Day01 1、什么是知识图谱? 概念:知识图谱是以图的形式来表示实体和实体之间关系的语义网络。
类型有两种:
实体-关系-实体【通常的说法!!】
实体-属性-属性值
2、项目的技术架构图是怎样的?
数据获取
业务数据:比较规范,一般可以直接使用构建知识图谱
采集数据:形式各异,需要进行清洗和信息抽取工作
信息抽取【核心】
工作:实体抽取、关系抽取、属性抽取
方法:规则匹配、机器学习、深度学习
知识融合
任务:消除冗余、解决冲突、统一表达、知识扩展
技术:指代消解、实体消岐、知识融合(实体对齐、关系对齐)
知识加工
图谱搭建
图谱应用
3、项目用到了哪些工具?
Doccano(多卡诺)是一种用于文本标注的开源工具,支持多种常见的文本标注任务,如命名实体识别、文本分类、关系抽取等。
Flask 是一个轻量级的 Python Web 框架,它的核心作用是帮助开发者快速构建 Web 应用程序和 API,实现使用URL对函数进行调用 。
Gunicorn是一个被广泛使用的高性能的Python WSGI UNIX HTTP服务组件(WSGI: Web Server Gateway Interface)
核心作用是为 Python Web 应用(如 Flask、Django)提供生产级并发、稳定性等。
具有使用非常简单,轻量级的资源消耗,以及高性能等特点。
Neo4j是一个高性能的图数据库,作为核心的知识存储和查询数据库。
4、为什么不用MySQL来存储三元组数据?
多跳关联查询需要多表连接,效率低
MySQL 是面向关系表结构设计的,缺乏对三元组语义和图结构的原生支持
5、什么是实体和NER?
实体:文本之中承载信息的语义单元。如人名、地名、机构名等。
实体抽取:又称为命名实体识别(named entity recognition,NER),指的是从文本之中抽取出命名性实体,并把这些实体划分到指定的类别。
6、命名实体识别有哪些方法? (1)基于规则的方法
针对有特殊上下文的实体,或实体本身有很多特征的文本,使用规则的方法简单且有效。比较适合半结构化或比较规范的文本中的进行抽取任务。
方法:
【设计规则的模版(词典+正则表达式)再去进行匹配】
优缺点
优点:简单,快速。
缺点:适用性差,维护成本高后期甚至不能维护。
(2)基于传统机器学习的方法
一般使用统计模型是把实体抽取任务转化为【序列标注问题】,使用IO、BIO、BIOES等标注方法对实体进行标注。对于文本之中的每个词,或者汉语之中的每个字,都有若干候选的标签
基于序列标注方法的统计模型,常见的包括:支持向量机(SVM)、隐马尔科夫模型(HMM)、条件随机场(CRF)等。在实际研究之中,研究人员往往把这些模型和其他方法结合在一起。
优缺点
优点:统计学习方法较之基于规则的方法,更加灵活和健壮,可以移植到其他领域。
缺点:特征的选择是至关重要的。这些模型依赖人工设计的特征和现有的自然语言处理工具(如分词工具)。
常见的特征可以分为形态、词汇、句法、全局特征、外部信息等。
(3)基于深度学习的方法
大量的深度学习模型被使用到实体抽取任务之中。
方法:基于深度学习的方法主要使用神经网络模型,结合条件随机场模型。
常用的神经网络模型包括卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等,其中【BiLSTM+CRF】是目前最为常用的命名实体识别模型.
优缺点
优点:不需要人工来设计特征,同时能够取得较高的准确率和召回率。缺点:这些模型十分依赖人工标注数据,标注语料的缺乏为模型的训练带来了极大的困难。
7、举个例子描述一下如何使用规则的方法抽取实体? 例子:比如要从一段新闻报道中识别出机构名。
规则:
思路:
1)先构建词典,用于定位结构名的结束位置
2)使用jieba的词性标注对文本进行序列标注,获取分词结果及对应的词性
3)根据规则将词标注为B、E或O
其中词性为ns的,即地名的,标注为B
词在词典中,标注成E
其余标注为O
4)然后使用正则表达式从标注序列中取出机构名
Day02 1、LSTM面试题
因为在RNN的反向传播时,梯度要经过多个时间步的链式相乘,而每个时间步使用的是相同的权重矩阵,就会造成梯度消失或爆炸!——当权重矩阵的特征值小于 1 时,梯度会指数级衰减(梯度消失);而当特征值大于 1 时,则会指数级增长(梯度爆炸)
LSTM的门控机制使得LSTM可以“选择性地”记忆和遗忘信息,从而有效缓解了梯度消失和梯度爆炸的问题,能够更好地捕捉序列中的长时间依赖关系。因此,LSTM相较于普通RNN在处理长序列任务(如文本生成、语音识别、时间序列预测等)中表现更为出色。
Bi-LSTM相比LSTM能同时捕捉前后文信息,提升序列建模效果,但计算成本更高、训练时间更长。
2、什么是线性链条件随机场(Linear-chain-CRF)? 线性链条件随机场是一类给定线性输入序列 𝑋 的条件下,输出线性标签序列 𝑌 的概率分布 𝑃(𝑌∣𝑋)的概率模型。其中每个位置的标签只依赖于它前后相邻的标签以及线性序列 𝑋 ,而不依赖于更远处的标签。
3、描述一下BiLSTM+CRF架构? BiLSTM+CRF架构主要由两部分构成,
第一部分:使用BiLSTM生成发射分数(有输入层、词嵌入层、BiLSTM层、线性层)
BiLSTM层捕捉文本前后向信息
线性层输出标签的概率分布
第二部分:基于BiLSTM生成的发射分数使用CRF获取最优的标签路径
CRF层来预测标签概率最大的标签路径
Viterbi解码:在预测时,解码概率最大的标签路径
4、CRF中的发射分数和转移分数是什么?
5、说一下CRF建模的损失函数是怎样的? 首先计算出真实路径的概率,然后让该概率值越大越好!!也就是让真实路径概率值最大时,估计未知参数的值,从而将问题转变成极大似然估计问题。
在问题求解中通过加负数,将求最大转换成求最小,通过求对数,将连除形式转换成对数减法形式,即负对数似然损失 !
最终损失函数有两部分组成,一部分是归一化项,一部分真实路径的分数。求解归一化项时使用的方法是前向算法的动态规划!
说一下什么叫极大似然估计?
找到一组参数,使得在这些参数下,观察到的数据出现的概率最大。
6、前向算法是什么? 首先:单条路径的分数怎么算的?
每条路径的分数就是由对应的发射分数和转移分数组合而成的。
背景:如果标签数量是𝑘,文本长度是𝑛,那么有k^n条路径,不能遍历每条路径获得所有路径的分数。
办法:使用前向算法的动态规划
目的:计算给定观测序列的概率总和。
过程:通过动态规划的方法,逐步计算每个时刻每个状态的累加概率,以得到最终的观测序列概率总和。
特点:关注所有状态路径的累加值,计算的是所有路径的概率总和。
递推公式:
7、Viterbi解码是什么? 目的:寻找给定观测序列下最可能的状态序列。
过程:同样使用动态规划,但在每一步中只保留最优路径(即最大概率路径),而不是所有路径。
特点:关注最优路径,只保留最大概率路径,而非所有路径。
Day03 1、在项目中,应该如何设置路径? 1)为了项目可移植性,需要配置成相对路径
2)为了避免文件在调用时,路径随着调用位置变化而变化,需要使用如下的方法
1 2 3 4 5 6 7 base_dir = os.path.dirname(os.path.abspath(__file__)) print (f'base_dir-->{base_dir} ' )path = os.path.join(base_dir, '../data/labels.json' ) print (f'拼接后的path-->{path} ' )
2、简单说一下数据处理的最终格式要求? 1)分样本的,每个样本是一个句子,并且是一个X,Y数据对
2)训练数据为id,而不是文字或者标签值
3)拆分出训练集和验证集,封装到DataLoder中
4)每个批次中样本的长度是一样的
3、在将原始数据处理成最终的格式要求时,一般可以在哪些地方做处理? 1)直接读取数据文件,然后将数据加工成想要的格式。一般用于比较复杂的数据清洗和转换操作。
2)在构造Dataset类时做处理。可以做一些x,y的封装、数据类型转换等。
3)在创建Dataloader时,在自定义函数collate_fn()中做处理。可以做一些id的转换、数据类型转换、长度对齐、生成掩码张量等。
4、在构造数据迭代器(Dataloader)时,有哪些步骤? 1)构建Dataset类
5、统一样本长度有哪些方法? 1)使用sequence来处理列表
1 2 3 4 5 6 7 from keras.preprocessing import sequence''' x_train: 文本的张量表示 max_len:最大的句子长度 可以通过padding和truncating设置补齐或截断的方向,默认是pre ''' return sequence.pad_sequences(x_train, max_len, padding="post" , truncating="pre" , value=0 )
2)使用pad_sequence来处理张量或者张量列表
1 2 3 4 5 6 from torch.nn.utils.rnn import pad_sequence''' pad_sequence:可以对一个批次的样本进行统一长度,统一长度的方式是以该批次中最长的样本为基准 batch_first=True,则返回的数据形状为[batch_size, max_seq_len] padding_value是指用什么补齐 ''' input_ids_padded = pad_sequence(x_train, batch_first=True , padding_value=0 )
3)使用BertTokenizer的batch_encode_plus来处理列表
1 2 3 4 5 6 7 8 my_tokenizer = BertTokenizer.from_pretrained('bert-base-chinese' ) data = my_tokenizer.batch_encode_plus(batch_text_or_text_pairs=sents, truncation=True , padding='max_length' , max_length=500 , return_tensors='pt' , return_length=True )
4)使用自定义的方法
6、描述一下BiLSTM_CRF模型的架构?
Day04 1、训练函数基本步骤是什么? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1.构建数据迭代器Dataloader(包括数据处理与构建数据源Dataset) 2.实例化模型 3.实例化损失函数对象 4.实例化优化器对象 5.定义打印日志参数 6.开始训练 6.1 实现外层大循环epoch 6.2 将模型设置为训练模式 6.3 内部遍历数据迭代器dataloader 1)将数据送入模型得到输出结果 2)计算损失 3)梯度清零 : optimizer.zero_grad() 4)反向传播(计算梯度) : loss.backward() 5)梯度更新(参数更新) : optimizer.step() 6)打印内部训练日志 6.4 使用验证集进行模型评估【将模型设置为评估模式】 6.5 保存模型: torch.save(model.state_dict(), "model_path") 6.6 打印外部训练日志
2、验证函数基本步骤是什么? 1 2 3 4 5 6 7 8 1.定义打印日志参数 2.将模型设置为评估模式 3.内部遍历数据迭代器dataloader 3.1 将数据送入模型得到输出结果 3.2 计算损失 3.3 处理结果 3.4 统计批次内指标 4.统计整体指标
3、BiLSTM_CRF模型在训练完后,可以做哪些优化来改善模型性能? 1)模型优化
预训练词向量:使用预训练的词向量(如Word2Vec、GloVe、FastText)替代随机初始化的词嵌入,可以更好地捕捉词汇语义信息。
自注意力机制:在BiLSTM后加入自注意力层,增强模型对长距离依赖的捕捉能力。
调整随机失活层:可以在embedding层后添加随机失活层,也可以修改随机失活比例。
2)训练过程优化
shuffles设置:注意真正训练时,需要将DataLoader中的shuffle设置为True
梯度裁剪:在反向传播时对梯度进行裁剪,防止梯度爆炸。
早停机制:监控验证集F1值,若连续多个epoch未提升则提前终止训练。
3)训练数据优化
如果训练集和验证集数据分布不同,也就是说使用的是差距很大的样本,会使模型的效果较差,所以可以将数据打散后再送到dataloader中
1 2 3 4 5 6 7 def get_data (): random.seed(66 ) random.shuffle(datas) train_dataset = NerDataset(datas[:6300 ])
除了这种方式之外,也可以使用分类采样的方式。这种方式可以绝对类型上,训练集和验证集的分布是一致的。
另外,还有以下方法——
更多数据:收集或标注更多数据,送到模型中进行训练。
随机替换:随机替换部分词为同义词或近义词,增强模型鲁棒性。
实体替换:保留实体边界,随机替换实体内容(如疾病名称、药品名称),提升实体识别泛化能力。
4、precision、recall、f1、report的使用方式是什么? 1 2 3 4 5 6 7 from sklearn.metrics import precision_score, recall_score, f1_score, classification_reportprecision = precision_score(golds, preds, average='micro' ) recall = recall_score(golds, preds, average='micro' ) f1 = f1_score(golds, preds, average='micro' ) report = classification_report(golds, preds)
其中golds和preds要求的格式要求为:
1)1D 数组(最常见)
Python 列表:[0, 1, 1, 0, 2]
NumPy 数组:np.array([0, 1, 1, 0, 2])
Pandas Series:pd.Series([0, 1, 1, 0, 2])
适用于 多分类、二分类、单标签 情况:
1 2 y_true = [0 , 1 , 1 , 0 , 2 ] y_pred = [0 , 0 , 1 , 0 , 2 ]
2)Label Indicator Array / Sparse Matrix
适用于 多标签分类(multi-label classification):
label indicator array:二维数组,每一列表示一个类别,值为 0/1,表示每个类别的有无。
1 2 3 4 5 6 y_true = [[1 , 0 , 1 ], [0 , 1 , 0 ], [1 , 1 , 0 ]] y_pred = [[1 , 0 , 0 ], [0 , 1 , 1 ], [1 , 0 , 0 ]]
含义是:
第一行:属于类别 0 和 2
第二行:属于类别 1
第三行:属于类别 0 和 1
把数据组装成一维列表的方法:
1 2 3 4 5 6 7 8 9 real_len = (input_ids>0 ).sum (-1 ).tolist() for index, label in enumerate (predict): preds.extend(label[:real_len[index]]) for index, label in enumerate (labels.tolist()): golds.extend(label[:real_len[index]])
5、模型预测基本步骤是什么? 1 2 3 4 5 1. 实例化模型2. 加载训练好的模型参数3. 处理数据4. 模型预测5. 结果处理
Day05 1、什么是关系抽取?本质是什么? 关系抽取就是从一段文本中抽取出 (主体,关系,客体) 这样的三元组
本质是:文本分类问题
关系抽取的常用方法有哪些?
基于规则方式实现关系抽取
基于机器学习
基于深度学习
基于Pipeline流水线方法实现关系抽取:在实体识别已经完成的基础上再进行实体之间关系的抽取
基于Joint联合抽取方法实现关系抽取:修改标注方法和模型结构直接输出文本中包含的(ei ,rk, ej)三元组
3、关系抽取任务常见问题有哪些?
正常关系 (Normal) 问题:数据中只有一个实体对及关系
单一实体关系重叠问题 (Single Entity Overlap (SEO) ):数据中一个实体参与到了多个关系中
BiLSTM+Attention模型即可解决,一个句子中有几个三元组就构建几个样本即可
实体对重叠(Entity Pair Overlap (EPO)):数据中一个实体对有两种不同的关系类型
4、基于规则的方法实现关系抽取的优缺点是什么?
优点:实现简单、无需训练,小规模数据集容易实现.
缺点:
无法解决复杂的场景
对跨领域的可移植性较差、人工制作规则的成本较高以及召回率较低.
5、描述一下BiLSTM+Attention模型的架构?
6、注意力机制是什么? 注意力机制是什么?
注意力机制(Attention)是一种动态加权的方法,它通过计算“查询”(query)与一组“键”(keys)之间的相似度来为对应的“值”(values)分配不同的重要性权重,从而使模型能够在处理序列或图像等输入时,重点关注与当前任务最相关的部分信息。
优势:
捕捉长距离依赖:不再依赖 RNN 的逐步传递,能直接建模序列中任意两位置的依赖关系。
并行计算:尤其在 Transformer 中,注意力计算可以大范围并行,极大加速训练。
可解释性:通过可视化注意力权重,可以了解到模型在处理时重点关注了哪些输入位置。
7、描述一下BiLSTM+Attention模型中注意力机制是如何实现的? 首先对 BiLSTM 的输出进行非线性变换,得到初步的语义特征表示;然后通过一个可训练的权重向量和 softmax 函数,计算每个单词对整体语义的重要性权重;接着使用这些注意力权重对 BiLSTM 的输出进行加权求和,提取出句子的全局语义特征;最后通过非线性变换得到最终的上下文向量,用于后续的分类任务。
8、BiLSTM+Attentiom模型中数据处理的整体思路是什么?
Day06 1、BERT预训练模型所接收的最大sequence长度是多少,为什么设置最大长度? 512
BERT 的输入除了 Token Embedding 之外,还要加上位置编码(position embeddings),以告诉模型“第 i 个 token 在序列中的位置”。它在进行embedding的时候,需要设置embedding层的 vocab_size(这里指的的是有多少个位置,而不是字符的数量),这个值会在构建模型时写死!所以,一旦写死之后,句子的最大长度就确定了,后续在使用时,就不能超过这个句子的最大长度,因为一旦超过之后,超出的位置编码就没有办法进行embedding查表了。训练BERT时,大部分语料都不超过512,所以最终指定句子的最大长度为512。模型训练好之后,在进行使用时,需要将样本统一成最大长度。
2、对于长文本(文本长度超过512的句子)在使用BERT时, 如何来构造训练样本? 核心就是如何进行截断。
head-only方式: 这是只保留长文本头部信息的截断方式, 具体为保存前510个token (要留两个位置给[CLS]和[SEP]).
tail-only方式: 这是只保留长文本尾部信息的截断方式, 具体为保存最后510个token (要留两个位置给[CLS]和[SEP]).
head+only方式: 选择前128个token和最后382个token (文本总长度在510以内), 或者前256个token和最后254个token (文本总长度大于510).
3、BiLSTM+Attention模型的架构是怎样的?
4、在BERT中,是如何将Token Embedding、Segment Embedding 和 Position Embedding组合在一起然后送到encoder中的? 在 BERT 中,模型的输入表示由三部分同维度的向量按位相加得到,然后送入后续的 Transformer encoder。
网络模型:
示意图:
示例:
5、两个矩阵相乘时,shape不符合要求怎么办? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import torchA = torch.randn(1 , 1 , 2 ) B = torch.randn(3 , 2 , 4 ) print (f'A-->{A} ' )print (f'B-->{B} ' )result = torch.matmul(A, B) print (result)result = torch.bmm(A.expand(3 , 1 , 2 ), B) print (result)
Day07 1、BiLSTM+Attention模型可以做哪些优化来改善模型性能? 1)模型优化
句子嵌入方式:可以使用jieba分词得到词语,然后再使用词语的方式进行嵌入。
替换BiLSTM:将BiLSTM替换成BERT/RoBERTa等这种预训练模型或BiGRU去做嵌入,看是否可以提供模型的语义表达能力。
多头注意力机制:借鉴Transformer中多头注意力机制,将单一注意力拆分到多个子空间,去捕捉不同维度的语义信息。
修改注意力机制的方式:使用transformer中注意力机制的计算方式或者先进行从concat再经过linear层的方式等,来计算注意力机制,看模型的性能效果。
调整随机失活层:调整随机失活层的位置、有无或随机失活比例,来观察模型的性能变化。
2)训练过程的优化
shuffle设置:注意在真正训练时,需要将dataloader中的shuffle设置为True
梯度裁剪:在反向传播时对梯度进行裁剪,防止梯度消失或爆炸。
早停机制:监控验证集上F1值或其他关键指标,如果连续多个epoch未提升或者开始下降,则提前终止训练。
3)训练数据优化
通过过采样或欠采样来解决样本不均衡问题
通过同义词替换、回译、实体替换等方法来扩充数据集。或者直接使用大模型进行训练样本的生成。
2、Pipeline方法的优缺点
优点:
易于实现,实体模型和关系模型使用独立的数据集,不需要同时标注实体和关系的数据集.
两者相互独立,若关系抽取模型没训练好不会影响到实体抽取.
缺点:
关系和实体两者是紧密相连的,互相之间的联系没有捕捉到.
上游 NER 的错误会直接影响下游关系抽取,容易造成误差积累.
BiLSTM_Attention难以处理EPO问题
3、Joint方法是什么?有哪两种类型? (1)概念
通过修改模型结构或标注方法, 直接输出文本中包含的SPO三元组
(2)类型
参数共享的联合模型【修改模型结构】
主体、客体和关系的抽取不是严格同步进行的 (通常是依次执行,但是某些情况下也可以其中两个任务一起进行) ,各个过程都可以得到一个loss值,整个模型的loss是各过程loss值之和.
联合解码的联合模型【修改标注方法】
主体、客体和关系的抽取是同时进行的,通过一个模型直接得到SPO三元组.
4、Casrel模型的架构是怎样的? 第一步:识别出句子中的Subject
第二步:根据识别出的Subject,识别出所有有可能的Relation及对应的Object
(1)bert隐藏层输出+所取的Subject特征向量作为输入【若Subject存在多个字,则取平均向量】(2)对于识别出来的每一个Subject,对应的每一种关系会解码出其Object的Start和End索引位置,与Subject类似
5、说一下Casrel模型的输入输出是什么?
6、数据处理整体思路是怎样的? 原始数据:
构建Dataset
在构建Dataset时,直接使用json.loads()方法逐行去加载数据,存储到字典列表中,然后取出text中的原始文本和spo_list中的三元组列表进行返回
构建自定义函数collect_fn()
使用bert的分词器对原始文本进行处理,获取input_ids和attention_mask基于每个样本的input_ids和spo_list去获取训练数据的其他输入和输出
对每个样本的结果数据进行拼接,再转成tensor作为最终模型训练的数据
构建get_data_loader()函数,获取数据迭代器
分别使用train/dev/test.json文件构造不同的Dataloader对象即可
训练数据:
输入:input_ids, attention_mask, 所取头实体从头到尾的位置信息,所取头实体的长度
输出:主实体的开始、结束位置信息,客实体的开始、结束位置信息及关系信息
注意:
在使用每个样本的input_ids和spo_list获取 sub_head2tail、sub_len、obj_heads、obj_tails这四个值的时候,做法如下:
在模型训练时,取的主实体的信息是真实spo_list中的值,原因是:
1)如果我们取模型第一步预测出来的主实体,此时有可能这个主实体预测错了,那么它就没有对应的客实体及关系信息,此时则无法构造标签,无法计算损失!
2)使用teacher_forcing这种方法,使用真实的spo_list中主实体信息去训练模型,可以加快模型的收敛速度,提高训练的效率
而在模型预测时,只知道原始文本,不知道主实体信息,此时sub_head2tail和sub_len这两个信息则是由模型第一步预测出来的主实体。
Day08 1、Casrel模型数据处理的整体思路是什么?
2、使用Casrel模型时,遇到什么问题,如何解决的? 遇到的问题:
解决方案:
在随机抽取时,每次随机抽取一个主实体,然后在客实体及关系信息中,记录该主实体所有的客实体开始位置及结束位置信息和关系。即sub_head2tail、sub_len是所取的主实体的信息,obj_heads、obj_tails为所取主实体对应的所有的客实体开始位置及结束位置信息和关系信息。
但是sub_heads和sub_tails需要记录一个样本的所有的主实体的开始位置信息及结束位置信息,这个不单单只记录抽取到的那个主实体,即sub_heads、sub_tails为该样本所有的主实体的开始位置和结束位置信息。
3、Casrel模型的结构是怎样的?
Day09 1、Casrel模型的损失函数怎么计算的? 损失计算:(1)模型有4个输出,需要对4个输出分别计算损失,再进行相加,相加之和是模型的损失
(2)因为标签是二分类的结果,所以在计算损失时,需要使用BCELoss
因为后续需要保留所有token对应的索引,而不是直接拿到平均损失,所以将reduction=’none’
(3)为了消除补齐部分对损失值的影响,需要将补齐的部分的损失置成0,然后再去进行计算非0部分的平均值,作为最终的损失
2、AdamW相关面试题 ①什么是权重衰减?
②为什么能防止过拟合?
模型参数越大,模型越容易对训练数据拟合过头,捕捉到不必要的噪声。
通过惩罚参数变大,可以使一些参数变成0,可以使模型学得更简单,泛化能力更强。
③Adam和AdamW的区别和优势是什么?
AdamW 相较于 Adam 的主要区别在于权重衰减的实现方式 。Adam 将 L2 正则项直接添加到梯度中,这会与自适应学习率机制耦合,导致正则化效果不稳定;而 AdamW 将权重衰减与梯度更新解耦,直接在参数更新时施加衰减,从而更符合理论上的正则化含义。优势在于:AdamW 提供了更稳定、有效的正则化效果,有助于提升模型的泛化能力 ,因此在许多现代深度学习任务中表现更优,已成为如 Transformers 等模型的默认优化器。
④为什么不对”bias”, “LayerNorm.bias”, “LayerNorm.weight”做权重衰减?
因为”bias” 和 “LayerNorm” 中的参数对模型的复杂度影响不大;另外,不做权重衰减,是为了避免干扰模型的偏移能力和归一化机制,从而保证训练稳定、性能更优。
3、Casrel模型中,Bert为什么要参与反向传播进行参数更新? **任务特定调整:**虽然BERT是预训练的,但它并不是针对特定任务(如关系抽取)进行优化的。通过在特定任务上进行微调(即反向传播更新参数),可以使BERT的表示更适合关系抽取的任务。这样,BERT模型能够更好地理解实体间的关系。
**领域适应:**预训练的BERT是在大规模语料上训练的,可能没有针对具体领域的知识或语言模式。通过微调BERT,可以使其更适应目标领域的数据,改善抽取效果。
**经验结果:**大量后续工作和实践都表明:在下游抽取、分类、生成等任务里,给BERT或其他Transformer设置较小的学习率,整体端到端的微调,一般比“冻结+只微调顶层”要好2—5个百分点的效果,尤其在中大型数据集上。
4、Casrel模型可以做哪些优化? 升级预训练模型:从基础 bert-base 换成效果更好的中文预训练,如 RoBERTa-wwm-ext、MacBERT、Erlangshen-RoBERTa-large 等。
修改主实体和bert隐藏层的融合方式:可以使用拼接的方式(Bert隐藏层输入拼接上所取主实体的平均向量;另外也可以将所取的主实体的向量前拼接N个1,其他的向量拼接N个0),或者使用增强的方式(将所取的主实体对应的张量扩大N倍)。
增加实体边界探索:在 subject/object 边界预测上加一个前馈全连接层 或者是BiLSTM+Linear层,提高识别的准确性。
增加drop层:通过增加几个不同的drop层,提高模型的过拟合能力。
修改0/1的阈值:目前设置的阈值为0.5,可以修改这个阈值进行训练或预测,比如修改成0.45,0.55等。
增加训练数据:可以使用数据增强,或更多标注数据。
Day10 1、Casrel模型在预测时,需要注意什么? 预测思路:与其他模型不一样的地方是,不能将数据处理之后,直接调用forward方法,获取模型的最终预测结果。而是需要先将数据处理好之后,送到模型中去预测主实体信息,然后再去处理这个主实体信息,处理好之后再送入模型中去预测客实体及关系,才能最终的预测结果。所以,预测时大的步就是有2个!
1、预测主实体
调用模型的get_encoded_text(),获取bert_output
调用模型的get_subs()方法,获取主实体开始和结束位置信息
抽取出主实体(先将数据转换成1或0,然后调用extract_sub方法)
注意:这一步有可能抽取到0个或1个或者多个主实体
不再预测客实体及关系需要进行遍历,去预测每个主实体的客实体及关系
2、预测客实体及关系
对每个主实体进行处理,获取sub_head2tail,sub_len
调用模型get_objs_and_rels()方法,预测客实体及关系
抽取客实体及关系(先将数据转换成1或0,然后调用extract_obj方法)
注意:这一步有可能抽取到0个或1个或者多个客实体及关系
不再解析结果,需要进行遍历,然后依次解析结果
3、结果解析
将id解析成文本,并拼接后输出
2、什么是知识融合? 知识融合,简单理解是将来自不同来源、格式、结构的异构数据统一整合到一个一致的知识图谱中。
3、主要有哪些问题?
消除冗余:有重复的spo三元组,需要去重
去重的方式:使用python进行数据清洗、借助图数据库
统一表达:不同名称的实体或关系,但表示的意思相同,需要统一。如鲁迅和周树人是同一人、父亲和爸爸是同一关系
解决冲突:同一个实体或关系的描述可能存在冲突,需要找到一致性或保留一个。如 张三-籍贯-河北 与 张三-籍贯-石家庄 冲突
知识扩展:挖掘新知识,丰富知识图谱
处理更多的语料,从而更多的三元组;可以查阅相关的资料,获取的更多的信息,补充到知识图谱中。
4、什么是实体消岐(实体链接)?怎么处理? 定义:根据上下文信息来解决同一名称可能指代多个不同对象的问题(即一词多义)。
目标:确定文本中提到的具体对象,以消除歧义。
方法:基于规则、机器学习、深度学习
比如:可以使用 tf-idf 生成向量,然后计算向量相似度
5、 什么是实体统一(实体对齐)?怎么处理? 定义:判断多个实体是不是属于一个实体。
目标:将来自不同数据源中的同一实体进行识别和合并。
方法:
基于规则:根据领域专家提供的规则,如对同义词或缩写的映射。
基于有监督的学习方法:训练模型自动判断实体是否相同。
6、什么是关系对齐(关系统一)?怎么处理? 定义:不同数据源可能使用不同的方式描述相同的关系,需要进行判断。
目标:将不同数据源中表示相同的关系进行对齐和融合。
方法:
7、如何使用TF-IDF来进行实体消歧?
8、你们项目选用的图数据库是什么?为什么? neo4j数据库企业版
因为neo4j图数据库是一个专业级的图数据库,性能强大,且企业版提供高可靠和高可用,非常稳定。在公司中使用广泛,有大量的学习资料可以参考。
9、NEO4J数据库中有哪些概念?和spo三元组有什么关系?
10、图数据库相比传统的MySQL数据库,有哪些优势?
图数据库以“节点”和“边”来表示实体及其关系,更容易理解和建模
MySQL通过外键关联表,查询复杂关系时需要大量 JOIN 操作,性能随关系深度和数据量急剧下降。而图数据库在查询时是沿着连接线“遍历”,在多跳查询时速度依然很快。
Day11 1、最终导入数据库的数据组织形式是怎样的?为什么? 将所有数据,包括spo三元组数据和从其他地方整理的数据整理到json文件中。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 { # 数据库中的唯一标识符。 "_id" : { "$oid" : "5bb578b6831b973a137e3ee8" } , # 伴随疾病或并发症。 "acompany" : [ "贫血" ] , # 疾病的分类,表明疾病所属的类别和科室。 "category" : [ "疾病百科" , "急诊科" ] , # 疾病的病因 "cause" : "吸入苯蒸气或皮肤接触苯而..." }
这样组织的原因是:
可以将一个实体的多个spo三元组存储在一起,更加直观,也方便后续的处理
可以把类似疾病描述、治疗费用、疾病的病因等这些从其他地方获取到的信息也存在这个json中,方便以属性的方式存到知识图谱中,从而使问答的范围变大!!
2、导入数据库都有哪些数据? 将所有实体,包括疾病名称、症状、科室、食物等以节点的方式导入neo4j中。
将所有关系,包括疾病-症状、疾病-忌吃食物、疾病-易吃食物、疾病 - 推荐药品等关系以关系的方式导入neo4j中。
将实体的属性,包括疾病描述、病因、预防方式、治疗方法等以属性的方式导入到neo4j中。
导入方式都是使用merge的方式,如果之前没有则创建,如果存在则更新。
3、问答系统分为哪几个部分,分别是做什么的?
4、什么是意图识别?
5、什么是槽位填充? 从用户的话语中提取出关键的参数信息,并填入预定义的结构化模板中对应的槽位,进而方便利用知识库回答用户问题或者完成某种操作。
6、如何设计语义槽?
有多少种意图,就预定义好多少种对应的语义槽
每个意图中需要多少个关键信息,就设计多少个槽位
每个槽位包括:待填充的槽位值、追问话术和歧义澄清话术【通过询问确定具体信息】、槽位预测API【通过接口从用户的输入中提取出该槽位的值(NER)】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 "订电影票" : { "电影名" : , { "槽位值" : ___, "追问话术" : "请问您需要看那部电影?" , "歧义澄清话术" : "你想看XX还是YYY" , "槽位预测" : "/api/predict_movie_name/" } "电影院名称" : , { "槽位值" : ___, "追问话术" : "请问您要去的电影院是哪个?" , "歧义澄清话术" : "你想看XX影院还是YY影院?" , "槽位预测" : "/api/predict_cinema/" } 。。。 }
7、医疗KBQA系统架构是怎样的?
Day12 1、医疗KBQA系统实现的步骤是什么?
NLU模块
实现第一个意图识别模型:判断是否是闲聊类的意图
实现第二个意图识别模型:包括13个医疗类的意图
实现第三个槽位填充(NER)模型:这里直接使用NER任务模型
DM模块
基于不同意图,设计对应的语义槽
槽位填充
根据意图执行度确定回复策略
NLG模块
主逻辑服务模块实现
2、如何实现第一个意图识别模型(判断是否是闲聊类的意图)? 使用IT-IDF向量化器构造TF-IDF向量化器,将文本转成TF-IDF向量作为训练特征。
将特征向量送入逻辑回归模型和GBDT模型中进行训练。
将两个模型预测出的概率值结果取平均值,然后选择概率最大的标签。
3、如何实现第二个意图识别模型(包括13个医疗类的意图)? 先将文本送入BERT模型中,学习语义特征,然后将BERT的池化层输出(pooler_output),送入全连接层得到预测的分类结果。
4、如何实现第三个槽位填充(NER)模型(用来识别用户话语中的实体)? (1)实现方式一:
使用课上讲的模型:BiLSTM+CRF
注意:
1)需要对数据进行处理,处理方式有两种:
第一种方式:直接将数据转成课上使用的数据格式。这一步可以借助大模型来完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 def process_train_file (input_file='train.txt' , output_file='processed_train.txt' ): with open (input_file, 'r' , encoding='utf-8' ) as f_in, \ open (output_file, 'w' , encoding='utf-8' ) as f_out: for line in f_in: line = line.strip() if not line: continue parts = line.split('\t' ) if len (parts) < 2 : continue text = parts[0 ].strip() labels = parts[1 ].strip().split() if text[-1 ] not in ['。' , '?' , '!' , '!' , '?' ]: text += '。' labels += ['O' ] if len (text) != len (labels): print (f"警告:文本长度与标签长度不匹配,跳过该行。\n文本:'{text} '\n长度:{len (text)} \n标签长度:{len (labels)} " ) continue for char, label in zip (text, labels): f_out.write(f"{char} \t{label} \n" ) f_out.write("\n" ) print (f"处理完成,结果已保存到 {output_file} " ) process_train_file('train.txt' , 'processed_train.txt' )
2)这个训练数据是分训练集和验证集的,不需要使用同一份数据进行拆分了!
3)标签数量不一样。所在在进行标签的填充的时候,填充的字符就是15了。
4)标签的分隔方式不一样。B- —> B_
(2)实现方式二:
使用BERT替换掉embedding层和BiLSTM层。
注意点:
1)需要将标签进行转换!!!!因为bert将文本转成input_ids之后,它的长度会发生变化,也就是输入和标签之间的对应关系会发生变化,所以需要对标签进行处理!!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def collate_fn (batch_data ): texts = ['' .join(sample[0 ]) for sample in batch_data] tags = [sample[1 ] for sample in batch_data] encoding = conf.tokenizer.batch_encode_plus( texts, truncation=True , padding=True , return_tensors='pt' , add_special_tokens=False ) input_ids_padded = encoding['input_ids' ] attention_mask = encoding['attention_mask' ] B, L = input_ids_padded.size() labels_padded = torch.zeros((B, L), dtype=torch.long) for i, (text, tag) in enumerate (zip (texts, tags)): input_ids = input_ids_padded[i] tokens = conf.tokenizer.convert_ids_to_tokens(input_ids.tolist()) char2token = {} char_idx = 0 for t_idx, token in enumerate (tokens): tok = token.replace('##' , '' ) if not tok: continue start = text.find(tok, char_idx) if start < 0 : continue end = start + len (tok) for c in range (start, end): char2token[c] = t_idx char_idx = end max_index = 0 for k, v in char2token.items(): labels_padded[i, v] = conf.tag2id[tag[k]] max_index = v labels_padded[i, max_index + 1 :] = 15 return input_ids_padded, labels_padded, attention_mask
2)在微调Bert时,需要将学习率设小一点,才能有效去修改参数。
原始的学习率为2e-3,这个值比较大,会造成无法有效修改bert的模型参数,会造成预测结果全为0的情况。可以把它修改成3e-5。
另外一个优化点,是使用了学习率预热。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ''' 优化点:学习率预热 学习率预热的目的:让模型在初始阶段更快的使用数据,避免训练过程中学习率过大或过小带来训练不稳定或者收敛速度太慢的问题,从而提高模型训练效果和泛化性能 实现方式:在初始阶段,将学习率从较小的值逐步增加到预设的初始值,然后按照我们设定的训练策略逐渐变小。 get_linear_schedule_with_warmup: 使用这个方法来实现学习率预热,它的方式是从0以线性的方式增大到预设的学习率,然后再以线性的方式逐渐降低到0 参数: optimizer:优化器对象 num_warmup_steps:预热步数,指的是从0增加到预设的学习率所需的步数 num_training_steps: 指的是整个训练过程的总的步数,确切来说在给定的数据集上,参数更新的次数。 ''' total_steps = len (train_dataloader) * conf.epochs scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=50 , num_training_steps=total_steps) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=10 ) optimizer.step() scheduler.step()
(3)实现方式三:
直接使用BERT+linear进行预测。
注意点:数据处理方式同方式二、模型训练方式同BiLSTM(使用交叉熵损失进行训练)。
(4)实现方式四:
结合了BERT+BiLSTM+Linear+CRF。
优化点:使用chinese-roberta-wwm-ext替换了bert-base-chinese 只要使用bert-base-chinese的地方都可以使用它进行优化,其他的bert变种也可以拿来进行尝试。
替换的方式:直接从魔搭社区上进行下载,下载完成后,替换掉原始的bert-base-chinese路径即可。
下载方式如下(在cmd中运行):
1 modelscope download --model dienstag/chinese-roberta-wwm-ext --local_dir ./chinese-roberta-wwm-ext
最终结论:方式四是相对最好的。
NER任务 BiLSTM+CRF项目完整实现 (1)整体步骤
1 2 3 4 5 6 7 8 9 整体实现思路(1-4数据数据预处理,5-8模型部分) : 1、获取数据,例如通过人工数据标注或者第三方数据等。 2、对数据进行处理,构造训练数据 3、构建DataSet类 4、加载数据集 DataLoader 5、定义模型(embedding、线性层、CRF层) 6、初始化模型、loss、优化器、前向传播、反向传播、梯度更新 7、模型训练、评估 8、模型加载、测试
(2)代码架构图
数据预处理 第一步: 查看项目数据集 data_origin:原始数据
(2)txtoriginal.txt结尾:原始文档
data:处理好的数据
labels.json 实体类型文件
1 2 3 4 5 6 7 { "治疗" : "TREATMENT", "身体部位" : "BODY", "症状和体征" : "SIGNS", "检查和检验" : "CHECK", "疾病和诊断" : "DISEASE" }
tag2id.json 标注标签及ID
1 2 3 4 5 6 7 8 9 10 11 12 13 { "O" : 0, "B-TREATMENT" : 1, "I-TREATMENT" : 2, "B-BODY" : 3, "I-BODY" : 4, "B-SIGNS" : 5, "I-SIGNS" : 6, "B-CHECK" : 7, "I-CHECK" : 8, "B-DISEASE" : 9, "I-DISEASE" : 10 }
第二步: 构造序列标注数据 (1)根据标注数据 和 标签类型构建索引和标签的字典
(2)遍历样本数据,通过 索引和标签的字典,给相应位置打上标签,如果在字典里则将字典的value作为标签,否则就是0
难点:
(1)获取到所有的原始数据
(2)获取原始数据对应的标注数据
(2)课堂知识补充
代码位置:P03_NER/LSTM_CRF/utils/test.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import osimport jsoncur = os.getcwd() print (f'当前路径-->{cur} ' )os.chdir('..' ) cur = os.getcwd() print (f'修改之后的路径-->{cur} ' )path = os.path.join(cur, 'data/labels.json' ) print (f'拼接之后的路径-->{path} ' )file_path = os.path.abspath(__file__) print (f'file_path-->{file_path} ' )base_dir = os.path.dirname(file_path) print (f'base_dir-->{base_dir} ' )path = os.path.join(base_dir, '../data/labels.json' ) print (f'拼接之后的路径2-->{path} ' )labels = json.load(open (path, 'r' , encoding='utf-8' )) print (f'labels-->{labels} ' )results = os.walk(os.path.join(base_dir, '../data_origin' )) print (f'results-->{results} ' )for dir_path, dirs, files in results: print ('*' *50 ) print (f'dir_path-->{dir_path} ' ) print (f'dirs-->{dirs} ' ) print (f'files-->{files} ' )
(3)代码
代码位置:P03_NER/LSTM_CRF/utils/data_process.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import osimport jsonbase_dir = os.path.dirname(os.path.abspath(__file__)) print (f'base_dir-->{base_dir} ' )class TransferData : def __init__ (self ): self.lables_dict = json.load(open (os.path.join(base_dir, '../data/labels.json' ), 'r' , encoding='utf-8' )) self.origin_path = os.path.join(base_dir, '../data_origin' ) self.train_path = os.path.join(base_dir, '../data/train.txt' ) def transfer (self ): with open (self.train_path, 'w' , encoding='utf-8' ) as fw: for dirpath, dirnames, filenames in os.walk(self.origin_path): for filename in filenames: if 'txtoriginal' not in filename: continue file_path = os.path.join(dirpath, filename) label_file_path = file_path.replace('.txtoriginal' , '' ) label_dict = self.read_label_text(label_file_path) with open (file_path, 'r' , encoding='utf-8' ) as fr: content = fr.read().strip() if content[-1 ] not in ['。' , '?' , '!' , '!' , '?' ]: content += '。' for i, char in enumerate (content): label = label_dict.get(i, 'O' ) final_str = char + '\t' + label + '\n' fw.write(final_str) def read_label_text (self, label_file_path ): label_dict = {} with open (label_file_path, 'r' , encoding='utf-8' ) as fr: for line in fr: line = line.strip() if not line: continue line_list = line.split('\t' ) start = int (line_list[1 ]) end = int (line_list[2 ]) label = self.lables_dict.get(line_list[3 ]) for i in range (start, end+1 ): if i ` start: label_dict[i] = 'B-' + label else : label_dict[i] = 'I-' + label return label_dict if __name__ ` '__main__' : td = TransferData() td.transfer()
第三步: 编写Config类项目文件配置代码 (1)目的: 配置项目常用变量,一般这些变量属于不经常改变的,比如: 训练文件路径、模型训练次数、模型超参数等等
(2)代码
注意:可以修改成相对路径
代码位置:P03_NER/LSTM_CRF/config.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import osimport torchimport jsonbase_dir = os.path.dirname(os.path.abspath(__file__)) class Config (object ): def __init__ (self ): self.device = "cuda:0" if torch.cuda.is_available() else "cpu:0" self.train_path = os.path.join(base_dir, 'data/train.txt' ) self.vocab_path = os.path.join(base_dir, 'vocab/vocab.txt' ) self.embedding_dim = 300 self.epochs = 5 self.batch_size = 8 self.hidden_dim = 256 self.lr = 2e-3 self.dropout = 0.2 self.model = "BiLSTM_CRF" self.tag2id = json.load(open (os.path.join(base_dir, 'data/tag2id.json' ), 'r' , encoding='utf-8' )) if __name__ ` '__main__' : conf = Config() print (conf.train_path) print (conf.tag2id)
第四步: 构建Dataset类与dataloader函数 (1)整体思路
将句子进行拆分后,分别将文字和对应的标签放到一个列表中,然后将同一个句子的x,y列表组合成一个大的列表,然后放到三维列表中
将数据拆分成句子,同时将句子中的文字和对应的标签分别存到两个列表中,然后再放到一个三维列表中
(2)构造(x,y)样本对,以及获取vocabs
代码:
代码位置:P03_NER/LSTM_CRF/utils/common.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from P03_NER.LSTM_CRF.config import Configconf = Config() def build_data (): datas = [] sample_x = [] sample_y = [] vocab_list = ['PAD' , 'UNK' ] for line in open (conf.train_path, 'r' , encoding='utf-8' ): word_tag_list = line.strip('\n' ).split('\t' ) if len (word_tag_list) != 2 : continue word = word_tag_list[0 ] tag = word_tag_list[1 ] if not word: continue sample_x.append(word) sample_y.append(tag) if word in ['。' , '?' , '!' , '!' , '?' ]: datas.append([sample_x, sample_y]) sample_x = [] sample_y = [] if word not in vocab_list: vocab_list.append(word) with open (conf.vocab_path, 'w' , encoding='utf-8' ) as fw: fw.write('\n' .join(vocab_list)) word2id = {word: i for i, word in enumerate (vocab_list)} return datas, word2id if __name__ ` '__main__' : datas, word2id = build_data() print (f'datas-->{datas[:5 ]} ' ) print (f'word2id-->{word2id} ' ) print (f'len(datas)-->{len (datas)} ' ) print (f'len(word2id)-->{len (word2id)} ' )
(3)构造数据迭代器
步骤:
1 2 3 1、构建Dataset类 2、构建自定义函数collate_ fn() 3、构建get_ data函数,获得数据迭代器
代码:
调用过程:
代码位置:P03_NER/LSTM_CRF/utils/data_loader.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 import torchfrom torch.nn.utils.rnn import pad_sequence from torch.utils.data import Dataset, DataLoaderfrom P03_NER.LSTM_CRF.config import Configfrom P03_NER.LSTM_CRF.utils.common import build_datadatas, word2id = build_data() conf = Config() class NerDataset (Dataset ): def __init__ (self, datas ): super (NerDataset, self).__init__() self.datas = datas def __len__ (self ): return len (self.datas) def __getitem__ (self, index ): sample = self.datas[index] x = sample[0 ] y = sample[1 ] return x, y def test_dataset (): ner_dataset = NerDataset(datas) print (f'len(ner_dataset)-->{ner_dataset.__len__()} ' ) print (f'len(ner_dataset)-->{len (ner_dataset)} ' ) print (f'ner_dataset[0]-->{ner_dataset.__getitem__(0 )} ' ) print (f'ner_dataset[0]-->{ner_dataset[0 ]} ' ) def collate_fn (batch_data ): x_train = [torch.tensor([word2id.get(word, 1 ) for word in data[0 ]]) for data in batch_data] y_train = [torch.tensor([conf.tag2id.get(tag, 0 ) for tag in data[1 ]]) for data in batch_data] input_ids = pad_sequence(x_train, batch_first=True , padding_value=0 ) labels = pad_sequence(y_train, batch_first=True , padding_value=11 ) attention_mask = (input_ids != 0 ).long() return input_ids, labels, attention_mask def get_data (): train_dataset = NerDataset(datas[:6300 ]) train_dataloader = DataLoader(train_dataset, batch_size=conf.batch_size, shuffle=False , collate_fn=collate_fn, drop_last=True ) valid_dataset = NerDataset(datas[6300 :]) valid_dataloader = DataLoader(valid_dataset, batch_size=conf.batch_size, shuffle=False , collate_fn=collate_fn, drop_last=True ) return train_dataloader, valid_dataloader if __name__ ` '__main__' : train_dataloader, valid_dataloader = get_data() for input_ids, labels, attention_mask in train_dataloader: print (f'input_ids-->{input_ids.shape} ' ) print (f'labels-->{labels.shape} ' ) print (f'attention_mask-->{attention_mask.shape} ' ) break
BiLSTM+CRF模型搭建 第一步: 编写模型类的代码
(1)思路
(2)代码
代码位置:P03_NER/LSTM_CRF/model/BiLSTM.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import torch.nn as nnfrom P03_NER.LSTM_CRF.config import Configfrom P03_NER.LSTM_CRF.utils.data_loader import word2id, get_dataclass NERLSTM (nn.Module): def __init__ (self, embedding_dim, hidden_dim, dropout, tag2id, word2id ): ''' 模型初始化 :param embedding_dim: 嵌入层维度 300 :param hidden_dim: 这里指的是BiLSTM模型输出时的维度,因为是双向LSTM,所以,隐藏层维度为 hidden_dim//2 :param dropout: 随机失活比例 :param tag2id: tag2id字典 :param word2id: word2id字典 ''' super (NERLSTM, self).__init__() self.name = 'BiLSTM' self.embedding_dim = embedding_dim self.hidden_dim = hidden_dim self.dropout = dropout self.tag_size = len (tag2id) self.vocab_size = len (word2id) self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim) self.bilstm = nn.LSTM(input_size=self.embedding_dim, hidden_size=self.hidden_dim // 2 , bidirectional=True , batch_first=True ) self.dropout = nn.Dropout(self.dropout) self.linear = nn.Linear(self.hidden_dim, self.tag_size) def forward (self, input_ids, attention_mask ): embedding = self.embedding(input_ids) bilstm_out, (h_n, c_n) = self.bilstm(embedding) dropout_out = self.dropout(bilstm_out) attention_mask = attention_mask.unsqueeze(-1 ) dropout_out = dropout_out * attention_mask linear_out = self.linear(dropout_out) return linear_out if __name__ ` '__main__' : conf = Config() ner_lstm = NERLSTM(conf.embedding_dim, conf.hidden_dim, conf.dropout, conf.tag2id, word2id) print (f'ner_lstm-->{ner_lstm} ' ) train_dataloader, valid_dataloader = get_data() for input_ids, labels, attention_mask in train_dataloader: result = ner_lstm(input_ids, attention_mask) print (f'result-->{result.shape} ' ) break
(1)思路
(2)代码
需要提前装一下包
注意:由于CRF是自定义的损失函数,所以这里不再需要使用交叉熵损失等,直接使用crf封装好的方法即可,计算损失的函数定义为log_likelihood()。而在forward方法不再用于计算概率值,而是通过viterbi解码得到概率最大的标签路径。
代码位置:P03_NER/LSTM_CRF/model/BiLSTM_CRF.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 import torch.nn as nnfrom TorchCRF import CRFfrom P03_NER.LSTM_CRF.config import Configfrom P03_NER.LSTM_CRF.utils.data_loader import word2id, get_dataclass NERLSTM_CRF (nn.Module): def __init__ (self, embedding_dim, hidden_dim, dropout, tag2id, word2id ): ''' 模型初始化 :param embedding_dim: 嵌入层维度 300 :param hidden_dim: 这里指的是BiLSTM模型输出时的维度,因为是双向LSTM,所以,隐藏层维度为 hidden_dim//2 :param dropout: 随机失活比例 :param tag2id: tag2id字典 :param word2id: word2id字典 ''' super (NERLSTM_CRF, self).__init__() self.name = 'BiLSTM_CRF' self.embedding_dim = embedding_dim self.hidden_dim = hidden_dim self.dropout = dropout self.tag_size = len (tag2id) self.vocab_size = len (word2id) self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim) self.bilstm = nn.LSTM(input_size=self.embedding_dim, hidden_size=self.hidden_dim // 2 , bidirectional=True , batch_first=True ) self.dropout = nn.Dropout(self.dropout) self.linear = nn.Linear(self.hidden_dim, self.tag_size) self.crf = CRF(self.tag_size) def get_emission_score (self, input_ids, attention_mask ): embedding = self.embedding(input_ids) bilstm_out, (h_n, c_n) = self.bilstm(embedding) dropout_out = self.dropout(bilstm_out) attention_mask = attention_mask.unsqueeze(-1 ) dropout_out = dropout_out * attention_mask linear_out = self.linear(dropout_out) return linear_out def log_likelihood (self, input_ids, labels, attention_mask ): emission_score = self.get_emission_score(input_ids, attention_mask) loss = -self.crf(emission_score, labels, attention_mask.bool ()) return loss def forward (self, input_ids, attention_mask ): emission_score = self.get_emission_score(input_ids, attention_mask) predict_result = self.crf.viterbi_decode(emission_score, attention_mask.bool ()) return predict_result if __name__ ` '__main__' : conf = Config() ner_lstm_crf = NERLSTM_CRF(conf.embedding_dim, conf.hidden_dim, conf.dropout, conf.tag2id, word2id) print (f'ner_lstm_crf-->{ner_lstm_crf} ' ) train_dataloader, valid_dataloader = get_data() for input_ids, labels, attention_mask in train_dataloader: loss = ner_lstm_crf.log_likelihood(input_ids, labels, attention_mask) print (f'loss-->{loss} ' ) predict_result = ner_lstm_crf(input_ids, attention_mask) print (f'predict_result-->{predict_result} ' ) break
第二步: 编写训练函数 (1)基本步骤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 训练函数基本步骤—— 1.构建数据迭代器Dataloader(包括数据处理与构建数据源Dataset) 2.实例化模型 3.实例化损失函数对象 4.实例化优化器对象 5.定义打印日志参数 6.开始训练 6.1 实现外层大循环epoch 6.2 将模型设置为训练模式 6.3 内部遍历数据迭代器dataloader 1)将数据送入模型得到输出结果 2)计算损失 3)梯度清零 : optimizer.zero_grad() 4)反向传播(计算梯度) : loss.backward() 5)梯度更新(参数更新) : optimizer.step() 6)打印内部训练日志 6.4 使用验证集进行模型评估【将模型设置为评估模式】 6.5 保存模型: torch.save(model.state_dict(), "model_path") 6.6 打印外部训练日志 验证函数基本步骤—— 1.定义打印日志参数 2.将模型设置为评估模式 3.内部遍历数据迭代器dataloader 3.1 将数据送入模型得到输出结果 3.2 计算损失 3.3 处理结果 3.4 统计批次内指标 4.统计整体指标
(2)代码
注意:使用BiLSTM_CRF模型时,使用自定义的损失函数,封装在了log_likelihood()方法中。而forward()方法可以直接获取预测的标签类型。
代码位置:P03_NER/LSTM_CRF/train.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 import timeimport torchimport torch.nn as nnfrom sklearn.metrics import precision_score, recall_score, classification_report, f1_scorefrom torch import optimfrom tqdm import tqdmfrom P03_NER.LSTM_CRF.config import Configfrom P03_NER.LSTM_CRF.model.BiLSTM import NERLSTMfrom P03_NER.LSTM_CRF.model.BiLSTM_CRF import NERLSTM_CRFfrom P03_NER.LSTM_CRF.utils.data_loader import get_data, word2idconf = Config() def model2dev (valid_dataloader, model, criterion=None ): ''' 使用验证集,评估模型的效果【同时支持 BiLSTM和 BiLSTM_CRF】 :param valid_dataloader: 验证集的dataloader :param model: 需要评估的模型实例 :param criterion: 损失函数对象,因为BiLSTM需要使用交叉熵损失,所以需要用到损失函数对象,而BiLSTM_CRF是不需要的,所以,需要设置默认值为None :return: 评估指标 ''' avg_loss = 0 preds = [] golds = [] model.eval () for index, (input_ids, labels, attention_mask) in enumerate (tqdm(valid_dataloader)): input_ids = input_ids.to(conf.device) labels = labels.to(conf.device) attention_mask = attention_mask.to(conf.device) if conf.model ` 'BiLSTM' : output = model(input_ids, attention_mask) output2 = output.view(-1 , len (conf.tag2id)) labels2 = labels.view(-1 ) loss = criterion(output2, labels2) avg_loss += loss predict = output.argmax(dim=-1 ).tolist() elif conf.model ` 'BiLSTM_CRF' : loss = model.log_likelihood(input_ids, labels, attention_mask).mean() avg_loss += loss predict = model(input_ids, attention_mask) real_len = (input_ids>0 ).sum (-1 ).tolist() for index, label in enumerate (predict): preds.extend(label[:real_len[index]]) for index, label in enumerate (labels.tolist()): golds.extend(label[:real_len[index]]) avg_loss = avg_loss / len (valid_dataloader) precision = precision_score(golds, preds, average='micro' ) recall = recall_score(golds, preds, average='micro' ) f1 = f1_score(golds, preds, average='micro' ) report = classification_report(golds, preds) return avg_loss, precision, recall, f1, report def model2train (): train_dataloader, valid_dataloader = get_data() models = {'BiLSTM' : NERLSTM, 'BiLSTM_CRF' : NERLSTM_CRF} model = models[conf.model](conf.embedding_dim, conf.hidden_dim, conf.dropout, conf.tag2id, word2id).to(conf.device) print (f'model-->{model} ' ) criterion = nn.CrossEntropyLoss(ignore_index=11 ) optimizer = optim.Adam(model.parameters(), lr=conf.lr) start_time = time.time() best_f1 = -1.0 if conf.model ` 'BiLSTM' : for epoch in range (conf.epochs): model.train() for index, (input_ids, labels, attention_mask) in enumerate (tqdm(train_dataloader)): input_ids = input_ids.to(conf.device) labels = labels.to(conf.device) attention_mask = attention_mask.to(conf.device) output = model(input_ids, attention_mask) output = output.view(-1 , len (conf.tag2id)) labels = labels.view(-1 ) loss = criterion(output, labels) optimizer.zero_grad() loss.backward() optimizer.step() if (index + 1 ) % 200 ` 0 : print ('epoch:%04d------------loss:%f' % (epoch, loss.item())) avg_loss, precision, recall, f1, report = model2dev(valid_dataloader, model, criterion) if f1 > best_f1: print (f'当前轮次为{epoch} 轮次, 获取到新的最佳f1为{best_f1} , 保存模型' ) print (f'report-->{report} ' ) torch.save(model.state_dict(), 'save_model/bilstm_best.pth' ) best_f1 = f1 elif conf.model ` 'BiLSTM_CRF' : for epoch in range (conf.epochs): model.train() for index, (input_ids, labels, attention_mask) in enumerate (tqdm(train_dataloader)): input_ids = input_ids.to(conf.device) labels = labels.to(conf.device) attention_mask = attention_mask.to(conf.device) loss = model.log_likelihood(input_ids, labels, attention_mask).mean() optimizer.zero_grad() loss.backward() optimizer.step() if (index + 1 ) % 200 ` 0 : print ('epoch:%04d------------loss:%f' % (epoch, loss.item())) avg_loss, precision, recall, f1, report = model2dev(valid_dataloader, model) if f1 > best_f1: print (f'当前轮次为{epoch} 轮次, 获取到新的最佳f1为{best_f1} , 保存模型' ) print (f'report-->{report} ' ) torch.save(model.state_dict(), 'save_model/bilstm_crf_best.pth' ) best_f1 = f1 print ('训练结束, 总耗时: %.2f' % (time.time() - start_time)) if __name__ ` '__main__' : model2train()
结论:
使用CRF之后,效果会比之前稍微好一些,但是训练成本会变高。
优化点:
(1)在正在训练时,将dataloader中的shuffle设置成true
(2)为了能够让训练集和验证集的样本分布一致,需要先将数据集打乱,然后再去进行划分
代码如下:
1 2 3 4 5 6 7 def get_data (): random.seed(66 ) random.shuffle(datas) train_dataset = NerDataset(datas[:6300 ])
除了这种方式之外,也可以使用分类采样的方式。这种方式可以绝对类型上,训练集和验证集的分布是一致的。
(3)训练优化:梯度裁剪,它的作用是防止参数过大带来训练不稳定或者梯度爆炸
它实现的方式,当参数的范数大于了设置的最大范数时,所有参数会乘以缩放比例进行变小,缩放比例=max_norm/total_norm
代码如下:
1 2 3 4 torch.nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=10 ) optimizer.step()
(4)增加标注数据
(5)和规则进行结合,去做结果后处理
(6)日志保存
第三步: 编写模型预测函数 (1)思路
1 2 3 4 5 1.实例化模型 2.加载训练好的模型参数 3.处理数据 4.模型预测 5.结果处理
(2)代码
代码位置:P03_NER/LSTM_CRF/ner_predict.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 import torchfrom P03_NER.LSTM_CRF.config import Configfrom P03_NER.LSTM_CRF.model.BiLSTM import NERLSTMfrom P03_NER.LSTM_CRF.model.BiLSTM_CRF import NERLSTM_CRFfrom P03_NER.LSTM_CRF.utils.data_loader import word2idconf = Config() id2tag = {v: k for k, v in conf.tag2id.items()} print (f'id2tag-->{id2tag} ' )models = {'BiLSTM' : NERLSTM, 'BiLSTM_CRF' : NERLSTM_CRF} model = models[conf.model](conf.embedding_dim, conf.hidden_dim, conf.dropout, conf.tag2id, word2id).to(conf.device) print (f'model-->{model} ' )if conf.model ` 'BiLSTM' : model.load_state_dict(torch.load('save_model/bilstm_best.pth' , weights_only=True )) else : model.load_state_dict(torch.load('save_model/bilstm_crf_best.pth' , weights_only=True )) def model2predict (text ): text_id = [word2id.get(i, 1 ) for i in text] print (f'text_id-->{text_id} ' ) id_tensor = torch.tensor([text_id]).to(conf.device) print (f'id_tensor-->{id_tensor} ' ) attention_mask = (id_tensor != 0 ).long().to(conf.device) print (f'attention_mask-->{attention_mask} ' ) model.eval () with torch.no_grad(): if conf.model ` 'BiLSTM' : logits = model(id_tensor, attention_mask) preds = logits.argmax(dim=-1 ).squeeze(0 ).tolist() print (f'preds-->{preds} ' ) else : preds = model(id_tensor, attention_mask)[0 ] print (f'preds-->{preds} ' ) predict_labels = [id2tag[i] for i in preds] print (f'predict_labels-->{predict_labels} ' ) result_dict = extract_entities(text, predict_labels) print (f'result_dict-->{result_dict} ' ) return result_dict def extract_entities (text, tags ): """ 从带 BIO 标签的文本中提取实体。 参数: text (str): 原始文本 tags (List[str]): 对应文本的标签列表 返回: dict: 实体名称到类型的映射,如 {'冠心病': 'DISEASE', '糖尿病': 'DISEASE'} """ entities = {} current_entity = [] current_type = None for char, tag in zip (text, tags): if tag.startswith('B-' ): if current_type is not None : entity_name = '' .join(current_entity) entities[entity_name] = current_type current_entity = [] current_type = None current_type = tag[2 :] current_entity.append(char) elif tag.startswith('I-' ): if current_type is not None and tag[2 :] ` current_type: current_entity.append(char) else : if current_type is not None : entity_name = '' .join(current_entity) entities[entity_name] = current_type current_entity = [] current_type = None if current_type is not None : entity_name = '' .join(current_entity) entities[entity_name] = current_type return entities if __name__ ` '__main__' : model2predict('女性,88岁,农民,双滦区应营子村人,主因右髋部摔伤后疼痛肿胀,活动受限5小时于2016-10-29;11:12入院。' )
关系抽取任务代码 基于规则方式实现关系抽取 原理
基于规则实现关系抽取的原理 (主要分为三个步骤)
第一步:定义需要抽取的关系集合,比如【夫妻关系,合作关系,,…】
第二步:遍历文章的每一句话,将每句话中非实体和非关系集合里面的词去掉
第三步:分别从实体集合和关系集合中,提取关系三元组
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import jieba.posseg as psegsamples = ["2014年1月8日,杨幂与刘恺威的婚礼在印度尼西亚巴厘岛举行" , "周星驰和吴孟达在《逃学威龙》中合作出演" , '成龙出演了《警察故事》等多部经典电影' ] relations2dict = {'夫妻关系' :['结婚' , '领证' , '婚礼' ], '合作关系' : ['搭档' , '合作' , '签约' ], '演员关系' : ['出演' , '角色' , '主演' ]} for text in samples: entities = [] relations = [] move_index = [] for word, flag in pseg.lcut(text): if flag ` 'nr' : entities.append(word) elif flag ` 'x' : if len (move_index) ` 0 : move_index.append(text.index(word)) else : move_index.append(text.index(word)) entities.append(text[move_index[0 ] + 1 : move_index[1 ]]) else : for key, value in relations2dict.items(): if word in value: relations.append(key) print (f'entities-->{entities} ' ) print (f'relations-->{relations} ' ) if len (entities) >= 2 and len (relations) >= 1 : print ("原始文本:" , text) print ('提取结果:' , entities[0 ] + '->' + relations[0 ] + '->' + entities[1 ]) else : print ("原始文本:" , text) print ('不好意思,暂时没能从文本中提取出关系结果' ) print ('*' *80 )
优缺点
优点:实现简单、无需训练,小规模数据集容易实现.
缺点:
无法解决复杂的场景
对跨领域的可移植性较差、人工标注成本较高以及召回率较低.
Pipline方法实现关系抽取 Pipeline方法的原理 步骤:先完成实体抽取;再进行关系分类
方法
CNN/RNN及其变体
CNN多样性卷积核的特性有利于识别目标的结构特征,而RNN能充分考虑长距离词之间的依赖性,其记忆功能有利于识别序列
BiLSTM+Attention模型架构⭐️ (1)模型架构
(2)注意力机制
【实现】代码实现概览 (1)整体步骤
1 2 3 4 5 6 7 8 9 整体实现思路(1-4数据数据预处理,5-8模型部分) : 1、获取数据,例如通过人工数据标注或者第三方数据等。 2、对数据进行处理,构造训练数据 3、构建DataSet类 4、加载数据集 DataLoader 5、定义模型(embedding、线性层、CRF层) 6、初始化模型、loss、优化器、前向传播、反向传播、梯度更新 7、模型训练、评估 8、模型加载、测试
(2)整体代码架构图
【实现】数据预处理 第一步: 查看项目数据集 存放在data文件夹中
关系类型文件 data/relation2id.txt
1 2 3 4 5 导演 0 歌手 1 作曲 2 作词 3 主演 4
relation2id.txt中包含5个类别标签, 文件共分为两列,第一列是类别名称,第二列为类别序号,中间空格符号隔开
1 2 3 今晚会在哪里醒来 黄家强 歌手 《今晚会在哪里醒来》是黄家强的一首粤语歌曲,由何启弘作词,黄家强作曲编曲并演唱,收录于2007年08月01日发行的专辑《她他》中 似水流年 许晓杰 作曲 似水流年,由著名作词家闫肃作词,著名音乐人许晓杰作曲,张烨演唱
train.txt 中包含18267行样本, 每行分为4列元素,元素中间用空格隔开,第一列元素为实体1、第二列元素为实体2、第三列元素为关系类型、第四列元素是原始文本
test.txt中包含5873行样本,数据样式通训练数据集
第二步: 编写Config类项目文件配置代码 (1)目的: 配置项目常用变量,一般这些变量属于不经常改变的,比如: 训练文件路径、模型训练次数、模型超参数等等
(2)代码
代码位置:P04_RE/Bilstm_Attention_RE/config.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import osimport torchbase_dir = os.path.dirname(os.path.abspath(__file__)) print (f'base_dir-->{base_dir} ' )class Config (object ): def __init__ (self ): self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) self.train_data_path = os.path.join(base_dir, 'data/train.txt' ) self.test_data_path = os.path.join(base_dir, 'data/test.txt' ) self.rel_data_path = os.path.join(base_dir, 'data/relation2id.txt' ) self.embedding_dim = 128 self.pos_dim = 32 self.hidden_dim = 200 self.epochs = 50 self.batch_size = 32 self.max_len = 70 self.learning_rate = 1e-3 if __name__ ` '__main__' : conf = Config() print (f'train_data_path-->{conf.train_data_path} ' )
第三步: 编写数据处理相关函数 (1)整体思路
(2)代码
代码位置:P04_RE/Bilstm_Attention_RE/utils/process.py
方法:
1)获取关系类型字典
2)处理数据,获取训练、测试数据集格式
3)文本数字化表示处理,得到word2id, id2word
4)把句子 words 转为 id 形式,并自动补全或截断为 max_len 长度。
5)负值相对编码处理
6)将id进行数字转换,防止为负数,而且进行句子长度的补齐或者截断
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 from P04_RE.Bilstm_Attention_RE.config import Configfrom collections import Counterconf = Config() relation2id = {} with open (conf.rel_data_path, 'r' , encoding='utf-8' ) as f: for line in f: line = line.strip().split(' ' ) relation2id[line[0 ]] = int (line[1 ]) def get_txt_data (file_path ): datas = [] labels = [] positionE1 = [] positionE2 = [] entities = [] count_dict = {k: 0 for k in relation2id} with open (file_path, 'r' , encoding='utf-8' ) as f: for line in f: line_list = line.strip().split(' ' , maxsplit=3 ) if len (line_list) != 4 : continue if line_list[2 ] not in relation2id: continue if count_dict[line_list[2 ]] >= 2000 : continue labels.append(relation2id[line_list[2 ]]) entities.append([line_list[0 ], line_list[1 ]]) sentence_str = line_list[3 ] e1_index = sentence_str.index(line_list[0 ]) e2_index = sentence_str.index(line_list[1 ]) sentence, position1, position2 = [], [], [] for index, word in enumerate (sentence_str): sentence.append(word) position1.append(index - e1_index) position2.append(index - e2_index) datas.append(sentence) positionE1.append(position1) positionE2.append(position2) count_dict[line_list[2 ]] += 1 return datas, labels, positionE1, positionE2, entities def get_word_id (file_path ): datas, labels, positionE1, positionE2, entities = get_txt_data(file_path) vocab_list = ['PAD' , 'UNK' ] for sentence in datas: for word in sentence: if word not in vocab_list: vocab_list.append(word) word2id = {word: i for i, word in enumerate (vocab_list)} id2word = {i: word for i, word in enumerate (vocab_list)} print (f'word2id-->{word2id} ' ) print (f'id2word-->{id2word} ' ) return word2id, id2word if __name__ ` '__main__' : get_word_id(conf.train_data_path)
第四步: 构建Dataset类与dataloader函数
1 2 3 1. 构建Dataset类2. 构建自定义函数collate_fn()3. 构建get_loader_data函数,获得数据迭代器
代码位置:P04_RE/Bilstm_Attention_RE/utils/data_loader.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 from torch.utils.data import Dataset, DataLoaderfrom P04_RE.Bilstm_Attention_RE.config import Configfrom P04_RE.Bilstm_Attention_RE.utils.process import get_txt_dataconf = Config() class MyDataset (Dataset ): def __init__ (self, file_path ): super (MyDataset, self).__init__() self.datas, self.labels, self.positionE1, self.positionE2, self.entities = get_txt_data(file_path) def __len__ (self ): return len (self.datas) def __getitem__ (self, index ): return self.datas[index], self.labels[index], self.positionE1[index], self.positionE2[index], self.entities[index] def collate_fn (batch_data ): print (f'batch_data-->{batch_data} ' ) pass def get_data_loader (): train_dataset = MyDataset(conf.train_data_path) train_dataloader = DataLoader(train_dataset, batch_size=conf.batch_size, shuffle=False , collate_fn=collate_fn, drop_last=True ) test_dataset = MyDataset(conf.test_data_path) test_dataloader = DataLoader(test_dataset, batch_size=conf.batch_size, shuffle=False , collate_fn=collate_fn, drop_last=True ) return train_dataloader, test_dataloader if __name__ ` '__main__' : train_dataloader, test_dataloader = get_data_loader() for x in train_dataloader: print (f'x-->{x} ' ) break
BiLSTM+Attention模型搭建 第一步: 编写模型类的代码 (1)思路
(2)代码
注意:weight不能在模型定义时直接将batch_size写死,否则后期在使用时,每次传入的样本必须是相同的batch_size个。
代码位置:P04_RE/Bilstm_Attention_RE/model/bilstm_atten.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 import torchimport torch.nn as nnimport torch.nn.functional as Ffrom P04_RE.Bilstm_Attention_RE.config import Configfrom P04_RE.Bilstm_Attention_RE.utils.data_loader import word2id, get_data_loaderfrom P04_RE.Bilstm_Attention_RE.utils.process import relation2idconf = Config() class BiLSTM_Attention (nn.Module): def __init__ (self, config, vocab_size, pos_size, tag_size ): ''' :param config: 配置文件对象 :param vocab_size: 文字词表的大小 :param pos_size: 位置编码的数量 :param tag_size: 标签的数量 ''' super (BiLSTM_Attention, self).__init__() self.conf = config self.vocab_size = vocab_size self.pos_size = pos_size self.tag_size = tag_size self.wordEembed = nn.Embedding(self.vocab_size, self.conf.embedding_dim) self.pos1Eembed = nn.Embedding(self.pos_size, self.conf.pos_dim) self.pos2Eembed = nn.Embedding(self.pos_size, self.conf.pos_dim) self.bilstm = nn.LSTM(input_size=self.conf.embedding_dim + self.conf.pos_dim * 2 , hidden_size=self.conf.hidden_dim//2 , batch_first=True , bidirectional=True ) self.fc = nn.Linear(self.conf.hidden_dim, self.tag_size) self.dropout_embed = nn.Dropout(p=0.2 ) self.dropout_bilstm = nn.Dropout(p=0.2 ) self.dropout_attention = nn.Dropout(p=0.2 ) self.att_weight = nn.Parameter(torch.FloatTensor(1 , 1 , self.conf.hidden_dim)).to(self.conf.device) def forward (self, sentence, pos1, pos2 ): embeds = torch.concat([self.wordEembed(sentence), self.pos1Eembed(pos1), self.pos2Eembed(pos2)], dim=-1 ) embeds = self.dropout_embed(embeds) lstm_out, (h_n, c_n) = self.bilstm(embeds) lstm_out = self.dropout_bilstm(lstm_out) H = lstm_out.transpose(1 , 2 ) attention_out = self.attention(H) attention_out = self.dropout_attention(attention_out) result = self.fc(attention_out.squeeze(-1 )) return result def attention (self, H ): ''' :param H: [batch_size, hidden_dim, seq_len] [2, 200, 70] :return: [batch_size, hidden_dim, 1] [2, 200, 1] ''' M = torch.tanh(H) a = F.softmax(torch.matmul(self.att_weight, M), dim=-1 ) r = torch.bmm(H, a.transpose(1 , 2 )) return torch.tanh(r) if __name__ ` '__main__' : vocab_size = len (word2id) pos_size = 142 tag_size = len (relation2id) print (vocab_size, pos_size, tag_size) model = BiLSTM_Attention(conf, vocab_size, pos_size, tag_size).to(conf.device) print (f'model-->{model} ' ) train_dataloader, test_dataloader = get_data_loader() for datas, positionE1, positionE2, labels, entities in train_dataloader: result = model(datas, positionE1, positionE2) print (f'result-->{result} ' ) break
第二步: 编写训练函数 (1)基本步骤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 训练函数基本步骤—— 1.构建数据迭代器Dataloader(包括数据处理与构建数据源Dataset) 2.实例化模型 3.实例化损失函数对象 4.实例化优化器对象 5.定义打印日志参数 6.开始训练 6.1 实现外层大循环epoch 6.2 将模型设置为训练模式 6.3 内部遍历数据迭代器dataloader 1)将数据送入模型得到输出结果 2)计算损失 3)梯度清零 : optimizer.zero_grad() 4)反向传播(计算梯度) : loss.backward() 5)梯度更新(参数更新) : optimizer.step() 6)打印内部训练日志 6.4 使用验证集进行模型评估【将模型设置为评估模式】 6.5 保存模型: torch.save(model.state_dict(), "model_path") 6.6 打印外部训练日志 验证函数基本步骤—— 1.定义打印日志参数 2.将模型设置为评估模式 3.内部遍历数据迭代器dataloader 3.1 将数据送入模型得到输出结果 3.2 计算损失 3.3 处理结果 3.4 统计批次内指标 4.统计整体指标
(2)代码
1)课件中没有遵循标准的训练、验证流程,可以优化。
2)这次没有使用sklearn中的方法来计算指标,而是通过手动计算的,这种方法也可以熟悉一下
代码位置:P04_RE/Bilstm_Attention_RE/train.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 import timeimport torchimport torch.nn as nnfrom tqdm import tqdmfrom P04_RE.Bilstm_Attention_RE.config import Configfrom P04_RE.Bilstm_Attention_RE.model.bilstm_atten import BiLSTM_Attentionfrom P04_RE.Bilstm_Attention_RE.utils.data_loader import get_data_loader, word2idfrom P04_RE.Bilstm_Attention_RE.utils.process import relation2iddef model2dev (test_dataloader, model, criterion ): train_loss = 0 total_iter_num = 0 train_acc = 0 total_sample = 0 model.eval () for index, (datas, positionE1, positionE2, labels, entities) in enumerate (tqdm(test_dataloader, desc='模型评估' )): output = model(datas, positionE1, positionE2) loss = criterion(output, labels) predict_labels = output.argmax(dim=-1 ) train_loss += loss.item() train_acc += sum (predict_labels ` labels) total_iter_num += 1 total_sample += labels.shape[0 ] dev_loss = train_loss / total_iter_num dev_acc = train_acc / total_sample return dev_loss, dev_acc def model2train (conf, vocab_size, pos_size, tag_size ): train_dataloader, test_dataloader = get_data_loader() model = BiLSTM_Attention(conf, vocab_size, pos_size, tag_size).to(conf.device) print (f'model-->{model} ' ) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=conf.learning_rate) start_time = time.time() train_loss = 0 total_iter_num = 0 train_acc = 0 total_sample = 0 best_acc = 0 for epoch in range (conf.epochs): model.train() for index, (datas, positionE1, positionE2, labels, entities) in enumerate (tqdm(train_dataloader, desc='模型训练' )): output = model(datas, positionE1, positionE2) loss = criterion(output, labels) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=10 ) optimizer.step() train_loss += loss.item() predict_labels = output.argmax(dim=-1 ) train_acc += sum (predict_labels ` labels) total_iter_num += 1 total_sample += labels.shape[0 ] if (index + 1 ) % 50 ` 0 : loss_avg = train_loss / total_iter_num acc_avg = train_acc / total_sample end_time = time.time() print (f'轮次:{epoch + 1 } ,,训练损失:{loss_avg:.4 f} ,训练准确率:{acc_avg:.4 f} ,用时:{end_time - start_time:.2 f} 秒' ) dev_loss, dev_acc = model2dev(test_dataloader, model, criterion) if dev_acc > best_acc: best_acc = dev_acc torch.save(model.state_dict(), "save_model/bilstm_atten_best.pth" ) print (f'保存模型,准确率:{best_acc:.4 f} , 平均损失:{dev_loss:.4 f} ' ) end_time = time.time() print (f'训练时间:{end_time - start_time:.2 f} ' ) if __name__ ` '__main__' : conf = Config() vocab_size = len (word2id) pos_size = 142 tag_size = len (relation2id) model2train(conf, vocab_size, pos_size, tag_size)
第三步: 编写模型预测函数 (1)步骤
1 2 3 4 5 1.实例化模型 2.加载模型参数 3.处理数据 4.模型预测 5.结果解析
(2)代码
代码位置:P04_RE/Bilstm_Attention_RE/predict.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import torchfrom P04_RE.Bilstm_Attention_RE.config import Configfrom P04_RE.Bilstm_Attention_RE.model.bilstm_atten import BiLSTM_Attentionfrom P04_RE.Bilstm_Attention_RE.utils.data_loader import word2idfrom P04_RE.Bilstm_Attention_RE.utils.process import relation2id, sentence_padding, position_paddingid2relation = {v: k for k, v in relation2id.items()} conf = Config() vocab_size = len (word2id) pos_size = 142 tag_size = len (relation2id) model = BiLSTM_Attention(conf, vocab_size, pos_size, tag_size).to(conf.device) model.load_state_dict(torch.load('save_model/bilstm_atten_best.pth' , weights_only=True )) def model2predict (sample, entity1, entity2 ): ''' :param sample: 样本(句子) :param entity1: 主实体 :param entity2: 客实体 :return: ''' e1_index = sample.index(entity1) e2_index = sample.index(entity2) sentence, position1, position2 = [], [], [] for index, word in enumerate (sample): sentence.append(word) position1.append(index - e1_index) position2.append(index - e2_index) sentece_ids = sentence_padding(sentence, word2id) position1_ids = position_padding(position1) position2_ids = position_padding(position2) datas_tensor = torch.tensor([sentece_ids], dtype=torch.long).to(conf.device) positionE1_tensor = torch.tensor([position1_ids], dtype=torch.long).to(conf.device) positionE2_tensor = torch.tensor([position2_ids], dtype=torch.long).to(conf.device) model.eval () with torch.no_grad(): result = model(datas_tensor, positionE1_tensor, positionE2_tensor) predict_label = torch.argmax(result[0 ], dim=-1 ) final_label = id2relation[predict_label.item()] print (f'输入的句子:{sample} ' ) print (f'主实体:{entity1} ' ) print (f'客实体:{entity2} ' ) print (f'预测结果:{final_label} ' ) if __name__ ` '__main__' : sample = '2011年,担任爱情片《失恋33天》的编剧,该片改编自鲍鲸鲸的同名小说,由文章、白百何共同主演6' entity1 = '失恋33天' entity2 = '白百何' model2predict(sample, entity1, entity2)
BiLSTM+Attention模型可以做哪些优化来改善模型性能? 1)模型优化
句子嵌入方式:可以使用jieba分词得到词语,然后再使用词语的方式进行嵌入。
替换BiLSTM:将BiLSTM替换成BERT/RoBERTa等这种预训练模型或BiGRU去做嵌入,看是否可以提供模型的语义表达能力。
多头注意力机制:借鉴Transformer中多头注意力机制,将单一注意力拆分到多个子空间,去捕捉不同维度的语义信息。
修改注意力机制的方式:使用transformer中注意力机制的计算方式或者先进行从concat再经过linear层的方式等,来计算注意力机制,看模型的性能效果。
调整随机失活层:调整随机失活层的位置、有无或随机失活比例,来观察模型的性能变化。
2)训练过程的优化
shuffle设置:注意在真正训练时,需要将dataloader中的shuffle设置为True
梯度裁剪:在反向传播时对梯度进行裁剪,防止梯度消失或爆炸。
早停机制:监控验证集上F1值或其他关键指标,如果连续多个epoch未提升或者开始下降,则提前终止训练。
3)训练数据优化
通过过采样或欠采样来解决样本不均衡问题
通过同义词替换、回译、实体替换等方法来扩充数据集。或者直接使用大模型进行训练样本的生成。
Pipeline方法的优缺点
优点:
易于实现,实体模型和关系模型使用独立的数据集,不需要同时标注实体和关系的数据集.
两者相互独立,若关系抽取模型没训练好不会影响到实体抽取.
缺点:
关系和实体两者是紧密相连的,互相之间的联系没有捕捉到.
上游 NER 的错误会直接影响下游关系抽取,容易造成误差积累.
BiLSTM+Attention模型难以处理EPO问题
Joint方法实现关系抽取 Joint方法的原理 (1)概念:通过修改标注方法和模型结构直接输出文本中包含的(ei,rk,ej)三元组
(2)类型
参数共享的联合模型【修改模型结构】
主体、客体和关系的抽取不是严格同步进行的 (通常是依次执行,但是某些情况下也可以其中两个任务一起进行 ) ,各个过程都可以得到一个loss值,整个模型的loss是各过程loss值之和.
联合解码的联合模型【修改标注方法】
主体、客体和关系的抽取是同时进行的,通过一个模型直接得到SPO三元组.
Casrel模型架构 架构图:
详细实现方式:
【实现】代码实现概览 (1)整体步骤
1 2 3 4 5 6 7 8 9 整体实现思路(1-4数据数据预处理,5-8模型部分) : 1、获取数据,例如通过人工数据标注或者第三方数据等。 2、对数据进行处理,构造训练数据【合并在第4步】 3、构建DataSet类 4、加载数据集 DataLoader 5、定义模型 6、初始化模型、loss、优化器、前向传播、反向传播、梯度更新 7、模型训练、评估 8、模型加载、测试
(2)整体代码架构图
【实现】数据预处理 第一步: 查看项目数据集
存放在data文件夹中
关系类型文件: data/relation.json
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 { "0" : "出品公司" , "1" : "国籍" , "2" : "出生地" , "3" : "民族" , "4" : "出生日期" , "5" : "毕业院校" , "6" : "歌手" , "7" : "所属专辑" , "8" : "作词" , "9" : "作曲" , "10" : "连载网站" , "11" : "作者" , "12" : "出版社" , "13" : "主演" , "14" : "导演" , "15" : "编剧" , "16" : "上映时间" , "17" : "成立日期" }
rel.json中包含18个类别标签, json文件可以看作是一个字典,key对应关系的id,value对应关系类型.
1 { "text" : "《今晚会在哪里醒来》是黄家强的一首粤语歌曲,由何启弘作词,黄家强作曲编曲并演唱,收录于2007年08月01日发行的专辑《她他》中" , "spo_list" : [ { "predicate" : "作曲" , "object_type" : "人物" , "subject_type" : "歌曲" , "object" : "黄家强" , "subject" : "今晚会在哪里醒来" } , { "predicate" : "所属专辑" , "object_type" : "音乐专辑" , "subject_type" : "歌曲" , "object" : "她他" , "subject" : "今晚会在哪里醒来" } , { "predicate" : "歌手" , "object_type" : "人物" , "subject_type" : "歌曲" , "object" : "黄家强" , "subject" : "今晚会在哪里醒来" } , { "predicate" : "作词" , "object_type" : "人物" , "subject_type" : "歌曲" , "object" : "何启弘" , "subject" : "今晚会在哪里醒来" } ] }
train.json中包含55433行样本, 每行为一个字典样式
第一个key为”text”, 对应的value为待抽取关系的中文文本, 第二个key为”spo_list”, 对应的value为句子中真实的spo关系三元组列表 (列表中含有多个spo三元组)
以spo_list的其中一个元素为例:元素格式为字典,其中”predictate”代表为关系类型; “object_type”代表尾实体的类型; “subject_type”代表主实体的类型; “object”代表尾实体; “subject” 代表主实体.
dev.json中包含11191行样本,格式同上
est.json中包含13417行样本,格式同上
第二步: 编写Config类项目文件配置代码
(1)目的: 配置项目常用变量,一般这些变量属于不经常改变的,比如: 训练文件路径、模型训练次数、模型超参数等等
(2)代码
1 2 # 使用fastNLP前需要先安装 pip install fastNLP
代码位置:P04_RE/Casrel_RE/config.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import torchfrom fastNLP import Vocabularyfrom transformers import BertTokenizerimport jsonimport osbase_dir = os.path.dirname(os.path.abspath(__file__)) print (f'base_dir-->{base_dir} ' )class Config (object ): def __init__ (self ): self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) self.bert_path = os.path.join(base_dir, 'bert-base-chinese' ) self.num_rel = 18 self.batch_size = 8 self.train_data_path = os.path.join(base_dir, 'data/train.json' ) self.dev_data_path = os.path.join(base_dir, 'data/dev.json' ) self.test_data_path = os.path.join(base_dir, 'data/test.json' ) self.rel_dict_path = os.path.join(base_dir, 'data/relation.json' ) id2rel = json.load(open (self.rel_dict_path, encoding='utf8' )) self.rel_vocab = Vocabulary(padding=None , unknown=None ) self.rel_vocab.add_word_lst(list (id2rel.values())) self.tokenizer = BertTokenizer.from_pretrained(self.bert_path) self.learning_rate = 1e-5 self.bert_dim = 768 self.epochs = 10 if __name__ ` '__main__' : conf = Config() print (f'rel2id-->{conf.rel_vocab.word2idx} ' ) print (f'id2rel-->{conf.rel_vocab.idx2word} ' ) print (conf.rel_vocab.to_word(2 )) print (conf.rel_vocab.to_index('出生地' ))
第三步: 编写数据处理相关函数
(1)获取训练数据思路
(2)补充知识—defaultdict使用
1 2 3 4 5 6 7 defaultdict() 是 Python 标准库 collections 中的一个字典子类,它的作用是 当访问不存在的键时,自动为这个键生成一个默认值,从而避免 KeyError 错误。 语法: from collections import defaultdict d = defaultdict(default_factory) 其中 default_factory 是一个可调用对象,比如 int、list、set、lambda 等。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from collections import defaultdictd = defaultdict(list ) print (f'd-->{d} ' )d['a' ].append(1 ) d['a' ].append(2 ) d['b' ].append(3 ) print (f'd-->{d} ' )print (f"d['ss']-->{d['ss' ]} " )mydict = {} mydict['a' ] = [] mydict['a' ].append(1 ) print (f'mydict-->{mydict} ' )print (mydict['ss' ])
(3)代码
代码位置:P04_RE/Casrel_RE/utils/process.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 from collections import defaultdictfrom random import choiceimport torchfrom P04_RE.Casrel_RE.config import Configconf = Config() def find_head_index (inner_input_ids, entity_id ): ''' 根据原始句子的input_ids和实体的id,找到实体的开始索引 :param inner_input_ids: 原始句子的input_ids :param entity_id: 实体经过bert分词器之后的id :return: 实体的开始索引 ''' entity_len = len (entity_id) for i in range (len (inner_input_ids) - entity_len + 1 ): if inner_input_ids[i:i + entity_len] ` entity_id: return i return -1 def create_label (inner_input_ids, inner_triple, seq_len ): ''' 基于输入的input_ids、三元组和序列长度,获取该样本在训练时的其他输入和输出数据 :param inner_input_ids: 该样本经过bert分词器后的input_ids :param inner_triple: 该样本的所有三元组列表 :param seq_len: input_ids的长度 :return: ''' inner_sub_heads = torch.zeros(seq_len) inner_sub_tails = torch.zeros(seq_len) inner_obj_heads = torch.zeros((seq_len, conf.num_rel)) inner_obj_tails = torch.zeros((seq_len, conf.num_rel)) inner_sub_head2tail = torch.zeros(seq_len) inner_sub_len = torch.ones(1 ) ''' 需要定义一个字典,用来存储 主实体和客实体的开始及结束索引 {(主实体1开始索引,主实体1结束索引): [(客实体的开始索引,客实体的结束索引,关系id), ()...], (主实体2开始索引,主实体2结束索引): [(客实体的开始索引,客实体的结束索引,关系id), ()...], } 作用:defaultdict的作用就是创建一个字典,如果字典中没有对应的key,则创建一个空列表,然后进行append操作 ''' spo_dict = defaultdict(list ) for spo in inner_triple: sub_id = conf.tokenizer(spo['subject' ], add_special_tokens=False )['input_ids' ] obj_id = conf.tokenizer(spo['object' ], add_special_tokens=False )['input_ids' ] rel_id = conf.rel_vocab.to_index(spo['predicate' ]) sub_head_index = find_head_index(inner_input_ids, sub_id) obj_head_index = find_head_index(inner_input_ids, obj_id) if sub_head_index != -1 and obj_head_index != -1 : sub_tail_index = sub_head_index + len (sub_id) - 1 obj_tail_index = obj_head_index + len (obj_id) - 1 spo_dict[(sub_head_index, sub_tail_index)].append((obj_head_index, obj_tail_index, rel_id)) if spo_dict: for sub_head_index, sub_tail_index in spo_dict: inner_sub_heads[sub_head_index] = 1 inner_sub_tails[sub_tail_index] = 1 choice_head_index, choice_tail_index = choice(list (spo_dict.keys())) inner_sub_head2tail[choice_head_index:choice_tail_index + 1 ] = 1 inner_sub_len = torch.tensor([choice_tail_index - choice_head_index + 1 ], dtype=torch.float ) for obj_head_index, obj_tail_index, rel_id in spo_dict.get((choice_head_index, choice_tail_index)): inner_obj_heads[obj_head_index, rel_id] = 1 inner_obj_tails[obj_tail_index, rel_id] = 1 return inner_sub_heads, inner_sub_tails, inner_obj_heads, inner_obj_tails, inner_sub_head2tail, inner_sub_len
第四步: 构建DataSet类与dataloader函数
(1)整体思路
(2)创建DataSet类
代码位置:P04_RE/Casrel_RE/utils/data_loader.py
(3)补充知识—stack使用
1 2 3 4 5 6 7 torch.stack() 是 PyTorch 中用于沿新维度连接一组张量的函数。它会在指定维度上增加一个新维度,并将多个形状相同的张量堆叠在一起。 语法: torch.stack(tensors, dim=0) 其中tensors:一个张量列表,所有张量形状必须一样。 dim:要插入的新维度位置(默认为 0)。
示例:
1 2 3 4 5 6 7 8 9 10 11 import torchtensor1 = torch.tensor([1 , 2 , 3 ]) tensor2 = torch.tensor([2 , 4 , 5 ]) tensor3 = torch.stack([tensor1, tensor2], dim=0 ) print (tensor3)tensor4 = torch.stack([tensor1, tensor2], dim=1 ) print (tensor4)
(4)collate_fn与dataloader
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 import jsonimport torchfrom torch.utils.data import Dataset, DataLoaderfrom P04_RE.Casrel_RE.config import Configfrom P04_RE.Casrel_RE.utils.process import create_labelconf = Config() class MyDataset (Dataset ): def __init__ (self, file_path ): super (MyDataset, self).__init__() self.datas = [json.loads(line) for line in open (file_path, 'r' , encoding='utf-8' )] def __len__ (self ): return len (self.datas) def __getitem__ (self, index ): text = self.datas[index]['text' ] spo_list = self.datas[index]['spo_list' ] return text, spo_list def collate_fn (batch ): text_list = [data[0 ] for data in batch] triple_list = [data[1 ] for data in batch] tokenizer_result = conf.tokenizer.batch_encode_plus(text_list, padding=True ) sub_heads = [] sub_tails = [] obj_heads = [] obj_tails = [] sub_len = [] sub_head2tail = [] batch_size = len (text_list) for index in range (batch_size): inner_input_ids = tokenizer_result['input_ids' ][index] inner_triple = triple_list[index] seq_len = len (inner_input_ids) inner_sub_heads, inner_sub_tails, inner_obj_heads, inner_obj_tails, inner_sub_head2tail, inner_sub_len = create_label(inner_input_ids, inner_triple, seq_len) sub_heads.append(inner_sub_heads) sub_tails.append(inner_sub_tails) obj_heads.append(inner_obj_heads) obj_tails.append(inner_obj_tails) sub_len.append(inner_sub_len) sub_head2tail.append(inner_sub_head2tail) input_ids = torch.tensor(tokenizer_result['input_ids' ], dtype=torch.long).to(conf.device) mask = torch.tensor(tokenizer_result['attention_mask' ], dtype=torch.long).to(conf.device) sub_head2tail = torch.stack(sub_head2tail, dim=0 ).to(conf.device) sub_len = torch.stack(sub_len, dim=0 ).to(conf.device) sub_heads = torch.stack(sub_heads, dim=0 ).to(conf.device) sub_tails = torch.stack(sub_tails, dim=0 ).to(conf.device) obj_heads = torch.stack(obj_heads, dim=0 ).to(conf.device) obj_tails = torch.stack(obj_tails, dim=0 ).to(conf.device) inputs = { 'input_ids' : input_ids, 'mask' : mask, 'sub_head2tail' : sub_head2tail, 'sub_len' : sub_len } labels = { 'sub_heads' : sub_heads, 'sub_tails' : sub_tails, 'obj_heads' : obj_heads, 'obj_tails' : obj_tails } return inputs, labels def get_data_loader (): train_dataset = MyDataset(conf.train_data_path) train_dataloader = DataLoader(dataset=train_dataset, batch_size=conf.batch_size, shuffle=False , collate_fn=collate_fn, drop_last=True ) dev_dataset = MyDataset(conf.dev_data_path) dev_dataloader = DataLoader(dev_dataset, batch_size=conf.batch_size, shuffle=True , collate_fn=collate_fn, drop_last=True ) test_dataset = MyDataset(conf.test_data_path) test_dataloader = DataLoader(test_dataset, batch_size=conf.batch_size, shuffle=True , collate_fn=collate_fn, drop_last=True ) return train_dataloader, dev_dataloader, test_dataloader if __name__ ` '__main__' : train_dataloader, dev_dataloader, test_dataloader = get_data_loader() for inputs, labels in train_dataloader: print (f'inputs["input_ids"]-->{inputs["input_ids" ].shape} ' ) print (f'inputs["mask"]-->{inputs["mask" ].shape} ' ) print (f'inputs["sub_head2tail"]-->{inputs["sub_head2tail" ].shape} ' ) print (f'inputs["sub_len"]-->{inputs["sub_len" ].shape} ' ) print (f'labels["sub_heads"]-->{labels["sub_heads" ].shape} ' ) print (f'labels["sub_tails"]-->{labels["sub_tails" ].shape} ' ) print (f'labels["obj_heads"]-->{labels["obj_heads" ].shape} ' ) print (f'labels["obj_tails"]-->{labels["obj_tails" ].shape} ' ) break
【掌握】Casrel模型搭建 第一步: 编写模型类的代码 (1)思路
(2)补充知识
1)BCELoss
1 在 PyTorch 中,torch.nn.BCELoss 是 二元交叉熵损失函数(Binary Cross Entropy Loss),用于二分类任务中,衡量预测概率和真实标签之间的差距。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import torchy_pred = torch.tensor([1.6901 , -0.5459 , -0.2469 ], requires_grad=True ) y_true = torch.tensor([0 , 1 , 0 ], dtype=torch.float32) sigmoid_result = torch.sigmoid(y_pred) print (f'sigmoid_result-->{sigmoid_result} ' )loss = torch.nn.BCELoss(reduction='none' ) loss_result = loss(sigmoid_result, y_true) print (f'loss_result-->{loss_result} ' )
2)repeat
1 2 3 4 5 6 7 tensor.repeat() 是用来在各个维度上重复 tensor 的数据,从而生成一个更大的 tensor。 注意:repeat() 是对数据的复制,不是广播(broadcasting) 语法: new_tensor = tensor.repeat(repeats) 其中repeats:一个元组或多个整数,表示每个维度上重复的次数。
示例:
1 2 3 4 5 6 import torchts = torch.tensor([[1 , 2 , 3 ]]) print (ts.shape)ts2 = ts.repeat((2 , 1 )) print (ts2.shape)print (ts2)
(3)代码
代码位置:P04_RE/Casrel_RE/model/CasrelModel.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 import torchimport torch.nn as nnfrom transformers import BertModelfrom P04_RE.Casrel_RE.config import Configfrom P04_RE.Casrel_RE.utils.data_loader import get_data_loaderclass Casrel (nn.Module): def __init__ (self, conf ): super (Casrel, self).__init__() self.bert = BertModel.from_pretrained(conf.bert_path) self.sub_heads_linear = nn.Linear(conf.bert_dim, 1 ) self.sub_tails_linear = nn.Linear(conf.bert_dim, 1 ) self.obj_heads_linear = nn.Linear(conf.bert_dim, conf.num_rel) self.obj_tails_linear = nn.Linear(conf.bert_dim, conf.num_rel) self.conf = conf def forward (self, input_ids, mask, sub_head2tail, sub_len ): bert_output = self.get_encoded_text(input_ids, mask) pre_sub_heads, pre_sub_tails = self.get_subs(bert_output) pre_obj_heads, pre_obj_tails = self.get_objs_and_rels(bert_output, sub_head2tail, sub_len) result_dict = { 'pre_sub_heads' : pre_sub_heads, 'pre_sub_tails' : pre_sub_tails, 'pre_obj_heads' : pre_obj_heads, 'pre_obj_tails' : pre_obj_tails, 'mask' : mask } return result_dict def get_encoded_text (self, input_ids, mask ): bert_output = self.bert(input_ids, attention_mask=mask)['last_hidden_state' ] return bert_output def get_subs (self, bert_output ): pre_sub_heads = torch.sigmoid(self.sub_heads_linear(bert_output)) pre_sub_tails = torch.sigmoid(self.sub_tails_linear(bert_output)) return pre_sub_heads, pre_sub_tails def get_objs_and_rels (self, bert_output, sub_head2tail, sub_len ): sub_head2tail = sub_head2tail.unsqueeze(dim=1 ) matmul_result = torch.matmul(sub_head2tail, bert_output) avg_result = matmul_result / sub_len.unsqueeze(dim=1 ) sum_input = avg_result + bert_output pre_obj_heads = torch.sigmoid(self.obj_heads_linear(sum_input)) pre_obj_tails = torch.sigmoid(self.obj_tails_linear(sum_input)) return pre_obj_heads, pre_obj_tails def compute_loss (self, pre_sub_heads, pre_sub_tails, pre_obj_heads, pre_obj_tails, mask, sub_heads, sub_tails, obj_heads, obj_tails ): loss1 = self.loss(pre_sub_heads, sub_heads, mask) loss2 = self.loss(pre_sub_tails, sub_tails, mask) mask = mask.unsqueeze(dim=2 ).repeat(1 , 1 , self.conf.num_rel) loss3 = self.loss(pre_obj_heads, obj_heads, mask) loss4 = self.loss(pre_obj_tails, obj_tails, mask) return loss1 + loss2 + loss3 + loss4 def loss (self, predict, label, mask ): ''' :param predict: 预测的结果(linear层经过sigmoid之后的结果) :param label: 真实的标签 :param mask: attention_mask :return: 平均损失 ''' predict = predict.squeeze(dim=2 ) criterion = nn.BCELoss(reduction='none' ) loss_tensor = criterion(predict, label) avg_loss = (loss_tensor * mask).sum () / mask.sum () return avg_loss if __name__ ` '__main__' : conf = Config() model = Casrel(conf).to(conf.device) print (model) train_dataloader, dev_dataloader, test_dataloader = get_data_loader() for inputs, labels in train_dataloader: result = model(**inputs) loss = model.compute_loss(**result, **labels) print (f'loss--->{loss} ' ) break
第二步: 编写工具类函数,训练函数,验证函数,测试函数 (1)训练函数
1)AdamW优化器
拓展知识:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 no_decay = ["bias" , "LayerNorm.bias" , "LayerNorm.weight" ] param_optimzer = [('obj_heads_linear.weight' , '参数1' ), ('obj_heads_linear.bias' , '参数2' ), ('ssssLayerNorm.bias' , '参数3' )] list1 = [p for n, p in param_optimzer if not any (nd in n for nd in no_decay)] print (list1)bl1 = [nd in 'obj_heads_linear.weight' for nd in no_decay] print (bl1)bl2 = [nd in 'obj_heads_linear.bias' for nd in no_decay] print (bl2)bl1 = any (nd in 'obj_heads_linear.weight' for nd in no_decay) print (bl1)bl2 = any (nd in 'obj_heads_linear.bias' for nd in no_decay) print (bl2)optimizer_grouped_parameters = [ {"params" : [p for n, p in param_optimzer if not any (nd in n for nd in no_decay)], "weight_decay" : 0.01 }, {"params" : [p for n, p in param_optimzer if any (nd in n for nd in no_decay)], "weight_decay" : 0.0 }] print (optimizer_grouped_parameters)
2)代码
代码位置:P04_RE/Casrel_RE/train.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import timeimport torch.nn as nnfrom torch.optim import AdamWfrom tqdm import tqdmfrom P04_RE.Casrel_RE.config import Configfrom P04_RE.Casrel_RE.model.CasrelModel import Casrelfrom P04_RE.Casrel_RE.utils.data_loader import get_data_loaderconf = Config() def model2dev (model, dev_dataloader ): pass def model2train (): train_dataloader, dev_dataloader, test_dataloader = get_data_loader() model = Casrel(conf).to(conf.device) param_optimizer = list (model.named_parameters()) no_decay = ["bias" , "LayerNorm.bias" , "LayerNorm.weight" ] optimizer_grouped_parameters = [ {"params" : [p for n, p in param_optimizer if not any (nd in n for nd in no_decay)], "weight_decay" : 0.01 }, {"params" : [p for n, p in param_optimizer if any (nd in n for nd in no_decay)], "weight_decay" : 0.0 }] optimizer = AdamW(optimizer_grouped_parameters, lr=conf.learning_rate) start_time = time.time() train_loss = 0 total_step = 0 for epoch in range (conf.epochs): model.train() for index, (inputs, labels) in enumerate (tqdm(train_dataloader, desc='Casrel模型训练' )): outputs = model(**inputs) loss = model.compute_loss(**outputs, **labels) optimizer.zero_grad() loss.backward() nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=10 ) optimizer.step() train_loss += loss.item() total_step += 1 if (index+1 ) % 200 ` 0 : print ('epoch:%d------------loss:%.4f' % (epoch, train_loss/total_step)) break result = model2dev(model, dev_dataloader) break if __name__ ` '__main__' : model2train()
**3)面试题:Casrel模型中,Bert为什么要参与反向传播进行参数更新?**
**任务特定调整:**虽然BERT是预训练的,但它并不是针对特定任务(如关系抽取)进行优化的。通过在特定任务上进行微调(即反向传播更新参数),可以使BERT的表示更适合关系抽取的任务。这样,BERT模型能够更好地理解实体间的关系。
**领域适应:**预训练的BERT是在大规模语料上训练的,可能没有针对具体领域的知识或语言模式。通过微调BERT,可以使其更适应目标领域的数据,改善抽取效果。
**经验结果:**大量后续工作和实践都表明:在下游抽取、分类、生成等任务里,给BERT或其他Transformer设置较小的学习率,整体端到端的微调,一般比“冻结+只微调顶层”要好2—5个百分点的效果,尤其在中大型数据集上。
(2)验证函数【完整代码】
1)思路
整体思路:
抽取主实体和客实体的思路:
2)代码
代码位置:同样在 P04_RE/Casrel_RE/train.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 import timeimport pandas as pdimport torchimport torch.nn as nnfrom torch.optim import AdamWfrom tqdm import tqdmfrom P04_RE.Casrel_RE.config import Configfrom P04_RE.Casrel_RE.model.CasrelModel import Casrelfrom P04_RE.Casrel_RE.utils.data_loader import get_data_loaderconf = Config() def convert_score_to_zero_one (ts ): ''' 将传进来的张量转成0或1 :param ts: 传进来的张量,也就是未处理的预测结果 :return: ''' ts[ts>=0.5 ] = 1 ts[ts<0.5 ] = 0 return ts def extract_sub (sub_head, sub_tail ): ''' :param sub_head: 主实体的开始位置 :param sub_tail: 主实体的结束位置 :return: ''' heads_index = torch.arange(0 , len (sub_head), device=conf.device)[sub_head ` 1 ] tails_index = torch.arange(0 , len (sub_tail), device=conf.device)[sub_tail ` 1 ] subs = [] for head_index, tail_index in zip (heads_index, tails_index): if head_index <= tail_index: subs.append((head_index.item(), tail_index.item())) return subs def extract_obj (obj_head, obj_tail ): ''' :param obj_head: 客实体的开始位置及关系信息 :param obj_tail: 客实体的结束位置及关系信息 :return: ''' obj_head = obj_head.T obj_tail = obj_tail.T obj_and_rel = [] for rel_id in range (conf.num_rel): head = obj_head[rel_id] tail = obj_tail[rel_id] objs = extract_sub(head, tail) if len (objs) > 0 : for obj in objs: obj_and_rel.append((rel_id, obj[0 ], obj[1 ])) return obj_and_rel def model2dev (model, dev_dataloader ): df = pd.DataFrame(columns=['TP' , 'PRED' , "REAL" , 'p' , 'r' , 'f1' ], index=['sub' , 'triple' ]) df.fillna(0 , inplace=True ) model.eval () for index, (inputs, labels) in enumerate (tqdm(dev_dataloader, desc='Casrel模型验证' )): outputs = model(**inputs) pre_sub_heads = convert_score_to_zero_one(outputs['pre_sub_heads' ]) pre_sub_tails = convert_score_to_zero_one(outputs['pre_sub_tails' ]) pre_obj_heads = convert_score_to_zero_one(outputs['pre_obj_heads' ]) pre_obj_tails = convert_score_to_zero_one(outputs['pre_obj_tails' ]) for batch_index in range (conf.batch_size): pre_sub_head = pre_sub_heads[batch_index].squeeze(-1 ) pre_sub_tail = pre_sub_tails[batch_index].squeeze(-1 ) pre_sub = extract_sub(pre_sub_head, pre_sub_tail) real_sub = extract_sub(labels['sub_heads' ][batch_index], labels['sub_tails' ][batch_index]) pre_obj = extract_obj(pre_obj_heads[batch_index], pre_obj_tails[batch_index]) real_obj = extract_obj(labels['obj_heads' ][batch_index], labels['obj_tails' ][batch_index]) df.loc['sub' , 'PRED' ] += len (pre_sub) df.loc['sub' , 'REAL' ] += len (real_sub) for sub in pre_sub: if sub in real_sub: df.loc['sub' , 'TP' ] += 1 df.loc['triple' , 'PRED' ] += len (pre_obj) df.loc['triple' , 'REAL' ] += len (real_obj) for obj in pre_obj: if obj in real_obj: df.loc['triple' , 'TP' ] += 1 sub_precision = df.loc['sub' , 'TP' ] / df.loc['sub' , 'PRED' ] df.loc['sub' , 'p' ] = sub_precision sub_recall = df.loc['sub' , 'TP' ] / df.loc['sub' , 'REAL' ] df.loc['sub' , 'r' ] = sub_recall sub_f1 = 2 * sub_precision * sub_recall / (sub_precision + sub_recall) df.loc['sub' , 'f1' ] = sub_f1 obj_precision = df.loc['triple' , 'TP' ] / df.loc['triple' , 'PRED' ] df.loc['triple' , 'p' ] = obj_precision obj_recall = df.loc['triple' , 'TP' ] / df.loc['triple' , 'REAL' ] df.loc['triple' , 'r' ] = obj_recall obj_f1 = 2 * obj_precision * obj_recall / (obj_precision + obj_recall) df.loc['triple' , 'f1' ] = obj_f1 return sub_precision, sub_recall, sub_f1, obj_precision, obj_recall, obj_f1, df def model2train (): train_dataloader, dev_dataloader, test_dataloader = get_data_loader() model = Casrel(conf).to(conf.device) param_optimizer = list (model.named_parameters()) no_decay = ["bias" , "LayerNorm.bias" , "LayerNorm.weight" ] optimizer_grouped_parameters = [ {"params" : [p for n, p in param_optimizer if not any (nd in n for nd in no_decay)], "weight_decay" : 0.01 }, {"params" : [p for n, p in param_optimizer if any (nd in n for nd in no_decay)], "weight_decay" : 0.0 }] optimizer = AdamW(optimizer_grouped_parameters, lr=conf.learning_rate) start_time = time.time() train_loss = 0 total_step = 0 best_triple_f1 = 0 for epoch in range (conf.epochs): model.train() for index, (inputs, labels) in enumerate (tqdm(train_dataloader, desc='Casrel模型训练' )): outputs = model(**inputs) loss = model.compute_loss(**outputs, **labels) optimizer.zero_grad() loss.backward() nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=10 ) optimizer.step() train_loss += loss.item() total_step += 1 if (index+1 ) % 20 ` 0 : print ('epoch:%d------------loss:%.4f' % (epoch+1 , train_loss/total_step)) result = model2dev(model, dev_dataloader) print (f'df-->{result[-1 ]} ' ) if result[-2 ] > best_triple_f1: print (f'当前模型效果更好,保存模型中...当前轮次为{epoch+1 } , 当前模型的triple_f1为{result[-2 ]} ' ) best_triple_f1 = result[-2 ] torch.save(model.state_dict(), 'save_model/casrel_best_f1.pth' ) end_time = time.time() print (f'训练时间:{end_time - start_time:.2 f} ' ) if __name__ ` '__main__' : model2train()
训练结果:
验证在epoch外部:
验证在epoch内部:
同验证函数,调用方式如下
1 2 3 4 5 6 7 8 9 10 11 model = Casrel(conf).to(conf.device) model.load_state_dict(torch.load('save_model/casrel_best_f1.pth' , weights_only=True )) train_dataloader, dev_dataloader, test_dataloader = get_data_loader() sub_precision, sub_recall, sub_f1, obj_precision, obj_recall, obj_f1, df = model2dev(model, test_dataloader) print (f'模型在测试集上的表现为:\n{df} ' )
这个是在epoch外部进行评估的模型在测试集上的表现。
这个是在epoch内部进行评估的模型在测试集上的表现。
(4)后续优化
升级预训练模型:从基础 bert-base 换成效果更好的中文预训练,如 RoBERTa-wwm-ext、MacBERT、Erlangshen-RoBERTa-large 等。
修改主实体和bert隐藏层的融合方式:可以使用拼接的方式(Bert隐藏层输入拼接上所取主实体的平均向量;另外也可以将所取的主实体的向量前拼接N个1,其他的向量拼接N个0),或者使用增强的方式(将所取的主实体对应的张量扩大N倍)。
增加实体边界探索:在 subject/object 边界预测上加一个前馈全连接层 或者是BiLSTM+Linear层,提高识别的准确性。
增加drop层:通过增加几个不同的drop层,提高模型的过拟合能力。
修改0/1的阈值:目前设置的阈值为0.5,可以修改这个阈值进行训练或预测,比如修改成0.45,0.55等。
增加训练数据:可以使用数据增强,或更多标注数据。
第三步: 编写模型预测函数 (1)思路
(2)代码
代码位置:P04_RE/Casrel_RE/predict.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 import torchfrom P04_RE.Casrel_RE.config import Configfrom P04_RE.Casrel_RE.model.CasrelModel import Casrelfrom P04_RE.Casrel_RE.train import convert_score_to_zero_one, extract_sub, extract_objconf = Config() def model2predict (sample ): model = Casrel(conf).to(conf.device) model.load_state_dict(torch.load('save_model/casrel_best_f1.pth' , weights_only=True )) tokenizer_result = conf.tokenizer(sample) input_ids = torch.tensor([tokenizer_result['input_ids' ]]).to(conf.device) mask = torch.tensor([tokenizer_result['attention_mask' ]]).to(conf.device) model.eval () with torch.no_grad(): bert_output = model.get_encoded_text(input_ids, mask) pre_sub_heads, pre_sub_tails = model.get_subs(bert_output) sub_heads = convert_score_to_zero_one(pre_sub_heads) sub_tails = convert_score_to_zero_one(pre_sub_tails) subs = extract_sub(sub_heads.squeeze(), sub_tails.squeeze()) spo_list = [] if len (subs) > 0 : for sub in subs: text_list = conf.tokenizer.convert_ids_to_tokens(input_ids[0 ]) sub_str = '' .join(text_list[sub[0 ]:sub[1 ]+1 ]) if '[CLS]' in sub_str or '[SEP]' in sub_str or '[PAD]' in sub_str: continue sub_head2tail = torch.zeros(len (input_ids[0 ])).to(conf.device) sub_head2tail[sub[0 ]:sub[1 ]+1 ] = 1 sub_len = torch.tensor([sub[1 ] - sub[0 ] + 1 ], dtype=torch.float ).to(conf.device) pre_obj_heads, pre_obj_tails = model.get_objs_and_rels(bert_output, sub_head2tail.unsqueeze(0 ), sub_len.unsqueeze(0 )) obj_heads = convert_score_to_zero_one(pre_obj_heads) obj_tails = convert_score_to_zero_one(pre_obj_tails) obj_and_rels = extract_obj(obj_heads.squeeze(), obj_tails.squeeze()) if len (obj_and_rels) ` 0 : print (f'没有抽取到{sub_str} 的客实体及关系' ) else : for rel_id, head, tail in obj_and_rels: relation = conf.rel_vocab.to_word(rel_id) obj_str = '' .join(text_list[head:tail+1 ]) if '[CLS]' in obj_str or '[SEP]' in obj_str or '[PAD]' in obj_str: continue sub_spo = {} sub_spo['subject' ] = sub_str sub_spo['predicate' ] = relation sub_spo['object' ] = obj_str spo_list.append(sub_spo) result = { 'text' : sample, 'spo_list' : spo_list } return result if __name__ ` '__main__' : result = model2predict('1997年,李柏光从北京大学法律系博士毕业' ) print (result)
文本分类任务
项目中用了那些模型,为什么选择这些模型?
项目中使用了随机森林模型,fasttext模型,和bert模型,使用随机森林模型和fasttext模型作为基线模型,为了快速判断数据是否存在明显问题,如标签错误,特征缺失或者任务本身是否具有可学习性,如果基线模型能达到较高性能,说明数据存在显著规律,如果性能非常差,可能需要检查数据质量,重新评估任务定义是否合理,如果基线模型效果非常好,也就无需复杂模型。
2. bert模型的原理是什么?如何构建的? bert模型基于transformer模型的encoder部分,双向上下文建模,其中包括输入部分,编码器部分,输出部分,输入部分将文本转换为词向量,其中输入的数据结合了词向量(token embedding),位置编码(position embedding),句子编码(segment embedding),到编码器层,编码器层包括多头注意力机制层,残差链接和规范化层和前馈神经网络,多头注意力机制层用于捕捉句子的不同语义信息,q*k的转置/根号d再通过softmax层再乘以V来计算出注意力机制,最后再融合多头的信息到残差链接层和规范化层,残差链接层防止信息丢失,保持训练稳定,层归一化加速收敛,防止过拟合。前馈神经网络层,对每个词向量进行特征强化,再经过残差链接和规范化层最后堆叠多个编码器层后到输出部分,通过全连接层输出。
详细讲一下你用到的随机森林的算法原理和使用\
随机森林算法是一种集成学习方法,具体属于 Bagging 类型。它由多棵决策树组成
给定训练集D,构建多个训练子集),每个通过随机采样产生。对每个子集训练一棵决策树。在每个树节点选择划分时,仅考虑一部分特征(例如,总特征数的一小部分)。最终预测时:分类:投票多数类,回归:取预测平均值。
介绍一下fasttext在有监督学习下怎么使用的\
项目中使用的是fasttext有监督学习的文本分类,将文本转化为词向量,词向量相加求平均为句向量,句向量输入到线性分类器,通过交叉熵来计算损失。
5. 模型蒸馏有哪几种方式?如何进行软标签蒸馏的? 模型蒸馏有3种方式,硬标签蒸馏,软标签蒸馏,中间层蒸馏,软标签蒸馏,是将复杂模型的知识传递给简单模型,构建教师模型和学生模型,教师模型和学生模型的softmax输出引入温度参数T,当T小于1时学生模型学到的知识少,趋向于硬标签,当T大于1时,曲线更加平滑,学生模型可以学习到更多的知识,而T趋向于无穷大,那概率分布相当于平均分布。最后引入alpha参数来衡量教师模型和学生模型的知识占比,当alpha趋向于0,倾向于教师模型,当alpha趋向于1,倾向于学生模型。
6. 介绍下模型量化,介绍下模型量化有几种方式,在项目中如何使用的 模型量化是将模型从高精度量化为低精度的一个过程,量化分为训练中量化,量化感知训练,训练后量化,动态量化和静态量化,在项目种使用的时动态量化,在模型训练后的激活float32量化为int8,与提前量化好的权重int8进行训练,输出的激活为int32,再将其反量化为float32输入到下一层。
说一下fasttext的负采样
Fasttext负采样是为了平衡样本数据,正例样本保持不变,随机对负例样本进行随机采样来达到平衡样本数据。
深度学习有那些激活函数?
Sigmoid函数,rule函数,tanh函数。
collect_fn函数是什么?
该函数是将批次数据中的input_ids,attention_mask,label转换为词向量,能够直接让bert模型使用。
3、项⽬架构 • 第⼀阶段:基线模型(Random Forest)⾸先选择⽤TF-IDF特征 + Random Forest作为基线模型。它的⽬的是快速验证数据预处理的有效性,并为后续所有模型建⽴⼀个性能基准参照物。
• 第⼆阶段:捕捉词序特征(FastText)这个模型⾮常轻量⾼效,训练速度快,⽽且能捕捉件中的词序规律,并对拼写错误有很强的鲁棒性,达到了不错的效果,作为⽣产环境中的⼀个⾼性能备选⽅案。
• 第三阶段:深度语义理解(BERT)但前两个模型对解决语义模糊问题效果不好,必须选择具备深度的上下⽂理解能⼒的模型。因此,我采⽤了BERT模型进⾏微调(Fine-tuning)。它达到了最⾼93.5%的准确率。
• 第四阶段:为部署⽽优化(知识蒸馏)BERT效果虽好,但模型参数多速度慢,线上直接⽤成本太⾼。为了解决部署问题,决定使⽤BiLSTM作为学⽣模型来蒸馏bert模型。
• 第五阶段:项⽬部署:在部署阶段,我使⽤ Flask 框架将蒸馏后的BiLSTM模型封装成了API。这样做实现了模型服务
与业务系统的解耦,前端或其他服务只需通过HTTP请求传递邮件⽂本,即可实时获取分类结果。
4、项⽬中遇到使⽤的问题 在这个项⽬中,我主要攻克了⼏个核⼼难题:
专业术语导致的准确率波动:设计⾏业术语(如“⽔电位”、“软装”)极易被通⽤分词⼯具切错。我采取的策略是:深度分析业务⽂档,构建了⼀套领域词典,并集成到分词器中,从根本上提升了⽂本预处理的质量。
模型蒸馏过程中的稳定性问题:在蒸馏初期,学⽣模型难以学到教师模型的精髓。我通过调整损失函数权重(平衡软标签损失和硬标签损失) 和 精细化调优超参数,最终稳定了训练过程,成功实现了知识的⾼效迁移。
2.你怎么做的这个项目?用的啥?
基线模型:随机森林
迭代模型:Fasttext
优化模型:Bert
上线模型:BiLSTM,以BERT作为教师模型蒸馏
3.随机森林中,怎么将句子文本转化为词向量的?
先使用结巴分词器对句子进行拆分,然后通过TF-IDF对 拆分后的词 进行加权处理。
4.讲解一下Fasttext中的霍夫曼树?核心思想:
根据词频构建:
高频词离根节点近(路径短)
低频词离根节点远(路径长)
路径即编码:每个词对应树中一条唯一路径(一串0/1编码)。
预测概率变为路径概率乘积:
传统 Softmax 需要计算所有节点概率
分层 Softmax 只需计算路径上每个节点的二分类概率(左/右子树)
5.讲解一下Bert模型?5.1 核心双向 Self-Attention:
传统模型的局限:过去模型(如 ELMo、GPT)只能从左到右或从右到左单向编码上下文。
BERT 的突破:通过双向Self-Attention 机制,同时学习文本左右两侧的上下文信息。
5.2 预训练+微调模型:
预训练:用 “无标注数据” 学通用语言规律
这一步是 BERT 的核心优势:它先用海量无标注文本 ,让模型 “自学” 通用的语言逻辑。
理解词语的上下文关联(如 “降噪” 和 “耳机” 常搭配,“快充” 和 “手机” 强相关);
掌握语法、语义甚至常识(如 “苹果” 在 “吃苹果” 中是水果,在 “苹果手机” 中是品牌)。
这一步完全不需要任何标注 (不需要人工给文本打标签),模型靠 “无监督学习” 就能掌握这些通用语言能力 —— 相当于让模型先 “学会说人话、理解人话”,打下扎实的 “语言基础”。
微调:用 “少量标注数据” 适配具体任务
当模型已经通过预训练具备 “通用语言理解能力” 后,再针对具体任务(比如你的 “商品描述→类目分类”)进行微调:
只需要少量任务相关的标注数据(比如几百条、上千条 “商品描述 + 类目标签”,远少于传统模型需要的几万 / 几十万条);
不需要重新训练整个模型,只需在预训练好的 BERT 基础上,加一个简单的 “分类层”,用少量标注数据 “微调” 模型参数 —— 本质是让模型把已有的 “通用语言知识”,快速适配到 “商品分类” 这个具体任务上。
6.Bert两个预训练任务是啥?
MLM(Masked Language Model):随机遮盖 15% 的单词,让模型预测被遮盖的词(如 “我 [MASK] 苹果” → “吃”)。
NSP(Next Sentence Prediction):判断两个句子是否连续(如 “天气真好” 和 “我们去公园” → 是连续的)。
7.Bert模型输入的话输入哪三个值?
BERT 的输入由三部分组成:
Token Embeddings:单词本身的向量(含特殊符号如 [CLS]、[SEP])。
Segment Embeddings:区分句子 A 和 B(用于 NSP 任务)。
Position Embeddings:标记单词的位置信息。
原始 Transformer采用的是固定的正弦余弦位置编码
BERT 的位置编码采用可学习的位置嵌入。
BERT 预先定义一个 “位置嵌入矩阵”,其形状为 [max_seq_len, d_model]:
max_seq_len:BERT 支持的最大序列长度(如基础版 BERT 是 512),即模型最多能处理 512 个词的句子;d_model:与 BERT 的词嵌入维度一致(如 768)。
这个矩阵中的每个元素都是可训练的参数,而非预定义的常数。在模型训练(包括预训练和微调阶段)过程中,位置嵌入矩阵会与其他参数(如自注意力层权重)一起,通过梯度下降不断优化更新。
9.讲解一下注意力机制的计算公式?$$
$$
$$
10.讲解项目中用到的蒸馏,使用了什么损失函数并介绍公式项目中采用训练好的Bert模型作为教师模型,负责传授知识,采用BiLSTM模型作为学生模型,学习参数。
使用了KL散度损失函数来衡量两个模型的预测概率差值。
公式如下:
11.如何解决过拟合问题?机器学习
正则化:L1 正则、L2 正则
减少特征维度:
减枝(树模型):预减枝、后减枝
数据增强
集成学习
深度学习
正则化:L1 正则、L2 正则
Dropout
early stop
归一化操作:批归一化、层归一化
降低模型复杂度:减少网络深度和宽度
数据增强:同义词替换、回译法、大模型生成
12.你知道哪些激活函数?你项目中的Bert模型里面用的什么激活函数?
激活函数:ReLU,Sigmoid,Tanh,GELU,Softmax
Bert模型中用的:GELU激活函数
13.介绍一下LSTMLSTM 通过设计细胞状态(Cell State) 和三个门控单元,实现了对信息的 “选择性记忆” 和 “选择性遗忘”,从而有效捕捉长序列中的长期依赖。
细胞状态
类似一条 “信息传送带”,贯穿整个序列过程,直接传递基本不变的信息,避免了梯度在长序列中快速衰减。
细胞状态的更新由门控机制控制,仅在必要时修改,保持了信息的长期稳定性。
三个门控单元
遗忘门 决定 “细胞状态中哪些历史信息需要被遗忘”
输入门 决定 “哪些新信息需要被存入细胞状态”。
细胞状态更新 结合遗忘门和输入门的结果,更新当前细胞状态:“先遗忘部分历史信息,再加入筛选后的新信息”。
输出门 决定 “基于当前细胞状态,输出哪些信息作为隐藏状态”。
问题:介绍一下BERT模型,模型输入是啥?经过哪些步骤?输出是啥? 答案:BERT模型主要用Transformer的encoder层(编码层)。输入部分是经过词嵌入层和位置编码的词向量;进入模型后,会经过多头注意力,再进行残差连接,接着进行前馈网络,最后再进行残差连接;输出是CLS的词向量,将其作为最后全分类的向量用于分类任务。BERT内部用的激活函数是Tanh。
问题:残差连接是怎么做的?为什么要做残差连接? 答案:残差连接是在多头注意力机制等操作后,将该操作的输入加上输出,再进行标准化,得到结果输出到下一层。作用是防止梯度消失和梯度爆炸,还能加速收敛、保留原始特征信息。
问题:进行BERT模型蒸馏时,双向LSTM是怎么做蒸馏的?具体的。 答案:通过软标签加硬标签的组合进行模型训练。硬标签是双向LSTM模型的输出经过Softmax层后的输出概率分布,对比真实标签用交叉熵损失计算;还用到了KL散度损失(表述不完整)。
问题:软标签相关的参数T(温度)的作用是什么? 答案:有点忘了。(面试官提示需回去查看)
问题:LSTM每个细胞由什么组成? 答案:由三门一细胞组成,分别是输入门、输出门、遗忘门和细胞状态这四部分。
笔记 https://kduk730tiw.feishu.cn/docx/UO8PdUywpofPoyxurFKcpkSInYb
机器学习题库 1:什么是样本、特征、标签?请举例说明。
1 2 3 样本:数据集中的单个数据个体,是模型学习的基本单位。 特征:描述样本的属性或变量,是模型的输入。 标签:样本的目标输出(在有监督学习中存在),用于指导模型学习
2:解释 x_train、y_train、x_test、y_test 的含义及用途。
1 2 3 4 5 x_train:训练集的特征数据,是模型学习的输入。 y_train:训练集的标签数据,与 x_train 对应,用于指导模型参数学习。 x_test:测试集的特征数据,用于评估模型在新数据上的表现。 y_test:测试集的标签数据,与 x_test 对应,用于计算模型预测误差(评估泛化能力)。 用途:x_train 和 y_train 用于模型训练(拟合参数);x_test 和 y_test 用于验证模型是否过度拟合(泛化能力)。
4:什么是回归问题和分类问题?如何区分?
1 2 回归问题:目标变量是连续值(如温度、价格),模型预测具体数值。 分类问题:目标变量是离散类别(如 “男 / 女”“正 / 负”),模型预测类别标签。
5:简述机器学习建模的基本流程(从数据到模型评估)。
6:【面试重点】什么是特征工程?为什么它在机器学习中至关重要?
7:【面试重点】解释过拟合和欠拟合的定义、原因及解决方案。
8:奥卡姆剃刀原则在机器学习中的体现是什么?
9:请简述 KNN 算法的核心思想
10:KNN 算法处理分类问题和回归问题的流程分别是什么?
11:KNN 算法中,K 值的选择对模型有什么影响?
12:为什么需要归一化和标准化的区别是什么?应用场景
13:交叉验证和网格搜索的作用是什么?两者结合的优势是什么?
14:什么是损失函数?
15:【面试重点】MSE、MAE、RMSE 的定义及区别是什么?
16:梯度下降的常见类型有哪些?各自的特点是什么?
17:梯度下降中,学习率(步长)的作用是什么?设置不当会有什么问题?
18:L1 正则化(Lasso 回归)和 L2 正则化(Ridge 回归)的区别是什么?
L1(Lasso):使部分权重为 0,可用于特征选择。
L2(Ridge):使权重趋近于 0,减少权重绝对值,避免过拟合。
19:【面试重点】逻辑回归主要解决什么类型的问题?逻辑回归的流程是什么 ? 逻辑回归(Logistic Regression)是一种用于二分类问题的机器学习算法,其核心原理是通过逻辑函数(sigmoid 函数)将线性回归模型的输出映射到概率空间(0 到 1 之间),从而实现分类。
逻辑回归的核心原理:
线性组合 + 非线性变换:通过线性回归建模特征与标签的关系,用 sigmoid 函数将其转换为概率;
概率建模:基于最大似然估计构建对数损失函数,衡量预测概率与真实标签的差距;
优化求解:通过梯度下降等算法最小化损失函数,得到最优参数;
正则化防过拟合:通过L1/L2 正则化约束参数复杂度,提升泛化能力
20:【面试重点】AUC 指标的含义是什么?其取值范围是多少?AUC=0.5、AUC=1 、AUC=0分别说明模型的什么性能?
21:CART 决策树与 ID3、C4.5 有哪些分支方式 ?
23:集成学习主要分为哪两类?请分别列举至少两种代表性算法。
24:K-means 算法的具体实现流程是什么?
机器学习补充 有监督学习和无监督学习
什么是特征工程 特征工程,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。
特征工程包括:特征提取、特征预处理、特征缩放
特征提取:将任意数据(如文本或图像)转换为可用于机器学习的数字特征
特征预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
最值归一化(Min-Max Scaling)也就是归一化
均值方差归一化(Z-Score标准化)也就是标准化
特征缩放:指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
过拟合和欠拟合 过拟合
训练集表现较好,但是测试集表现不好
产生原因:模型复杂度过高、训练数据量不足
可以通过剪枝(减少特征列)
欠拟合
训练集表现不好,测试集表现不好
产生原因: 学习到数据的特征过少
通过增加特征列解决
注意:正则化可以解决过拟合
KNN 算法的核心思想 K近邻算法,给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
KNN算法可以用于分类问题,也可以用于回归问题:
分类问题,取前n个最近的实例,选择前n个最近的实例标签中最多的即为预测标签
回归问题,取前n个最近的实例,选择前n个最近的实例标签的均值作为预测标签
KNN分类问题和回归问题
计算测试样本和训练样本中每个样本点的距离(常见的距离度量有欧式距离,曼哈顿距离等);
对上面所有的距离值进行排序;选前 k 个最小距离的样本;根据这 k 个样本的标签进行投票,得到最后的分类类别;
任务类型
流程步骤
输出决策方式
分类问题
1. 计算距离 → 2. 选取K近邻 → 3. 统计K个邻居的类别频率 → 4. 最高票类别作为预测结果
多数表决(Majority Vote)
回归问题
1. 计算距离 → 2. 选取K近邻 → 3. 计算K个邻居目标值的均值 → 4. 输出均值
加权平均(可距离倒数加权)
KNN算法K值的选择
K值过小就意味着整体模型变得复杂,模型对噪声敏感,容易发生过拟合。K值过大就意味着整体的模型变得简单,模型忽略局部特征,可能欠拟合。K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的累,模型过于简单,忽略了训练实例中大量有用信息。
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。
特征预处理(归一化,标准化区别) 特征预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
归一化:将特征值转换为0-1之间数据(也可以自定义区间范围)
标准化:将特征转换为服从均值为0,方差为1的正态分布的数据
最值归一化(Min-Max Scaling)也就是归一化
$$
$$
均值方差归一化(Z-Score标准化)也就是标准化
$$
Latex语法:传送门
交叉验证和网格搜索
交叉验证解决模型的数据输入问题(也就是数据集划分),目的是得到更可靠的模型
网格搜索解决超参数的组合问题,目的是选择最优超参
两个组合再一起形成一个模型参数调优的解决方案
API:GridSearchCV
1 2 3 es_model = KNeighborsClassifier() param_dict = {'n_neighbors' : [i for i in range (1 , 11 )]} es = GridSearchCV(es_model, param_dict, cv=4 )
损失函数是什么 损失函数是衡量预测值和真实值误差的一种函数。
线性回归的损失函数有MSE、MAE、RMSE
$$
$$
逻辑回归的损失函数为似然函数
线性回归中最优参数求解 对于小数据集,使用最小二乘法(求导,求偏导联立方程),并且要求特征矩阵$X$($Y=X\cdot\beta$)可逆
对于大数据集,且$X$特征矩阵不可逆的情况下使用梯度下降方法
特征共线性或高维数据,使用正则化
梯度下降的常见类型
在使用梯度下降时,需要进行调优
算法的步长选择。步长太大,会导致迭代过快,有可能错过最优解。步长太小,收敛速度过慢。需要多次运行后才能得到一个较为优的值。算法参数的初始值选择。由于有局部最优解的风险,需要多次用不同初始值运行算法,选择损失函数最小化的初值。归一化。由于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据归一化。新期望为0,新方差为1,迭代速度可以大大加快。
$$
步长:$θ_0$,
学习率:$α$,
$\frac{\partial}{\partial \theta_{i} } J(\theta)$为回归函数的对变量的导数。
批量梯度下降 (Batch Gradient Descent, BGD)
每次迭代使用 全部训练数据 计算损失函数的梯度。
梯度计算稳定,但可能陷入局部最优且内存消耗大
$\eta$:学习率
$\nabla_\theta J(\theta)$:损失函数对参数 $\theta$ 的梯度
1 2 3 4 5 6 def batch_gradient_descent (X, y, lr=0.01 , epochs=100 ): theta = np.zeros(X.shape[1 ]) for _ in range (epochs): grad = X.T @ (X @ theta - y) / len (y) theta -= lr * grad return theta
随机梯度下降 (Stochastic Gradient Descent, SGD)
每次迭代 随机选择一个样本 计算梯度并更新参数。
1 2 3 4 5 6 7 8 def stochastic_gradient_descent (X, y, lr=0.01 , epochs=100 ): theta = np.zeros(X.shape[1 ]) for _ in range (epochs): for i in range (len (y)): rand_idx = np.random.randint(len (y)) grad = X[rand_idx] * (X[rand_idx] @ theta - y[rand_idx]) theta -= lr * grad return theta
小批量梯度下降 (Mini-Batch Gradient Descent, MBGD)
折中方案,每次迭代使用 一小批样本(Batch) 计算梯度。
1 2 3 4 5 6 7 8 9 def mini_batch_gradient_descent (X, y, batch_size=32 , lr=0.01 , epochs=100 ): theta = np.zeros(X.shape[1 ]) for _ in range (epochs): for i in range (0 , len (y), batch_size): batch_X = X[i:i+batch_size] batch_y = y[i:i+batch_size] grad = batch_X.T @ (batch_X @ theta - batch_y) / batch_size theta -= lr * grad return theta
类型
数据使用
内存消耗
收敛速度
适用场景
BGD
全量数据
高
慢
小型数据集
SGD
单样本
低
快但不稳定
在线学习、非凸优化
MBGD
小批量(Batch)
中
中
深度学习(默认选择)
Momentum/Adam
小批量 + 历史梯度
中
快且稳定
复杂非凸优化(如神经网络)
L1, L2 正则化的区别 正则化项,也就是给损失函数loss function加上一个参数项,由于参数项的不同,产生了L1和L2正则化两种方式。
L1正则化(Lasso回归):将不重要的特征的参数为0
在原始损失函数中添加权重的绝对值惩罚迫使部分参数精确为零
L2正则化(Ridge岭回归):将不重要的特征参数趋向于0
在原始损失函数中添加权重的平方和作为惩罚项
逻辑回归流程及解决了什么
获取数据
基本数据处理
缺失值处理
确定特征值,目标值
分割数据
特征工程(标准化)
机器学习(逻辑回归)
模型评估
解决了二分类问题(可扩展至多分类):
垃圾邮件检测(是/否)
疾病诊断(患病/健康)
信用评分(违约/不违约)
混淆矩阵四象限 混淆矩阵作用在测试集样本集中:
真实值是 正例 的样本中,被分类为 正例 的样本数量,叫做真正例(TP,True Positive)
真实值是 正例 的样本中,被分类为 假例 的样本数量,叫做伪反例(FN,False Negative)
真实值是 假例 的样本中,被分类为 正例 的样本数量,叫做伪正例(FP,False Positive)
真实值是 假例 的样本中,被分类为 假例 的样本数量,叫做真反例(TN,True Negative)
精确率,召回率反映什么 精确率也叫做查准率,指的是对正例样本的预测准确率。
ROC曲线横纵轴,每个点 横纵:TPR (True Positive Rate):正样本中被预测为正样本的概率 (召回率)
纵轴:FPR (False Positive Rate):负样本中被预测为正样本的概率
ROC曲线是评估二分类模型性能的重要工具,尤其在样本不平衡的场景下表现优异。
AUC 指标 AUC 是 ROC 曲线下面的面积,该值越大,则模型的辨别能力就越强
AUC 值主要评估模型对正例样本、负例样本的辨别能力
AUC=0.5、AUC=1 、AUC=0分别说明模型的什么性能
AUC=0.5说明模型无判别能力(等同于随机猜测)
AUC=1说明模型完美分类
AUC=0说明模型完全反向预测
决策树?基本结构
树中每个内部节点表示一个特征上的判断
每个分支代表一个判断结果的输出
每个叶子节点代表一种分类结果
构建决策树包括三个步骤:
特征选择:选取有较强分类能力的特征。
决策树生成:根据选择的特征生成决策树。典型的算法有ID3、C4.5、CART,它们生成决策树过程相似,ID3是采用信息增益作为特征选择度量,而C4.5采用信息增益率、CART基尼指数。
决策树剪枝:决策树也易过拟合,采用剪枝的方法缓解过拟合。剪枝原因是决策树生成算法生成的树对训练数据的预测很准确,但是对于未知数据分类很差,这就产生了过拟合的现象。
熵(Entropy)在决策树中作用 熵(Entropy):信息论中代表随机变量不确定度的度量
熵越大,数据的不确定性度越高,信息就越多
熵越小,数据的不确定性越低
ID3,C4.5,CART 决策树 ID3是采用信息增益作为特征选择度量,而C4.5采用信息增益率、CART基尼指数。
信息增益(ID3)、信息增益率值越大(C4.5),则说明优先选择该特征。
基尼指数值越小(cart),则说明优先选择该特征。
决策树节点切分依据 不同类型的决策树有不同的特征度量指标
例如ID3是采用信息增益作为特征选择度量,而C4.5采用信息增益率、CART基尼指数。
信息熵:
决策树剪枝 决策树的剪枝基本策略有 预剪枝 (Pre-Pruning) 和 后剪枝 (Post-Pruning)。
预剪枝:其中的核心思想就是,在每一次实际对结点进行进一步划分之前,先采用验证集的数据来验证如果划分是否能提高划分的准确性。如果不能,就把结点标记为叶结点并退出进一步划分;如果可以就继续递归生成节点。
后剪枝:后剪枝则是先从训练集生成一颗完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来泛化性能提升,则将该子树替换为叶结点。
Bagging 与 Boosting区别
Baggging 框架通过有放回的抽样产生不同的训练集,从而训练具有差异性的弱学习器,然后通过平权投票、多数表决的方式决定预测结果。
Boosting 体现了提升思想,每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,得出预测结果。
只有随机森林算法是基于Bagging,Adaboost,GDBT,XGBoost都是基于Boosting。
区别一:数据方面
Bagging:有放回采样
Boosting:全部数据集, 重点关注前一个弱学习器不足
区别二:投票方面
Bagging:平权投票
Boosting:加权投票
区别三:学习顺序
Bagging的学习是并行的,每个学习器没有依赖关系
Boosting学习是串行,学习有先后顺序
Adaboost 的完整构建流程 1 初始化弱学习器(目标值的均值作为预测值)
2 迭代构建学习器,每一个学习器拟合上一个学习器的负梯度
3 直到达到指定的学习器个数
4 当输入未知样本时,将所有弱学习器的输出结果组合起来作为强学习器的输出
梯度提升树与随机森林区别 梯度提升树(GDBT)
维度
梯度提升树 (GBDT)
随机森林 (RF)
集成策略
Boosting:串行训练,每棵树纠正前一棵的错误
Bagging:并行训练,每棵树独立投票
依赖关系
树之间有强依赖(残差拟合)
树之间完全独立
目标
最小化损失函数的梯度方向
通过投票/平均降低方差
XGBoost推导过程概述
在损失函数的基础上+正则化项,(使用泰勒展开二项式进行展开)基于泰勒展开二项式进行转换,转换为近似函数 。(把问题从样本的角度转换为叶子节点角度!!!)把问题从样本角度-》叶子节点的角度进行分析得出最终结果 ,打分函数
Gain值 = 拆分前的分-(拆分后的左子树的分+拆分后的右子树的分)
Gain值越小越好如果gain > 0,则分类之后树的损失更小,会考虑此次分裂
如果gain < 0,说明分裂后的分数比分裂之前的分数大,此时不建议分裂
参考链接:
NLP面试题库 提示:输入部分、输出部分、编码器部分、解码器部分输入部分、编码器部分、解码器部分和输出部分。
输入部分:包括源文本嵌入层及其位置编码器,目标文本嵌入层及其位置编码器。源文本嵌入层将源语言文本转化为向量表示,目标文本嵌入层将目标语言文本转化为向量表示。位置编码器则将位置信息转化为向量表示,以用于Transformer模型中的自注意力机制。
编码器部分:由N个编码器层堆叠而成。每个编码器层由两个子层连接结构组成。第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接。第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接。编码器部分可以有效地捕捉输入序列中的上下文信息。
解码器部分:由N个解码器层堆叠而成。每个解码器层由三个子层连接结构组成。第一个子层连接结构包括一个带掩码的-多头自注意力子层和规范化层以及一个残差连接。第二个子层连接结构包括一个多头注意力子层(编码器到解码器)和规范化层以及一个残差连接。第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接。解码器部分可以有效地生成目标序列。
输出部分:包括线性层和Softmax层。线性层将解码器部分的输出转化为目标语言文本的向量表示,Softmax层则将这个向量表示转化为预测的目标语言文本。
总的来说,Transformer架构通过使用自注意力机制和残差连接等方法,有效地捕捉输入序列中的上下文信息,并生成目标序列。同时,其预训练模型可以用于不同的NLP任务,如机器翻译、文本生成等,表现出较强的泛化能力。
上面看看就行:
Transformer架构:分为Encoder和Decoder两个部分
Encoder部分主要包括:
Input Embedding (输入嵌入):将输入的单词或者符号转换成固定维度的向量表示,使其能够被模型处理。
Positional Encoding(位置编码):因为在LSTM中,每个隐含层的节点,都是要接收上一个隐含层的输出,所以他是有天然的时序顺序在里面的。但是Transformer中,没有使用RNN,所以就需要给他的词向量中加入位置信息。
Multi-Head Attention 多头注意力机制:所谓多头,其实在底层就是多个权重矩阵。Feed Forward 前馈网络:
前馈网络包含两个全连接层:
第一个全连接层将输入的维度扩展(例如,从512维扩展到2048维),接着是一个激活函数(通常是ReLU或GELU)
第二个全连接层,将维度从扩展的维度缩减回原始维度(例如,从2048维缩减回512维)。
前馈网络处理完后,先对其进行一个残差连接,再进行层归一化处理。
Decoder部分主要包括:
Masked Multi-Head Attention 具有掩码的多头注意力机制
Feed Forward 前馈网络
分类器
注意力机制QKV 注意力机制中的Q、K和V分别表示查询(Query)、键(Key)和值 (Value)。它们是用于计算注意力分数的必要元素
其中,q表示查询向量,k表示键向量,v表示值向量,$\sqrt{d}$表示是一个关键的缩放因子,避免其绝对值过大导致Softmax输出梯度消失。
这个公式主要用于计算查询(Query)和键(Key)之间的相似度,并通过Softmax函数得到一个权重分布,最后用这个权重分布去获取对应的值(Value)。
自注意力机制的计算过程 自注意力机制的计算过程如下:
输入句子中的每个词向量依次被用作査询(Q)、键(K)和值(V)。在这个过程中,每个词向量都与其他所有词向量进行计算,从而得到一个注意力分数。
注意力分数被用于计算一个新的表示向量,这个向量将取代原来的词向量。具体来说,每个词向量都被乘以对应的其他词向量的权重(由注意力分数决定),并将这些乘积相加,得到一个新的表示向量。
这个新的表示向量可以捕捉到句子中的长依赖关系,因为它包含了其他词向量的信息。然而,这种计算方式可能会在计算过程中产生梯度消失或爆炸的问题。为了解决这个问题,可以使用点积注意力机制或加性注意力机制来进行改进。
点积注意力机制的计算过程与上述过程类似,但使用了点积操作来计算注意力分数。具体来说,每个词向量与其他所有词向量进行点积计算,得到一个分数矩阵。这个短阵被用于计算新的表示向量。
加性注意力机制的计算过程也类似,但使用了加法操作来计算注意力分数。具体来说,每个词向量与其他所有词向量进行加法计算,得到一个加法结果。这个结果被用于计算新的表示向量。需要注意的是,在实际应用中,自注意力机制的计算可能会根据具体的任务和模型结构进行调整和优化。
CBOW模式和skipgram模式(FASTTEXT) Word2Vec是一个用于生成词向量的工具,它通过两种模型–跳字模型(Skipgram)和连续词袋模型(Continuous Bag ofWords,简称CBOW)-一以及两种高效训练方法–负采样和层序softmax–来实现词向量的训练。
NLP中词向量的表示方法 提示关键词:one-hot、word2vec,nn.Embedding,动态词向量、静态词向量
one·hot编码:这是一种将离散变量转换为连续向量的方法。在NLP中,每个单词被分配一个唯一的整数,然后使用一个非常大的向量(通常是一维的)来表示这个单词。在这个向量中,只有对应单词编号的位置是1,其余位置都是0。这种表示方法不能很好地捕捉单词之间的语义和语法关系,因为它们在向量空间中是孤立的。
word2vec:这是由Google开发的一种用于学习词向量的神经网络模型。它通过训练语料库学习单词的表示,使得相似的单词在向量空间中相互靠近。Word2Vec有两种模型:CBOW(ContinuousBag ofWords)和Skip-gram。CBOW模型通过训练一个神经网络来预测一个词,给定其上下文;Skip-gram模型则通过训练一个神经网络来预测上下文中的词,给定当前词。Word2Vec的词向量可以捕捉到单词之间的语义和语法关系,使得相似的单词在向量空间中聚集在一起。
nn.Embedding:这是PyTorch等深度学习框架提供的一种用于学习词向量的方法。它可以将离散的单词映射到一个连续的向量空间中。nn.Embedding层可以接受一个单词的索引作为输入,并返回对应的词向量作为输出。与one·hot编码不同,nn.Embedding可以学习到单词之间的语义关系,并且可以在句子中捕捉到上下文信息。
静态词向量和动态词向量:静态词向量是指在训练时固定不变的词向量,如Word2Vec和nn.Embedding生成的词向量。而动态词向量则是指在推理时根据上下文动态调整的词向量。动态词向量的代表模型有BERT、GPT等。这些模型在训练时会对每个单词生成一个固定的词向量,但在推理时可以根据上下文动态调整词向量的权重,从而更好地捕捉当前单词的语义信息。
BERT是双向语言模型, 如何理解
对于输入BERT的语言的序列, 站在任意位置, 即可以看见前面的信息又可以看见后面的信息, 所以是双向语言模型. 区别于GPT系列的生成式语言模型, 只能look-ahead, 不能获取后面的信息.
追问: BERT为啥能解决一词多意的问题?
上下文不同, 经过多层计算后的输出层词张量自然不同, 一词就有多个张量, 对应不同的语义
追问: BERT提取的词向量, 同一个词在不同句子获取的词向量一致吗?
BERT多头注意力机制代码层面 源代码中将Q, K, V三个矩阵的最后一个维度768进行了除法操作, 变成了4维张量. 在进行完多头注意力的各自独立操作后, 又重新view()操作回到了3维张量.
BatchNorm - 计算每个批次每层的平均值和方差.
LayerNorm - 独立计算每层每个样本的均值和方差.
因为LayerNorm对于批量大小是鲁棒的, 而且不会受到批次中不同长度样本的影响, 并且工作的更好. 因为LayerNorm在样本级别而不是批量级别工作!!!
view和transpose先后问题
可以先view(), 再算transpose()
如果先transpose(), 必须加上contiguous(), 才能再view()
预训练模型序列长度为1000+
推理时碰到sequence_length比训练时更长, 会出现碰见没有见过的position encoding, 造成训练和预测的不一致.
BERT训练时有MASK, 预测时没有MASK, 这个不一致怎么办?
MacBERT在优化MLM预训练任务
1: 采用了n-gram的模式, 对1-gram, 2-gram, 3-gram, 4-gram的词汇依次按照40%, 30%, 20%, 10%的比例进行掩码.
2: 不用[MASK]来遮掩, 而是用word2vec的近义词来遮掩, 选用同样字符数的词来mask, 如果找不到则进行规则降级, 用随机字来遮掩.
多分类问题数据样本不均衡
可以采用单一检测模型先进行一轮过滤, 把难分类的或者样本少的类别先分出来.
损失函数可以对少样本的类别加权重, 采用FocalLoss
对比学习最重要的两个衡量指标
Alignment: 对齐性, 对于相似的样本应该更接近, 也就是越相似的样本特征越接近.
Uniformity: 均匀性, 映射到单位超球面的特征应该尽量均匀分布, 意味着不同的样本要有差异.
追问: 具体用过哪些模型?
SimCSE模型在项目中用过, 做用户关于搜索语义匹配的模块.
Transformer中是三角函数算完后, 就固定不变了.
BERT中是三角函数算(初始化的时候不变), 但是后续随着模型一起训练就会变化.
模型在工业界的加速部署的问题? 一般部署中比较喜欢的模型有哪些?
首先肯定是选取简单模型, 比如做NER任务的IDCNN, 左文本分类任务的TextCNN, 或者FastText. 当然了现实中BERT系列的直接部署应用很广泛.
追问: 有用过哪些更高级的方案吗? 不是模型层面的?
其次就是模型量化, 剪枝, 或者知识蒸馏, 达成模型的小型化目标
工程方面onnxruntime 🥭格式, 可以极大的加速 — 2022年已经成为工业界事实上的推理标准!!! ⭕️
土豪公司可以考虑TensorRT的GPU优化方案
底层的C++改写, 尤其在移动端部署的时候
FlashAttention 🥭加速技术—2023年已经成为工业界事实上的训练标准!!! ⭕️

