P01_RAG系统项目介绍 1 背景介绍【了解】
业务:IT教育的答疑项目
技术:RAG【知识库+LLM】
2 RAG相关介绍【掌握】 2.1 RAG概念 通⽤的基础⼤模型存在一些问题:
幻觉问题,LLM有时会在回答中⽣成看似合理但实际上是错误的信息
LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后
LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识
RAG是一种将大规模语言模型(LLM)与外部知识源的检索相结合,以改进问答能力的工程框架。 它使用来自私有或专有数据源的信息来辅助文本生成,从而弥补LLM的局限性,特别是在解决幻觉问题和提升时效性方面。
2.2 RAG作用
缓解LLM“幻觉”问题 : LLM在生成文本时有时会“一本正经地胡说八道”,即生成听起来合理但实际上不准确或捏造的信息,这被称为“幻觉”。RAG通过提供外部事实依据,显著减少了这种幻觉现象,让LLM的输出更具 事实性 和 可靠性 。
获取最新信息 :LLM的训练数据通常是静态的,这意味着它们无法获取到训练截止日期之后发生的事件或更新的信息。RAG允许LLM连接到实时或定期更新的外部数据源(如新闻、数据库、内部文档等),从而提供 最新、最及时 的答案。
领域特定知识增强 :对于特定行业或企业内部的知识,LLM的通用训练数据往往不足。RAG能够将LLM与企业内部的知识库文档或特定领域的数据连接起来,使LLM能够回答高度专业化的问题,并提供 更符合上下文的答案 。
降低模型微调成本 :传统上,为了让LLM适应特定任务或数据,需要进行昂贵的 微调(Fine-tuning) 。RAG提供了一种更经济高效 的替代方案,它无需修改LLM的底层参数,只需更新外部知识库即可,大大降低了维护和更新模型的成本。
提高答案的可解释性和溯源性 :RAG可以引用其获取信息的来源,这意味着用户可以查看LLM答案所依据的原始文档或数据,增强了答案的 透明度 和 用户信任度 。
RAG通过将检索和生成相结合,既保留了传统检索问答的可靠性,又获得了LLM的灵活性和自然表达能力。它能让AI始终基于最新的、可信的知识来回答问题,同时保持对话的流畅自然。
2.3 RAG 的工作原理 2.3.1 工作流程图解
2.3.2 RAG标准流程
RAG 标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
索引阶段,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。
加载文件
内容提取
文本分割 ,形成chunk
文本向量化
将向量存储到向量数据库
检索阶段,用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
query向量化
在文本向量中匹配出与问句向量相似的top_k个
生成阶段,检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
匹配出的文本作为上下文和问题一起添加到prompt中
提交给LLM生成答案
3 项目流程【掌握】
(AI)学科在线答疑系统RAG主要步骤:
第一步:将现有后台搜集的FQA数据集存储到Mysql数据库中
第二步:基于query实现Mysql数据库检索:将query和现有问题匹配(做相似度计算),如果阈值>=0.85,就认为问题比较明确,直接返回对应的答案;否则,进入RAG检索系统
第三步:搭建本地知识库:对本地文档加载读取;进行文档分割;文档向量化;存储向量数据库(Milvus)
第四步:基于query实现Milvus数据库检索:将query进行向量表示,并从Milvus数据库中检索出相似的top-k个文本段
第五步:将query和检索出的top-k文本段拼接,送入大模型,实现预测
4 项目结构【实现】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 integrated_qa_system/ ├── config.ini # 配置文件,包含所有模块的配置 ├── base/ │ ├── config.py # 配置管理,加载 config.ini │ ├── logger.py # 日志设置 ├── rag_qa/ │ ├── core/ │ │ ├── prompts.py # RAG 提示模板 │ │ ├── query_classifier.py # 查询分类器 │ │ ├── strategy_selector.py # 检索策略选择器 │ │ ├── vector_store.py # 向量存储与检索 │ │ ├── rag_system.py # RAG 系统核心逻辑 │ ├── main.py # RAG 系统独立入口,支持存储和查询 ├── mysql_qa/ │ ├── db/ │ │ ├── mysql_client.py # MySQL 数据库操作 │ ├── cache/ │ │ ├── redis_client.py # Redis 缓存操作 │ ├── retrieval/ │ │ ├── bm25_search.py # BM25 搜索 │ ├── utils/ │ │ ├── preprocess.py # 文本预处理 │ ├── main.py # MySQL 系统独立入口,支持查询 ├── main.py # 集成系统入口,结合 RAG 和 MySQL ├── requirements.txt # 依赖文件 └── logs/ └── app.log # 日志文件
5 环境配置【实现】 5.1 python环境
为了不影响之前的python环境,也为了新项目中不会出现环境问题,需要新安装一个新的python环境。
如果之前虚拟环境是安装在C盘,C盘空间不足了,可以按下面的文档设置,安装到新的盘。https://blog.csdn.net/weixin_64878779/article/details/143457384?spm=1001.2014.3001.5506
1 2 3 4 5 6 7 8 # 打开conda终端后,设置镜像 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/ # 安装虚拟环境 conda create -n edu_rag python`3.10.18 # 激活虚拟环境 conda activate edu_rag
先在终端执行位置创建一个文件 requirements.txt,里边的内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ollama`0.4.4 requests`2.32.3 langchain`0.3.10 langchain_community`0.3.27 langchain-ollama`0.3.6 numexpr`2.11.0 unstructured`0.11.0 nltk`3.9.1 chromadb`1.0.15 faiss-cpu`1.12.0 pymilvus`2.5.4 pandas`2.3.1 jieba rank_bm25`0.2.2 redis`5.3.1 pymysql`1.1.1 opencv-python`4.10.0.84 PyMuPDF`1.23.16 python-docx`1.1.2 pillow`11.1.0 rapidocr-onnxruntime`1.4.4 python-pptx`0.6.23 transformers`4.45.0 modelscope`1.23.0 addict`2.4.0 datasets`3.3.1 simplejson`3.19.2 sortedcontainers`2.4.0 markdown`3.6 sentence-transformers`3.0.1 milvus-model`0.2.5 tiktoken`0.7.0 sentencepiece`0.2.0 ragas`0.2.6 starlette`0.46.2 fastapi`0.115.12
然后执行命令:
1 pip install -r requirements.txt
如果电脑支持GPU,可以按照之前讲过的方法安装不高于CUDA版本的torch等三方包,比如(cu121为cuda的版本):
1 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
5.2 相关工具介绍 Ollama:一个开源的大型语言模型服务工具,用于快速在本地运行大模型。
LangChain:为各种LLMs实现通用的接口,把LLMs相关的组件“链接”在一起,简化LLMs应用的开发难度,方便开发者快速地开发复杂的LLMs应用。
Milvus:一个开源向量数据库,用于实现向量数据的存储和检索。
MySQL/Redis:分别为关系型数据库和内存数据库,用于实现缓存高频问答对,加快回复效率。
LangChain 1 简述【理解】 1.1 什么是LangChain LangChain是一个框架,来帮助开发者快速开发智能应用。
参考官网介绍:
https://python.langchain.com/docs/introduction/
LangChain 简化了 LLM 应用程序生命周期的每个阶段:
开发:使用 LangChain 的开源组件和第三方集成构建应用程序。使用 LangGraph 构建具有一流流式和人机交互支持的状态智能体。
生产化:使用 LangSmith 检查、监控和评估应用程序,方便持续优化和部署。
部署:使用 LangGraph平台 将应用程序转变为可用于生产的 API 和助手。
1.2 主要组件
Models:模型,各种类型的模型和模型集成,比如GPT-4
Prompts:提示,包括提示管理、提示优化和提示序列化
Memory:记忆,用来保存和模型交互时的上下文状态
Indexes:索引,用来结构化文档,以便和模型交互
Chains:链,一系列对各种组件的调用
Agents:代理,决定模型采取哪些行动,执行并且观察流程,直到完成为止
1.3 LangChain核心包 langchain-core:聊天模型和其他组件的基础抽象。
集成包(例如 langchain-openai、langchain-anthropic 等):重要的集成被拆分为轻量级的独立包,由 LangChain 团队和集成方共同维护。
langchain:包含链(chains)、智能体(agents)和检索策略,这些构成了应用的认知架构。
langchain-community:由社区维护的第三方集成。
langgraph:一个编排框架,用于将 LangChain 组件组合成可用于生产的应用,支持持久化、流式处理及其他关键特性。
2 Models【熟悉】 2.1 LLMs (大语言模型) LLMs使用场景最多,常用大模型的下载库:
https://huggingface.co/models
https://modelscope.cn/models
下面Qwen为例进行讲解。
模型调用有2种方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from langchain_openai import ChatOpenAIfrom dotenv import load_dotenvimport osload_dotenv() llm = ChatOpenAI(base_url=os.environ.get('DASHSCOPE_BASE_URL' ), model=os.environ.get('DASHSCOPE_MODEL_NAME' ), api_key=os.environ.get('DASHSCOPE_API_KEY' ), temperature=0.7 ) result = llm.invoke("帮我讲个笑话吧" ) print (result.content)
1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvload_dotenv() llm = ChatTongyi(model=os.environ.get('DASHSCOPE_MODEL_NAME' )) result = llm.invoke("帮我讲个笑话吧" ) print (result.content)
2.2 Chat Models (聊天模型) 聊天消息包含下面几种类型,使用时需要按照约定传入合适的值:
AIMessage: 就是 AI 输出的消息,可以是针对问题的回答.
HumanMessage: 人类消息就是用户信息,由人给出的信息发送给LLMs的提示信息,比如“实现一个快速排序方法”.
SystemMessage: 可以用于指定模型具体所处的环境和背景,如角色扮演等。你可以在这里给出具体的指示,比如“作为一个代码专家”,或者“返回json格式”.
ChatMessage: Chat 消息可以接受任意角色的参数,但是在大多数时间,我们应该使用上面的三种类型.
LangChain支持大量的chat 模型,可以通过官网查询:
https://python.langchain.com/docs/integrations/chat/
SystemMessage+HumanMessage+AIMessage
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from langchain_community.chat_models.tongyi import ChatTongyifrom langchain_core.messages import SystemMessage,HumanMessage,AIMessagefrom dotenv import load_dotenvload_dotenv() chat = ChatTongyi() message = [SystemMessage(content="你是一个田园诗人" ), HumanMessage(content="给我写一首唐诗,请尊重版权,不要抄袭" ), AIMessage(content=""" 闲步柴门外,斜阳照野田。 风轻花影动,水静月光圆。 老树鸣蝉歇,新荷映日鲜。 心随云去远,不问世间缘。 """ ), HumanMessage(content="请继续写诗" )] response = chat.invoke(message) print (response.content)
2.3 Embeddings Models(嵌入模型) Embedding的作用就是将数据进行文本向量化
不同的Embedding模型对多语言支持和文本类型有不同的特点:
多语言支持 :
text-embedding-ada-002:支持多种语言,但对中文等亚洲语言的支持相对较弱bge-large-zh:对中文有很好的支持multilingual-e5-large:对多语言都有较好的支持
文本类型适用性 :
代码文本:建议使用专门的代码Embedding模型,如 CodeBERT
通用文本:可以使用text-embedding-ada-002或 bge-large-zh
专业领域文本:建议使用该领域的专门模型
可以参考MTEB(大规模文本嵌入基准)排行榜以获取最新模型效果:https://huggingface.co/spaces/mteb/leaderboard
接下来以一个文本嵌入模型的例子进行说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from langchain_community.embeddings import DashScopeEmbeddingsfrom dotenv import load_dotenvload_dotenv() embed = DashScopeEmbeddings() doc_embedding = embed.embed_query("Embeddings Models可以为文本创建向量映射,这样就能在向量空间里去考虑文本,执行诸如语义搜索之类的操作,比如说寻找相似的文本片段。" ) print (doc_embedding)print (len (doc_embedding)) doc_embeddings = embed.embed_documents(["Embeddings Models特点:将字符串作为输入,返回一个浮动数的列表。" , "在NLP中,Embedding的作用就是将数据进行文本向量化。" ]) print (doc_embeddings)print (len (doc_embeddings))
运行结果:
3 Prompts【掌握】 3.1 通用prompt Prompt是指当用户输入信息给模型时加入的提示,这个提示的形式可以是zero-shot或者few-shot等方式,目的是让模型理解更为复杂的业务场景以便更好的解决问题。
提示模板:如果你有了一个起作用的提示,你可能想把它作为一个模板用于解决其他问题,LangChain就提供了PromptTemplates组件,它可以帮助你更方便的构建提示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvfrom langchain_core.prompts import PromptTemplateload_dotenv() model = ChatTongyi(model='qwen-max' , temperature=1.5 ) template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字" prompt_template = PromptTemplate(template=template, input_variables=["lastname" ]) prompt = prompt_template.format (lastname="王" ) print (f'prompt-->{prompt} ' )result = model.invoke(prompt) print (f'result-->{result.content} ' )
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from langchain_community.llms.tongyi import Tongyifrom dotenv import load_dotenvfrom langchain_core.prompts import PromptTemplate, FewShotPromptTemplateload_dotenv() model = Tongyi(model='qwen-max' , temperature=1.5 ) examples = [ {"word" : "开心" , "antonym" : "难过" }, {"word" : "高" , "antonym" : "矮" }, ] example_template = """ 单词: {word} 反义词: {antonym} """ example_prompt = PromptTemplate(template=example_template, input_variables=["word" , "antonym" ]) few_shot_prompt = FewShotPromptTemplate(example_prompt=example_prompt, examples=examples, example_separator="" , prefix="请给出单词的反义词,以下是一些示例:" , suffix="\n单词:{input}\n反义词:" , input_variables=["input" ] ) prompt = few_shot_prompt.format (input ="富有" ) print (f'prompt-->{prompt} ' )result = model.invoke(prompt) print (f'result-->{result} ' )
运行结果:
3.2 chatprompts 适合交互式对话应用,如聊天机器人、智能客服等,这些应用需要处理用户和LLM之间的多轮对话。
ChatPromptTemplate
SystemMessagePromptTemplate
HumanMessagePromptTemplate
history=[(“system”,”……”),(‘human’,”……”),(“ai”,”……”)]
提示模板就是把一些常见的提示整理成模板,用户只需要修改模板中特定的词语,就能快速准确地告诉模型自己的需求。我们看个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvfrom langchain_core.prompts import ChatPromptTemplateload_dotenv() model = ChatTongyi(model='qwen-max' , temperature=1.5 ) template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字" prompt_template = ChatPromptTemplate.from_template(template) prompt = prompt_template.format_messages(lastname="王" ) print (f'prompt-->{prompt} ' )result = model.invoke(prompt) print (f'result-->{result.content} ' )
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvfrom langchain_core.messages import SystemMessagefrom langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplateload_dotenv() model = ChatTongyi(model='qwen-max' , temperature=1.5 ) system_prompt = SystemMessage("你是一个取名专家" ) template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字" prompt_template = HumanMessagePromptTemplate.from_template(template) chat_template = ChatPromptTemplate.from_messages([system_prompt, prompt_template]) prompt = chat_template.format_messages(lastname="王" ) print (f'prompt-->{prompt} ' )result = model.invoke(prompt) print (f'result-->{result.content} ' )
运行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvfrom langchain_core.messages import HumanMessage, AIMessagefrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderload_dotenv() model = ChatTongyi(model='qwen-max' , temperature=1.5 ) prompt_template = ChatPromptTemplate.from_messages([ ("system" , "给出每个单词的反义词" ), MessagesPlaceholder(variable_name="history" ), ("human" , "{input}" ) ]) history = [("human" , "开心" ), ("ai" , "难过" ), ("human" , "高" ), ("assistant" , "矮" )] prompt = prompt_template.format_messages(history=history, input ='富有' ) print (f'prompt-->{prompt} ' )response = model.invoke(prompt) print (f'response-->{response.content} ' )
运行结果:
4 Chains【掌握】 4.1 chain 在LangChain中,Chains描述了将LLM与其他组件结合起来完成一个应用程序的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from langchain.chains.llm import LLMChainfrom langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvfrom langchain_core.prompts import PromptTemplateload_dotenv() model = ChatTongyi(model='qwen-max' , temperature=1.5 ) template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字" prompt_template = PromptTemplate(template=template, input_variables=["lastname" ]) chain = LLMChain(llm=model, prompt=prompt_template) result = chain.invoke(input ={"lastname" : "王" }) print (f'result-->{result} ' )
如果你想将第一个模型输出的结果,直接作为第二个模型的输入,还可以使用LangChain的SimpleSequentialChain, 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from langchain.chains.llm import LLMChainfrom langchain.chains.sequential import SimpleSequentialChainfrom langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvfrom langchain_core.prompts import PromptTemplateload_dotenv() model = ChatTongyi(model='qwen-max' , temperature=1.5 ) template1 = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字" prompt_template1 = PromptTemplate(template=template1, input_variables=["lastname" ]) chain1 = LLMChain(llm=model, prompt=prompt_template1) template2 = "邻居的儿子名字叫{child_name},给他起一个小名" prompt_template2 = PromptTemplate(template=template2, input_variables=["child_name" ]) chain2 = LLMChain(llm=model, prompt=prompt_template2) final_chain = SimpleSequentialChain(chains=[chain1, chain2], verbose=True ) print (f'final_chain-->{final_chain} ' )result = final_chain.invoke("王" ) print (f'result-->{result} ' )
运行结果:
思考过程:
最终结果:
4.2 LCEL LCEL(Lang Chain Expression Language) 是一种声明式的方法,用于轻松组合链条。
LCEL的基本语法规则是使用|符号将不同的组件连接起来,形成一个链式结构。|符号类似于Unix的管道操作符,它将一个组件的输出作为下一个组件的输入,从而实现数据的传递和处理。
上一个组件的输出作为下一个组件的输入,输出和输入的类型必须保持一致,否则不能连接。
我们改造一下前面2个chain:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from langchain.chains.llm import LLMChainfrom langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvfrom langchain_core.prompts import PromptTemplateload_dotenv() model = ChatTongyi(model='qwen-max' , temperature=1.5 ) template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字" prompt_template = PromptTemplate(template=template, input_variables=["lastname" ]) chain = prompt_template | model result = chain.invoke(input ={"lastname" : "王" }) print (f'result-->{result} ' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from langchain.chains.llm import LLMChainfrom langchain.chains.sequential import SimpleSequentialChainfrom langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvfrom langchain_core.prompts import PromptTemplateload_dotenv() model = ChatTongyi(model='qwen-max' , temperature=1.5 ) template1 = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字" prompt_template1 = PromptTemplate(template=template1, input_variables=["lastname" ]) template2 = "邻居的儿子名字叫{child_name},给他起一个小名" prompt_template2 = PromptTemplate(template=template2, input_variables=["child_name" ]) final_chain = prompt_template1 | model | prompt_template2 | model result = final_chain.invoke("王" ) print (f'result-->{result} ' )
运行结果:
5 Output parsers【了解】 LLM 的输出是自然语言文本,但在应用开发中,我们经常需要将这些文本转换为结构化的数据格式,如列表、字典或对象。LangChain 输出解析器负责获取 LLM 的输出并将其转换为更合适的格式。
部分解析器如下:
解析器名称
核心功能
输出的 Python 类型
工业级应用场景
StrOutputParser
默认解析器。将 LLM 的输出直接解析为字符串。
str
只需要原始回答时(如问答任务、对话场景)
CommaSeparatedListParser
将 LLM 输出的、用逗号分隔的文本解析为列表。
list[str]
列表/枚举型输出
JsonOutputParser
极其常用。将 LLM 输出的 JSON 字符串解析为 Python 字典。
dict
结构化 JSON 输出
PydanticOutputParser
极其常用。将 LLM 输出解析为预先定义的 Pydantic 对象,提供类型安全和数据验证。
自定义的 pydantic.BaseModel 对象
输出需要严格结构化(JSON-like)数据时
DatetimeOutputParser
从文本中智能地解析出日期和时间信息。
datetime.datetime
需要时间格式时
6 Memory【理解】 大模型本身不具备上下文的概念,它并不保存上次交互的内容,ChatGPT之所以能够和人正常沟通对话,因为它进行了一层封装,将历史记录回传给了模型。
因此 LangChain 也提供了Memory组件, Memory分为两种类型: 短期记忆和长期记忆 。短期记忆一般指单一会话时传递数据,长期记忆则是处理多个会话时获取和更新信息。
方法一:使用 ChatMessageHistory 手动添加上下文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import jsonfrom langchain_community.chat_message_histories import ChatMessageHistoryfrom langchain_core.messages import messages_to_dict, messages_from_dicthistory = ChatMessageHistory() history.add_user_message("你好" ) history.add_ai_message("您好" ) print (f'history-->{history} ' )print (f'history.messages-->{history.messages} ' ) message_dict = json.load(open ('history.json' , 'r' , encoding='utf-8' )) print (f'message_dict-->{message_dict} ' )messages = messages_from_dict(message_dict) print (f'messages-->{messages} ' )
运行结果:
方法二:使用 ConversationChain 自动保存用户和AI的历史交互内容,作为后续回复的上下文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain.chains.conversation.base import ConversationChainfrom langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvload_dotenv() model = ChatTongyi(model='qwen-max' , temperature=1.5 ) conversation = ConversationChain(llm=model) result1 = conversation.predict(input ="小明有1只猫" ) print (f'result1-->{result1} ' )result2 = conversation.predict(input ="小明有2只狗" ) print (f'result2-->{result2} ' )result3 = conversation.predict(input ="小明家一共有几只宠物" ) print (f'result3-->{result3} ' )print ('*' *50 )print (conversation.memory.buffer)
运行结果:
7 Indexes【掌握】 Indexes组件的目的是让LangChain具备处理文档处理的能力,包括:文档加载、检索等。注意,这里的文档不局限于txt、pdf等文本类内容,还涵盖email、区块链、视频等内容。
Indexes组件主要包含类型:
文档加载器
文本分割器
VectorStores
检索器
7.1 文档加载器
https://python.langchain.com/v0.2/docs/introduction/
文档加载器主要基于Unstructured 包,Unstructured 是一个python包,可以把各种类型的文件转换成文本。文档加载器使用起来很简单,只需要引入相应的loader工具。
LangChain支持的文档加载器 (部分):
示例代码:
需要安装的包:
pip install unstructured
pip install langchain-unstructured
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain_unstructured import UnstructuredLoaderloader = UnstructuredLoader('./langchain_data/衣服属性.txt' , encoding='utf-8' ) docs = loader.load() print (f'docs-->{docs} ' )print (f'docs-->{len (docs)} ' )print (f'docs[0].page_content-->{docs[0 ].page_content} ' )print ('*' *80 )from langchain_community.document_loaders import TextLoaderloader = TextLoader('./langchain_data/衣服属性.txt' , encoding='utf-8' ) docs = loader.load() print (f'docs-->{docs} ' )print (f'docs-->{len (docs)} ' )print (docs[0 ].page_content.split("\n" )[0 ])
运行结果:
7.2 文档分割器 由于模型对输入的字符长度有限制,我们在碰到很长的文本时,需要把文本分割成多个小的文本片段。
文本分割最简单的方式是按照字符长度进行分割,但是这会带来很多问题,比如说如果文本是一段代码,一个函数被分割到两段之后就成了没有意义的字符,所以整体的原则是把语义相关的文本片段放在一起。
LangChain中最基本的文本分割器是CharacterTextSplitter ,它按照指定的分隔符(默认“\n\n”)进行分割,并且考虑文本片段的最大长度。我们看个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from langchain_core.documents import Documentfrom langchain_text_splitters import CharacterTextSplittertext_splitter = CharacterTextSplitter(separator=" " , chunk_size=5 , chunk_overlap=2 ) result1 = text_splitter.split_text("a b cd d e f" ) print (f'result1-->{result1} ' )result2 = text_splitter.create_documents(["a b c d e f" , "e f g h" ]) print (f'result2--->{result2} ' )result3 = text_splitter.split_documents([Document(page_content="a b c d e f" , metadata={"id" : "1" })]) print (f'result3--->{result3} ' )
运行结果:
在跑上述代码时,可能会报错,报错如下:
解决方式:
1 2 import nltknltk.download('punkt_tab' )
因为下载速度较慢,所以强烈建议大家,直接将同步文件夹中的nltk_data放到报错提示的Searched in中的任意一个文件夹下。
比如放到 C:\Users\14091 文件夹下。
除了CharacterTextSplitter分割器,LangChain还支持其他文档分割器 (部分):
分割器名称
功能描述
类型
工业场景应用
CharacterTextSplitter
简单按指定分隔符(如换行、逗号)直接分割。
基础字符解析
简单字符串或 CSV 数据处理,如传感器数据日志。
RecursiveCharacterTextSplitter
递归按字符分割,先尝试自然边界(如段落、句子),太大则继续细分。
通用字符解析
通用文本处理,如日志、报告、PDF 文档分割,便于 RAG 检索。
TokenTextSplitter
按 token(词元)分割,支持 LLM token 计数。
Token 基于解析
LLM 输入优化,如处理 API 响应或长查询,控制 token 限制。
SentenceTextSplitter
按句子边界分割,使用 NLP 识别句子(包括标点)。
语义解析
自然语言文本,如文章或对话分析,保持句子完整。
SpacyTextSplitter
使用 SpaCy NLP 库按句子或实体分割(需安装 SpaCy)。
语义解析
高级 NLP 场景,如实体提取或生物医学文本。
NLTKTextSplitter
使用 NLTK 库按句子或词分割(需安装 NLTK)。
语义解析
文本研究或分析,如时间序列数据描述。
MarkdownHeaderTextSplitter
按 Markdown 结构(如标题、列表)智能分割。
结构化解析
Markdown 文档分割,保留语义结构,用于知识库构建。
HTMLSplitter
按 HTML 标签(如 、)分割网页内容。
结构化解析
网页数据爬取,如在线技术文档或新闻提取。
LatexTextSplitter
按 LaTeX 结构(如章节、公式)分割。
结构化解析
学术论文或数学文档处理。
PythonCodeTextSplitter
按 Python 代码结构(如函数、类)分割。
代码解析
源代码文件分析,如脚本调试或代码库管理。
下面就几个重要的分割器进行讲解。
递归字符文本分割器(RecursiveCharacterTextSplitter)
递归字符文本分割器是一种更智能的分割方法,它尝试在特定分隔符处分割文本,以保持更好的语义完整性。 特点:
尝试在自然断点处分割文本
比简单的字符分割更能保持语义完整性
适用于结构化程度较高的文本,如 Markdown、HTML 等
运行流程:
首先尝试使用第一个分隔符(如 “\n\n”)分割文本
如果分割后的块仍然过大,则使用下一个分隔符继续分割
重复此过程,直到达到指定的 chunk_size 或用完所有分隔符
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter( chunk_size=100 , chunk_overlap=20 , length_function=len , separators=["\n\n" , "\n" , " " , "" ] ) text = """ 人工智能正在快速发展,尤其是大语言模型的应用,正在改变人类的工作方式。 它们可以帮助人们进行写作、代码生成、甚至是科研探索。 相比之下,新能源的发展同样重要。 电动车和太阳能正在逐渐替代传统能源,减少碳排放,对全球环境保护至关重要。 """ docs = text_splitter.split_text(text) print (docs)
运行结果
语义文档分割器使用语义理解来分割文本,这是一种更高级的分割方法。 特点:
基于语义相似性分割文本
能够更好地保持语义完整性
计算成本较高,处理大量文本时可能效率较低
适用于需要高度语义理解的场景
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from langchain_experimental.text_splitter import SemanticChunkerfrom langchain_community.embeddings import DashScopeEmbeddingsfrom dotenv import load_dotenvload_dotenv() embed = DashScopeEmbeddings() text_splitter = SemanticChunker( embeddings=embed, breakpoint_threshold_type='percentile' , breakpoint_threshold_amount=70.0 , sentence_split_regex=r'(?<=[。!?.!?])\s*' , min_chunk_size=10 ) text = """ 人工智能正在快速发展,尤其是大语言模型的应用,正在改变人类的工作方式。 它们可以帮助人们进行写作、代码生成、甚至是科研探索。 相比之下,新能源的发展同样重要。 电动车和太阳能正在逐渐替代传统能源,减少碳排放,对全球环境保护至关重要。 """ docs = text_splitter.split_text(text) for i, d in enumerate (docs): print (f"------ Chunk {i+1 } ------" ) print (d.strip()) print ()
运行结果
MarkdownHeaderTextSplitter(Markdown文档切割器)
适用于Markdown文档,按照标题进行拆分
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 >from langchain.text_splitter import MarkdownHeaderTextSplitter >headers_to_split_on = [ >("#" , "Header 1" ), >("##" , "Header 2" ), >("###" , "Header 3" ), >] >markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on) >markdown_text = "# Header 1\nSome text\n## Header 2\nMore text\n### Header 3\nEven more text" >docs = markdown_splitter.split_text(markdown_text) >print (docs)
运行结果
其他拓展知识可以参考:https://blog.csdn.net/qq_28540861/article/details/149161419
7.3 VectorStores VectorStores是一种特殊类型的数据库,它的作用是存储由嵌入创建的向量,提供相似查询等功能。
LangChain支持的VectorStore有https://python.langchain.com/docs/integrations/vectorstores/,常见的如下:
我们使用其中一个Chroma 组件作为例子:
pip install chromadb
pip install langchain-chroma
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from langchain.text_splitter import CharacterTextSplitterfrom langchain_chroma import Chromafrom langchain_community.embeddings import DashScopeEmbeddingsfrom langchain_community.document_loaders import TextLoaderfrom dotenv import load_dotenvload_dotenv() loader = TextLoader('langchain_data/pku.txt' , encoding='utf-8' ) docs = loader.load() text_splitter = CharacterTextSplitter(separator="\n\n" , chunk_size=200 , chunk_overlap=30 ) split_docs = text_splitter.split_documents(docs) print (f'split_docs-->{split_docs} ' )embedding_model = DashScopeEmbeddings() chromadb = Chroma(persist_directory="./chroma_db" , embedding_function=embedding_model) query = "1937年北京大学发生了什么?" result = chromadb.similarity_search(query, k=2 ) print (f'result-->{result} ' )
运行结果:
7.4 检索器 7.4.1 LangChain中的检索器定义 检索器是 LangChain 中负责信息检索的模块,通常与 索引(Indexes) 模块(如向量存储、嵌入模型)结合使用。它的核心功能是:
输入:接收用户查询(通常是文本)。
处理:根据查询从数据源中检索相关内容。
输出:返回一组相关文档或文本片段(通常是 Document 对象列表)。
7.4.2 检索器的工作原理 检索器通常与 向量存储(Vector Stores) 配合,通过嵌入模型(Embedding Models)将查询和文档转为向量,基于相似性进行检索。工作流程可以分为以下步骤:
