
OLLAMA
Ollama大模型
Ollama是什么?
答:一只羊驼,不信可以去官网看看(doge)。
但是通过认知的不断完善我们可以发现,
Ollama是一款旨在简化大型语言模型本地部署和运行过程的开源软件。Ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)。通过Ollama,开发者可以访问和运行一系列预构建的模型,或者导入和定制自己的模型,无需关注复杂的底层实现细节。
Ollama的主要功能包括快速部署和运行各种大语言模型,如Llama 2、Code Llama等。它还支持从GGUF、PyTorch或Safetensors格式导入自定义模型,并提供了丰富的API和CLI命令行工具,方便开发者进行高级定制和应用开发。
给我个人的感觉就是类似于声音大模型UVR5或者MSST的模型部署运行软件。

Ollama下载
Ollama共支持三种平台:
Ollama安装与DeepSeek大模型部署
Ollama跟别的软件一样都是需要解压安装后需要修改一些配置文件的。
手动安装
window和mac版本直接下载安装或解压即可使用。由于Ollama需要安装在linux中,且工作中如果接触有内网环境,所以需要知道如何手动安装:
Step 1. 安装
在虚拟机/root/resource目录中已经下载好Linux版本所需的ollama-linux-amd64.tgz文件,则执行下面命令开始安装:
操作成功之后,可以通过查看版本指令来验证是否安装成功
2
3
Warning: could not connect to a running Ollama instance
Warning: client version is 0.3.9Step 2. 添加开启自启服务
创建服务文件/etc/systemd/system/ollama.service,并写入文件内容:
2
3
4
5
6
7
8
9
10
11
12
13
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=root
Group=root
