Fine-Tuning
P01_大模型微调的主要方式【掌握】
1、大模型Prompt-Tuning方法
1.1 NLP任务四种范式
- 第一范式:基于传统机器学习模型
- 第二范式:基于深度学习
- 第三范式:基于预训练模型+fine-tuning
- 第四范式:预训练模型+Prompt+预测
1.2 Fine-Tuning(微调)
Fine-Tuning基本思想:使用小规模的特定任务文本继续训练预训练语言模型。
Fine-Tuning问题:
- 所需的Fine-Tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的Fine-Tuning,如果两者不相似,则可能需要更多的Fine-Tuning,并且效果不明显。
- 成本高
Prompt-Tuning的基本思想:通过添加模板的方法将任务目标转化为与预训练目标相似的形式(如MLM),避免引入额外的参数的同时,最大化利用模型的预训练知识。
Prompt-Tuning主要解决传统Fine-Tuning方式的两个痛点:
- **降低语义偏差:**预训练任务主要以MLM为主,而下游任务则重新引入新的训练参数,因此两个阶段目标差异较大。因此需要解决Pre-Training和Fine-Tuning之间的Gap。
- **避免过拟合:**由于Fine-Tuning阶段需要引入新的参数适配相应任务,因此在样本数量有限的情况下容易发生过拟合,降低模型泛化能力。因此需要解决预训练模型的过拟合能力。
1.3 Prompt-Tuning(提示微调)
(1)什么是Prompt?
即提示词
(2)Prompt-Tuing的本质
Fine-Tuning的本质:调整预训练模型,让预训练模型去迁就下游任务。
Prompt-Tuing的本质:让下游任务去迁就预训练模型,将Fine-tuning的下游任务目标转换为Pre-training的任务。
(3)Fine-Tuning和Prompt-Tuing对比
| 特征 | Fine-tuning (模型迁就任务) | Prompt Tuning (任务迁就模型) |
|---|---|---|
| 核心操作 | 修改预训练模型的参数,使其适应下游任务的数据和目标 | 调整少量参数(如软提示向量)或仅依赖输入设计(提示工程) |
| 模型状态 | 发生变化,学习新的特定任务知识 | 保持不变,利用已有的通用知识 |
| 任务目标 | 直接学习下游任务的特定目标函数 | 将下游任务目标重构为预训练模型更擅长的形式(如生成、补全) |
| 资源消耗 | 通常需要大量计算资源进行训练,为每个任务存储一个模型副本 | 计算资源消耗极少,只需存储和处理 Prompt |
| 目的 | 深度适应特定任务,可能牺牲通用性,但通常性能上限高 | 高效利用预训练模型的通用能力,在资源有限时效果显著,泛化性好 |
1.4 Prompt-Tuning技术发展历程
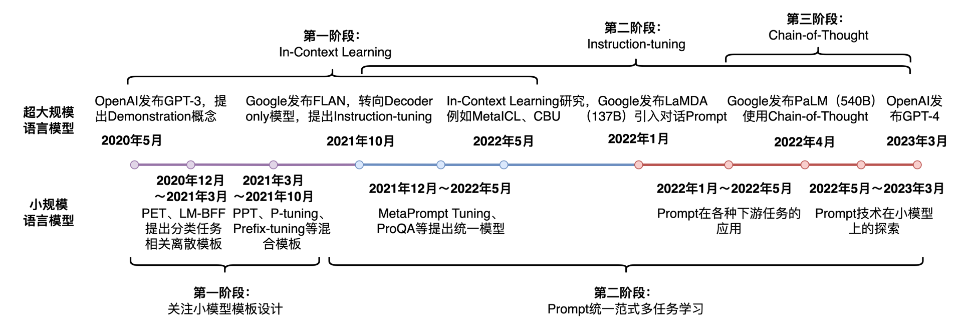
1.5 面向超大规模语言模型的Prompt-Tuning
特点:模型的 参数量足够大,训练过程中使用了足够多的语料,同时设计的预训练任务足够有效。
效果:只需要设计合适的模板或指令即可以实现免参数训练的零样本学习 。
类型:
- In-Context Learning(上下文学习):通过上下文示例(demonstrations)让模型理解任务,而无需显式训练。
- Instruction-Tuning(指令微调):在已有的预训练语言模型基础上,收集大量的成对数据(指令,期望输出),对模型进行额外的监督微调,让它学会遵循人类自然语言指令完成任务。
- Chain-of-Thought(思维链):一种改进的提示策略,用于提高 LLM 在复杂推理任务中的性能。方法就是相比于之前的上下文学习多了中间的推导过程提示。
1.6 面向小规模语言模型的Prompt-Tuning
1.6.1 Prompt-Tuning的鼻祖—PET模型
