P01_项目技术 一、Function Call 函数调用 1 什么是Function Call【理解】 概念:大模型基于具体任务,智能决策何时需要调用某个函数,同时返回符合函数参数的 JSON对象。
能力获得的方式:基于训练来得到的,所以并不是所有大模型都具有Function Call能力。
优势:信息实时性、数据局限性、功能扩展性。
2 Function Call 工作原理【理解】 主要步骤:
用户(client)发请求提示词,chat server将提示词和可以调用的函数发送给大模型
GPT模型根据用户的提示词,判断是用普通文本还是函数调用的格式回复我们的服务(chat server)
如果是函数调用格式,那么chat server就会执行这个函数,并且将结果返回给GPT
然后模型使用提供的数据,用连贯的文本响应。
3 Function Call 使用方式 代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 from langchain_openai import ChatOpenAIfrom langchain_core.messages import HumanMessage, ToolMessagefrom agent_learn.config import Configconf = Config() def add (a: int , b: int ) -> int : """ 将数字a与数字b相加 Args: a: 第一个数字 b: 第二个数字 """ return a + b def multiply (a: int , b: int ) -> int : """ 将数字a与数字b相乘 Args: a: 第一个数字 b: 第二个数字 """ return a * b tools = [ { "type" : "function" , "function" : { "name" : "add" , "description" : "将数字a与数字b相加" , "parameters" : { "type" : "object" , "properties" : { "a" : { "type" : "integer" , "description" : "第一个数字" }, "b" : { "type" : "integer" , "description" : "第二个数字" } }, "required" : ["a" , "b" ] } } }, { "type" : "function" , "function" : { "name" : "multiply" , "description" : "将数字a与数字b相乘" , "parameters" : { "type" : "object" , "properties" : { "a" : { "type" : "integer" , "description" : "第一个数字" }, "b" : { "type" : "integer" , "description" : "第二个数字" } }, "required" : ["a" , "b" ] } } } ] llm = ChatOpenAI(base_url=conf.base_url, model=conf.model_name, api_key=conf.api_key, temperature=0.2 ) llm_with_tools = llm.bind_tools(tools, tool_choice="auto" ) query = "2+1等于多少?" messages = [HumanMessage(query)] try : ai_msg = llm_with_tools.invoke(messages) messages.append(ai_msg) print (f"\n第一轮调用后结果:\n{messages} " ) if hasattr (ai_msg, "tool_calls" ) and ai_msg.tool_calls: for tool_call in ai_msg.tool_calls: func = {"add" : add, "multiply" : multiply}[tool_call["name" ].lower()] tool_result = func(**tool_call["args" ]) messages.append(ToolMessage(content=tool_result, tool_call_id=tool_call["id" ])) print (f"\n工具调用结果添加到messages后:\n{messages} " ) final_response = llm_with_tools.invoke(messages) print (f"\n最终模型响应:\n{final_response.content} " ) else : print ("模型未生成工具调用,直接返回文本:" ) print (ai_msg.content) except Exception as e: print (f"调用失败:{e} " )
注意:
1 2 3 4 llm.invoke(messages, tools=tools, ...): 绑定方式 : 直接在 .invoke() 调用中传入 tools 参数。这是一种临时、一次性的绑定方式,仅对本次调用有效。 调用方式 : 如果你想再次调用模型并使用工具,你必须在下一次 .invoke() 调用中再次传递 tools 参数。 适用场景 : 适用于简单、单次的工具调用需求,
以下是代码通过装饰器@tool的方式进行工具定义:
定义方式 :通过 @tool 装饰器直接装饰一个普通的 Python 函数,比如 add 和 multiply。
工作原理 :@tool 装饰器会自动根据函数签名(如 a: int, b: int)和文档字符串生成一个完整的工具定义(schema),包括工具名称、描述和参数结构。
优势 :
简洁高效 :这是最简单、最 Pythonic 的方式,几乎不需要额外的样板代码。你只需编写核心函数逻辑,工具定义部分由框架自动处理。自动化 :LangChain 的工具系统会自动处理工具的封装和调用,包括基本的参数类型验证。
使用的方法:
1)添加注解
from langchain_core.tools import tool
在函数名上使用@tool进行注解
2)定义tools
tools = [add, multiply]
3)解析参数,调用函数
1 2 tool_result = func.invoke(tool_call["args" ])
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 from langchain_core.tools import toolfrom langchain_openai import ChatOpenAIfrom langchain_core.messages import HumanMessage, ToolMessagefrom agent_learn.config import Configconf = Config() @tool def add (a: int , b: int ) -> int : """ 将数字a与数字b相加 Args: a: 第一个数字 b: 第二个数字 """ return a + b @tool def multiply (a: int , b: int ) -> int : """ 将数字a与数字b相乘 Args: a: 第一个数字 b: 第二个数字 """ return a * b tools = [add, multiply] llm = ChatOpenAI(base_url=conf.base_url, model=conf.model_name, api_key=conf.api_key, temperature=0.2 ) llm_with_tools = llm.bind_tools(tools, tool_choice="auto" ) query = "2+1等于多少?" messages = [HumanMessage(query)] try : ai_msg = llm_with_tools.invoke(messages) messages.append(ai_msg) print (f"\n第一轮调用后结果:\n{messages} " ) if hasattr (ai_msg, "tool_calls" ) and ai_msg.tool_calls: for tool_call in ai_msg.tool_calls: func = {"add" : add, "multiply" : multiply}[tool_call["name" ].lower()] tool_result = func.invoke(tool_call["args" ]) messages.append(ToolMessage(content=tool_result, tool_call_id=tool_call["id" ])) print (f"\n工具调用结果添加到messages后:\n{messages} " ) final_response = llm_with_tools.invoke(messages) print (f"\n最终模型响应:\n{final_response.content} " ) else : print ("模型未生成工具调用,直接返回文本:" ) print (ai_msg.content) except Exception as e: print (f"调用失败:{e} " )
通过严格数据校验pydantic进行工具定义:
定义方式 :创建一个继承自 BaseModel 的类,用类型注解和 Field 定义工具的参数。同时,需要在类中手动实现一个 invoke 方法来包含工具的执行逻辑。
工作原理 :
数据验证 :Pydantic 提供了强大的数据验证功能。当工具被调用时,它会自动验证传入的参数是否符合你在 BaseModel 中定义的类型和约束。手动实现 :与 @tool 不同,Pydantic 本身不提供工具的执行逻辑。因此,你必须显式地编写 invoke 方法来处理参数并返回结果。
优势 :
强大的数据验证 :Pydantic 提供了比 @tool 更细粒度和更丰富的参数验证功能,可以定义更复杂的约束。高度可控 :由于 invoke 方法是手动实现的,你可以完全控制工具的执行逻辑,例如添加复杂的预处理、错误处理或自定义逻辑。清晰的结构 :工具的参数定义和执行逻辑被封装在一个类中,使得代码结构更加清晰。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 from langchain_core.tools import toolfrom langchain_openai import ChatOpenAIfrom langchain_core.messages import HumanMessage, ToolMessagefrom pydantic.v1 import BaseModel, Fieldfrom agent_learn.config import Configconf = Config() class Add (BaseModel ): """ 将两个数字相加 """ a: int = Field(..., description="第一个数字" ) b: int = Field(..., description="第二个数字" ) def invoke (self, args ): tool_instance = self.__class__(**args) return tool_instance.a + tool_instance.b class Multiply (BaseModel ): """ 将两个数字相乘 """ a: int = Field(..., description="第一个数字" ) b: int = Field(..., description="第二个数字" ) def invoke (self, args ): tool_instance = self.__class__(**args) return tool_instance.a * tool_instance.b tools = [Add, Multiply] llm = ChatOpenAI(base_url=conf.base_url, model=conf.model_name, api_key=conf.api_key, temperature=0.2 ) llm_with_tools = llm.bind_tools(tools, tool_choice="auto" ) query = "2.1 + 1 等于多少?" messages = [HumanMessage(query)] try : ai_msg = llm_with_tools.invoke(messages) messages.append(ai_msg) print (f"\n第一轮调用后结果:\n{messages} " ) if hasattr (ai_msg, "tool_calls" ) and ai_msg.tool_calls: for tool_call in ai_msg.tool_calls: func_class = {"add" : Add, "multiply" : Multiply}[tool_call["name" ].lower()] func_obj = func_class(**tool_call["args" ]) tool_result = func_obj.invoke(tool_call["args" ]) messages.append(ToolMessage(content=tool_result, tool_call_id=tool_call["id" ])) print (f"\n工具调用结果添加到messages后:\n{messages} " ) final_response = llm_with_tools.invoke(messages) print (f"\n最终模型响应:\n{final_response.content} " ) else : print ("模型未生成工具调用,直接返回文本:" ) print (ai_msg.content) except Exception as e: print (f"调用失败:{e} " )
总结:
特性
JSON Schema
@tool 装饰器
Pydantic
定义方式
手动编写 Python 字典(JSON Schema)
装饰 Python 函数
继承 Pydantic BaseModel
自动化程度
低:完全手动定义和分发
高:自动生成 Schema 和调用逻辑
中等:自动验证数据,但需手动实现 invoke
数据验证
需要手动验证或依赖外部库
基础类型检查
强大:提供丰富的验证功能
适用场景
需要与其他系统集成、通用性和最大灵活性的场景
快速开发、简单工具、原型验证
需要复杂数据验证、清晰结构和自定义逻辑的场景
Agent(智能体)是一种能够感知环境、进行决策和执行动作的智能实体。从大模型的角度来看,Agent其实就是基于大模型的语义理解和推理能力,让大模型拥有解决复杂问题时的任务规划能力,并调用外部工具来执行各种任务,并且能够保留“记忆”的一个智能体 。
Agent = 大模型 + 任务规划(Planning) + 使用外部工具执行任务(Tools&Action) + 记忆(Memory)
Agent的核心就是大模型,它调用工具的方式通常通过Function Call实现,不够很多的Agent框架对内部的调用过程进行了封装,所以更易使用。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from langchain.agents import initialize_agent, AgentTypefrom langchain_core.tools import toolfrom langchain_openai import ChatOpenAIfrom langchain_core.messages import HumanMessage, ToolMessagefrom agent_learn.config import Configconf = Config() @tool def add (a: int , b: int ) -> int : """ 将数字a与数字b相加 Args: a: 第一个数字 b: 第二个数字 """ return a + b @tool def multiply (a: int , b: int ) -> int : """ 将数字a与数字b相乘 Args: a: 第一个数字 b: 第二个数字 """ return a * b tools = [add, multiply] llm = ChatOpenAI(base_url=conf.base_url, model=conf.model_name, api_key=conf.api_key, temperature=0.2 ) agent = initialize_agent(tools, llm, AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True ) query = "2+1等于多少?" result = agent.invoke(query) print (f'result-->{result} ' )
二、MCP协议 1 背景 【了解】 使用function call时,需要对工具的描述,这是一个繁琐而复杂的过程。MCP的出现就是将这些工具的描述和调用进行统一。
2 什么是MCP协议【理解】 MCP(Model Context Protocol,模型上下文协议)是由 Anthropic 在2024年1月提出的一套开放协议,旨在实现大型语言模型(LLM)与外部数据源和工具的无缝集成,用来在大模型和数据源之间建立安全双向的链接。
2.1 MCP 核心架构 MCP协议有两个核心角色:客户端与服务端。
MCP服务端 (Tool Provider):
角色 :工具的提供者。职责 :将一个或多个本地函数(例如,Python函数)包装起来,通过一个标准的MCP接口暴露出去。它监听来自客户端的请求,执行对应的函数,并返回结果。例子 :一个天气查询服务、一个数学计算服务、一个数据库访问服务。
MCP客户端 (Tool Consumer) :
角色 :工具的调用者或消费者。职责 :连接到MCP服务端,查询可用的工具列表(自发现),并根据需要调用这些工具。例子 :大模型Agent、自动化脚本、任何需要远程执行功能的应用程序。
MCP 主机(MCP Hosts)指的是发起请求的 LLM 应用程序。MCP 客户端(MCP Clients)指的是在主机程序内部的一个对象。
2.2 MCP 工具调用流程 步骤 1:客户端注册并连接 MCP Server
MCP Client 启动后,根据配置文件或命令参数连接多个 MCP Server。
每个 Server 都会返回一份工具描述列表(Tool Manifest),包括:
1 2 3 4 5 6 7 8 [ { "name" : "query_mysql" , "description" : "执行 SQL 查询" , "input_schema" : { ...} , "output_schema" : { ...} } ]
Client 将这些工具的元信息缓存并上报给 LLM,使大模型“知道”有哪些可用工具。
步骤 2:LLM 接收用户输入并决定调用工具
用户输入请求(如:“帮我查一下 users 表中有多少行数据”)。
LLM 分析语义后,判断需要使用 query_mysql 工具。
LLM 生成 function calling 格式的调用指令:
1 2 3 4 5 6 { "name" : "query_mysql" , "arguments" : { "sql" : "SELECT COUNT(*) FROM users;" } }
步骤 3:MCP Client 执行工具调用
步骤 4:MCP Server 执行工具逻辑
步骤 5:结果回传给 LLM
2.3 MCP的通信传输方式 MCP协议本身与传输方式无关,MCP 主要有三种通信传输方式:stdio、基于HTTP的SSE和Streamable。
(1)stdio (标准输入/输出)
类型:stdio一种非常经典和简单的进程间通信(IPC)方式。客户端启动服务端作为一个子进程。
工作原理: 客户端通过写入子进程的 标准输入 (stdin) 来发送请求,并通过读取子进程的 标准输出 (stdout) 来获取响应。这种方式简单高效,无需网络开销。
适用场景:非常适合在本地环境 中,将一个命令行工具或脚本快速封装成一个 MCP 服务。
(2)SSE (Server-Sent Events)
类型:SSE 是一种 基于 HTTP 的单向推送协议 ,它允许服务器在保持连接开放的情况下,持续向客户端发送事件流。
工作原理:客户端发起一个 HTTP 请求,服务器接收请求并保持连接,然后以 text/event-stream 格式将响应数据流式传输给客户端。这在 MCP 中被用来实现请求与响应的通信。
适用场景: 适用于 分布式或网络环境 ,当服务需要部署在远端,并通过网络供多个客户端访问时。
(3)Streamable
类型:Streamable-HTTP 是 MCP 提供的另一种基于 HTTP 的传输方式,它同样用于网络通信。
工作原理:客户端通过 HTTP 请求与服务器通信。与 SSE 的主要区别在于其传输格式和机制可能有所不同,比如Streamble的传输格式可以为任意格式,而SSE为特定格式;Streamble的通信方向可以为双向,而SSE只能是单向。
适用场景:与 SSE 类似,适用于需要通过网络进行通信的分布式应用 。
对比:
传输方式
stdio
SSE (Server-Sent Events)
Streamable-HTTP
通信方向
双向(请求-响应)
单向(服务器推送到客户端)
双向(双向流)
通信模式
本地进程间通信(IPC)
网络通信(长连接流)
网络通信(双向流)
主要用途
封装本地命令行工具
仅需接收服务器更新的场景
复杂的、需要实时双向流的场景
是否容易丢失数据
由操作系统保证可靠性
由 TCP 协议保证可靠性
由 TCP 协议保证可靠性
关键优势
简单、高效、安全,无需网络开销
适用于简单、单向的数据推送,浏览器兼容性好
灵活性高,支持双向流式传输,提升大型任务的响应效率
3 mcp包使用
注意:以下代码需要安装langchain_mcp_adapters包,安装方式如下。
pip install langchain-mcp-adapters –index-url https://pypi.org/simple
3.1 stdio传输方式【理解】 服务端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from mcp.server import FastMCPmcp = FastMCP('stoio_server' , log_level='ERROR' ) @mcp.tool( name="query_high_frequency_question" , description="从知识库中检索常见问题解答(FAQ),返回包含问题和答案的结构化JSON数据。" , async def query_high_frequency_question () -> str : """ 高频问题查询 """ try : print ("调用查询高频问题的tool成功!!" ) return "高频问题是: 恐龙是怎么灭绝的?" except Exception as e: print (f"Unexpected error in question retrieval: {str (e)} " ) raise @mcp.tool( name="get_weather" , description="查询天气" async def get_weather () -> str : """ 查询天气的tools """ try : print ("调用查询天气的tools" ) return "北京的天气是多云" except Exception as e: print (f"Unexpected error in question retrieval: {str (e)} " ) raise if __name__ == '__main__' : mcp.run(transport='stdio' )
客户端(直接调用)
如果直接运行报错,可能是编码集的问题,可以尝试使用命令行的方式运行:
set PYTHONIOENCODING=utf-8
python client_direct.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from langchain_mcp_adapters.tools import load_mcp_toolsfrom mcp import StdioServerParameters, ClientSessionfrom mcp.client.stdio import stdio_clientimport asyncioserver_script = r".\stdio_server.py" server_parameters = StdioServerParameters( command = "python" if server_script.endswith(".py" ) else "node" , args = [server_script], ) mcp_client = None async def main (): global mcp_client async with stdio_client(server_parameters) as (read, write): async with ClientSession(read, write) as session: await session.initialize() mcp_client = type ("MCPClientHolder" , (), {"session" : session})() tools = await load_mcp_tools(session) print (f"tools-->{tools} " ) result = await session.call_tool("get_weather" , {}) print (f'result-->{result} ' ) return if __name__ == '__main__' : asyncio.run(main())
客户端(agent调用) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import osimport syssys.path.append(os.path.join(os.path.dirname(__file__), "../../.." )) from langchain.agents import create_tool_calling_agent, AgentExecutorfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_mcp_adapters.tools import load_mcp_toolsfrom langchain_openai import ChatOpenAIfrom mcp import StdioServerParameters, ClientSessionfrom mcp.client.stdio import stdio_clientimport asynciofrom agent_learn.config import Configconf = Config() llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 ) server_script = r".\stdio_server.py" server_parameters = StdioServerParameters( command = "python" if server_script.endswith(".py" ) else "node" , args = [server_script], ) mcp_client = None async def main (): global mcp_client async with stdio_client(server_parameters) as (read, write): async with ClientSession(read, write) as session: await session.initialize() mcp_client = type ("MCPClientHolder" , (), {"session" : session})() tools = await load_mcp_tools(session) print (f"tools-->{tools} " ) prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个乐于助人的助手,能够调用工具回答用户问题。" ), ("human" , "{input}" ), ("placeholder" , "{agent_scratchpad}" ), ]) agent = create_tool_calling_agent(llm, tools, prompt_template) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True ) print ("MCP客户端启动,输入'quit'退出" ) while True : query = input ("\nQuery: " ).strip() if query.lower() == "quit" : break try : response = await agent_executor.ainvoke({"input" : query}) print (f"response-->{response} " ) except Exception: print ("解析有问题" ) return if __name__ == '__main__' : asyncio.run(main())