查询嵌入:将用户查询通过嵌入模型(如 OpenAIEmbeddings)转为向量表示
相似性搜索:在向量存储中查找与查询向量最相似的文档向量。
文档返回:返回匹配的文档(包含内容、元数据等)。
后处理(可选):对检索结果进行排序、过滤或重新排名。
检索器的核心依赖:
嵌入模型:将文本转为向量(如 OpenAIEmbeddings, HuggingFaceEmbeddings)。
向量存储:存储文档向量(如 Chroma、FAISS、Pinecone)。
相似性度量:如余弦相似度、欧几里得距离
7.4.3 检索器类型 langchain支持很多检索器https://python.langchain.com/docs/integrations/retrievers/,部分如下:
此处我们讲解VectorStoreRetriever。
在 LangChain 中,as_retriever() 方法的 search_type 参数决定了向量检索的具体算法和行为。
1 2 3 4 5 6 7 8 9 retriever = vector_store.as_retriever( search_type="similarity" , search_kwargs={ "k" : 5 , "score_threshold" : 0.7 , "filter" : {"source" : "重要文档.pdf" }, "lambda_mult" : 0.25 } )
以下是三种搜索类型的对比:
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain.text_splitter import CharacterTextSplitterfrom langchain_chroma import Chromafrom langchain_community.embeddings import DashScopeEmbeddingsfrom dotenv import load_dotenvload_dotenv() embedding_model = DashScopeEmbeddings() chromadb = Chroma(persist_directory="./chroma_db" , embedding_function=embedding_model) query = "1937年北京大学发生了什么?" retriever = chromadb.as_retriever(search_kwargs={"k" : 3 }) result = retriever.invoke(query) print (f'result-->{result} ' )
运行结果:
拓展:
vectordb.as_retriever() 和 vectordb.similarity_search() 都是用于从向量数据库中检索相关文档的方法,它们有什么异同:
相同
核心功能:两者都基于向量相似度(如余弦相似度)从向量数据库中检索与查询最相关的文档。
底层技术:通常使用相同的嵌入模型和相似度计算方式(如 FAISS、Chroma、Pinecone 等)。
不同
7.4.4 拓展 其他几种常用的检索器介绍如下。
功能:基于 TF-IDF(词频-逆文档频率)的检索器。
特点:
使用 TF-IDF 向量表示文档和查询。
适合快速构建原型。
不支持语义搜索。
适用场景:
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_community.retrievers import TFIDFRetrieverfrom langchain_core.documents import Documentdocs = [ Document(page_content="量子计算是一种基于量子力学的计算范式。" ), Document(page_content="人工智能是模拟人类智能的技术。" ) ] retriever = TFIDFRetriever.from_documents(docs) retriever.k = 1 results = retriever.invoke("量子计算" ) print (results)
运行结果:
BM25算法:BM25 是对 TF-IDF 的改进版本,在 TF-IDF 基础上做了归一化(防止长文档优势)与饱和控制(防止词频无限增长)。
功能:基于 BM25 算法的关键词检索器,适合基于词频的搜索。
特点:
不依赖嵌入模型,使用词频和逆文档频率(TF-IDF)计算相关性。
适合关键词匹配场景,计算成本低。
不支持语义搜索,效果依赖文本的字面匹配。
适用场景:
环境依赖:
pip install rank_bm25
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_community.retrievers import BM25Retrieverfrom langchain_core.documents import Documentdocs = [ Document(page_content="量子计算是一种基于量子力学的计算范式。" ), Document(page_content="人工智能是模拟人类智能的技术。" ) ] retriever = BM25Retriever.from_documents(docs) retriever.k = 1 results = retriever.invoke("量子计算" ) print (results)
运行结果:
功能:它借助 LLM 自动生成多个语义等价的改写查询,把用户的问题扩展成多个角度,然后对每个改写进行检索,最后合并结果,以提高召回率。
特点:
使用语言模型生成查询的多种表达方式
从向量存储中检索所有变体的结果并合并
提高召回率,适合复杂查询
适用场景:
查询表达不明确或需要覆盖多种语义
提高检索的全面性
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain.retrievers.multi_query import MultiQueryRetrieverfrom langchain_community.chat_models.tongyi import ChatTongyifrom langchain_community.embeddings import DashScopeEmbeddingsfrom langchain_core.documents import Documentfrom langchain_chroma import Chromafrom dotenv import load_dotenvload_dotenv() docs = [ Document(page_content="量子计算基于量子力学。" ), Document(page_content="人工智能模拟人类智能。" ) ] embeddings = DashScopeEmbeddings() vectorstore = Chroma.from_documents(docs, embeddings) llm = ChatTongyi() retriever = MultiQueryRetriever.from_llm( retriever=vectorstore.as_retriever(), llm=llm ) results = retriever.invoke("量子计算是什么?" ) print (results)
运行结果:
功能:结合多种检索器(如 BM25 和向量存储),融合结果。
特点:
结合关键词搜索和语义搜索的优点
支持加权融合,调整不同检索器的权重
提高召回率和精准度
适用场景:
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from langchain_community.embeddings import DashScopeEmbeddingsfrom langchain.retrievers import EnsembleRetrieverfrom langchain_community.retrievers import BM25Retrieverfrom langchain_core.documents import Documentfrom langchain_chroma import Chromafrom dotenv import load_dotenvload_dotenv() docs = [ Document(page_content="量子计算基于量子力学。" ), Document(page_content="人工智能模拟人类智能。" ) ] bm25_retriever = BM25Retriever.from_documents(docs) bm25_retriever.k = 1 embeddings = DashScopeEmbeddings() vectorstore = Chroma.from_documents(docs, embeddings) vector_retriever = vectorstore.as_retriever(search_kwargs={"k" : 1 }) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, vector_retriever], weights=[0.5 , 0.5 ] ) results = ensemble_retriever.invoke("量子计算" ) print (results)
运行结果:
ContextualCompressionRetriever
功能:对检索结果进行压缩,提取最相关的内容
特点:
使用语言模型对检索到的文档进行重新排序或精炼
减少无关内容,提高结果质量
增加计算开销,但提升精准度
适用场景:
文档内容冗长,需要提取关键信息
提高问答系统的答案质量
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 >from langchain.retrievers import ContextualCompressionRetriever >from langchain.retrievers.document_compressors import LLMChainExtractor >from langchain_community.chat_models.tongyi import ChatTongyi >from langchain_community.embeddings import DashScopeEmbeddings >from langchain_core.documents import Document >from langchain_chroma import Chroma >from dotenv import load_dotenv >load_dotenv() > >docs = [ Document(page_content="""量子计算是一种基于量子力学的计算范式。 >它利用量子比特(qubit)进行运算,能够表示叠加态和纠缠态。 >这种计算方式在某些特定问题上(比如大数分解、搜索问题)可能远远快于经典计算机。 >量子计算机的核心是量子比特和量子门操作,它们共同决定了计算的能力。 >除此之外,量子计算的研究还涉及量子误差纠正、量子通信、量子算法的设计等多个方向。""" ), Document(page_content="""人工智能是一门研究如何使机器表现出类似人类智能的学科。 >它的主要技术包括机器学习、深度学习、自然语言处理、计算机视觉等。 >人工智能的应用非常广泛,比如自动驾驶、智能推荐、医疗辅助诊断等。 >在哲学上,人们也讨论人工智能是否可能拥有意识和思维。""" )>] > >embeddings = DashScopeEmbeddings() >vectorstore = Chroma.from_documents(docs, embeddings) > >llm = ChatTongyi(model="qwen-max" ) > >compressor = LLMChainExtractor.from_llm(llm) > >retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=vectorstore.as_retriever() >) > >results = retriever.invoke("量子计算的核心组成部分是什么?" ) >print ("---- 原始检索结果 ----" ) >raw_results = vectorstore.as_retriever().invoke("量子计算的核心组成部分是什么?" ) >for r in raw_results: print (r.page_content) >print ("\n---- 压缩后的结果 ----" ) >for r in results: print (r.page_content)
运行结果:
功能:开发者可以自定义检索逻辑,适配特定数据源或算法
特点:
继承 BaseRetriever 类,实现 get_relevant_documents 方法
支持任意数据源(如数据库、API)
适用场景:
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain_core.retrievers import BaseRetrieverfrom langchain_core.documents import Documentclass CustomRetriever (BaseRetriever ): def _get_relevant_documents (self, query: str , **kwargs ): return [Document(page_content=f"自定义结果 for {query} " )] retriever = CustomRetriever() results = retriever.invoke("量子计算" ) print (results)
运行结果:
8 Agents【理解】 8.1 Agent 概念 Agent(智能体)是一种能够感知环境、进行决策和执行动作的智能实体。不同于传统的人工智能,Agent 具备通过主动思考、调用工具去逐步完成给定目标的能力。
从大模型的角度来看,Agent其实就是基于大模型的语义理解和推理能力,让大模型拥有解决复杂问题时的任务规划能力,并调用外部工具来执行各种任务,并且能够保留“记忆”的一个智能体 。
Agent = 大模型 + 任务规划(Planning) + 使用外部工具执行任务(Tools&Action) + 记忆(Memory)
工作流程概述:
用户提出任务。
Agent 启动: 将用户输入与预设的“提示词模板”结合,并结合当前的“上下文”和“变量”,形成一个完整的输入发送给大模型。
大模型思考与决策 (循环):
大模型接收输入后,根据其内置的逻辑和提示词的指导,进行“思考”。
它会判断完成当前任务是需要继续使用工具来获取更多信息/执行操作,还是已经可以直接生成最终答案。
如果需要工具: 大模型会根据任务需求和对工具的描述,选择合适的工具,并生成执行该工具所需的输入参数。这些参数通常会从上下文或变量中提取。
工具执行: 选定的工具被调用,执行其功能。
结果反馈: 工具执行的结果会返回给 Agent,并被用来更新“上下文”和“变量”。
循环: Agent 将更新后的“上下文”、“变量”以及工具执行结果再次反馈给大模型,大模型继续进行新一轮的“思考-行动”循环,直到任务完成。
如果直接回答: 当大模型判断任务已完成,或无需额外工具即可回答时,它会生成最终的答案。
用户输出: 最终答案被呈现给用户。
8.2 Agent关键组成部分
8.3 langchain实现Agent LangChain 提供了不同类型的代理(主要罗列一下三种):
Zero-shot ReAct Description
Structured Chat Zero-shot ReAct Description
Conversational ReAct Description
在 ReAct 框架基础上,增强了 对话记忆能力 。
特点:能根据上下文对话历史来做出工具选择和回应,更适合持续性对话场景。
使用场景:多轮对话,用户可能引用之前的内容或需要长期上下文跟踪。
LangChain 中集成了很多工具,可以通过下面的方式进行查询:
1 2 3 from langchain_community.agent_toolkits.load_tools import get_all_tool_namesresults = get_all_tool_names() print (results)
运行结果:
1 ['sleep', 'wolfram-alpha', 'google-search', 'google-search-results-json', 'searx-search-results-json', 'bing-search', 'metaphor-search', 'ddg-search', 'google-books', 'google-lens', 'google-serper', 'google-scholar', 'google-finance', 'google-trends', 'google-jobs', 'google-serper-results-json', 'searchapi', 'searchapi-results-json', 'serpapi', 'dalle-image-generator', 'twilio', 'searx-search', 'merriam-webster', 'wikipedia', 'arxiv', 'golden-query', 'pubmed', 'human', 'awslambda', 'stackexchange', 'sceneXplain', 'graphql', 'openweathermap-api', 'dataforseo-api-search', 'dataforseo-api-search-json', 'eleven_labs_text2speech', 'google_cloud_texttospeech', 'read_file', 'reddit_search', 'news-api', 'tmdb-api', 'podcast-api', 'memorize', 'llm-math', 'open-meteo-api', 'requests', 'requests_get', 'requests_post', 'requests_patch', 'requests_put', 'requests_delete', 'terminal']
接下来,通过一个示例来学习Agent的基本使用。
问题1:计算一下300的25%是多少?
问题2:请帮我介绍一下故宫
示例代码:
需要提前安装 wikipedia
pip install wikipedia
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from langchain.agents import initialize_agent, AgentTypefrom langchain_community.agent_toolkits.load_tools import load_tools, get_all_tool_namesfrom langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvtool_names = get_all_tool_names() print (f'tool_names-->{tool_names} ' )load_dotenv() model = ChatTongyi(model='qwen-max' ) tools = load_tools(['wikipedia' , 'llm-math' ], llm=model) agent = initialize_agent(tools, model, AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True ) prompt = "请帮我介绍一下故宫" result = agent.invoke(prompt) print (f'result--->{result} ' )
运行结果:
8.4 langchain自定义工具
参考官网 https://python.langchain.com/docs/how_to/custom_tools/
自定义工具除了调用的实际函数外,还需要几个组件:
name (str)是必需的,并且在提供给代理的一组工具中必须是唯一的description (str)是可选的,但建议使用,因为代理使用它来确定工具的使用情况return_direct (bool), 默认关闭,打开时tool会返回执行结果args_schema (Pydantic BaseModel), 可选,但推荐使用,可用于提供更多信息(例如,少量示例)或验证预期参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from langchain_community.agent_toolkits.load_tools import load_toolsfrom langchain.agents import initialize_agentfrom langchain.agents import AgentTypefrom langchain.agents import toolfrom langchain_community.chat_models.tongyi import ChatTongyifrom dotenv import load_dotenvfrom datetime import dateload_dotenv() llm = ChatTongyi(model='qwen-max' ) @tool def time (text: str ) -> str : """返回今天的日期。用于任何与获取今天日期相关的问题。 该函数的输入应始终为空字符串,且它始终返回今天的日期。 任何与日期相关的计算应在此函数之外完成。 """ return str (date.today()) tools = load_tools(["llm-math" , "wikipedia" ], llm=llm) agent = initialize_agent(tools+[time], llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True ) prompt = "今天是什么日期?" result = agent.invoke(prompt) print (result['output' ])
运行结果:
9 LangChain使用场景【理解】
个人助手
基于文档的问答系统
聊天机器人
Tabular数据查询
API交互
信息提取
文档总结
Milvus向量数据库 1 什么是 Milvus 向量数据库?【理解】 Milvus 是一款开源的向量数据库(2019年提出),其唯一目标是存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。
两大作用:存储、检索
2 关键概念【理解】 2.1 非结构化数据 非结构化数据包括图像、视频、音频和自然语言等信息,这些信息不遵循预定义的模型或组织方式,占据了世界数据的约 80%。非结构化数据可以通过各种模型转化为向量数据后进行处理。
2.2 嵌入向量 嵌入向量是对非结构化数据(如电子邮件、物联网传感器数据、Instagram 照片、蛋白质结构等)的特征抽象。数学上,嵌入向量是一个浮点数或二进制数的数组。
通过现代的向量转化技术,比如各种机器学习模型或者深度学习模型,可以将非结构化数据抽象为 n 维特征向量空间的向量。
2.3 向量相似度搜索 向量相似度搜索是将向量与数据库进行比较,以找到与查询向量最相似的向量的过程。近似最近邻搜索(ANN)算法能够计算向量之间的距离,从而提升向量相似度检索的速度。如果两条向量十分相似,这就意味着它们所代表的源数据也十分相似。
2.4 Collection 和 Field 与传统数据库引擎类似,用户也可以在 Milvus 中创建数据库,并为某些用户分配权限来管理它们。一个 Milvus 集群最多支持 64 个数据库。
在Milvus数据库中,有Collection和Field的概念,可以和关系数据库中表和字段进行对应:
Milvus
关系数据库
描述
Collection
表
集合相当于关系数据库中的表,用于组织数据
Field
字段
字段Schema相当于表中的列
Entity
行
实体就是一条完整的数据记录,包含一个或多个字段
Index
索引
从原始数据衍生出来的重组数据结构,可以大大加快向量相似性搜索的过程
Partition
分区
在物理存储上将 Collections 数据分成多个部分,即分区
注意:1个collection最多支持4个向量Field
3 为什么选择 Milvus?【掌握】
高性能:性能卓越,可对海量数据集进行向量相似度检索。
高可用、高可靠:Milvus 支持在云上扩展,其容灾能力能够保证服务高可用。
混合查询:Milvus 支持在向量相似度检索过程中进行标量字段过滤,实现混合查询。
开发者友好:支持多语言、多工具的 Milvus 生态系统。
4 支持哪些索引和度量?【理解】 索引是数据的组织单位。在搜索或查询插入的实体之前,必须声明索引类型和相似度度量。如果您未指定索引类型,则 Milvus 将默认使用暴力搜索。
4.1 索引类型
特性/索引类型
FLAT (Flat)
IVF_FLAT
IVF_SQ8
IVF_PQ
HNSW
全称 平面扫描
倒排文件 - 平面
倒排文件 - 标量量化8位
倒排文件 - 乘积量化
层级可导航小世界图
核心原理 暴力计算所有向量与查询向量的距离
先聚类划分簇,再在目标簇内暴力搜索
类似 IVF_FLAT,但向量被压缩存储(8位整数)
将向量空间划分为子空间并分别量化编码
构建多层导航图进行快速近邻搜索
精度 (Recall) 最高 (100%,精确搜索)高
中高
中
非常高
查询速度 最慢 (O(n))快
较快
最快 非常快
内存使用 高 (存储原始浮点向量)
高 (存储原始向量)
中等 (量化后节省空间)
最低 (高度压缩)高 (存储原始向量和图结构)
构建时间 无 (无需构建)
中等
中等
较快
较长
是否支持动态数据 是
是
是
是
是
适用场景 数据量小 (< 百万),要求绝对精确
数据量中等,追求高召回率
数据量大,平衡速度、精度和内存
超大规模数据,极致追求查询速度和低内存
数据量大,要求高精度和较快查询,支持动态增删
主要优势 精确、简单、无需训练
高召回、实现成熟
内存占用适中,性能良好
查询极快,内存占用极低
支持动态数据,精度高,查询快
主要劣势 速度慢,不适用于大数据
内存占用高,构建需聚类
精度因量化略有损失
精度损失相对较大,配置复杂
构建时间较长,内存占用高
使用建议
追求绝对精度且数据量小: 选择 FLAT。
通用场景,平衡各方面: IVF_SQ8 或 HNSW 是很好的选择。HNSW 在支持动态更新方面更具优势。
超大规模数据,追求极致性能: 优先考虑 IVF_PQ。
数据频繁增删改: 选择 HNSW (Milvus 推荐用于动态数据)。
4.2 相似度度量 对于浮点向量,通常使用以下指标:
L2(欧几里得距离):计算向量间的直线距离,值越小越相似,常用于图像处理等领域。
IP(内积):计算两个向量的点积,值越大越相似。当向量经过归一化时,其结果等价于余弦相似度,常用于NLP文本向量搜索。
COSINE(余弦相似度):衡量两个向量方向的夹角余弦值,值越大(越接近1)表示方向越一致,对向量的幅度不敏感,非常适合文本和语义相似性搜索。
对于稀疏向量,通常使用以下指标:
IP(内积):主要用于衡量稀疏向量的相似性。
BM25:一种常用于信息检索的评分函数,也支持用于稀疏向量的搜索。
5 Milvus数据库操作【熟悉】 开始之前,请确保本地环境中有 Python 3.8+ 可用。安装pymilvus ,其中包含 python 客户端库和 Milvus Lite:
在操作Milvus数据库之前,需要先启动服务。
可视化页面:
http://127.0.0.1:30000
查询ip的命令:
5.1 设置向量数据库 连接Milvus向量数据库,并创建一个名称为milvus_demo的数据库。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from pymilvus import MilvusClient, DataType, RRFRanker, AnnSearchRequestdef operate_db (): client = MilvusClient(host='127.0.0.1' , port=19530 ) databases = client.list_databases() print (f'Databases-->{databases} ' ) if 'milvus_demo' not in databases: client.create_database('milvus_demo' ) client.using_database('milvus_demo' ) return client
5.2 Collections操作 在 Milvus 中,我们需要一个 Collections 来存储向量及其相关元数据。你可以把它想象成传统 SQL 数据库中的表格。创建 Collections 时,可以定义 Schema 和索引参数来配置向量规格,如维度、索引类型和远距离度量。此外,还有一些复杂的概念来优化索引以提高向量搜索性能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def operate_table (client ): schema = client.create_schema(auto_id=False , enable_dynamic_field=True ) schema.add_field(field_name='id' , datatype=DataType.INT64, is_primary=True , description="主键" ) schema.add_field(field_name='vector' , datatype=DataType.FLOAT_VECTOR, dim=8 , description="向量字段" ) schema.add_field(field_name='scalar' , datatype=DataType.VARCHAR, max_length=256 , description="标量字段" ) client.create_collection(collection_name='demo_v1' , schema=schema) index_params = client.prepare_index_params() index_params.add_index(field_name='vector' , index_type='IVF_FLAT' , metric_type='COSINE' , index_name='vector_index' , nlist=1024 ) index_params.add_index(field_name='scalar' , index_type='' , index_name='scalar_index' ) client.create_index(collection_name='demo_v1' , index_params=index_params) res = client.list_indexes(collection_name='demo_v1' ) print (f'索引信息-->{res} ' ) res = client.describe_index(collection_name='demo_v1' , index_name='vector_index' ) print (f'指定索引详细信息-->{res} ' ) print (client.get_load_state(collection_name='demo_v1' )) client.load_collection(collection_name='demo_v1' ) print (client.get_load_state(collection_name='demo_v1' )) client.release_collection(collection_name='demo_v1' ) client.drop_index(collection_name='demo_v1' , index_name='vector_index' )
5.3 Entity实体数据操作 在 Milvus 中,实体 指的是Collections 中共享相同Schema 的数据记录,行中每个字段的数据构成一个实体。因此,同一 Collections 中的实体具有相同的属性(如字段名称、数据类型和其他约束)。
5.3.1 数据的增、删、改 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 def operate_entity (client ): client.create_collection(collection_name='demo_v2' , dimension=5 , metric_type='IP' ) data = [ {"id" : 0 , "vector" : [0.3580376395471989 , -0.6023495712049978 , 0.18414012509913835 , -0.26286205330961354 , 0.9029438446296592 ], "color" : "pink_8682" }, {"id" : 1 , "vector" : [0.19886812562848388 , 0.06023560599112088 , 0.6976963061752597 , 0.2614474506242501 , 0.838729485096104 ], "color" : "red_7025" }, {"id" : 2 , "vector" : [0.43742130801983836 , -0.5597502546264526 , 0.6457887650909682 , 0.7894058910881185 , 0.20785793220625592 ], "color" : "orange_6781" }, {"id" : 3 , "vector" : [0.3172005263489739 , 0.9719044792798428 , -0.36981146090600725 , -0.4860894583077995 , 0.95791889146345 ], "color" : "pink_9298" }, {"id" : 4 , "vector" : [0.4452349528804562 , -0.8757026943054742 , 0.8220779437047674 , 0.46406290649483184 , 0.30337481143159106 ], "color" : "red_4794" }, {"id" : 5 , "vector" : [0.985825131989184 , -0.8144651566660419 , 0.6299267002202009 , 0.1206906911183383 , -0.1446277761879955 ], "color" : "yellow_4222" }, {"id" : 6 , "vector" : [0.8371977790571115 , -0.015764369584852833 , -0.31062937026679327 , -0.562666951622192 , -0.8984947637863987 ], "color" : "red_9392" }, {"id" : 7 , "vector" : [-0.33445148015177995 , -0.2567135004164067 , 0.8987539745369246 , 0.9402995886420709 , 0.5378064918413052 ], "color" : "grey_8510" }, {"id" : 8 , "vector" : [0.39524717779832685 , 0.4000257286739164 , -0.5890507376891594 , -0.8650502298996872 , -0.6140360785406336 ], "color" : "white_9381" }, {"id" : 9 , "vector" : [0.5718280481994695 , 0.24070317428066512 , -0.3737913482606834 , -0.06726932177492717 , -0.6980531615588608 ], "color" : "purple_4976" } ] result1 = client.insert(collection_name='demo_v2' , data=data) print (f'插入数据结果-->{result1} ' ) data = [ {"id" : 0 , "vector" : [-0.619954382375778 , 0.4479436794798608 , -0.17493894838751745 , -0.4248030059917294 , -0.8648452746018911 ], "color" : "black_9898" }, {"id" : 1 , "vector" : [0.4762662251462588 , -0.6942502138717026 , -0.4490002642657902 , -0.628696575798281 , 0.9660395877041965 ], "color" : "red_7319" }, {"id" : 2 , "vector" : [-0.8864122635045097 , 0.9260170474445351 , 0.801326976181461 , 0.6383943392381306 , 0.7563037341572827 ], "color" : "white_6465" }, {"id" : 3 , "vector" : [0.14594326235891586 , -0.3775407299900644 , -0.3765479013078812 , 0.20612075380355122 , 0.4902678929632145 ], "color" : "orange_7580" }, {"id" : 4 , "vector" : [0.4548498669607359 , -0.887610217681605 , 0.5655081329910452 , 0.19220509387904117 , 0.016513983433433577 ], "color" : "red_3314" }, {"id" : 5 , "vector" : [0.11755001847051827 , -0.7295149788999611 , 0.2608115847524266 , -0.1719167007897875 , 0.7417611743754855 ], "color" : "black_9955" }, {"id" : 6 , "vector" : [0.9363032158314308 , 0.030699901477745373 , 0.8365910312319647 , 0.7823840208444011 , 0.2625222076909237 ], "color" : "yellow_2461" }, {"id" : 7 , "vector" : [0.0754823906014721 , -0.6390658668265143 , 0.5610517334334937 , -0.8986261118798251 , 0.9372056764266794 ], "color" : "white_5015" }, {"id" : 8 , "vector" : [-0.3038434006935904 , 0.1279149203380523 , 0.503958664270957 , -0.2622661156746988 , 0.7407627307791929 ], "color" : "purple_6414" }, {"id" : 9 , "vector" : [-0.7125086947677588 , -0.8050968321012257 , -0.32608864121785786 , 0.3255654958645424 , 0.26227968923834233 ], "color" : "brown_7231" } ] result3 = client.upsert(collection_name='demo_v2' , data=data) print (f'更新数据结果-->{result3} ' ) result4 = client.delete(collection_name='demo_v2' , filter ="id in [0, 1, 2, 3]" ) print (f'删除数据结果-->{result4} ' )
5.3.2 数据的查询 简单查询:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 def query_operation (client ): res = client.search(collection_name='demo_v2' , data=[[0.19886812562848388 , 0.06023560599112088 , 0.6976963061752597 , 0.2614474506242501 , 0.838729485096104 ]], limit=2 , search_params={"metric_type" : "IP" }, output_fields=["id" , 'vector' ]) print (res) res = client.search(collection_name='demo_v2' , data=[[0.19886812562848388 , 0.06023560599112088 , 0.6976963061752597 , 0.2614474506242501 , 0.838729485096104 ], [0.3172005263489739 , 0.9719044792798428 , -0.36981146090600725 , -0.4860894583077995 , 0.95791889146345 ]], limit=2 , search_params={"metric_type" : "IP" }, output_fields=["id" , 'vector' ]) print (res) res = client.search(collection_name='demo_v2' , data=[[0.19886812562848388 , 0.06023560599112088 , 0.6976963061752597 , 0.2614474506242501 , 0.838729485096104 ]], limit=2 , search_params={"metric_type" : "IP" }, output_fields=["id" , 'vector' ], partition_names=['partition1' ]) print (res) res = client.search(collection_name='demo_v2' , data=[[0.19886812562848388 , 0.06023560599112088 , 0.6976963061752597 , 0.2614474506242501 , 0.838729485096104 ]], limit=2 , search_params={"metric_type" : "IP" }, output_fields=["id" , 'vector' ], filter ="color like 'red%'" ) print (res) res = client.search(collection_name='demo_v2' , data=[[0.19886812562848388 , 0.06023560599112088 , 0.6976963061752597 , 0.2614474506242501 , 0.838729485096104 ]], limit=2 , search_params={"metric_type" : "IP" , "params" :{"radius" : 0.8 , "range_filter" : 1 }}, output_fields=["id" , 'vector' ]) print (res)
复杂查询:
混合检索 :要对两组 ANN 搜索结果进行合并和重新排序,有必要选择适当的重新排序策略。支持两种重排策略:加权排名策略(WeightedRanker )和重排序 策略(RRFRanker )。在选择重排策略时,需要考虑的一个问题是,在向量场中是否需要强调一个或多个基本 ANN 搜索。
加权排名 :如果用户要求结果强调特定的向量场,建议使用该策略。通过 WeightedRanker,用户可以为某些向量场分配更高的权重,从而更加强调这些向量场。例如,在多模态搜索中,图片的文字描述可能比图片的颜色更重要。
使用 WeightedRanker 策略时,需要在WeightedRanker 函数中输入权重值。混合搜索中的基本 ANN 搜索次数与需要输入的值的次数相对应。输入值的范围应为 [0,1],数值越接近 1 表示重要性越高。
1 2 from pymilvus import WeightedRankerrerank= WeightedRanker(0.8 , 0.3 )
RRFRanker(倒数排序融合) :在没有特定重点的情况下,建议采用这种策略。RRF 可以有效平衡每个向量场的重要性
RRFRanker的核心思想是根据每个结果在其检索列表中的排名位置来计算分数。具体而言,算法使用以下公式为每个结果分配分数:
1 2 3 from pymilvus import RRFRankerranker = RRFRanker(100 )
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 def complex_query (client ): schema = client.create_schema(enable_dynamic_field=False ) schema.add_field(field_name='film_id' , datatype=DataType.INT64, is_primary=True ) schema.add_field(field_name='filmVector' , datatype=DataType.FLOAT_VECTOR, dim=5 ) schema.add_field(field_name='posterVector' , datatype=DataType.FLOAT_VECTOR, dim=5 ) index_params = client.prepare_index_params() index_params.add_index(field_name='filmVector' , index_type="IVF_FLAT" , metric_type="L2" , params={"nlist" : 128 }) index_params.add_index(field_name='posterVector' , index_type="" , metric_type="COSINE" ) client.create_collection(collection_name='demo_v3' , schema=schema, index_params=index_params) entities = [] for _ in range (1000 ): film_id = random.randint(1 , 10000 ) film_vector = [random.random() for _ in range (5 )] poster_vector = [random.random() for _ in range (5 )] entities.append({"film_id" : film_id, "filmVector" : film_vector, "posterVector" : poster_vector}) client.insert(collection_name='demo_v3' , data=entities) query_filmVector = [[0.8896863042430693 , 0.370613100114602 , 0.23779315077113428 , 0.38227915951132996 , 0.5997064603128835 ]] dense_search_params = { "data" : query_filmVector, "anns_field" : "filmVector" , "param" : {"metric_type" : "L2" , "nprobe" : 10 }, "limit" : 2 } request_1 = AnnSearchRequest(**dense_search_params) print (f'Request 1-->{request_1} ' ) query_posterVector = [[0.02550758562349764 , 0.006085637357292062 , 0.5325251250159071 , 0.7676432650114147 , 0.5521074424751443 ]] sparse_search_params = { "data" : query_posterVector, "anns_field" : "posterVector" , "param" : {"metric_type" : "COSINE" }, "limit" : 2 } request_2 = AnnSearchRequest(**sparse_search_params) print (f'Request 2-->{request_2} ' ) rerank = WeightedRanker(0.8 , 0.3 ) final_result = client.hybrid_search(collection_name='demo_v3' , reqs=[request_1, request_2], ranker=rerank, output_fields=["film_id" , "filmVector" , "posterVector" ], limit=2 ) print (f'final_result-->{final_result} ' ) ranker = RRFRanker(k=100 ) final_result = client.hybrid_search(collection_name='demo_v3' , reqs=[request_1, request_2], ranker=ranker, output_fields=["film_id" , "filmVector" , "posterVector" ], limit=2 ) print (f'final_result-->{final_result} ' )