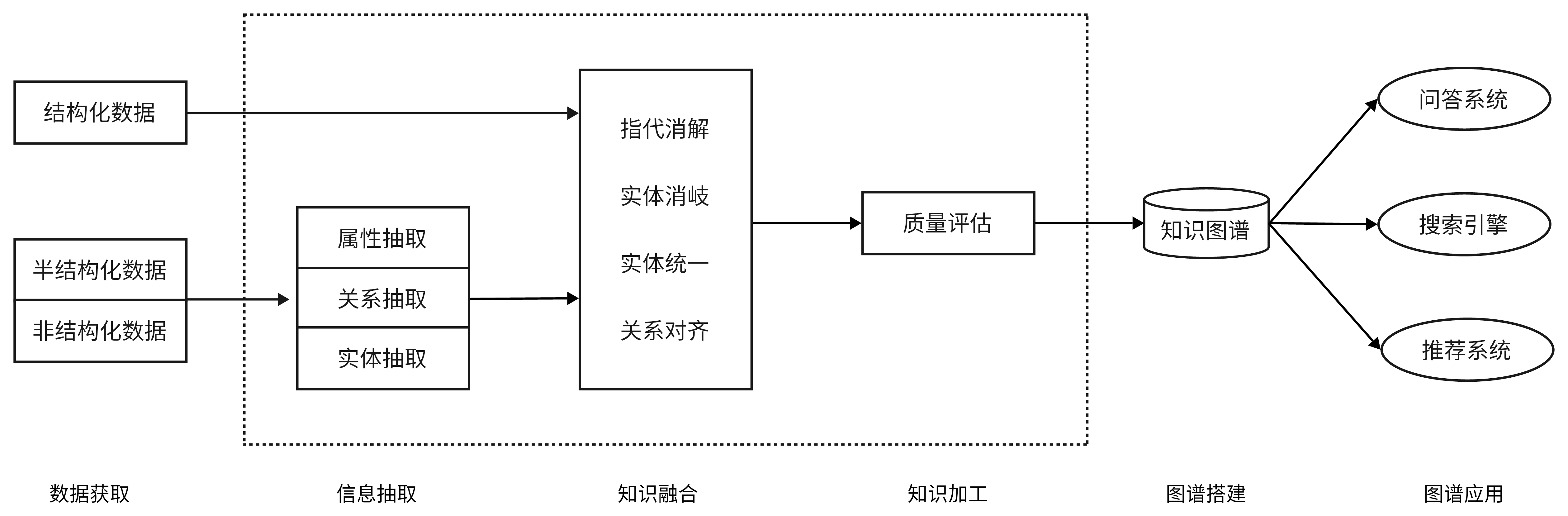
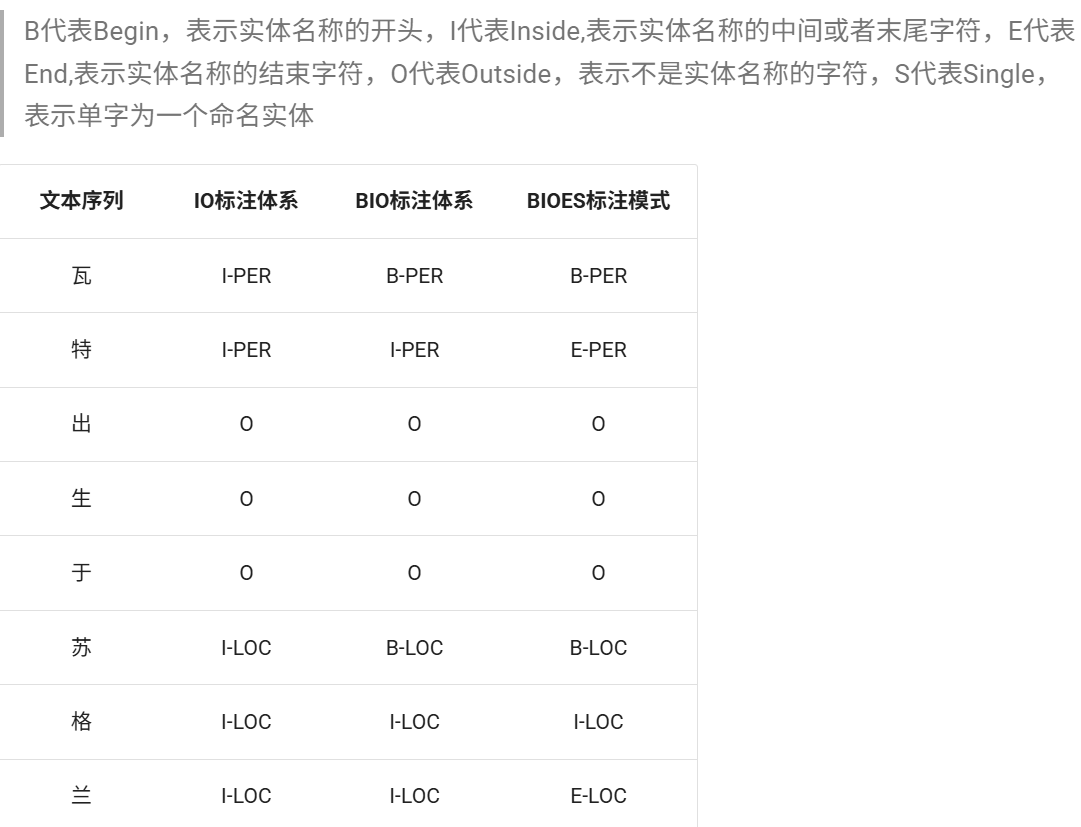
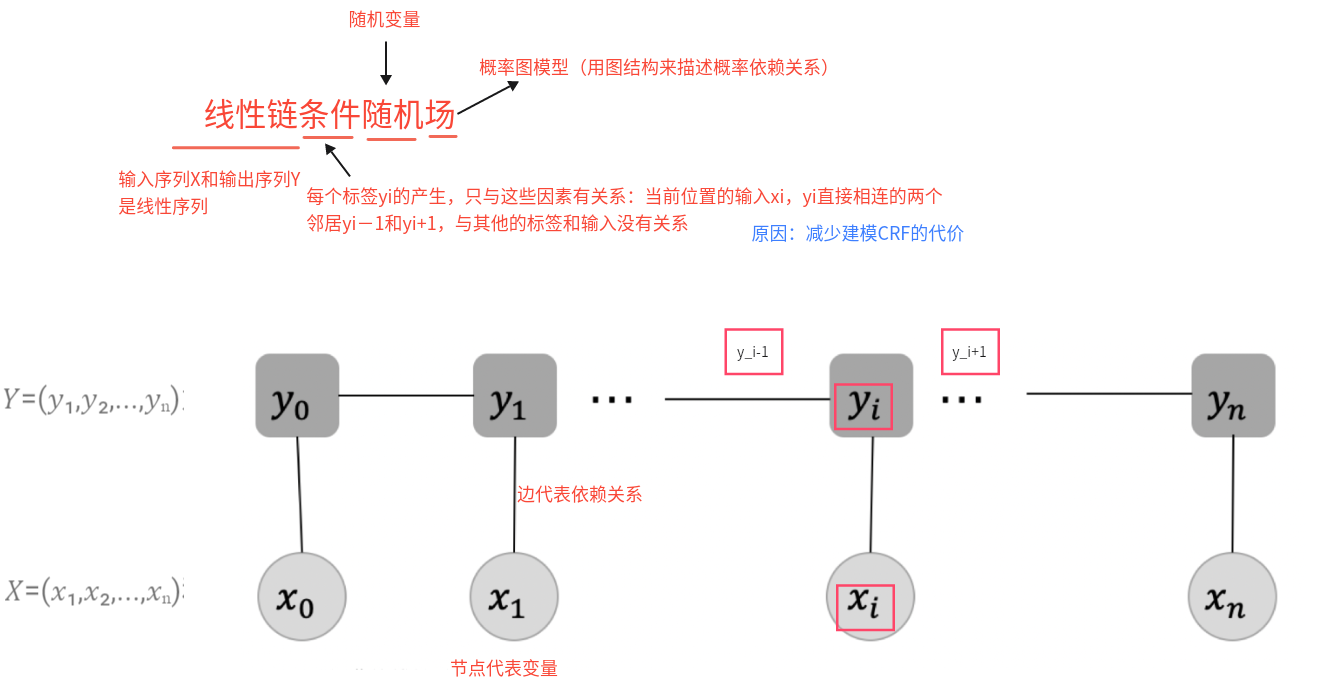
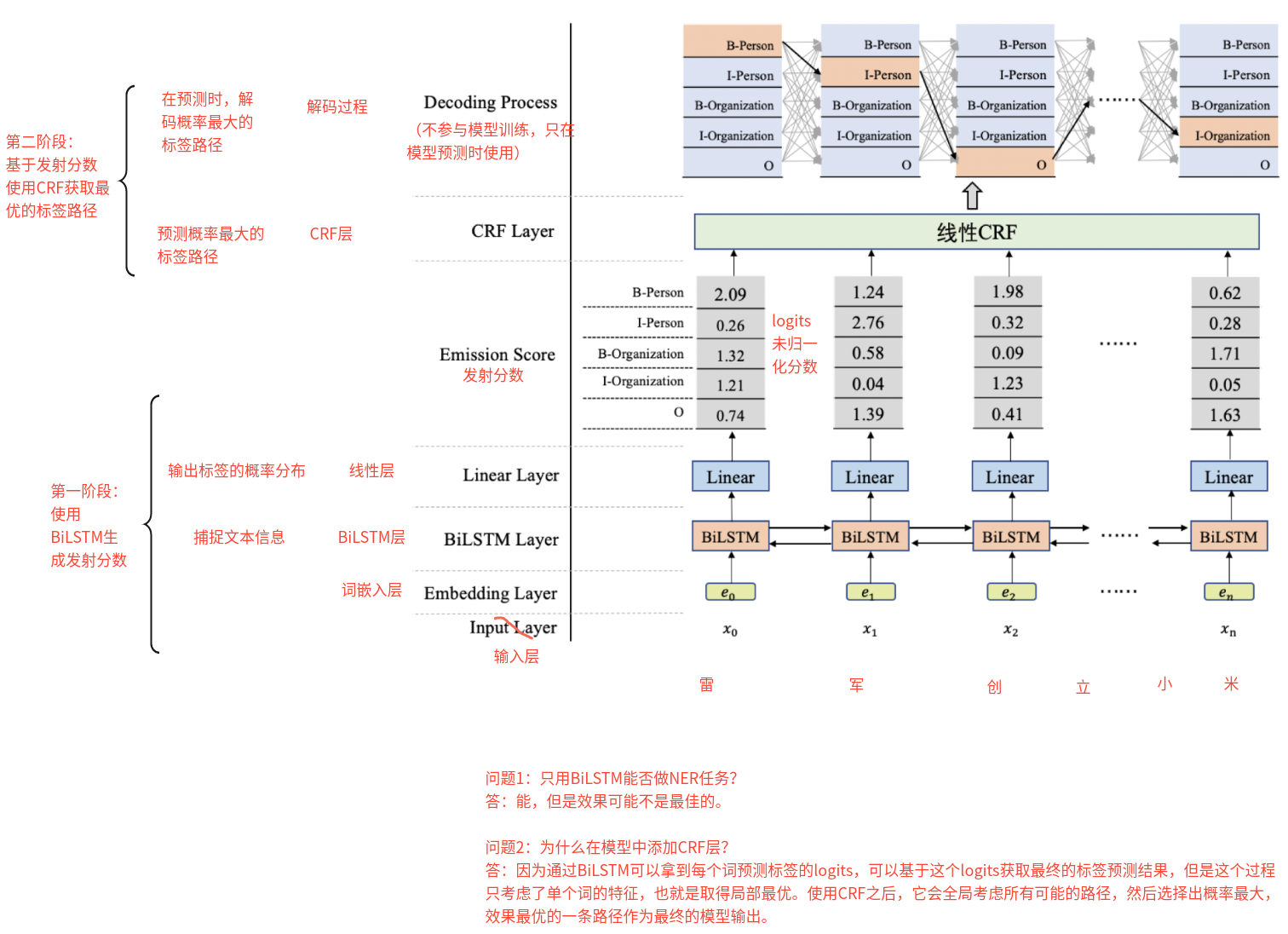
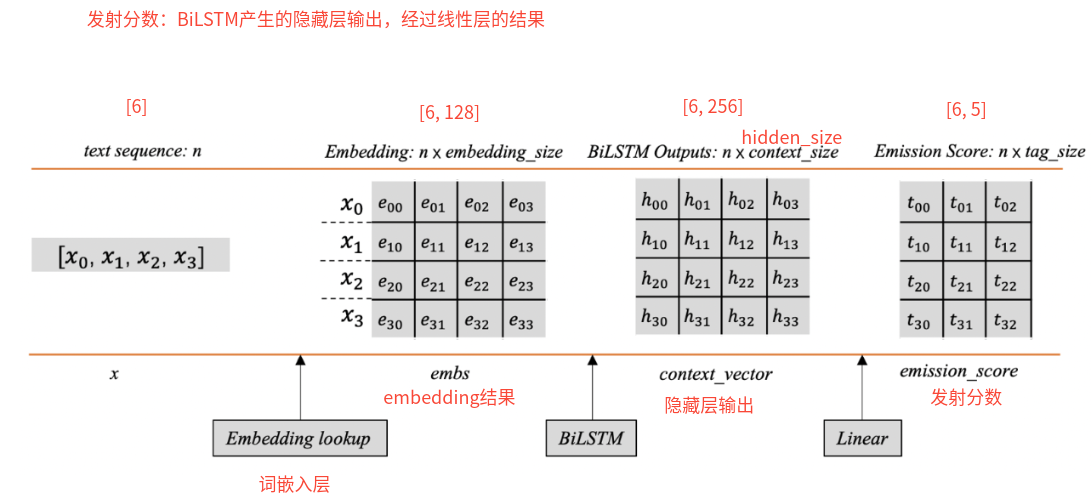
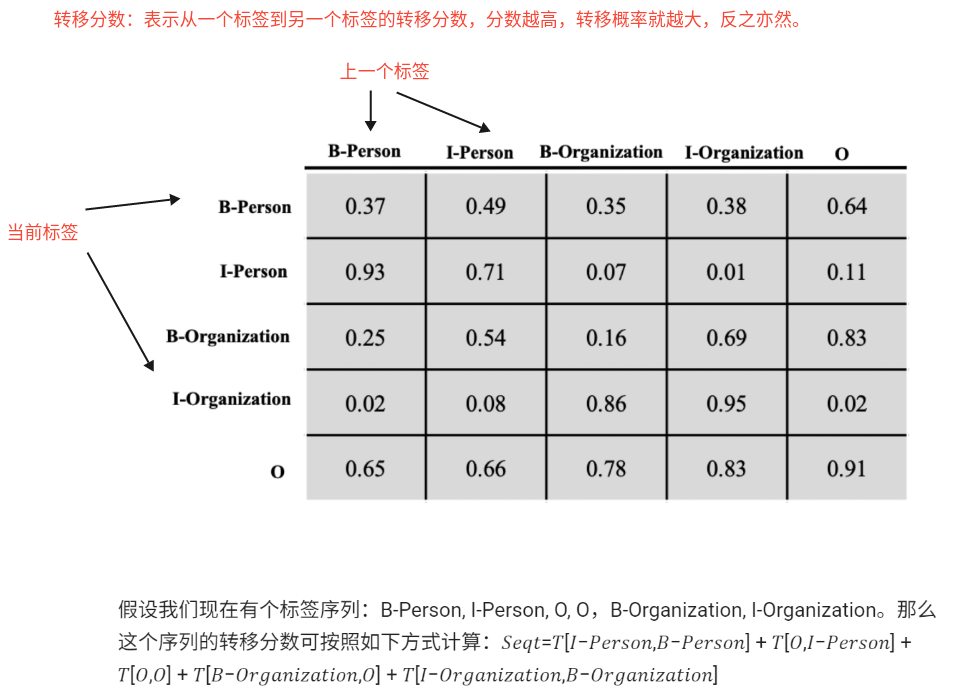