Restart=always
RestartSec=3
[Install]
WantedBy=default.target生效服务:
2
sudo systemctl enable ollama启动服务:
一键安装
Ollama在Linux上也提供了简便的安装命令,工作中一般采用下面命令进行安装:
1 | curl -fsSL https://ollama.com/install.sh | sh |
修改模型路径
在虚拟机中已经提前下载好了相关模型(包括后续用到的模型),存储在/root/ollama目录中,因此这里我们需要修改ollama的模型路径,ollama软件在各个操作系统上的默认存储路径是:
macOS: ~/.ollama/models
Linux: ~/.ollama/models
Windows: ~/.ollama/models
要修改其默认存储路径,需要通过设置系统环境变量来实现,即在/etc/profile文件中最后增加一下环境变量:
vim /etc/profile
1 | export OLLAMA_MODELS=/root/ollama |
然后执行一下命令,生效环境变量:
1 | [root@bogon ollama]# source /etc/profile |
然后重新ollama服务,则会跳过下载,直接进入大模型,对话完成后可以通过/bye指令终止对话:
1 | [root@bogon ollama]# systemctl stop ollama |
让重启也支持模型路径:
上述方式修改后,通过ollama命令是生效的,但是重启电脑则不生效,要解决这个问题,则还需要进行如下配置:
修改服务文件/etc/systemd/system/ollama.service内容为一下::
1 | [Unit] |
生效修改的配置:
1 | systemctl daemon-reload |
DeepSeek大模型部署
直接通过Ollama pull命令拉取deepseek模型
或者通过命令:
ollama run 模型名称:模型规模运行模型,如果没有则会自动拉取