(1)PET模型的核心思想:将下游任务重构为预训练模型最熟悉的“完形填空”问题,从而利用语言模型对文本的理解能力,最终通过少量示例训练获得较好的下游性能。
(2)方法:通过设计自然语言模式(pattern)和标签词映射(verbalizer),将输入句子转换为带有[MASK]位置的文本,例如“这个电影很[MASK]。”,然后用预训练语言模型(如BERT)预测[MASK]位置的词,再通过verbalizer转换来完成分类任务。
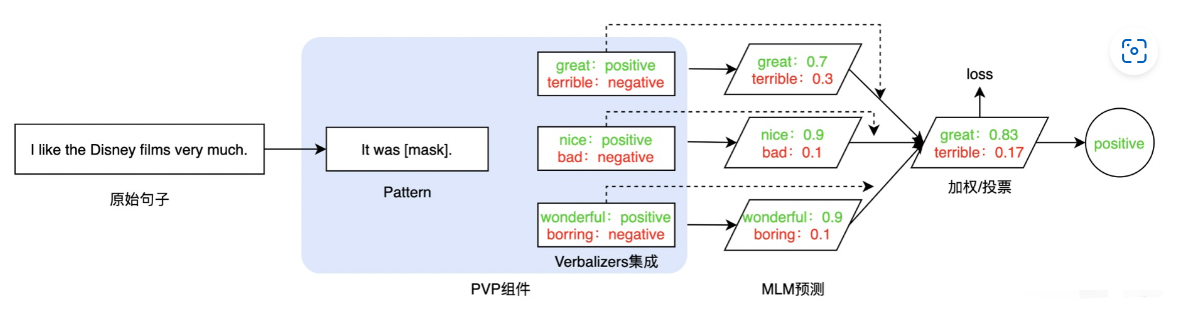
(3)PVP组件
- Pattern(Template) :记作T,为额外添加的带有
[mask]标记的短文本,用于引出不同任务的预测词。 - Verbalizer :记作V, 即标签词的映射,对于具体的分类任务,需要选择指定的标签词(label word)。
(4)人工设计PVP的缺陷
- 采用人工构建的方法成本高,需要与领域任务相关的先验知识
- 人工设计的Pattern和Verbalizer不能保证获得最优解,训练不稳定,不同的PVP对结果产生的差异明显,方差大
- 人工构建的Pattern和Verbalizer使得Prompt-Tuning与MLM在语义和分布上依然存在差异
1.6.2 Prompt-Oriented Fine-Tuning
(1)本质:本将目标任务转换为适应预训练模型的预训练任务,以适应预训练模型的学习体系。
(2)类型
根据提示的类型不同,POFT方法主要分成三种类型:
- 离散提示:也叫硬模版,其提示是由真实的自然语言单词或符号组成,直接拼接到输入中。
- 连续提示:
也叫软模板,提示不是实际的单词,而是**可训练的向量**,插入到输入 embedding 序列中。 - 混合提示:同时使用人工可读的离散 token和可训练的连续向量。
按照训练时参数更新的范围不同,POFT方法主要分成三种类型:
- 全量微调(Full Fine-Tuning):模型所有参数都参与更新,包括预训练模型参数和下游任务层参数。如PET模型。
- 部分参数微调(Partial Fine-Tuning):只更新预训练模型中的一部分参数,比如高层 transformer block、某些 attention 层或特定模块,其余参数冻结。如Adapter Tuning。
- 仅提示参数微调(Prompt-Only Tuning):
冻结原始预训练模型参数,只训练 prompt 参数。如P-tuning、Prompt Tuning等。
(3)PET中使用的POFT:硬模板+ 全量微调
全量微调:成本高,要求数据量大
硬模版:人工构建成本高、不同PVP对结果产生的差异明显、与MLM训练任务不完全一致
1.6.3 Soft Prompt及微调方法
1.6.3.1 连续提示模板
Soft Prompt (连续提示) :是指通过给模型输入一个可参数化的提示模板,从而引导模型生成符合特定要求的文本。
特点:
- 将模板变为可训练的参数,不同的样本可以在连续的向量空间中寻找合适的伪标记,同时也增加模型的泛化能力。
- 连续法需要引入少量的参数并在训练时进行参数更新,但预训练模型参数是不变的,变的是prompt token对应的词向量(Word Embedding)表征及其他引入的少量参数。
1.6.3.2 Prompt Tuning(NLG任务)
(1)方法:为每一个输入文本假设一个固定前缀提示,该提示表由神经网络参数化,并在下游任务微调时进行更新,整个过程中预训练的大模型参数被冻结。
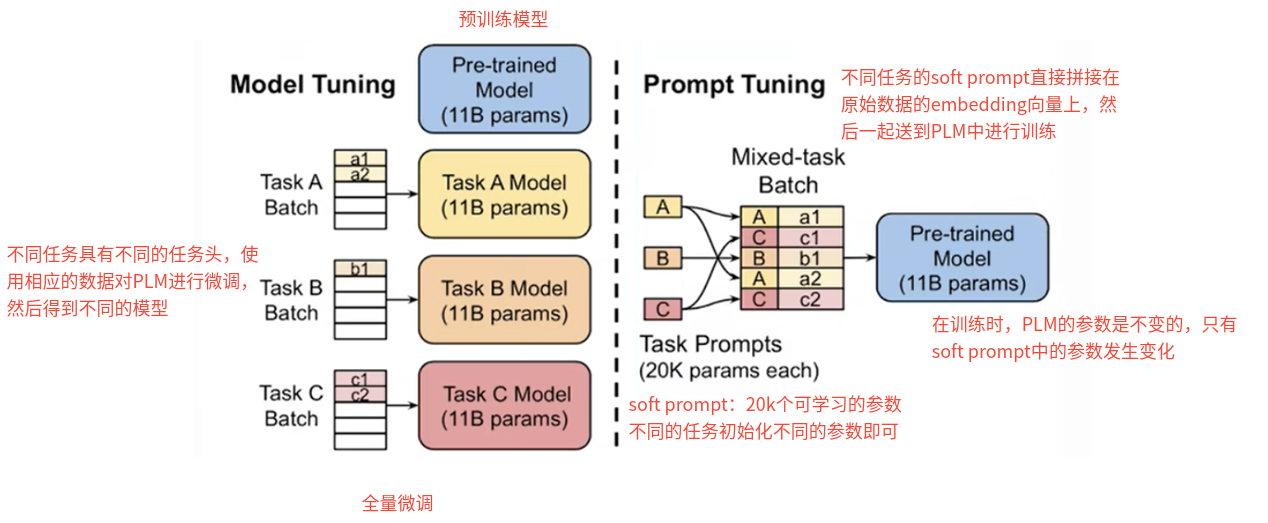
(2)特点
- 优点:
- 大模型的微调新范式
- 模型参数规模大了之后,可以将大模型参数固定,指定附加参数来适配下游任务,而且适配性能基本和全参数微调相当。
- 缺点:
- 在小样本学习场景上表现不太行
- 收敛速度比较慢
- 调参比较复杂
1.6.3.3 P-tuning(NLU任务)