3.2 sse传输方式【理解】 服务端
创建MCP对象不一样
1 2 mcp = FastMCP('stoio_server' , log_level='ERROR' , host="127.0.0.1" , port=8001 )
运行sse服务器
1 mcp.run(transport="sse" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 from mcp.server import FastMCPmcp = FastMCP('stoio_server' , log_level='ERROR' , host="127.0.0.1" , port=8001 ) @mcp.tool( name="query_high_frequency_question" , description="从知识库中检索常见问题解答(FAQ),返回包含问题和答案的结构化JSON数据。" , async def query_high_frequency_question () -> str : """ 高频问题查询 """ try : print ("调用查询高频问题的tool成功!!" ) return "高频问题是: 恐龙是怎么灭绝的?" except Exception as e: print (f"Unexpected error in question retrieval: {str (e)} " ) raise @mcp.tool( name="get_weather" , description="查询天气" async def get_weather () -> str : """ 查询天气的tools """ try : print ("调用查询天气的tools" ) return "北京的天气是多云" except Exception as e: print (f"Unexpected error in question retrieval: {str (e)} " ) raise if __name__ == '__main__' : print ("正在启动MCP SSE服务器..." ) print ("SSE端点: http://localhost:8001/sse" ) print ("按 Ctrl+C 停止服务器" ) try : mcp.run(transport="sse" ) except KeyboardInterrupt: print ("\n服务器已停止" ) except Exception as e: print (f"服务器启动失败: {e} " )
客户端(直接调用)
1 server_url = "http://localhost:8001/sse"
1 2 3 4 async with sse_client(url=server_url) as streams: async with ClientSession(*streams) as session:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from langchain_mcp_adapters.tools import load_mcp_toolsfrom mcp import StdioServerParameters, ClientSessionfrom mcp.client.sse import sse_clientfrom mcp.client.stdio import stdio_clientimport asyncioserver_url = "http://localhost:8001/sse" mcp_client = None async def main (): global mcp_client async with sse_client(url=server_url) as streams: async with ClientSession(*streams) as session: await session.initialize() mcp_client = type ("MCPClientHolder" , (), {"session" : session})() tools = await load_mcp_tools(session) print (f"tools-->{tools} " ) result = await session.call_tool("get_weather" , {}) print (f'result-->{result} ' ) result2 = await mcp_client.session.call_tool("query_high_frequency_question" , arguments={}) print (f'result2-->{result2} ' ) return if __name__ == '__main__' : asyncio.run(main())
客户端(agent调用) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import osimport sysfrom mcp.client.sse import sse_clientsys.path.append(os.path.join(os.path.dirname(__file__), "../../.." )) from langchain.agents import create_tool_calling_agent, AgentExecutorfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_mcp_adapters.tools import load_mcp_toolsfrom langchain_openai import ChatOpenAIfrom mcp import StdioServerParameters, ClientSessionfrom mcp.client.stdio import stdio_clientimport asynciofrom agent_learn.config import Configconf = Config() llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 ) server_url = "http://localhost:8001/sse" mcp_client = None async def main (): global mcp_client async with sse_client(url=server_url) as streams: async with ClientSession(*streams) as session: await session.initialize() mcp_client = type ("MCPClientHolder" , (), {"session" : session})() tools = await load_mcp_tools(session) print (f"tools-->{tools} " ) prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个乐于助人的助手,能够调用工具回答用户问题。" ), ("human" , "{input}" ), ("placeholder" , "{agent_scratchpad}" ), ]) agent = create_tool_calling_agent(llm, tools, prompt_template) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True ) print ("MCP客户端启动,输入'quit'退出" ) while True : query = input ("\nQuery: " ).strip() if query.lower() == "quit" : break try : response = await agent_executor.ainvoke({"input" : query}) print (f"response-->{response} " ) except Exception: print ("解析有问题" ) return if __name__ == '__main__' : asyncio.run(main())
3.3 streamable方式【熟悉】 服务端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 from mcp.server.fastmcp import FastMCPmcp = FastMCP("sdg" , log_level="ERROR" , host="127.0.0.1" , port=8001 ) @mcp.tool( name="query_high_frequency_question" , description="从知识库中检索常见问题解答(FAQ),返回包含问题和答案的结构化JSON数据。" , async def query_high_frequency_question () -> str : """ 高频问题查询 """ try : print ("调用查询高频问题的tool成功!!" ) return "高频问题是: 恐龙是怎么灭绝的?" except Exception as e: print (f"Unexpected error in question retrieval: {str (e)} " ) raise @mcp.tool( name="get_weather" , description="查询天气" async def get_weather () -> str : """ 查询天气的tools """ try : print ("调用查询天气的tools" ) return "北京的天气是多云" except Exception as e: print (f"Unexpected error in question retrieval: {str (e)} " ) raise def main (): """ 启动 Streamable HTTP 服务器。 """ print ("正在启动MCP Streamable服务器..." ) print ("服务器将在 http://localhost:8001 上运行" ) print ("按 Ctrl+C 停止服务器" ) try : mcp.run(transport="streamable-http" ) except KeyboardInterrupt: print ("\n服务器已停止" ) except Exception as e: print (f"服务器启动失败: {e} " ) if __name__ == "__main__" : main()
客户端(直接调用) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import asyncioimport loggingfrom langchain_mcp_adapters.tools import load_mcp_toolsfrom mcp import ClientSessionfrom mcp.client.streamable_http import streamablehttp_clientserver_url = "http://127.0.0.1:8001/mcp" mcp_client = None logging.basicConfig( level=logging.DEBUG, format ='[客户端] %(asctime)s - %(levelname)s - %(message)s' ) async def main (): global mcp_client logging.info(f"准备连接到 Streamable-HTTP 服务器: {server_url} " ) try : async with streamablehttp_client(server_url) as (read, write, _): logging.info("连接已成功建立!" ) async with ClientSession(read, write) as session: try : await session.initialize() logging.info("会话初始化成功,可以开始调用工具。" ) mcp_client = type ("MCPClientHolder" , (), {"session" : session})() tools = await load_mcp_tools(session) logging.info("--> 正在调用工具: query_high_frequency_question" ) response = await session.call_tool("query_high_frequency_question" , {}) print (f"response-->{response} " ) logging.info(f"<-- 收到响应: {response} " ) print ("-" * 30 ) logging.info("--> 正在调用工具: get_weather" ) response = await session.call_tool("get_weather" , {}) print (f"response-->{response} " ) logging.info(f"<-- 收到响应: {response} " ) except Exception as e: logging.error(f"调用工具时发生错误: {e} " , exc_info=True ) raise except Exception as e: logging.error(f"连接或会话初始化时发生错误: {e} " , exc_info=True ) logging.error("请确认服务端脚本已启动并运行在 http://127.0.0.1:8001/mcp" ) raise if __name__ == "__main__" : try : asyncio.run(main()) except Exception as e: logging.error(f"客户端运行失败: {e} " , exc_info=True )
客户端(agent调用) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import jsonimport loggingimport asynciofrom langchain_openai import ChatOpenAIfrom mcp import ClientSessionfrom mcp.client.streamable_http import streamablehttp_clientfrom langchain_mcp_adapters.tools import load_mcp_toolsfrom langchain.agents import create_tool_calling_agent, AgentExecutorfrom langchain_core.prompts import ChatPromptTemplatefrom agent_learn.config import Configconf = Config() llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 ) server_url = "http://127.0.0.1:8001/mcp" logging.basicConfig( level=logging.DEBUG, format ='[客户端] %(asctime)s - %(levelname)s - %(message)s' ) mcp_client = None async def run_agent (): global mcp_client logging.info(f"准备连接到 Streamable-HTTP 服务器: {server_url} " ) async with streamablehttp_client(server_url) as (read, write, _): logging.info("连接已成功建立!" ) async with ClientSession(read, write) as session: try : await session.initialize() logging.info("会话初始化成功,可以开始加载工具。" ) mcp_client = type ("MCPClientHolder" , (), {"session" : session})() tools = await load_mcp_tools(session) prompt = ChatPromptTemplate.from_messages([ ("system" , "你是一个乐于助人的助手,能够调用工具回答用户问题。" ), ("human" , "{input}" ), ("placeholder" , "{agent_scratchpad}" ), ]) agent = create_tool_calling_agent(llm, tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True ) print ("MCP客户端启动,输入'quit'退出" ) while True : query = input ("\nQuery: " ).strip() if query.lower() == "quit" : break logging.info(f"处理用户查询: {query} " ) try : response = await agent_executor.ainvoke({"input" : query}) print (f"response-->{response} " ) except Exception: print ("解析有问题" ) except Exception as e: logging.error(f"会话初始化或工具调用时发生错误: {e} " , exc_info=True ) raise if __name__ == "__main__" : try : asyncio.run(run_agent()) except Exception as e: logging.error(f"客户端运行失败: {e} " , exc_info=True )
4 python_a2a包使用【熟悉】 服务端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import loggingimport uvicornfrom python_a2a.mcp import FastMCPfrom python_a2a.mcp import create_fastapi_applogging.basicConfig(level=logging.INFO, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) mcp = FastMCP( name="MyMCPTools" , description="提供高频问题和天气查询工具" , version="1.0.0" ) @mcp.tool( name="query_high_frequency_question" , description="从知识库中检索常见问题解答(FAQ),返回包含问题和答案的结构化JSON数据。" , async def query_high_frequency_question (**kwargs ) -> str : """ 高频问题查询 """ try : print (f"调用查询高频问题的tool成功!!传进来的参数为{kwargs} " ) return '{"status": "success", "data": [{"question_id": 1, "question_text": "恐龙是怎么灭绝的?", "answer_text": "可能是小行星撞击", "category": "历史", "frequency_score": 0.9}]}' except Exception as e: print (f"Unexpected error in question retrieval: {str (e)} " ) raise @mcp.tool( name="get_weather" , description="查询天气" async def get_weather (**kwargs ) -> str : """ 查询天气的tools """ try : print (f"调用查询天气的tools。传进来的参数为{kwargs} " ) return '{"status": "success", "data": "北京的天气是多云"}' except Exception as e: print (f"Unexpected error in question retrieval: {str (e)} " ) raise def start_server (): logger.info("=== MCP 服务器信息 ===" ) logger.info(f"名称: {mcp.name} " ) logger.info(f"描述: {mcp.description} " ) port = 8010 app = create_fastapi_app(mcp) logger.info(f"启动 MCP 服务器于 http://localhost:{port} " ) uvicorn.run(app, host="0.0.0.0" , port=port) if __name__ == '__main__' : start_server()
客户端(直接调用) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import asyncioimport loggingfrom python_a2a.mcp import MCPClientlogging.basicConfig(level=logging.INFO, format ='%(asctime)s - %(levelname)s - %(message)s' ) logger = logging.getLogger(__name__) async def test_mcp_tools (): mcp_client = MCPClient(server_url="http://localhost:8010" ) try : tools = await mcp_client.get_tools() print (f'MCP tools-->{tools} ' ) result = await mcp_client.call_tool("query_high_frequency_question" ) print (f'MCP result-->{result} ' ) except Exception as e: logger.error(f'执行报错,错误信息为:{e} ' ) if __name__ == '__main__' : asyncio.run(test_mcp_tools())
客户端(agent调用) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 from mcp.client.streamable_http import streamablehttp_clientfrom langchain.agents import create_tool_calling_agent, AgentExecutorfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_mcp_adapters.tools import load_mcp_toolsfrom langchain_openai import ChatOpenAIfrom mcp import ClientSessionimport asynciofrom python_a2a import MCPClient, to_langchain_toolfrom agent_learn.config import Configconf = Config() llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 ) async def main (): url = "http://localhost:8010" mcp_client = MCPClient(server_url=url) try : tools = await mcp_client.get_tools() print (f'MCP tools-->{tools} ' ) get_weather_tool = to_langchain_tool(url, "get_weather" ) query_high_frequency_question = to_langchain_tool(url, "query_high_frequency_question" ) tools = [get_weather_tool, query_high_frequency_question] prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个乐于助人的助手,能够调用工具回答用户问题。" ), ("human" , "{user_input}" ), ("placeholder" , "{agent_scratchpad}" ), ]) agent = create_tool_calling_agent(llm, tools, prompt_template) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True ) print ("MCP客户端启动,输入'quit'退出" ) while True : query = input ("\nQuery: " ).strip() if query.lower() == "quit" : break try : response = await agent_executor.ainvoke({"user_input" : query}) print (f"response-->{response} " ) except Exception: print ("解析有问题" ) except Exception as e: print (f"Error: {e} " ) if __name__ == '__main__' : asyncio.run(main())
三、Agent智能体 1 什么是 Agent 【理解】 Agent(智能体)是一种能够感知环境、进行决策和执行动作的智能实体。从大模型的角度来看,Agent其实就是基于大模型的语义理解和推理能力,让大模型拥有解决复杂问题时的任务规划能力,并调用外部工具来执行各种任务,并且能够保留“记忆”的一个智能体 。
Agent = 大模型 + 任务规划(Planning) + 使用外部工具执行任务(Tools&Action) + 记忆(Memory)
2 什么是Agentic【理解】 描述的是一个系统所表现出的“ 像 Agent 一样的程度 ”。一个系统越是 Agentic,它就越表现出自主性、目标导向性和主动性。
Agentic 特性并非凭空出现 ,它通过多种具体的工作模式来实现。
3 Agent五种模式【掌握】 允许 Agent 调用外部工具来弥补自身知识的不足。
agent会自动完成工具的选择和调用,并基于工具调用结果进行最终答案生成。
3.2 ReAct 模式 (ReAct Pattern) 将“思考”(Reasoning)和 “行动”(Acting)紧密地结合在一起,形成一个动态的循环。这个模式让Agent不再是简单地调用工具,而是像人类一样“边想边做” ,从而解决更复杂的问题。
工作流程:
思考: Agent接收用户请求,推理任务需求并制定初步行动计划。行动: 根据思考结果,决定并执行具体行动(如调用工具)。行动输入: 为选定的工具提供必要参数。观察: 接收工具执行结果,作为对环境的“观察”。循环迭代: 将观察结果反馈给自己,再次思考并决定下一步,直到达到目标。
3.3 反思模式(Reflection pattern) Agent 在完成一个步骤或整个任务后,对其结果进行评估生成反馈, 然后Agent根据反馈结果进行反思并对结果进行修正。
3.4 规划模式(Planning Pattern) 先将一个大目标分解成一个详细的、有序的计划(Plan),然后再逐一执行计划中的每个步骤(每个步骤可能是一个 ReAct 循环)。
3.5 多智能体模式 (Multi-agent Pattern) 可以设计多个具有不同角色和能力的 Agent,让它们协同工作来完成极复杂的任务。
3.6 Agent 模式的演进关系 上述5种模式构成了一个从简单到复杂的演进阶梯:
Tool Use (基础) -> ReAct (核心循环) -> Planning (宏观规划) -> Reflection (质量保证) -> Multi-Agent (规模化协作)