1 | ollama pull deepseek-r1:1.5b |
Ollama终端命令&对话指令(※)
终端命令
下载模型:ollama pull deepseek-r1:1.5b
- 标准:ollama pull MODEL[:Version] [flags]
- [:Version] 可以理解成版本,但在这里理解成大模型规模,可以不写,不写则模式成latest
- [flags] 参数,目前只有一个–insecure参数,用于来指定非安全模式下载数据
运行模型:ollama run qwen2
- 或者:ollama run qwen2:latest(同上)
查看模型的信息:ollama show -h
2
3
4
5
6
7
8
9
10
11
12
13
Show information for a model
Usage:
ollama show MODEL [flags]
Flags:
-h, --help 查看使用帮助
--license 查看模型的许可信息
--modelfile 查看模型的制作源文件Modelfile
--parameters 查看模型的内置参数信息
--system 查看模型的内置Sytem信息
--template 查看模型的提示词模版
查看本地下载的大模型列表:ollama list
- 也可以使用简写ls:ollama ls
- 列表字段说明:
- NAME:名称
- ID:大模型唯一ID
- SIZE:大模型大小
- MODIFIED:本地存活时间
删除本地大模型:ollama rm qwen2:0.5b
查看当前运行的大模型列表,PS命令没其它参数:ollama ps
对话指令
- /show指令
/show 指令:用于查看当前模型详细信息
2
3
4
5
6
7
8
9
>> /show
Available Commands:
/show info 查看模型的基本信息
/show license 查看模型的许可信息
/show modelfile 查看模型的制作源文件Modelfile
/show parameters 查看模型的内置参数信息