(1)P-tuning 的核心思想是:用一个小的可训练模块把一组“连续提示向量”生成并插入到原始输入 embedding 中,令冻结的预训练模型在下游任务上产生正确输出,训练时仅更新 prompt encoder(或提示向量),从而实现低成本高效的调优。
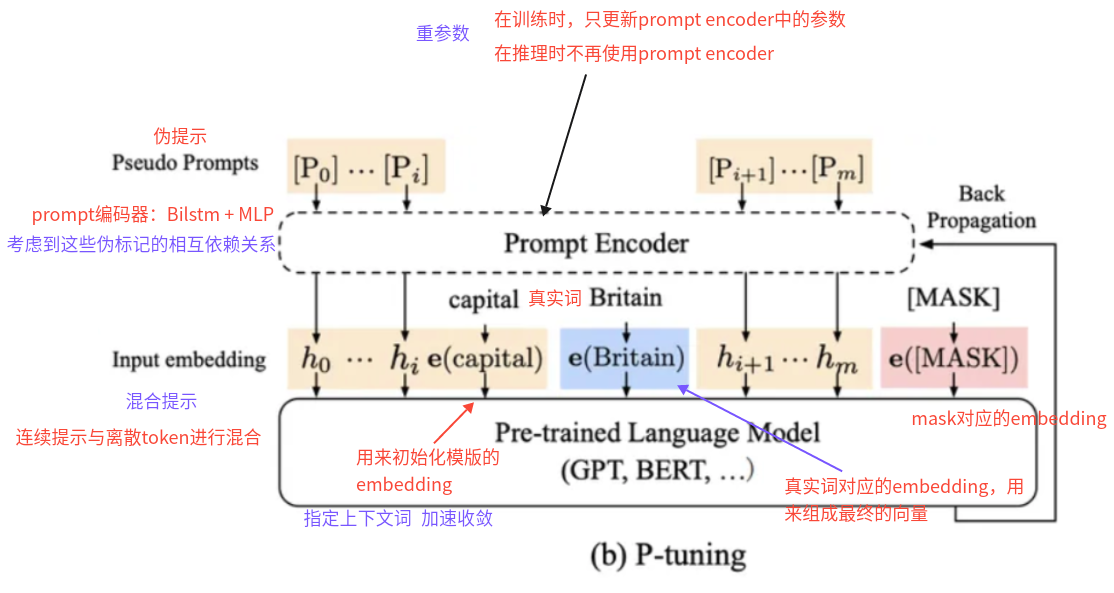
(2)P-tuning的特点:
- 优点:
- 引入了一个 LSTM +MLP模块对 soft prompt 进行建模,能捕捉 token 之间的顺序和语义关系
- 改进了离散 prompt的不稳定性问题,收敛速度更快
- 缺点
- 仅放在输入层时,对模型内部深层表征的影响有限,面对一些需要深层表示调整的 NLU/序列标注任务表现并不稳定或不足
- 在中小模型(100M–1B)表现较差
(3)P-Tuning v2的核心思想:在模型的每一层都应用连续的 prompts 并对 prompts 参数进行更新优化
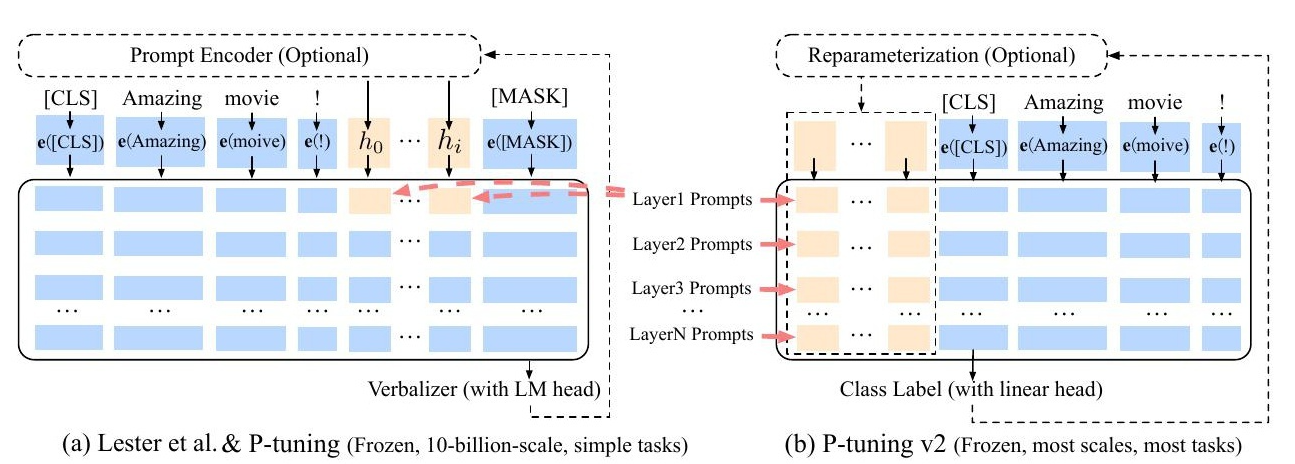
注意:P-Tuning v2中,在一些任务中,引入一个重参数化的编码器(如MLP,多层感知机)可以对提示向量进行非线性变换,提升模型性能。但是,研究发现其效果因任务而异,因此在P-Tuning v2中,是否使用重参数化需要根据具体任务进行选择。
- 使用重参数化:使用MLP对前缀嵌入进行转换(对应于Prefix-Tuning)
- 不使用重参数化:直接使用前缀嵌入(对应于P-Tuning v2)
(4)P-tuning v2的特点:
- 优点:
- 把 soft prompts 注入每层,能在多种规模与任务上接近全量微调效果
- 缺点
- 深层 prompt 或长 soft prompt 会占用较多 token / 输入空间
- P-tuning 的 soft prompt 是针对每个下游任务独立训练的,无法直接迁移到其他任务上使用
(5)P-tuning v1与P-tuning v2对比
| 对比 维度 | P-tuning v1 | P-tuning v2 |
|---|---|---|
| 提出时间 | 2021(原始 P-tuning) | 2022(P-tuning v2) |
| 核心思路 | 在输入 embedding 层前插入连续可训练的 prompt embeddings,通过 LSTM/MLP 对伪标记编码,优化这些参数以适配下游任务 | 在 Transformer 每一层 注入可训练的 layer-wise prompts(类似 prefix-tuning),直接与各层隐状态交互 |
| 插入位置 | 仅作用于 embedding 层(输入端) | 作用于 每一层 Transformer(layer-wise prompt) |
| 参数规模 | 较少(仅输入 prompt 参数) | 略多于 v1(每层都有 prompt 参数),但仍远小于全量微调 |
| 表达能力 | 容易受限,难以在小数据任务中获得与全量微调接近的性能 | 表达能力更强,性能更接近甚至超越全量微调 |
| 训练方式 | 仅优化 prompt encoder 参数,其余预训练模型参数冻结 | 冻结预训练模型主干,优化每层的 prompt 参数 |
| 初始化方式 | 通常从 vocab embedding 随机或用任务相关词初始化 | 通常随机初始化,也可借助任务先验初始化 |
| 依赖组件 | 需要 Prompt Encoder(如 LSTM/MLP)来生成连续模板向量 | 不需要复杂 Prompt Encoder,直接将可训练向量作为 prefix 注入每层 |
| 优点 | 参数量小、实现简单、易迁移到不同任务 | 表达能力强、在低资源场景下性能稳定、接近全量微调效果 |
| 缺点 | 对复杂任务适配能力不足,深层信息利用不充分 | 参数量稍大,实现比 v1 复杂,需要改造模型结构 |
| 适用场景 | 对计算资源和任务复杂度要求低的场景 | 更复杂、对性能要求高或低资源任务中替代全量微调 |
