = (5.56-5.56)^2+(5.7-7.5)^2+(5.91-7.5)^2+(6.4-7.5)^2=15.72
$$
通过计算不同分裂点的平方误差的和得出如下结果:

$x=6.5$ 是 $m(s)$ 到达最小值为最佳切割点,此时可以将样本分割成左右两部分:
$$
R_1 = {1, 2, \ldots, 6}, \quad R_2 = {7, 8, 9, 10}
$$
如果该树仅仅分裂一次,保持树深度为2,那么未来当输入的变量小于等于6.5时,预测值(左子集均值)为:
$$
c_1 = \frac{1}{6}(5.56+5.7+5.91+6.4+6.8+7.05)=6.24
$$
当输入变量大于6.5时,此时预测值为(均值):
$$
c_2=\frac{1}{4}(8.9+8.7+9.0+9.05)=8.91
$$
最终得出:
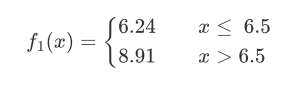
XGBoost算法

 最终目标函数形式
最终目标函数形式
简化后的目标函数:
$$
\mathcal{L}^{(t)}\approx\sum_{i=1}^{n}\left[g_{i}f_{t}(x_{i})+\frac{1}{2}h_{i}f_{t}^{2}(x_{i})\right]+\Omega(f_{t})
$$
通用泰勒展开公式
对于任意函数$g(x)$的二阶泰勒展开:
$$
g(x+\Delta x)\approx g(x)+g’(x)\Delta x+\frac{1}{2}g’’(x)(\Delta x)^{2}
$$
树的结构和正则化项
假设树函数 $f_{t}$ 可以表示为:
$$
f_{t}(x)=w_{q(x)}
$$
其中:
- $q(x)$ 是将样本 $x$ 映射到叶子节点的函数
- $w$ 是叶子节点的权重向量
正则化项定义为:
$$
\Omega(f_{t})=\gamma T+\frac{1}{2}\lambda\sum_{j=1}^{T}w_{j}^{2}
$$
参数说明:
- $T$:叶子节点数量
- $\gamma$, $\lambda$:正则化参数
- $w_{j}$:第 $j$ 个叶子节点的权重
目标函数重写
将树函数和正则化项代入目标函数:
$$
\mathcal{L}^{(t)}\approx\sum_{i=1}^{n}\left[g_{i}w_{q(x_{i})}+\frac{1}{2}h_{i}w_{q(x_{i})}^{2}\right]+\gamma T+\frac{1}{2}\lambda\sum_{j=1}^{T}w_{j}^{2}
$$
定义叶子节点 $j$ 的样本集合:
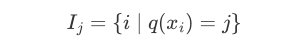
重写目标函数:
$$
\mathcal{L}^{(t)}\approx\sum_{j=1}^{T}\left[\left(\sum_{i\in I_{j}}g_{i}\right)w_{j}+\frac{1}{2}\left(\sum_{i\in I_{j}}h_{i}+\lambda\right)w_{j}^{2}\right]+\gamma T
$$
令:
$$
\begin{aligned}
G_{j}&=\sum_{i\in I_{j}}g_{i} \
H_{j}&=\sum_{i\in I_{j}}h_{i}
\end{aligned}
$$
简化形式:
$$
\mathcal{L}^{(t)}\approx\sum_{j=1}^{T}\left[G_{j}w_{j}+\frac{1}{2}(H_{j}+\lambda)w_{j}^{2}\right]+\gamma T
$$
最优叶子节点权重求解
对 $w_{j}$ 求导并令导数为零:
$$
\frac{\partial\mathcal{L}^{(t)}}{\partial w_{j}}=G_{j}+(H_{j}+\lambda)w_{j}=0
$$
最优解:
$$
w_{j}^{*}=-\frac{G_{j}}{H_{j}+\lambda}
$$
最优目标函数值计算
代入最优权重后的目标函数值:
$$
\mathcal{L}^{(t)*}=-\frac{1}{2}\sum_{j=1}^{T}\frac{G_{j}^{2}}{H_{j}+\lambda}+\gamma T
$$
树的分裂准则