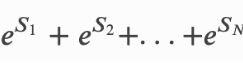
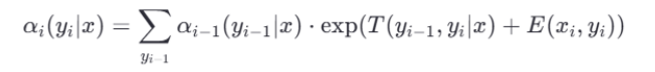
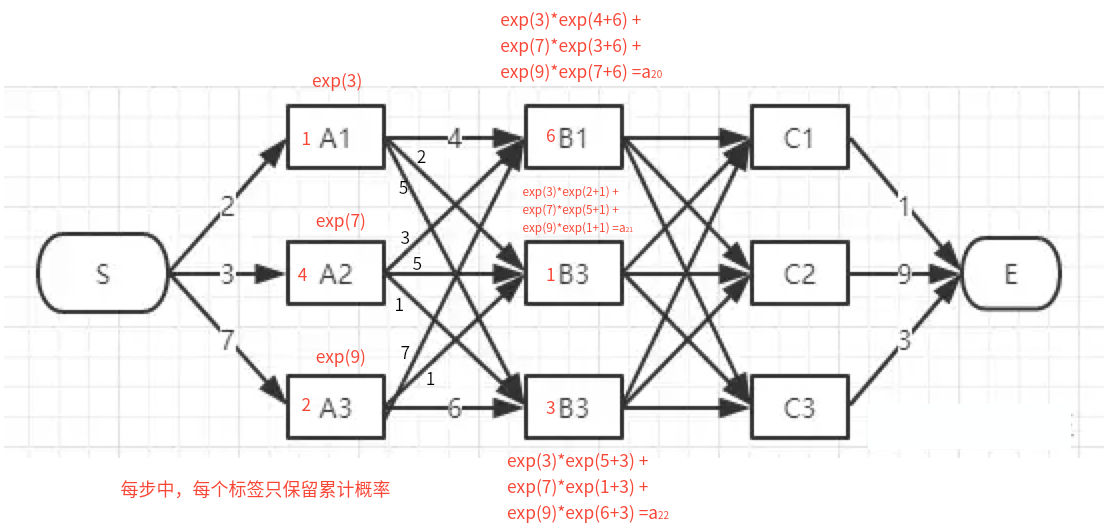
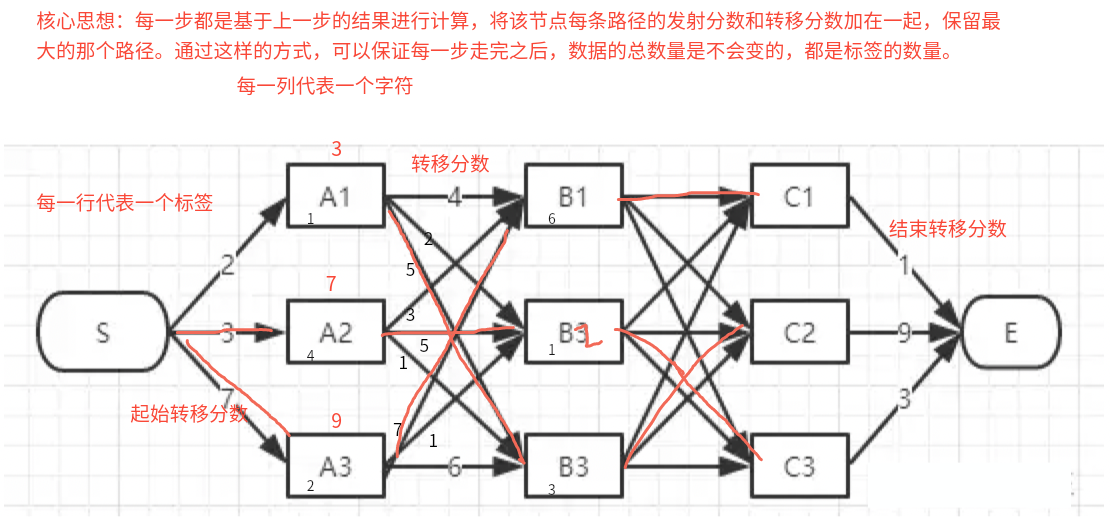