1.6.3.4 PPT(Pre-trained Prompt Tuning)
(1)PPT 的核心思想:对连续提示模板也进行预训练——先让这些连续提示在大量无标注的预训练语料进行预训练(注意,预训练过程中,Pre-train-model参数固定不变,只改变soft prompt),然后将其加载到对应下游任务的PLM上进行微调后使用。
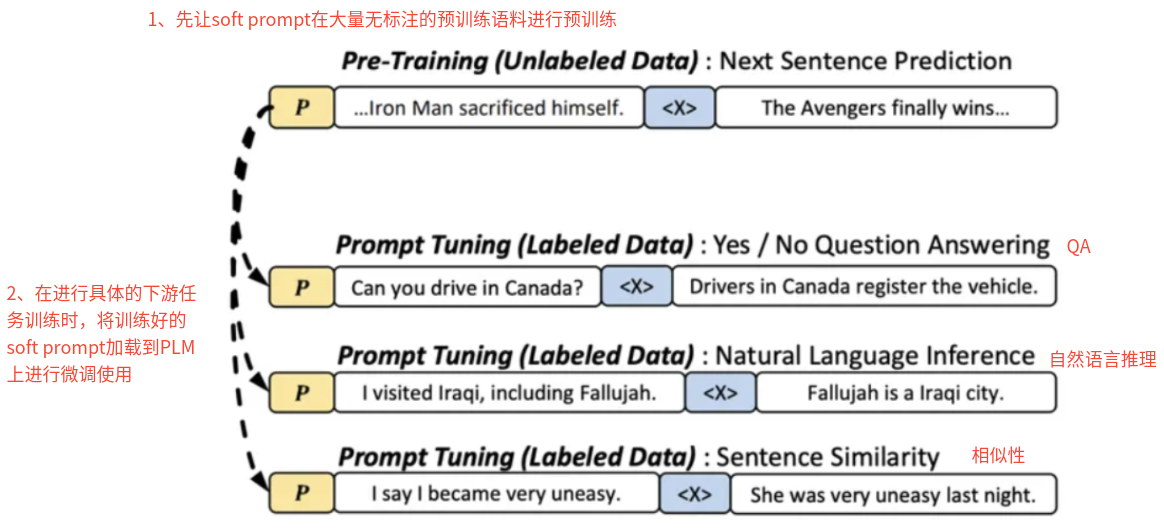
(2)PPT的特点:
- 优点:
- 预训练soft-prompt带来了 小样本学习场景上的显著提升
- 缓解了prompt-tuning收敛慢的问题
- 缺点
- 高度依赖于源任务集的覆盖度与多样性(一旦目标任务与预训练时用到的源任务在分布、格式或语义上差异较大,通用提示 𝑃就难以提供有效的初始引导,导致下游微调效果大幅下降)
2、大模型PEFT微调方法【掌握】
(1)参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT)特点:
PEFT 方法仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本
最先进的 PEFT 技术也能实现了与全量微调相当的性能
(2)类型
- Prefix/Prompt-Tuning:在模型的输入或隐层添加 $k$个额外可训练的前缀 tokens(这些前缀是连续的伪 tokens,不对应真实的 tokens),只训练这些前缀参数;
- Adapter-Tuning:将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块称为 adapter(适配器),下游任务微调时也只训练这些适配器参数;
- LoRA:通过学习小参数的低秩矩阵来近似模型权重矩阵 $W$的参数更新,训练时只优化低秩矩阵参数。
2.1 Prefix Tuning
(1)做法:在模型的输入或隐层添加 $k$个额外可训练的前缀 tokens(这些前缀是连续的伪 tokens,不对应真实的 tokens),只训练这些前缀参数
(2)具体实现流程如下:
1)确定任务与基模型
- 任务:条件生成(如摘要、表格到文本、对话)或 seq2seq。
- 选模型:GPT-2/decoder-only 或 BART/T5(encoder-decoder)。
2)设计 prefix 配置
- 决定
num_prefix(每层的虚拟 token 数,常见 10–100),以及是否对所有层都使用 prefix(论文对每层都用了 prefix,但可做只对部分层)。
3)构造可训练参数(初始化)
原始论文中为每层创建一个可以训练的矩阵$P_θ$ ,作为前缀向量拼接到原向量中。但是论文中提出直接优化 $P_θ$ 会导致训练不稳定,可以通过一个更小的矩阵 $P_w$和一个更大的前馈神经网络$MLP_θ$ 对$P_θ$ 进行重参数化: $P_θ[i,:]=MLP_θ(P_w[i,:])$ 。
所以目前实际实现时,通常会先训练一个 (num_layers, num_prefix, hidden_dim) 的 prefix embedding,然后通过一个小的 MLP 投影成 (num_layers, num_prefix, 2 * head_dim * num_heads),再 reshape 成 (num_layers, num_heads, num_prefix, head_dim),分别拆成 K 和 V。因此需要创建一个可训练的矩阵 $P_θ$ ,以及一个MLP模型。
4)修改模型前向(插入 prefix)
- 在 Transformer 的每一层注意力里,将 prefix 对应的 key/value 拼接到原始的 key/value——这样后续 token 可以像“看到真实 tokens”一样 attend 到 prefix,然后一起进行训练。
5)训练设置
- 冻结原模型参数(
