Fine-Tuning-Note
Day02
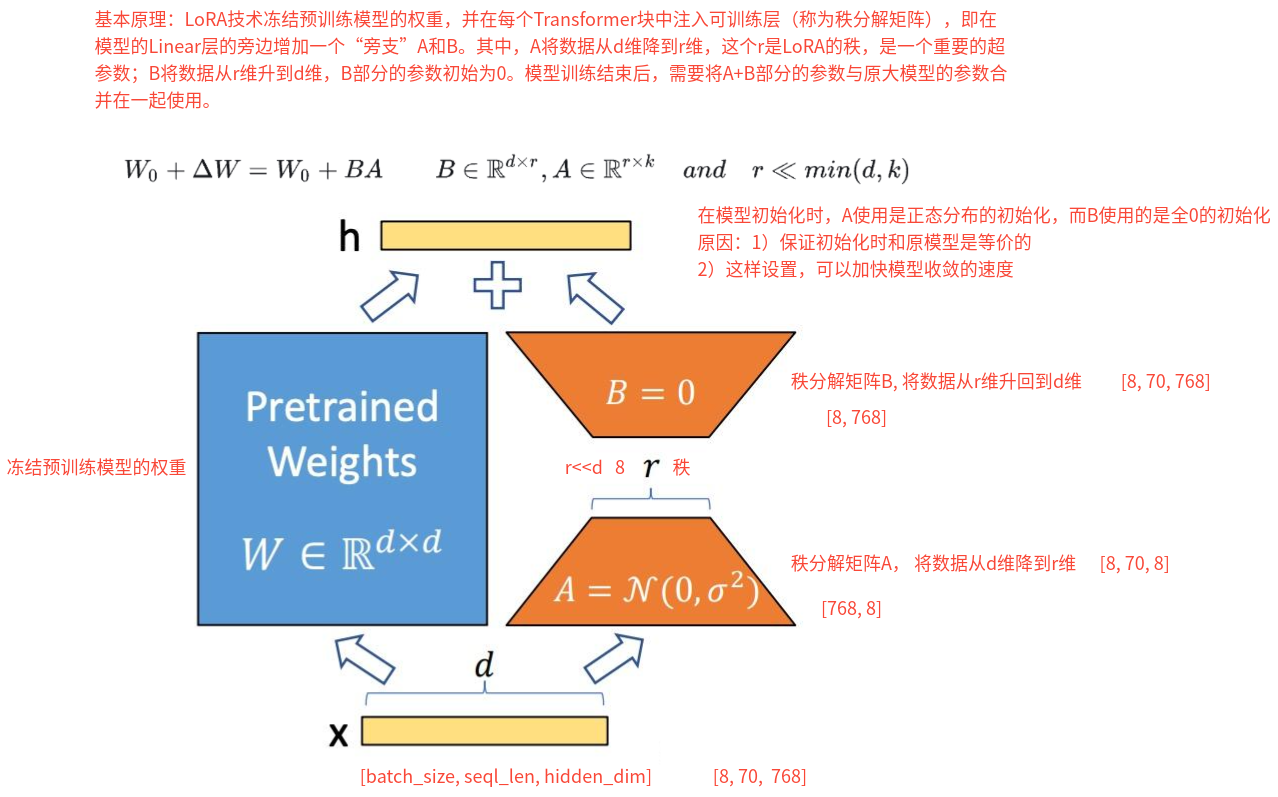
1、说一下LoRA的原理?
LoRA假设模型在适配新任务时,其权重的更新(ΔW)具有低内在秩(intrinsic low rank),因此可以将这个更新矩阵分解为两个更小的、可学习的矩阵A和B的乘积(即 ΔW = A × B)。在微调过程中,冻结原始模型的绝大部分参数,转而在PLM的特定线性层(如自注意力机制中的 Q、K、V 投影层和前馈网络)旁边,并行地注入一对小的、可训练的低秩分解矩阵。通过只训练这些低秩矩阵,LoRA就能让模型学习到新任务的知识,同时保持了原始模型的强大泛化能力,并极大地节省了计算资源和存储开销。
2、说一下LoRA的优缺点
- 优点:
- 只训练极少参数,相对全量微调的存储和训练成本低。
- 效果接近全参数微调,且保留原模型能力。
- 不同任务的 LoRA 模块可插拔,便于多任务部署。
- 缺点:
- LoRA 本质是用低秩分解逼近权重更新矩阵,这对参数空间的表达能力有限制,可能无法拟合某些复杂任务所需的高秩变化。
- LoRA 通常加在 attention 的投影矩阵(Wq/Wv)上,但不同任务可能对位置敏感,选择不好会影响性能。
- 相对来说,如果预训练模型的参数较大,则微调的门槛依然很高。
3、说一下QLoRA的原理?