/show system 查看模型的内置Sytem信息
/show template 查看模型的提示词模版
- /? shortcuts 指令
查看在控制台中可用的快捷键
1 | >>> /? shortcuts |
- “”” 指令
“”” 用于输入内容有换行时使用,如何多行输入结束也使用 “””
1 | >> """ |
- /set 指令
set指令主要用来设置当前对话模型的系列参数
1 | >>> /set |
设置对话参数
1 | >>> /set parameter |
| Parameter | Description | Value Type | Example Usage |
|---|---|---|---|
| num_ctx | 设置上下文token大小. (默认: 2048) | int | num_ctx 4096 |
| repeat_last_n | 设置模型要回顾的距离以防止重复. (默认: 64, 0 = 禁用, -1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设置惩罚重复的强度。较高的值(例如,1.5)将更强烈地惩罚重复,而较低值(例如,0.9)会更加宽容。(默认值:1.1) | float | repeat_penalty 1.1 |
| temperature | 模型的温度。提高温度将使模型的答案更有创造性。(默认值:0.8) | float | temperature 0.7 |
| stop | 设置停止词。当遇到这种词时,LLM将停止生成文本并返回 | string | stop “AI assistant:” |
| top_k | 减少产生无意义的可能性。较高的值(例如100)将给出更多样化的答案,而较低的值(例如10)将更加保守。(默认值:40) | int | top_k 40 |
- /clear 指令
在命令行终端中对话是自带上下文记忆功能,如果要清除上下文功能,则使用/clear指令清除上下文内容,例如:
前2个问题都关联的,在输入/clear则把前2个问题的内容给清理掉了,第3次提问时则找不到开始的上下文了。