requires_grad=False),只对 prefix 参数做优化。 - 损失函数通常是标准的交叉熵,训练器只更新 prefix。
6)推理
- 推理时把训练好的 prefix 附加到每层(同训练时),然后用常见的解码策略进行生成。
(3)Prefix Tuning的特点:
- 优点:
- 只训练少量 prefix 参数,相对全量微调的存储和训练成本低。
- 不同任务只需切换 prefix,无需保存多个完整模型。
- 缺点
- 小模型表现差:在 BERT-base 等小模型上效果不佳
- 需在每层注入 prefix,会占用输入序列的长度
- 在判别式任务上常逊于 LoRA、P-Tuning v2
(4)Prefix Tuning与P-Tuning v1和v2的区别
1)目标任务
Prefix-Tuning:主要面向生成类任务(table→text、summarization、GPT-2/BART 等场景),论文强调在生成上用少量参数达到接近微调的效果。
P-Tuning v1和v2:主要针对NLU(分类、序列标注、QA 等),目标是让 prompt-only 方法在 NLU 上也能普遍接近微调的性能。
2)注入位置
- P-tuning v1:只在输入 embedding 处(相当于在输入序列前加若干soft prompt 的 embedding)。
- Prefix Tuning / P-tuning v2:在 Transformer 每一层的中都进行注入。
3)注入形式
Prefix Tuning和P-tuning v2:将前缀token直接作用到注意力机制计算的
key/value上,然后进行注意力计算。P-tuning v1是将原始embedding+prompt embedding组成的新输入后送入下一层。
4)参数化方式
- Prefix Tuning:原始论文中直接优化每层的“past key/value”向量(通常把这些向量当作要学习的参数矩阵);另外,也提出生成一个初始向量,再通过MLP进行投影效果更好。
- P-tuning v1:通过 prompt encoder优化一组输入级别的 embedding。
- P-tuning v2:提出了可选的 reparameterization(用小网络如MLP把少量可训练参数映射成每层的完整 prompt),利于参数共享、稳定训练并在层数很多时控制参数量。如果不用reparameterization则直接使用embedding的结果。
5)效果
- P-tuning v1:对 decoder-only、encoder-decoder 都可用,但效果和适用性有限(因为只在输入层)。
- Prefix Tuning 与 P-tuning v2:更适合需要深层修改注意力的信息流的任务(对 decoder-only 和 encoder-decoder 都能做扩展,且在很多任务上性能更好)。
2.2 Adapter Tuning
(1)做法:在预训练模型内部的网络层之间添加新的网络层或模块来适配下游任务
(2)Series Adapter的适配器结构和与 Transformer 的集成结构:
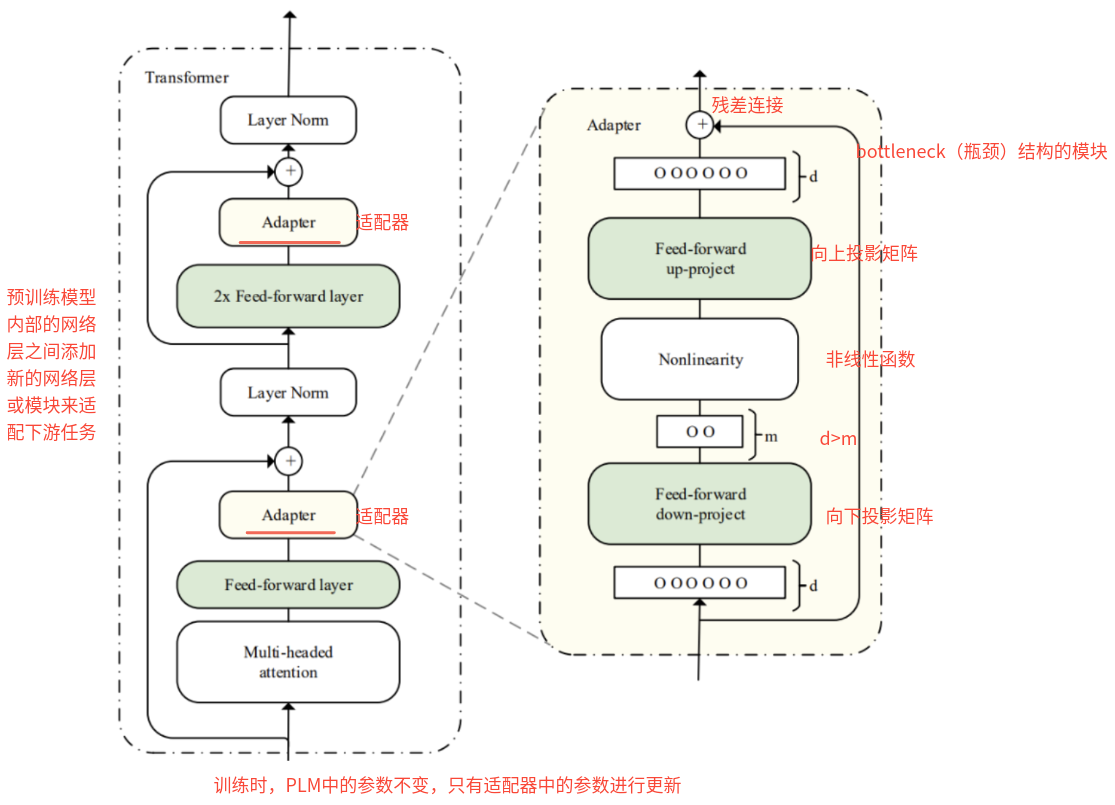
(3)Adapter Tuning的特点:
- 优点:
- 只训练少量 adapter 参数,相对全量微调的存储和训练成本低。
- 可以为多个任务保存不同的 adapter,而共享一个大模型。
- 多个任务的 adapters 可以在推理时进行切换或融合,提升迁移和泛化能力。
- 缺点
- 因为大部分参数被冻结,adapter 的容量有限,对复杂任务或需要大规模参数调整的任务可能效果不如全量微调。
- Adapter 的维度大小(瓶颈层大小)、插入位置等超参数对性能影响较大,调参复杂度较高。
- PLM 基础上添加适配器层会引入额外的计算,带来推理延迟问题
2.3 LoRA
(1)补充知识——秩
- 1)什么叫做秩?