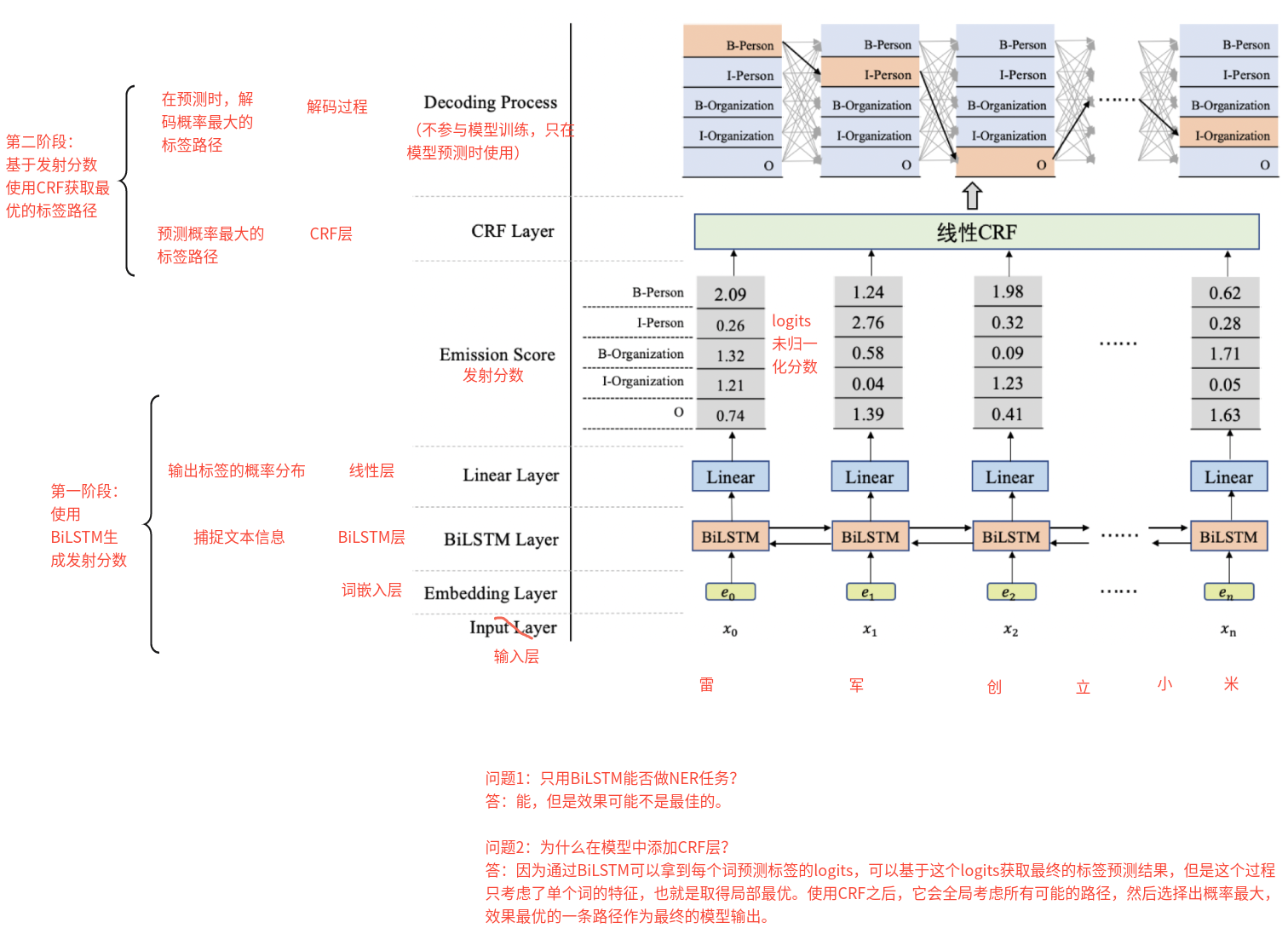
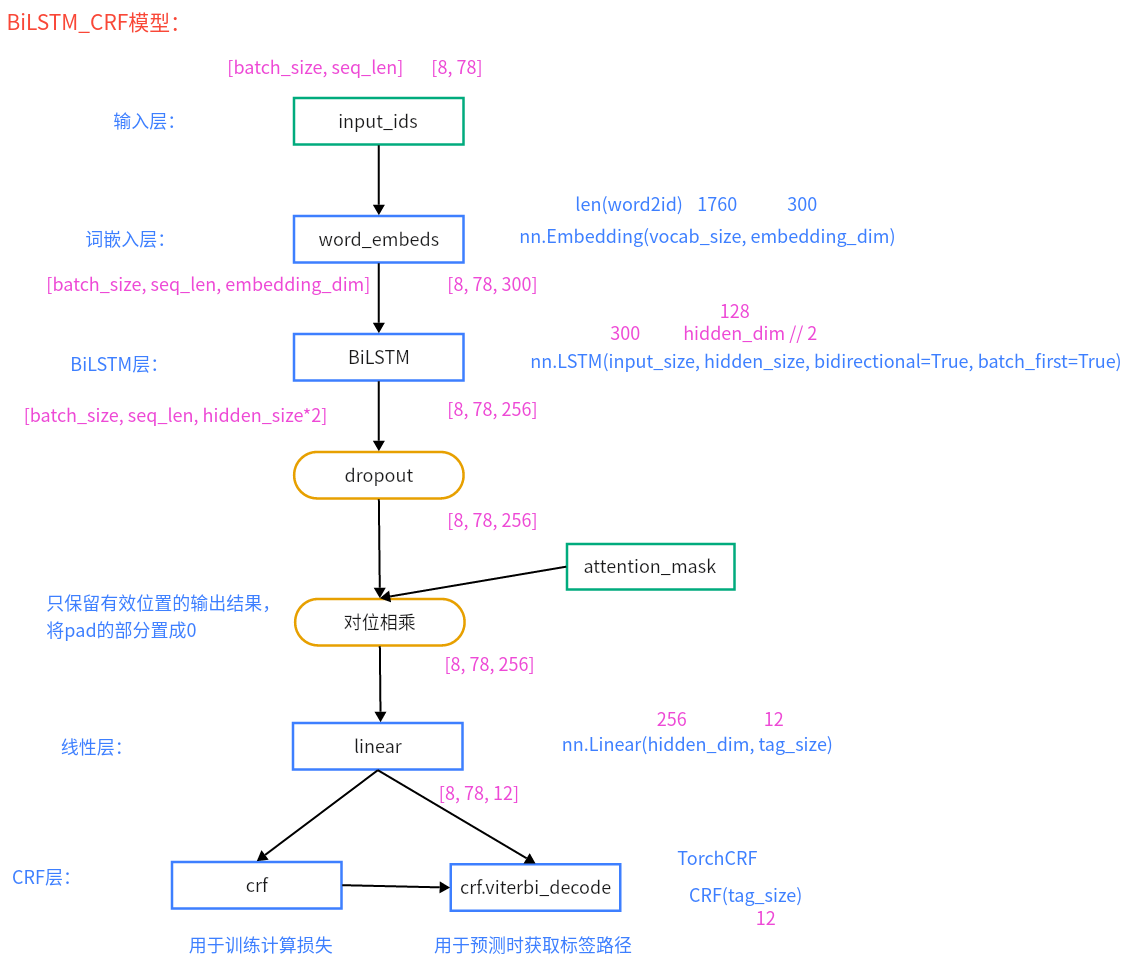
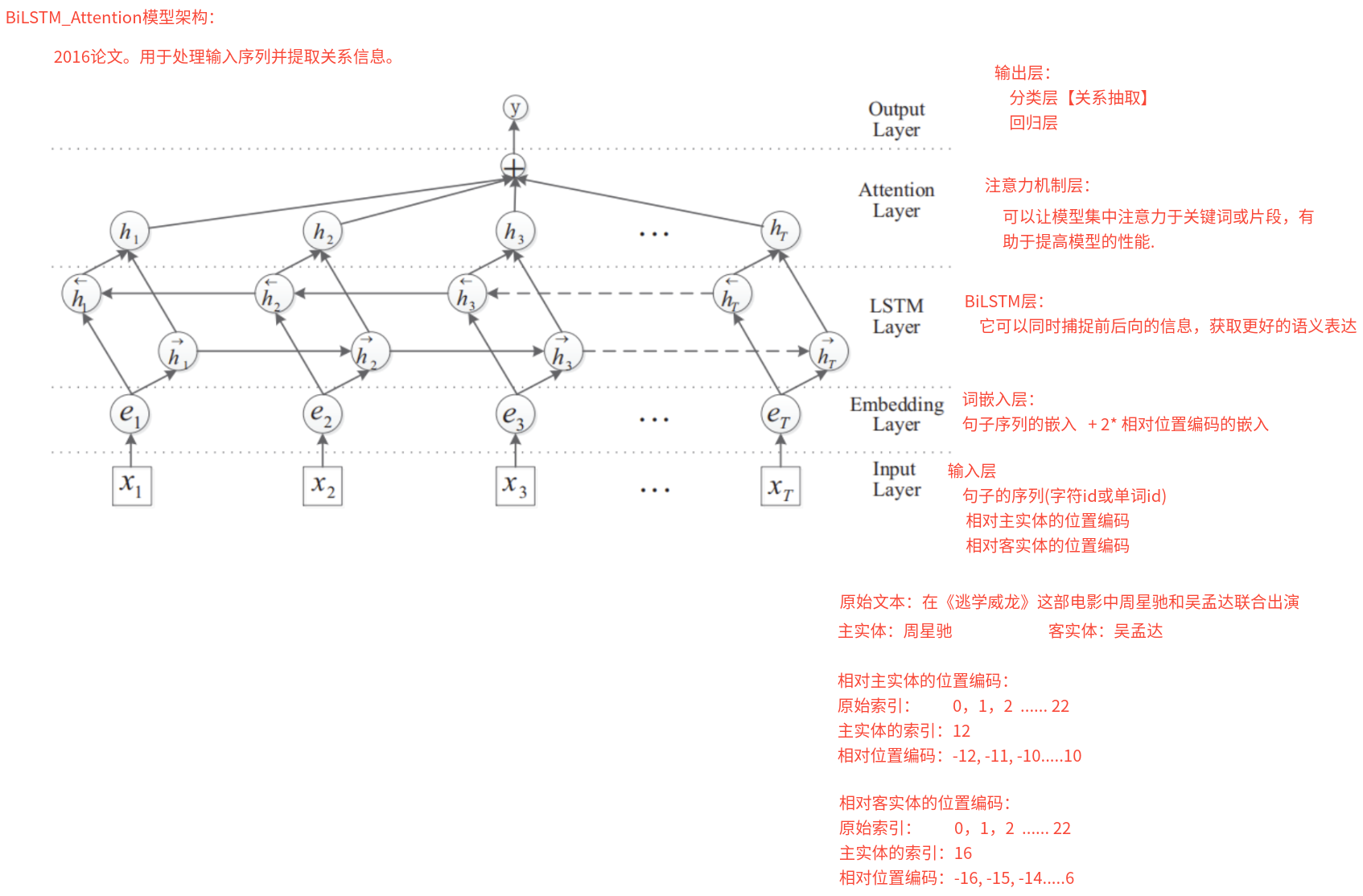