5.4 删除 Collections 如果想删除某个 Collections 中的所有数据,可以通过以下方法丢弃该 Collections
1 2 client.drop_collection(collection_name="demo_collection" )
一、Python日志介绍与应用 1 日志记录概述【掌握】 日志(Logging)是程序运行时记录关键信息的一种方式,例如操作成功、错误发生或调试信息。它在开发和维护中非常重要,因为:
调试 :帮助找到代码中的问题。监控 :记录程序的运行状态。审计 :追踪用户或系统的行为。
Python的logging模块是一个内置工具,提供灵活的日志记录功能,比简单的print语句更强大。
核心概念:
(1)日志级别 :表示日志的重要性,常见级别从低到高:
DEBUG:调试信息(最低)。INFO:一般信息。WARNING:警告,可能有问题。ERROR:错误,已影响程序。CRITICAL:严重错误(最高)。
(2)日志处理器(Handler) :决定日志输出到哪里(如控制台或文件)。
(3)日志格式(Formatter) :定义日志的显示样式(如时间、级别、消息)。
2 示例1:基础日志记录【实现】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import logginglogging.basicConfig(level=logging.WARNING) logger = logging.getLogger("Example1" ) logger.debug("这是调试信息,通常用于开发" ) logger.info("程序运行正常" ) logger.warning("注意,可能有小问题" ) logger.error("发生错误" ) logger.critical("严重错误,程序可能崩溃" )
3 示例2:自定义日志格式【实现】 1 2 3 4 5 6 7 8 9 10 11 12 logging.basicConfig( level=logging.DEBUG, format ='%(name)s - %(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger("Example2" ) logger.debug("调试模式已开启" ) logger.info("正在处理数据" ) logger.error("数据处理失败" )
常见的 format 占位符说明表:
占位符
含义
示例
%(asctime)s日志事件发生的时间(格式默认为 YYYY-MM-DD HH:MM:SS,mmm)
2025-10-11 11:12:23,456
%(levelname)s日志级别名称
DEBUG、INFO、WARNING、ERROR、CRITICAL
%(message)s实际的日志消息内容
This is a log message
%(name)s日志记录器的名称(logger 名称)
root 或自定义名称
%(filename)s当前执行的文件名(不含路径)
main.py
%(pathname)s当前执行的文件完整路径
/home/user/project/main.py
%(lineno)d日志语句所在的行号
42
%(funcName)s调用日志的函数名
process_data
%(module)s模块名(去掉 .py 的文件名)
main
%(thread)d线程 ID(整数)
139635528570624
%(threadName)s线程名称
MainThread
%(process)d进程 ID
12345
%(processName)s进程名称
MainProcess
%(levelno)s日志级别的数字值(DEBUG=10, INFO=20, 等)
10
4 示例3:将日志存储到文件【实现】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import logginglogging.basicConfig( level=logging.DEBUG, format ='%(name)s - %(asctime)s - %(levelname)s - %(message)s' , filename='C03_base_use.log' , filemode='w' , encoding='utf-8' ) logger = logging.getLogger("Example3" ) logger.debug("调试模式已开启" ) logger.info("正在处理数据" ) logger.error("数据处理失败" )
5 示例4:同时输出到控制台和文件【实现】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import logginglogger = logging.getLogger("Example4" ) logger.setLevel(logging.DEBUG) formatter = logging.Formatter('%(name)s - %(asctime)s - %(levelname)s - %(message)s' ) console_handler = logging.StreamHandler() console_handler.setFormatter(formatter) console_handler.setLevel(logging.WARNING) file_handler = logging.FileHandler(filename="C04_base_use.log" , encoding="utf-8" , mode="a" ) file_handler.setFormatter(formatter) file_handler.setLevel(logging.INFO) logger.addHandler(console_handler) logger.addHandler(file_handler) logger.debug("调试模式已开启" ) logger.info("正在处理数据" ) logger.error("数据处理失败" )
6 代码实现【理解】 6.1 整体结构 1 2 3 4 5 6 logging_lesson/ ├── logs/ │ └── app.log # 日志文件 ├── utils/ │ └── logger.py # 日志配置模块 ├── main.py # 主程序入口
6.2 日志配置模块 位置:logging_lesson/utils/logger.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import loggingimport osdef setup_logger (name, log_file='logs/app.log' ): os.makedirs(os.path.dirname(log_file), exist_ok=True ) logger = logging.getLogger(name) logger.setLevel(logging.DEBUG) formatter = logging.Formatter('%(name)s - %(asctime)s - %(levelname)s - %(message)s' ) console_handler = logging.StreamHandler() console_handler.setFormatter(formatter) console_handler.setLevel(logging.INFO) file_handler = logging.FileHandler(filename=log_file, encoding="utf-8" , mode="a" ) file_handler.setFormatter(formatter) file_handler.setLevel(logging.DEBUG) if not logger.handlers: logger.addHandler(console_handler) logger.addHandler(file_handler) return logger if __name__ ` '__main__' : setup_logger('demo' , r'D:\workspace\python\llm_sy1\P02_tools\logging_lesson\logs\app.log' )
6.2 主程序 位置:logging_lesson/main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from P02_tools.logging_lesson.utils.logger import setup_loggerlogger = setup_logger('MainApp' , r'D:\workspace\python\llm_sy1\P02_tools\logging_lesson\logs\app.log' ) def process_data (data ): logger.debug(f"开始处理数据: {data} " ) if not data: logger.error("数据为空,无法处理" ) return None logger.info("数据处理完成" ) return data.upper() def main (): logger.info("程序启动" ) result = process_data("hello" ) if result: logger.info(f"处理结果: {result} " ) else : logger.warning("处理失败" ) logger.info("程序结束" ) if __name__ ` "__main__" : main()
二、BM25算法简介与应用 1 BM25算法概述【掌握】 BM25(Best Matching 25)是一种信息检索领域的排名算法,用于计算查询(Query)与文档(Document)之间的相关性得分。它改进了传统的TF-IDF算法,使检索结果更准确。
2 简单示例【理解】 假设我们有以下文档集合:
需要查询 “他喜欢编程” 最相关的文档
步骤 :
分词:将文档和查询拆分为词。
文档1:[“我”, “喜欢”, “编程”]
文档2:[“编程”, “很”, “有趣”]
查询:[“他”, “喜欢”, “编程”]
计算BM25得分:使用rank_bm25库计算每个文档与查询的相关性。
3 代码实现【掌握】 3.1 整体结构 1 2 3 4 bm25_lesson/ ├── retrieval/ │ └── bm25_search.py # BM25检索模块 ├── main.py # 主程序入口
3.2 检索模块 位置:bm25_lesson/retrieval/bm25_search.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import jiebafrom rank_bm25 import BM25Limport logginglogging.basicConfig( level=logging.DEBUG, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) class BM25Search (object ): def __init__ (self, docs ): self.docs = docs self.tokenized_docs = [jieba.lcut(doc) for doc in self.docs] self.bm25 = BM25L(self.tokenized_docs) logger.info(f'BM25模型对象创建成功' ) def search (self, query ): tokenized_query = jieba.lcut(query) scores = self.bm25.get_scores(tokenized_query) best_index = scores.argmax() best_score = scores[best_index] best_doc = self.docs[best_index] logger.info(f'查询语句:{query} ,最匹配的文档:{best_doc} ,BM25得分:{best_score} ' ) return best_doc, best_score if __name__ ` '__main__' : documents = ["我喜欢编程" , "编程很有趣" ] obj = BM25Search(documents) query = "他喜欢编程" best_doc, best_score = obj.search(query)
拓展:
模型
核心改进
优势
适用场景
BM25Okapi 标准版本
理论基础扎实,参数直观
通用文本检索任务
BM25L 对低词频项加平滑(+δ)
改善低频词、短文本表现
新闻、微博、短文本检索
BM25Plus 对整体加平滑(+Δ)
综合性能更稳健,长度惩罚更合理
通用任务、长短文混合场景
3.3 主程序 位置:bm25_lesson/main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from retrieval.bm25_search import BM25Searchimport logginglogging.basicConfig(level=logging.INFO, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) def main (): documents = ["我喜欢编程" , "编程很有趣" ] obj = BM25Search(documents) query = "他喜欢编程" best_doc, best_score = obj.search(query) if best_doc: print (f"查询语句:{query} ,最匹配的文档:{best_doc} ,BM25得分:{best_score} " ) else : logger.warning(f"未找到匹配的文档!" ) if __name__ ` '__main__' : main()
三、Redis数据库简介与使用 1 Redis 数据库概述【理解】 Redis(Remote Dictionary Server)是一个高性能的键值对数据库,常用于缓存、会话管理等场景。它支持多种数据结构(如字符串、哈希、列表等),并提供快速的内存操作。
官网:https://redis.io/
Redis 的核心特性:
高性能 :数据存储在内存中,读写速度极快。持久化 :支持 RDB(快照式) 和 AOF(日志式) 两种持久化方式。灵活性 :支持多种数据类型和丰富命令。简单易用 :提供直观的 API,易于集成。
应用场景:
缓存查询结果以减少数据库压力。
存储用户会话信息。
实现排行榜或计数器功能。
Redis在本项目中的作用:
去缓存极高频的问答对,如果用户的问题到达后,会直接检索Redis中有没有相同的问题,如果有则直接返回答案!如果没有,则去MySQL有没有相似的问题,如果有则返回问题答案;如果没有则进行RAG搜索。
2 代码实现【实现】 2.1 整体结构 1 2 3 4 redis_ lesson/ ├── base.py # 配置文件和日志模块 ├── redis_ client.py # Redis 客户端模块 ├── main.py # 主程序入口
操作Redis之前,需要先启动Docker中的Redis。
2.2 配置文件 位置:redis_lesson/base.py
1 2 3 4 5 6 7 8 9 10 11 import logginglogging.basicConfig(level=logging.INFO, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) class Config : REDIS_HOST = "localhost" REDIS_PORT = 6379 REDIS_PASSWORD = 1234 REDIS_DB = 0
2.3 Redis 客户端模块 位置:redis_lesson/redis_client.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import redisimport jsonfrom base import Config, loggerclass RedisClient : def __init__ (self ): self.logger = logger self.conf = Config() try : self.client = redis.StrictRedis(host=self.conf.REDIS_HOST, port=self.conf.REDIS_PORT, password=self.conf.REDIS_PASSWORD, db=self.conf.REDIS_DB, decode_responses=True ) self.logger.info("RedisClient成功启动!" ) except Exception as e: self.logger.error(f"Redis 连接失败: {e} " ) raise def set_data (self, key, value ): try : self.client.set (key, json.dumps(value)) self.logger.info(f"数据 {key} 存储成功" ) except Exception as e: self.logger.error(f"数据 {key} 存储失败: {e} " ) def get_data (self, key ): try : value = self.client.get(key) return json.loads(value) if value else None except Exception as e: self.logger.error(f"数据 {key} 获取失败: {e} " ) return None def get_answer (self, query ): try : value = self.client.get(f"answer:{query} " ) if value: self.logger.info(f"从 Redis 中获取 '{query} ' 的答案成功" ) return json.loads(value) return None except Exception as e: self.logger.error(f"问题 {query} 获取失败: {e} " ) return None def delete_data (self, key ): try : self.client.delete(key) self.logger.info(f"数据 {key} 删除成功" ) except Exception as e: self.logger.error(f"数据 {key} 删除失败: {e} " ) if __name__ ` '__main__' : redis_client = RedisClient()
2.4 主程序 位置:redis_lesson/main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from redis_client import RedisClientfrom base import loggerdef main (): redis_client = RedisClient() key = "user1" value = {"name" : "Alice" , "age" : 25 } redis_client.set_data(key, value) data = redis_client.get_data(key) print (f"获取的数据为:{data} " ) query = "什么是AI" key = "answer:" + query value = "人工智能" redis_client.set_data(key, value) answer = redis_client.get_answer(query) print (f"获取的答案为:{answer} " ) redis_client.delete_data(key) answer = redis_client.get_answer(query) print (f"获取的答案为:{answer} " ) if __name__ ` '__main__' : main()
运行结果:
四、基于MySQL的FQA问答系统实现 1 FQA系统概述 本系统从MySQL数据库检索问答对,使用BM25算法计算相似度,并通过Softmax归一化将得分转换为概率值,阈值0.85判断答案可靠性。若MySQL无可靠答案,则调用RAG系统检索。为加快查询效率,优先使用Redis查询相同问题的答案,因为Redis中缓存了高可靠性结果(相似度>0.85且有答案)。
1.1 系统流程【掌握】
数据存储 :MySQL存储FQA高频问答对数据。缓存管理 :先基于Redis缓存,返回相同问题的答案,如果没有命中则进行MySQL问题检索;Redis中仅缓存相似度>0.85且有答案的数据。问题检索 :如果Redis中没有命中相同问题,则使用BM25计算与所有问题的相似度,将相似分数Softmax归一化。获取最相似文档的分数,并判断是否大于阈值0.85,如果是则认为是同一问题,去MySQL中查询该问题的答案;如果不是则调用RAG系统检索。答案返回 :
在MySQL中根据问题查询答案,若返回可靠答案,直接返回。
否则,调用RAG系统检索。
流程图如下:
1.2 项目结构【理解】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 integrated_qa_system/ ├── config.ini # 配置文件,包含所有模块的配置 ├── base/ │ ├── config.py # 配置管理,加载 config.ini │ ├── create_logger.py # 日志设置 ├── mysql_qa/ │ ├── data/ │ │ ├── JP学科知识问答.csv # FQA数据集 │ ├── db/ │ │ ├── mysql_client.py # MySQL 数据库操作 │ ├── cache/ │ │ ├── redis_client.py # Redis 缓存操作 │ ├── retrieval/ │ │ ├── bm25_search.py # BM25 搜索 │ ├── utils/ │ │ ├── preprocess.py # 文本预处理 │ ├── main.py # MySQL 系统独立入口,支持查询 └── logs/ └── app.log # 日志文件
2 代码实现 2.1 配置文件【理解】 位置:integrated_qa_system/config.ini
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [mysql] host = localhostuser = rootpassword = rootdatabase = subjects_kg[redis] host = localhostport = 6379 password = 1234 db = 0 [logger] log_file = logs/app.log
注意:mysql的账号密码需要根据个人情况来设置。
2.2 配置管理【理解】 功能 config.py文件定义了Config类,用于集中管理系统中的所有配置参数。这些参数包括数据库连接信息、模型选择、分块策略、API设置等。通过集中管理配置,系统可以方便地调整参数、适配不同环境,并支持通过环境变量进行灵活配置。
代码实现 位置:integrated_qa_system/base/config.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import configparserimport osproject_root = os.path.join(os.path.dirname(os.path.abspath(__file__)), '..' ) config_path = os.path.join(project_root, 'config.ini' ) class Config : def __init__ (self, config_file=config_path ): self.cf = configparser.ConfigParser() self.cf.read(config_file, encoding='utf-8' ) self.MYSQL_HOST = self.cf.get('mysql' , 'host' , fallback='localhost' ) self.MYSQL_USER = self.cf.get('mysql' , 'user' , fallback='root' ) self.MYSQL_PASSWORD = self.cf.get('mysql' , 'password' , fallback='123456' ) self.MYSQL_DATABASE = self.cf.get('mysql' , 'database' , fallback='subjects_kg' ) self.REDIS_HOST = self.cf.get('redis' , 'host' , fallback='localhost' ) self.REDIS_PORT = self.cf.getint('redis' , 'port' , fallback=6379 ) self.REDIS_PASSWORD = self.cf.get('redis' , 'password' , fallback='1234' ) self.REDIS_DB = self.cf.getint('redis' , 'db' , fallback=0 ) self.LOG_FILE = os.path.join(project_root, self.cf.get('logger' , 'log_file' , fallback='logs/app.log' )) if __name__ ` '__main__' : config = Config() print (config.LOG_FILE)
说明
默认值 :每个参数设有默认值,确保未配置环境变量时系统仍可运行。参数分类 :按功能分类(如数据库、日志、模型等),便于管理和维护。
2.3 日志记录【实现】 功能 create_logger.py文件定义了setup_logger函数,用于配置系统的日志记录器。日志记录器将运行信息、警告和错误输出到文件和控制台,便于开发、调试和运维人员监控系统状态。
代码实现 位置:integrated_qa_system/base/create_logger.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import loggingimport osfrom integrated_qa_system.base.config import Configdef setup_logger (name, log_file='logs/app.log' ): os.makedirs(os.path.dirname(log_file), exist_ok=True ) logger = logging.getLogger(name) logger.setLevel(logging.DEBUG) formatter = logging.Formatter('%(name)s - %(asctime)s - %(levelname)s - %(message)s' ) console_handler = logging.StreamHandler() console_handler.setFormatter(formatter) console_handler.setLevel(logging.INFO) file_handler = logging.FileHandler(filename=log_file, encoding="utf-8" , mode="a" ) file_handler.setFormatter(formatter) file_handler.setLevel(logging.DEBUG) if not logger.handlers: logger.addHandler(console_handler) logger.addHandler(file_handler) return logger logger = setup_logger('EduRAG' , Config().LOG_FILE)
说明
日志级别 :默认设为INFO,记录关键运行信息。双重输出 :同时输出到文件和控制台,便于实时监控和后续分析。格式化 :日志包含时间戳、名称、级别和内容,便于问题定位。
2.4 MySQL操作模块【理解】 功能 mysql_client.py是一个用于与 MySQL 交互的模块。模块通过读取配置文件连接数据库,支持创建表、从 CSV 文件插入数据、查询问题和答案,以及安全关闭连接。所有操作均通过日志记录,便于调试和监控系统状态。
代码实现 需提前创建数据库:
1 create database if not exists subjects_kg;
在pycharm中配置方式如下:
位置:integrated_qa_system/mysql_qa/db/mysql_client.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 import pandas as pdimport pymysqlfrom integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerclass MySQLClient : def __init__ (self ): self.logger = logger self.conf = Config() try : self.connection = pymysql.connect(host=self.conf.MYSQL_HOST, user=self.conf.MYSQL_USER, password=self.conf.MYSQL_PASSWORD, database=self.conf.MYSQL_DATABASE) self.cursor = self.connection.cursor() self.logger.info(f'连接MySQL数据库成功' ) except Exception as e: self.logger.error(f'连接MySQL数据库失败,错误信息为:{e} ' ) raise def create_table (self ): create_table_sql = """ CREATE TABLE IF NOT EXISTS jpkb ( id INT AUTO_INCREMENT PRIMARY KEY, subject_name VARCHAR(20), question VARCHAR(1000), answer VARCHAR(1000) ) """ try : self.cursor.execute(create_table_sql) self.logger.info(f'创建表成功' ) except Exception as e: self.logger.error(f'创建表失败,错误信息为:{e} ' ) raise def insert_data (self, csv_path ): data = pd.read_csv(csv_path) for index, row in data.iterrows(): insert_sql = """ INSERT INTO subjects_kg.jpkb (subject_name, question, answer) VALUES (%s, %s, %s) """ try : self.cursor.execute(insert_sql, (row['学科名称' ], row['问题' ], row['答案' ])) self.connection.commit() self.logger.info(f'插入数据成功' ) except Exception as e: self.connection.rollback() self.logger.error(f'插入数据失败,错误信息为:{e} ' ) raise def fecth_questions (self ): select_sql = """ SELECT question FROM subjects_kg.jpkb """ try : self.cursor.execute(select_sql) questions = self.cursor.fetchall() self.logger.info(f'获取所有问题成功' ) return questions except Exception as e: self.logger.error(f'获取所有问题失败,错误信息为:{e} ' ) return [] def fetch_answer (self, question ): select_sql = """ SELECT answer FROM subjects_kg.jpkb WHERE question = %s """ try : self.cursor.execute(select_sql, (question,)) answer = self.cursor.fetchone() if answer: answer = answer[0 ] self.logger.info(f'根据问题获取答案成功' ) return answer else : self.logger.warning(f'根据问题获取到一个空答案' ) return None except Exception as e: self.logger.error(f'根据问题获取答案失败,错误信息为:{e} ' ) return None def close (self ): try : self.connection.close() self.logger.info("MySQL 连接已关闭" ) except pymysql.MySQLError as e: self.logger.error(f"关闭连接失败: {e} " ) if __name__ ` '__main__' : mysql_client = MySQLClient() mysql_client.close()
说明
数据库连接 :通过 config.ini 配置文件读取 MySQL 参数,使用 pymysql 建立连接。
表管理 :创建 jpkb 表,包含字段 id(自增主键)、subject_name(学科名称)、question(问题)、answer(答案),使用 IF NOT EXISTS 避免重复创建。
插入数据 :读取CSV文件数据并输入表中。
获取问题 :获取所有问题,用于与查询问题计算相似度。
获取答案 :根据问题获取答案。
关闭连接 :关闭MySQL连接,节省资源。
异常处理 :每个方法均捕获异常,记录错误日志并根据需要回滚事务或抛出异常。
2.5 Redis 缓存操作模块【理解】 功能 redis_client.py该模块用于与 Redis 数据库交互。模块通过配置文件连接 Redis,支持键值对存储与查询(使用 JSON 序列化)、答案缓存查询,并记录操作日志,便于调试和监控。
代码实现 位置:integrated_qa_system/mysql_qa/cache/redis_client.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import redisimport jsonfrom integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerclass RedisClient : def __init__ (self ): self.logger = logger self.conf = Config() try : self.client = redis.StrictRedis(host=self.conf.REDIS_HOST, port=self.conf.REDIS_PORT, password=self.conf.REDIS_PASSWORD, db=self.conf.REDIS_DB, decode_responses=True ) self.logger.info("RedisClient成功启动!" ) except Exception as e: self.logger.error(f"Redis 连接失败: {e} " ) raise def set_data (self, key, value ): try : self.client.set (key, json.dumps(value)) self.logger.info(f"数据 {key} 存储成功" ) except Exception as e: self.logger.error(f"数据 {key} 存储失败: {e} " ) def get_data (self, key ): try : value = self.client.get(key) return json.loads(value) if value else None except Exception as e: self.logger.error(f"数据 {key} 获取失败: {e} " ) return None def get_answer (self, query ): try : value = self.client.get(f"answer:{query} " ) if value: self.logger.info(f"从 Redis 中获取 '{query} ' 的答案成功" ) return json.loads(value) return None except Exception as e: self.logger.error(f"问题 {query} 获取失败: {e} " ) return None def delete_data (self, key ): try : self.client.delete(key) self.logger.info(f"数据 {key} 删除成功" ) except Exception as e: self.logger.error(f"数据 {key} 删除失败: {e} " ) if __name__ ` '__main__' : redis_client = RedisClient()
说明
Redis 连接 :通过 config.ini 读取 Redis 配置,使用 redis.StrictRedis 建立连接。数据操作 :
set_data:将键值对(值序列化为 JSON)存储到 Redis。
get_data:根据键获取值并反序列化 JSON。
get_answer:查询以 answer:{query} 格式存储的答案缓存。
2.6 文本预处理模块【理解】 功能 preprocess.py是一个基于 jieba 分词库实现文本预处理的模块。该模块将输入文本转换为小写并进行分词,返回分词结果,支持日志记录以监控处理状态。
代码实现 位置:integrated_qa_system/mysql_qa/utils/preprocess.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import jiebafrom integrated_qa_system.base.create_logger import loggerdef preprocess_text (text ): try : return jieba.lcut(text.lower()) except : logger.error(f'文本"{text} "分词处理出现错误' ) return [] if __name__ ` '__main__' : print (preprocess_text('我今天在北京' ))
说明
文本处理 :使用 jieba.lcut 对输入文本进行中文分词,并将文本转换为小写以规范化。
2.7 BM25+Softmax检索模块【掌握】 功能 bm25_search.py 是一个基于 BM25 算法和 Softmax 归一化的文本检索模块,用于从问题库中检索与查询最匹配的答案。模块结合 Redis 缓存和 MySQL 数据库,支持问题加载、分词、BM25 评分、Softmax 归一化,并记录操作日志。
代码实现 位置:integrated_qa_system/mysql_qa/retrieval/bm25_search.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 import jiebaimport numpy as npfrom rank_bm25 import BM25Okapifrom integrated_qa_system.base.create_logger import loggerfrom integrated_qa_system.mysql_qa.cache.redis_client import RedisClientfrom integrated_qa_system.mysql_qa.db.mysql_client import MySQLClientfrom integrated_qa_system.mysql_qa.utils.preprocess import preprocess_textclass BM25Search (object ): def __init__ (self, mysql_client, redis_client ): self.logger = logger self.mysql_client = mysql_client self.redis_client = redis_client self.original_questions = None self.tokenized_questions = None self.bm25 = None self._load_data() logger.info(f'BM25模型对象创建成功' ) def _load_data (self ): original_key = "qa_original_questions" tokenized_key = "qa_tokenized_questions" self.original_questions = self.redis_client.get_data(original_key) self.tokenized_questions = self.redis_client.get_data(tokenized_key) if not self.original_questions or not self.tokenized_questions: self.original_questions = self.mysql_client.fecth_questions() if not self.original_questions: self.logger.error("没有获取到原始问题!" ) return self.tokenized_questions = [preprocess_text(question[0 ]) for question in self.original_questions] self.redis_client.set_data(tokenized_key, self.tokenized_questions) self.redis_client.set_data(original_key, self.original_questions) self.bm25 = BM25Okapi(self.tokenized_questions) def search (self, query, threshold=0.85 ): ''' 通过用户的问题去检索redis和mysql,获取缓存的答案 :param query: 用户的问题 :param threshold: 相似度阈值:在检索相似问题时,超过该阈值认为是同一个问题 :return: 缓存的答案,是否需要进行RAG ''' if not query or not isinstance (query, str ): self.logger.error("无效查询" ) return None , False cached_answer = self.redis_client.get_answer(query) if cached_answer: self.logger.info(f"从Redis缓存中获取答案:{cached_answer} " ) return cached_answer, False try : query_tokens = preprocess_text(query) scores = self.bm25.get_scores(query_tokens) softmax_scores = self._softmax(scores) best_index = np.argmax(softmax_scores) best_score = softmax_scores[best_index] if best_score >= threshold: original_question = self.original_questions[best_index][0 ] print (f'original_question-->{original_question} ' ) answer = self.mysql_client.fetch_answer(original_question) if answer: self.logger.info(f"从MySQL数据库中获取答案:{answer} " ) self.redis_client.set_data("answer:" + query, answer) return answer, False self.logger.info(f"best_score为{best_score} , 最终没有在MySQL找到答案,将进行RAG" ) return None , True except Exception as e: self.logger.error(f"搜索失败:{e} " ) return None , True def _softmax (self, scores ): exp_scores = np.exp(scores - np.max (scores)) return exp_scores / np.sum (exp_scores) if __name__ ` '__main__' : mysql_client = MySQLClient() redis_client = RedisClient() bm25_search = BM25Search(mysql_client, redis_client) query = "关联子查询的执行顺序是什么" bm25_search.search(query)
说明
数据加载 :优先从 Redis 获取问题和分词数据,若无则从 MySQL 加载并分词后缓存到 Redis。BM25 检索 :使用 BM25Okapi 计算查询与问题库的相似度,结合 Softmax 归一化评分。答案查询 :通过 Redis 缓存答案,若无缓存则从 MySQL 获取并缓存,阈值(默认 0.85)控制答案可靠性。
**注意点1:**
因为后续需要将最高分数对应的值 和 阈值进行判断,所以需要将分数进行归一化
归一化的方式:
原始计算公式为
优化的方式为
对应最终的结果:
1 2 3 4 5 6 7 8 9 10 import numpy as npdef _softmax (scores ): exp_scores = np.exp(scores - np.max (scores)) return exp_scores / np.sum (exp_scores) scores = np.array([3 , 1 , -2 ]) print (_softmax(scores))
**注意点2:**
当MySQL的数据更新之后,如何更新Redis中的数据,进而更新BM25模型?