ReAct 是 Tool Use 的规范化和显式化,让工具使用变得有迹可循。Planning 是在执行多个 ReAct 循环之前的高层战略制定。Reflection 是对 ReAct 或 Planning 执行结果的检查与优化。Multi-Agent 是将多个可能使用上述所有模式的 Agent 组织起来,形成一个系统。
通过上述的agent模式的演进过程,它清晰地指明了“如何一步步构建一个更强大的 Agent”。
TIPS:
一个真正强大的 Agent 系统,并不会只使用其中一种模式。它会根据任务的复杂性,灵活地将这些模式组合起来。例如,一个 Agent 面对一个复杂问题时,可能会先启动 规划模式 来分解任务,然后将子任务交给一个使用 ReAct 模式 的执行者,而这个执行者在执行过程中又会调用各种 工具 ,并在遇到困难时启动 反思模式 来修正自己的策略。
这种组合和嵌套的能力,正是 Agentic 系统能够处理现实世界中各种复杂任务的关键。
在项目中的应用:
4 代码实战【熟悉】 4.1 工具使用模式 位置:agent_learn/agent_types/C01_ToolUsePattern.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 from langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIfrom langchain_core.tools import toolfrom langchain.agents import AgentExecutor, create_tool_calling_agent, create_react_agentfrom agent_learn.config import Configconf = Config() llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 ) @tool def multiply (a: int , b: int ) -> int : """用于计算两个整数的乘积。""" print (f"正在执行乘法: {a} * {b} " ) return a * b @tool def search_weather (city: str ) -> str : """用于查询指定城市的实时天气。""" print (f"正在查询天气: {city} " ) if "北京" in city: return "北京今天是晴天,气温25摄氏度。" elif "上海" in city: return "上海今天是阴天,有小雨,气温22摄氏度。" else : return f"抱歉,我没有'{city} '的天气信息。" tools = [multiply, search_weather] tool_use_prompt = ChatPromptTemplate.from_messages([ ("system" , "你是一个强大的AI助手,可以访问和使用各种工具来回答问题。请根据用户的问题,决定是否需要调用工具。当需要调用工具时,请使用正确的JSON格式。" ), ("user" , "{input}" ), ("placeholder" , "{agent_scratchpad}" ) ]) tool_calling_agent = create_tool_calling_agent(llm, tools, tool_use_prompt) tool_use_executor = AgentExecutor( agent=tool_calling_agent, tools=tools, verbose=True ) def run_agent_and_print (agent_executor, query ): """一个通用函数,用于运行Agent并打印结果。""" print (f"--- 运行Agent,查询: {query} ---" ) response = agent_executor.invoke({"input" : query}) print (f"\n--- Agent响应: ---" ) print (response.get("output" , "没有找到输出。" )) print ("-" * 30 + "\n" ) if __name__ == "__main__" : run_agent_and_print(tool_use_executor, "上海今天的天气怎么样?" ) run_agent_and_print(tool_use_executor, "30乘以5等于多少? 上海天气怎么样" )
4.2 ReAct模式 注意点:
(1)修改成react模式的提示词
(2)创建react风格的智能体
1 react_agent = create_react_agent(llm, tools, react_prompt)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 from langchain_openai import ChatOpenAIfrom langchain_core.tools import toolfrom langchain_core.prompts import ChatPromptTemplatefrom langchain.agents import AgentExecutor, create_react_agentfrom agent_learn.config import Configconf = Config() llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 ) @tool def multiply (numbers_str: str ) -> int : """用于计算两个整数的乘积。 参数: numbers_str (str): 包含两个整数的字符串,用逗号分隔,例如:"100,25"。 返回: int: 两个整数的乘积。 """ print (f"正在执行乘法: {numbers_str} " ) try : a_str, b_str = numbers_str.split(',' ) a = int (a_str.strip()) b = int (b_str.strip()) return a * b except ValueError: return "输入的格式不正确,请确保是两个用逗号分隔的整数,例如:'100,25'" @tool def search_weather (city: str ) -> str : """用于查询指定城市的实时天气。""" print (f"正在查询天气: {city} " ) if "北京" in city: return "北京今天是晴天,气温25摄氏度。" elif "上海" in city: return "上海今天是阴天,有小雨,气温22摄氏度。" else : return f"抱歉,我没有'{city} '的天气信息。" tools = [multiply, search_weather] react_prompt_template = """你是一个有用的 AI 助手,可以访问以下工具: {tools} 请根据用户输入一步步推理,并按以下规则操作: 1. 每次输出只能包含一个动作(Action 和 Action Input)或一个最终答案(Final Answer)。 2. 如果用户输入包含多个任务,依次处理每个任务,不要一次性输出所有步骤。 3. 每次行动前,说明你的思考(Thought),并选择合适的工具或直接给出最终答案。 4. 如果需要使用工具,格式必须为: Thought: [你的思考] Action: [工具名称] Action Input: [工具的输入参数,例如对于multiply工具,使用'100,25'格式] 5. 如果可以直接回答或所有任务都完成,格式为: Thought: [你的思考] Final Answer: [最终答案] 可用的工具名称有: {tool_names} 用户输入: {input} agent的推理过程: {agent_scratchpad} """ react_prompt = ChatPromptTemplate.from_template(react_prompt_template) react_agent = create_react_agent(llm, tools, react_prompt) react_executor = AgentExecutor( agent=react_agent, tools=tools, verbose=True , handle_parsing_errors=True ) if __name__ == '__main__' : print (react_executor.invoke({"input" : "请计算100乘以25,并查询上海的天气" }))
4.3 反思模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 from langchain_openai import ChatOpenAIfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom agent_learn.config import Configconf = Config() llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 ) initial_response_prompt = ChatPromptTemplate.from_template( "请根据以下问题给出你的初步回答: {question}" ) initial_response_chain = initial_response_prompt | llm | StrOutputParser() reflection_prompt = ChatPromptTemplate.from_template( """你是一个专业的、善于反思的AI助手。你之前给出了以下回答: --- {previous_response} --- 现在,你收到了用户对你的回答给出的反馈: --- {user_feedback} --- 请根据用户的反馈,认真反思你之前的回答,并生成一个更准确、更完善的新回答。 新回答:""" ) reflection_chain = reflection_prompt | llm | StrOutputParser() def reflect_and_refine (query: str , feedback: str ): """模拟一个完整的反射过程,从初始响应到优化后的响应。""" print ("--- 启动反射模式 ---" ) print (f"用户查询: {query} " ) print ("\n生成初步响应..." ) initial_response = initial_response_chain.invoke({"question" : query}) print (f"LLM 初步响应:\n{initial_response} " ) print ("\n模拟用户反馈..." ) print (feedback) print ("\nLLM 反思并生成新回答..." ) refined_response = reflection_chain.invoke( {"previous_response" : initial_response, "user_feedback" : feedback} ) print (f"LLM 优化后的回答:\n{refined_response} " ) return refined_response if __name__ == "__main__" : initial_question = "请用一句话介绍一下 LangChain。" user_feedback_text = "你的回答太简单了,请更详细地解释一下 LangChain 的核心概念,比如 Agent 和 Chain 的区别。" reflect_and_refine(initial_question, user_feedback_text)
4.4 规划模式 这个案例分了两个智能体,一个做任务规划,一个做任务执行。因为有多个智能体,所以也可以称为多智能体模式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 from langchain_openai import ChatOpenAIfrom langchain_core.tools import toolfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom langchain.agents import AgentExecutor, create_react_agentfrom agent_learn.config import Configconf = Config() llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 ) @tool def multiply (numbers_str: str ) -> int : """用于计算两个整数的乘积。 参数: numbers_str (str): 包含两个整数的字符串,用逗号分隔,例如:"100,25"。 返回: int: 两个整数的乘积。 """ print (f"正在执行乘法: {numbers_str} " ) try : a_str, b_str = numbers_str.split(',' ) a = int (a_str.strip()) b = int (b_str.strip()) return a * b except ValueError: return "输入的格式不正确,请确保是两个用逗号分隔的整数,例如:'100,25'" @tool def search_weather (city: str ) -> str : """用于查询指定城市的实时天气。""" print (f"正在查询天气: {city} " ) if "北京" in city: return "北京今天是晴天,气温25摄氏度。" elif "上海" in city: return "上海今天是阴天,有小雨,气温22摄氏度。" else : return f"抱歉,我没有'{city} '的天气信息。" tools = [multiply, search_weather] planner_prompt = ChatPromptTemplate.from_template( """你是一个任务规划师,你的工作是将用户提出的一个复杂任务分解成一系列清晰、可执行的步骤。 你的输出应该是一个简单的任务列表,每行一个任务。 例子: 用户任务: "请先查上海的天气,然后计算20乘以30。" 任务列表: - 查找上海的天气 - 计算20乘以30的结果 用户任务: {user_input} 任务列表: """ ) planner_chain = planner_prompt | llm | StrOutputParser() executor_react_prompt_template = """你是一个专业的工具执行者,可以访问以下工具: {tools} 根据你的思考(Thought)决定下一步的行动(Action)。你的行动必须遵循以下格式: Thought: 我需要思考如何完成任务。 Action: [工具名称] Action Input: [工具的输入参数,对于multiply工具,请使用'100,25'这样的格式] 可用的工具名称有: {tool_names} 当你获取了所有必要信息并可以给出最终答案时,请以以下格式结束: Thought: 我已经有了最终答案。 Final Answer: [最终答案] 请执行以下任务: {input} {agent_scratchpad} """ executor_prompt = ChatPromptTemplate.from_template(executor_react_prompt_template) executor_agent = create_react_agent(llm, tools, executor_prompt) executor_executor = AgentExecutor( agent=executor_agent, tools=tools, verbose=True , handle_parsing_errors=True ) def execute_planning_pattern (query: str ): print ("--- 启动规划模式 ---" ) print ("\n规划器正在分解任务..." ) plan = planner_chain.invoke({"user_input" : query}) tasks = [task.strip() for task in plan.split('\n' ) if task.strip()] print ("规划器生成的任务列表:" ) for i, task in enumerate (tasks): print (f" {i + 1 } . {task} " ) print ("\n执行者正在逐一执行任务..." ) for i, task in enumerate (tasks): print (f"\n--- 执行任务 {i + 1 } : {task} ---" ) result = executor_executor.invoke({"input" : task}) print (f"执行者输出: {result} " ) print ("\n--- 所有任务执行完毕!---" ) if __name__ == "__main__" : test_query = "请先计算 50 乘以 60 的结果,然后告诉我上海的天气怎么样?" execute_planning_pattern(test_query)
4.5 多智能体模式 这个案例分了3个智能体,一个是计算专家用来处理计算任务;一个是信息专家,用来处理信息检索任务;还有一个内容整合智能体,用于生成最终答案。
这里案例里少了一个任务规划的智能体,这部分工作是由我们手动来完成的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, \ HumanMessagePromptTemplate from langchain_openai import ChatOpenAIfrom langchain_core.tools import toolfrom langchain.agents import AgentExecutor, create_tool_calling_agentfrom langchain_core.output_parsers import StrOutputParserfrom agent_learn.config import Configconf = Config() llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 ) @tool def multiply (a: int , b: int ) -> int : """用于计算两个整数的乘积。 参数: a (int): 第一个整数。 b (int): 第二个整数。 """ print (f"\n[计算专家] -> 正在执行乘法: {a} * {b} " ) return a * b @tool def add (a: int , b: int ) -> int : """用于计算两个整数的和。 参数: a (int): 第一个整数。 b (int): 第二个整数。 """ print (f"\n[计算专家] -> 正在执行加法: {a} + {b} " ) return a + b math_tools = [multiply, add] math_prompt = ChatPromptTemplate.from_messages([ SystemMessagePromptTemplate.from_template("你是一个强大的数学计算专家,可以访问和使用各种数学工具。" ), HumanMessagePromptTemplate.from_template("{input}" ), MessagesPlaceholder(variable_name="agent_scratchpad" ) ]) math_agent = create_tool_calling_agent(llm, math_tools, math_prompt) math_executor = AgentExecutor( agent=math_agent, tools=math_tools, verbose=True ) @tool def search_weather (city: str ) -> str : """用于查询指定城市的实时天气。""" print (f"正在查询天气: {city} " ) if "北京" in city: return "北京今天是晴天,气温25摄氏度。" elif "上海" in city: return "上海今天是阴天,有小雨,气温22摄氏度。" else : return f"抱歉,我没有'{city} '的天气信息。" @tool def get_current_date () -> str : """用于获取当前日期。""" print ("\n[信息专家] -> 正在获取当前日期..." ) import datetime return datetime.date.today().strftime("%Y年%m月%d日" ) info_tools = [search_weather, get_current_date] info_prompt = ChatPromptTemplate.from_messages([ SystemMessagePromptTemplate.from_template("你是一个强大的信息查询专家,可以访问和使用各种查询工具。" ), HumanMessagePromptTemplate.from_template("{input}" ), MessagesPlaceholder(variable_name="agent_scratchpad" ) ]) info_agent = create_tool_calling_agent(llm, info_tools, info_prompt) info_executor = AgentExecutor( agent=info_agent, tools=info_tools, verbose=True ) def multi_agent_workflow (query: str , math_task: str , info_task: str ): print ("--- 启动多智能体协作流程 ---" ) print (f"\n用户原始请求: {query} " ) print ("\n[主程序] -> 将任务分配给计算专家..." ) math_result = math_executor.invoke({"input" : math_task}).get("output" ) print (f"\n[主程序] -> 计算专家返回结果: {math_result} " ) print ("\n[主程序] -> 将任务分配给信息专家..." ) info_result = info_executor.invoke({"input" : info_task}).get("output" ) print (f"\n[主程序] -> 信息专家返回结果: {info_result} " ) print ("\n[主程序] -> 使用大模型进行最终总结..." ) summarize_prompt = ChatPromptTemplate.from_messages([ ("system" , "你是一个善于总结和整合信息的助手。请根据以下信息,为用户原始请求生成一个完整的回答。" ), ("human" , f"用户请求: {query} \n\n计算结果: {math_result} \n\n信息查询结果: {info_result} \n\n请整合以上信息,生成一个连贯的最终回答。" ) ]) summarize_chain = summarize_prompt | llm | StrOutputParser() final_answer = summarize_chain.invoke({"query" : query}) print ("\n--- 协作流程已完成!---" ) print (f"最终综合回答:\n{final_answer} " ) return final_answer if __name__ == "__main__" : original_query = "请先计算 25 乘以 4,然后告诉我北京今天的天气和当前日期。" math_task = "计算 25 乘以 4" info_task = "查询北京今天的天气和当前日期" multi_agent_workflow(original_query, math_task, info_task)
四、A2A协议 1 Agent2Agent Protocol【理解】 A2A协议就是不同智能体进行沟通协作的协议。
作用:安全协作(可以保证agent之间的信息是安全的) 、任务与状态管理(提交一个任务后,可以跟踪任务的状态和处理结果) 、用户体验协商(智能体可以根据用户的问题和反馈进行调整,提高用户的体验) 、能力发现(agent通过AgentCard 来展示自己的功能,其他agent可以自动读取AgentCard 中的信息来了解该智能体的功能)
1.1 Agent2Agent 架构剖析 A2A核心角色:
User:用户是协议中的关键主体,主要负责进行认证和授权操作,确保交互的安全性和合法性。
Client Agent:客户端 Agent 是任务的发起者,它代表用户提出需求或请求。
Server Agent:服务端 Agent 是任务的执行者,它接收来自客户端 Agent 的请求,并执行相应的操作。
1.2 Agent2Agent 核心概念 AgentSkill :AgentSkill 定义了单个智能体(Agent)所具备的、可被外部调用的具体功能或能力。
AgentCard :AgentCard 是描述一个智能体身份、能力(AgentSkill)、接口信息和元数据的标准化声明文件,用于代理发现和服务注册。
Task :Task 指的是具体的需要完成目标,会包含关于session_id、状态、任务的内容、处理结果等信息。
TaskState :TaskState是任务状态枚举类,定义了任务的可能状态,包括SUBMITTED/COMPLETED等。
TaskStatus :TaskStatus 表示 A2A 任务的当前状态对象,包括状态枚举(TaskState)、附加消息和时间戳。
A2AServer :A2AServer是A2A协议的核心实现类,用于 构建代理服务器 。
artifacts :artifacts 是 A2A 协议中 Task 对象的核心字段之一,用于存储任务执行后的输出产物(结果)。
AgentNetwork :AgentNetwork 是 A2A 协议中的agent网络管理类,用于集中管理和发现 A2AServer。
AIAgentRouter :AIAgentRouter 是负责根据任务需求和 AgentCard 信息,将任务路由到最合适智能体的组件。
2 A2AServer结合MCP Server【掌握】 接下来通过一个案例,来看一下如何将A2AServer和MCP Server结合起来进行使用。
调用逻辑:
2.1 创建MCP Server 位置:agent_learn/A2A_base/a2a_mcp_collaboration/mcp_weather_tool_agent.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import uvicornfrom python_a2a.mcp import FastMCP, create_fastapi_appmcp = FastMCP(name="WeatherTool" ) @mcp.tool(name="get_weather" , description="获取城市天气" ) def get_weather (city: str ) -> str : print (f"[MCP 工具 Agent 日志] 收到工具调用,查询城市: {city} " ) if city == "北京" : return "北京今天阳光明媚,29°C" return f"找不到 {city} 的天气" if __name__ == "__main__" : app = create_fastapi_app(mcp) print ("[MCP 工具 Agent] 已启动,在 http://127.0.0.1:6005" ) uvicorn.run(app, host="127.0.0.1" , port=6005 )