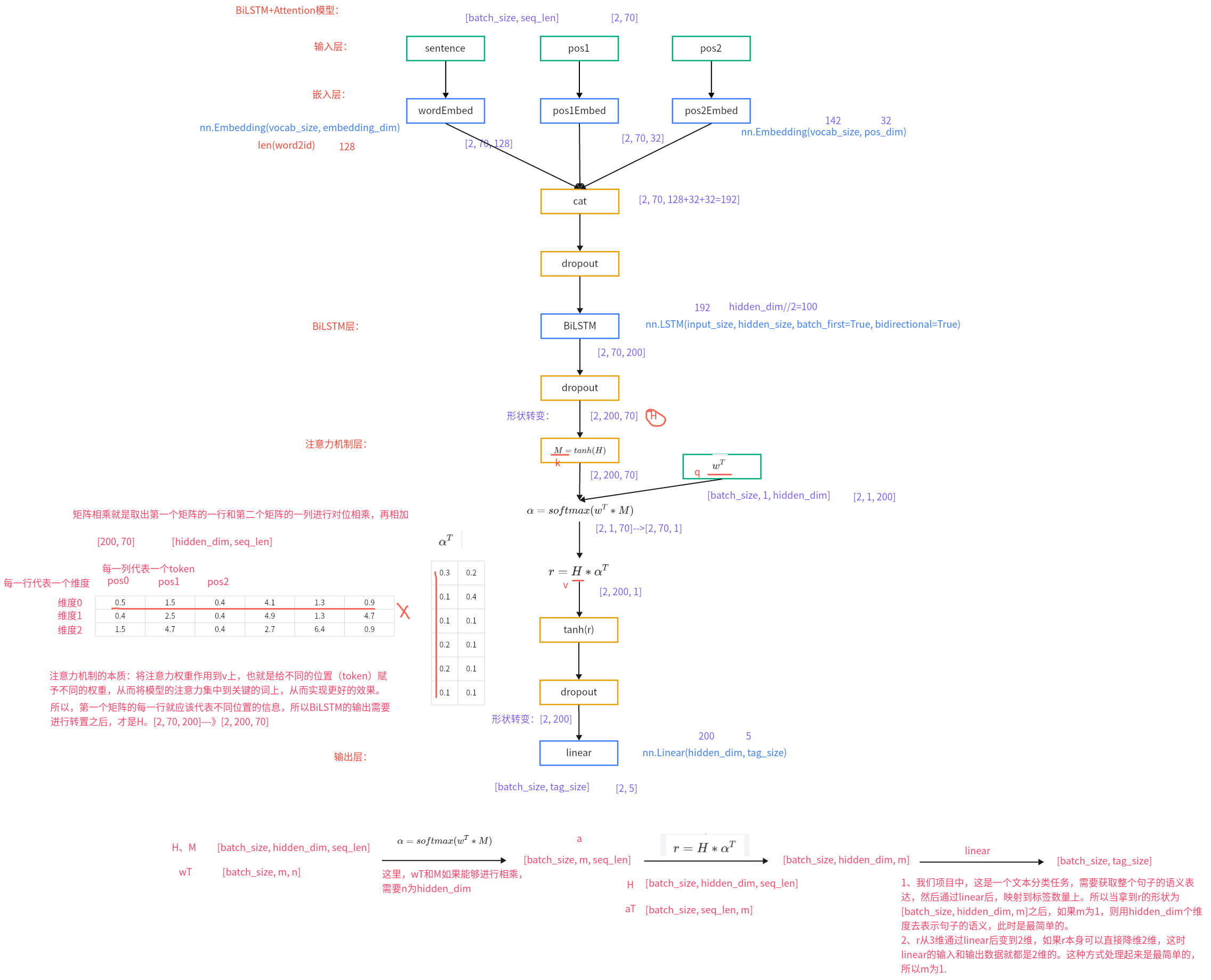
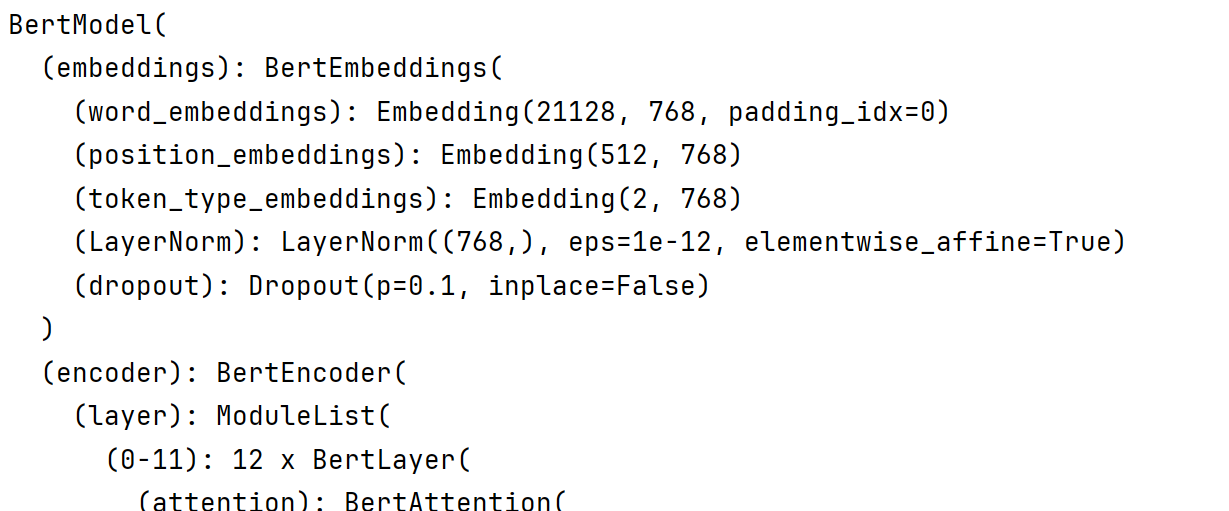
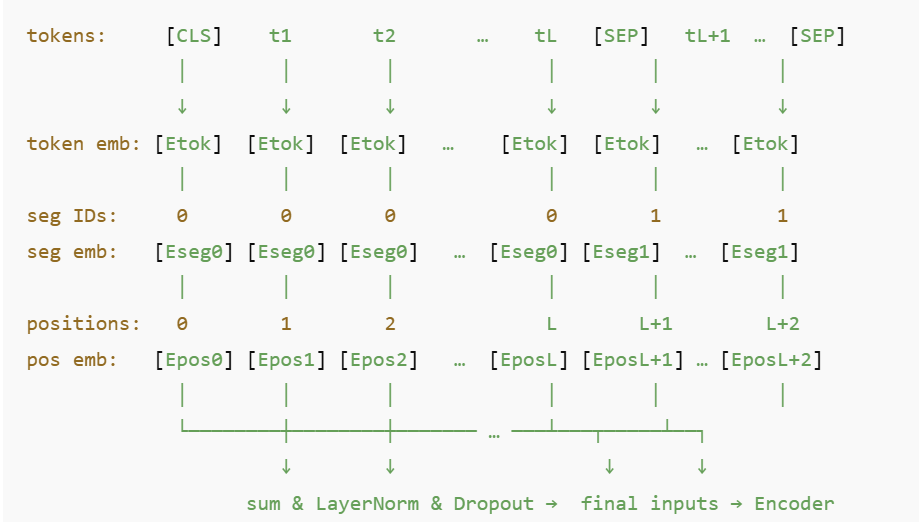