核心思想:通过对预训练语言模型(PLM)进行量化(通常是 4-bit NormalFloat),并结合 LoRA 技术进行微调,从而在极低的内存消耗下,仍然能够高效地微调巨型语言模型,同时保持甚至超越全量 16-bit LoRA 的性能。
核心创新点:
- 使用专为正态分布的数据设计的
NF4量化,使得在极低精度下仍能保持接近 FP16 的模型性能。 - 采用双量化和分页优化器,进一步减少显存占用。
- 在量化后的冻结PLM上,LoRA的微调机制保持不变。
4、说一下微调的数据集格式
1 | { |
每一条数据都分为 context 和 target 两部分:
context部分是接受用户的输入。2.target部分用于指定模型的输出。
在 context 中又包括 2 个部分:
- Instruction:用于告知模型的具体指令,当需要一个模型同时解决多个任务时可以设定不同的 Instruction 来帮助模型判别当前应当做什么任务。
- Input:当前用户的输入。
5、说一下GLM模型的架构原理?
GLM(General Language Model,通用语言模型)是一种基于自回归空白填充(Autoregressive Blank Infilling)目标进行预训练的神经网络架构,旨在统一处理自然语言理解与生成任务。
其核心原理是将输入文本中的多个连续或离散的“空白片段”(masked spans)打乱顺序后填入一个特殊的提示符序列,模型则按随机排列的顺序,自回归地预测这些空白处的内容。这种独特的预训练任务设计,使得GLM能够同时吸收和融合自回归模型(如GPT)的生成能力和自编码模型(如BERT)的双向上下文理解能力。通过一个统一的模型架构和目标,GLM在文本分类、问答、摘要、翻译等多种下游任务上均表现出强大的性能,实现了“一个模型,多种任务”的通用性。
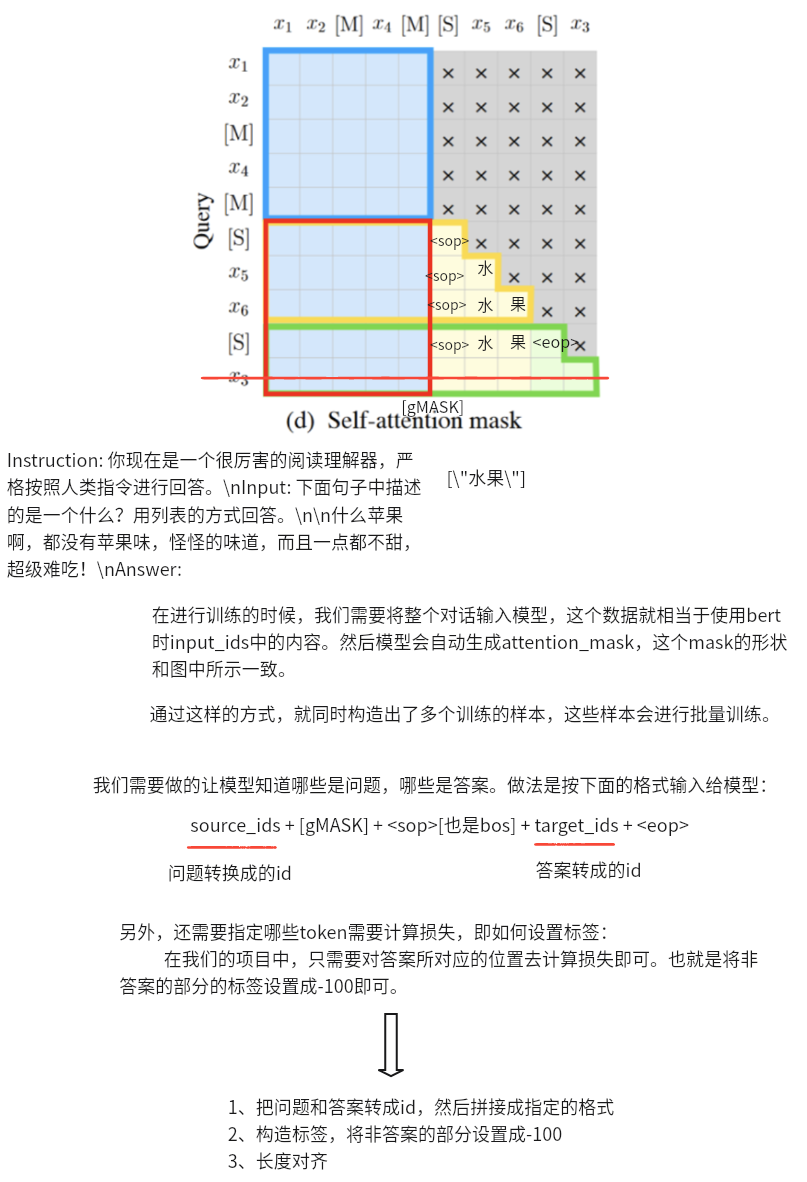
6、说一下微调时数据处理的思路
Day03
1、lora使用
lora模型配置:
1 | # 如果使用lora方法微调 |
TaskType及含义:
| TaskType | 中文名 | 适用模型架构 | 典型下游任务 |
|---|---|---|---|
CAUSAL_LM |
因果语言模型 | Decoder-only (e.g., GPT) | 文本生成、对话 |
SEQ_2_SEQ_LM |
序列到序列 | Encoder-Decoder (e.g., T5) | 翻译、摘要 |
SEQ_CLS |
序列分类 | Encoder-only (e.g., BERT) | 情感分析、NLI |
TOKEN_CLS |
Token 分类 | Encoder-only (e.g., BERT) | NER、词性标注 |
lora调用:
1 | loss = model( |
lora模型保存:
1 | def save_model(model, cur_save_dir: str): |
ptuning的用法:
1 | # 加载预训练模型的配置 |
2、训练优化
1、混合精度训练:
使用方式:
模型的配置:
1 | # model.half()将模型数据类型从默认的float32精度转换为更低的float16精度,减少内存 |
1 | 训练时的使用: |
效果:
通过使用混合精度训练,可以降低训练时对显存的占用!并且使模型最终的精度损失比较小。
2、关闭KVcache,减少显存占用:
用法:
1 | 不进行缓存,减少内存 |
效果:
本来的作用:use_cache 参数通常控制模型在生成(generation)时是否缓存注意力机制中的 Key (K) 和 Value (V) 矩阵。在自回归生成(如文本续写)过程中,模型会逐个生成 token。启用 use_cache 时,之前生成的 token 对应的 K/V 矩阵会被缓存起来,这样在生成下一个 token 时,就不需要重新计算历史 token 的 K/V,从而大大加快推理速度。