2.2 创建A2AServer 位置:agent_learn/A2A_base/a2a_mcp_collaboration/a2a_main_agent.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from python_a2a import A2AServer, run_server, AgentCard, AgentSkill, TaskStatus, TaskStatefrom python_a2a.mcp import MCPClientimport asyncioagent_card = AgentCard( name="WeatherServer" , description="用来查询天气" , url="http://127.0.0.1:8005" , skills=[AgentSkill(name="查询天气" , description="查询指定城市的天气" )] ) class WeatherServer (A2AServer ): def __init__ (self ): super ().__init__(agent_card=agent_card) self.mcp_client = MCPClient('http://127.0.0.1:6005' ) def handle_task (self, task ): print ("收到A2A任务的task:=>" , task) query = (task.message or {}).get('content' , {}).get('text' , '' ) if "天气" in query: city = "北京" weather_result = asyncio.run(self.mcp_client.call_tool(tool_name="get_weather" , city=city)) print ("天气查询结果:=>" , weather_result) task.artifacts = [{"parts" : [{"type" : "text" , "text" : weather_result}]}] else : task.artifacts = [{"parts" : [{"type" : "text" , "text" : "无法理解的任务" }]}] task.status = TaskStatus(TaskState.COMPLETED) print (f"[{self.agent_card.name} 日志] 任务完成,结果已返回给 A2A" ) print ("task:=>" ,task) print ("task.artifacts:=>" ,task.artifacts) return task if __name__ == '__main__' : run_server(WeatherServer(), host="127.0.0.1" , port=8005 )
2.3 客户端 位置:agent_learn/A2A_base/a2a_mcp_collaboration/main_client.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import asynciofrom python_a2a import A2AClientasync def main (): magent_client = A2AClient("http://127.0.0.1:8005" ) print ("[主客户端日志] 准备向主控 Agent 发送任务..." ) query = "请帮我查一下北京的天气" result = magent_client.ask(query) print (f"[主客户端日志] 收到最终结果: '{result} '" ) if __name__ == "__main__" : asyncio.run(main())
3 A2AServer串行【掌握】 本部分主要实现A2A串行协作的场景。
3.1 weather_agent 位置:agent_learn/A2A_base/a2a_serial/weather_agent.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from python_a2a import A2AServer, run_server, AgentCard, AgentSkill, TaskStatus, TaskStateagent_card = AgentCard( name="WeatherAgentServer" , description="一个天气预报查询的专家 Agent" , url="http://127.0.0.1:5008" , skills=[AgentSkill(name="query" , description="接受天气查询查询" ,examples=["天气北京" ])] ) class WeatherAgentServer (A2AServer ): def __init__ (self ): super ().__init__(agent_card=agent_card) def handle_task (self, task ): print ("收到A2A任务的task:=>" , task) query = (task.message or {}).get("content" , {}).get("text" , "" ) print (f"[{self.agent_card.name} 日志] 收到 A2A 任务: '{query} '" ) if "天气" in query: print (f"[{self.agent_card.name} 日志] 决策:任务需要天气数据,准备调用工具..." ) try : weather_result = {"温度" : 30 , "天气" : "晴天" } print (f"[{self.agent_card.name} 日志] 从 MCP 工具获得结果: '{weather_result} '" ) task.artifacts = [{"parts" : [{"type" : "text" , "text" : weather_result}]}] except Exception as e: error_msg = f"调用 工具失败: {e} " print (f"[{self.agent_card.name} 日志] {error_msg} " ) task.artifacts = [{"parts" : [{"type" : "text" , "text" : error_msg}]}] else : task.artifacts = [{"parts" : [{"type" : "text" , "text" : "无法理解的任务" }]}] task.status = TaskStatus(state=TaskState.COMPLETED) print (f"[{self.agent_card.name} 日志] 任务处理完毕" ) print (f"[{self.agent_card.name} 日志] 输出结果task: {task} " ) print (f"[{self.agent_card.name} 日志] 输出结果task.artifacts: {task.artifacts} " ) return task if __name__ == "__main__" : server = WeatherAgentServer() print (f"[{server.agent_card.name} ] 已启动,在 {server.agent_card.url} " ) run_server(server, host="127.0.0.1" , port=5008 )
3.2 ticket_agent 位置:agent_learn/A2A_base/a2a_serial/ticket_agent.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from python_a2a import A2AServer, run_server, AgentCard, AgentSkill, TaskStatus, TaskStateticket_card = AgentCard( name="TicketAgentServer" , description="一个可以预订票务的专家 Agent。" , url="http://127.0.0.1:5009" , version="1.0.0" , skills=[AgentSkill(name="book_ticket" , description="预订票务" )] ) class TicketServer (A2AServer ): def __init__ (self ): super ().__init__(agent_card=ticket_card) def handle_task (self, task ): print ("收到A2A任务的task:=>" , task) query = (task.message or {}).get("content" , {}).get("text" , "" ) print (f"[{self.agent_card.name} 日志] 收到 A2A 任务: '{query} '" ) if "上海" in query and "北京" in query: train_result = "上海到北京的火车票已经预订成功! G1001,10车1A " else : train_result = "请输入明确的出发地和目的地。" print (f"[{self.agent_card.name} 日志] 返回结果: {train_result} " ) task.artifacts = [{"parts" : [{"type" : "text" , "text" : train_result}]}] task.status = TaskStatus(state=TaskState.COMPLETED) print (f"[{self.agent_card.name} 日志] 任务处理完毕" ) print (f"[{self.agent_card.name} 日志] 输出结果task: {task} " ) print (f"[{self.agent_card.name} 日志] 输出结果task.artifacts: {task.artifacts} " ) return task if __name__ == "__main__" : server = TicketServer() print (f"[{server.agent_card.name} ] 启动成功,服务地址: {server.agent_card.url} " ) run_server(server, host="127.0.0.1" , port=5009 )
3.3 main_orchestrator 位置:agent_learn/A2A_base/a2a_serial/main_orchestrator.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 import asynciofrom python_a2a import AgentNetwork, A2AClient, Task, Message, MessageRole, TextContentimport jsonimport uuidfrom time import sleepasync def main (): network = AgentNetwork(name="TravelOrchestrator" ) network.add("TicketAgent" , "http://127.0.0.1:5009" ) network.add("WeatherAgent" , "http://127.0.0.1:5008" ) print ("[主控日志] AgentNetwork 初始化完成,已添加专家代理:" ) for agent_info in network.list_agents(): print (json.dumps(agent_info, indent=4 , ensure_ascii=False )) print ("-" * 50 ) weather_query = "北京的天气怎么样" weather_client = network.get_agent("WeatherAgent" ) message = Message(content=TextContent(text=weather_query), role=MessageRole.USER) weather_task = Task(message=message.to_dict(), id ="task-" + str (uuid.uuid4())) weather_result = await weather_client.send_task_async(weather_task) weather_info = "未知天气" try : weather_parts = weather_result.artifacts[0 ]["parts" ] if weather_parts and weather_parts[0 ].get("type" ) == "text" : weather_info = weather_parts[0 ].get("text" ) print (f"[主控日志] 收到 WeatherAgent 的结果: '{weather_info} '" ) except Exception as e: print (f"[主控日志] 解析天气结果出错: {e} " ) ticket_query = f"预订一张从北京到上海的火车票,当前天气是:{weather_info} " ticket_client = network.get_agent("TicketAgent" ) ticket_message = Message(content=TextContent(text=ticket_query), role=MessageRole.USER) ticket_task = Task(message=ticket_message.to_dict(), id ="task-" + str (uuid.uuid4())) ticket_result = await ticket_client.send_task_async(ticket_task) print (f"\n[主控日志] 收到 TicketAgent 的最终结果:" ) print (json.dumps(ticket_result.to_dict(), indent=4 , ensure_ascii=False )) if __name__ == "__main__" : asyncio.run(main())
4 A2A实战案例【掌握】 A2A(Agent-to-Agent)协议是一种支持代理间通信的框架,允许不同 AI 代理通过任务、消息和产物进行协作。在本实战中,我们基于四个脚本(router_A2Aagent_Server.py、weather_agent.py、ticket_agent.py 和 main.py),实现一个 LLM 驱动的路由系统:
路由服务器(router_A2Aagent_Server.py):使用 LangChain 和 OpenAI LLM 作为路由决策引擎。
票务代理(TicketAgentServer):处理火车票预订请求。
天气代理(WeatherAgentServer):处理天气查询请求。
主控客户端(main.py):使用 AgentNetwork 和 AIAgentRouter 路由查询到合适代理,获取结果。
目标:
通过4个脚本,基于A2A 协议的路由协作,LLM 识别意图,将查询路由到票务或天气代理,模拟旅行助手系统。实战通过异步运行服务器和客户端,验证意图识别和任务处理。
4.1 router_agent 实现目标 :router_A2Aagent_Server主要构建 LLM 路由代理服务器进行意图识别和路由决策。使用 LangChain 转换 OpenAI LLM 为 A2A 服务器,监听端口 5555,支持异步路由决策。
核心功能 :
使用 ChatOpenAI 创建 LLM。
通过 to_a2a_server(llm) 转换为 A2A 服务器。
异步启动 run_server,提供路由服务。
代码位置 :agent_learn/A2A_base/a2a_case/router_A2Aagent_Server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain_openai import ChatOpenAIfrom python_a2a import run_serverfrom python_a2a.langchain import to_a2a_serverimport asynciofrom agent_learn.config import Configconf = Config() async def main (): llm = ChatOpenAI(base_url=conf.base_url, api_key=conf.api_key, model=conf.model_name, temperature=0.1 , streaming=True ) llm_server = to_a2a_server(llm) print (llm_server.agent_card) run_server(llm_server, port=5555 ) if __name__ == '__main__' : asyncio.run(main())
4.2 ticket_agent 代码位置 :agent_learn/A2A_base/a2a_case/ticket_agent.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from python_a2a import A2AServer, run_server, AgentCard, AgentSkill, TaskStatus, TaskStateticket_card = AgentCard( name="TicketAgentServer" , description="一个可以预订票务的专家 Agent。" , url="http://127.0.0.1:5009" , version="1.0.0" , skills=[AgentSkill(name="book_ticket" , description="预订票务" )] ) class TicketServer (A2AServer ): def __init__ (self ): super ().__init__(agent_card=ticket_card) def handle_task (self, task ): print ("收到A2A任务的task:=>" , task) query = (task.message or {}).get("content" , {}).get("text" , "" ) print (f"[{self.agent_card.name} 日志] 收到 A2A 任务: '{query} '" ) if "上海" in query and "北京" in query: train_result = "上海到北京的火车票已经预订成功! G1001,10车1A " else : train_result = "请输入明确的出发地和目的地。" print (f"[{self.agent_card.name} 日志] 返回结果: {train_result} " ) task.artifacts = [{"parts" : [{"type" : "text" , "text" : train_result}]}] task.status = TaskStatus(state=TaskState.COMPLETED) print (f"[{self.agent_card.name} 日志] 任务处理完毕" ) print (f"[{self.agent_card.name} 日志] 输出结果task: {task} " ) print (f"[{self.agent_card.name} 日志] 输出结果task.artifacts: {task.artifacts} " ) return task if __name__ == "__main__" : server = TicketServer() print (f"[{server.agent_card.name} ] 启动成功,服务地址: {server.agent_card.url} " ) run_server(server, host="127.0.0.1" , port=5009 )
4.3 weather_agent 代码位置 :agent_learn/A2A_base/a2a_case/weather_agent.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 from python_a2a import A2AServer, run_server, AgentCard, AgentSkill, TaskStatus, TaskStateagent_card = AgentCard( name="WeatherAgentServer" , description="一个天气预报查询的专家 Agent" , url="http://127.0.0.1:5008" , skills=[AgentSkill(name="query" , description="接受天气查询查询" ,examples=["天气北京" ])] ) class WeatherAgentServer (A2AServer ): def __init__ (self ): super ().__init__(agent_card=agent_card) def handle_task (self, task ): print ("收到A2A任务的task:=>" , task) query = (task.message or {}).get("content" , {}).get("text" , "" ) print (f"[{self.agent_card.name} 日志] 收到 A2A 任务: '{query} '" ) if "天气" in query: print (f"[{self.agent_card.name} 日志] 决策:任务需要天气数据,准备调用工具..." ) try : weather_result = {"温度" : 30 , "天气" : "晴天" } print (f"[{self.agent_card.name} 日志] 从 MCP 工具获得结果: '{weather_result} '" ) task.artifacts = [{"parts" : [{"type" : "text" , "text" : weather_result}]}] except Exception as e: error_msg = f"调用 工具失败: {e} " print (f"[{self.agent_card.name} 日志] {error_msg} " ) task.artifacts = [{"parts" : [{"type" : "text" , "text" : error_msg}]}] else : task.artifacts = [{"parts" : [{"type" : "text" , "text" : "无法理解的任务" }]}] task.status = TaskStatus(state=TaskState.COMPLETED) print (f"[{self.agent_card.name} 日志] 任务处理完毕" ) print (f"[{self.agent_card.name} 日志] 输出结果task: {task} " ) print (f"[{self.agent_card.name} 日志] 输出结果task.artifacts: {task.artifacts} " ) return task if __name__ == "__main__" : server = WeatherAgentServer() print (f"[{server.agent_card.name} ] 已启动,在 {server.agent_card.url} " ) run_server(server, host="127.0.0.1" , port=5008 )
4.4 main **实现目标:**作为主控客户端,使用 AgentNetwork 和 AIAgentRouter 路由查询到票务或天气代理,获取完整响应。
核心功能:
初始化 AgentNetwork,添加代理 URL。
使用 AIAgentRouter 路由查询,返回代理名称和置信度。
发送 Task 到选择的代理,解析 artifacts 中的 parts。
代码位置 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import asynciofrom python_a2a import AgentNetwork, AIAgentRouter, A2AClient, Task, Message, MessageRole, TextContentimport jsonimport uuidfrom time import sleepasync def main (): network = AgentNetwork(name='TravelAgentNetwork' ) network.add(name='WeatherAgent' , agent_or_url='http://127.0.0.1:5008' ) network.add(name='TicketAgent' , agent_or_url='http://127.0.0.1:5009' ) for agent_info in network.list_agents(): print (json.dumps(agent_info, indent=4 , ensure_ascii=False )) router = AIAgentRouter(llm_client=A2AClient("http://127.0.0.1:5555" ), agent_network=network) queries = [ "帮我查下北京的天气" , "预订一张从北京到上海的火车票" ] for query in queries: print (f"[主控日志] 用户查询: '{query} '" ) agent_name, confidence = router.route_query(query) print (f"[主控日志] 匹配的agent: '{agent_name} ', 匹配度: {confidence} " ) if agent_name: agent_client = network.get_agent(agent_name) if agent_client: message = Message(content=TextContent(text=query), role=MessageRole.USER) agent_task = Task(message=message.to_dict(), id ="task-" + str (uuid.uuid4())) try : agent_result = await agent_client.send_task_async(agent_task) print ("[主控日志] agent返回结果:" ) print (json.dumps(agent_result.to_dict(), indent=4 , ensure_ascii=False )) except Exception as e: print (f"[主控日志] agent调用失败: '{e} '" ) if __name__ == '__main__' : asyncio.run(main())
4.5 扩展: multi_intents 核心功能 :演示一个能够处理多意图查询的主控 Agent。
流程 :用户查询 -> LLM分解子查询 -> 路由到不同的专家Agent -> 并行执行 -> 收集并展示结果。
==总结:==
复杂任务如何拆解?——使用任务拆解agent(大模型,用提示词的方式),将复杂任务拆解成子任务。【同agent的规划模式】
如何做到任务的并行?——先将任务的协程对象进行保存,然后调用asyncio.gather()一起执行这些任务。