1 | >>> 请帮我出1道java list的单选题 |
- /load 指令
load可以在对话过程中随时切换大模型
1 | >> 你是什么大模型 |
- /save 指令
可以把当前对话模型存储成一个新的模型
1 | >> /save test |
保存的模型存储在ollama的model文件中,进入下面路径即可看见模型文件test:
1 | [root@bogon library]# pwd |
小结
- /bye指令 :退出当前控制台对话
- /show指令:用于查看当前模型详细信息
- /load指令:可以在对话过程中随时切换大模型
- /set指令:指令主要用来设置当前对话模型的系列参数
- clear指令:清除上下文内容
Ollama的API接口(※)
Ollama对客户端相关的命令也提供API操作的接口,方便在企业应用中通过程序类操作私有大模型。
开通远程访问
为了在本机(开发环境)中能访问虚拟机中的Ollama API,我们需要先开通Ollama的远程访问权限:
Step 1:增加环境变量
在/etc/profile中增加一下环境变量:
vim /etc/profile
1 | export OLLAMA_HOST=0.0.0.0:11434 |
然后通过一下命令,生效环境变量:
1 | source /etc/profile |
Step 2:增加服务变量
修改服务文件/etc/systemd/system/ollama.service内容为一下:
vim /etc/systemd/system/ollama.service
1 | [Unit] |
生效修改的配置:
1 | systemctl daemon-reload |
Step 3:开通防火墙
1 | firewall-cmd --zone=public --add-port=11434/tcp --permanent |
也可以关闭防火墙:
1 | systemctl stop firewalld |
接口说明文档
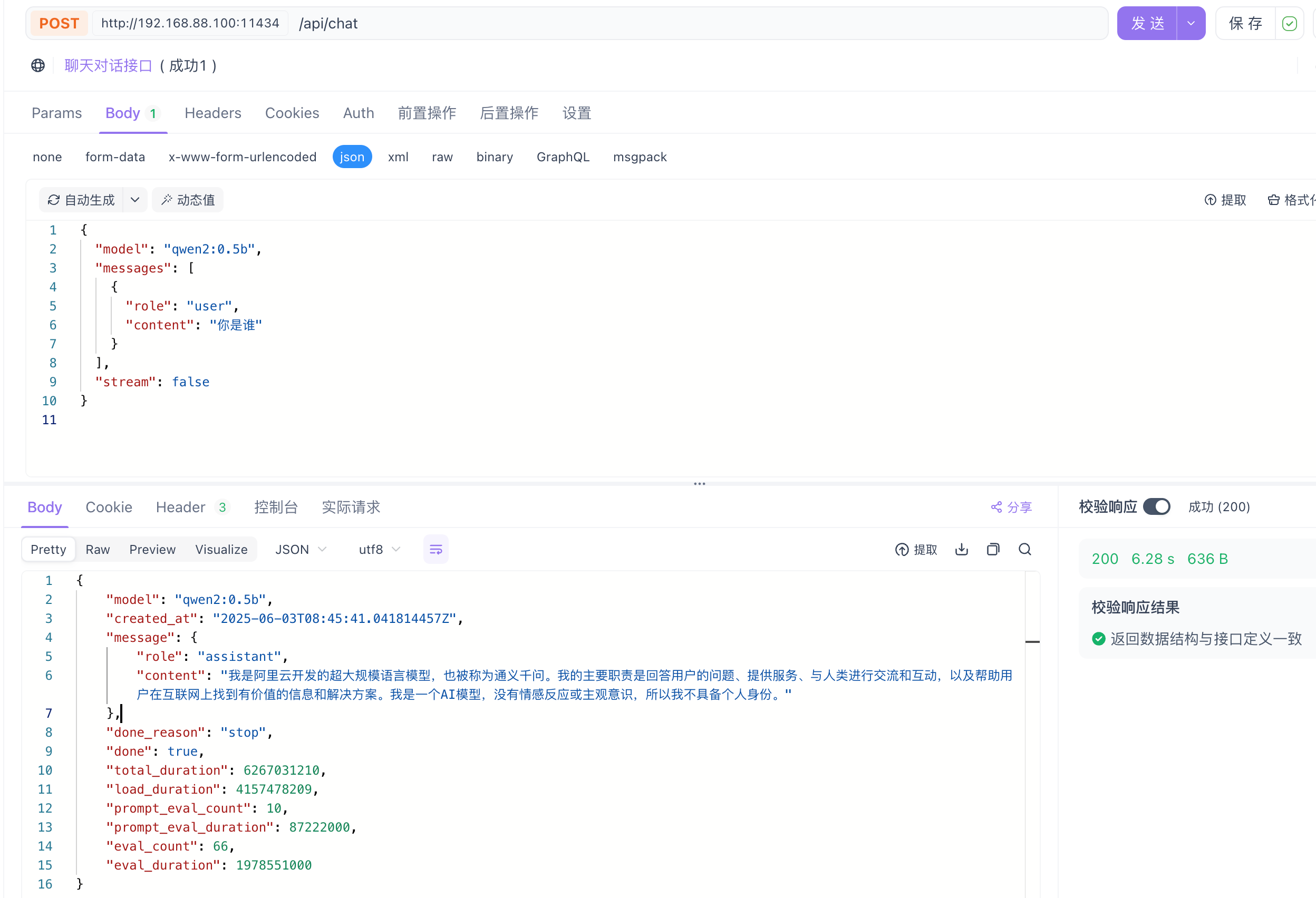