我们可以对Redis中 用于记录所有历史问题和所有分词问题的key ,即 “qa_original_questions” 和”qa_tokenized_questions”设置一个有效期,有效期可以设置为3小时,这样redis中的这2个key的数据会定期进行删除。当redis中这2个key的数据进行删除之后,就可以按照代码从MySQL中重新进行加载,从而实现它的更新。
3 主程序【理解】 代码实现 位置:integrated_qa_system/mysql_qa/main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import timefrom integrated_qa_system.base.create_logger import loggerfrom integrated_qa_system.mysql_qa.cache.redis_client import RedisClientfrom integrated_qa_system.mysql_qa.db.mysql_client import MySQLClientfrom integrated_qa_system.mysql_qa.retrieval.bm25_search import BM25Searchclass MySQLQASystem : def __init__ (self ): self.logger = logger self.redis_client = RedisClient() self.mysql_client = MySQLClient() self.bm25_search = BM25Search(self.mysql_client, self.redis_client) def query (self, query ): start_time = time.time() answer, if_rag = self.bm25_search.search(query, threshold=0.85 ) if not answer: answer = "在MySQL中没有检索到答案" self.logger.info(f"查询结束,耗时:{time.time() - start_time} s" ) return answer, if_rag def main (): system = MySQLQASystem() print ("\n欢迎使用 MySQL 问答系统!" ) print ("输入查询进行问答,输入 'exit' 退出。" ) try : while True : query = input ("\n请输入查询:" ).strip() if query.lower() ` "exit" : print ("感谢使用 MySQL 问答系统!" ) logger.info("退出系统" ) break answer, if_rag = system.query(query) print (f"\n答案:{answer} " ) print (f"是否使用rag:{if_rag} " ) except Exception as e: logger.error(f"发生错误:{e} " ) print (f"发生错误:{e} " ) finally : system.mysql_client.close() if __name__ ` "__main__" : main()
运行结果 假设MySQL中有数据:
问题:”切割字符中,特殊符号的切割”,答案:”字符串切割特殊字符时,需要进行转义比如split(“#“),加上转义就可以了”
查询:”特殊符号的切割”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 2025-10-11 18:05:21,011 - INFO - EduRAG - Redis 连接成功 2025-10-11 18:05:21,017 - INFO - EduRAG - MySQL 连接成功 2025-10-11 18:05:21,024 - INFO - EduRAG - BM25 模型初始化完成 欢迎使用 MySQL 问答系统! 输入查询进行问答,输入 'exit' 退出。 输入查询: 特殊符号的切割 2025-10-11 18:05:26,376 - INFO - EduRAG - 处理查询: '特殊符号的切割' 2025-10-11 18:05:26,377 - INFO - EduRAG - 从 Redis 获取答案: 特殊符号的切割 2025-10-11 18:05:26,377 - INFO - EduRAG - MySQL 答案: 字符串切割特殊字符时,需要进行转义比如split("\#"),加上转义就可以了 2025-10-11 18:05:26,377 - INFO - EduRAG - 查询处理耗时 0.00秒 答案: 字符串切割特殊字符时,需要进行转义比如split("\#"),加上转义就可以了
P05-基于Milvus构建RAG问答系统 一、整体架构与工程流程 1 RAG系统整体架构介绍【理解】 1.1 系统背景 EduRAG智慧问答系统是一个基于 RAG 技术的智能问答平台,专为IT教育培训设计。它通过结合信息检索和生成式模型,从知识库中提取相关信息并生成准确、自然的回答。系统采用工程化的模块化设计,代码结构清晰,便于开发、维护和扩展。
1.2 模块化架构 系统的代码组织分为以下几个核心模块:
base/core/main.py
模块详情
base模块 :
config.py:管理系统配置,如API密钥、模型选择等。create_logger.py:记录系统运行日志,便于调试和监控。
core模块 :
document_processor.py:处理输入文档,分块并准备向量存储。prompts.py:管理Prompt模板,支持不同任务。query_classifier.py:分类用户查询类型。strategy_selector.py:选择合适的检索策略。vector_store.py:管理向量数据库,进行文档存储和检索。rag_system.py:整合RAG流程,生成最终回答。
main.py :命令行交互入口,测试和运行系统。
1.3 代码目录结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 integrated_qa_system/ ├── config.ini # 配置文件,包含所有模块的配置 ├── base/ │ ├── config.py # 配置管理,加载 config.ini │ ├── create_logger.py # 日志设置 ├── rag_qa/ │ ├── data/ │ │ ├── ai_data/ # ai学科数据 │ ├── samples/ # 示例数据 │ ├── models/ # 模型 │ ├── nlp_bert_document-segmentation_chinese-base/ # 语义解析模型 │ ├── edu_document_loaders/ # 文档加载器 │ ├── edu_text_spliter/ # 文档分割器 │ ├── core/ │ │ ├── prompts.py # RAG 提示模板 │ │ ├── document_processor.py # 处理输入文档,分块并准备向量存储。 │ │ ├── query_classifier.py # 查询分类器 │ │ ├── strategy_selector.py # 检索策略选择器 │ │ ├── vector_store.py # 向量存储与检索 │ │ ├── rag_system.py # RAG 系统核心逻辑 │ ├── main.py # RAG 系统独立入口,支持存储和查询 └── logs/ └── app.log # 日志文件
2 RAG系统基本工作流程【掌握】 EduRAG系统的工作流程分为四个主要步骤,确保从用户查询到生成回答的高效性和准确性:
查询分类 :
系统首先判断查询类型(如“通用知识”或“专业咨询”)。
通用知识直接由大语言模型回答,专业咨询进入检索流程。
策略选择 :
根据查询特点选择检索策略:
直接检索 :适用于明确查询。HyDE检索 :适用于抽象问题,生成假设答案后检索。子查询检索 :分解复杂查询。回溯检索 :简化复杂问题后检索。
文档检索 :
使用vector_store.py从向量数据库中检索相关文档。
支持稠密向量和稀疏向量的混合检索,结果经过重排序优化。
生成回答 :
将检索到的文档作为上下文,结合用户查询输入大语言模型,生成自然语言回答。
若大模型调用报错则联系人工。
流程图如下:
二、基础模块(base) base模块是EduRAG智慧问答系统的基础,负责提供系统运行所需的核心功能,包括配置管理、日志记录。这些功能为系统的其他模块提供了稳定的支持,确保系统能够灵活配置、监控运行状态。
1 配置文件【实现】 位置:integrated_qa_system/config.ini
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 [mysql] host = localhost user = root password = root database = subjects_kg [redis] host = localhost port = 6379 password = 1234 db = 0 [logger] log_file = logs/app.log [milvus] host = localhost port = 19530 database_name = itcast collection_name = edurag_0421 [llm] model = qwen-plus dashscope_api_key = sk-e69e1fb6754042ca9aa160834b3d17ff dashscope_base_url = https://dashscope.aliyuncs.com/compatible-mode/v1 [retrieval] parent_chunk_size = 1200 child_chunk_size = 300 parent_overlap = 150 child_overlap = 50 retrieval_k = 3 candidate_m = 2 [app] valid_sources = ["ai", "java", "test", "ops", "bigdata"] customer_service_phone = 12345678
注意:mysql的账号密码和 dashscope_api_key 需要根据个人情况来设置。
2 配置管理【实现】 位置:integrated_qa_system/base/config.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 import configparserimport osproject_root = os.path.join(os.path.dirname(os.path.abspath(__file__)), '..' ) config_path = os.path.join(project_root, 'config.ini' ) class Config : def __init__ (self, config_file=config_path ): self.cf = configparser.ConfigParser() self.cf.read(config_file, encoding='utf-8' ) self.MYSQL_HOST = self.cf.get('mysql' , 'host' , fallback='localhost' ) self.MYSQL_USER = self.cf.get('mysql' , 'user' , fallback='root' ) self.MYSQL_PASSWORD = self.cf.get('mysql' , 'password' , fallback='123456' ) self.MYSQL_DATABASE = self.cf.get('mysql' , 'database' , fallback='subjects_kg' ) self.REDIS_HOST = self.cf.get('redis' , 'host' , fallback='localhost' ) self.REDIS_PORT = self.cf.getint('redis' , 'port' , fallback=6379 ) self.REDIS_PASSWORD = self.cf.get('redis' , 'password' , fallback='1234' ) self.REDIS_DB = self.cf.getint('redis' , 'db' , fallback=0 ) self.LOG_FILE = os.path.join(project_root, self.cf.get('logger' , 'log_file' , fallback='logs/app.log' )) self.MILVUS_HOST = self.cf.get('milvus' , 'host' , fallback='localhost' ) self.MILVUS_PORT = self.cf.get('milvus' , 'port' , fallback='19530' ) self.MILVUS_DATABASE_NAME = self.cf.get('milvus' , 'database_name' , fallback='itcast' ) self.MILVUS_COLLECTION_NAME = self.cf.get('milvus' , 'collection_name' , fallback='edurag_final' ) self.LLM_MODEL = self.cf.get('llm' , 'model' , fallback='qwen-plus' ) self.DASHSCOPE_API_KEY = self.cf.get('llm' , 'dashscope_api_key' ) self.DASHSCOPE_BASE_URL = self.cf.get('llm' , 'dashscope_base_url' , fallback='https://dashscope.aliyuncs.com/compatible-mode/v1' ) self.PARENT_CHUNK_SIZE = self.cf.getint('retrieval' , 'parent_chunk_size' , fallback=1200 ) self.CHILD_CHUNK_SIZE = self.cf.getint('retrieval' , 'child_chunk_size' , fallback=300 ) self.PARENT_OVERLAP = self.cf.getint('retrieval' , 'parent_overlap' , fallback=150 ) self.CHILD_OVERLAP = self.cf.getint('retrieval' , 'child_overlap' , fallback=50 ) self.RETRIEVAL_K = self.cf.getint('retrieval' , 'retrieval_k' , fallback=5 ) self.CANDIDATE_M = self.cf.getint('retrieval' , 'candidate_m' , fallback=2 ) self.VALID_SOURCES = eval ( self.cf.get('app' , 'valid_sources' , fallback='["ai", "java", "test", "ops", "bigdata"]' )) self.CUSTOMER_SERVICE_PHONE = self.cf.get('app' , 'customer_service_phone' , fallback='12345678' ) if __name__ ` '__main__' : config = Config() print (config.LOG_FILE) print (config.CUSTOMER_SERVICE_PHONE)
3 日志记录【实现】 直接使用第三章的代码即可,无需修改。
三、文档处理 1 文档解析【掌握】 document_processor.py是EduRAG系统的核心模块之一,用于文档解析。主要负责加载多种格式的文档(如.txt、.pdf等),并对其进行分层切分,生成 父块和子块,为后续的向量存储和检索做好准备。
说明
文档加载 :支持多种格式(如.txt、.pdf),使用专用加载器处理复杂文档。
分层切分 :采用ChineseRecursiveTextSplitter生成父块和子块,优化中文文本处理。
元数据管理 :为每个块添加唯一ID、来源和时间戳,便于检索和溯源。
文本切分方式
文本切分器的选择:根据文档的类型进行选择——如果是markdown,则使用MarkdownTextSplitter进行切割;如果是一大段文本,没有明确的段落标识,比如从网上爬取到的信息,则使用AliTextSplitter;其他使用ChineseRecursiveTextSplitter进行切割。
文本切块的方式:先切分了父块,然后在每个父块里边切分了子块。在子块中保存了元数据信息,包括父块的id,路径,父块的内容!最后返回的是所有的子块,需要将子块进行embedding后,存入Milvus中。
为什么要进行父块和子块的区分?
如果块特别大,这个时候块中会包括大量跟问题无关的信息,在检索时,没有办法精准找到我们想要的数据。如果将文档切分成了一个一个的小块,可以提高检索时的精准性。但是有一个新的问题,因为块比较小,所以块的上下文信息是比较缺失的,在回答问题时,可能语义不完整。
所以解决方式是:大块切分和小块切分进行了融合,即使用父块和子块组合切分的方式。具体来说,先切分父块,然后在每个父块里边切分了子块,然后在子块中保存父块的内容。最终存储到向量数据时,是将子块进行embedding后进行存储。在检索的时候,就是用子块进行检索,此时可以实现精准检索。当检索到子块后,会将该子块元数据信息中的父块内容进行返回,用于问答,从而解决了上下文缺失问题!
代码实现 位置:integrated_qa_system/rag_qa/core/document_processor.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 import osfrom langchain_community.document_loaders import TextLoaderfrom langchain_community.document_loaders.markdown import UnstructuredMarkdownLoaderfrom langchain.text_splitter import MarkdownTextSplitterfrom datetime import datetimefrom integrated_qa_system.rag_qa.edu_text_spliter import AliTextSplitter, ChineseRecursiveTextSplitterfrom integrated_qa_system.rag_qa.edu_document_loaders import OCRPDFLoader, OCRDOCLoader, OCRPPTLoader, OCRIMGLoaderfrom integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerconf = Config() document_loaders = { ".txt" : TextLoader, ".pdf" : OCRPDFLoader, ".docx" : OCRDOCLoader, ".ppt" : OCRPPTLoader, ".pptx" : OCRPPTLoader, ".jpg" : OCRIMGLoader, ".png" : OCRIMGLoader, ".md" : UnstructuredMarkdownLoader } def load_documents_from_directory (directory_path ): documents = [] supported_file_type = document_loaders.keys() source = os.path.basename(directory_path).replace("_data" , "" ) for root, dirs, files in os.walk(directory_path): for file in files: file_path = os.path.join(root, file) file_extension = os.path.splitext(file)[1 ].lower() if file_extension in supported_file_type: loader_class = document_loaders[file_extension] try : if file_extension ` '.txt' : loader = loader_class(file_path, encoding='utf-8' ) else : loader = loader_class(file_path) loaded_documents = loader.load() for document in loaded_documents: document.metadata['source' ] = source document.metadata['file_path' ] = file_path document.metadata['timestamp' ] = datetime.now().strftime("%Y-%m-%d %H:%M:%S" ) documents.extend(loaded_documents) logger.info(f'从 {file_path} 中加载了 {len (loaded_documents)} 个documents' ) except Exception as e: logger.error(f'从 {file_path} 中加载文档时出错:{e} ' ) else : logger.warning(f'不支持的文件类型:{file_path} ' ) return documents def process_documents (directory_path, parent_chunk_size=conf.PARENT_CHUNK_SIZE, child_chunk_size=conf.CHILD_CHUNK_SIZE, parent_overlap=conf.PARENT_OVERLAP, child_overlap=conf.CHILD_OVERLAP ): documents = load_documents_from_directory(directory_path) logger.info(f"加载的文档数量: {len (documents)} " ) markdown_splitter_parent = MarkdownTextSplitter(chunk_size=parent_chunk_size, chunk_overlap=parent_overlap) text_splitter_parent = ChineseRecursiveTextSplitter(chunk_size=parent_chunk_size, chunk_overlap=parent_overlap) markdown_splitter_child = MarkdownTextSplitter(chunk_size=child_chunk_size, chunk_overlap=child_overlap) text_splitter_child = ChineseRecursiveTextSplitter(chunk_size=child_chunk_size, chunk_overlap=child_overlap) processed_documents = [] for i, document in enumerate (documents): file_extension = os.path.splitext(document.metadata.get('file_path' , '' ))[1 ].lower() if file_extension ` '.md' : parent_splitter = markdown_splitter_parent child_splitter = markdown_splitter_child else : parent_splitter = text_splitter_parent child_splitter = text_splitter_child logger.info(f"处理文档: {document.metadata['file_path' ]} , 使用切分器: {'Markdown' if (file_extension ` '.md' ) else 'ChineseRecursive' } " ) parent_chunks = parent_splitter.split_documents([document]) for j, parent_chunk in enumerate (parent_chunks): parent_id = f"doc_{i} _parent_{j} " child_chunks = child_splitter.split_documents([parent_chunk]) for k, child_chunk in enumerate (child_chunks): child_chunk.metadata['id' ] = f"{parent_id} _child_{k} " child_chunk.metadata['parent_id' ] = parent_id child_chunk.metadata['parent_content' ] = parent_chunk.page_content processed_documents.append(child_chunk) logger.info(f"处理完成,共生成 {len (processed_documents)} 个文档" ) return processed_documents if __name__ ` '__main__' : child_chunks = process_documents(r'..\data\ai_data' ) print (f'child_chunks[0]-->{child_chunks[0 ]} ' ) print (f'child_chunks-->{len (child_chunks)} ' )
2 自定义文档加载器【理解】 (1)pdf加载器 主要思路:
继承LangChain中的BaseLoader类,实现init方法和lazy_load方法,将整个 pdf 的提取结果加上元数据信息作为一个 Document yield 出去。
内容提取的核心逻辑是:使用PyMuPDF模块中的fitz加载PDF,用来提取文字和图片元数据信息,对于图片信息使用PaddleORC(使用的rapidocr_paddle 模块下的 RapidOCR类)识别图片中的文字,最终将结果拼接到一起。
主要流程:
使用 fitz.open() 打开 PDF。
逐页 (page) 处理。
使用 page.get_text() 提取原生文本。
使用 page.get_image_info(xrefs=True) 获取页面上的图片信息。
OCR 应用 : 对获取到的图片,检查其尺寸是否超过预设阈值 PDF_OCR_THRESHOLD(默认为页面宽高的 60%)。仅对大于阈值的图片执行 OCR。处理页面旋转 (page.rotation),确保 OCR 时图像方向正确。
调用 get_ocr() 获取的 OCR 实例识别图片文字。
合并原生文本和 OCR 结果。
(2)doc加载器 主要思路:
继承LangChain中的BaseLoader类,实现init方法和lazy_load方法,将整个 word文档 的提取结果加上元数据信息作为一个 Document yield 出去。
内容提取的核心逻辑是:使用python-docx模块加载word文档,然后获取该文档的块信息(Paragraph或Table),接下来去处理每一个块。如果是段落,先把段落中的文字提取出来,然后段落中的图片使用PaddleORC(使用的rapidocr_paddle 模块下的 RapidOCR类)识别其中的文字;如果是表格,则直接遍历获取表格单元格中的信息。最终将结果拼接到一起。
主要流程:
使用 docx.Document() 打开 DOCX 文件。
定义 iter_block_items 辅助函数,用于统一遍历文档中的段落 (Paragraph) 和表格 (Table) 块。
遍历所有块:
如果是段落,提取 block.text。同时,使用 XPath (.//pic:pic, .//a:blip/@r:embed) 查找并提取段落内嵌入的图片。对提取的图片执行 OCR。
如果是表格,遍历所有单元格 (cell),提取单元格内段落的文本。
合并所有提取的文本和 OCR 结果。
(3)ppt加载器 主要思路:
继承LangChain中的BaseLoader类,实现init方法和lazy_load方法,将整个 ppt 的提取结果加上元数据信息作为一个 Document yield 出去。
内容提取的核心逻辑是:使用python-pptx模块加载ppt,然后逐张处理PPT。在处理PPT时,首先将PPT上的形状 (shape) 按视觉顺序(top, left 坐标)排序,排序完后依次去处理每个形状。在处理形状时,如果是文本框 ,则直接提取文本;如果是表格,则直接遍历获取表格单元格中的信息;如果是图片,则使用PaddleORC(使用的rapidocr_paddle 模块下的 RapidOCR类)识别其中的文字;如果是组合形状,则进行递归调用。最终将结果拼接到一起。
主要流程:
使用 pptx.Presentation() 打开演示文稿。
逐张幻灯片 (slide) 处理。
顺序处理 : 将幻灯片上的形状 (shape) 按视觉顺序(top, left 坐标)排序。定义 extract_text 递归函数处理单个形状:
提取文本框 (shape.has_text_frame) 的文本。
提取表格 (shape.has_table) 内所有单元格的文本。
如果形状是图片 (shape.shape_type 13),提取图片数据 (shape.image.blob`),执行 OCR。
如果形状是组合 (shape.shape_type 6),递归调用 extract_text` 处理其包含的子形状。
遍历排序后的形状,调用 extract_text。
合并所有提取的文本和 OCR 结果。
(4)图片加载器 主要思路:
继承LangChain中的BaseLoader类,实现init方法和lazy_load方法,将整个图片的提取结果加上元数据信息作为一个 Document yield 出去。
内容提取的核心逻辑是:使用PaddleORC(使用的rapidocr_paddle 模块下的 RapidOCR类)识别其中的文字。
主要流程:
接收图像文件路径 img_path。
调用 get_ocr() 获取 OCR 实例。
直接对图像文件执行 OCR。
将 OCR 结果(所有识别出的文本行)合并成一个字符串。
3 自定义文本切分器(文档分割器)【理解】 (1)中文递归文本切分器 主要实现逻辑:继承langchain.text_splitter.RecursiveCharacterTextSplitter,对分割符列表进行了修改,修改成包括常见的中文标点和换行符,如 ["\n\n", "\n", "。|!|?", "\.\s|\!\s|\?\s", ";|;\s", ",|,\s"]。这有助于在切分时尽量保持中文句子的完整性。
最终效果(为什么自定义文本切分器):将长文本按照预设的中文分隔符递归地切分成指定大小的块。
(2)基于模型的语义切分器 主要实现逻辑:继承langchain.text_splitter.CharacterTextSplitter,对split_text方法进行了修改。修改的方式就是利用预训练的文档语义分割模型对文本进行切分。具体的切分方式调用 modelscope.pipeline 加载指定的文档分割模型(nlp_bert_document-segmentation_chinese-base,达摩院开源的文档语义分割模型)模型,将输入文本传递给模型 pipeline 进行处理,最后解析模型输出,得到分块的结果。
最终效果(为什么自定义文本切分器):实现了基于文档语义分割模型对文本进行切分,准确度高并且效率高。
为什么选用这个模型?