矩阵中所有行向量(或列向量)所张成的向量空间的维数。
换句话说,秩衡量了矩阵里有多少个 线性无关的行/列。如果把矩阵看成是很多向量的集合,那么秩就是这些向量中最多能取出的互不依赖的数量。

2)秩的几种等价定义
行秩:矩阵中线性无关的行向量个数
列秩:矩阵中线性无关的列向量个数
基本定理:行秩 = 列秩,这个共同的数就是矩阵的秩。
3)秩的直观理解
秩 = 有效信息量,秩越高,矩阵包含的独立信息越多。
(2)做法:在预训练语言模型(PLM)的特定线性层(如自注意力机制中的 Q、K、V 投影层和前馈网络)旁边,并行地注入一对小的、可训练的低秩分解矩阵,而冻结 PLM 的原有参数。
低秩适应:对大型模型的权重矩阵进行隐式的低秩转换,也就是:通过一个较低维度的表示来近似表示一个高维矩阵或数据集。
(3)基本原理:LoRA技术冻结预训练模型的权重,并在每个Transformer块中注入可训练层(称为秩分解矩阵),即在模型的Linear层的旁边增加一个“旁支”A和B。其中,A将数据从d维降到r维,这个r是LoRA的秩,是一个重要的超参数;B将数据从r维升到d维,B部分的参数初始为0。模型训练结束后,需要将A+B部分的参数与原大模型的参数合并在一起使用。
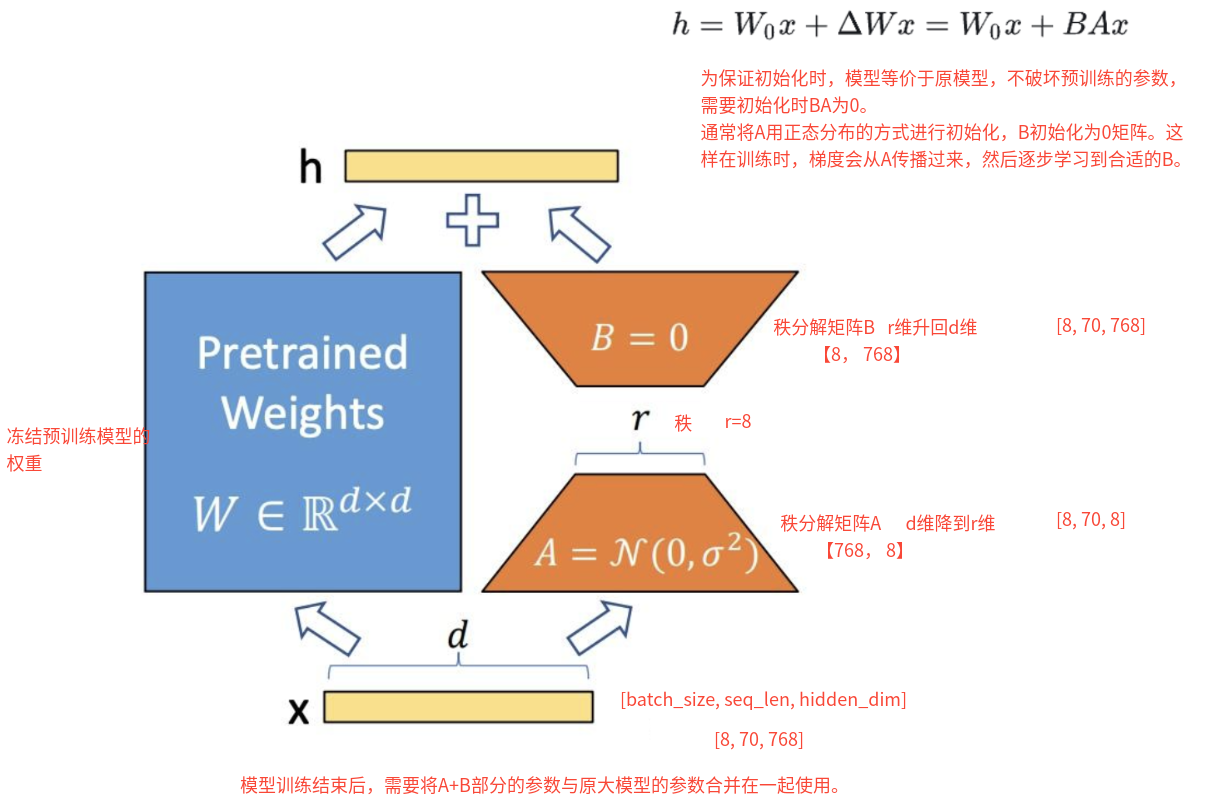
(4)LoRA的特点:
- 优点:
- 只训练极少参数,相对全量微调的存储和训练成本低。
- 效果接近全参数微调,且保留原模型能力。
- 不同任务的 LoRA 模块可插拔,便于多任务部署。
- 缺点
- LoRA 本质是用低秩分解逼近权重更新矩阵,这对参数空间的表达能力有限制,可能无法拟合某些复杂任务所需的高秩变化。
- LoRA 通常加在 attention 的投影矩阵(Wq/Wv)上,但不同任务可能对位置敏感,选择不好会影响性能。
2.4 QLoRA
(1)核心思想是:通过对预训练语言模型(PLM)进行量化(通常是 4-bit NormalFloat),并结合 LoRA 技术进行微调,从而在极低的内存消耗下,仍然能够高效地微调巨型语言模型,同时保持甚至超越全量 16-bit LoRA 的性能。
(2)核心创新点
- 高效低精度量化(NF4 量化):NF4 采用了非均匀的数值分布映射,更好地保留了原始权重的细微差异,使得在极低精度下仍能保持接近 FP16 的模型性能。
- 采用双量化和分页优化器,进一步减少显存占用。
- 在量化后的冻结PLM上,LoRA的微调机制保持不变。
(3)QLoRA的特点
- 优点:
- 极低的内存消耗。这是 QLoRA 最显著的优势。可以将训练巨型模型的内存需求降低 3-4 倍,使得在单张消费级 GPU 上(如 24GB VRAM 的 RTX 3090/4090)微调 65B 甚至 70B 参数的模型成为可能。
- 性能优异:尽管进行了 4-bit 量化,但由于 16-bit 的 LoRA 权重和优化器状态,QLoRA 在许多任务上能够保持与 16-bit LoRA 甚至全量微调相媲美的性能。
- 训练速度快:由于只训练少量参数且内存效率高,训练速度非常快。
- 缺点
- 虽然 NF4 优化了精度,但极端任务或敏感任务可能仍受 4-bit 量化影响。
- 由于量化和分页机制的存在,训练和问题调试会比标准 LoRA 更复杂。
基于GPT2的医疗问诊机器人
学习目标
- 理解医疗问诊机器人的开发背景.