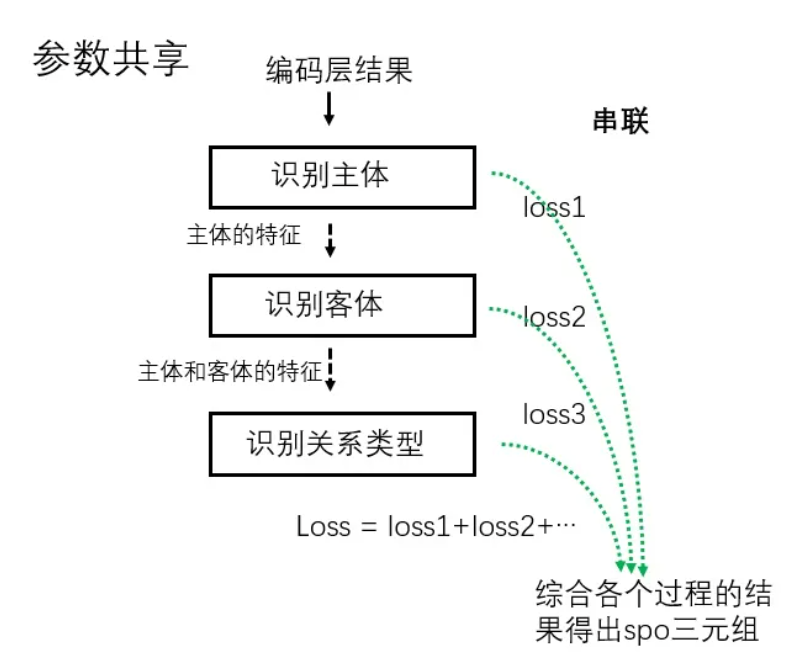
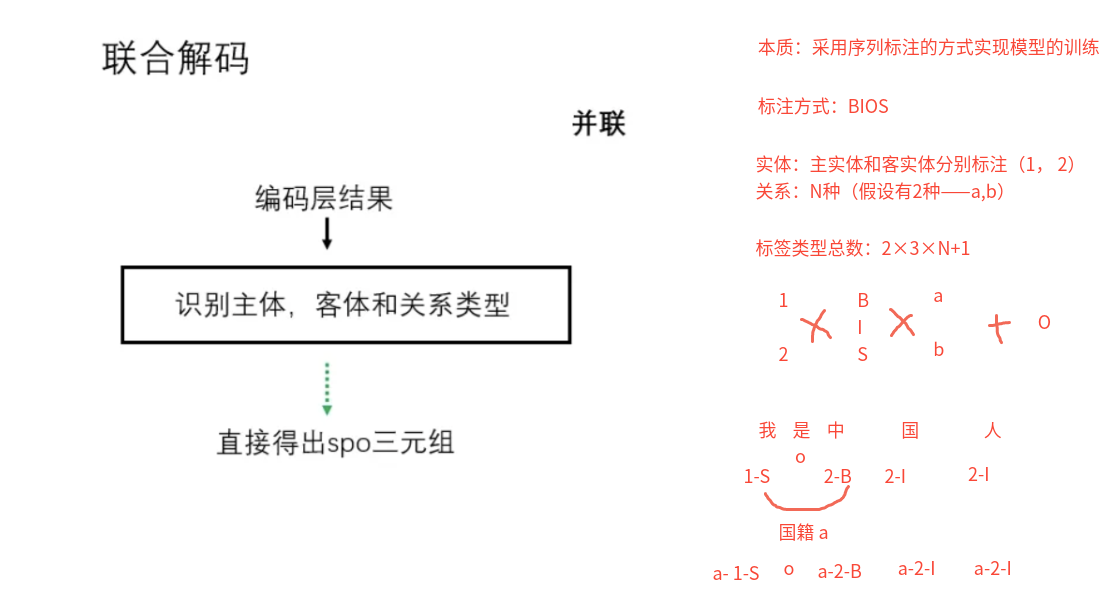
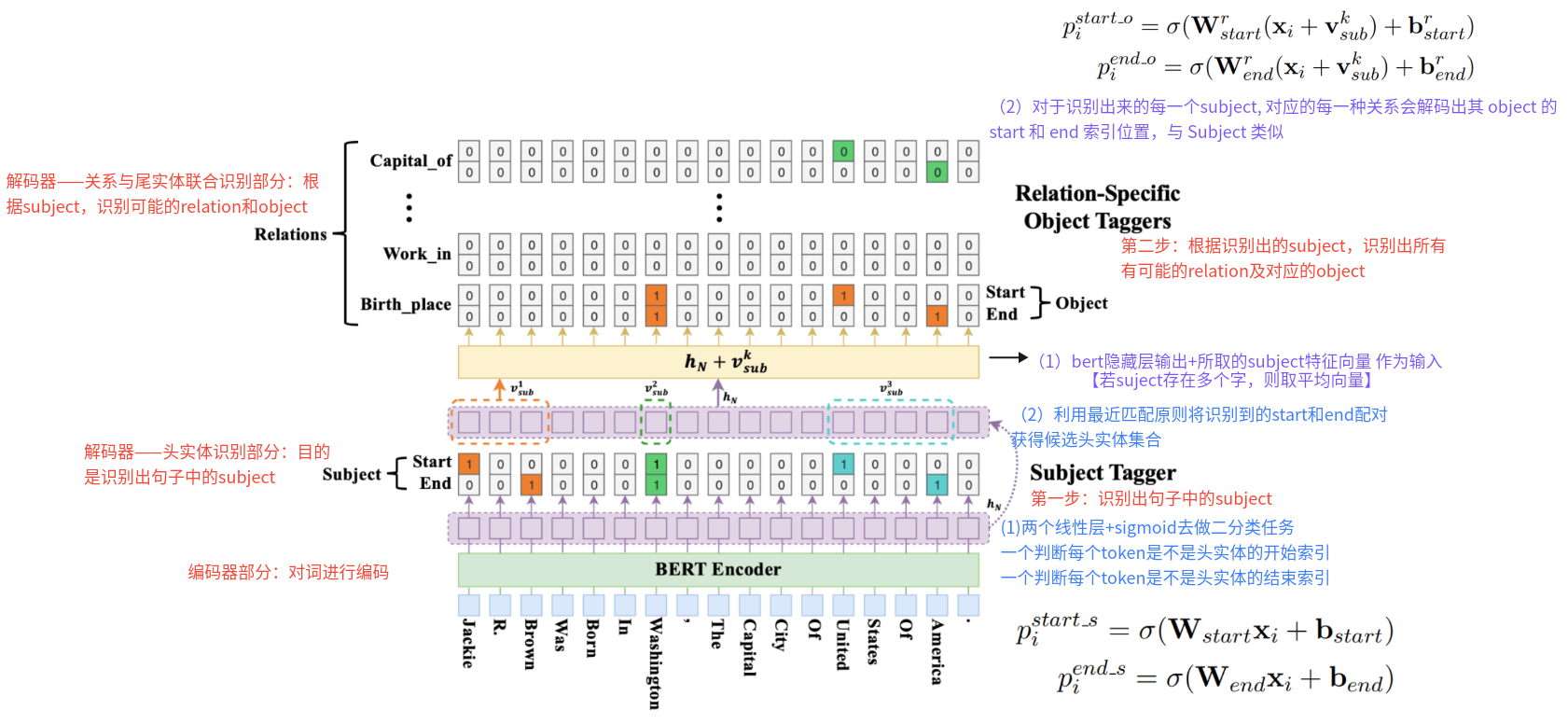
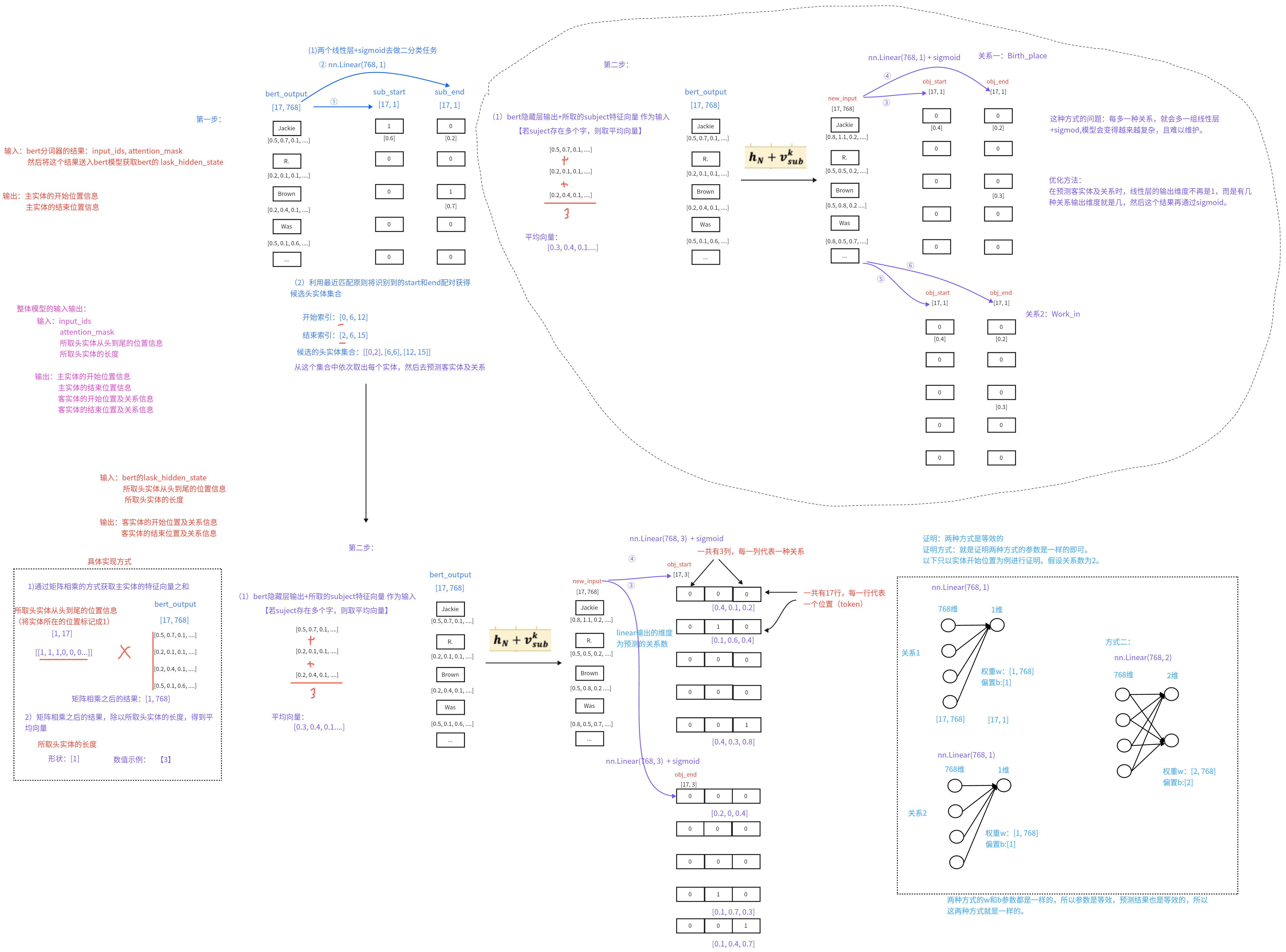
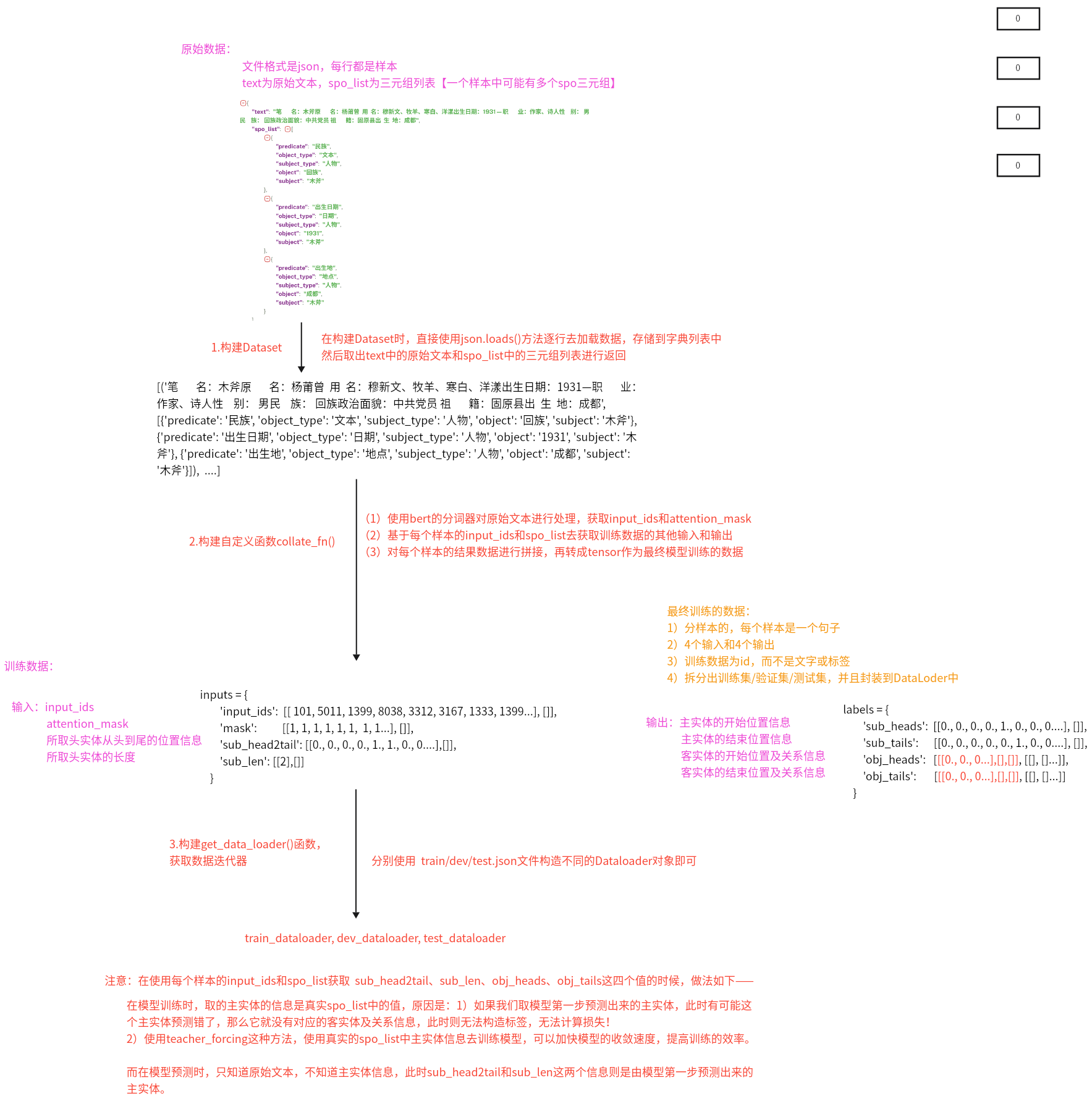
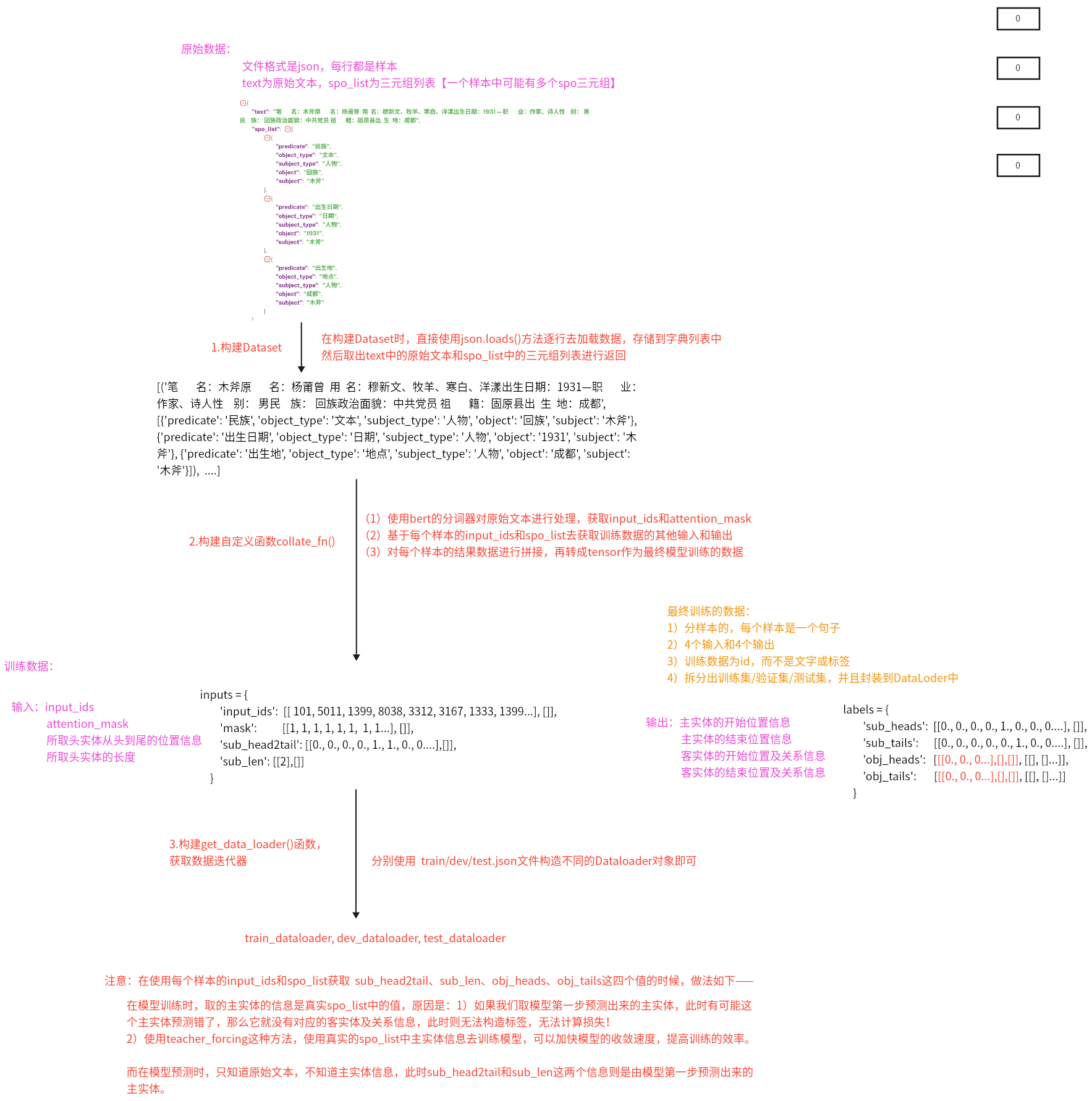
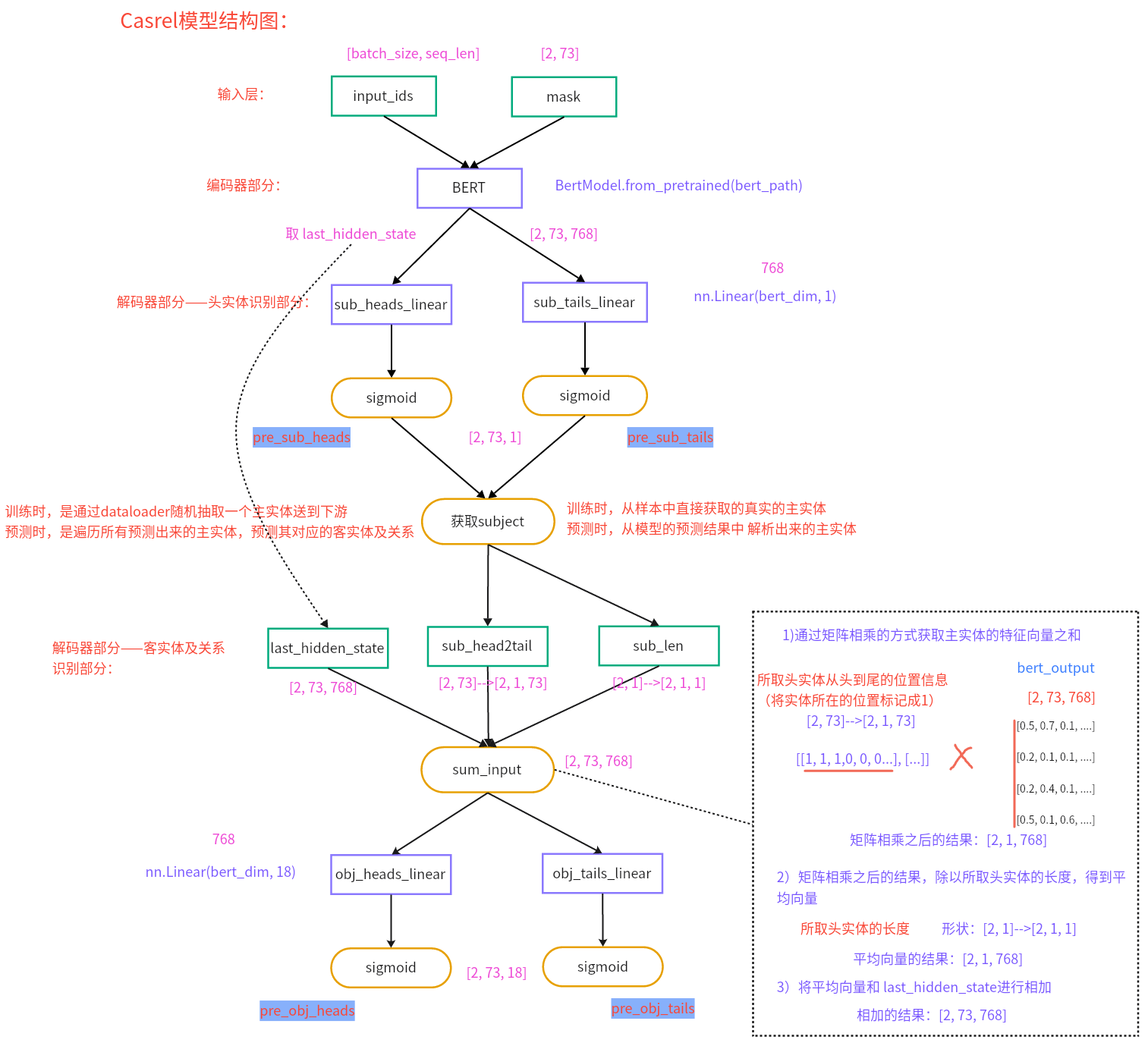
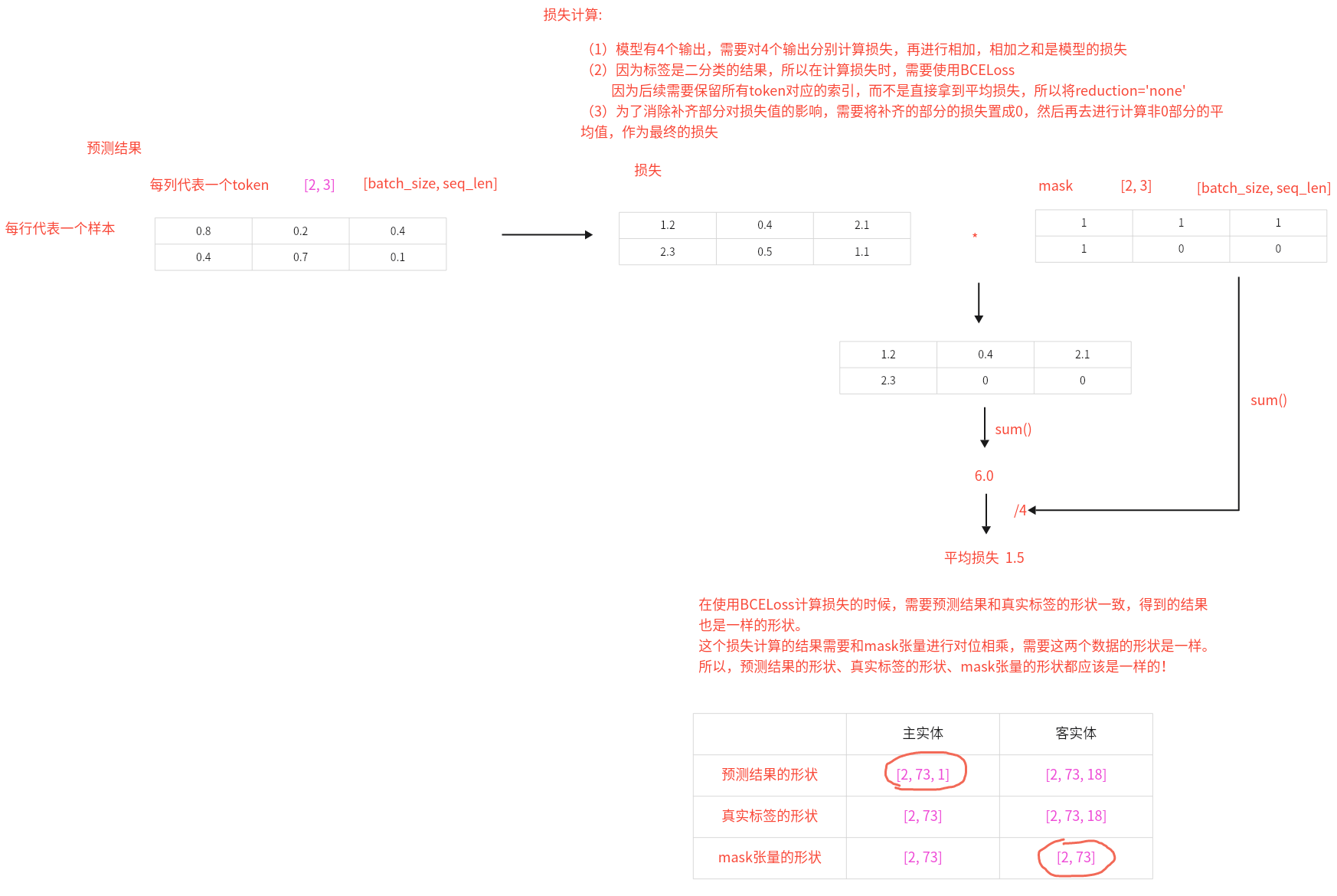