因为 nlp_bert_document-segmentation_chinese-base 是 达摩院开源的文档语义分割模型,通过自适应滑动窗口的序列模型,对输入文本进行语义层面的段落分割。它先将整个文本作为序列输入,然后使用使用 BERT 基础模型预测每个 token 是否是段落边界,通过自适应滑动窗口动态调整处理窗口大小,提高准确性和效率。
四、向量存储 vector_store.py是EduRAG系统的核心模块之一,封装了与Milvus向量数据库的交互逻辑。它负责将文档转化为向量存储到数据库中,并提供高效的混合检索功能。通过结合BGE-M3嵌入模型和重排序机制,该模块确保系统能够快速检索到与用户查询最相关的文档。
1 模块功能概述【理解】 VectorStore类提供了以下主要功能:
初始化与集合管理 :创建或加载Milvus向量数据库集合。文档向量化与存储 :将分块后的文档转换为向量并存储。混合检索与重排序 :结合稠密和稀疏向量进行检索,并通过重排序优化结果。
以下将逐一讲解每个方法的实现细节。
导入必备工具包 注意:BGE-M3 模型需要依赖peft和FlagEmbedding。所以运行下面的代码之前,需要提前安装:
1 2 pip install peft -i https://pypi.tuna.tsinghua.edu.cn/simple pip install FlagEmbedding>=1.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
位置:integrated_qa_system/rag_qa/core/vector_store.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import osfrom milvus_model.hybrid import BGEM3EmbeddingFunctionfrom pymilvus import MilvusClient, DataType, AnnSearchRequest, WeightedRankerfrom langchain.docstore.document import Documentfrom sentence_transformers import CrossEncoderimport hashlibfrom integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerconf = Config() base_dir = os.path.dirname(os.path.abspath(__file__))
2 初始化方法【实现】 功能 __init__方法初始化VectorStore类的实例,设置基本参数并调用集合创建或加载方法。
实现步骤
参数设置 :
使用Config中的默认值初始化集合名称、主机、端口和数据库名称。
模型初始化 :
reranker:加载BGE-Reranker模型,用于后续重排序。embedding_function:初始化BGE-M3嵌入模型。
注意:BGE-M3 模型需要依赖peft和FlagEmbedding。所以运行代码之前,需要提前安装:
1 2 pip install peft -i https://pypi.tuna.tsinghua.edu.cn/simple pip install FlagEmbedding>=1.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
客户端连接 :
创建MilvusClient实例,连接到指定主机和数据库。
注意:连接数据库之前需要先手动进行创建数据库,名称为 itcast。
集合管理 :
调用_create_or_load_collection方法,确保集合可用。
说明
BGE-M3模型 :提供稠密和稀疏向量生成能力。灵活性 :通过参数支持自定义配置。
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class VectorStore : def __init__ (self, collection_name=conf.MILVUS_COLLECTION_NAME, host=conf.MILVUS_HOST, port=conf.MILVUS_PORT, database=conf.MILVUS_DATABASE_NAME ): self.logger = logger self.host = host self.port = port self.database = database self.collection_name = collection_name self.client = MilvusClient(uri=f"http://{self.host} :{self.port} " , db_name=self.database) self.embedding_function = BGEM3EmbeddingFunction(model_name_or_path=os.path.join(base_dir, '../models/bge-m3' ), device="cuda:0" ) self.dense_dim = self.embedding_function.dim['dense' ] self.reranker = CrossEncoder(os.path.join(base_dir, '../models/bge-reranker-large' ), device="cuda:0" ) self._create_or_load_collection()
3 创建或加载集合【掌握】 功能 _create_or_load_collection方法检查并创建或加载Milvus集合,定义字段结构和索引参数。
实现步骤
检查集合是否存在 :
使用has_collection判断是否需要创建新集合。
定义Schema :
设置字段:包括id(主键)、text(原文)、向量字段和元数据字段。
禁用自动ID,启用动态字段。
创建索引 :
稠密向量使用IVF_FLAT索引,稀疏向量使用SPARSE_INVERTED_INDEX。
创建并加载集合 :
调用create_collection创建集合,并加载到内存。
说明
字段设计 :支持多种数据类型和元数据管理。索引优化 :平衡检索速度和精度。
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 def _create_or_load_collection (self ): if not self.client.has_collection(self.collection_name): schema = self.client.create_schema(auto_id=False , enable_dynamic_field=True ) schema.add_field(field_name="id" , datatype=DataType.VARCHAR, is_primary=True , max_length=100 ) schema.add_field(field_name="text" , datatype=DataType.VARCHAR, max_length=65535 ) schema.add_field(field_name="dense_vector" , datatype=DataType.FLOAT_VECTOR, dim=self.dense_dim) schema.add_field(field_name="sparse_vector" , datatype=DataType.SPARSE_FLOAT_VECTOR) schema.add_field(field_name="parent_id" , datatype=DataType.VARCHAR, max_length=100 ) schema.add_field(field_name="parent_content" , datatype=DataType.VARCHAR, max_length=65535 ) schema.add_field(field_name="source" , datatype=DataType.VARCHAR, max_length=50 ) schema.add_field(field_name="timestamp" , datatype=DataType.VARCHAR, max_length=50 ) index_params = self.client.prepare_index_params() index_params.add_index(field_name="dense_vector" , index_name="dense_index" , index_type="IVF_SQ8" , metric_type="IP" , params={"nlist" : 10 }) index_params.add_index(field_name="sparse_vector" , index_name="sparse_index" , index_type="SPARSE_INVERTED_INDEX" , metric_type="IP" ) self.client.create_collection(collection_name=self.collection_name, schema=schema, index_params=index_params) logger.info(f"已创建集合 {self.collection_name} " ) else : logger.info(f"已加载集合 {self.collection_name} " ) self.client.load_collection(self.collection_name)
4 添加文档【掌握】 功能 add_documents方法将分块后的文档转换为向量并存储到Milvus集合中。
实现步骤
提取文本 :
生成向量 :
构造数据 :
为每篇文档生成唯一ID(MD5哈希)。
将向量和元数据组织成字典。
存储数据 :
说明
唯一性 :通过MD5哈希确保ID唯一。稀疏向量处理 :将稀疏矩阵转换为字典格式。
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 def add_documents (self, documents ): texts = [doc.page_content for doc in documents] embeddings = self.embedding_function(texts) data = [] for i, doc in enumerate (documents): doc_id = hashlib.md5(doc.page_content.encode('utf-8' )).hexdigest() sparse_vector = {} row_vector = embeddings['sparse' ]._getrow(i) indices = row_vector.indices values = row_vector.data for index, value in zip (indices, values): sparse_vector[index] = value data.append({ "id" : doc_id, "text" : doc.page_content, "dense_vector" : embeddings["dense" ][i], "sparse_vector" : sparse_vector, "parent_id" : doc.metadata.get("parent_id" , "" ), "parent_content" : doc.metadata.get("parent_content" , "" ), "source" : doc.metadata.get("source" , "" ), "timestamp" : doc.metadata.get("timestamp" , "" ) }) self.client.upsert(collection_name=self.collection_name, data=data) logger.info(f"Milvus中已成功添加 {len (data)} 个文档" )
5 混合检索与重排序【掌握】 功能 hybrid_search_with_rerank方法实现混合检索并重排序,返回最相关文档。
实现步骤
生成查询向量 :
构造检索请求 :
为稠密和稀疏向量分别创建AnnSearchRequest。
混合检索 :
重排序 :
说明
混合检索 :提升覆盖率和准确性。重排序 :确保最相关文档优先。
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 def hybrid_search_with_rerank (self, query, top_k=conf.RETRIEVAL_K, source_filter=None ): ''' :param query: 查询的问题 :param top_k: 检索返回的topk个文档 :param source_filter: 进行查询过滤的条件,这里指的是学科 :return: ''' query_embeddings = self.embedding_function([query]) dense_vector = query_embeddings["dense" ][0 ] sparse_vector = query_embeddings["sparse" ]._getrow(0 ) sparse_dict = {index: value for index, value in zip (sparse_vector.indices, sparse_vector.data)} filter_expression = f"source ` '{source_filter} '" if source_filter else "" dense_search_params = { "data" : [dense_vector], "anns_field" : "dense_vector" , "param" : {"metric_type" : "IP" , "nprobe" : 2 }, "limit" : top_k, "expr" : filter_expression } request_1 = AnnSearchRequest(**dense_search_params) request_2 = AnnSearchRequest( data=[sparse_dict], anns_field="sparse_vector" , param={"metric_type" : "IP" }, limit=top_k, expr=filter_expression ) ranker = WeightedRanker(1.0 , 0.7 ) results = self.client.hybrid_search(collection_name=self.collection_name, reqs=[request_1, request_2], ranker=ranker, limit=top_k, output_fields=["text" , "parent_id" , "parent_content" , "source" , "timestamp" ])[0 ] sub_chunks = [self._doc_from_hit(hit['entity' ]) for hit in results] parent_docs = self._get_unique_parent_docs(sub_chunks) if parent_docs: data_pairs = [(query, doc.page_content) for doc in parent_docs] scores = self.reranker.predict(data_pairs) ranked_parent_docs = [doc for score, doc in sorted (zip (scores, parent_docs), reverse=True )] self.logger.info(f"Milvus中已找到 {len (ranked_parent_docs)} 个去重父块,最终返回 {conf.CANDIDATE_M} 个父块" ) return ranked_parent_docs[:conf.CANDIDATE_M] else : self.logger.warning(f"在Milvus中没有找到去重父块" ) return []
6 从查询结果创建文档【实现】 功能 _doc_from_hit方法将Milvus查询结果转换为Document对象。
实现步骤
提取内容和元数据 :
创建对象 :
说明
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 def _doc_from_hit (self, hit ): return Document( page_content=hit.get("text" ), metadata={ "parent_id" : hit.get("parent_id" ), "parent_content" : hit.get("parent_content" ), "source" : hit.get("source" ), "timestamp" : hit.get("timestamp" ) } )
7 获取唯一父文档【理解】 功能 _get_unique_parent_docs方法从子块中提取去重的父文档。
实现步骤
去重 :
构造文档 :
说明
去重逻辑 :避免重复父文档。元数据保留 :保持完整性。
代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def _get_unique_parent_docs (self, chunks ): unique_parent_ids = set () parent_docs = [] for chunk in chunks: parent_id = chunk.metadata.get("parent_id" , "1" ) parent_content = chunk.metadata.get("parent_content" , chunk.page_content) if parent_id not in unique_parent_ids: unique_parent_ids.add(parent_id) parent_docs.append(Document(page_content=parent_content, metadata=chunk.metadata)) return parent_docs
8 完整代码 位置:integrated_qa_system/rag_qa/core/vector_store.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 import osfrom milvus_model.hybrid import BGEM3EmbeddingFunctionfrom pymilvus import MilvusClient, DataType, AnnSearchRequest, WeightedRankerfrom langchain.docstore.document import Documentfrom sentence_transformers import CrossEncoderimport hashlibfrom integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerfrom integrated_qa_system.rag_qa.core.document_processor import process_documentsconf = Config() base_dir = os.path.dirname(os.path.abspath(__file__)) class VectorStore : def __init__ (self, collection_name=conf.MILVUS_COLLECTION_NAME, host=conf.MILVUS_HOST, port=conf.MILVUS_PORT, database=conf.MILVUS_DATABASE_NAME ): self.logger = logger self.host = host self.port = port self.database = database self.collection_name = collection_name self.client = MilvusClient(uri=f"http://{self.host} :{self.port} " , db_name=self.database) self.embedding_function = BGEM3EmbeddingFunction(model_name_or_path=os.path.join(base_dir, '../models/bge-m3' ), device="cuda:0" ) self.dense_dim = self.embedding_function.dim['dense' ] self.reranker = CrossEncoder(os.path.join(base_dir, '../models/bge-reranker-large' ), device="cuda:0" ) self._create_or_load_collection() def _create_or_load_collection (self ): if not self.client.has_collection(self.collection_name): schema = self.client.create_schema(auto_id=False , enable_dynamic_field=True ) schema.add_field(field_name="id" , datatype=DataType.VARCHAR, is_primary=True , max_length=100 ) schema.add_field(field_name="text" , datatype=DataType.VARCHAR, max_length=65535 ) schema.add_field(field_name="dense_vector" , datatype=DataType.FLOAT_VECTOR, dim=self.dense_dim) schema.add_field(field_name="sparse_vector" , datatype=DataType.SPARSE_FLOAT_VECTOR) schema.add_field(field_name="parent_id" , datatype=DataType.VARCHAR, max_length=100 ) schema.add_field(field_name="parent_content" , datatype=DataType.VARCHAR, max_length=65535 ) schema.add_field(field_name="source" , datatype=DataType.VARCHAR, max_length=50 ) schema.add_field(field_name="timestamp" , datatype=DataType.VARCHAR, max_length=50 ) index_params = self.client.prepare_index_params() index_params.add_index(field_name="dense_vector" , index_name="dense_index" , index_type="IVF_SQ8" , metric_type="IP" , params={"nlist" : 10 }) index_params.add_index(field_name="sparse_vector" , index_name="sparse_index" , index_type="SPARSE_INVERTED_INDEX" , metric_type="IP" ) self.client.create_collection(collection_name=self.collection_name, schema=schema, index_params=index_params) logger.info(f"已创建集合 {self.collection_name} " ) else : logger.info(f"已加载集合 {self.collection_name} " ) self.client.load_collection(self.collection_name) def add_documents (self, documents ): texts = [doc.page_content for doc in documents] embeddings = self.embedding_function(texts) data = [] for i, doc in enumerate (documents): doc_id = hashlib.md5(doc.page_content.encode('utf-8' )).hexdigest() sparse_vector = {} row_vector = embeddings['sparse' ]._getrow(i) indices = row_vector.indices values = row_vector.data for index, value in zip (indices, values): sparse_vector[index] = value data.append({ "id" : doc_id, "text" : doc.page_content, "dense_vector" : embeddings["dense" ][i], "sparse_vector" : sparse_vector, "parent_id" : doc.metadata.get("parent_id" , "" ), "parent_content" : doc.metadata.get("parent_content" , "" ), "source" : doc.metadata.get("source" , "" ), "timestamp" : doc.metadata.get("timestamp" , "" ) }) self.client.upsert(collection_name=self.collection_name, data=data) logger.info(f"Milvus中已成功添加 {len (data)} 个文档" ) def hybrid_search_with_rerank (self, query, top_k=conf.RETRIEVAL_K, source_filter=None ): ''' :param query: 查询的问题 :param top_k: 检索返回的topk个文档 :param source_filter: 进行查询过滤的条件,这里指的是学科 :return: ''' query_embeddings = self.embedding_function([query]) dense_vector = query_embeddings["dense" ][0 ] sparse_vector = query_embeddings["sparse" ]._getrow(0 ) sparse_dict = {index: value for index, value in zip (sparse_vector.indices, sparse_vector.data)} filter_expression = f"source ` '{source_filter} '" if source_filter else "" dense_search_params = { "data" : [dense_vector], "anns_field" : "dense_vector" , "param" : {"metric_type" : "IP" , "nprobe" : 2 }, "limit" : top_k, "expr" : filter_expression } request_1 = AnnSearchRequest(**dense_search_params) request_2 = AnnSearchRequest( data=[sparse_dict], anns_field="sparse_vector" , param={"metric_type" : "IP" }, limit=top_k, expr=filter_expression ) ranker = WeightedRanker(1.0 , 0.7 ) results = self.client.hybrid_search(collection_name=self.collection_name, reqs=[request_1, request_2], ranker=ranker, limit=top_k, output_fields=["text" , "parent_id" , "parent_content" , "source" , "timestamp" ])[0 ] sub_chunks = [self._doc_from_hit(hit['entity' ]) for hit in results] parent_docs = self._get_unique_parent_docs(sub_chunks) if parent_docs: data_pairs = [(query, doc.page_content) for doc in parent_docs] scores = self.reranker.predict(data_pairs) ranked_parent_docs = [doc for score, doc in sorted (zip (scores, parent_docs), reverse=True )] self.logger.info(f"Milvus中已找到 {len (ranked_parent_docs)} 个去重父块,最终返回 {conf.CANDIDATE_M} 个父块" ) return ranked_parent_docs[:conf.CANDIDATE_M] else : self.logger.warning(f"在Milvus中没有找到去重父块" ) return [] def _doc_from_hit (self, hit ): return Document( page_content=hit.get("text" ), metadata={ "parent_id" : hit.get("parent_id" ), "parent_content" : hit.get("parent_content" ), "source" : hit.get("source" ), "timestamp" : hit.get("timestamp" ) } ) def _get_unique_parent_docs (self, chunks ): unique_parent_ids = set () parent_docs = [] for chunk in chunks: parent_id = chunk.metadata.get("parent_id" , "1" ) parent_content = chunk.metadata.get("parent_content" , chunk.page_content) if parent_id not in unique_parent_ids: unique_parent_ids.add(parent_id) parent_docs.append(Document(page_content=parent_content, metadata=chunk.metadata)) return parent_docs if __name__ ` '__main__' : vector_store = VectorStore() results = vector_store.hybrid_search_with_rerank("什么是大语言模型?" ) print (f'results-->{results} ' )