这里使用API调用大模型最重要的就是跟大模型对话、是实现类似ChatGPT、文心、通义千问等网页对话功能的关键接口,请求的地址与参数如下:
POST /api/generate
接口请求实例:
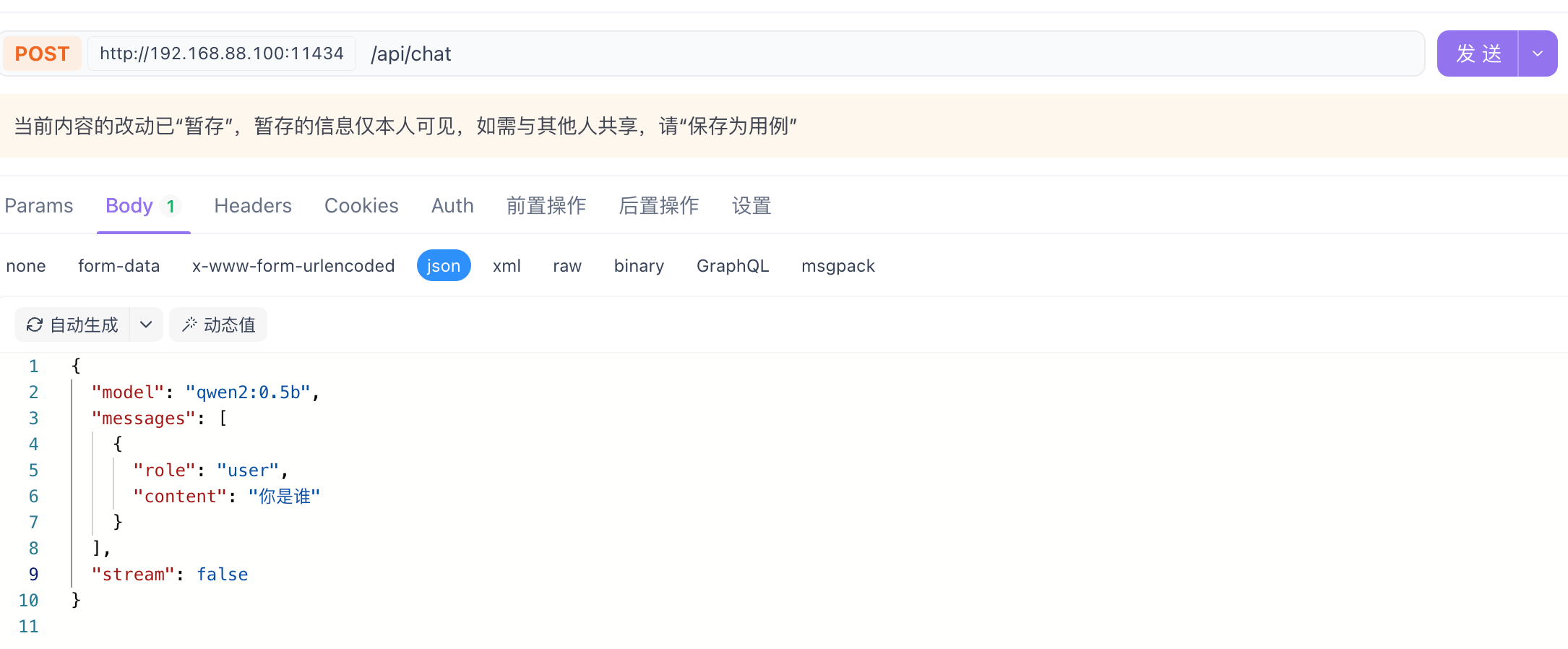
1 | { |
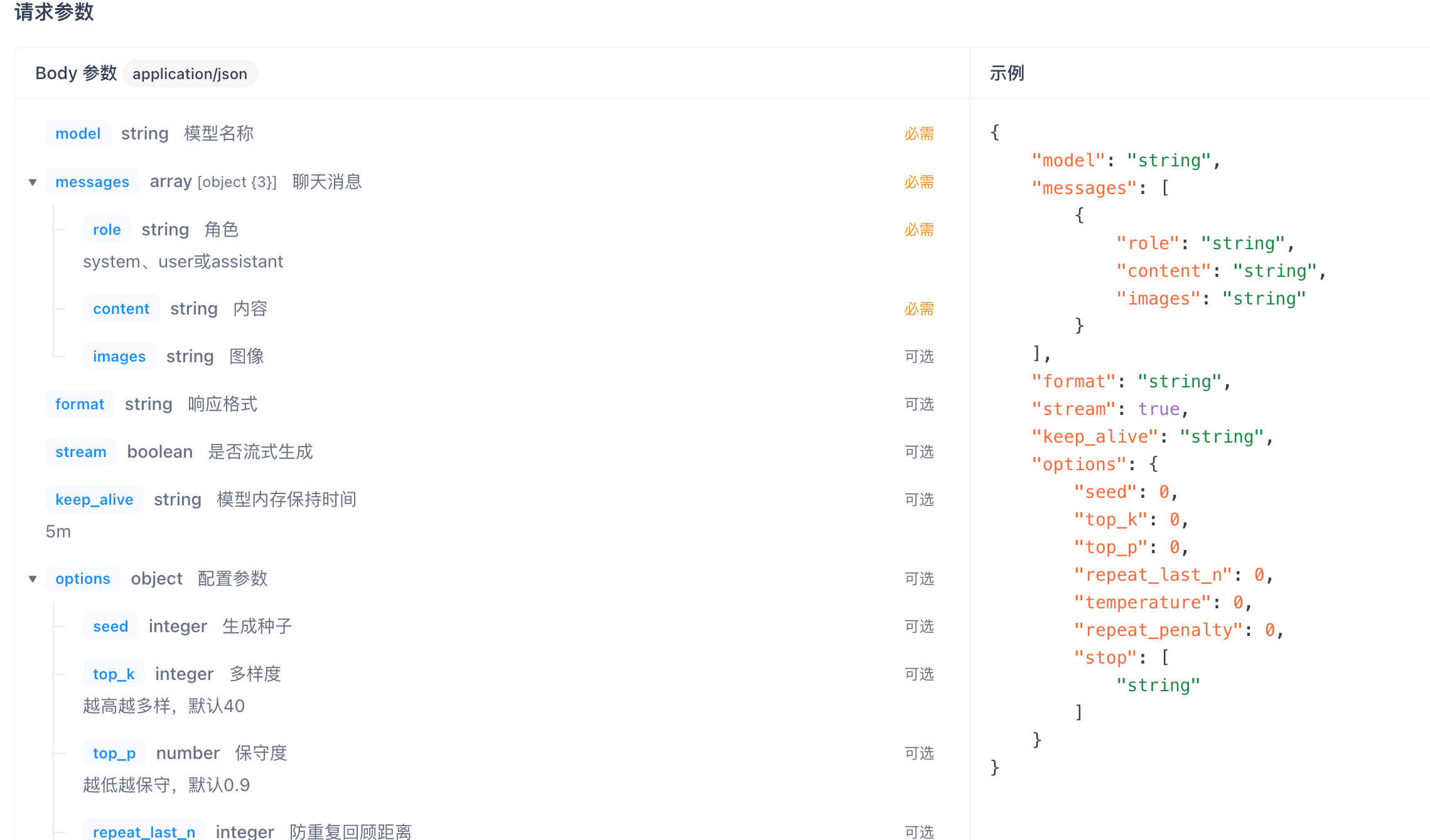
请求参数说明
| 名称 | 位置 | 类型 | 必选 | 中文名 | 说明 |
|---|---|---|---|---|---|
| body | body | object | 否 | none | |
| model | body | string | 是 | 模型名称 | none |
| messages | body | [object] | 是 | 聊天消息 | none |
| role | body | string | 是 | 角色 | system、user或assistant |
| content | body | string | 是 | 内容 | none |
| images | body | string | 否 | 图像 | none |
| format | body | string | 否 | 响应格式 | none |
| stream | body | boolean | 否 | 是否流式生成 | none |
| keep_alive | body | string | 否 | 模型内存保持时间 | 5m |
| tools | body | [object] | 否 | 工具 | |
| options | body | object | 否 | 配置参数 | none |
| seed | body | integer | 否 | 生成种子 | none |
| top_k | body | integer | 否 | 多样度 | 越高越多样,默认40 |
| top_p | body | number | 否 | 保守度 | 越低越保守,默认0.9 |