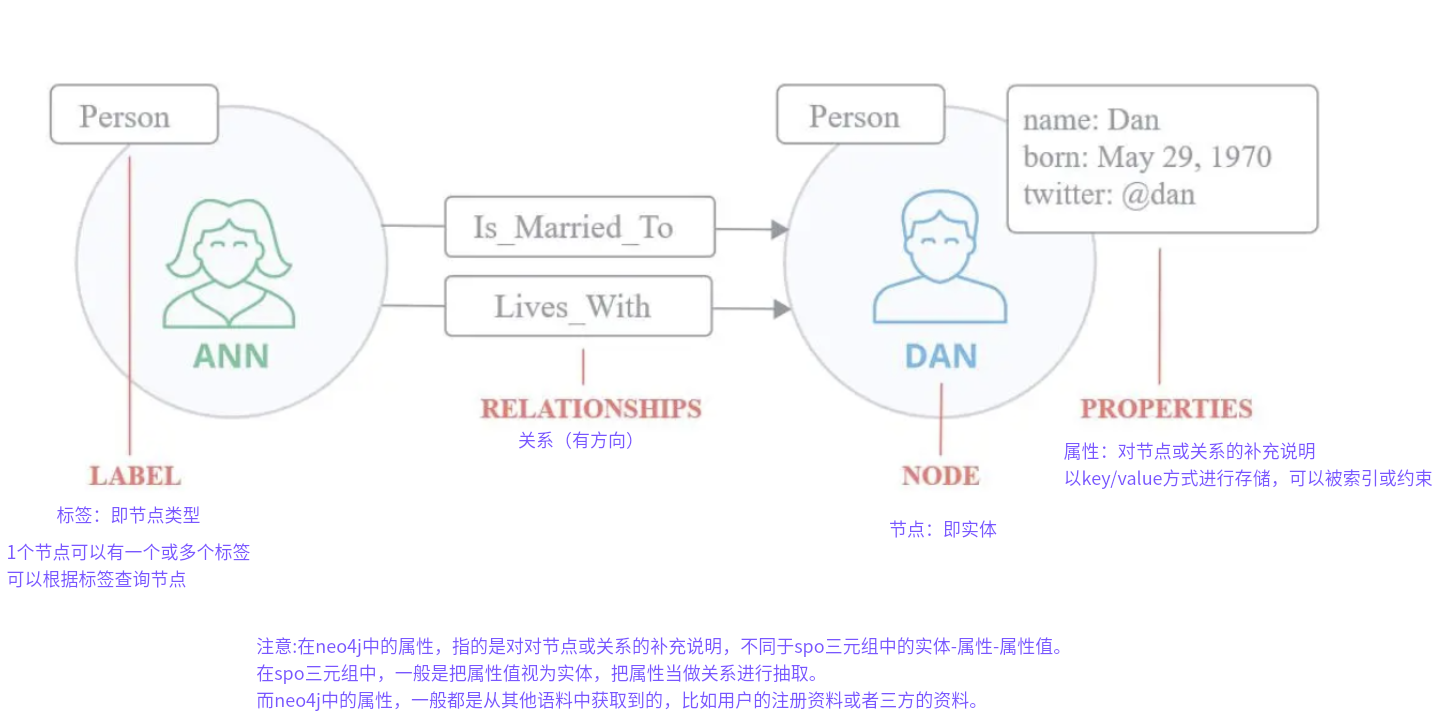
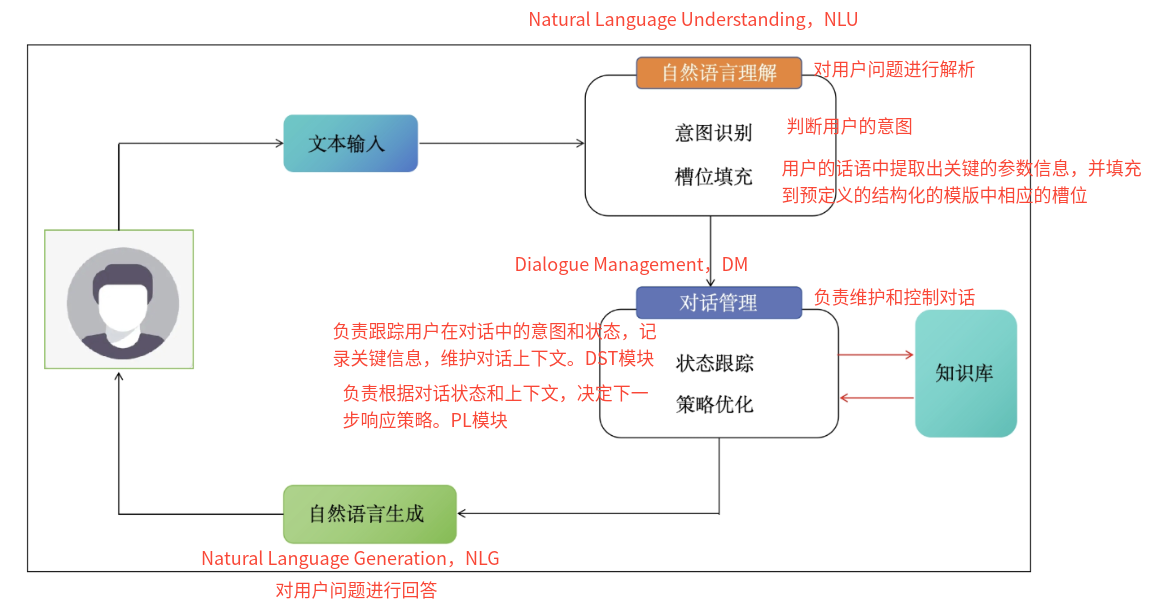
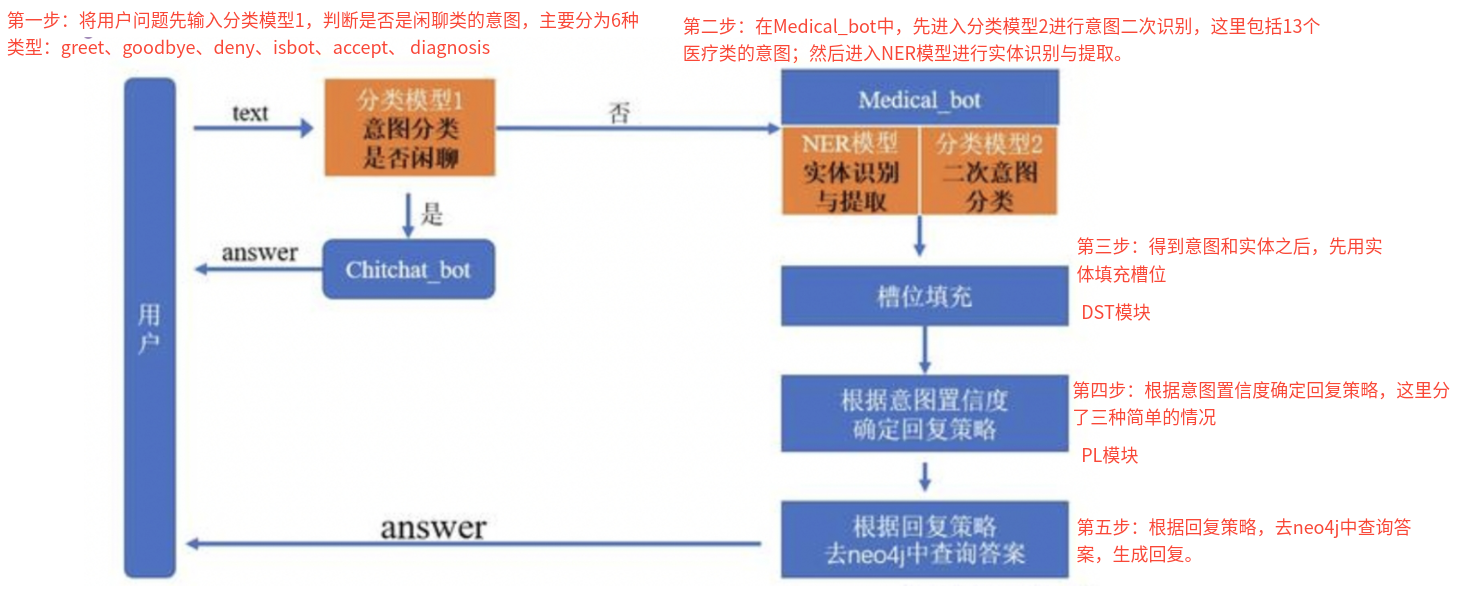



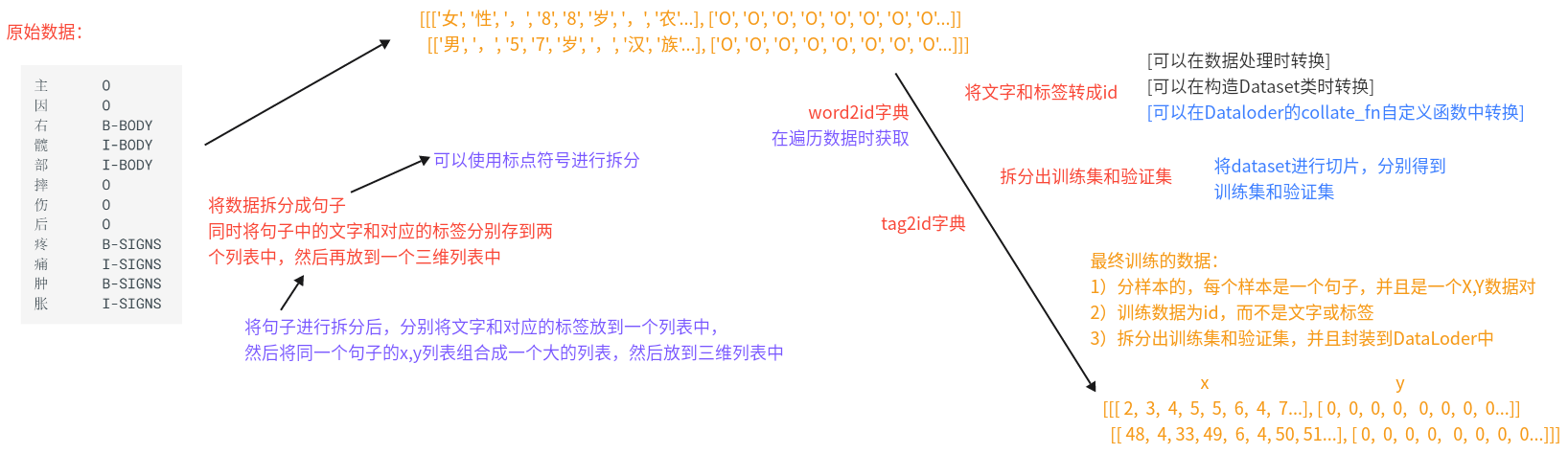
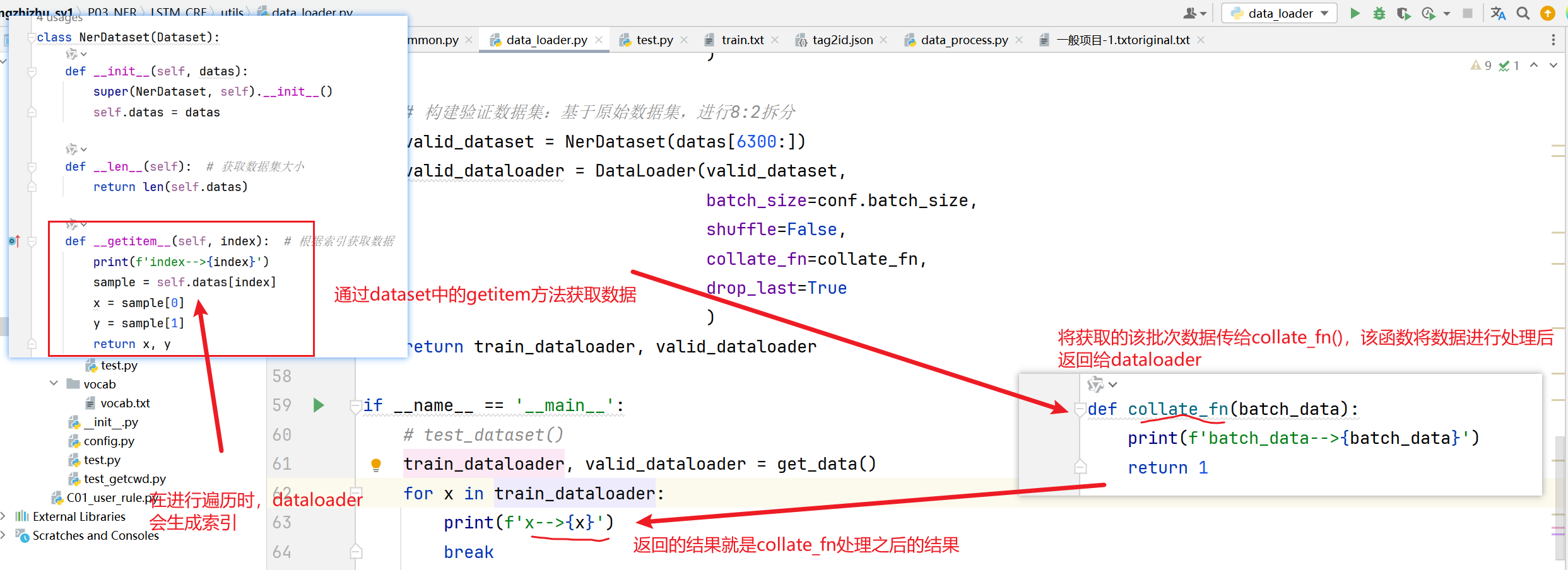

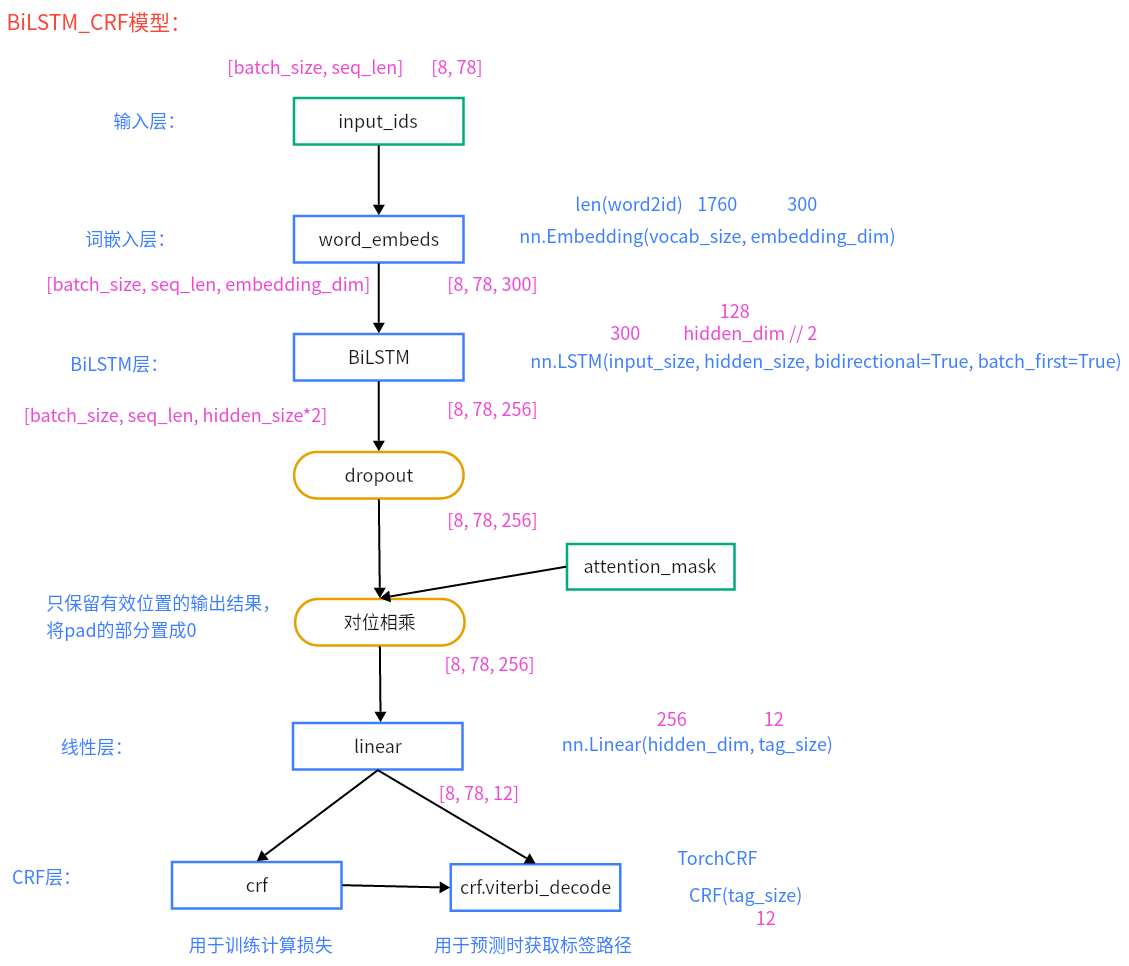

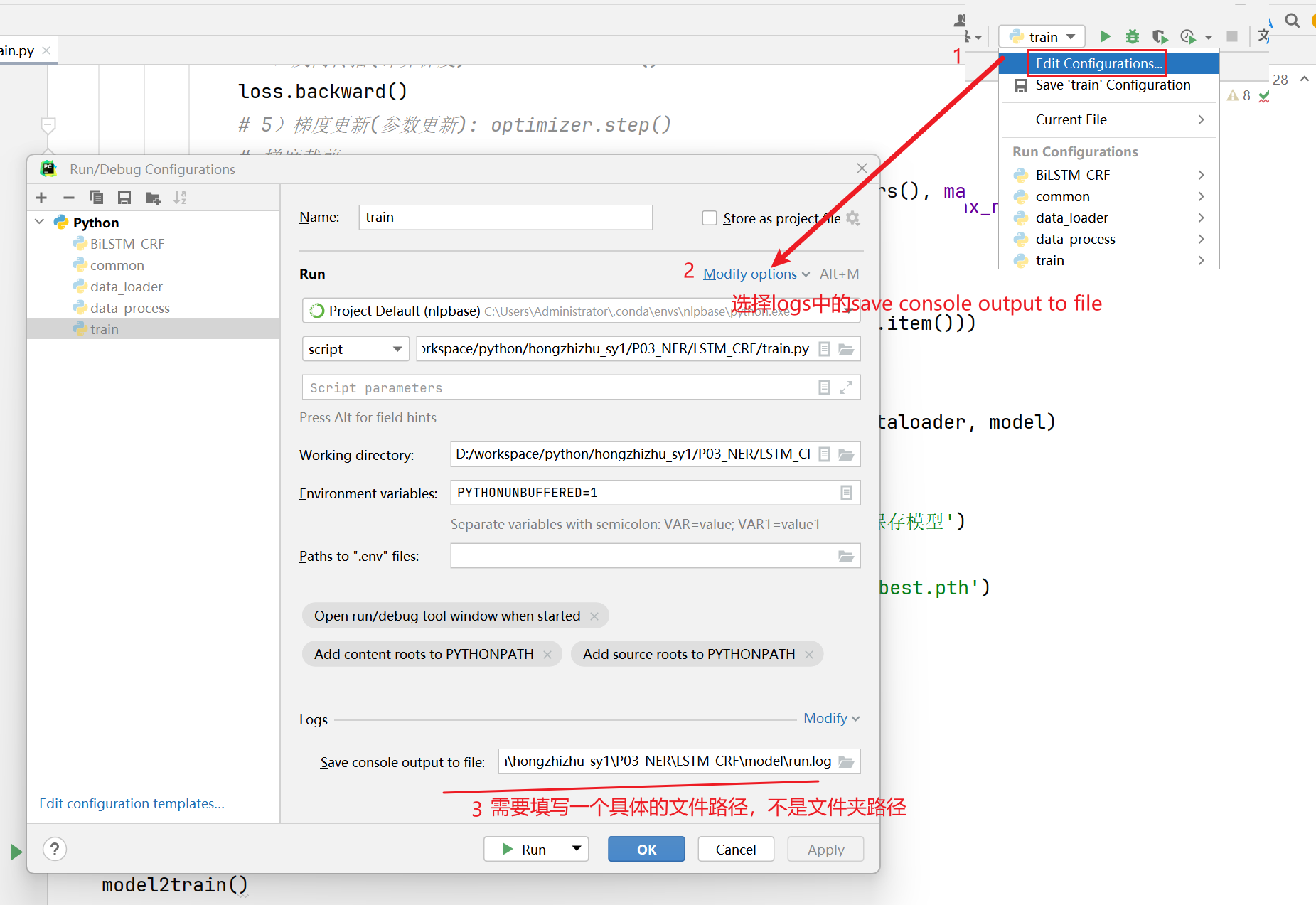
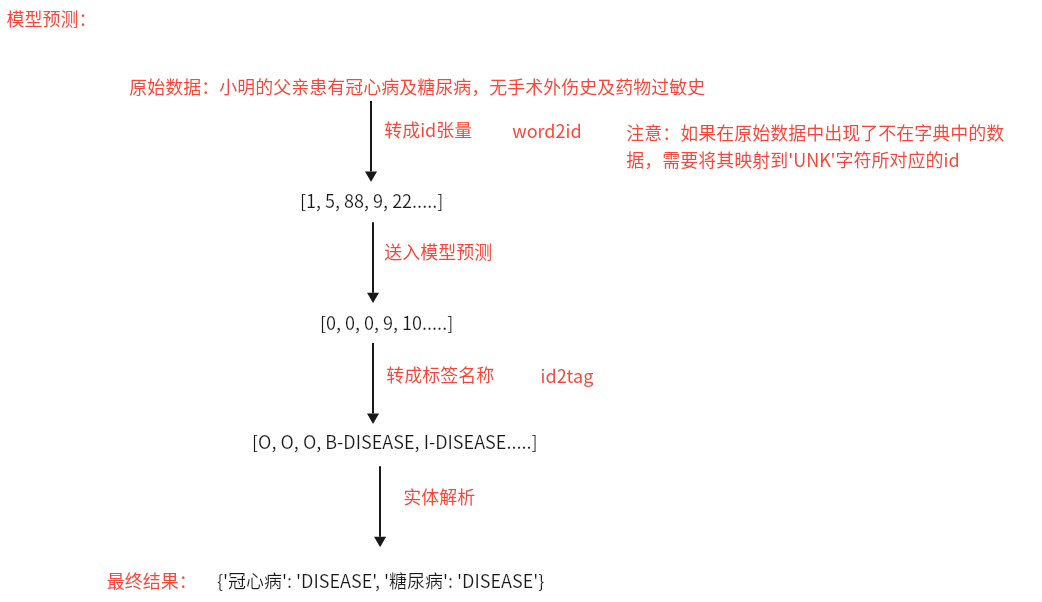
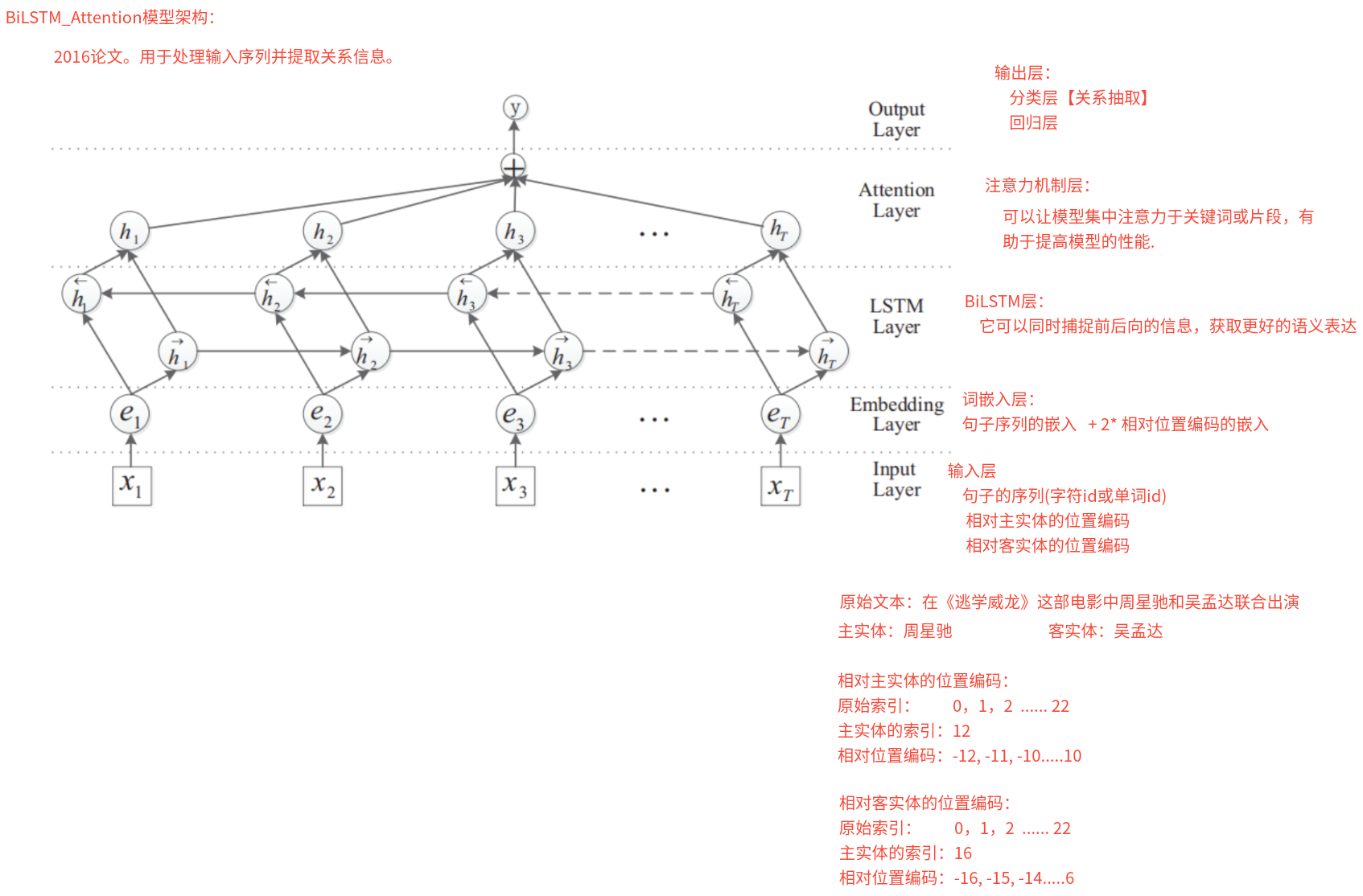



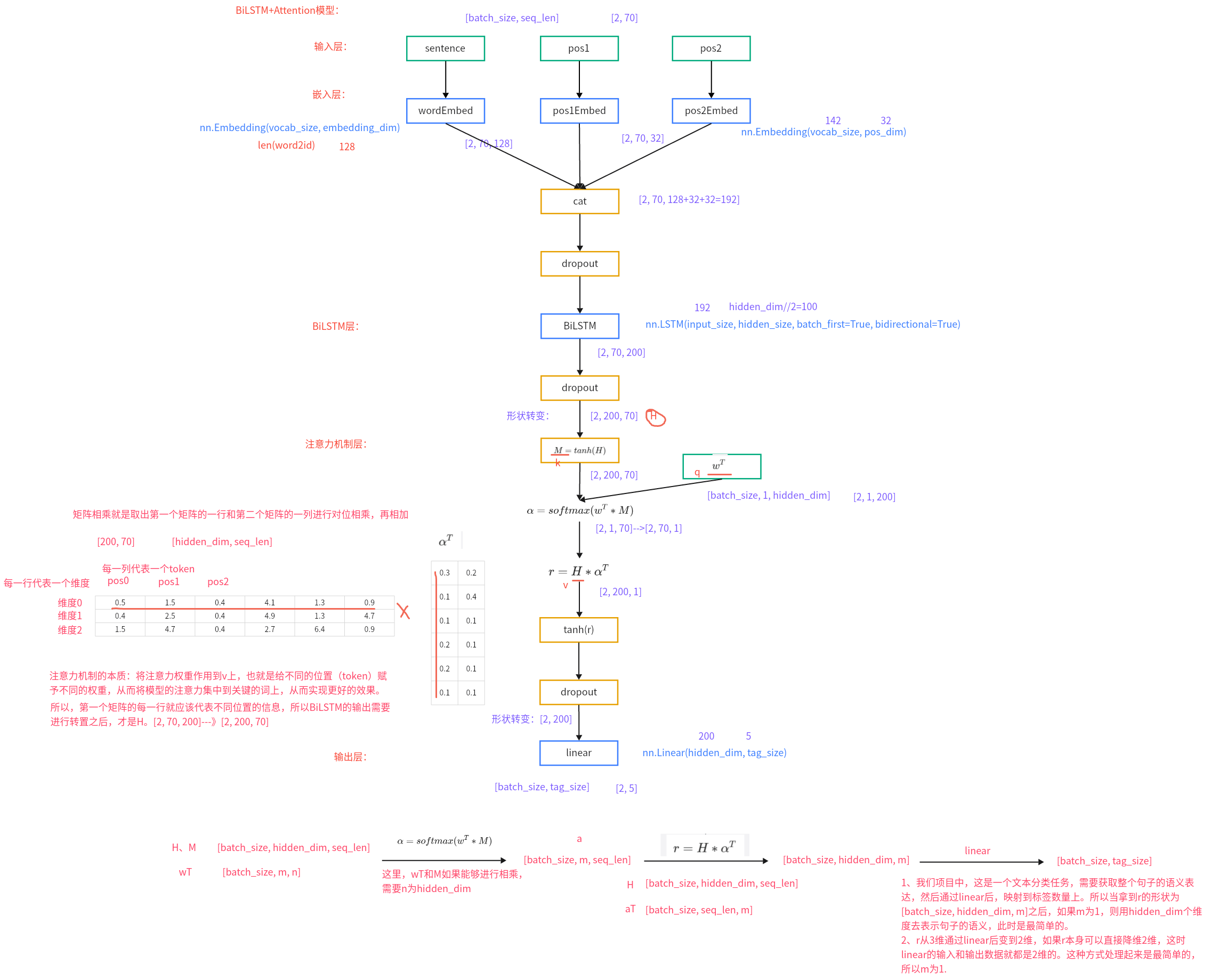
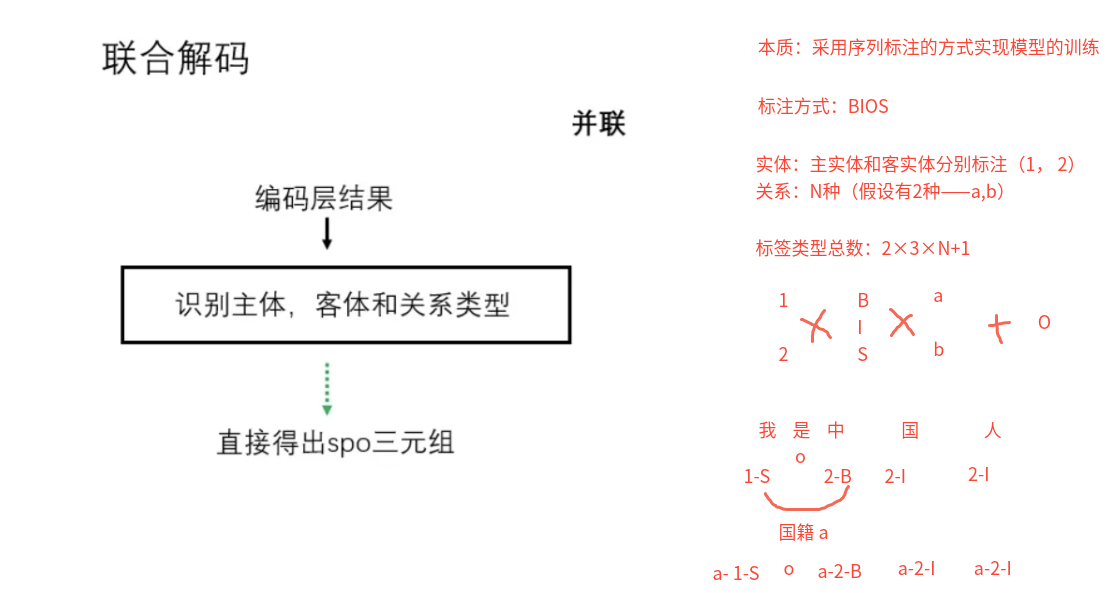
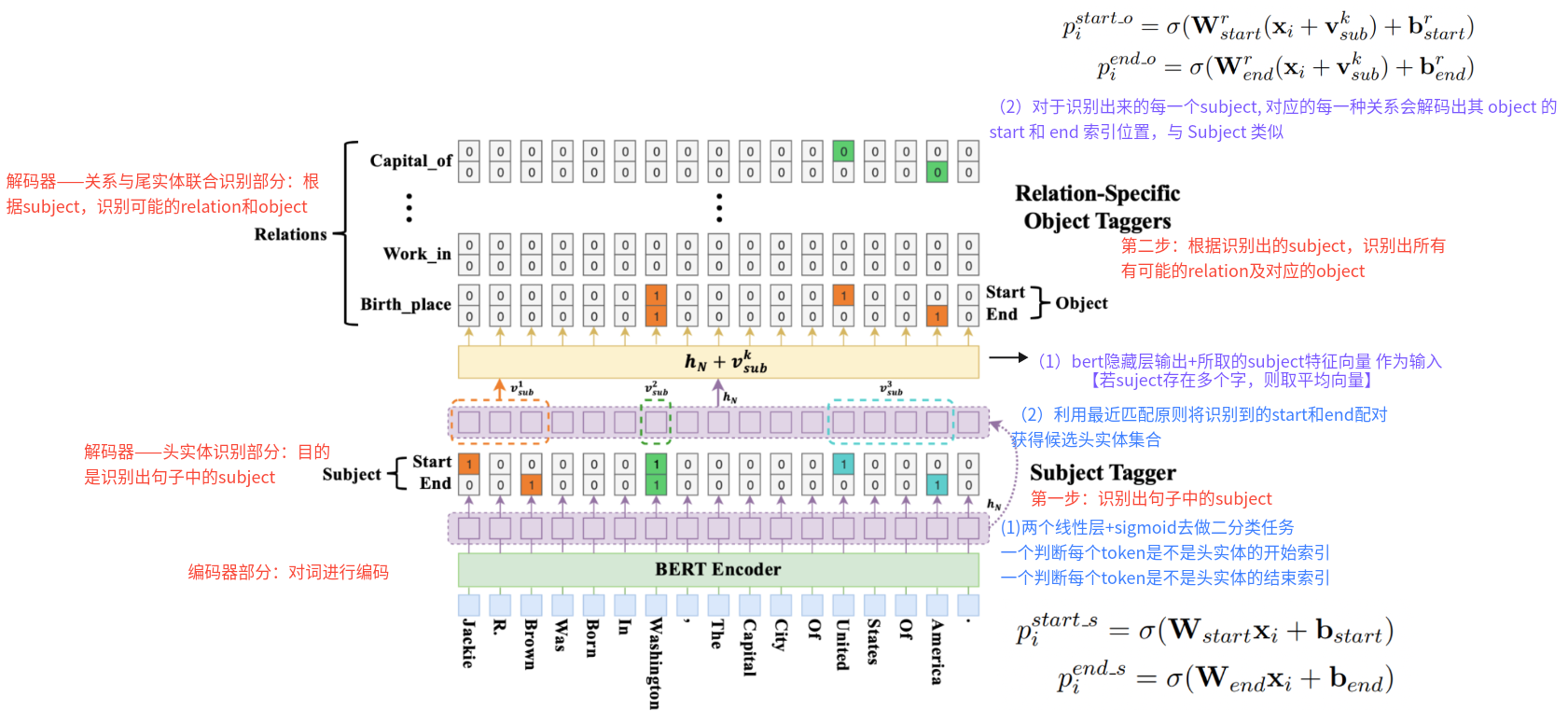
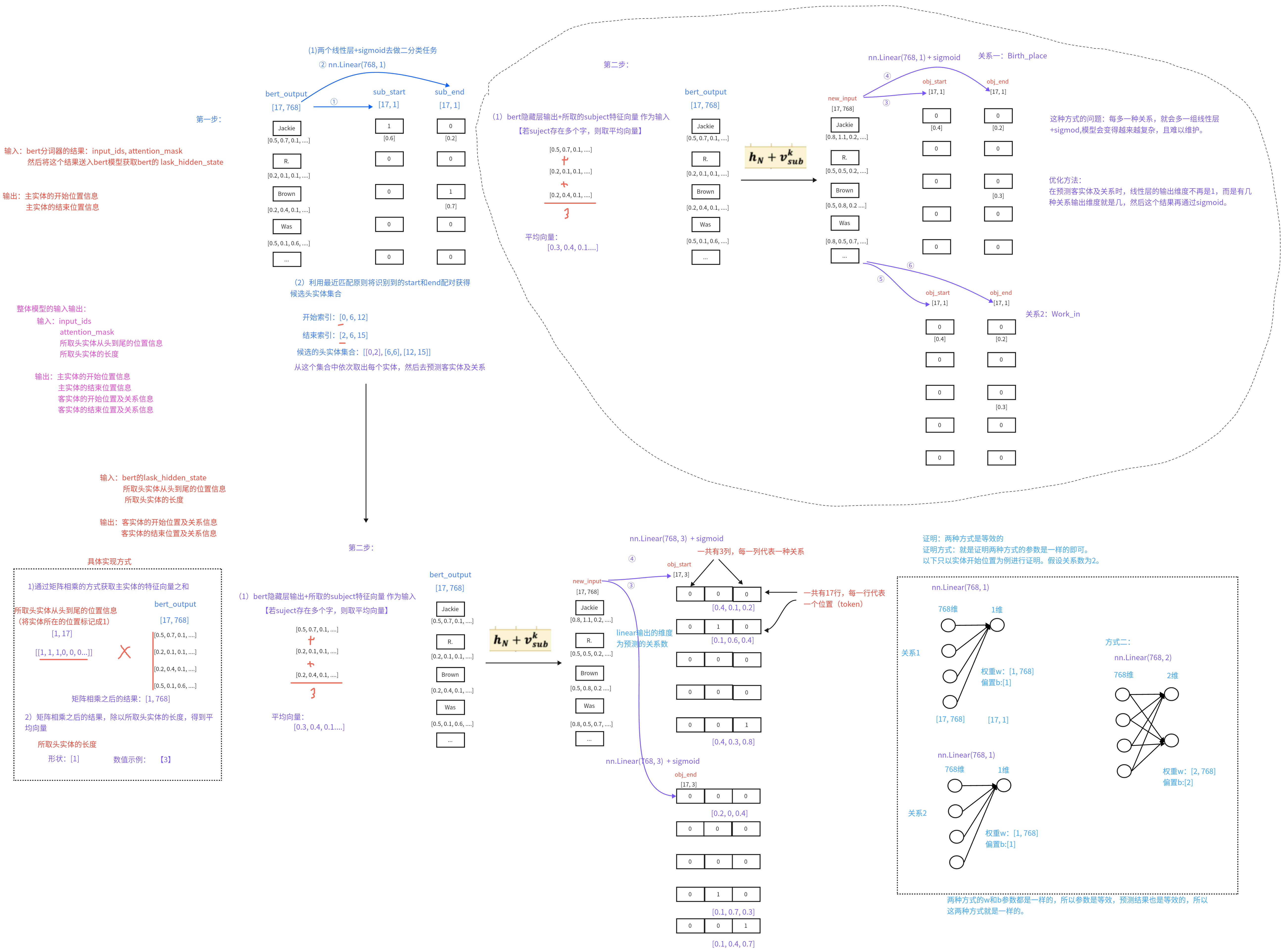