五、查询分类 1 查询分类【掌握】 QueryClassifier 是 EduRAG 系统的核心组件,负责将用户查询分为“通用知识”和“专业咨询”两类,以决定查询路由到知识库还是咨询接口。本模块利用 5000 条混合数据集(假设“通用知识”和“专业咨询”各约 2500 条)进行训练,并解决评估中的标签处理问题。
1.1 功能概述 QueryClassifier 提供以下功能:
数据加载与处理 :读取 5000 条 JSON 数据集,包含查询和标签(“通用知识”或“专业咨询”)。对数据进行处理,处理成模型训练的格式。BERT 训练 :使用 bert-base-chinese 模型,微调二分类任务,准确率达 90%+。评估优化 :直接处理数字标签(0 或 1),生成分类报告和混淆矩阵。预测接口 :支持实时分类,集成到 EduRAG 系统。
1.2 实现细节
__init__ 方法
作用 :初始化 BERT 分词器(bert-base-chinese)和模型,支持二分类。优化 :设备选择优先 CUDA,若不可用则回退到 CPU。标签映射 :定义 label_map = {"通用知识": 0, "专业咨询": 1},用于训练时字符串标签转换。
preprocess_data 方法
作用 :将查询文本分词为 BERT 输入,将字符串标签转换为数字(0 或 1)。细节 :设置 max_length=128,平衡效率和信息完整性。
create_dataset 方法
作用 :构建 PyTorch 数据集,适配 Trainer 的输入格式。实现 :将输出封装到一个字典中,方便后续使用。
train_model 方法
作用 :加载 5000 条数据集,划分 80% 训练(4000 条)和 20% 验证(1000 条),微调 BERT 模型。参数 :
num_train_epochs=3:训练 3 轮,适合中等规模数据集。per_device_train_batch_size=8:平衡内存和速度。fp16=False:禁用混合精度,兼容 PyTorch 2.5 和 CPU。
流程 :
加载 training_dataset_hybrid_5000.json。
预处理数据,将标签转换为数字。
使用 Trainer 训练,自动保存最佳模型。
evaluate_model 方法
作用 :在验证集上评估模型,生成分类报告和混淆矩阵。输出 :精确率、召回率、F1 分数和混淆矩阵。
predict_category 方法
作用 :对单条查询分类,返回“通用知识”或“专业咨询”。实现 :分词后通过模型预测,返回人类可读标签。
1.3 代码实现 位置:integrated_qa_system/rag_qa/core/query_classifier.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 import jsonimport osimport torchfrom torch.utils.data import Datasetimport numpy as npfrom transformers import BertTokenizer, BertForSequenceClassificationfrom transformers import Trainer, TrainingArgumentsfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_report, confusion_matrixfrom integrated_qa_system.base.create_logger import loggerbase_dir = os.path.dirname(os.path.abspath(__file__)) class QueryClassifier : def __init__ (self, model_path="bert_query_classifier" ): self.logger = logger self.model_path = os.path.join(base_dir, '../models' , model_path) print (f'self.model_path-->{self.model_path} ' ) self.bert_path = os.path.join(base_dir, '../models' , 'bert-base-chinese' ) self.tokenizer = BertTokenizer.from_pretrained(self.bert_path) self.model = None self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu" ) self.logger.info(f"使用设备: {self.device} " ) self.load_model() self.label_map = {"通用知识" : 0 , "专业咨询" : 1 } def load_model (self ): if os.path.exists(self.model_path): self.model = BertForSequenceClassification.from_pretrained(self.model_path, num_labels=2 ).to(self.device) self.logger.info(f"加载已训练好的模型成功:{self.model_path} " ) else : self.model = BertForSequenceClassification.from_pretrained(self.bert_path, num_labels=2 ).to(self.device) self.logger.info(f"加载BERT模型成功:{self.bert_path} ,用于模型训练" ) def train_model (self, data_file ): """ 训练模型 :param data_file: 训练数据文件路径 :return: None """ if not os.path.exists(data_file): self.logger.error(f"数据集文件 {data_file} 不存在" ) raise FileNotFoundError(f"数据集文件 {data_file} 不存在" ) with open (data_file, 'r' , encoding='utf-8' ) as f: data = [json.loads(line) for line in f.readlines()] querys = [item['query' ] for item in data] labels = [item['label' ] for item in data] train_querys, val_querys, train_labels, val_labels = train_test_split(querys, labels, test_size=0.2 , random_state=42 ) train_encodings, train_labels = self.preprocess_data(train_querys, train_labels) val_encodings, val_labels = self.preprocess_data(val_querys, val_labels) train_dataset = self.create_dataset(train_encodings, train_labels) val_dataset = self.create_dataset(val_encodings, val_labels) training_args = TrainingArguments( output_dir="./bert_results" , num_train_epochs=3 , per_device_train_batch_size=8 , per_device_eval_batch_size=8 , warmup_steps=50 , weight_decay=0.01 , logging_dir="./bert_logs" , logging_steps=10 , evaluation_strategy="epoch" , save_strategy="epoch" , load_best_model_at_end=True , save_total_limit=1 , metric_for_best_model="eval_loss" , greater_is_better=False , fp16=False , ) trainer = Trainer( model=self.model, args=training_args, train_dataset=train_dataset, eval_dataset=val_dataset, compute_metrics=self.compute_metrics, ) self.logger.info("开始训练模型..." ) trainer.train() self.save_model() self.evaluate_model(self.model, val_dataset, val_labels) def preprocess_data (self, querys, labels ): """ 数据处理,将数据转换成模型训练需要的数据格式 :param querys: 查询数据列表 :param labels: 数据标签列表 """ encodings = self.tokenizer.batch_encode_plus(querys, truncation=True , padding=True , max_length=128 , return_tensors='pt' ) label_ids = [self.label_map[label] for label in labels] return encodings, label_ids def create_dataset (self, encodings, label_ids ): """ 创建数据集 :param encodings: 模型训练需要的编码数据 :param label_ids: 数据标签列表 """ class MyDataset (Dataset ): def __init__ (self, encodings, label_ids ): self.encodings = encodings self.label_ids = label_ids def __len__ (self ): return len (self.label_ids) def __getitem__ (self, idx ): item = {key: val[idx] for key, val in self.encodings.items()} item['labels' ] = torch.tensor(self.label_ids[idx]) return item return MyDataset(encodings, label_ids) def compute_metrics (self, eval_pred ): logits, labels = eval_pred predictions = np.argmax(logits, axis=-1 ) accuracy = np.mean(predictions ` labels) return {"accuracy" : accuracy} def save_model (self ): self.logger.info("保存模型..." ) self.model.save_pretrained(self.model_path) self.tokenizer.save_pretrained(self.model_path) self.logger.info(f"模型保存成功!保存路径为{self.model_path} " ) def evaluate_model (self, model, dataset, labels ): """ 评估模型 :param model: 模型 :param dataset: 测试数据集 :param labels: 真实标签 """ self.logger.info("开始评估模型..." ) trainer = Trainer(model=model) predict = trainer.predict(dataset) predict_labels = np.argmax(predict.predictions, axis=-1 ) real_labels = labels self.logger.info("打印分类报告..." ) self.logger.info(classification_report(real_labels, predict_labels, target_names=["通用知识" , "专业咨询" ])) self.logger.info("打印混淆矩阵..." ) self.logger.info(confusion_matrix(real_labels, predict_labels)) def predict_category (self, query ): if self.model is None : self.logger.error("模型未加载,请先加载模型!" ) return '通用知识' encoding = self.tokenizer(query, truncation=True , padding=True , max_length=128 , return_tensors='pt' ) encoding = {key: val.to(self.device) for key, val in encoding.items()} with torch.no_grad(): output = self.model(**encoding) predict_label = torch.argmax(output['logits' ], dim=-1 ).item() return '通用知识' if predict_label ` 0 else '专业咨询' if __name__ ` '__main__' : query_classifier = QueryClassifier() test_queries = [ "AI学科的课程大纲是什么" , "JAVA课程费用多少?" , "5*9等于多少?" , "AI培训有哪些老师?" ] for query in test_queries: category = query_classifier.predict_category(query) print (f"查询: {query} -> 分类: {category} " )
六、RAG系统工作流程实现 流程设计图
1 检索策略选择【掌握】 1.1 功能概述 strategy_selector.py定义了StrategySelector类,通过调用大语言模型根据用户查询选择最合适的检索策略。支持的策略包括直接检索、HyDE(假设问题检索)、子查询检索和回溯问题检索,旨在优化检索阶段的输入处理。
1.2 实现细节
__init__
作用 :初始化DashScope客户端和策略选择Prompt。逻辑 :连接大语言模型API,准备Prompt模板。
call_dashscope
作用 :封装DashScope API调用,处理异常并返回模型输出。逻辑 :确保API调用的鲁棒性,记录错误日志。
_get_strategy_prompt
作用 :定义用于策略选择的Prompt模板。设计逻辑 :简洁描述四种策略及其适用场景,要求模型直接返回策略名称。
select_strategy
作用 :根据查询调用模型选择策略并返回。逻辑 :记录选择的策略,便于调试。
1.3 代码示例 位置:integrated_qa_system/rag_qa/core/strategy_selector.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 from langchain.prompts import PromptTemplatefrom openai import OpenAIfrom integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerconf = Config() class StrategySelector : def __init__ (self ): self.logger = logger self.client = OpenAI(api_key=conf.DASHSCOPE_API_KEY, base_url=conf.DASHSCOPE_BASE_URL) self.strategy_prompt_template = self._get_strategy_prompt() def _get_strategy_prompt (self ): return PromptTemplate( template=""" 你是一个智能助手,负责分析用户查询 {query},并从以下四种检索增强策略中选择一个最适合的策略,直接返回策略名称,不需要解释过程。 以下是几种检索增强策略及其适用场景: 1. **直接检索:** * 描述:对用户查询直接进行检索,不进行任何增强处理。 * 适用场景:适用于查询意图明确,需要从知识库中检索**特定信息**的问题,例如: * 示例: * 查询:AI 学科学费是多少? * 思考:这个问题比较简单,直接查询就行,所以使用直接检索。 * 策略:直接检索 2. **假设问题检索(HyDE):** * 描述:使用 LLM 生成一个假设的答案,然后基于假设答案进行检索。 * 适用场景:适用于查询较为抽象,直接检索效果不佳的问题,例如: * 示例: * 查询:人工智能在教育领域的应用有哪些? * 思考:这个问题比较抽象,可以先生成一个近似的答案,再去检索这个答案相似的文档,效果更好,所以使用假设问题检索。 * 策略:假设问题检索 3. **子查询检索:** * 描述:将复杂的用户查询拆分为多个简单的子查询,分别检索并合并结果。 * 适用场景:适用于查询涉及多个实体或方面,需要分别检索不同信息的问题,例如: * 示例: * 查询:比较 Milvus 和 Zilliz Cloud 的优缺点。 * 思考:要想知道Milvus 和 Zilliz Cloud 的优缺点,需要分别查询Milvus的优缺点和Zilliz Cloud的优缺点,所以使用子查询检索。 * 策略:子查询检索 4. **回溯问题检索:** * 描述:将复杂的用户查询转化为更基础、更易于检索的问题,然后进行检索。 * 适用场景:适用于查询较为复杂,需要简化后才能有效检索的问题,例如: * 示例: * 查询:我是毕业于江西应用技术职业学院的大专生,专业是会计,可以报人工智能学科吗? * 思考:不论学生什么身份,只要查询报名要求就行了。可以对原问题进行简化,查询 '人工智能学科报名要求',所以使用回溯问题检索。 * 策略:回溯问题检索 根据用户查询 {query},直接返回最适合的策略名称,例如 "直接检索"。不要输出任何分析过程或其他内容。 """ , input_variables=["query" ], ) def call_dashscope (self, prompt ): try : completion = self.client.chat.completions.create( model=conf.LLM_MODEL, messages=[ {"role" : "system" , "content" : "你是一个有用的助手。" }, {"role" : "user" , "content" : prompt}, ], temperature=0.1 ) return completion.choices[0 ].message.content if completion.choices else "直接检索" except Exception as e: self.logger.error(f"DashScope API 调用失败: {e} " ) return "直接检索" def select_strategy (self, query ): prompt = self.strategy_prompt_template.format (query=query) strategy = self.call_dashscope(prompt).strip() self.logger.info(f"问题:{query} 策略选择结果: {strategy} " ) return strategy if __name__ ` '__main__' : selector = StrategySelector() print (selector.select_strategy("LSTM和RNN有什么区别" ))
2 Prompt管理【掌握】 2.1 功能概述 prompts.py定义了RAGPrompts类,负责管理系统中使用的所有Prompt模板。这些模板用于指导大语言模型完成不同任务,例如生成最终答案、假设答案、子查询或简化问题。通过集中管理Prompt,系统能够确保输入的一致性和输出质量。
2.2 实现细节
rag_prompt
作用 :核心回答模板,结合检索到的上下文生成最终答案。输入变量 :context(检索文档内容)、question(用户查询)、phone(客服电话)。设计逻辑 :支持有无上下文的回答,并提供兜底回复,确保用户体验。
hyde_prompt
作用 :生成假设答案,用于HyDE(Hypothetical Document Embeddings)策略,优化抽象查询的检索。输入变量 :query(用户查询)。设计逻辑 :通过生成假设答案,间接增强查询与文档的语义匹配。
subquery_prompt
作用 :将复杂查询分解为多个子查询,适合涉及多方面的查询。输入变量 :query(用户查询)。设计逻辑 :分解复杂问题以提高检索覆盖率。
backtracking_prompt
作用 :将复杂查询简化为更基础的问题,便于检索。输入变量 :query(用户查询)。设计逻辑 :通过简化查询降低检索难度。
2.3 代码实现 位置:integrated_qa_system/rag_qa/core/prompts.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from langchain.prompts import PromptTemplateclass RAGPrompts : @staticmethod def rag_prompt (): return PromptTemplate( template=""" 你是一个智能助手,帮助用户回答问题。 如果提供了上下文,请基于上下文回答;如果提供了上下文但上下文信息不足时,请回复:“信息不足,无法回答,请联系人工客服,电话:{phone}。” 如果没有上下文,请直接根据你的知识回答。 如果答案来源于检索到的文档,请在回答中说明。 直接生成答案即可。 上下文: '''{context}''' 问题: '''{question}''' 回答: """ , input_variables=["context" , "question" , "phone" ], )
3 RAG核心逻辑【掌握】 3.1 功能概述 rag_system.py定义了RAGSystem类,整合系统的各个模块,完成从查询输入到答案生成的完整流程。它通过查询分类选择处理路径,利用检索策略优化文档检索,并结合上下文生成最终答案。
3.2 实现细节
init :
作用 :初始化RAG系统,整合向量存储、大语言模型和其他核心组件。依赖 :依赖VectorStore、RAGPrompts、QueryClassifier和StrategySelector。
_retrieve_with_hyde :
作用 :生成假设答案并调用混合检索,适合抽象查询。逻辑 :使用hyde_prompt生成假设答案,传递给hybrid_search_with_rerank。
_retrieve_with_subqueries :
作用 :分解查询为子查询,分别检索并去重。逻辑 :使用subquery_prompt分解查询,合并结果并限制数量。
_retrieve_with_backtracking :
作用 :简化查询后检索,降低复杂度。逻辑 :使用backtracking_prompt简化查询,调用混合检索。
retrieve_and_merge :
作用 :根据策略选择执行检索,直接返回结果。优化 :移除冗余的合并逻辑,直接使用hybrid_search_with_rerank的结果(去重的父文档)。
generate_answer :
作用 :整合分类、检索和生成,输出最终答案。流程:
使用QueryClassifier判断查询类型。
“通用知识”直接生成答案,“专业咨询”触发检索。
结合上下文调用rag_prompt生成回答。
3.3 代码示例 位置:integrated_qa_system/rag_qa/core/rag_system.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 import timefrom integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerfrom integrated_qa_system.rag_qa.core.prompts import RAGPromptsfrom integrated_qa_system.rag_qa.core.query_classifier import QueryClassifierfrom integrated_qa_system.rag_qa.core.strategy_selector import StrategySelectorfrom integrated_qa_system.rag_qa.core.vector_store import VectorStoreconf = Config() class RAGSystem : def __init__ (self, llm ): self.logger = logger self.llm = llm self.vector_store = VectorStore() self.rag_prompt = RAGPrompts.rag_prompt() self.query_classifier = QueryClassifier(model_path="bert_query_classifier" ) self.strategy_selector = StrategySelector() def generate_answer (self, query, source_filter=None ): start_time = time.time() self.logger.info(f"开始处理查询: '{query} ', 学科过滤: {source_filter} " ) query_type = self.query_classifier.predict_category(query) self.logger.info(f"查询:{query} , 查询类别: {query_type} " ) if query_type ` "通用知识" : self.logger.info("查询为通用知识,直接调用 LLM" ) prompt_input = self.rag_prompt.format (question=query, context='' , phone=conf.CUSTOMER_SERVICE_PHONE) try : answer = self.llm(prompt_input) except Exception as e: self.logger.error(f"LLM 调用失败: {e} " ) answer = f"抱歉,处理您的通用知识问题时出错。请联系人工客服:{conf.CUSTOMER_SERVICE_PHONE} " end_time = time.time() self.logger.info(f"通用知识 查询结束,耗时: {end_time - start_time} s" ) return answer self.logger.info("查询为专业咨询,进行 RAG 检索" ) strategy = self.strategy_selector.select_strategy(query) ranked_chunks = self.retrieve_and_merge(query, source_filter, strategy) if ranked_chunks: context = '\n\n' .join([chunk.page_content for chunk in ranked_chunks]) self.logger.info(f"文档拼接完成,共 {len (ranked_chunks)} 个文档" ) else : context = '' self.logger.warning(f"没有通过RAG检索到相似文档,context为空" ) prompt_input = self.rag_prompt.format (question=query, context=context, phone=conf.CUSTOMER_SERVICE_PHONE) self.logger.debug(f"最终生成的提示词: {prompt_input} " ) try : answer = self.llm(prompt_input) except Exception as e: self.logger.error(f"LLM 调用失败: {e} " ) answer = f"抱歉,处理您的专业咨询问题时出错。请联系人工客服:{conf.CUSTOMER_SERVICE_PHONE} " end_time = time.time() self.logger.info(f"专业咨询 查询结束,耗时: {end_time - start_time} s" ) return answer def retrieve_and_merge (self, query, source_filter=None , strategy=None ): ''' :param query: 查询的问题 :param source_filter: 学科,用于做条件过滤的 :param strategy: 检索的策略 :return: 重排序后的去重的父块的文档信息 ''' if strategy is None : strategy = '直接检索' if strategy ` '假设问题检索' : ranked_chunks = self._retrieve_with_hyde(query, source_filter) elif strategy ` '子查询检索' : ranked_chunks = self._retrieve_with_sub_queries(query, source_filter) elif strategy ` '回溯问题检索' : ranked_chunks = self._retrieve_with_backtracking(query, source_filter) else : self.logger.info("使用 直接检索 " ) ranked_chunks = self.vector_store.hybrid_search_with_rerank(query=query, top_k=conf.RETRIEVAL_K, source_filter=source_filter) self.logger.info(f"策略 '{strategy} ' 检索到 {len (ranked_chunks)} 个候选文档" ) return ranked_chunks def _retrieve_with_hyde (self, query, source_filter=None ): self.logger.info("使用 假设问题检索 " ) hyde_prompt_template = RAGPrompts.hyde_prompt() try : hyde_answer = self.llm(hyde_prompt_template.format (query=query)).strip() self.logger.info(f"假设的答案: {hyde_answer} " ) return self.vector_store.hybrid_search_with_rerank(query=hyde_answer, top_k=conf.RETRIEVAL_K, source_filter=source_filter) except Exception as e: self.logger.error(f"HyDE 策略执行失败: {e} " ) return [] def _retrieve_with_sub_queries (self, query, source_filter=None ): self.logger.info("使用 子查询检索 " ) sub_query_prompt_template = RAGPrompts.subquery_prompt() try : sub_queries = self.llm(sub_query_prompt_template.format (query=query)).strip() sub_queries_list = [q.strip() for q in sub_queries.split('\n' ) if q.strip()] self.logger.info(f"子问题: {sub_queries_list} " ) all_docs = [] for sub_query in sub_queries_list: docs = self.vector_store.hybrid_search_with_rerank(query=sub_query, top_k=1 , source_filter=source_filter) all_docs.extend(docs) self.logger.info(f"子查询: {sub_query} , 检索到的文档个数: {len (docs)} " ) unique_docs = {doc.metadata['parent_id' ]: doc for doc in all_docs} unique_docs_list = list (unique_docs.values()) self.logger.info(f"去重前的文档个数: {len (all_docs)} 去重后的文档个数: {len (unique_docs_list)} " ) return unique_docs_list except Exception as e: self.logger.error(f"子查询策略执行失败: {e} " ) return [] def _retrieve_with_backtracking (self, query, source_filter=None ): self.logger.info("使用 回溯问题检索 " ) backtracking_prompt_template = RAGPrompts.backtracking_prompt() try : simple_query = self.llm(backtracking_prompt_template.format (query=query)).strip() self.logger.info(f"简化的问题: {simple_query} " ) return self.vector_store.hybrid_search_with_rerank(query=simple_query, top_k=conf.RETRIEVAL_K, source_filter=source_filter) except Exception as e: self.logger.error(f"回溯问题策略执行失败: {e} " ) return [] if __name__ ` '__main__' : llm = StrategySelector().call_dashscope rag_system = RAGSystem(llm) query = "我是学文科的,我叫张三,大专毕业,可以报名AI课程吗" answer = rag_system.generate_answer(query, source_filter="ai" ) print (f'answer-->{answer} ' )