- 了解企业中聊天机器人的应用场景
- 掌握基于GPT2模型搭建医疗问诊机器人的实现过程
1. 项目介绍
1.1 项目背景
- 本项目基于医疗领域数据构建了智能医疗问答系统,目的是为为用户提供准确、高效、优质的医疗问答服务。
1.2 环境准备
- python`3.10
- transformers`4.40.2
- torch`2.5.1+cu121
1.3 项目整体结构
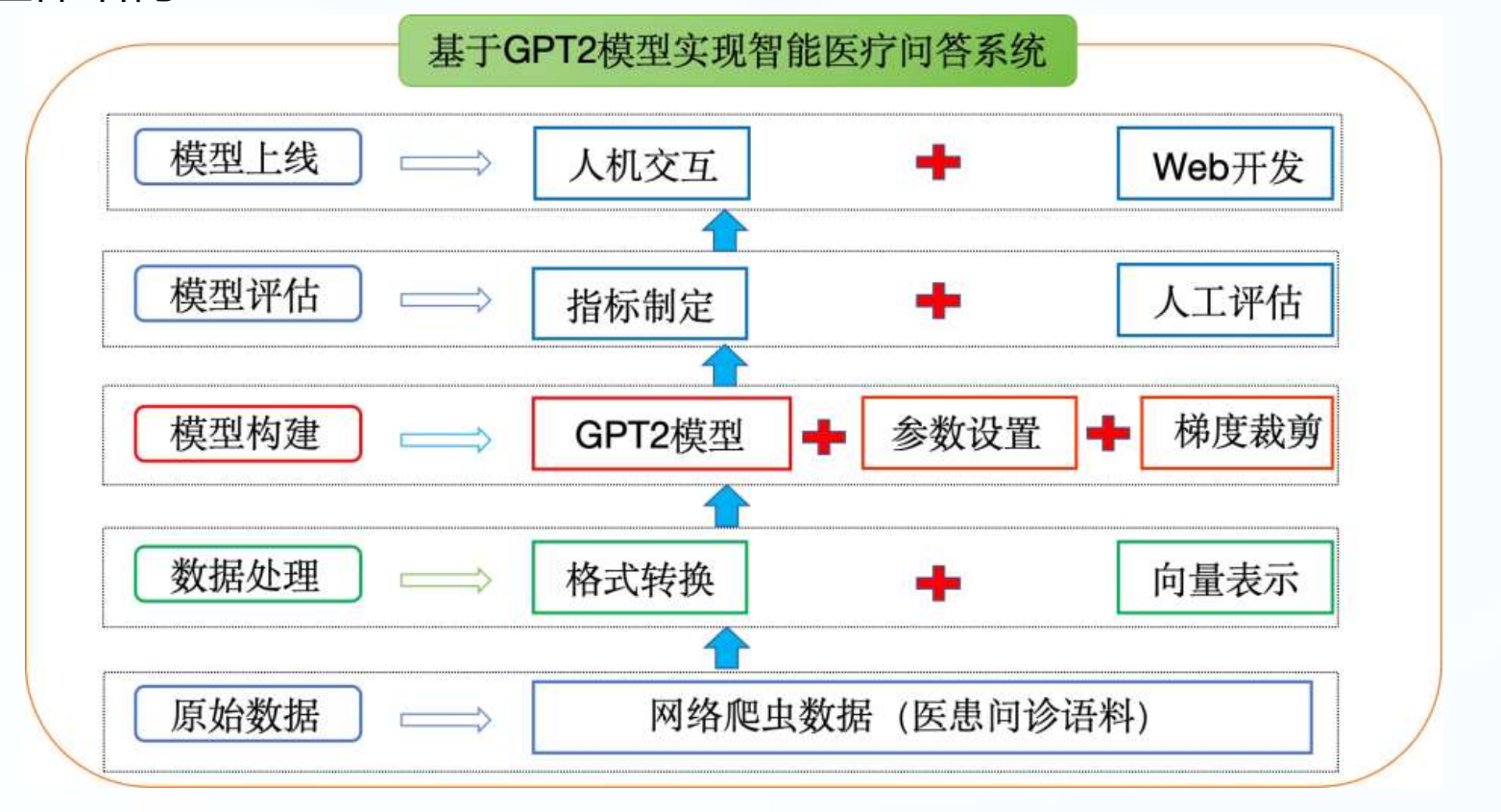
整体代码结构:

2. 数据处理
2.1 数据介绍
- 数据存放位置:llm_tuning/Gpt2_Chatbot/data
- data文件夹中存有原始训练语料为train.txt。train.txt的格式如下,每段闲聊之间间隔一行,格式如下:
1 | 帕金森叠加综合征的辅助治疗有些什么? |
2.2 数据处理
- 目的:将中文文本数据处理成模型能够识别的张量形式,并将上述文本进行张量的转换
- 实现过程:
- 运行preprocess.py,对data/train.txt对话语料进行tokenize,然后进行序列化保存到data/train.pkl。train.pkl中序列化的对象的类型为List[List],记录对话列表中,每个对话包含的token。
2.2.1 配置文件
- 代码路径:llm_tuning/Gpt2_Chatbot/parameter_config.py
1 | import torch |
2.2.1 数据张量转换
- 步骤

1 | 1. 加载分词器 |
- 代码路径:llm_tuning/Gpt2_Chatbot/data_preprocess/preprocess.py
1 | import pickle |
2.2.2 获取dataloader
(1)封装Dataset对象
- 代码路径:llm_tuning/Gpt2_Chatbot/data_preprocess/dataset.py