代码位置 :agent_learn/A2A_base/a2a_case/multi_intents.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 import asyncio from python_a2a import AgentNetwork, AIAgentRouter, A2AClient, Task, Message, MessageRole, TextContent from langchain_openai import ChatOpenAI from langchain_core.prompts import PromptTemplate from langchain_core.output_parsers import StrOutputParser import json import uuid from time import sleep from agent_learn.config import Config import re conf = Config() decompose_llm = ChatOpenAI( model=conf.model_name, api_key=conf.api_key, base_url=conf.base_url, temperature=0.1 , streaming=True ) decompose_prompt = PromptTemplate.from_template(""" 将以下用户查询分解为独立的子查询,每个子查询对应一个单一意图。 返回 JSON 格式的列表:{{"sub_queries": ["子查询1", "子查询2", ...]}} 示例: 查询: "预订票,查天气" 输出: {{"sub_queries": ["预订票", "查天气"]}} 查询: {query} """ )decompose_chain = decompose_prompt | decompose_llm | StrOutputParser() async def main (): network = AgentNetwork(name='TravelAgentNetwork' ) network.add(name='WeatherAgent' , agent_or_url='http://127.0.0.1:5008' ) network.add(name='TicketAgent' , agent_or_url='http://127.0.0.1:5009' ) for agent_info in network.list_agents(): print (json.dumps(agent_info, indent=4 , ensure_ascii=False )) router = AIAgentRouter(llm_client=A2AClient("http://127.0.0.1:5555" ), agent_network=network) queries = [ "帮我查下北京的天气,并预订一张从北京到上海的火车票" , "帮我查下北京的天气" , "预订一张从北京到上海的火车票" , ] for query in queries: print (f"[主控日志] 用户查询: '{query} '" ) try : decompose_result = decompose_chain.invoke({"query" : query}) print (f"[主控日志] 分解结果: {decompose_result} " ) decompose_response = re.sub(r'^```json\n|\n```$' , '' , decompose_result.strip()) decompose_data = json.loads(decompose_response) sub_queries = decompose_data.get("sub_queries" , [query]) except Exception as e: print (f"[主控日志] 分解失败: {e} " ) sub_queries = [query] print (f"[主控日志] 子查询列表: {sub_queries} " ) tasks = [] agent_names = [] confidences = [] for sub_query in sub_queries: print (f"[主控日志] 子查询: '{sub_query} '" ) agent_name, confidence = router.route_query(sub_query) print (f"[主控日志] 匹配的agent: '{agent_name} ', 匹配度: {confidence} " ) if agent_name: agent_client = network.get_agent(agent_name) if agent_client: message = Message(content=TextContent(text=sub_query), role=MessageRole.USER) agent_task = Task(message=message.to_dict(), id ="task-" + str (uuid.uuid4())) tasks.append(agent_client.send_task_async(agent_task)) agent_names.append(agent_name) confidences.append(confidence) confidence = sum (confidences) / len (confidences) if confidences else 0.1 print ("===========所有子查询置信度的平均值==============" ) print (confidence) if tasks: results = await asyncio.gather(*tasks, return_exceptions=True ) print ("[主控日志]检查query拆解任务之后的所有 任务结果:" ) print (results) for i, result in enumerate (results): if isinstance (result, Exception): print (f"[主控日志] {agent_names[i]} 处理错误: {str (result)} " ) else : print (f"[主控日志] {agent_names[i]} 收到完整响应:" ) print (json.dumps(result.to_dict(), indent=4 , ensure_ascii=False )) print (f"\n[主控日志] {agent_names[i]} 解析 artifacts 中的 parts:" ) for artifact in result.artifacts: if "parts" in artifact: for part in artifact["parts" ]: part_type = part.get("type" ) if part_type == "text" : print (f"Text 结果: {part.get('text' )} " ) elif part_type == "error" : print (f"Error 消息: {part.get('message' )} " ) elif part_type == "function_response" : print ( f"Function Response: name={part.get('name' )} , response={part.get('response' )} " ) else : print (f"未知类型: {part} " ) else : print ("[主控日志] 未找到合适代理" ) print ('*' *80 ) if __name__ == '__main__' : asyncio.run(main())
P02-项目实现 一、项目架构与代码架构图【掌握】 1 项目架构图 SmartVoyage 是基于A2A与MCP协议实现是一个多agent系统。系统包括 LLM 路由服务器(意图识别)、天气代理服务器(查询天气数据库)、票务代理服务器(查询票务数据库)、票务预定服务器(API接口)、MCP 工具服务器(数据库接口)、数据采集脚本和 Streamlit 前端客户端。
2 代码架构图 以下是代码层面的架构图。
代码结构如下:
二、项目实现 1 整体流程【熟悉】
配置基础环境(config.py 和 create_logger.py)
初始化数据库(SQL 脚本)
采集数据(spider_weather.py)
完成 MCP 服务器(mcp_weather_server.py 、mcp_ticket_server.py 和 mcp_order_server.py)
完成A2A代理服务器(weather_server.py 、ticket_server.py 和 order_server.py)
完成客户端(main.py)
启动服务进行联调
启动MCP 服务器(mcp_weather_server.py 、mcp_ticket_server.py 和 mcp_order_server.py)
启动代理服务器(weather_server.py 、ticket_server.py 和 order_server.py)
启动客户端(main.py)
2 配置模块【实现】 2.1 config.py 位置 :SmartVoyage/config.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import osproject_root = os.path.join(os.path.dirname(os.path.abspath(__file__)), '..' ) class Config : def __init__ (self ): self.base_url = 'https://dashscope.aliyuncs.com/compatible-mode/v1' self.api_key = 'sk-67320312aa3e4fsdfsss3411aa0d7' self.model_name = 'qwen-plus' self.host = 'localhost' self.user = 'root' self.password = 'root' self.database = 'travel_rag' self.log_file = os.path.join(project_root, 'SmartVoyage' , 'logs/app.log' ) if __name__ == '__main__' : print (Config().log_file)
2.2 create_logger.py 位置 :SmartVoyage/create_logger.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import loggingimport osfrom SmartVoyage.config import Configdef setup_logger (name, log_file='logs/app.log' ): os.makedirs(os.path.dirname(log_file), exist_ok=True ) logger = logging.getLogger(name) logger.setLevel(logging.DEBUG) logger.propagate = False formatter = logging.Formatter('%(name)s - %(asctime)s - %(levelname)s - %(message)s' ) console_handler = logging.StreamHandler() console_handler.setFormatter(formatter) console_handler.setLevel(logging.INFO) file_handler = logging.FileHandler(filename=log_file, encoding="utf-8" , mode="a" ) file_handler.setFormatter(formatter) file_handler.setLevel(logging.DEBUG) if not logger.handlers: logger.addHandler(console_handler) logger.addHandler(file_handler) return logger logger = setup_logger('SmartVoage' , Config().log_file)
3 数据库初始化【实现】 SQL 脚本,创建票务和天气数据库表。定义数据结构,确保 MCP 服务器能查询存储的数据。
项目中的定位 :数据基础,存储天气和票务信息。
核心功能 :创建表、设置唯一键和注释。
数据库概述:
4 数据采集【实现】 spider_weather天气数据采集脚本,从 API 获取数据,写入 MySQL。保持数据库实时更新,支持代理查询。数据采集地址:https://dev.qweather.com/docs/api/weather/weather-daily-forecast/
项目中的定位 :后台数据源,定时执行。
核心功能 :API 请求、数据解析、写入/更新数据库、调度。
**代码路径:**SmartVoyage/sql
5 数据导入【实现】 5.1 导包及配置 以下配置是关于天气API配置以及数据库配置,通过爬虫爬取天气信息网站存储到数据库用于作为A2A检索数据库。
位置:SmartVoyage/utils/spider_weather.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import requestsimport mysql.connectorfrom datetime import datetime, timedeltaimport scheduleimport timeimport jsonimport gzipimport pytzAPI_KEY = "5ef0a4×××××××××317eae83" city_codes = { "北京" : "101010100" , "上海" : "101020100" , "广州" : "101280101" , "深圳" : "101280601" } BASE_URL = "https://m7487r6ych.re.qweatherapi.com/v7/weather/30d" TZ = pytz.timezone('Asia/Shanghai' ) db_config = { "host" : "localhost" , "user" : "root" , "password" : "root" , "database" : "travel_rag" , "charset" : "utf8mb4" }
5.2 连接数据库 connect_db函数
目标 :建立 MySQL 数据库连接。
功能 :使用 db_config 配置连接 MySQL,返回连接对象
输入输出 :
输入:无。
输出:mysql.connector.connection.MySQLConnection 对象。
1 2 def connect_db (): return mysql.connector.connect(**db_config)
测试:
1 2 3 4 5 if __name__ == '__main__' : conn = connect_db() print (conn.is_connected()) print ("数据库连接成功!" ) conn.close()
5.3 爬取数据 fetch_weather_data函数用于天气数据的爬取与解析。
目标 :从和风天气 API 获取 30 天天气预报数据。
功能 :发送 GET 请求,处理 gzip 压缩,解析 JSON 返回数据。
输入输出 :
输入:city(字符串,如“北京”),location(字符串,如“101010100”)。
输出:JSON 字典(包含 daily 预报列表)或 None。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def fetch_weather_data (city, location ): headers = { "X-QW-Api-Key" : API_KEY, "Accept-Encoding" : "gzip" } url = f"{BASE_URL} ?location={location} " try : response = requests.get(url, headers=headers, timeout=10 ) response.raise_for_status() if response.headers.get('Content-Encoding' ) == 'gzip' : data = gzip.decompress(response.content).decode('utf-8' ) else : data = response.text return json.loads(data) except requests.RequestException as e: print (f"请求 {city} 天气数据失败: {e} " ) return None except json.JSONDecodeError as e: print (f"{city} JSON 解析错误: {e} , 响应内容: {response.text[:500 ]} ..." ) return None except gzip.BadGzipFile: print (f"{city} 数据未正确解压,尝试直接解析: {response.text[:500 ]} ..." ) return json.loads(response.text) if response.text else None
测试:
1 2 3 4 if __name__ == "__main__" : weather_data = fetch_weather_data("北京" , city_codes["北京" ]) print (weather_data) print ("解析成功!" )
5.4 查询数据更新时间 get_latest_update_time函数
目标 :查询数据库中指定城市的最新更新时间。
功能 :执行 SQL 查询,返回 weather_data 表中 city 的最新 update_time。
输入输出 :
输入:cursor(MySQL 游标),city(字符串,如“北京”)。
输出:datetime 对象或 None。
1 2 3 4 def get_latest_update_time (cursor, city ): cursor.execute("SELECT MAX(update_time) FROM weather_data WHERE city = %s" , (city,)) result = cursor.fetchone() return result[0 ] if result[0 ] else None
测试:
1 2 3 4 5 6 7 8 9 10 11 if __name__ == "__main__" : conn = connect_db() cursor = conn.cursor() print (get_latest_update_time(cursor, '北京' )) cursor.close() conn.close()
5.5 是否需要更新 should_update_data函数
目标 :判断是否需要更新城市天气数据。
功能 :检查最新更新时间是否超过 1 天,或强制更新。
输入输出 :
输入:latest_time(datetime 或 None),force_update(布尔值)。
输出:布尔值(True/False)。
1 2 3 4 5 6 7 8 9 10 11 12 def should_update_data (latest_time, force_update=False ): if force_update: return True if latest_time is None : return True if latest_time and latest_time.tzinfo is None : latest_time = latest_time.replace(tzinfo=TZ) current_time = datetime.now(TZ) return (current_time - latest_time) > timedelta(days=1 )
测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 if __name__ == "__main__" : from datetime import datetime, timedelta import pytz TZ = pytz.timezone('Asia/Shanghai' ) latest = datetime.now(TZ) - timedelta(days=2 ) print ("========模拟一个两天前的时间==============" ) print (latest) print (should_update_data(latest)) if should_update_data(latest): print (f"需要更新数据,上次更新时间:{latest} " ) else : print ("没有数据,需要更新数据!" )
5.6 存储数据 store_weather_data函数
目标 :写入或更新天气预报数据到数据库。
功能 :循环预报数据,使用 INSERT ON DUPLICATE KEY UPDATE 插入/更新 weather_data 表。
输入输出 :
输入:数据库连接、mysql游标,城市、数据。
输出:无,数据库更新。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 def store_weather_data (conn, cursor, city, data ): if not data or data.get("code" ) != "200" : print (f"{city} 数据无效,跳过存储。" ) return daily_data = data.get("daily" , []) update_time = datetime.fromisoformat(data.get("updateTime" ).replace("+08:00" , "+08:00" )).replace(tzinfo=TZ) for day in daily_data: fx_date = datetime.strptime(day["fxDate" ], "%Y-%m-%d" ).date() values = ( city, fx_date, day.get("sunrise" ), day.get("sunset" ), day.get("moonrise" ), day.get("moonset" ), day.get("moonPhase" ), day.get("moonPhaseIcon" ), day.get("tempMax" ), day.get("tempMin" ), day.get("iconDay" ), day.get("textDay" ), day.get("iconNight" ), day.get("textNight" ), day.get("wind360Day" ), day.get("windDirDay" ), day.get("windScaleDay" ), day.get("windSpeedDay" ), day.get("wind360Night" ), day.get("windDirNight" ), day.get("windScaleNight" ), day.get("windSpeedNight" ), day.get("precip" ), day.get("uvIndex" ), day.get("humidity" ), day.get("pressure" ), day.get("vis" ), day.get("cloud" ), update_time ) insert_query = """ INSERT INTO weather_data ( city, fx_date, sunrise, sunset, moonrise, moonset, moon_phase, moon_phase_icon, temp_max, temp_min, icon_day, text_day, icon_night, text_night, wind360_day, wind_dir_day, wind_scale_day, wind_speed_day, wind360_night, wind_dir_night, wind_scale_night, wind_speed_night, precip, uv_index, humidity, pressure, vis, cloud, update_time ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE sunrise = VALUES(sunrise), sunset = VALUES(sunset), moonrise = VALUES(moonrise), moonset = VALUES(moonset), moon_phase = VALUES(moon_phase), moon_phase_icon = VALUES(moon_phase_icon), temp_max = VALUES(temp_max), temp_min = VALUES(temp_min), icon_day = VALUES(icon_day), text_day = VALUES(text_day), icon_night = VALUES(icon_night), text_night = VALUES(text_night), wind360_day = VALUES(wind360_day), wind_dir_day = VALUES(wind_dir_day), wind_scale_day = VALUES(wind_scale_day), wind_speed_day = VALUES(wind_speed_day), wind360_night = VALUES(wind360_night), wind_dir_night = VALUES(wind_dir_night), wind_scale_night = VALUES(wind_scale_night), wind_speed_night = VALUES(wind_speed_night), precip = VALUES(precip), uv_index = VALUES(uv_index), humidity = VALUES(humidity), pressure = VALUES(pressure), vis = VALUES(vis), cloud = VALUES(cloud), update_time = VALUES(update_time) """ try : cursor.execute(insert_query, values) print (f"{city} {fx_date} 数据写入/更新成功: {day.get('textDay' )} , 影响行数: {cursor.rowcount} " ) except mysql.connector.Error as e: print (f"{city} {fx_date} 数据库错误: {e} " ) conn.commit() print (f"{city} 事务提交完成。" )
测试:
1 2 3 4 5 6 if __name__ = = "__main__": conn = connect_db() cursor = conn.cursor() data = fetch_weather_data("北京", "101010100") store_weather_data(conn, cursor , "北京", data) print("数据存储完成。")
5.7 更新数据 update_weather函数
目标: 更新所有城市数据。
功能: 查看是否满足更新条件,调用数据存储与数据爬取。
输入输出:
输入:更新条件
输出:无,数据库更新。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def update_weather (force_update=False ): conn = connect_db() cursor = conn.cursor() for city, location in city_codes.items(): latest_time = get_latest_update_time(cursor, city) if should_update_data(latest_time, force_update): print (f"开始更新 {city} 天气数据..." ) data = fetch_weather_data(city, location) if data: store_weather_data(conn, cursor, city, data) else : print (f"{city} 数据已为最新,无需更新。最新更新时间: {latest_time} " ) cursor.close() conn.close()
测试:
1 2 if __name__ == "__main__" : update_weather(force_update=True )
5.8 定时更新 setup_scheduler函数
目标: 设置定时任务,每天在 PDT 16:00(北京时间 01:00)调用 update_weather 函数。保证数据的实时性。
功能 :
使用 schedule 库注册每日任务。
进入无限循环,检查并运行待执行任务,每 60 秒检查一次。
项目中的定位 :确保天气数据定时更新,保持 weather_data 表的数据新鲜,支持 weather_server.py 和 mcp_weather_server.py 查询。
1 2 3 4 5 6 def setup_scheduler (): schedule.every().day.at("16:00" ).do(update_weather) while True : schedule.run_pending() time.sleep(60 )
原理测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from datetime import datetime, timedeltaimport timeimport schedulenow = datetime.now() trigger_time = (now + timedelta(seconds=20 )).strftime("%H:%M:%S" ) print (f"[测试日志] 当前时间: {now} " )print (f"[测试日志] 设置任务在 {trigger_time} 触发 update_weather" )schedule.every().day.at(trigger_time).do(lambda : print ("任务已触发!" )) end_time = now + timedelta(seconds=60 ) while datetime.now() < end_time: schedule.run_pending() print (f"[测试日志] 检查待执行任务: {datetime.now()} " ) time.sleep(1 )