4 完整流程的整合【实现】 4.1 从查询到回答的流程
查询分类 :
QueryClassifier分类查询,决定是否需要检索。
策略选择 :
StrategySelector根据查询选择最佳检索策略。
文档检索 :
根据策略调用VectorStore的混合检索,获取相关文档。
生成回答 :
4.2 代码示例 1 2 3 4 5 6 7 8 9 10 11 12 if __name__ ` '__main__' : llm = StrategySelector().call_dashscope rag_system = RAGSystem(llm) query = "我是学文科的,我叫张三,大专毕业,可以报名AI课程吗" answer = rag_system.generate_answer(query, source_filter="ai" ) print (f'answer-->{answer} ' )
七、RAG系统运行 1 系统运行入口【实现】 1.1 功能概述 main.py是EduRAG系统的运行入口,提供三种运行模式:
数据处理模式 :加载并向量化文档,构建向量数据库,支持多学科目录处理。查询模式 :通过命令行交互式回答用户查询,支持学科过滤。命令行模式 :增加了环境变量加载、详细的错误处理、命令行参数支持和用户友好的提示。
1.2 实现细节
环境变量加载 :
使用Config文件,确保API密钥等配置从环境变量读取。
LLM客户端初始化 :
增强错误处理,若初始化失败,在查询模式下退出,数据处理模式可继续。
定义call_dashscope函数,封装DashScope API调用,包含详细异常处理。
VectorStore初始化 :
使用显式参数初始化,确保配置可控,若失败则终止程序。
数据处理模式 :
遍历VALID_SOURCES,处理每个学科目录,记录处理的文档块数量。
支持自定义分块参数(如PARENT_CHUNK_SIZE)。
交互查询模式 :
显示支持的学科类别,提供输入提示。
校验source_filter,若无效则提示并忽略。
输出格式化答案,增强用户体验。
命令行参数 :
使用argparse支持--data-processing和--data-dir,提高灵活性。
1.3 完整代码 代码位置:integrated_qa_system/rag_qa/main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 import osimport sysbase_dir = os.path.dirname(os.path.abspath(__file__)) sys.path.append(os.path.join(base_dir, '../..' )) from openai import OpenAI from integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerfrom integrated_qa_system.rag_qa.core.document_processor import process_documentsfrom integrated_qa_system.rag_qa.core.rag_system import RAGSystemfrom integrated_qa_system.rag_qa.core.vector_store import VectorStoreconf = Config() def main (query_mode=True , directory_path="data" ): ''' :param query_mode: True代表是交互式查询模型,False代表数据处理模式 :param directory_path: 数据文件夹的路径 :return: ''' try : client = OpenAI(api_key=conf.DASHSCOPE_API_KEY, base_url=conf.DASHSCOPE_BASE_URL) except Exception as e: logger.error(f"初始化 OpenAI 客户端失败 (请检查 API Key 和 Base URL): {e} " ) if query_mode: logger.error("错误:无法初始化语言模型客户端,无法进入查询模式。" ) return client = None def call_dashscope (prompt ): if not client: logger.error("LLM 客户端未初始化,无法调用 call_dashscope" ) return f"错误: LLM客户端不可用" try : completion = client.chat.completions.create( model=conf.LLM_MODEL, messages=[ {"role" : "system" , "content" : "你是一个有用的助手。" }, {"role" : "user" , "content" : prompt}, ], temperature=0.1 ) if completion.choices and completion.choices[0 ].message: return completion.choices[0 ].message.content else : logger.error("LLM API 调用返回无效响应或空消息" ) return "错误: LLM返回无效响应" except Exception as e: logger.error(f"DashScope API 调用失败: {e} " ) return f"错误: 调用LLM失败 - {e} " if not query_mode: try : vector_store = VectorStore( collection_name=conf.MILVUS_COLLECTION_NAME, host=conf.MILVUS_HOST, port=conf.MILVUS_PORT, database=conf.MILVUS_DATABASE_NAME, ) except Exception as e: logger.error(f"初始化 VectorStore 失败 (请检查 Milvus 连接配置): {e} " ) return logger.info("进入数据处理模式..." ) total_chunks_added = 0 for source_dir in conf.VALID_SOURCES: dir_path = os.path.join(os.path.join(base_dir, directory_path), f"{source_dir} _data" ) if os.path.exists(dir_path): logger.info(f"开始处理目录: {dir_path} " ) try : chunks = process_documents( dir_path, conf.PARENT_CHUNK_SIZE, conf.CHILD_CHUNK_SIZE, conf.PARENT_OVERLAP, conf.CHILD_OVERLAP ) if chunks: vector_store.add_documents(chunks) total_chunks_added += len (chunks) logger.info(f"成功处理目录 {dir_path} ,添加了 {len (chunks)} 个文档块" ) else : logger.info(f"目录 {dir_path} 未发现有效文档或处理结果为空" ) except Exception as e: logger.error(f"处理目录 {dir_path} 时出错: {e} " ) else : logger.warning(f"目录 {dir_path} 不存在,跳过处理" ) else : if not client: print ("错误:查询模式需要语言模型客户端,但初始化失败。" ) return logger.info("进入交互式查询模式..." ) try : rag_system = RAGSystem(llm=call_dashscope) except Exception as e: logger.error(f"初始化 RAGSystem 失败: {e} " ) print ("错误:无法初始化 RAG 系统,无法进入查询模式。" ) return valid_sources = conf.VALID_SOURCES print ("\n欢迎使用 EduRAG 交互式查询系统!" ) print (f"支持的学科类别:{valid_sources} " ) print ("输入您的问题,或输入 'exit' 退出。" ) while True : query = input ("\n请输入您的问题:" ) if query.lower() ` "exit" : logger.info("用户退出查询模式" ) print ("再见!" ) break source_filter_input = input (f"请输入学科类别 ({'/' .join(valid_sources)} ) (直接回车默认不过滤):" ).strip() source_filter = None if source_filter_input: if source_filter_input in valid_sources: source_filter = source_filter_input logger.info(f"用户选择了学科过滤: {source_filter} " ) else : logger.warning(f"无效的学科类别 '{source_filter_input} ',将不过滤" ) print (f"提示:输入的学科 '{source_filter_input} ' 无效,将不过滤。" ) try : print ("正在生成答案,请稍候..." ) answer = rag_system.generate_answer(query, source_filter=source_filter) print ("-" * 30 ) print (f"问题: {query} " ) print (f"回答: {answer} " ) print ("-" * 30 ) except Exception as e: logger.error(f"处理查询 '{query} ' 时失败: {str (e)} " ) print (f"抱歉,处理您的问题时遇到了错误,请稍后重试或联系管理员。\n" ) if __name__ ` '__main__' : main()
2 RAG系统运行【实现】 命令行运行(main.py) :
1 2 3 4 5 6 7 8 if __name__ ` "__main__" : import argparse parser = argparse.ArgumentParser(description="EduRAG 系统主入口" ) parser.add_argument('--data-processing' , action='store_true' , help ='运行模式:默认为查询模式,设置后为数据处理模式。' ) parser.add_argument('--data-dir' , type =str , default='data' , help ='数据文件夹路径,传相对路径即可,默认为 data' ) args = parser.parse_args() main(query_mode=(not args.data_processing), directory_path=args.data_dir)
数据处理 :
1 python main.py --data-processing --data-dir data
查询模式 :
P06-RAG系统评估 1 评估数据集构造【掌握】 流程如下:
使用大模型生成测试样本,具体来说是使用Milvus中存储好的分块文档(子块内容),基于这些文档逆向生成问题和答案 ,这些数据构成了评估系统的基础。
使用大模型对测试样本进行质量审核,确保数据具备清晰性和可检索性。
使用RAG系统对测试样本进行处理,记录检索文档和最终答案,连同问题和真实答案,构造评估数据集,用于评估系统。
使用大模型或评估框架对RAG系统性能进行量化评估。
评估数据集格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [ { "question" : "人工智能就业课的课程版本是什么?", "context" : ["人工智能学科全新升级——人工智能开发V6.0课程。"], "answer" : "人工智能就业课的课程版本是V6.0。", "ground_truth" : "V6.0" }, { "question" : "课程的一句话概括是什么?", "context" : ["解锁「大模型」 新技能成就「高薪AI」人才"], "answer" : "课程的一句话概括是:解锁「大模型」新技能成就「高薪AI」人才。", "ground_truth" : "解锁「大模型」新技能成就「高薪AI」人才。" } ]
2 RAGAS评估框架【理解】 RAGAS (Retrieval Augmented Generation Assessment) 我们一般称为 Automated Evaluation of Retrieval Augmented Generation,即检索增强生成的自动评估。Ragas是一个大模型评测框架,可以评估检索增强生成(RAG)的效果,帮助分析模型的输出,了解模型在给定任务上的表现。Github地址: https://github.com/explodinggradients/ragas
3 评估指标【理解】 3.1 上下文相关性 (context precision)
3.2 上下文召回率 (context recall)
作用:衡量检索到的上下文(contexts)是否足够覆盖真实答案(ground_truths)。
该指标通过问题、标注答案和检索到的上下文计算,分数范围在0到1之间,得分越高表示性能更好。
要从真实答案中估计上下文召回率,需要分析真实答案中的每个事实(claim),以确定它是否可以从检索到的上下文中推理出来。理想情况下,真实答案中的所有事实都应该能从检索到的上下文中推出。
实现方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 假设真实答案(Reference Answer)为: 真实答案: “2010年世界杯的冠军是西班牙。” “西班牙在决赛中以1-0击败了荷兰。” RAG检索到的上下文(Retrieved Context)为: “西班牙在2010年世界杯的决赛中击败了荷兰。” “2010年世界杯的冠军是西班牙,西班牙队首次赢得世界杯。” 步骤具体实施: 事实1: "2010年世界杯的冠军是西班牙。" 输入给GPT-3.5:检索到的上下文 + 事实1。 GPT-3.5检查上下文是否包含“2010年世界杯的冠军是西班牙”。 结果:GPT-3.5发现上下文包含该信息,因此该事实“召回”。 事实2: "西班牙在决赛中以1-0击败了荷兰。" 输入给GPT-3.5:检索到的上下文 + 事实2。 GPT-3.5检查上下文是否包含“西班牙在决赛中以1-0击败了荷兰”。 结果:GPT-3.5确认上下文中提到西班牙击败了荷兰,但未提到具体的比分1-0,因此该事实“未召回”。 计算召回率: 总事实数:2(事实1和事实2)。 被召回的事实数:1(事实1被召回,事实2未召回)。 Context Recall =0.5
公式:
分子:GT claims that can be attributed to context,表示在真实答案(GT)中的事实中,有多少是可以归因于检索到的上下文的。换句话说,这些事实在检索到的上下文中找到了支持或依据。
分母:Number of claims in GT 表示真实答案中事实的总数量。
3.3 忠实度(faithfulness)
3.4 答案相关性(answer relevancy)
简单总结如下:
指标
阶段
作用
谁和谁
通俗理解
上下文相关性
检索
衡量检索到的文档是否全和原始问题有关系
文档与问题
开卷资料带没带对
上下文召回率
检索
衡量真实答案能否全从检索到的文档中推出来
真实答案与文档
开卷资料带没带全
忠实度
生成
衡量模型生成的答案能否全从检索到的文档中推出来
模型答案与文档
是不是根据开卷资料里回答的
答案相关性
生成
衡量模型生成的答案是否和原始问题有关系
模型答案与问题
有没有跑题(是否抄对资料)
4 RAGAS 评估脚本【实现】 1.1 功能描述 ragas_evaluate.py脚本用于评估RAG系统的性能,具体功能包括:
数据集加载 :从JSON文件加载包含问题、答案、上下文和真实答案的评估数据集。数据格式转换 :将JSON数据转换为RAGAS要求的Dataset格式。环境配置 :使用LangChain的OpenAI模型和嵌入模型初始化RAGAS评估环境。评估执行 :计算四个核心指标:
Context Precision(上下文相关性) :上下文是否与问题相关。Context Recall(上下文召回率) :上下文是否包含所有必要信息。Faithfulness(忠实度) :答案是否忠于上下文。Answer Relevancy(答案相关性) :答案与问题的匹配程度。
结果输出与保存 :打印评估结果并保存为CSV文件,便于后续分析。
1.2 代码实现 位置:integrated_qa_system/rag_qa/rag_evaluate/ragas_evaluate.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import pandas as pdimport jsonfrom datasets import Datasetfrom langchain_openai import ChatOpenAIfrom langchain_community.embeddings import DashScopeEmbeddingsfrom ragas import evaluatefrom ragas.metrics import ( faithfulness, answer_relevancy, context_precision, context_recall ) from integrated_qa_system.base.config import Configconf = Config() with open ('../data/rag_evaluate_data.json' , 'r' , encoding='utf-8' ) as f: data = json.load(f) print (f'data-->{len (data), data[:1 ]} ' ) eval_data = { "question" : [item["question" ] for item in data], "answer" : [item["answer" ] for item in data], "contexts" : [item["context" ] for item in data], "ground_truth" : [item["ground_truth" ] for item in data] } dataset = Dataset.from_dict(eval_data) print (f'dataset-->{len (dataset), dataset[:1 ]} ' )llm = ChatOpenAI(base_url=conf.DASHSCOPE_BASE_URL, model=conf.LLM_MODEL, api_key=conf.DASHSCOPE_API_KEY, temperature=0.1 ) embed = DashScopeEmbeddings(dashscope_api_key=conf.DASHSCOPE_API_KEY) result = evaluate( dataset=dataset, metrics=[ faithfulness, answer_relevancy, context_precision, context_recall ], llm=llm, embeddings=embed ) print (f"RAGAS评估结果:\n{result} " )result_df = pd.DataFrame([result]) result_df.to_csv("ragas_evaluation_results.csv" , index=False )
1.3 指标范围 一般企业中这几个指标的范围 :
context_recall:84%左右
context_precision:79%左右
faithfulness:92%左右
answer_relevancy:90%左右
注意:
context_precision和context_recall是负相关的。一般会牺牲context_precision来换取高的context_recall。
answer_relevancy是答案相关性,不等同于答案正确率,答案正确率由context_recall、faithfulness、answer_relevancy共同决定。答案正确率大概在75%。
faithfulness和answer_relevancy也是有负相关性的,只是没有那么强烈。在选择时,如果上下文检索的特别好,就可以提高faithfulness;如果上下文检索的不好,就提高answer_relevancy。
P07-融合MySQL的RAG系统 一、融合 FAQ 和知识库查询 1 查询流程图【掌握】 以下是智能问答系统的查询流程图,展示从用户输入到答案输出的完整逻辑。
2 流程说明【掌握】
输入处理 :用户提供查询 (query) 和可选的学科过滤 (source_filter)。BM25 搜索 :使用 BM25 算法在 MySQL 知识库中搜索,设置相似度阈值 0.85。答案判断 :
若找到可靠答案(相似度 > 0.85),直接返回。
若无可靠答案且需要 RAG,调用 RAG 系统生成答案。
若无可靠答案且不需要 RAG,则返回默认答案。
日志记录 :记录查询内容、答案和处理时间,便于调试和性能分析。输出 :将答案返回给用户。
3 代码介绍【理解】 以下是 old_main.py 的完整代码,包含详细注释,逐行解析功能与实现逻辑。
3.1 导入必备的工具包 位置:integrated_qa_system/old_main.py
1 2 3 4 5 6 7 8 9 10 11 import timefrom openai import OpenAIfrom integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerfrom integrated_qa_system.mysql_qa.cache.redis_client import RedisClientfrom integrated_qa_system.mysql_qa.db.mysql_client import MySQLClientfrom integrated_qa_system.mysql_qa.retrieval.bm25_search import BM25Searchfrom integrated_qa_system.rag_qa.core.rag_system import RAGSystemconf = Config()
3.2 系统初始化
(__init__) 初始化方法
功能 :初始化日志、配置、数据库客户端、搜索模块、向量存储和 RAG 系统。关键点 :通过 Config 管理 API 密钥和模型参数,异常处理确保 OpenAI 客户端初始化成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class IntegratedQASystem : def __init__ (self ): self.logger = logger self.mysql_client = MySQLClient() self.redis_client = RedisClient() self.bm25_search = BM25Search(self.mysql_client, self.redis_client) try : self.client = OpenAI(api_key=conf.DASHSCOPE_API_KEY, base_url=conf.DASHSCOPE_BASE_URL) except Exception as e: self.logger.error(f'创建OpenAI客户端失败!{e} ' ) self.rag_system = RAGSystem(llm=self.call_dashscope)
3.3 调用 DashScope API
(call_dashscope) 方法
功能 :通过 OpenAI 客户端调用 DashScope API,基于用户提示生成答案。关键点 :设置系统提示为“你是一个有用的助手”,异常处理捕获 API 调用失败,返回错误信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def call_dashscope (self, prompt ): if not self.client: logger.error("LLM 客户端未初始化,无法调用 call_dashscope" ) return f"错误: LLM客户端不可用" try : completion = self.client.chat.completions.create( model=conf.LLM_MODEL, messages=[ {"role" : "system" , "content" : "你是一个有用的助手。" }, {"role" : "user" , "content" : prompt}, ], temperature=0.1 ) if completion.choices and completion.choices[0 ].message: return completion.choices[0 ].message.content else : self.logger.error("DashScope API 调用返回无效响应或空消息" ) return "错误:LLM返回无效响应或空消息" except Exception as e: self.logger.error(f"DashScope API 调用失败: {e} " ) return f'错误:LLM API 调用失败 {e} '
3.4 查询处理
(query) 方法