在训练时通常需要将其设置为False(尤其是在启用gradient_checkpointing时,因为缓存与checkpoint在某些实现上不兼容,会导致错误或额外的内存问题,把它设置成False后,可以避免相关冲突),训练时不进行KV缓存,可以降低显存的占用。
3、开启梯度检查点
1 | # 梯度检查点是一种优化技术,用于在反向传播过程中降低内存使用,保存部分激活值,未保存的反向传播时重新计算 |
核心思想是:不保存所有的中间激活值,而是只保存一部分关键点的激活值。当需要计算某个区间的梯度时,利用最近的一个检查点处的激活值,重新执行一次该区间的前向传播,以重新计算出所需的中间激活值。然后用这些重新计算出的值进行反向传播。
所以,使用这种方式之后,模型训练的时长会变长。所以需要根据实际情况去确定开启或不开启,如果显存够用,则不开启。
4、对输入层进行微调
1 | # 对输入层进行require_grads(进行参数更新,即微调) |
作用:允许把梯度传入输入层(嵌入层),对嵌入层进行微调。一般来说使用prompt tuning、lora、adapter tuning时,会把它开启,从而获取更好的微调效果。
3、lora微调结果如何评估?
LoRA 微调的结果评估,通常可以从以下几个方面简要说明:
- 下游任务性能
- 如果微调用于特定任务(如分类、生成、问答),可以直接在验证集或测试集上评估:
- 分类任务:准确率(Accuracy)、F1、精确率/召回率(Precision/Recall)
- 生成任务:BLEU、ROUGE、METEOR、Perplexity(困惑度)
- 问答任务:EM(Exact Match)、F1、大模型评估
- 如果微调用于特定任务(如分类、生成、问答),可以直接在验证集或测试集上评估:
- 损失函数变化
- 查看训练/验证集上的 Loss 下降趋势,判断模型是否收敛以及是否过拟合。
- 生成质量主观评估
- 对于生成任务,可以通过人工打分或者少量样例检查,观察文本是否符合预期风格、内容准确性和流畅度。
- 参数量和推理效率
- LoRA 的一个优势是低成本微调,因此可以评估微调后模型大小和推理速度是否满足需求。
4、lora微调效果不好,如何调整?
- LoRA 超参数调整
- rank(r)
- LoRA 的秩越大,模型学习能力越强,但也增加过拟合风险。
- 如果效果差,可尝试增大 rank。
- alpha(缩放因子)
- 控制 LoRA 权重对原模型的影响。
- 适当增大 alpha 可以让微调效果更明显。
- dropout
- 对 LoRA 层加 dropout 可防止过拟合。
- 如果训练数据量小,可以尝试增加 dropout。
- 训练策略优化
- 学习率
- 太高可能导致发散,太低学习不足。
- 可尝试学习率调度或微调学习率。
- 训练轮数 / 步数
- LoRA 通常需要较少步数,如果训练不足,可能效果差。
- 如果过拟合,可减少步数或早停。
- 梯度累积 / batch size
- 增大 batch size 或梯度累积有助于稳定训练。
- 数据质量与数量
- 数据量不足
- LoRA 对小数据量敏感,如果数据量太少,效果可能差。
- 尝试增加标注数据或做数据增强。
- 数据噪声
- 错误或不一致的标注会影响微调效果。
- 清洗数据,提高质量。
- 模型与任务匹配
- 基础模型选择
- 有些基础模型更适合特定任务,例如 GPT 系列更适合生成,BERT 系列更适合分类。
- 如果基础模型不适合任务,微调效果有限。
- LoRA 微调层选择
- 不同层微调效果差异明显,一般优先微调 transformer 的 attention 或 feed-forward 层。
- 可以尝试只微调部分关键层。
- 融合策略
- 混合微调
- LoRA + P-Tuning 或 LoRA + 少量 full-parameter 微调,有时效果更好。
 微信
微信 支付宝
支付宝