5.9 完整代码 位置:SmartVoyage/utils/spider_weather.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 import requestsimport mysql.connectorfrom datetime import datetime, timedeltaimport scheduleimport timeimport jsonimport gzipimport pytzAPI_KEY = "5ef0a47e161a4ea997227322317eae83" city_codes = { "北京" : "101010100" , "上海" : "101020100" , "广州" : "101280101" , "深圳" : "101280601" } BASE_URL = "https://m7487r6ych.re.qweatherapi.com/v7/weather/30d" TZ = pytz.timezone('Asia/Shanghai' ) db_config = { "host" : "localhost" , "user" : "root" , "password" : "123456" , "database" : "travel_rag" , "charset" : "utf8mb4" } def connect_db (): return mysql.connector.connect(**db_config) def fetch_weather_data (city, location ): headers = { "X-QW-Api-Key" : API_KEY, "Accept-Encoding" : "gzip" } url = f"{BASE_URL} ?location={location} " try : response = requests.get(url, headers=headers, timeout=10 ) response.raise_for_status() if response.headers.get('Content-Encoding' ) == 'gzip' : data = gzip.decompress(response.content).decode('utf-8' ) else : data = response.text return json.loads(data) except requests.RequestException as e: print (f"请求 {city} 天气数据失败: {e} " ) return None except json.JSONDecodeError as e: print (f"{city} JSON 解析错误: {e} , 响应内容: {response.text[:500 ]} ..." ) return None except gzip.BadGzipFile: print (f"{city} 数据未正确解压,尝试直接解析: {response.text[:500 ]} ..." ) return json.loads(response.text) if response.text else None def get_latest_update_time (cursor, city ): cursor.execute("SELECT MAX(update_time) FROM weather_data WHERE city = %s" , (city,)) result = cursor.fetchone() return result[0 ] if result[0 ] else None def should_update_data (latest_time, force_update=False ): if force_update: return True if not latest_time: return True current_time = datetime.now(TZ) latest_time = latest_time.replace(tzinfo=TZ) return (current_time - latest_time).total_seconds() / 3600 >= 24 def store_weather_data (conn, cursor, city, data ): if not data or data.get("code" ) != "200" : print (f"{city} 数据无效,跳过存储。" ) return daily_data = data.get("daily" , []) update_time = datetime.fromisoformat(data.get("updateTime" ).replace("+08:00" , "+08:00" )).replace(tzinfo=TZ) for day in daily_data: fx_date = datetime.strptime(day["fxDate" ], "%Y-%m-%d" ).date() values = ( city, fx_date, day.get("sunrise" ), day.get("sunset" ), day.get("moonrise" ), day.get("moonset" ), day.get("moonPhase" ), day.get("moonPhaseIcon" ), day.get("tempMax" ), day.get("tempMin" ), day.get("iconDay" ), day.get("textDay" ), day.get("iconNight" ), day.get("textNight" ), day.get("wind360Day" ), day.get("windDirDay" ), day.get("windScaleDay" ), day.get("windSpeedDay" ), day.get("wind360Night" ), day.get("windDirNight" ), day.get("windScaleNight" ), day.get("windSpeedNight" ), day.get("precip" ), day.get("uvIndex" ), day.get("humidity" ), day.get("pressure" ), day.get("vis" ), day.get("cloud" ), update_time ) insert_query = """ INSERT INTO weather_data ( city, fx_date, sunrise, sunset, moonrise, moonset, moon_phase, moon_phase_icon, temp_max, temp_min, icon_day, text_day, icon_night, text_night, wind360_day, wind_dir_day, wind_scale_day, wind_speed_day, wind360_night, wind_dir_night, wind_scale_night, wind_speed_night, precip, uv_index, humidity, pressure, vis, cloud, update_time ) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE sunrise = VALUES(sunrise), sunset = VALUES(sunset), moonrise = VALUES(moonrise), moonset = VALUES(moonset), moon_phase = VALUES(moon_phase), moon_phase_icon = VALUES(moon_phase_icon), temp_max = VALUES(temp_max), temp_min = VALUES(temp_min), icon_day = VALUES(icon_day), text_day = VALUES(text_day), icon_night = VALUES(icon_night), text_night = VALUES(text_night), wind360_day = VALUES(wind360_day), wind_dir_day = VALUES(wind_dir_day), wind_scale_day = VALUES(wind_scale_day), wind_speed_day = VALUES(wind_speed_day), wind360_night = VALUES(wind360_night), wind_dir_night = VALUES(wind_dir_night), wind_scale_night = VALUES(wind_scale_night), wind_speed_night = VALUES(wind_speed_night), precip = VALUES(precip), uv_index = VALUES(uv_index), humidity = VALUES(humidity), pressure = VALUES(pressure), vis = VALUES(vis), cloud = VALUES(cloud), update_time = VALUES(update_time) """ try : cursor.execute(insert_query, values) print (f"{city} {fx_date} 数据插入/更新成功: {day.get('textDay' )} , 影响行数: {cursor.rowcount} " ) except mysql.connector.Error as e: print (f"{city} {fx_date} 数据库错误: {e} " ) conn.commit() print (f"{city} 事务提交完成。" ) def update_weather (force_update=False ): conn = connect_db() cursor = conn.cursor() for city, location in city_codes.items(): latest_time = get_latest_update_time(cursor, city) if should_update_data(latest_time, force_update): print (f"开始更新 {city} 天气数据..." ) data = fetch_weather_data(city, location) if data: store_weather_data(conn, cursor, city, data) else : print (f"{city} 数据已为最新,无需更新。最新更新时间: {latest_time} " ) cursor.close() conn.close() def setup_scheduler (): schedule.every().day.at("16:00" ).do(update_weather) while True : schedule.run_pending() time.sleep(60 ) if __name__ == "__main__" : with mysql.connector.connect(**db_config) as conn: cursor = conn.cursor() cursor.execute(""" CREATE TABLE IF NOT EXISTS weather_data ( id INT AUTO_INCREMENT PRIMARY KEY, city VARCHAR(50) NOT NULL COMMENT '城市名称', fx_date DATE NOT NULL COMMENT '预报日期', sunrise TIME COMMENT '日出时间', sunset TIME COMMENT '日落时间', moonrise TIME COMMENT '月升时间', moonset TIME COMMENT '月落时间', moon_phase VARCHAR(20) COMMENT '月相名称', moon_phase_icon VARCHAR(10) COMMENT '月相图标代码', temp_max INT COMMENT '最高温度', temp_min INT COMMENT '最低温度', icon_day VARCHAR(10) COMMENT '白天天气图标代码', text_day VARCHAR(20) COMMENT '白天天气描述', icon_night VARCHAR(10) COMMENT '夜间天气图标代码', text_night VARCHAR(20) COMMENT '夜间天气描述', wind360_day INT COMMENT '白天风向360角度', wind_dir_day VARCHAR(20) COMMENT '白天风向', wind_scale_day VARCHAR(10) COMMENT '白天风力等级', wind_speed_day INT COMMENT '白天风速 (km/h)', wind360_night INT COMMENT '夜间风向360角度', wind_dir_night VARCHAR(20) COMMENT '夜间风向', wind_scale_night VARCHAR(10) COMMENT '夜间风力等级', wind_speed_night INT COMMENT '夜间风速 (km/h)', precip DECIMAL(5,1) COMMENT '降水量 (mm)', uv_index INT COMMENT '紫外线指数', humidity INT COMMENT '相对湿度 (%)', pressure INT COMMENT '大气压强 (hPa)', vis INT COMMENT '能见度 (km)', cloud INT COMMENT '云量 (%)', update_time DATETIME COMMENT '数据更新时间', UNIQUE KEY unique_city_date (city, fx_date) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='天气数据表' """ ) conn.commit() update_weather() setup_scheduler()
6 天气MCP服务器【掌握】 mcp_ticket_server.py:票务 MCP 服务器,提供 train_tickets、flight_tickets 和 concert_tickets 表的 SELECT 查询接口,返回 JSON 格式结果。
核心功能 :
初始化 MySQL 数据库连接。
执行 SELECT 查询,返回 JSON 格式结果。
格式化日期和数值字段,确保 JSON 序列化兼容。
通过 FastAPI 提供 HTTP 接口,响应 MCP 工具调用。
位置:SmartVoyage/mcp_server/mcp_weather_server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 import mysql.connectorimport jsonfrom datetime import date, datetime, timedeltafrom decimal import Decimalfrom mcp.server.fastmcp import FastMCPfrom SmartVoyage.config import Configfrom SmartVoyage.create_logger import loggerfrom SmartVoyage.utils.format import DateEncoder, default_encoderconf = Config() class WeatherService : def __init__ (self ): self.conn = mysql.connector.connect( host=conf.host, user=conf.user, password=conf.password, database=conf.database ) def execute_query (self, sql: str ) -> str : try : cursor = self.conn.cursor(dictionary=True ) cursor.execute(sql) results = cursor.fetchall() cursor.close() for result in results: for key, value in result.items(): if isinstance (value, (date, datetime, timedelta, Decimal)): result[key] = default_encoder(value) return json.dumps({"status" : "success" , "data" : results} if results else {"status" : "no_data" , "message" : "未找到天气数据,请确认城市和日期。" }, cls=DateEncoder, ensure_ascii=False ) except Exception as e: logger.error(f'查询失败:{e} ' ) return json.dumps({"status" : "error" , "message" : str (e)}, ensure_ascii=False ) def create_weather_mcp_server (): weather_mcp = FastMCP(name="WeatherTools" , instructions="天气查询工具,基于 weather_data 表。" , log_level="ERROR" , host="127.0.0.1" , port=8002 ) service = WeatherService() @weather_mcp.tool( name="query_weather" , description="查询天气数据,输入 SQL,如 'SELECT * FROM weather_data WHERE city = \"北京\" AND fx_date = \"2025-07-30\"'" ) def query_weather (sql: str ) -> str : logger.info(f"执行天气查询: {sql} " ) return service.execute_query(sql) logger.info("=== 天气MCP服务器信息 ===" ) logger.info(f"名称: {weather_mcp.name} " ) logger.info(f"描述: {weather_mcp.instructions} " ) try : print ("服务器已启动,请访问 http://127.0.0.1:8002/mcp" ) weather_mcp.run(transport="streamable-http" ) except Exception as e: print (f"服务器启动失败: {e} " ) if __name__ == '__main__' : create_weather_mcp_server()
7 票务MCP 服务器【掌握】 mcp_weather_server天气 MCP 服务器,提供 weather_data 表的 SELECT 查询接口,返回 JSON 格式结果。
核心功能 :
初始化 MySQL 数据库连接。
执行 SELECT 查询,返回 JSON 格式结果。
格式化日期和数值字段,确保 JSON 序列化兼容。
通过 FastAPI 提供 HTTP 接口,响应 MCP 工具调用。
位置 :SmartVoyage/mcp_server/mcp_ticket_server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import mysql.connectorimport jsonfrom datetime import date, datetime, timedeltafrom decimal import Decimalfrom mcp.server.fastmcp import FastMCPfrom SmartVoyage.config import Configfrom SmartVoyage.create_logger import loggerfrom SmartVoyage.utils.format import DateEncoder, default_encoderconf = Config() class TicketService : def __init__ (self ): self.conn = mysql.connector.connect( host=conf.host, user=conf.user, password=conf.password, database=conf.database ) def execute_query (self, sql: str ) -> str : try : cursor = self.conn.cursor(dictionary=True ) cursor.execute(sql) results = cursor.fetchall() cursor.close() for result in results: for key, value in result.items(): if isinstance (value, (date, datetime, timedelta, Decimal)): result[key] = default_encoder(value) return json.dumps({"status" : "success" , "data" : results} if results else {"status" : "no_data" , "message" : "未找到票务数据,请确认查询条件。" }, cls=DateEncoder, ensure_ascii=False ) except Exception as e: logger.error(f"票务查询错误: {str (e)} " ) return json.dumps({"status" : "error" , "message" : str (e)}, ensure_ascii=False ) def create_ticket_mcp_server (): ticket_mcp = FastMCP(name="TicketTools" , instructions="票务查询工具,基于 train_tickets, flight_tickets, concert_tickets 表。只支持查询。" , log_level="ERROR" , host="127.0.0.1" , port=8001 ) service = TicketService() @ticket_mcp.tool( name="query_tickets" , description="查询票务数据,输入 SQL,如 'SELECT * FROM train_tickets WHERE departure_city = \"北京\" AND arrival_city = \"上海\"'" ) def query_tickets (sql: str ) -> str : logger.info(f"执行票务查询: {sql} " ) return service.execute_query(sql) logger.info("=== 票务MCP服务器信息 ===" ) logger.info(f"名称: {ticket_mcp.name} " ) logger.info(f"描述: {ticket_mcp.instructions} " ) try : print ("服务器已启动,请访问 http://127.0.0.1:8001/mcp" ) ticket_mcp.run(transport="streamable-http" ) except Exception as e: print (f"服务器启动失败: {e} " ) if __name__ == "__main__" : create_ticket_mcp_server()
8 订票MCP服务器【掌握】 mcp_order_server.py:订票 MCP 服务器,通过调用API完成火车票、飞机票和演唱会票的预定。
位置:SmartVoyage/mcp_server/mcp_order_server.py
9 天气agent服务器【掌握】 weather_server.py:天气代理服务器,使用 LLM 生成 SQL 查询 MCP 票务工具,返回用户友好文本结果。
作用 :处理用户自然语言查询,转为 SQL 调用 MCP,提升智能性,支持追问和默认值。
项目中的定位 :执行层,接收路由任务,生成 SQL 调用 MCP,返回 artifacts 给客户端。
核心功能 :
初始化 LLM 和 MCP 客户端。
生成 SQL,提取代码块,调用 MCP。
解析 JSON 结果,返回格式化文本。
位置 :SmartVoyage/a2a_server/weather_server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 import jsonimport asynciofrom mcp import ClientSessionfrom mcp.client.streamable_http import streamablehttp_clientfrom python_a2a import A2AServer, run_server, AgentCard, AgentSkill, TaskStatus, TaskState, Message, TextContent, \ MessageRole, Task from langchain_openai import ChatOpenAIfrom langchain_core.prompts import ChatPromptTemplatefrom SmartVoyage.config import Configfrom datetime import datetimeimport pytzfrom SmartVoyage.create_logger import loggerconf = Config() llm = ChatOpenAI( model=conf.model_name, base_url=conf.base_url, api_key=conf.api_key, temperature=0.1 ) table_schema_string = """ # 定义天气数据表的SQL schema字符串,用于Prompt上下文 CREATE TABLE IF NOT EXISTS weather_data ( id INT AUTO_INCREMENT PRIMARY KEY, city VARCHAR(50) NOT NULL COMMENT '城市名称', fx_date DATE NOT NULL COMMENT '预报日期', sunrise TIME COMMENT '日出时间', sunset TIME COMMENT '日落时间', moonrise TIME COMMENT '月升时间', moonset TIME COMMENT '月落时间', moon_phase VARCHAR(20) COMMENT '月相名称', moon_phase_icon VARCHAR(10) COMMENT '月相图标代码', temp_max INT COMMENT '最高温度', temp_min INT COMMENT '最低温度', icon_day VARCHAR(10) COMMENT '白天天气图标代码', text_day VARCHAR(20) COMMENT '白天天气描述', icon_night VARCHAR(10) COMMENT '夜间天气图标代码', text_night VARCHAR(20) COMMENT '夜间天气描述', wind360_day INT COMMENT '白天风向360角度', wind_dir_day VARCHAR(20) COMMENT '白天风向', wind_scale_day VARCHAR(10) COMMENT '白天风力等级', wind_speed_day INT COMMENT '白天风速 (km/h)', wind360_night INT COMMENT '夜间风向360角度', wind_dir_night VARCHAR(20) COMMENT '夜间风向', wind_scale_night VARCHAR(10) COMMENT '夜间风力等级', wind_speed_night INT COMMENT '夜间风速 (km/h)', precip DECIMAL(5,1) COMMENT '降水量 (mm)', uv_index INT COMMENT '紫外线指数', humidity INT COMMENT '相对湿度 (%)', pressure INT COMMENT '大气压强 (hPa)', vis INT COMMENT '能见度 (km)', cloud INT COMMENT '云量 (%)', update_time DATETIME COMMENT '数据更新时间', UNIQUE KEY unique_city_date (city, fx_date) ) ENGINE=INNODB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='天气数据表'; """ sql_prompt = ChatPromptTemplate.from_template( """ 系统提示:你是一个专业的天气SQL生成器,需要从对话历史(含用户的问题)中提取关键信息,然后基于weather_data表生成SELECT语句。 - 如果用户需要查天气,则至少需要城市和时间信息。如果对话历史中缺乏必要的信息,可以向其追问,输出格式为json格式,如示例所示;如果对话历史中信息齐全,则输出纯SQL即可。 - 如果用户问与天气无关的问题,则模仿最后2个示例回复即可。 示例: - 对话: user: 北京 2025-07-30 输出: SELECT city, fx_date, temp_max, temp_min, text_day, text_night, humidity, wind_dir_day, precip FROM weather_data WHERE city = '北京' AND fx_date = '2025-07-30' - 对话: user: 上海未来3天的天气 输出: SELECT city, fx_date, temp_max, temp_min, text_day, text_night, humidity, wind_dir_day, precip FROM weather_data WHERE city = '上海' AND fx_date BETWEEN '2025-07-30' AND '2025-08-01' ORDER BY fx_date - 对话: user: 北京的天气 输出: {{"status": "input_required", "message": "请提供具体的需要查询的日期,例如 '2025-07-30'。"}} - 对话: user: 今天\nassistant: 请提供城市。\nuser: 北京 输出: SELECT city, fx_date, temp_max, temp_min, text_day, text_night, humidity, wind_dir_day, precip FROM weather_data WHERE city = '北京' AND fx_date = '2025-07-30' - 对话: user: 北京明天的天气\nassistant: 多云。\nuser: 后天呢 输出: SELECT city, fx_date, temp_max, temp_min, text_day, text_night, humidity, wind_dir_day, precip FROM weather_data WHERE city = '北京' AND fx_date = '2025-08-01' - 对话: user: 你好 输出: {{"status": "input_required", "message": "请提供城市和日期,例如 '北京 2025-07-30'。"}} - 对话: user: 今天有什么好吃的 输出: {{"status": "input_required", "message": "请提供天气相关查询,包括城市和日期。"}} weather_data表结构:{table_schema_string} 对话历史: {conversation} 当前日期: {current_date} (Asia/Shanghai) """ ) async def get_weather (sql ): try : async with streamablehttp_client("http://127.0.0.1:8002/mcp" ) as (read, write, _): async with ClientSession(read, write) as session: try : await session.initialize() result = await session.call_tool("query_weather" , {"sql" : sql}) result_data = json.loads(result) if isinstance (result, str ) else result logger.info(f"天气查询结果:{result_data} " ) return result_data.content[0 ].text except Exception as e: logger.error(f"天气 MCP 测试出错:{str (e)} " ) return {"status" : "error" , "message" : f"天气 MCP 查询出错:{str (e)} " } except Exception as e: logger.error(f"连接或会话初始化时发生错误: {e} " ) return {"status" : "error" , "message" : "连接或会话初始化时发生错误" } agent_card = AgentCard( name="WeatherQueryAssistant" , description="基于LangChain提供天气查询服务的助手" , url="http://localhost:5005" , version="1.0.0" , capabilities={"streaming" : True , "memory" : True }, skills=[ AgentSkill( name="execute weather query" , description="执行天气查询,返回天气数据库结果,支持自然语言输入" , examples=["北京 2025-07-30 天气" , "上海未来5天" , "今天天气如何" ] ) ] ) class WeatherQueryServer (A2AServer ): def __init__ (self ): super ().__init__(agent_card=agent_card) self.llm = llm self.sql_prompt = sql_prompt self.schema = table_schema_string def generate_sql_query (self, conversation: str ) -> dict : try : chain = self.sql_prompt | self.llm current_date = datetime.now(pytz.timezone('Asia/Shanghai' )).strftime("%Y-%m-%d" ) output = chain.invoke({"conversation" : conversation, "current_date" : current_date, "table_schema_string" : self.schema}).content.strip() logger.info(f"原始 LLM 输出: {output} " ) if output.startswith("{" ): return json.loads(output) else : return {"status" : "sql" , "sql" : output} except Exception as e: logger.error(f"生成SQL查询出错: {e} " ) return {"status" : "input_required" , "message" : "查询无效,请提供城市和日期。" } def handle_task (self, task ): content = (task.message or {}).get("content" , {}) conversation = content.get("text" , "" ) if isinstance (content, dict ) else "" logger.info(f"对话历史及用户问题: {conversation} " ) try : sql_result = self.generate_sql_query(conversation) if sql_result.get("status" ) == "input_required" : task.status = TaskStatus(state=TaskState.INPUT_REQUIRED, message={"role" : "agent" , "content" : {"text" : sql_result["message" ]}}) return task else : sql_query = sql_result["sql" ] logger.info(f"SQL查询语句: {sql_query} " ) weather_result = asyncio.run(get_weather(sql_query)) response = json.loads(weather_result) if isinstance (weather_result, str ) else weather_result logger.info(f"MCP 返回: {response} " ) if response.get("status" ) == "success" : data = response.get("data" , []) response_text = "\n" .join([ f"{d['city' ]} {d['fx_date' ]} : {d['text_day' ]} (夜间 {d['text_night' ]} ),温度 {d['temp_min' ]} -{d['temp_max' ]} °C,湿度 {d['humidity' ]} %,风向 {d['wind_dir_day' ]} ,降水 {d['precip' ]} mm" for d in data]) task.artifacts = [{"parts" : [{"type" : "text" , "text" : response_text}]}] task.status = TaskStatus(state=TaskState.COMPLETED) elif response.get("status" ) == "no_data" : response_text = response.get("message" , "请重新输入查询的城市和日期。" ) task.status = TaskStatus(state=TaskState.INPUT_REQUIRED, message={"role" : "agent" , "content" : {"text" : response_text}}) else : response_text = response.get("message" , "查询失败,请重试或提供更多细节。" ) task.status = TaskStatus(state=TaskState.FAILED, message={"role" : "agent" , "content" : {"text" : response_text}}) return task except Exception as e: logger.error(f"查询失败: {str (e)} " ) task.status = TaskStatus(state=TaskState.FAILED, message={"role" : "agent" , "content" : {"text" : f"查询失败: {str (e)} 请重试或提供更多细节。" }}) return task if __name__ == "__main__" : weather_server = WeatherQueryServer() print ("\n=== 服务器信息 ===" ) print (f"名称: {weather_server.agent_card.name} " ) print (f"描述: {weather_server.agent_card.description} " ) print ("\n技能:" ) for skill in weather_server.agent_card.skills: print (f"- {skill.name} : {skill.description} " ) run_server(weather_server, host="127.0.0.1" , port=5005 )
10 票务Agent服务器【掌握】 ticket_server.py:票务代理服务器,使用 LLM 生成 SQL 查询 MCP 票务工具,返回用户友好文本结果。
**作用:**处理用户自然语言查询,转为 SQL 调用 MCP,提升智能性,支持追问和默认值。
项目中的定位 :执行层,接收路由任务,生成 SQL 调用 MCP,返回 artifacts 给客户端。
核心功能 :
初始化 LLM 和 MCP 客户端。
生成 SQL,提取代码块,调用 MCP。
解析 JSON 结果,返回格式化文本。
调用链 :
==位置==:SmartVoyage/mcp_server/mcp_ticket_server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 import jsonimport asynciofrom mcp import ClientSessionfrom mcp.client.streamable_http import streamablehttp_clientfrom python_a2a import A2AServer, run_server, AgentCard, AgentSkill, TaskStatus, TaskState, Message, TextContent, \ MessageRole, Task from langchain_openai import ChatOpenAIfrom langchain_core.prompts import ChatPromptTemplatefrom datetime import datetimeimport pytzfrom SmartVoyage.config import Configfrom SmartVoyage.create_logger import loggerconf = Config() llm = ChatOpenAI( model=conf.model_name, base_url=conf.base_url, api_key=conf.api_key, temperature=0.1 ) table_schema_string = """ # 定义票务表SQL schema字符串,用于Prompt上下文 CREATE TABLE train_tickets ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键,自增,唯一标识每条记录', departure_city VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '出发城市(如“北京”)', arrival_city VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '到达城市(如“上海”)', departure_time DATETIME NOT NULL COMMENT '出发时间(如“2025-08-12 07:00:00”)', arrival_time DATETIME NOT NULL COMMENT '到达时间(如“2025-08-12 11:30:00”)', train_number VARCHAR(20) NOT NULL COMMENT '火车车次(如“G1001”)', seat_type VARCHAR(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '座位类型(如“二等座”)', total_seats INT NOT NULL COMMENT '总座位数(如 1000)', remaining_seats INT NOT NULL COMMENT '剩余座位数(如 50)', price DECIMAL(10, 2) NOT NULL COMMENT '票价(如 553.50)', created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间,自动记录插入时间', UNIQUE KEY unique_train (departure_time, train_number) ) COMMENT='火车票信息表'; -- 机票表 CREATE TABLE flight_tickets ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键,自增,唯一标识每条记录', departure_city VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '出发城市(如“北京”)', arrival_city VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '到达城市(如“上海”)', departure_time DATETIME NOT NULL COMMENT '出发时间(如“2025-08-12 08:00:00”)', arrival_time DATETIME NOT NULL COMMENT '到达时间(如“2025-08-12 10:30:00”)', flight_number VARCHAR(20) NOT NULL COMMENT '航班号(如“CA1234”)', cabin_type VARCHAR(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '舱位类型(如“经济舱”)', total_seats INT NOT NULL COMMENT '总座位数(如 200)', remaining_seats INT NOT NULL COMMENT '剩余座位数(如 10)', price DECIMAL(10, 2) NOT NULL COMMENT '票价(如 1200.00)', created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间,自动记录插入时间', UNIQUE KEY unique_flight (departure_time, flight_number) ) COMMENT='航班机票信息表'; -- 演唱会票表 CREATE TABLE concert_tickets ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键,自增,唯一标识每条记录', artist VARCHAR(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '艺人名称(如“周杰伦”)', city VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '举办城市(如“上海”)', venue VARCHAR(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '场馆(如“上海体育场”)', start_time DATETIME NOT NULL COMMENT '开始时间(如“2025-08-12 19:00:00”)', end_time DATETIME NOT NULL COMMENT '结束时间(如“2025-08-12 22:00:00”)', ticket_type VARCHAR(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '票类型(如“VIP”)', total_seats INT NOT NULL COMMENT '总座位数(如 5000)', remaining_seats INT NOT NULL COMMENT '剩余座位数(如 100)', price DECIMAL(10, 2) NOT NULL COMMENT '票价(如 880.00)', created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间,自动记录插入时间', UNIQUE KEY unique_concert (start_time, artist, ticket_type) ) COMMENT='演唱会门票信息表'; """ sql_prompt = ChatPromptTemplate.from_template( """ 系统提示:你是一个专业的票务SQL生成器,需要从对话历史(含用户的问题)中提取用户的意图以及关键信息,然后基于train_tickets、flight_tickets、concert_tickets表生成SELECT语句。 根据对话历史: 1. 提取用户的意图,意图有3种(train: 火车/高铁, flight: 机票, concert: 演唱会),输出:{{"type": "train/flight/concert"}};如果无法识别意图,或者意图不在这3种内,则模仿最后1个示例回复即可。 2. 根据用户的意图,生成对应表的 SELECT 语句,仅查询指定字段: - train_tickets: id, departure_city, arrival_city, departure_time, arrival_time, train_number, seat_type, price, remaining_seats - flight_tickets: id, departure_city, arrival_city, departure_time, arrival_time, flight_number, cabin_type, price, remaining_seats - concert_tickets: id, artist, city, venue, start_time, end_time, ticket_type, price, remaining_seats 3. 如果用户在查询票务信息时,缺少必要信息,则输出:{{"status": "input_required", "message": "请提供票务类型(如火车票、机票、演唱会)和必要信息(如城市、日期)。"}} ,如示例所示;如果对话历史中信息齐全,则输出纯SQL即可。 其中,每种意图必要的信息有: - flight/train: departure_city (出发城市), arrival_city (到达城市), date (日期)。 - concert: city (城市), artist (艺人), date (日期)。 4. 按要求输出两行数据或一行数据即可,不需要输出其他内容。 示例: - 对话: user: 火车票 北京 上海 2025-07-31 硬卧 输出: {{"type": "train"}} SELECT id, departure_city, arrival_city, departure_time, arrival_time, train_number, seat_type, price, remaining_seats FROM train_tickets WHERE departure_city = '北京' AND arrival_city = '上海' AND DATE(departure_time) = '2025-07-31' AND seat_type = '硬卧' - 对话: user: 机票 上海 广州 2025-09-11 头等舱 输出: {{"type": "flight"}} SELECT id, departure_city, arrival_city, departure_time, arrival_time, flight_number, cabin_type, price, remaining_seats FROM flight_tickets WHERE departure_city = '上海' AND arrival_city = '广州' AND DATE(departure_time) = '2025-09-11' AND cabin_type = '头等舱' - 对话: user: 演唱会 北京 刀郎 2025-08-23 看台 输出: {{"type": "concert"}} SELECT id, artist, city, venue, start_time, end_time, ticket_type, price, remaining_seats FROM concert_tickets WHERE city = '北京' AND artist = '刀郎' AND DATE(start_time) = '2025-08-23' AND ticket_type = '看台' - 对话: user: 火车票 输出: {{"status": "input_required", "message": "请提供票务类型(如火车票、机票、演唱会)和必要信息(如城市、日期)。"}} - 对话: user: 你好 输出: {{"status": "input_required", "message": "请提供票务类型(如火车票、机票、演唱会)和必要信息(如城市、日期)。"}} 表结构:{table_schema_string} 对话历史: {conversation} 当前日期: {current_date} (Asia/Shanghai) """ ) async def get_ticket_info (sql ): try : async with streamablehttp_client("http://127.0.0.1:8001/mcp" ) as (read, write, _): async with ClientSession(read, write) as session: try : await session.initialize() result = await session.call_tool("query_tickets" , {"sql" : sql}) result_data = json.loads(result) if isinstance (result, str ) else result logger.info(f"票务查询结果:{result_data} " ) return result_data.content[0 ].text except Exception as e: logger.error(f"票务 MCP 测试出错:{str (e)} " ) return {"status" : "error" , "message" : f"票务 MCP 查询出错:{str (e)} " } except Exception as e: logger.error(f"连接或会话初始化时发生错误: {e} " ) return {"status" : "error" , "message" : "连接或会话初始化时发生错误" } agent_card = AgentCard( name="TicketQueryAssistant" , description="基于 LangChain 提供票务查询服务的助手" , url="http://localhost:5006" , version="1.0.4" , capabilities={"streaming" : True , "memory" : True }, skills=[ AgentSkill( name="execute ticket query" , description="根据客户端提供的输入执行票务查询,返回数据库结果,支持自然语言输入" , examples=["火车票 北京 上海 2025-07-31 硬卧" , "机票 北京 上海 2025-07-31 经济舱" , "演唱会 北京 刀郎 2025-08-23 看台" ] ) ] ) class TicketQueryServer (A2AServer ): def __init__ (self ): super ().