| repeat_last_n | body | integer | 否 | 防重复回顾距离 | 默认: 64, 0 = 禁用, -1 = num_ctx |
| temperature | body | number | 否 | 温度值 | 越高创造性越强,默认0.8 |
| repeat_penalty | body | number | 否 | 重复惩罚强度 | 越高惩罚越强,默认1.1 |
| stop | body | [string] | 是 | 停止词 | none |
返回示例
1 | { |
- 返回结果
| 状态码 | 状态码含义 | 说明 | 数据模型 |
|---|---|---|---|
| 200 | OK | 成功 | Inline |
- 返回数据结构
状态码 200 时才返回以下信息。
| 名称 | 类型 | 必选 | 约束 | 中文名 | 说明 |
|---|---|---|---|---|---|
| model | string | true | none | 模型 | none |
| created_at | string | true | none | 响应时间 | none |
| message | object | true | none | 响应内容 | none |
| role | string | true | none | 角色 | none |
| content | string | true | none | 内容 | none |
| tool_calls | [object] | false | none | 调用的工具集 | |
| done | boolean | false | none | none | |
| total_duration | integer | false | none | 总耗时 | none |
| load_duration | integer | false | none | 模型加载耗时 | none |
| prompt_eval_count | integer | false | none | 提示词token消耗数 | none |