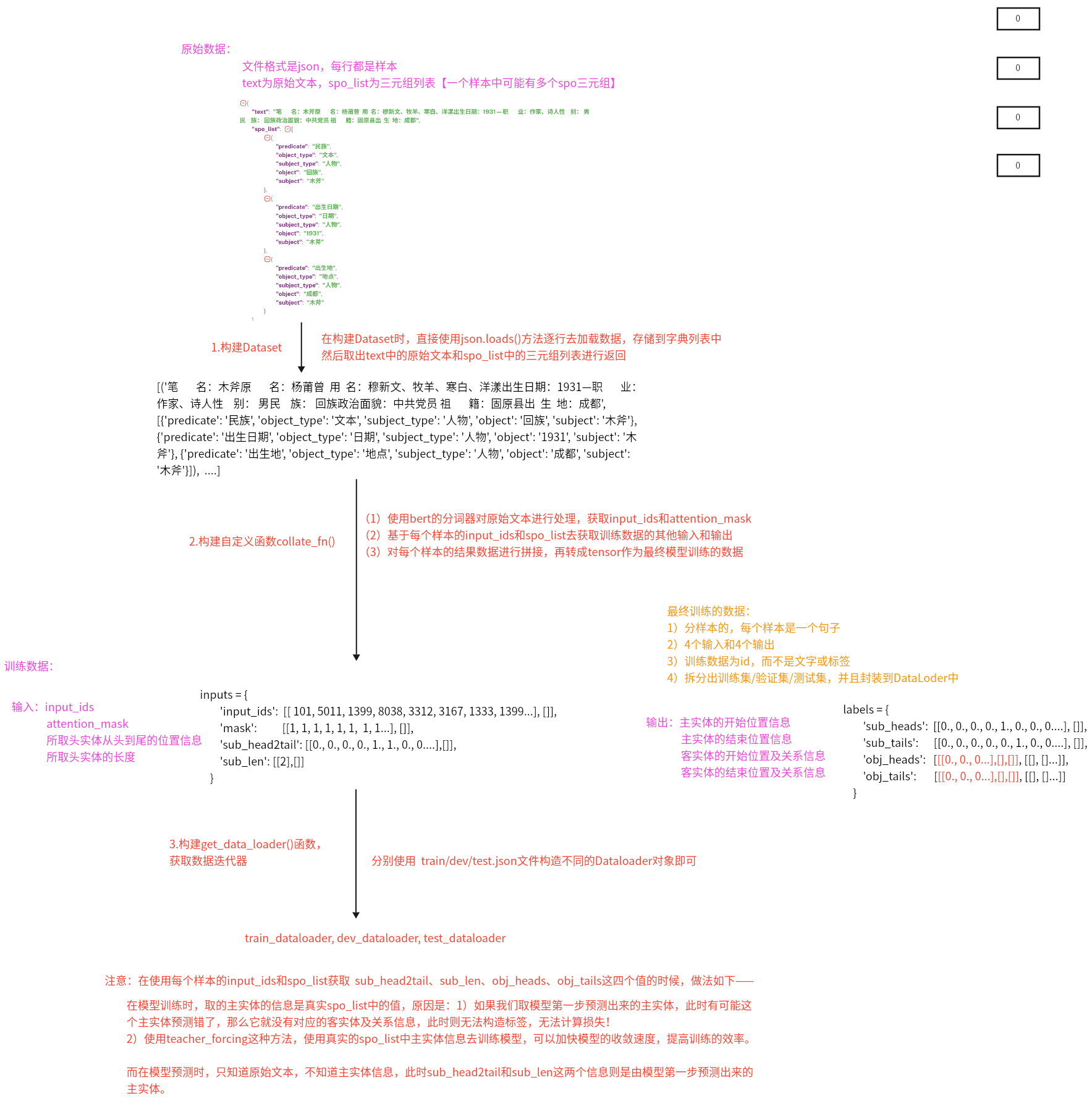
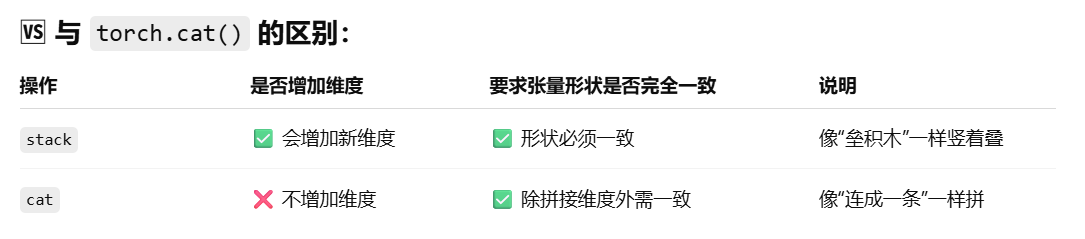

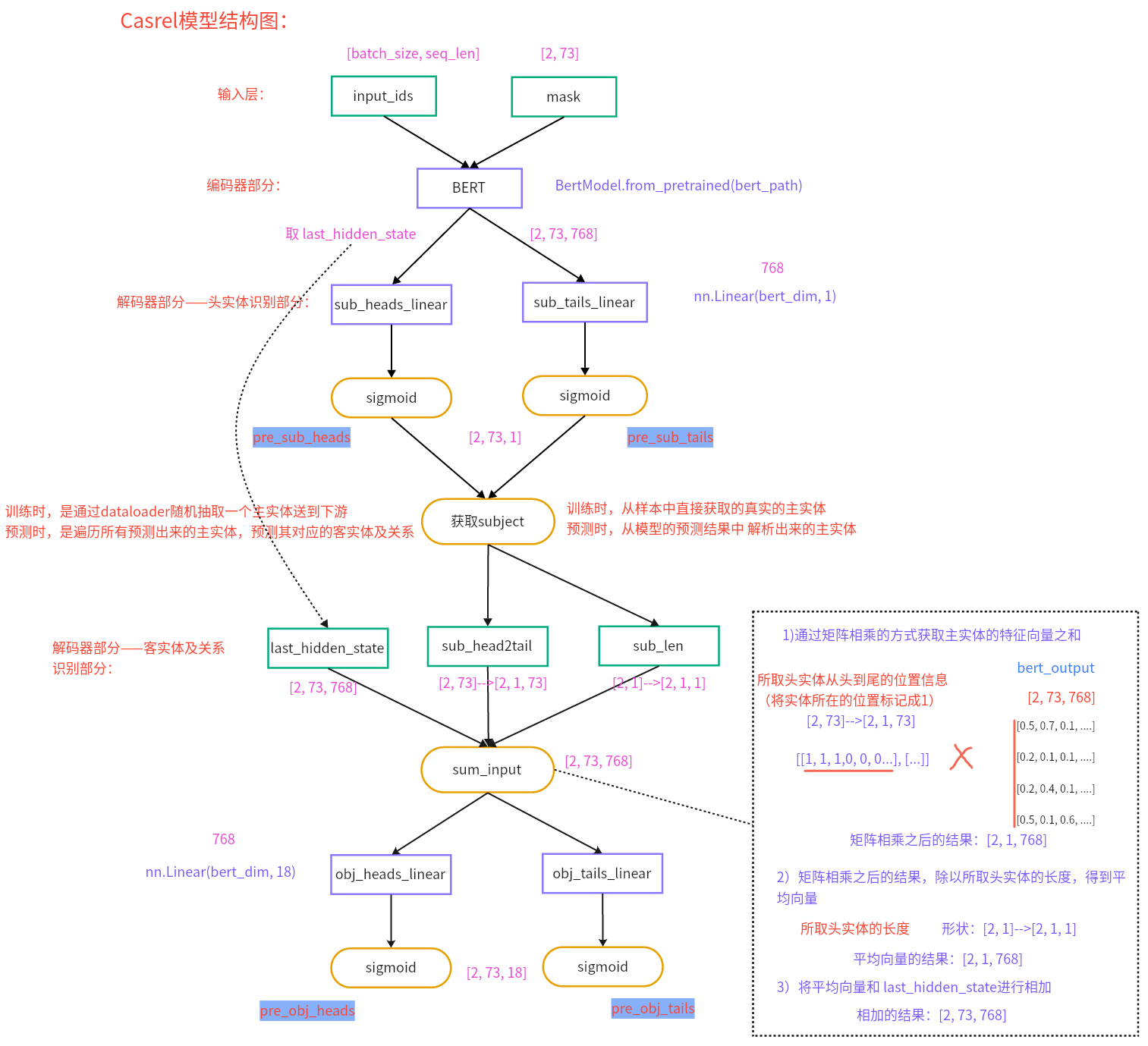
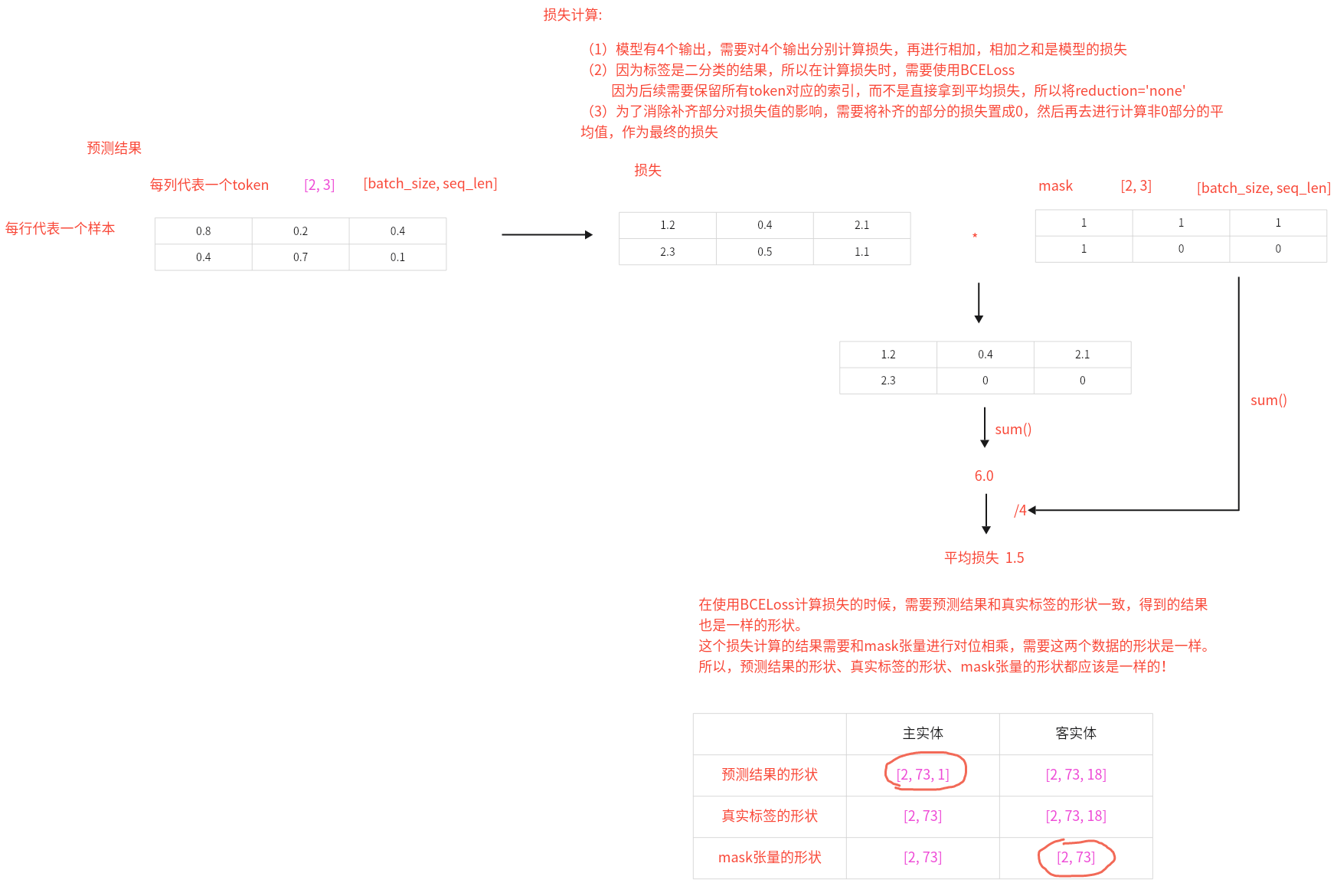



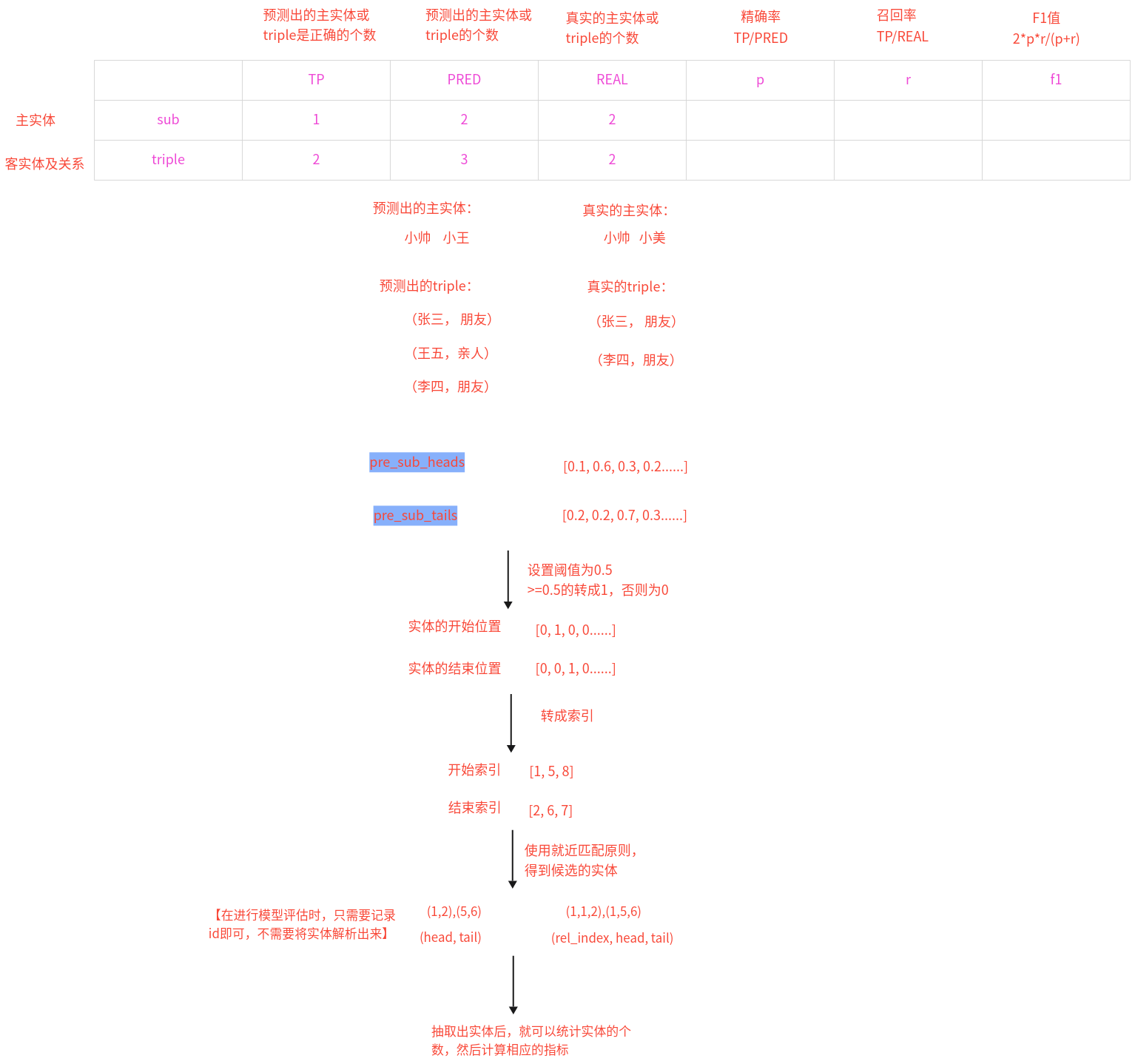


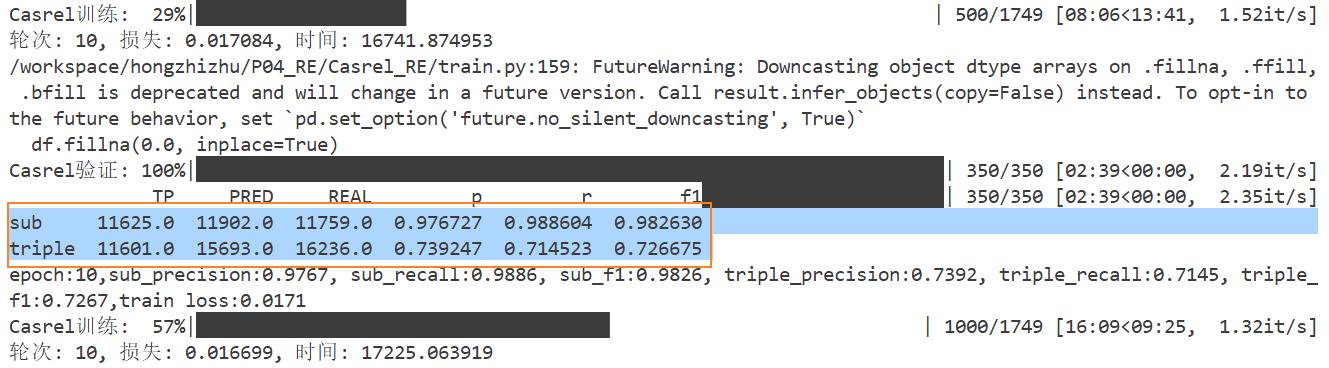 (3)测试函数
(3)测试函数

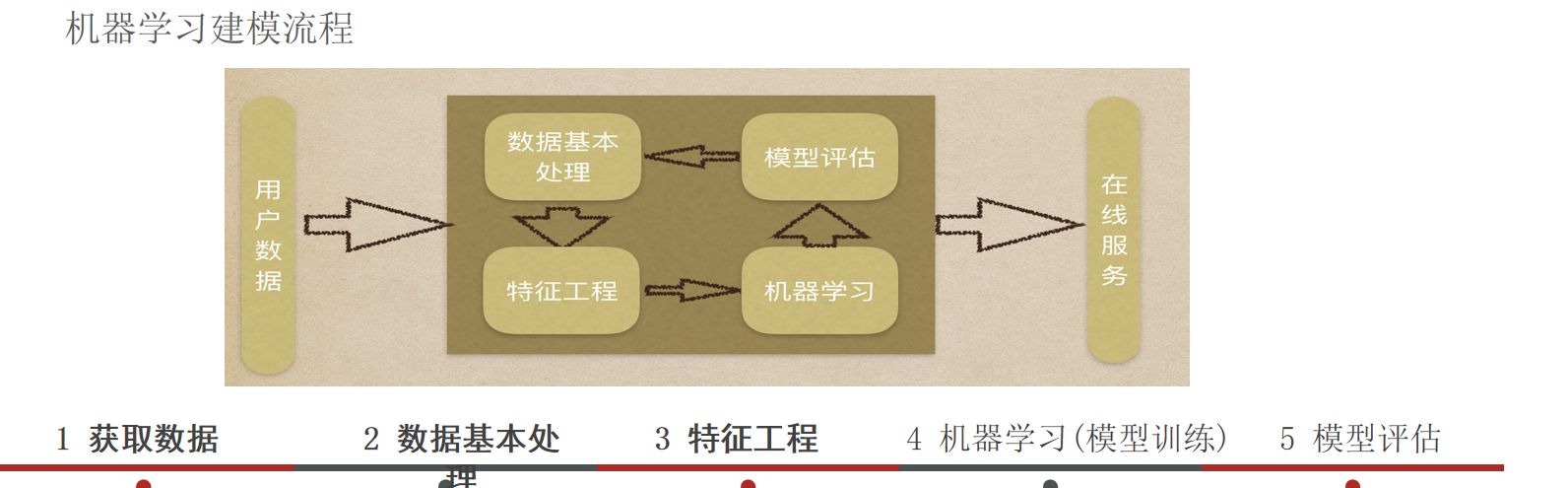













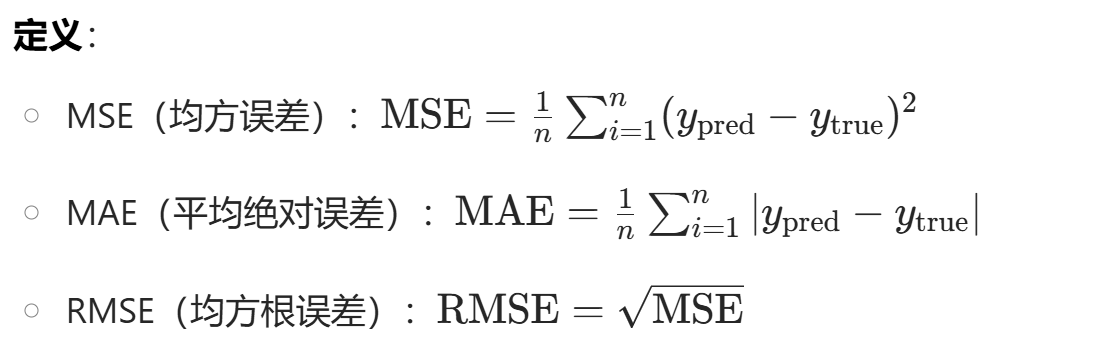

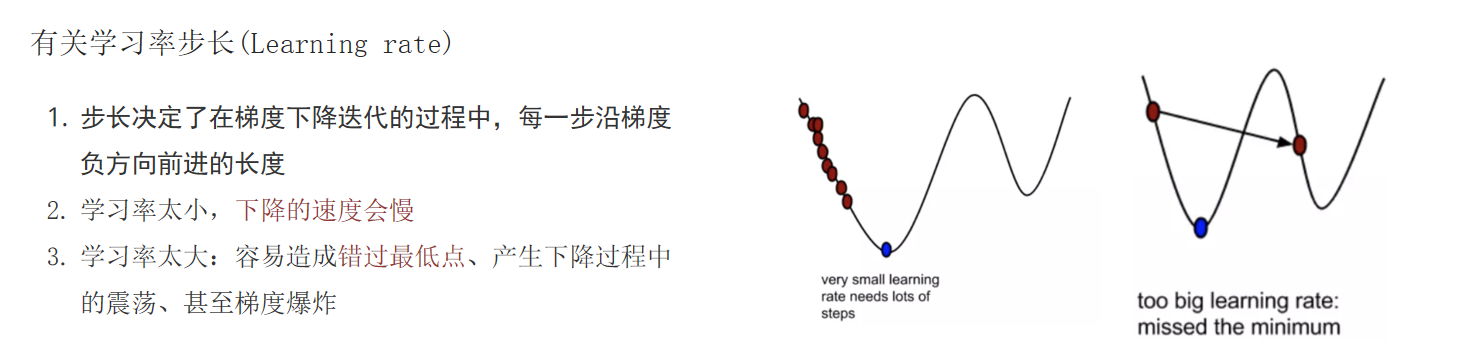


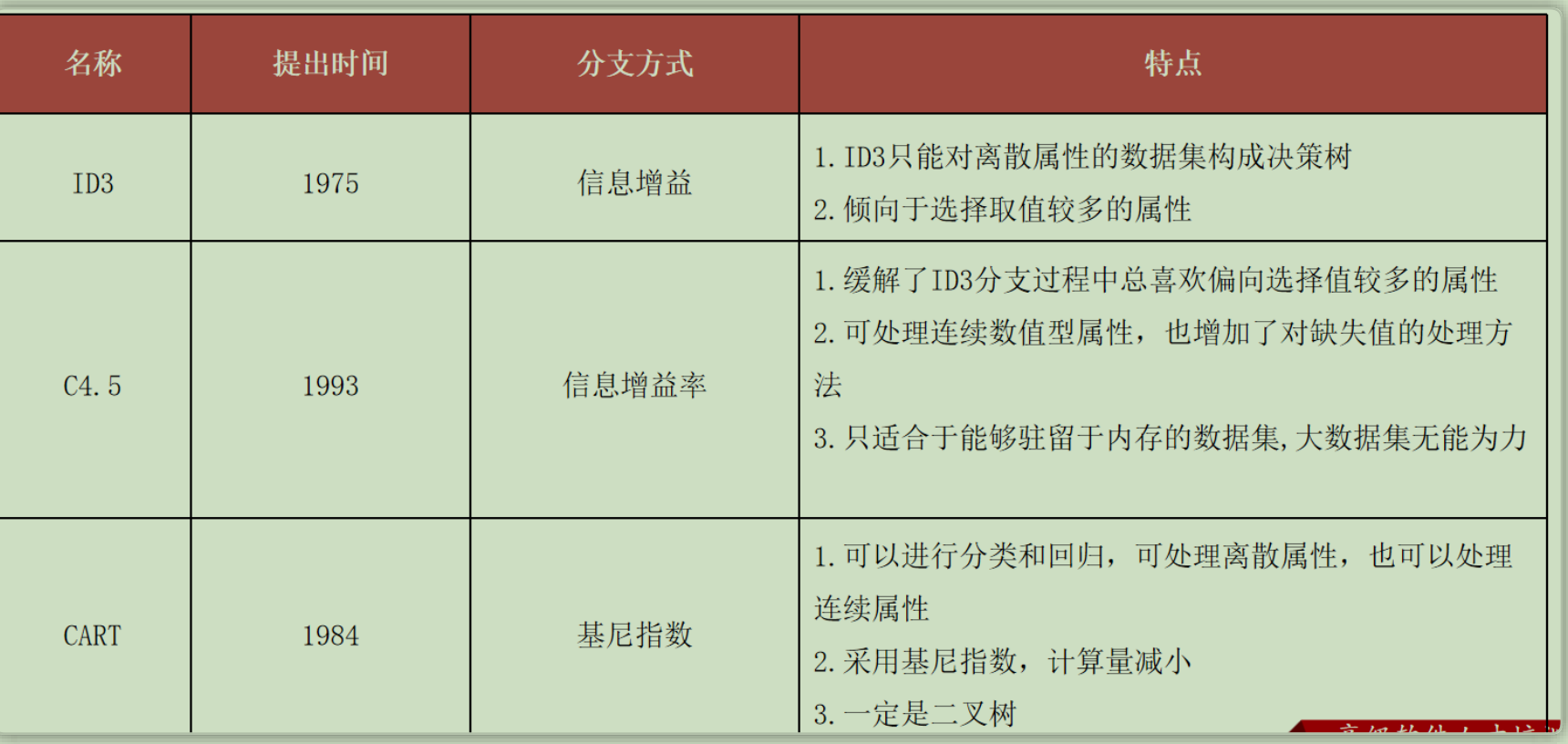 22:为什么需要对决策树进行剪枝?常用的剪枝方法有哪些?
22:为什么需要对决策树进行剪枝?常用的剪枝方法有哪些?
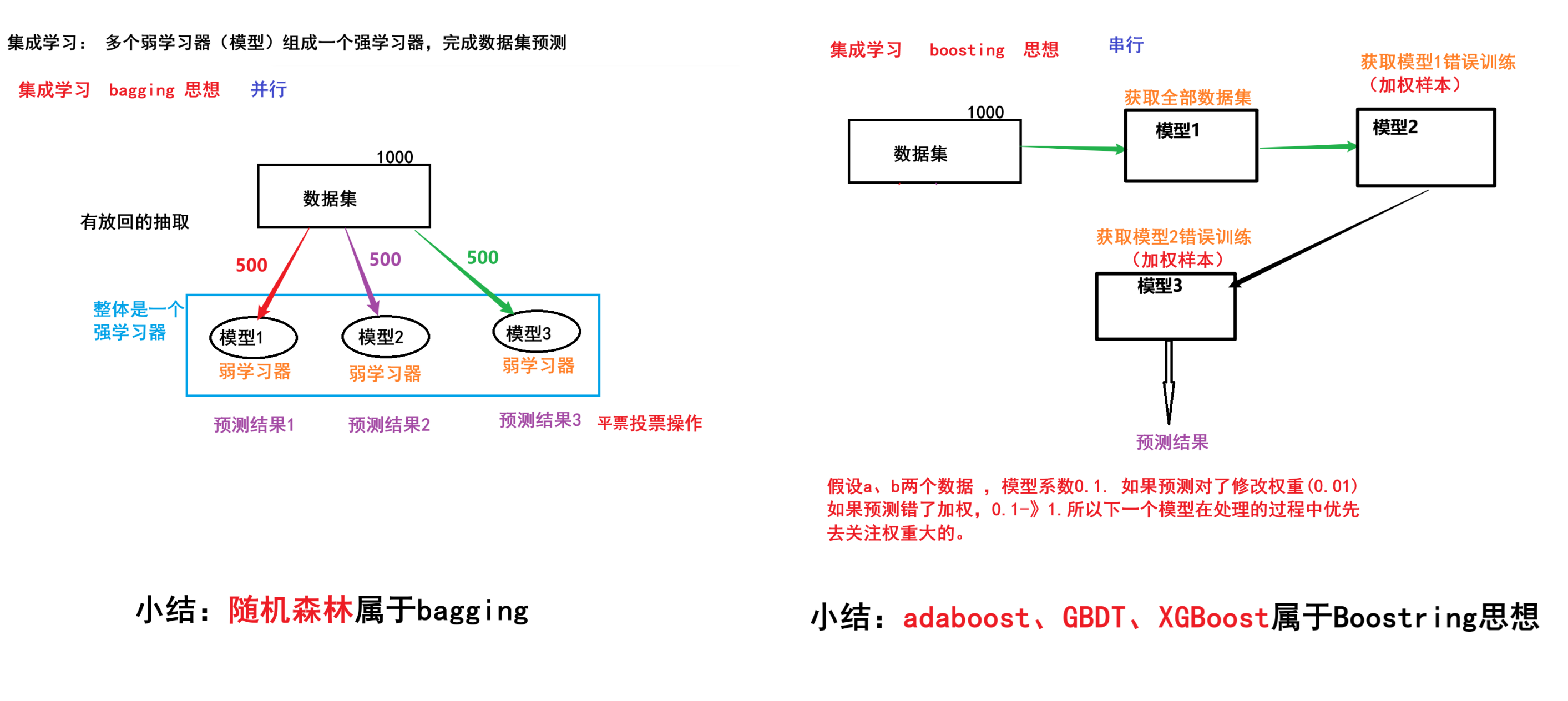

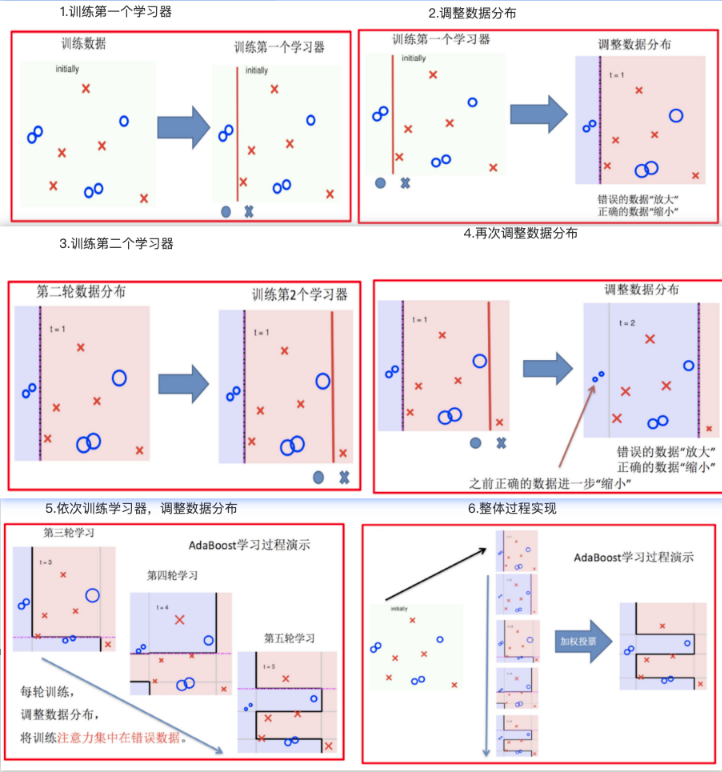
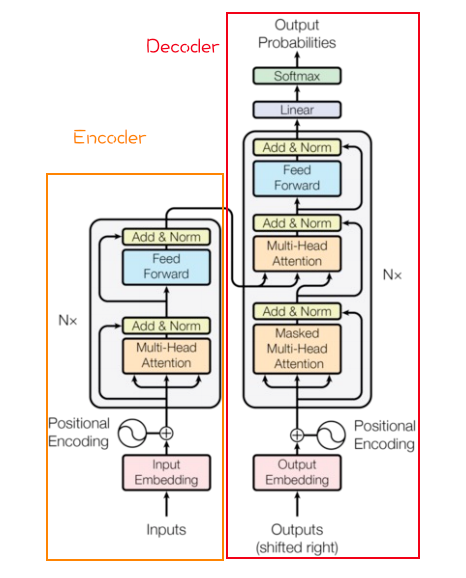
 微信
微信 支付宝
支付宝