__init__(agent_card=agent_card) self.llm = llm self.sql_prompt = sql_prompt self.schema = table_schema_string def generate_sql_query (self, conversation: str ) -> dict : try : chain = self.sql_prompt | self.llm current_date = datetime.now(pytz.timezone('Asia/Shanghai' )).strftime('%Y-%m-%d' ) output = chain.invoke({"conversation" : conversation, "current_date" : current_date, "table_schema_string" : self.schema}).content.strip() logger.info(f"原始 LLM 输出: {output} " ) lines = output.split('\n' ) type_line = lines[0 ].strip() if type_line.startswith('```json' ): type_line = lines[1 ].strip() sql_lines = lines[3 :-1 ] if lines[-1 ].strip() == '```' else lines[3 :] else : sql_lines = lines[1 :] if len (lines) > 1 else [] if type_line.startswith('{"type":' ): query_type = json.loads(type_line)["type" ] sql_query = ' ' .join([line.strip() for line in sql_lines if line.strip() and not line.startswith('```' )]) logger.info(f"分类类型: {query_type} , 生成的 SQL: {sql_query} " ) return {"status" : "sql" , "type" : query_type, "sql" : sql_query} elif type_line.startswith('{"status": "input_required"' ): return json.loads(type_line) else : logger.error(f"无效的 LLM 输出格式: {output} " ) return {"status" : "input_required" , "message" : "无法解析查询类型或SQL,请提供更明确的信息。" } except Exception as e: logger.error(f"SQL 生成失败: {str (e)} " ) return {"status" : "input_required" , "message" : "查询无效,请提供查询票务的相关信息。" } def handle_task (self, task ): content = (task.message or {}).get("content" , {}) conversation = content.get("text" , "" ) if isinstance (content, dict ) else "" logger.info(f"对话历史及用户问题: {conversation} " ) try : gen_result = self.generate_sql_query(conversation) if gen_result["status" ] == "input_required" : task.status = TaskStatus(state=TaskState.INPUT_REQUIRED, message={"role" : "agent" , "content" : {"text" : gen_result["message" ]}}) return task sql_query = gen_result["sql" ] query_type = gen_result["type" ] logger.info(f"执行 SQL 查询: {sql_query} (类型: {query_type} )" ) ticket_result = asyncio.run(get_ticket_info(sql_query)) response = json.loads(ticket_result) if isinstance (ticket_result, str ) else ticket_result logger.info(f"MCP 返回: {response} " ) if response.get("status" ) == "success" : data = response.get("data" , []) response_text = "" for d in data: if query_type == "train" : response_text += f"{d['departure_city' ]} 到 {d['arrival_city' ]} {d['departure_time' ]} : 车次 {d['train_number' ]} ,{d['seat_type' ]} ,票价 {d['price' ]} 元,剩余 {d['remaining_seats' ]} 张\n" elif query_type == "flight" : response_text += f"{d['departure_city' ]} 到 {d['arrival_city' ]} {d['departure_time' ]} : 航班 {d['flight_number' ]} ,{d['cabin_type' ]} ,票价 {d['price' ]} 元,剩余 {d['remaining_seats' ]} 张\n" elif query_type == "concert" : response_text += f"{d['city' ]} {d['start_time' ]} : {d['artist' ]} 演唱会,{d['ticket_type' ]} ,场地 {d['venue' ]} ,票价 {d['price' ]} 元,剩余 {d['remaining_seats' ]} 张\n" if not response_text: response_text = "无结果。如果需要其他日期,请补充。" task.artifacts = [{"parts" : [{"type" : "text" , "text" : response_text}]}] task.status = TaskStatus(state=TaskState.COMPLETED) elif response.get("status" ) == "no_data" : response_text = response.get("message" , "请输出查询票务的详细信息。" ) task.status = TaskStatus(state=TaskState.INPUT_REQUIRED, message={"role" : "agent" , "content" : {"text" : response_text}}) else : response_text = response.get("message" , "查询失败,请重试或提供更多细节。" ) task.status = TaskStatus(state=TaskState.FAILED, message={"role" : "agent" , "content" : {"text" : response_text}}) return task except Exception as e: logger.error(f"查询失败: {str (e)} " ) task.status = TaskStatus(state=TaskState.FAILED, message={"role" : "agent" , "content" : {"text" : f"查询失败: {str (e)} 请重试或提供更多细节。" }}) return task if __name__ == "__main__" : ticket_server = TicketQueryServer() print ("\n=== 服务器信息 ===" ) print (f"名称: {ticket_server.agent_card.name} " ) print (f"描述: {ticket_server.agent_card.description} " ) print ("\n技能:" ) for skill in ticket_server.agent_card.skills: print (f"- {skill.name} : {skill.description} " ) run_server(ticket_server, host="127.0.0.1" , port=5006 )
11 订票Agent服务器【掌握】 order_server.py:订票代理服务器,首先根据用户的意图去调用票务Agent服务器查询余票信息,然后进行调用订票MCP服务器完成订票。
位置:SmartVoyage/a2a_server/order_server.py
12 main主程序【掌握】 提示词: 位置:SmartVoyage/main_prompts.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 from langchain_core.prompts import ChatPromptTemplateclass SmartVoyagePrompts : @staticmethod def intent_prompt (): return ChatPromptTemplate.from_template( """ 系统提示:您是一个专业的旅行意图识别专家,基于用户查询和对话历史,识别其意图,用于调用专门的agent server来执行;为方便后续的agent server处理,可以基于对话历史对用户查询进行改写,使问题更明确。严格遵守规则: - 支持意图:['weather' (天气查询), 'flight' (机票查询), 'train' (高铁/火车票查询), 'concert' (演唱会票查询), 'attraction' (景点推荐)] 或其组合(如 ['weather', 'flight'])。如果意图超出范围,返回意图 'out_of_scope'。 - 如果意图为 'out_of_scope'时,此时不需要再进行查询改写,你可以直接根据用户问题进行回复,将回复答案写到follow_up_message中即可。 - 在进行用户查询改写时,不要回答其问题,也不要修改其原意,只需要将对话历史中跟该查询相关的上下文信息取出来,然后整合到一起,使用户查询更明确即可。如果用户查询跟对话历史无关,则不需要考虑历史对话,直接进行查询改写即可。将改写后的问题存储到user_queries。 - 如果用户的意图很不明确或者有歧义,可以向其进行追问,将追问问题填充到follow_up_message中。 - 输出严格为JSON:{{"intents": ["intent1", "intent2"], "user_queries": {{"intent1": "user_query1", "intent2": "user_query2"}}, "follow_up_message": "追问消息"}}。不要添加额外文本! 输出示例: {{"intents": ["weather"], "user_queries": {{"weather": "今天北京天气如何"}}, "follow_up_message": ""}} {{"intents": ["weather"], "user_queries": {{}}, "follow_up_message": "你问的是今天北京天气状况吗"}} {{"intents": ["weather", "flight"], "user_queries": {{"weather": "今天北京天气如何", "flight": "查询一下10月28日,从北京飞往杭州的机票"}}, "follow_up_message": ""}} {{"intents": ["out_of_scope"], "user_queries": {{}}, "follow_up_message": "你好,我是智能旅行助手,欢迎提问旅行方面的问题。"}} 当前日期:{current_date} (Asia/Shanghai)。 对话历史:{conversation_history} 用户查询:{query} """ ) @staticmethod def summarize_weather_prompt (): return ChatPromptTemplate.from_template( """ 系统提示:您是一位专业的天气预报员,以生动、准确的风格总结天气信息。基于查询和结果: - 核心描述点:城市、日期、温度范围、天气描述、湿度、风向、降水等。 - 如果结果为空或者意思为需要补充数据,则委婉提示“未找到数据,请确认城市/日期” - 语气:专业预报,如“根据最新数据,北京2025-07-31的天气预报为...”。 - 保持中文,100-150字。 - 如果查询无关,返回“请提供天气相关查询。” 查询:{query} 结果:{raw_response} """ ) @staticmethod def summarize_ticket_prompt (): return ChatPromptTemplate.from_template( """ 系统提示:您是一位专业的旅行顾问,以热情、精确的风格总结票务信息。基于查询和结果: - 核心描述点:出发/到达、时间、类型、价格、剩余座位等。 - 如果结果为空或者意思为需要补充数据,则委婉提示“未找到数据,请确认或修改条件” - 语气:顾问式,如“为您推荐北京到上海的机票选项...”。 - 保持中文,100-150字。 - 如果查询无关,返回“请提供票务相关查询。” 查询:{query} 结果:{raw_response} """ ) @staticmethod def attraction_prompt (): return ChatPromptTemplate.from_template( """ 系统提示:您是一位旅行专家,基于用户查询生成景点推荐。规则: - 推荐3-5个景点,包含描述、理由、注意事项。 - 基于槽位:城市、偏好。 - 语气:热情推荐,如“推荐您在北京探索故宫...”。 - 备注:内容生成,仅供参考。 - 保持中文,150-250字。 查询:{query} """ )if __name__ == '__main__' : print (SmartVoyagePrompts.intent_prompt())
意图识别: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def intent_agent (user_input ): ''' 意图识别agent:实现意图的分类以及问题的改写 :param user_input: 用户的原始问题 :return: intents 用户意图, user_queries 改写后的问题, follow_up_message 追问的问题 ''' global conversation_history, llm chain = SmartVoyagePrompts.intent_prompt() | llm current_date = datetime.now(pytz.timezone('Asia/Shanghai' )).strftime('%Y-%m-%d' ) intent_response = chain.invoke( {"conversation_history" : conversation_history, "query" : user_input, "current_date" : current_date}).content.strip() logger.info(f"意图识别原始响应: {intent_response} " ) intent_response = re.sub(r'^```json\s*|\s*```$' , '' , intent_response).strip() logger.info(f"清理后响应: {intent_response} " ) intent_output = json.loads(intent_response) intents = intent_output.get("intents" , []) user_queries = intent_output.get("user_queries" , {}) follow_up_message = intent_output.get("follow_up_message" , "" ) logger.info(f"intents: {intents} ||user_queries: {user_queries} ||follow_up_message: {follow_up_message} " ) return intents, user_queries, follow_up_message
不同意图的处理流程: 位置:SmartVoyage/main.py
完整代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 import asyncioimport jsonimport uuidfrom datetime import datetimeimport pytzimport refrom python_a2a import AgentNetwork, TextContent, Message, MessageRole, Taskfrom langchain_openai import ChatOpenAIfrom SmartVoyage.config import Configfrom SmartVoyage.create_logger import loggerfrom SmartVoyage.main_prompts import SmartVoyagePromptsconf = Config() messages = [] agent_network = None llm = None agent_urls = {} conversation_history = "" def initialize_system (): """ 初始化系统组件,包括代理网络、路由器、LLM和会话状态 核心逻辑:构建AgentNetwork,添加代理,创建路由器和LLM """ global agent_network, llm, agent_urls, conversation_history agent_urls = { "WeatherQueryAssistant" : "http://localhost:5005" , "TicketQueryAssistant" : "http://localhost:5006" } network = AgentNetwork(name="旅行助手网络" ) network.add("WeatherQueryAssistant" , "http://localhost:5005" ) network.add("TicketQueryAssistant" , "http://localhost:5006" ) agent_network = network llm = ChatOpenAI( model=conf.model_name, api_key=conf.api_key, base_url=conf.base_url, temperature=0.1 ) conversation_history = "" def intent_agent (user_input ): ''' 意图识别agent:实现意图的分类以及问题的改写 :param user_input: 用户的原始问题 :return: intents 用户意图, user_queries 改写后的问题, follow_up_message 追问的问题 ''' global conversation_history, llm chain = SmartVoyagePrompts.intent_prompt() | llm current_date = datetime.now(pytz.timezone('Asia/Shanghai' )).strftime('%Y-%m-%d' ) intent_response = chain.invoke( {"conversation_history" : '\n' .join(conversation_history.split("\n" )[-6 :]), "query" : user_input, "current_date" : current_date}).content.strip() logger.info(f"意图识别原始响应: {intent_response} " ) intent_response = re.sub(r'^```json\s*|\s*```$' , '' , intent_response).strip() logger.info(f"清理后响应: {intent_response} " ) intent_output = json.loads(intent_response) intents = intent_output.get("intents" , []) user_queries = intent_output.get("user_queries" , {}) follow_up_message = intent_output.get("follow_up_message" , "" ) logger.info(f"intents: {intents} ||user_queries: {user_queries} ||follow_up_message: {follow_up_message} " ) return intents, user_queries, follow_up_message def process_user_input (prompt ): """ 处理用户输入:识别意图、调用代理、生成响应 核心逻辑:使用LLM进行意图识别,根据意图路由到相应代理或直接生成内容 """ global messages, conversation_history, llm messages.append({"role" : "user" , "content" : prompt}) conversation_history += f"\nUser: {prompt} " print ("正在分析您的意图..." ) try : intents, user_queries, follow_up_message = intent_agent(prompt) if "out_of_scope" in intents: response = follow_up_message conversation_history += f"\nAssistant: {response} " elif follow_up_message != "" : response = follow_up_message conversation_history += f"\nAssistant: {response} " else : responses = [] routed_agents = [] for intent in intents: logger.info(f"处理意图:{intent} " ) if intent == "weather" : agent_name = "WeatherQueryAssistant" elif intent in ["flight" , "train" , "concert" ]: agent_name = "TicketQueryAssistant" else : agent_name = None if intent == "attraction" : chain = SmartVoyagePrompts.attraction_prompt() | llm rec_response = chain.invoke({"query" : prompt}).content.strip() responses.append(rec_response) elif agent_name: query_str = user_queries.get(intent, {}) logger.info(f"{agent_name} 查询:{query_str} " ) agent = agent_network.get_agent(agent_name) chat_history = '\n' .join(conversation_history.split("\n" )[-7 :-1 ]) + f'\nUser: {query_str} ' message = Message(content=TextContent(text=chat_history), role=MessageRole.USER) task = Task(id ="task-" + str (uuid.uuid4()), message=message.to_dict()) raw_response = asyncio.run(agent.send_task_async(task)) logger.info(f"{agent_name} 原始响应: {raw_response} " ) if raw_response.status.state == 'completed' : agent_result = raw_response.artifacts[0 ]['parts' ][0 ]['text' ] else : agent_result = raw_response.status.message['content' ]['text' ] if agent_name == "WeatherQueryAssistant" : chain = SmartVoyagePrompts.summarize_weather_prompt() | llm final_response = chain.invoke({"query" : query_str, "raw_response" : agent_result}).content.strip() else : chain = SmartVoyagePrompts.summarize_ticket_prompt() | llm final_response = chain.invoke({"query" : query_str, "raw_response" : agent_result}).content.strip() responses.append(final_response) routed_agents.append(agent_name) else : responses.append("暂不支持此意图。" ) response = "\n\n" .join(responses) if routed_agents: logger.info(f"路由到代理:{routed_agents} " ) conversation_history += f"\nAssistant: {response} " print (f"\n助手回复:\n{response} \n" ) messages.append({"role" : "assistant" , "content" : response}) except json.JSONDecodeError as json_err: logger.error(f"意图识别JSON解析失败" ) error_message = f"意图识别JSON解析失败:{str (json_err)} 。请重试。" print (f"\n助手回复:\n{error_message} \n" ) messages.append({"role" : "assistant" , "content" : error_message}) except Exception as e: logger.error(f"处理异常: {str (e)} " ) error_message = f"处理失败:{str (e)} 。请重试。" print (f"\n助手回复:\n{error_message} \n" ) messages.append({"role" : "assistant" , "content" : error_message}) def display_agent_cards (): """ 显示所有代理的卡片信息,包括技能、描述、地址和状态 核心逻辑:遍历代理网络,获取并打印卡片内容 """ print ("\n🛠️ Agent Cards:" ) for agent_name in agent_network.agents.keys(): agent_card = agent_network.get_agent_card(agent_name) agent_url = agent_urls.get(agent_name, "未知地址" ) print (f"\n--- Agent: {agent_name} ---" ) print (f"技能: {agent_card.skills} " ) print (f"描述: {agent_card.description} " ) print (f"地址: {agent_url} " ) print (f"状态: 在线" ) if __name__ == "__main__" : initialize_system() print ("🤖 基于A2A的SmartVoyage旅行智能助手" ) print ("欢迎体验智能对话!输入问题,按回车提交;输入'quit'退出;输入'cards'查看代理卡片。" ) display_agent_cards() while True : prompt = input ("\n请输入您的问题: " ).strip() if prompt.lower() == 'quit' : print ("感谢使用SmartVoyage!再见!" ) break elif prompt.lower() == 'cards' : display_agent_cards() continue elif not prompt: continue else : process_user_input(prompt) print ("\n---" ) print ("Powered by 黑马程序员 | 基于Agent2Agent的旅行助手系统 v2.0" )

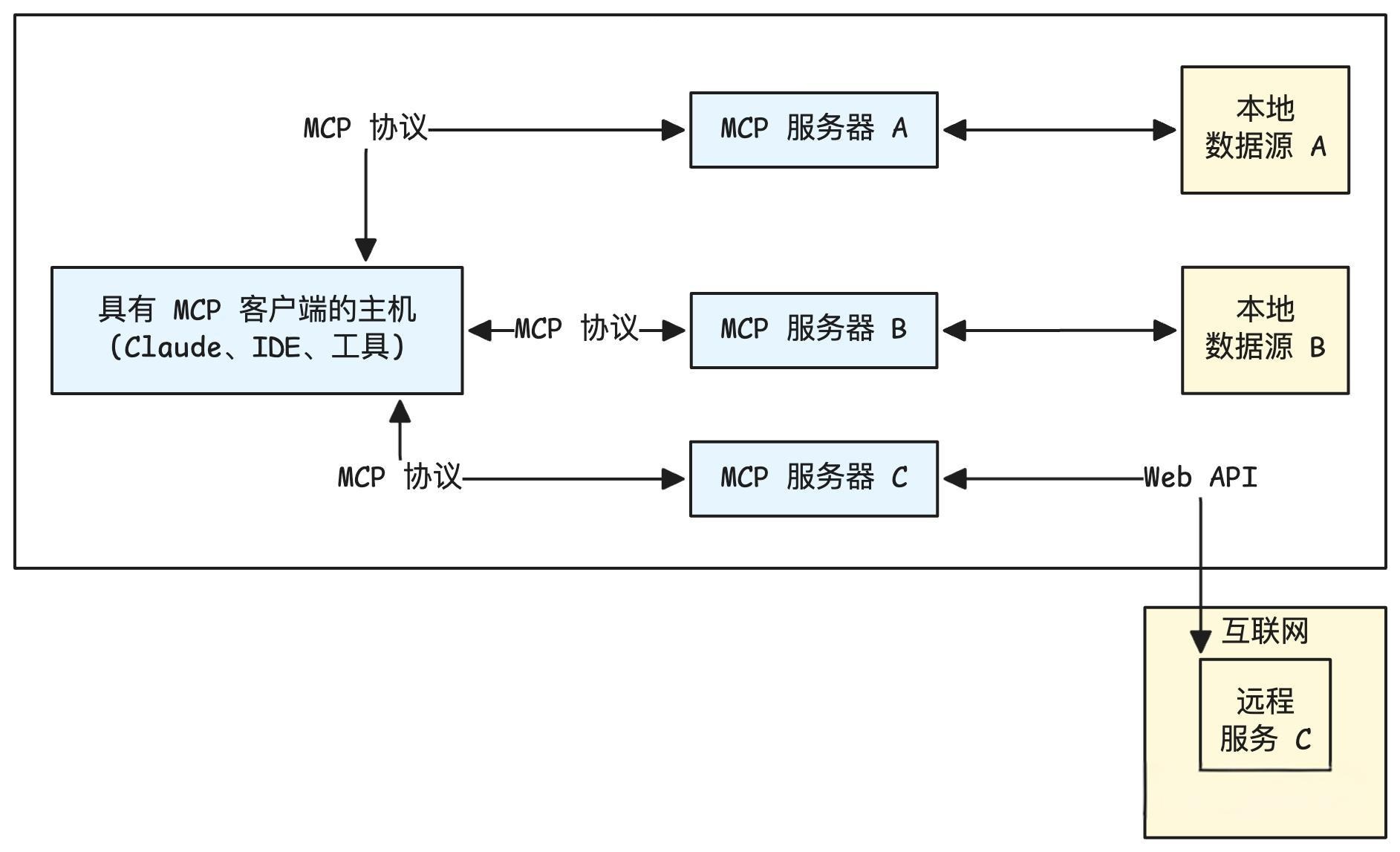
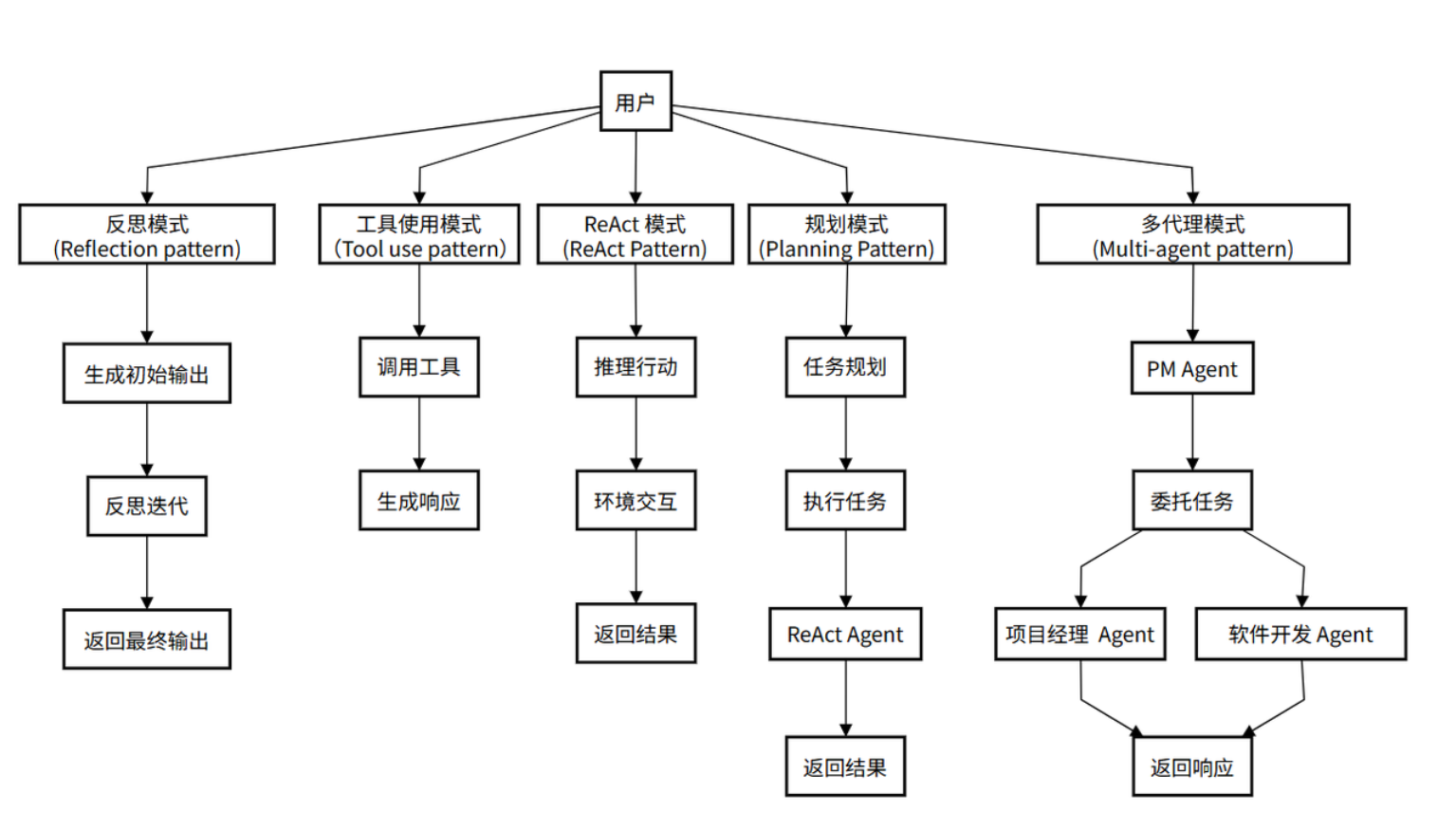
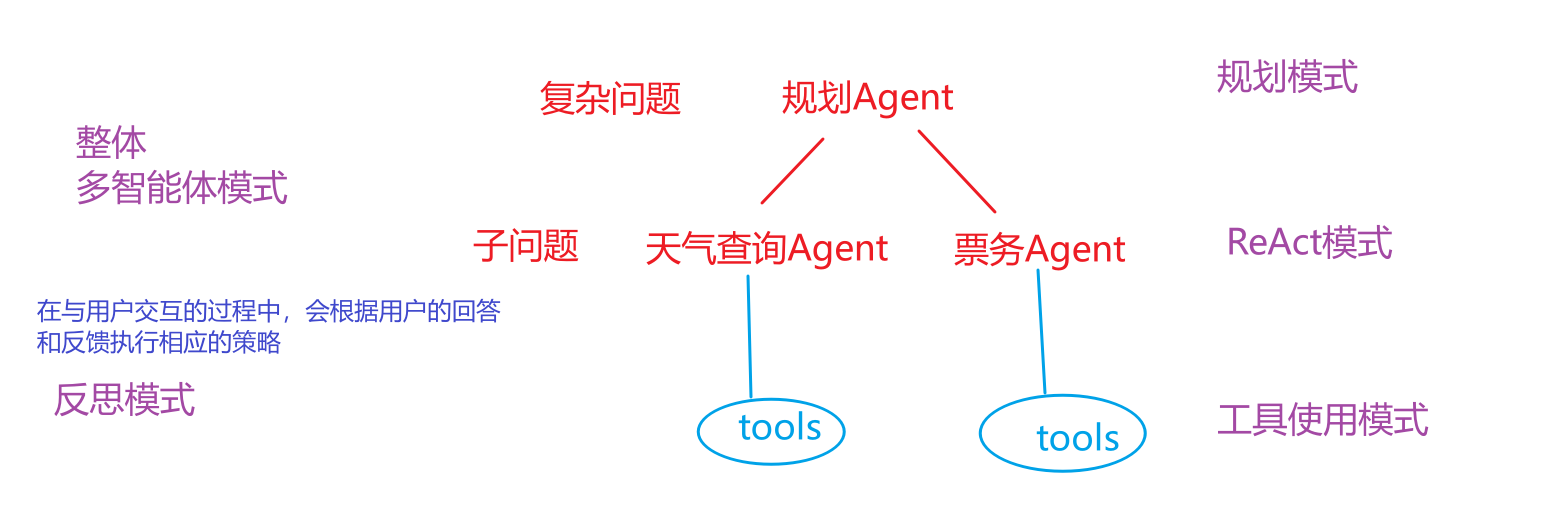

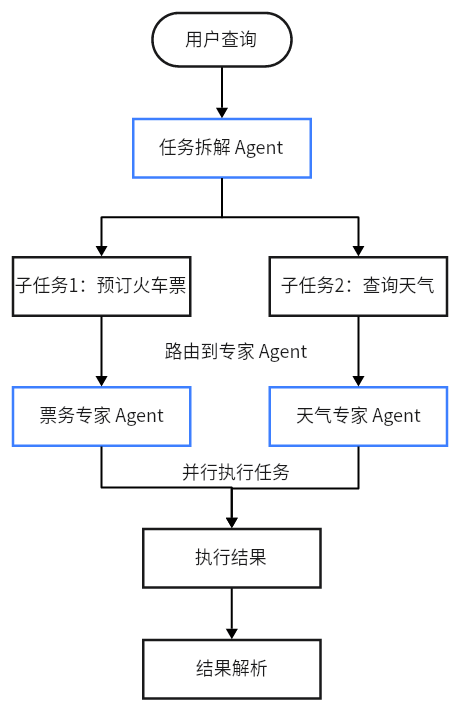
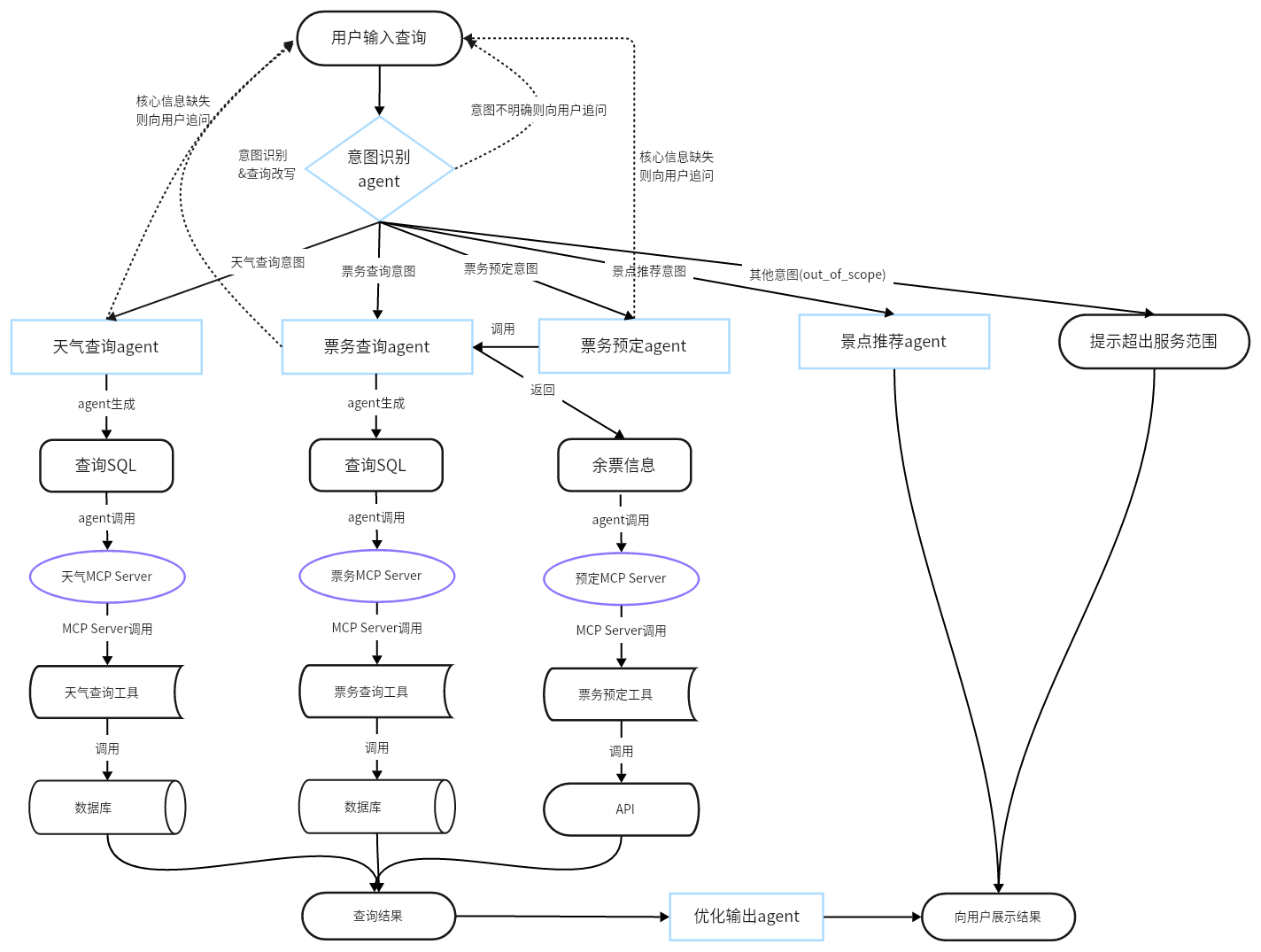
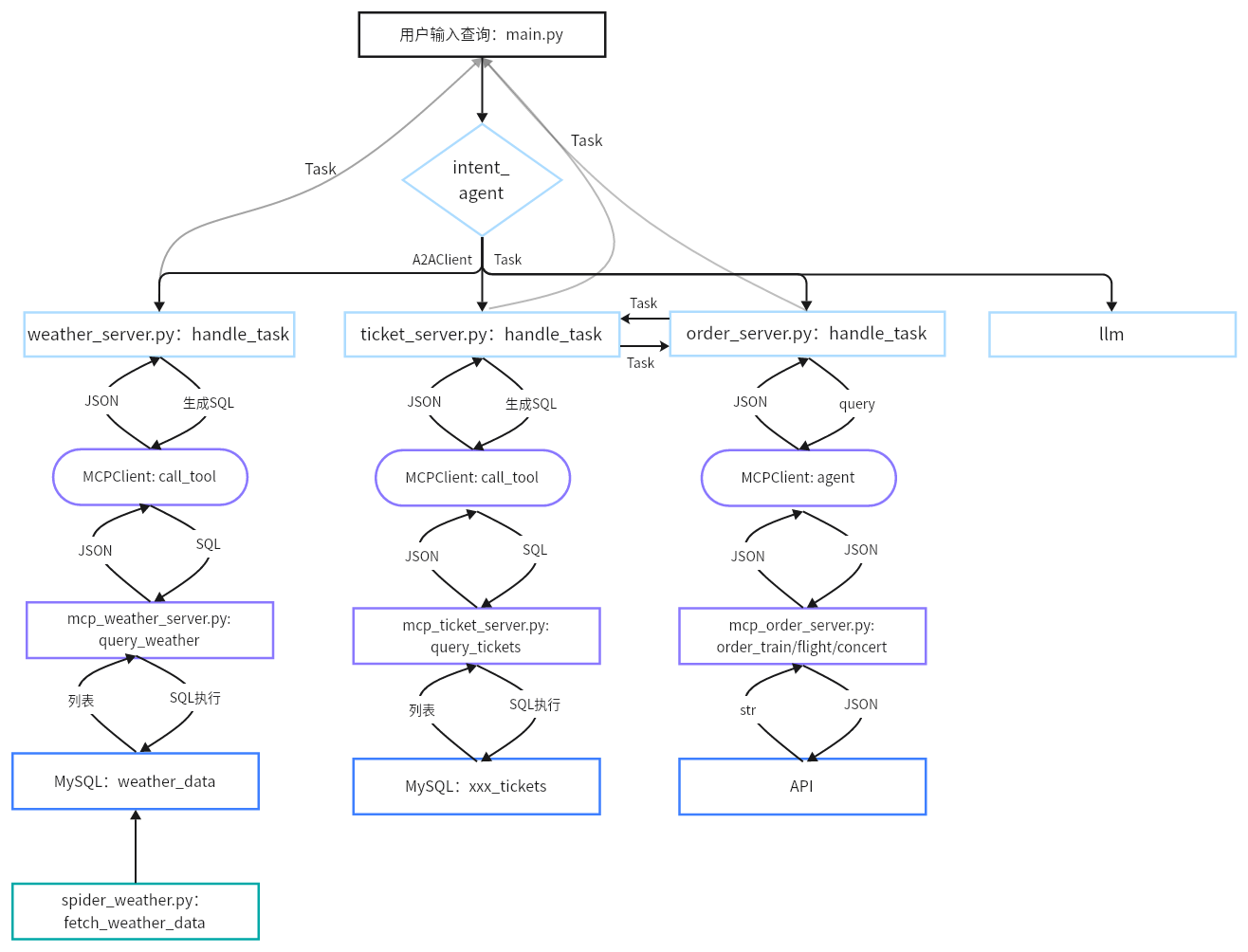
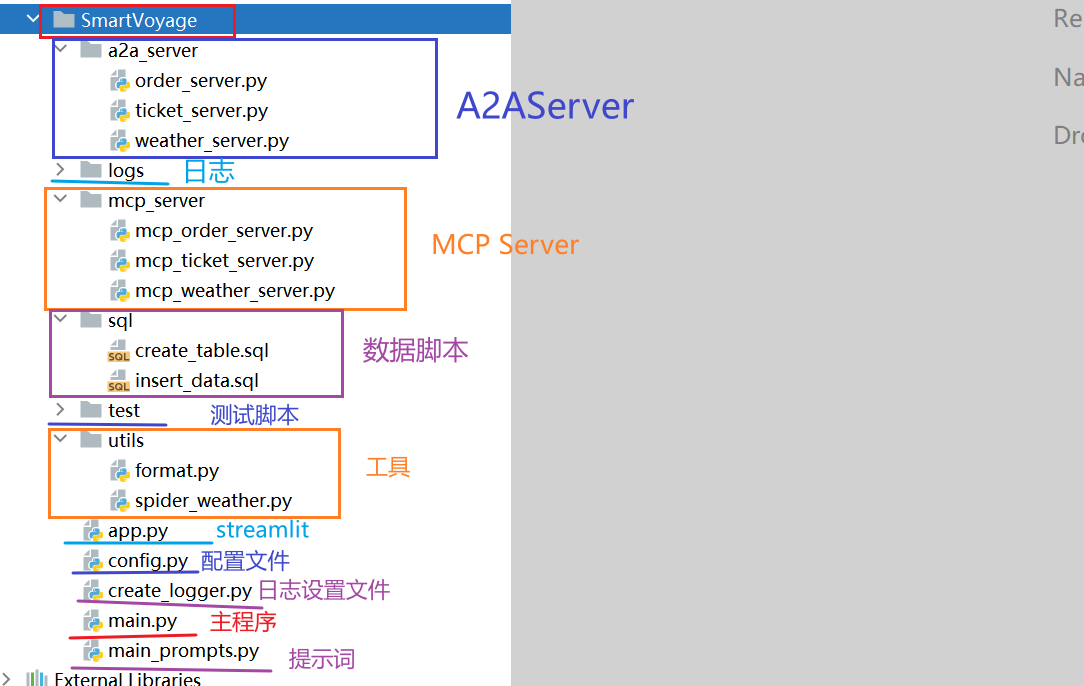

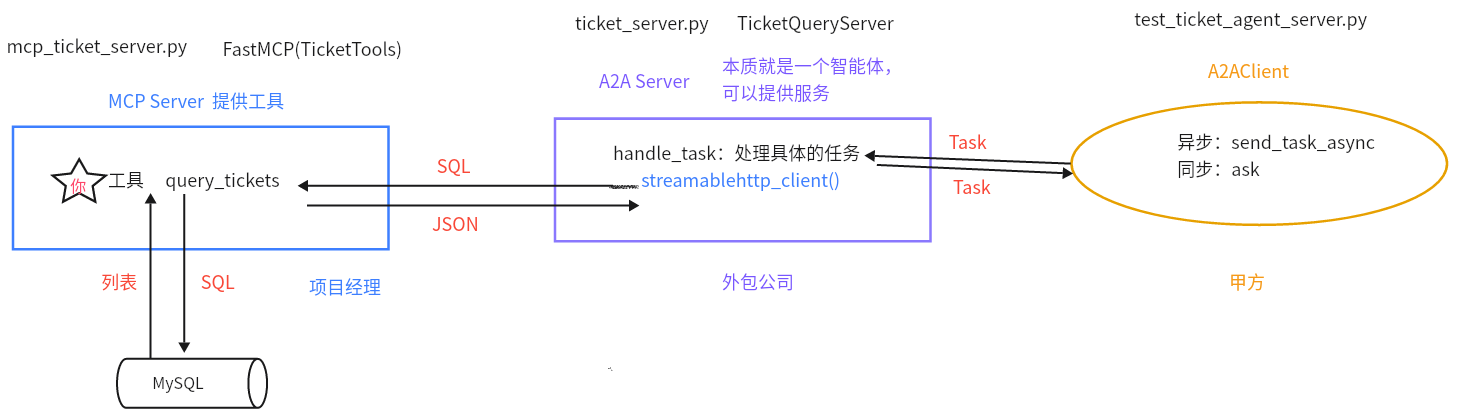
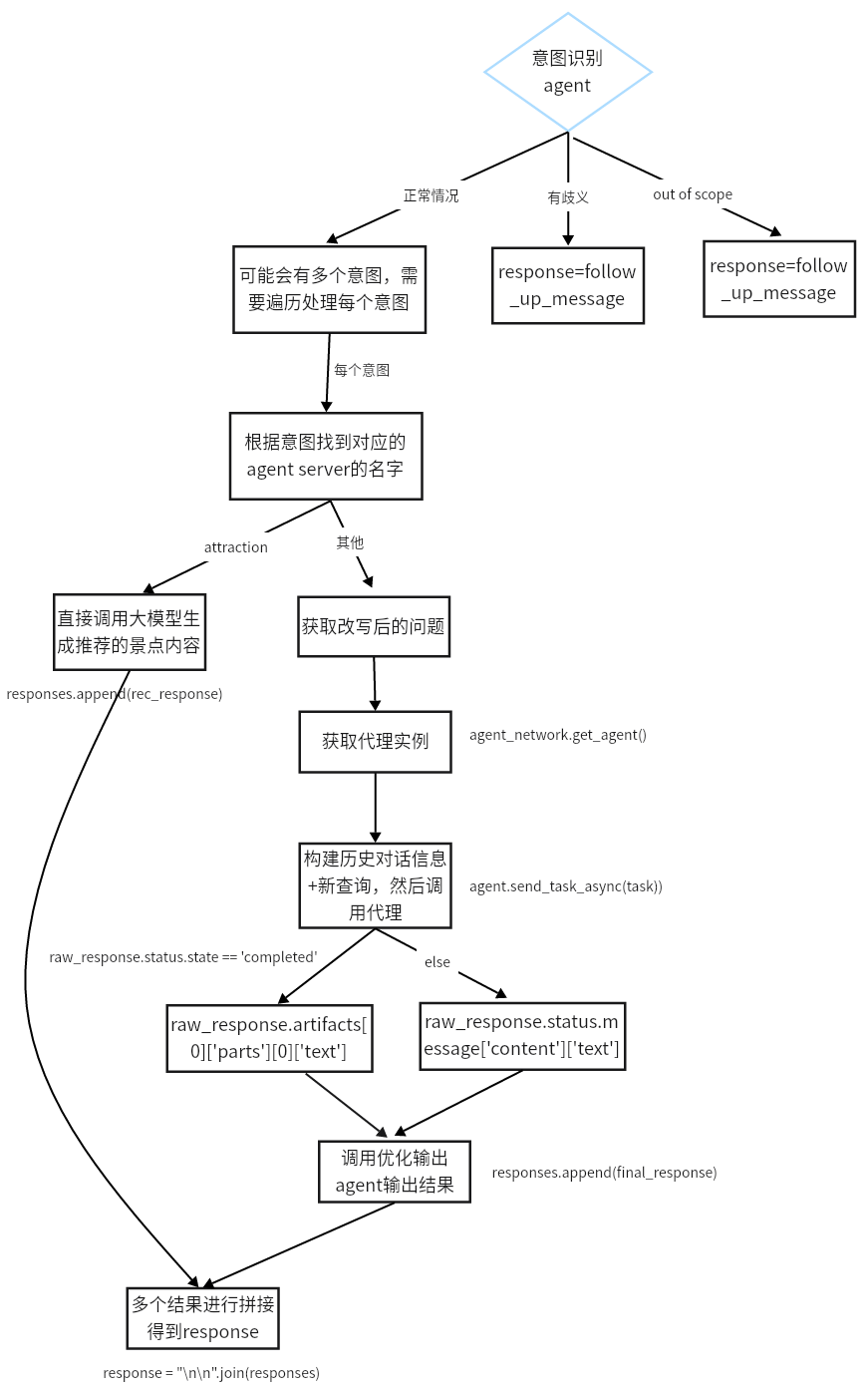
 微信
微信 支付宝
支付宝