功能 :处理用户查询,优先通过 BM25 搜索 MySQL,若无可靠答案则使用 RAG 系统。关键点 :设置 BM25 相似度阈值 0.85,记录查询和处理时间,支持学科过滤。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 def query (self, query, source_filter=None ): start_time = time.time() self.logger.info(f"处理查询: '{query} '" ) answer, need_rag = self.bm25_search.search(query, threshold=0.85 ) if answer: self.logger.info(f"找到缓存的可靠答案: {answer} " ) processing_time = time.time() - start_time self.logger.info(f"查询处理耗时 {processing_time:.2 f} 秒" ) return answer elif need_rag: self.logger.info("未找到缓存的可靠答案,需要 RAG 搜索" ) answer = self.rag_system.generate_answer(query, source_filter) self.logger.info(f"RAG 答案: {answer} " ) processing_time = time.time() - start_time self.logger.info(f"查询处理耗时 {processing_time:.2 f} 秒" ) return answer else : self.logger.info("未找到缓存的答案,且不需要 RAG 搜索" ) answer = f"抱歉,处理您的问题时出错。请联系人工客服:{conf.CUSTOMER_SERVICE_PHONE} " processing_time = time.time() - start_time self.logger.info(f"查询处理耗时 {processing_time:.2 f} 秒" ) return answer
3.5 命令行交互
(main) 函数
功能 :提供交互式命令行界面,接受用户查询和学科过滤,显示答案。关键点 :验证学科过滤的有效性,异常处理和资源清理确保系统健壮。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def main (): qa_system = IntegratedQASystem() try : print ("\n欢迎使用集成问答系统!" ) print (f"支持的来源: {conf.VALID_SOURCES} " ) print ("输入查询进行问答,输入 'exit' 退出。" ) while True : query = input ("\n输入查询: " ).strip() if query.lower() ` "exit" : logger.info("退出系统" ) print ("再见!" ) break source_filter = input (f"输入来源过滤 ({'/' .join(conf.VALID_SOURCES)} ) (按 Enter 跳过): " ).strip() if source_filter and source_filter not in conf.VALID_SOURCES: logger.warning(f"无效来源 '{source_filter} ',忽略过滤" ) print (f"无效来源 '{source_filter} ',继续无过滤。" ) source_filter = None answer = qa_system.query(query, source_filter) print (f"\n答案: {answer} " ) except Exception as e: logger.error(f"系统错误: {e} " ) print (f"发生错误: {e} " ) finally : qa_system.mysql_client.close()
二、融合 FAQ 和知识库查询-优化版 new_main.py 是对 old_main.py 的优化版本,新增了对话历史管理和流式输出功能,增强了交互性和实时性。
1 查询流程图【掌握】 以下是优化后的智能问答系统查询流程图,展示用户输入到答案输出的处理逻辑,包括对话历史和流式输出。
2 流程说明【掌握】
输入处理 :用户提供查询 (query)、会话 ID (session_id) 和可选的学科过滤 (source_filter)。会话管理 :若提供 session_id,从 MySQL 获取最近 5 轮对话历史;否则生成新的 UUID。BM25 搜索 :使用 BM25 算法搜索 MySQL 知识库,设置相似度阈值 0.85。答案判断 :
若找到可靠答案(相似度 > 0.85),一次性返回。
若无可靠答案且需要 RAG,调用 RAG 系统以流式方式生成答案。
若无可靠答案且不需要 RAG,则一次性返回默认答案。
历史更新 :将查询和答案存入 MySQL 的 conversations 表。输出 :通过流式输出(RAG)或一次性输出(MySQL)返回答案,并展示对话历史。
3 代码介绍 以下是 new_main.py 的完整代码,包含逐行注释,详细解析功能与实现逻辑。
3.1 导入必备的工具包【实现】 位置:integrated_qa_system/new_main.py
1 2 3 4 5 6 7 8 9 10 11 12 import timefrom openai import OpenAIimport uuid from integrated_qa_system.base.config import Configfrom integrated_qa_system.base.create_logger import loggerfrom integrated_qa_system.mysql_qa.cache.redis_client import RedisClientfrom integrated_qa_system.mysql_qa.db.mysql_client import MySQLClientfrom integrated_qa_system.mysql_qa.retrieval.bm25_search import BM25Searchfrom integrated_qa_system.rag_qa.core.rag_system import RAGSystemconf = Config()
3.2 系统初始化【实现】
(__init__) 初始化方法
功能 :初始化日志、配置、数据库客户端、搜索模块、向量存储、RAG 系统和对话历史表。关键点 :通过 Config 管理 API 密钥和模型参数,异常处理确保 OpenAI 客户端初始化成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class IntegratedQASystem : def __init__ (self ): self.logger = logger self.mysql_client = MySQLClient() self.redis_client = RedisClient() self.bm25_search = BM25Search(self.mysql_client, self.redis_client) try : self.client = OpenAI(api_key=conf.DASHSCOPE_API_KEY, base_url=conf.DASHSCOPE_BASE_URL) except Exception as e: self.logger.error(f'创建OpenAI客户端失败!{e} ' ) self.rag_system = RAGSystem(llm=self.call_dashscope)
3.3 调用 DashScope API【实现】 除了原有的call_dashscope外,还需要有call_dashscope_stream方法。
(call_dashscope_stream) 方法
功能 :通过 OpenAI 客户端调用 DashScope API,支持流式输出,逐 token 返回答案。关键点 :启用 stream=True 实现流式输出,异常处理捕获 API 调用失败,支持前端实时显示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 def call_dashscope (self, prompt ): if not self.client: logger.error("LLM 客户端未初始化,无法调用 call_dashscope" ) return f"错误: LLM客户端不可用" try : completion = self.client.chat.completions.create( model=conf.LLM_MODEL, messages=[ {"role" : "system" , "content" : "你是一个有用的助手。" }, {"role" : "user" , "content" : prompt}, ], temperature=0.1 ) if completion.choices and completion.choices[0 ].message: return completion.choices[0 ].message.content else : self.logger.error("DashScope API 调用返回无效响应或空消息" ) return "错误:LLM返回无效响应或空消息" except Exception as e: self.logger.error(f"DashScope API 调用失败: {e} " ) return f'错误:LLM API 调用失败 {e} ' def call_dashscope_stream (self, prompt ): if not self.client: logger.error("LLM 客户端未初始化,无法调用 call_dashscope" ) return f"错误: LLM客户端不可用" try : completion = self.client.chat.completions.create( model=conf.LLM_MODEL, messages=[ {"role" : "system" , "content" : "你是一个有用的助手。" }, {"role" : "user" , "content" : prompt}, ], temperature=0.1 , stream=True , timeout=30 ) for chunk in completion: if chunk.choices and chunk.choices[0 ].delta.content: yield chunk.choices[0 ].delta.content except Exception as e: self.logger.error(f"DashScope API 调用失败: {e} " ) yield f'错误:LLM API 调用失败 {e} '
3.4 对话历史表初始化【实现】
功能 :在 MySQL 中创建 conversations 表,存储会话 ID、问题、答案和时间戳,添加索引优化查询。然后向MySQL中插入一些测试数据,方便代码开发。
以下代码在MySQL中运行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 CREATE TABLE IF NOT EXISTS subjects_kg.conversations ( id INT AUTO_INCREMENT PRIMARY KEY, session_id VARCHAR (36 ) NOT NULL , question TEXT NOT NULL , answer TEXT NOT NULL , timestamp DATETIME NOT NULL , INDEX idx_session_id (session_id) ); insert into subjects_kg.conversations values (1 , 'a' , '什么是AI' , '人工智能' , now()), (2 , 'a' , '什么是java' , '编程语言' , now()+ 1 ), (3 , 'a' , '什么是ops' , '运维' , now()+ 2 ), (4 , 'a' , '什么是test' , '测试' , now()+ 3 ), (5 , 'a' , '什么是bigdata' , '大数据' , now()+ 4 ), (6 , 'a' , '什么是fe' , '前端' , now()+ 5 );
3.5 获取最近对话历史【实现】
(get_session_history) 方法
功能 :从 MySQL 的 conversations 表获取指定 session_id 的最近 5 轮对话历史。关键点 :使用参数化查询防止 SQL 注入,返回结果按时间正序,异常处理确保健壮性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def get_session_history (self, session_id: str ) -> list : """获取最近5轮对话历史""" try : self.mysql_client.cursor.execute(""" SELECT question, answer FROM subjects_kg.conversations WHERE session_id = %s ORDER BY timestamp DESC LIMIT %s """ , (session_id, 5 )) history = self.mysql_client.cursor.fetchall() history_list = [{"question" : q, "answer" : a} for q, a in history] return history_list[::-1 ] except Exception as e: self.logger.error(f"获取对话历史失败: {e} " ) return []
3.6 更新会话历史【实现】
(update_session_history) 方法
功能 :将新问题和答案插入 conversations 表。关键点 :使用事务确保数据一致性,日志记录操作结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def update_session_history (self, session_id: str , question: str , answer: str ) -> list : """更新会话历史到MySQL""" try : self.mysql_client.cursor.execute(""" INSERT INTO subjects_kg.conversations (session_id, question, answer, timestamp) VALUES (%s, %s, %s, NOW()) """ , (session_id, question, answer)) self.mysql_client.connection.commit() self.logger.info(f"会话 {session_id} 历史更新成功" ) except Exception as e: self.logger.error(f"更新会话历史意外错误: {e} " ) self.mysql_client.connection.rollback() raise
3.7 清除会话历史【实现】
(clear_session_history) 方法
功能 :删除指定 session_id 的所有对话历史记录。关键点 :使用参数化查询防止 SQL 注入,事务管理确保操作原子性,返回布尔值表示成功或失败。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def clear_session_history (self, session_id: str ) -> bool : """清除指定会话历史""" try : self.mysql_client.cursor.execute(""" DELETE FROM subjects_kg.conversations WHERE session_id = %s """ , (session_id,)) self.mysql_client.connection.commit() self.logger.info(f"会话 {session_id} 历史已清除" ) return True except Exception as e: self.logger.error(f"清除会话历史失败: {e} " ) self.mysql_client.connection.rollback() return False
3.8 查询处理【掌握】
(query) 方法
功能 :处理用户查询,优先使用 BM25 搜索 MySQL,若无可靠答案则回退到 RAG,支持流式输出和对话历史。关键点 :通过生成器逐 token 返回 RAG 答案,记录处理时间,支持学科过滤。注意 :1.需要RAGPrompts中添加rag_prompt_with_history方法;2.需要RAGSystem中添加generate_answer_stream方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def query (self, query, source_filter=None , session_id=None ): start_time = time.time() self.logger.info(f"处理查询: '{query} ', 会话ID: {session_id} " ) answer, need_rag = self.bm25_search.search(query, threshold=0.85 ) history_list = self.get_session_history(session_id) if session_id else [] if answer: self.logger.info(f"找到缓存的可靠答案: {answer} " ) if session_id: self.update_session_history(session_id, query, answer) processing_time = time.time() - start_time self.logger.info(f"查询处理耗时 {processing_time:.2 f} 秒" ) yield answer, True elif need_rag: self.logger.info("未找到缓存的可靠答案,需要 RAG 搜索" ) llm_answer = '' for token in self.rag_system.generate_answer_stream(query, llm_stream=self.call_dashscope_stream, source_filter=source_filter, history=history_list): llm_answer += token yield token, False self.logger.info(f"RAG 答案: {llm_answer} " ) if session_id: self.update_session_history(session_id, query, llm_answer) processing_time = time.time() - start_time self.logger.info(f"查询处理耗时 {processing_time:.2 f} 秒" ) yield '' , True else : self.logger.info("未找到缓存的答案,且不需要 RAG 搜索" ) answer = f"抱歉,处理您的问题时出错。请联系人工客服:{conf.CUSTOMER_SERVICE_PHONE} " if session_id: self.update_session_history(session_id, query, answer) processing_time = time.time() - start_time self.logger.info(f"查询处理耗时 {processing_time:.2 f} 秒" ) yield answer, True
需要RAGPrompts中添加rag_prompt_with_history方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @staticmethod def rag_prompt_with_history (): return PromptTemplate( template=""" 你是一个智能助手,负责帮助用户回答问题。请按照以下步骤处理: 1. **分析问题和上下文**: - 如果提供了上下文,请基于上下文回答。 - 如果没有上下文,请直接根据你的知识回答和对话历史来回答。 - 如果答案来源于检索到的文档,请在回答中明确说明,例如:“根据提供的文档,……”。 2. **评估对话历史**: - 检查对话历史是否与当前问题相关(例如,是否涉及相同的话题、实体或问题背景)。 - 如果对话历史与问题相关,请结合历史信息生成更准确的回答。 - 如果对话历史无关(例如,仅包含问候或不相关的内容),忽略历史,仅基于上下文和问题回答。 3. **生成回答**: - 如果没有提供上下文,也没有提供对话历史,则调用自身知识来回答。 - 如果没有提供上下文,只提供了对话历史,但是对话历史又和当前问题无关,则调用自身知识来回答。 - 如果提供了上下文,但仍然不足以回答问题,并且对话历史中也没有答案,则回复:“信息不足,无法回答,请联系人工客服,电话:{phone}。” - 提供清晰、准确的回答,避免无关信息。 **上下文**: '''{context}''' **对话历史**: '''{history}''' **问题**: '''{question}''' **回答**: """ , input_variables=["context" , "history" , "question" , "phone" ], )
需要RAGSystem中添加generate_answer_stream方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 def generate_answer_stream (self, query, llm_stream, source_filter=None , history=None ): start_time = time.time() self.logger.info(f"开始处理查询: '{query} ', 学科过滤: {source_filter} " ) if history is None or not isinstance (history, list ): self.logger.warning(f"历史对话为空,将使用空历史对话" ) history_context = '' else : history_context = '\n' .join([f"Question:{qa['question' ]} \nAnswer:{qa['answer' ]} " for qa in history]) self.logger.info(f"历史对话拼接完成,示例:{history_context[:50 ]} " ) query_type = self.query_classifier.predict_category(query) self.logger.info(f"查询:{query} , 查询类别: {query_type} " ) if query_type ` "通用知识" : self.logger.info("查询为通用知识,直接调用 LLM" ) prompt_input = RAGPrompts.rag_prompt_with_history().format (question=query, context='' , phone=conf.CUSTOMER_SERVICE_PHONE, history=history_context) try : for token in llm_stream(prompt_input): yield token except Exception as e: self.logger.error(f"LLM 调用失败: {e} " ) yield f"抱歉,处理您的通用知识问题时出错。请联系人工客服:{conf.CUSTOMER_SERVICE_PHONE} " end_time = time.time() self.logger.info(f"通用知识 查询结束,耗时: {end_time - start_time} s" ) return self.logger.info("查询为专业咨询,进行 RAG 检索" ) strategy = self.strategy_selector.select_strategy(query) ranked_chunks = self.retrieve_and_merge(query, source_filter, strategy) if ranked_chunks: context = '\n\n' .join([chunk.page_content for chunk in ranked_chunks]) self.logger.info(f"文档拼接完成,共 {len (ranked_chunks)} 个文档" ) else : context = '' self.logger.warning(f"没有通过RAG检索到相似文档,context为空" ) prompt_input = RAGPrompts.rag_prompt_with_history().format (question=query, context=context, phone=conf.CUSTOMER_SERVICE_PHONE, history=history_context) self.logger.debug(f"最终生成的提示词: {prompt_input} " ) self.logger.info(f"检索耗时: {time.time() - start_time} s" ) try : for token in llm_stream(prompt_input): yield token except Exception as e: self.logger.error(f"LLM 调用失败: {e} " ) yield f"抱歉,处理您的专业咨询问题时出错。请联系人工客服:{conf.CUSTOMER_SERVICE_PHONE} " end_time = time.time() self.logger.info(f"专业咨询 查询结束,耗时: {end_time - start_time} s" ) return
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 if __name__ ` '__main__' : qa_system = IntegratedQASystem() query = 'AI课程都学什么?' for anwer, is_complete in qa_system.query(query, session_id='a' ): if anwer: print (anwer, end="" , flush=True ) if is_complete: break
3.9 命令行交互【实现】
(main) 函数
功能 :提供交互式命令行界面,生成唯一会话 ID,接受用户查询和学科过滤,流式显示答案并展示对话历史。关键点 :支持流式输出,验证学科过滤有效性,异常处理和资源清理确保系统健壮。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 def main (): qa_system = IntegratedQASystem() session_id = str (uuid.uuid4()) try : print ("\n欢迎使用集成问答系统!" ) print (f"支持的来源: {conf.VALID_SOURCES} " ) print ("输入查询进行问答,输入 'exit' 退出。" ) while True : query = input ("\n输入查询: " ).strip() if query.lower() ` "exit" : logger.info("退出系统" ) print ("再见!" ) break source_filter = input (f"输入来源过滤 ({'/' .join(conf.VALID_SOURCES)} ) (按 Enter 跳过): " ).strip() if source_filter and source_filter not in conf.VALID_SOURCES: logger.warning(f"无效来源 '{source_filter} ',忽略过滤" ) print (f"无效来源 '{source_filter} ',继续无过滤。" ) source_filter = None print ("\n答案: " , end="" , flush=True ) answer = "" for token, is_complete in qa_system.query(query, source_filter=source_filter, session_id=session_id): if token: answer += token print (token, end="" , flush=True ) if is_complete: print () break history = qa_system.get_session_history(session_id) print ("\n最近对话历史:" ) for idx, entry in enumerate (history, 1 ): print (f"{idx} . 问: {entry['question' ]} \n 答: {entry['answer' ]} " ) except Exception as e: logger.error(f"系统错误: {e} " ) print (f"发生错误: {e} " ) finally : qa_system.mysql_client.close()

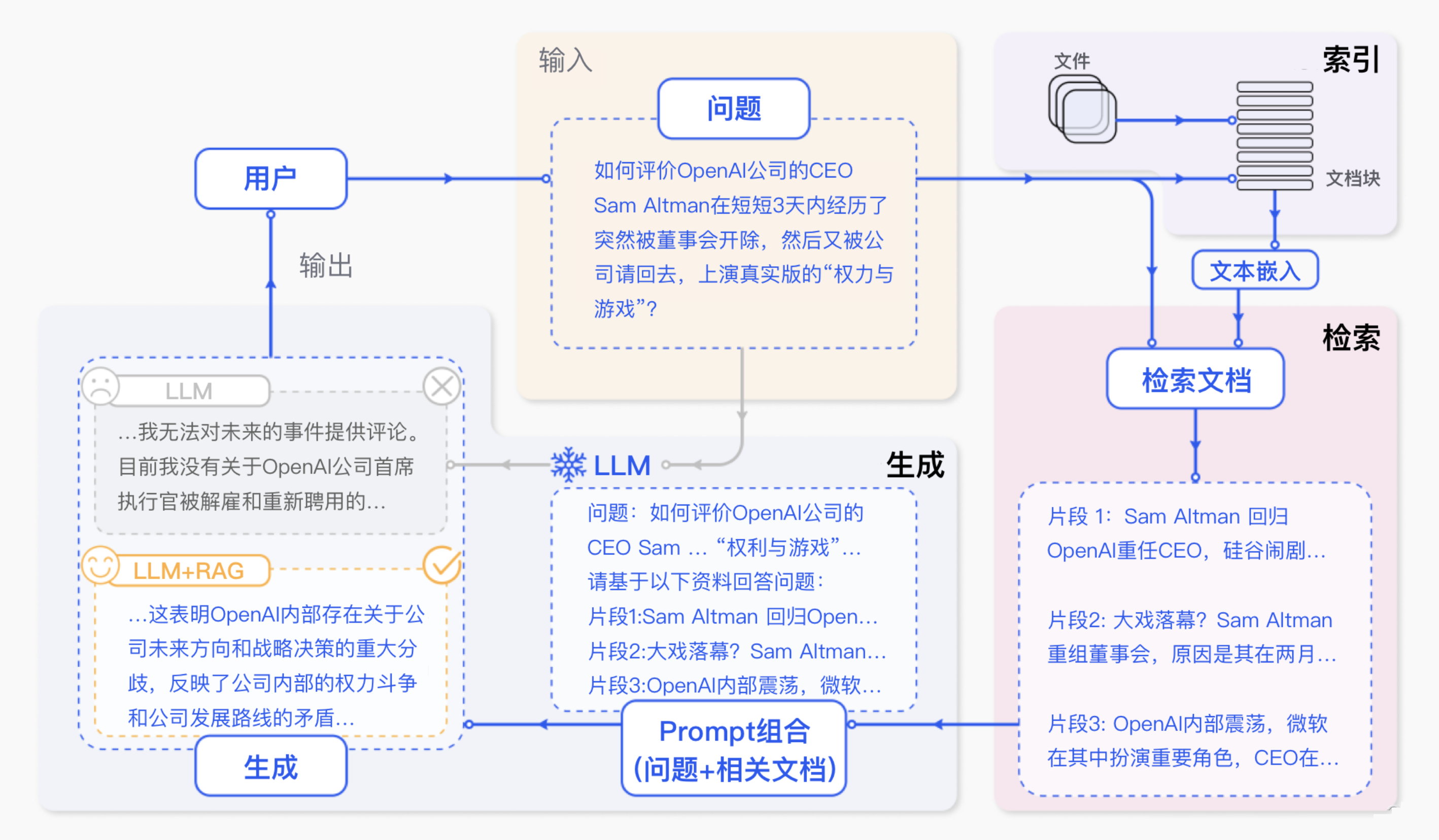
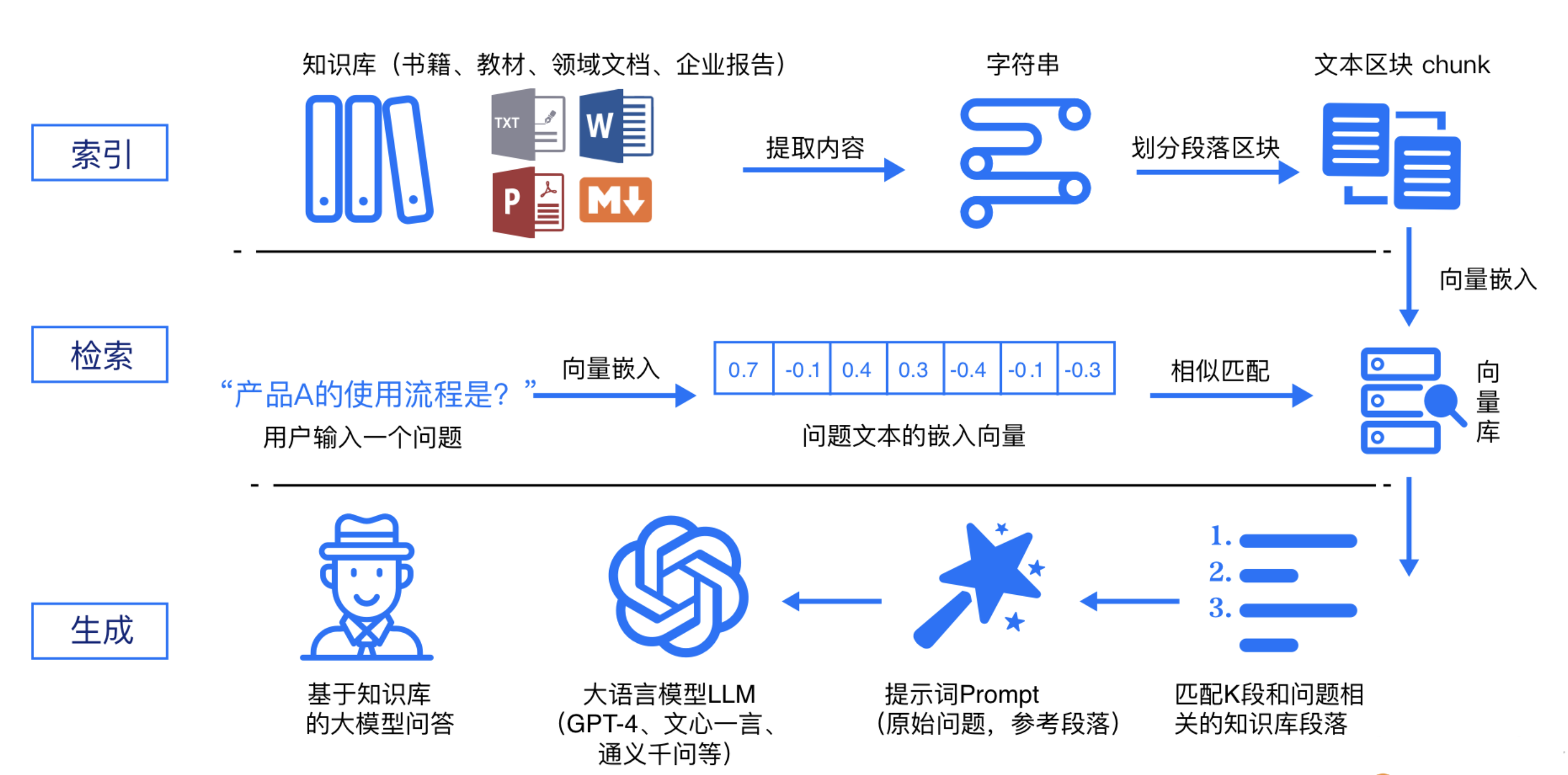
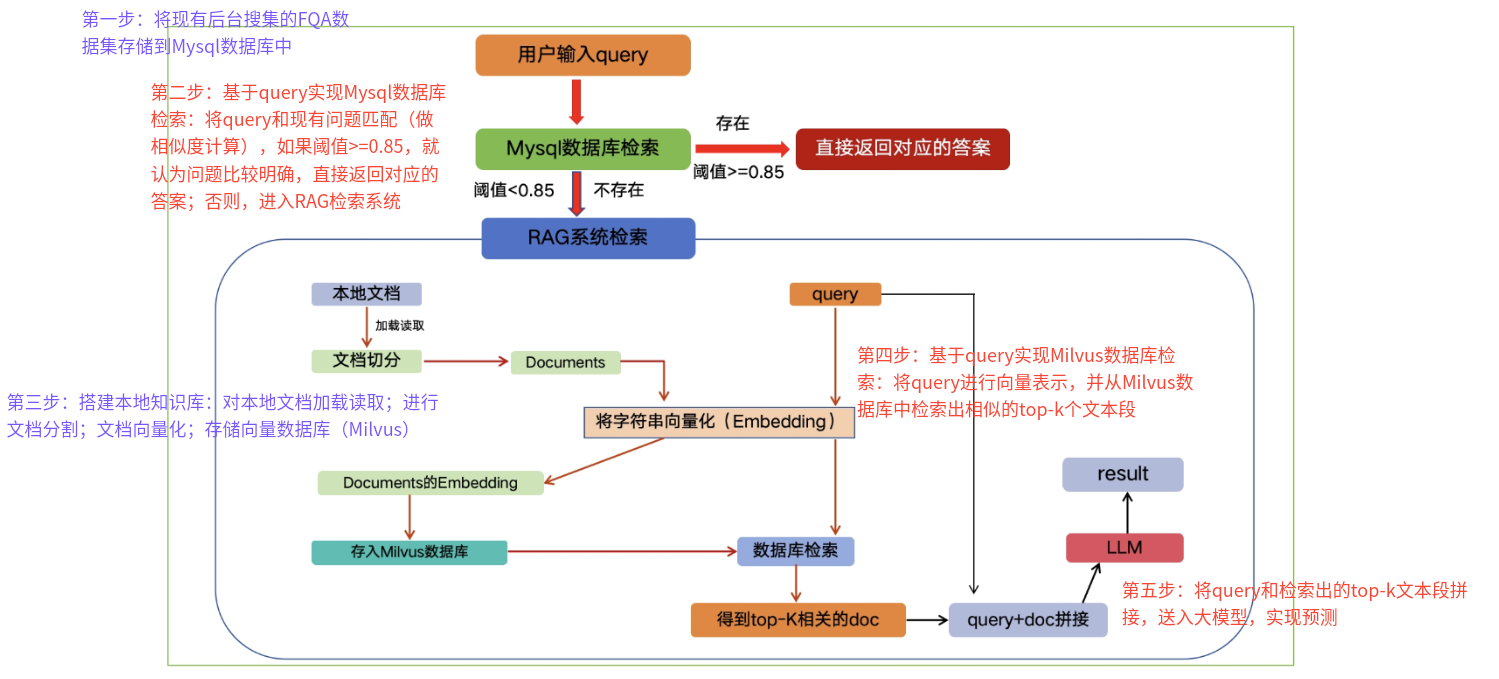
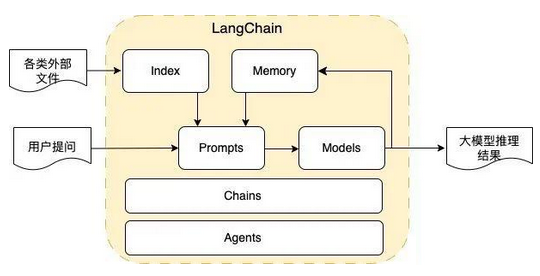












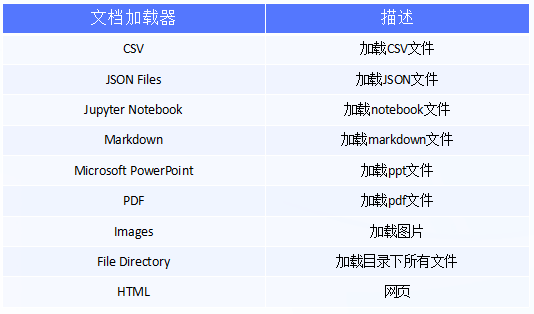


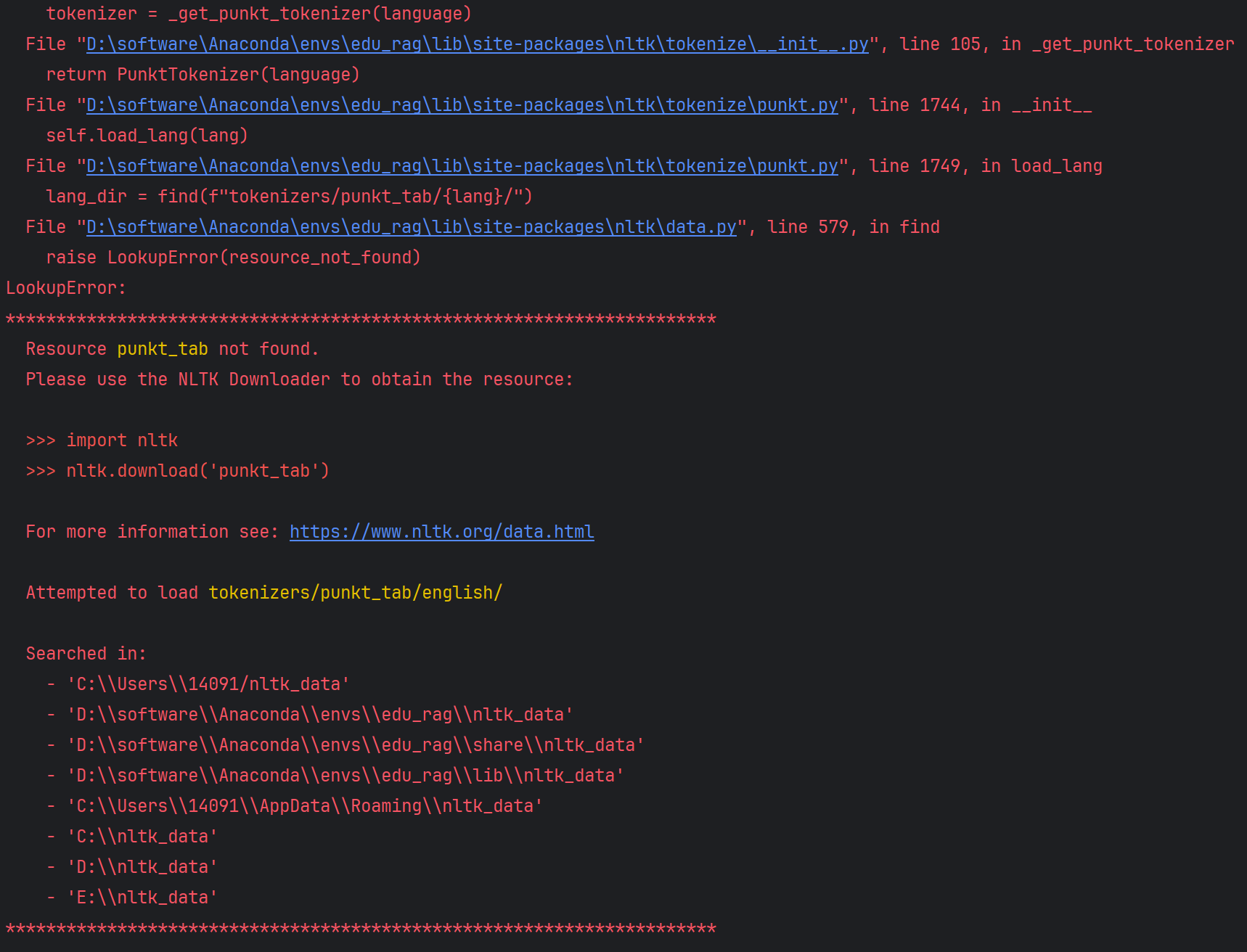
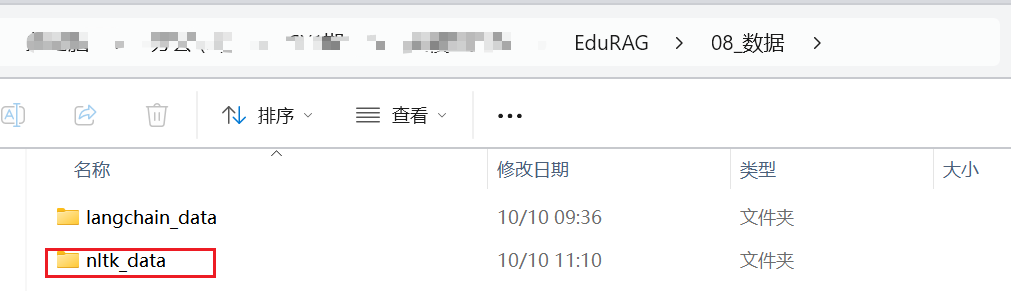



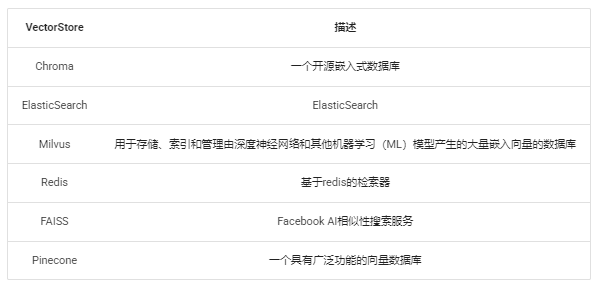

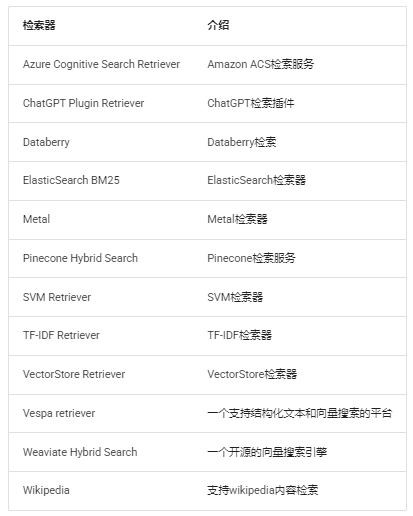







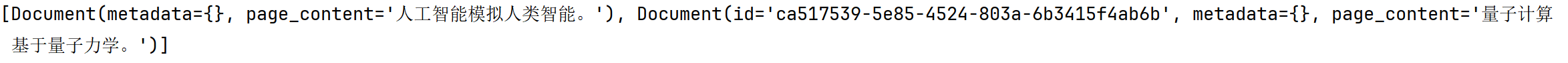


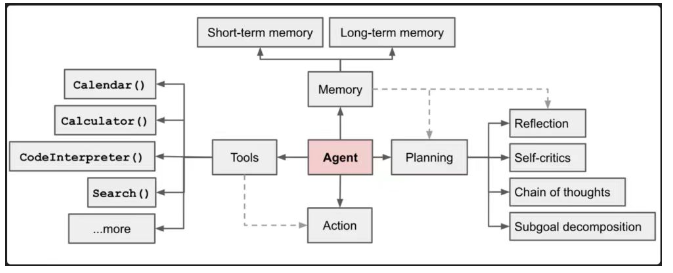

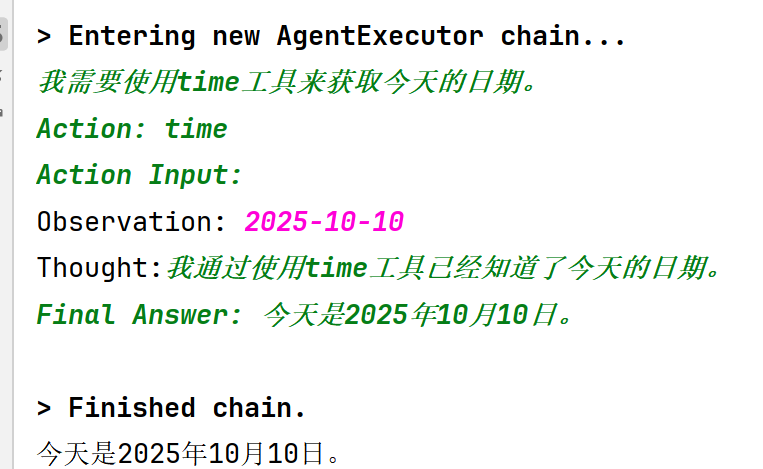
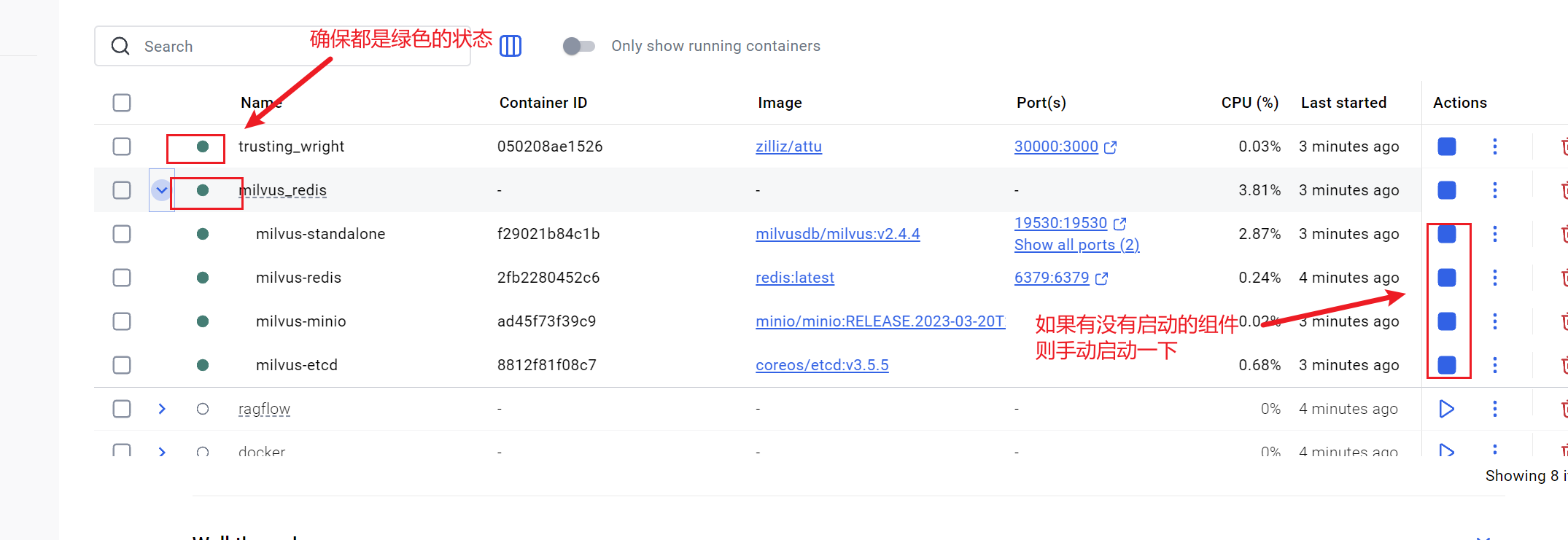
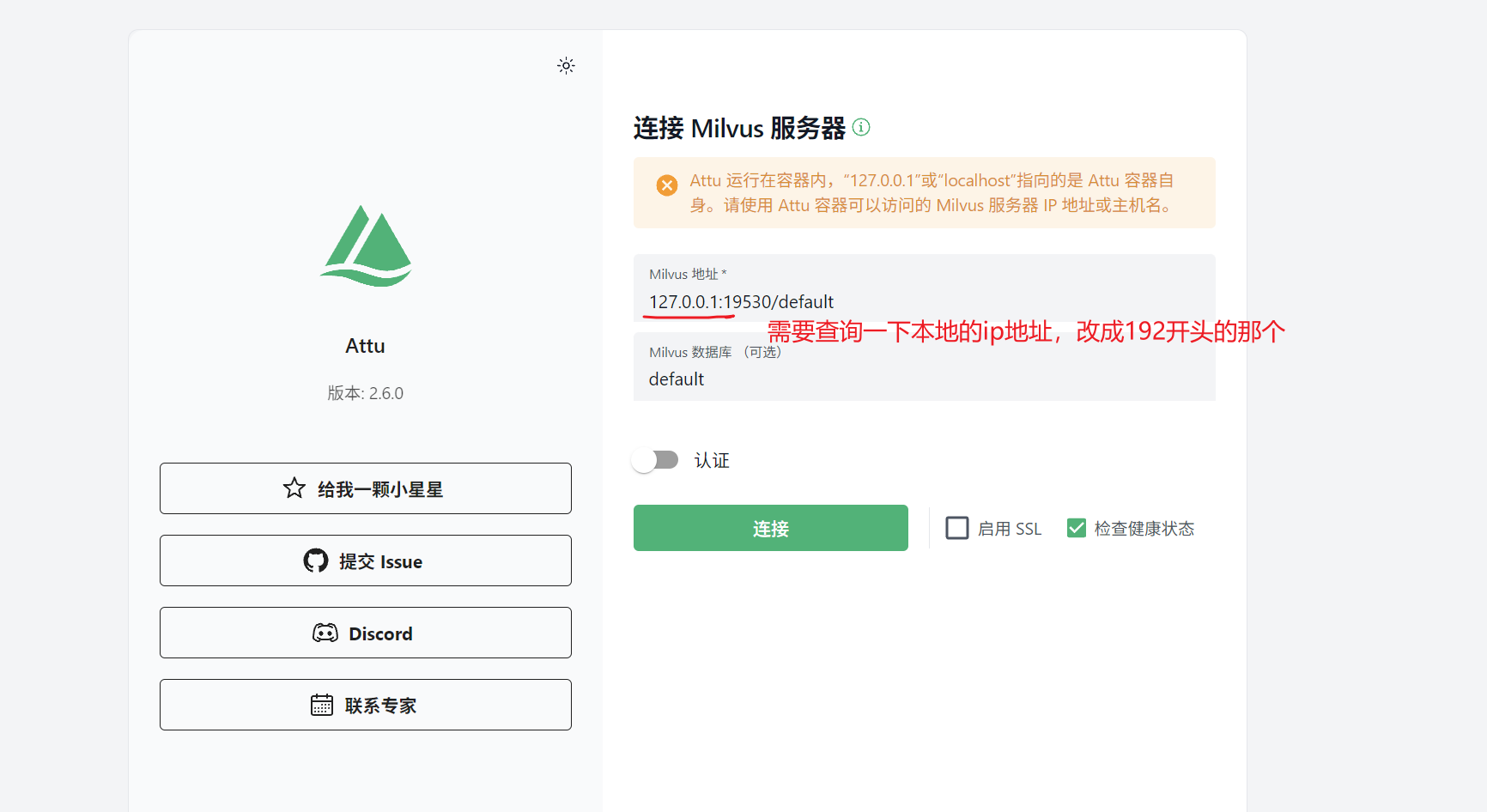
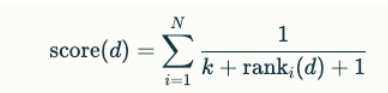
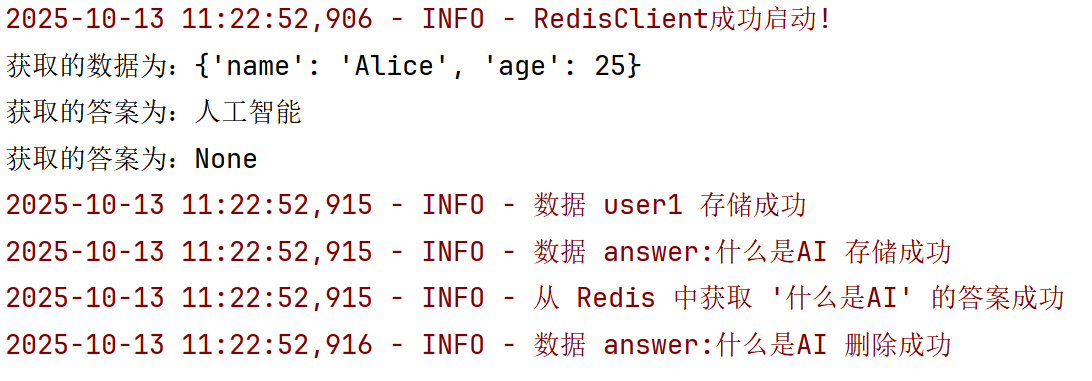
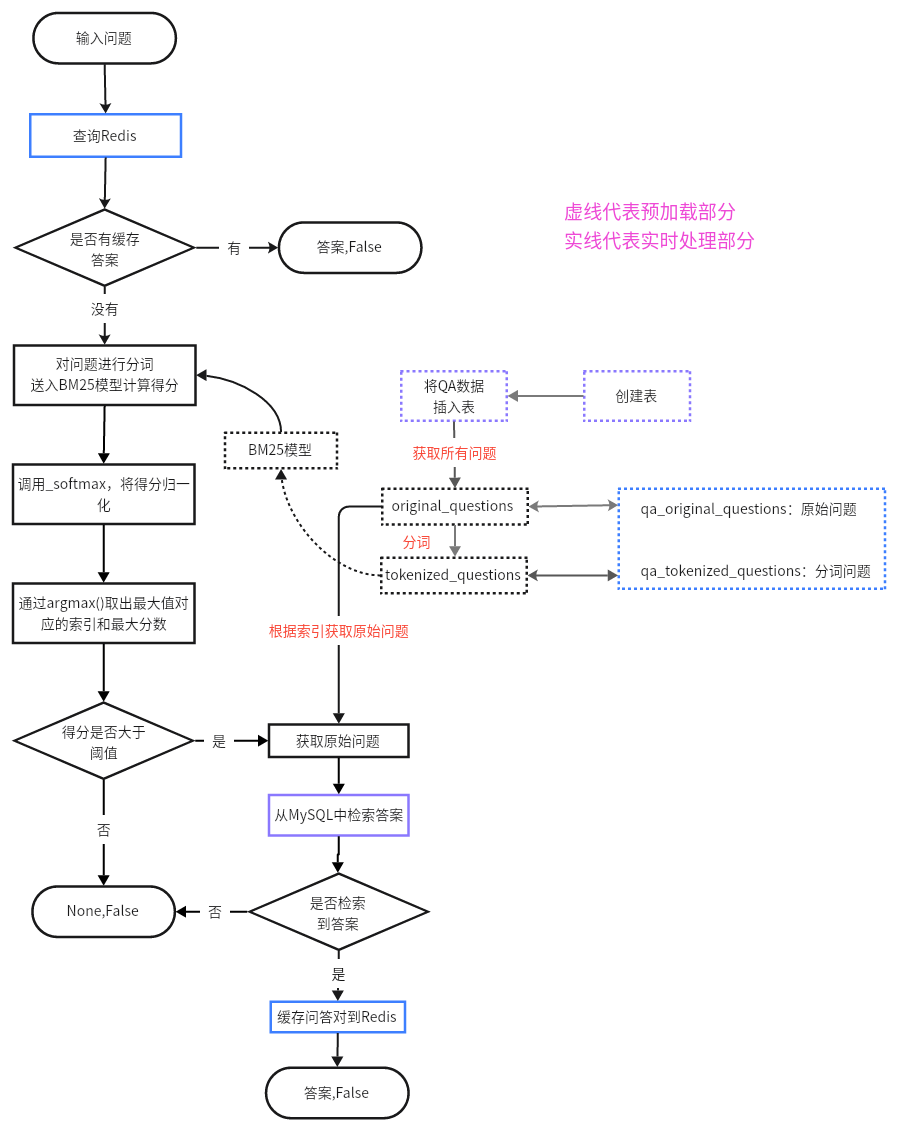


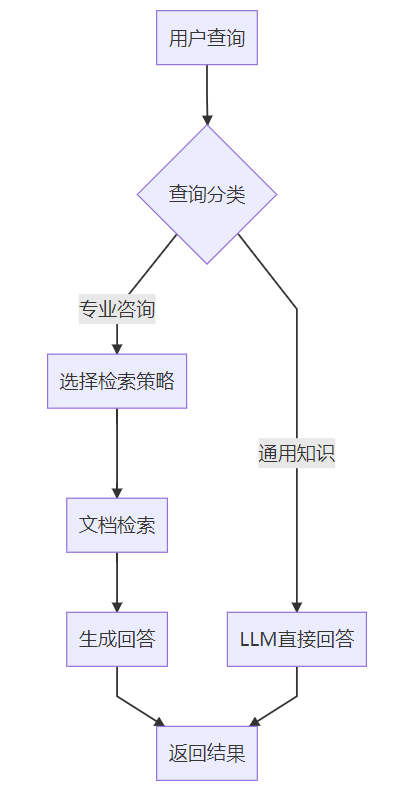
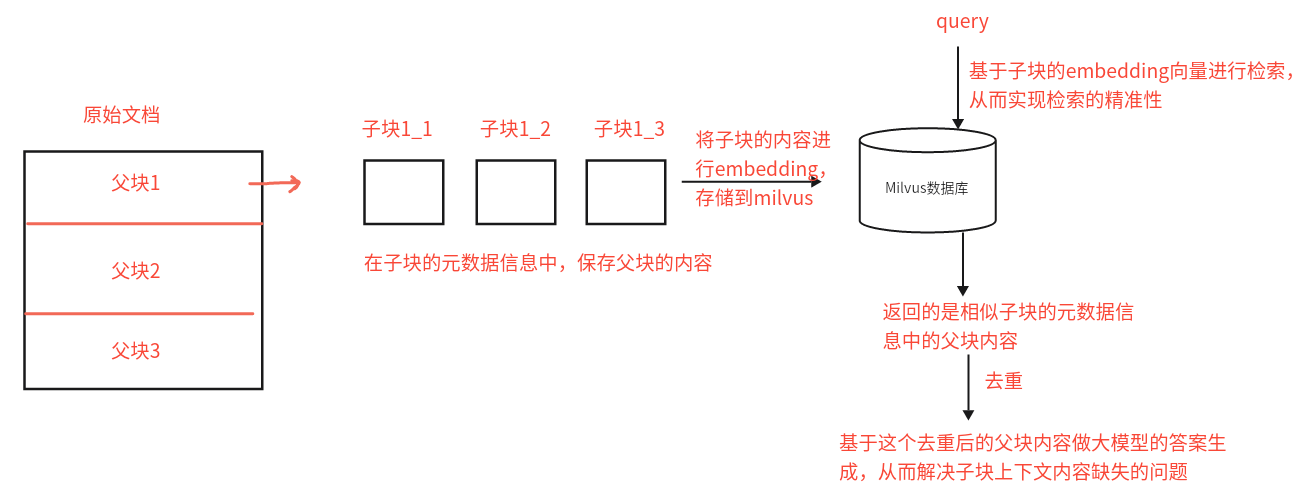

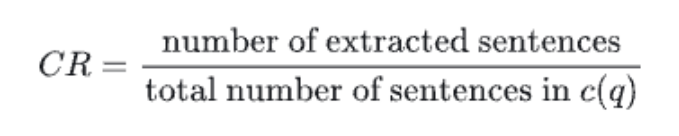
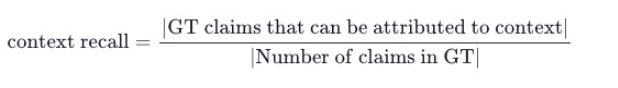
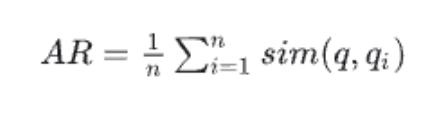
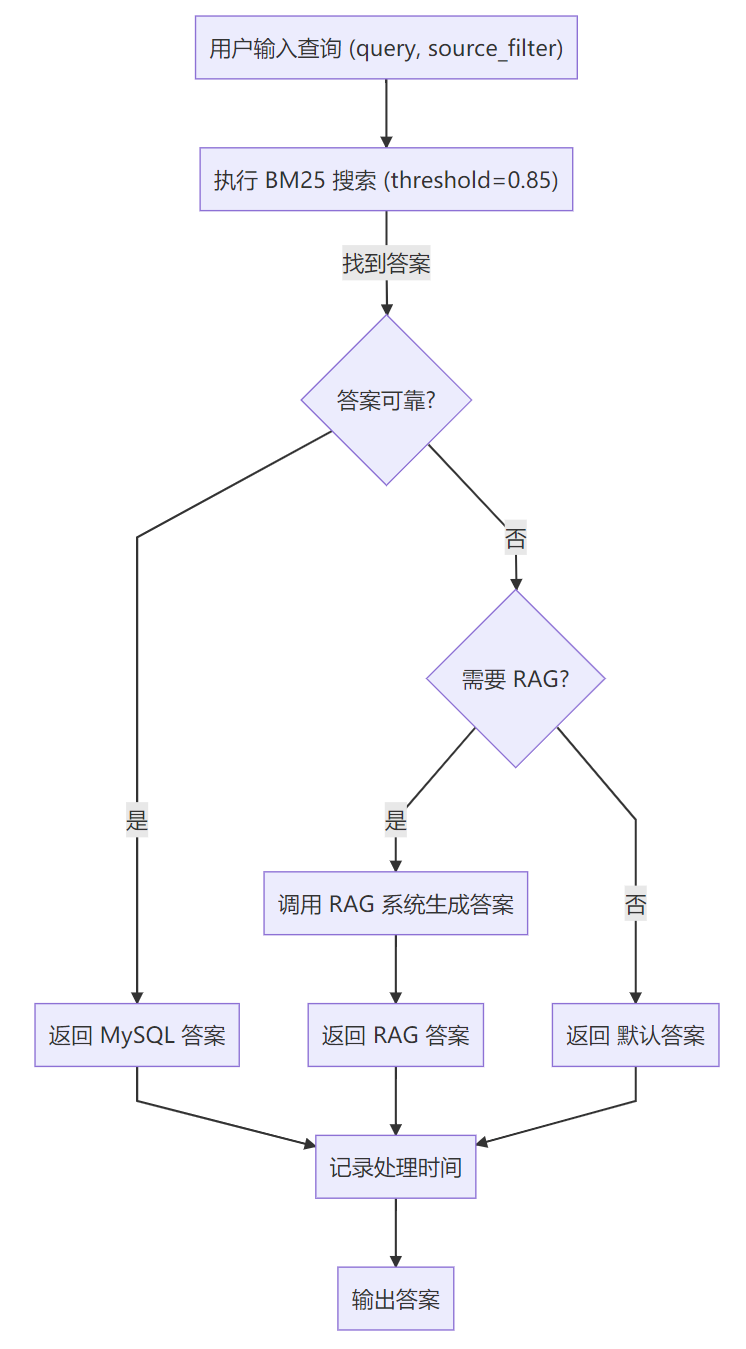
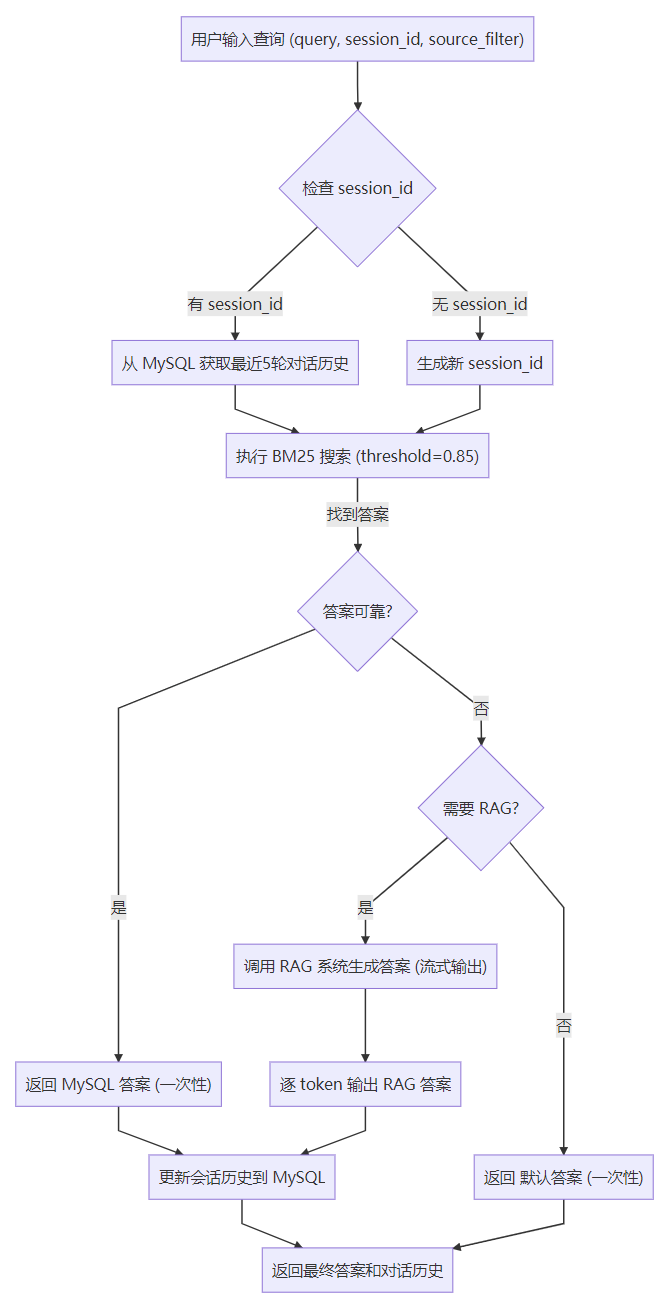
 微信
微信 支付宝
支付宝