| prompt_eval_duration | integer | false | none | 提示词耗时 | none |
| eval_count | integer | false | none | 响应token消耗数 | none |
| eval_duration | integer | false | none | 响应耗时 | none |
- 对话操作演示
视觉识别接口
也就是大模型可以分析图片,咱们可以上传一张图片让大模型识别,并结合图片进行提问。
Step 1:私有化多模态大模型
LLaVA( Large Language and Vision Assistant)是一个开源的多模态大模型,它可以同时处理文本、图像和其他类型的数据,实现跨模态的理解和生成。
1 | ollama run llava |
Step 2:准备图片素材
准备一张图片:

然后通过程序把图片数据转出Base64字符串:
1 | import base64 |
生成的Base64也可以在【资料/多模态测试图片Base64字符串.txt 】中找到。
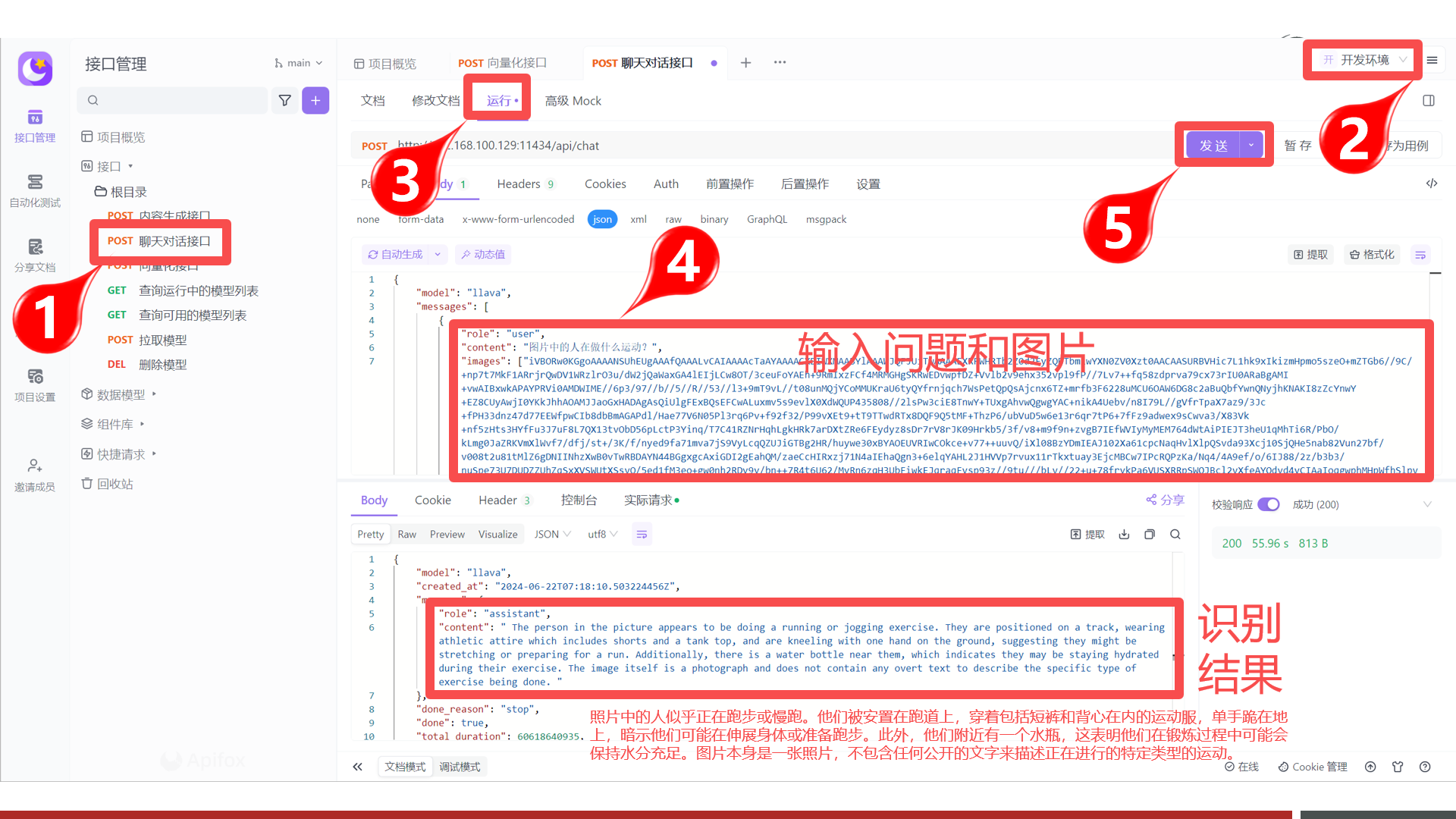
Step 3:调用多模态接口
在Ollama中可以通过内容生成接口和聊天对话接口来支持多模态,在此以聊天对话接口为例:
- 图片信息通过images字段传入,且可传入多张
- 识别的结果为引文,需要自行翻译
ChatBox集成Ollama
说白了就是将命令行的输出进行美化,以两人对话的形式进行呈现。
Step 1:运行本地大模型
1 | ollama run qwen2 --keepalive 1h |
命令说明:
- 命令运行的是通义大模型
- 通过
--keepalive参数设置大模型被加载到内存中的存活时长为1小时
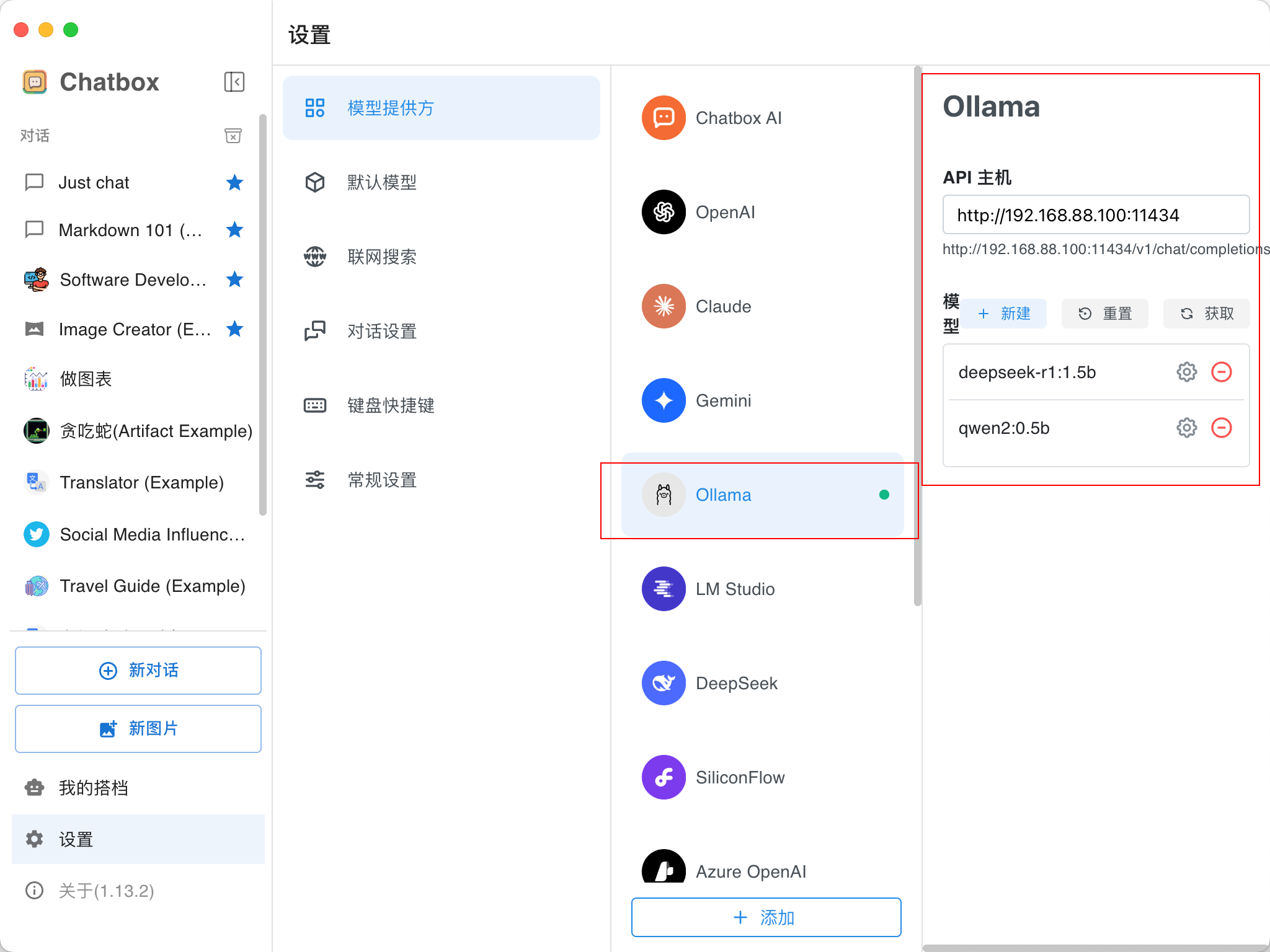
Step 2:配置Ollama信息
安装ChatBox并在设置中输入Ollama的地址,为Linux的Ollama,端口为11434
 微信
微信 支付宝
支付宝