最优分裂点选择:
$$
\max_{\text{所有可能分裂点}} \mathcal{L}_{split}
$$
图例

Softmax函数
根据下图,可以看到SoftMax函数的输出为0-1之间的概率,并且概率总和为1.
参考链接:
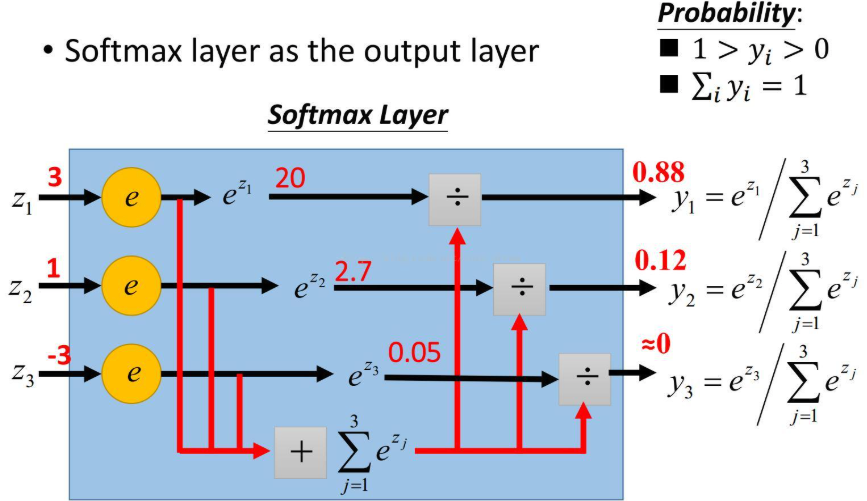
SoftMax函数表达式:
$$
y_i = \frac{e^{z_i}}{\sum_{k=1}^K e^{z_j}} \quad \text{for } i=1,…,K
$$
SoftMax函数特性:
- 将$K$维向量$\mathbf{z}$压缩为
概率分布,概率输出范围$(0,1)$,且所有元素和为1
SoftMax函数特性使得能够:突出最大值,抑制较小值,且便于反向传播
且SoftMax函数存在恒等变形,使得后续求导过程中非常有用:
$$
\frac{e^{z_{i}}}{\sum_{j} e^{z_{j}}} = 1 - \frac{\sum_{j \neq i} e^{z_{j}}}{\sum_{j} e^{z_{j}}}
$$
恒等变形推导:
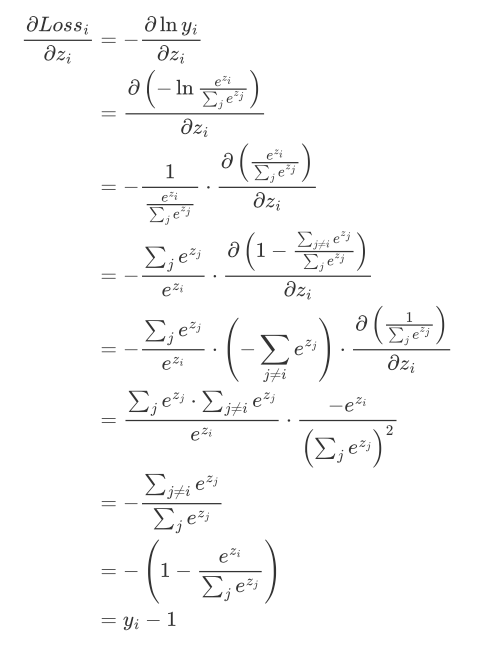
第四行:将 $\frac{e^{z_i}}{\sum_j e^{z_j}}$ 改写为 $1 - \frac{\sum_{j\neq i}e^{z_j}}{\sum_j e^{z_j}}$
第五、六行:对 $\frac{1}{\sum_j e^{z_j}}$ 求导会产生 $-e^{z_i}$ 项
SoftMax应用:
交叉熵损失函数定义:在多分类问题中,我们经常使用交叉熵作为损失函数:
$$
Loss = -\sum_{i} t_{i} \ln y_{i}
$$
其中:
- $t_{i}$ 表示真实标签(one-hot编码)
- $y_{i}$ 表示模型输出的softmax概率值
当预测第$i$个类别时(即真实类别为$i$),可以认为$t_{i}=1$,此时损失函数简化为:
$$
Loss_{i} = -\ln y_{i}
$$
根据上述求导可以得出SoftMax函数的最小值,于是求得损失函数的最小值。
深度学习
NLP
#朴素贝叶斯
#支持向量机
#EM算法
#HMM模型
 微信
微信 支付宝
支付宝