1 | import pickle |
(2)封装DataLoader对象
- 代码路径:/home/user/ProjectStudy/Gpt2_Chatbot/data_preprocess/dataloader.py
1 | import pickle |
3. 模型搭建
3.1 模型架构介绍
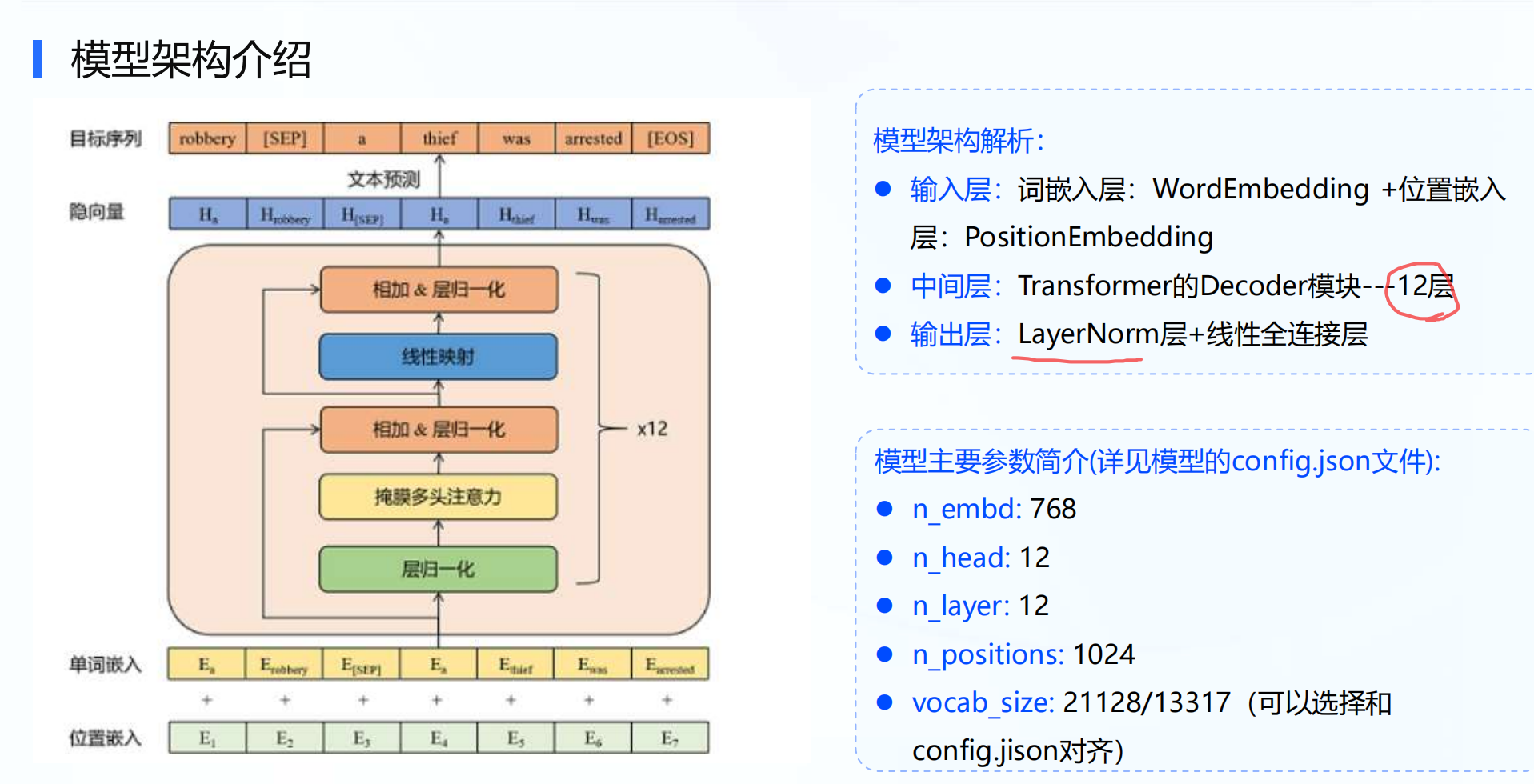
模型架构解析:
- 输入层:词嵌入层:WordEmbedding +位置嵌入层:PositionEmbedding
- 中间层:Transformer的Decoder模块—12层
- 输出层:LayerNorm层 + 线性全连接层
模型主要参数简介(详见模型的config.json文件):
- n_embd: 768
- n_head: 12
- n_layer: 12
- n_positions: 1024
- vocab_size: 13317
3.2 GPT2模型准备
- 本次项目使用GPT2的预训练模型,因此不需要额外搭建Model类,下面代码是如何直接加载使用GPT2预训练模型
- 代码示例:
1 | from transformers import GPT2LMHeadModel, GPT2Config |
- 如果使用第二种方式,需要配置模型的参数
- 注意:
这里指的参数并不是模型的权重!
位置:llm_tuning/Gpt2_Chatbot/config/config.json
1 | { |
4. 模型训练和验证
代码介绍
代码位置
训练主函数:llm_tuning/Gpt2_Chatbot/train.py
辅助工具类:llm_tuning/Gpt2_Chatbot/functions_tools.py
模型调用
1 | print(f'input_ids-->{input_ids.shape}') # [8, 49] |
训练技巧
(1)学习率预热
1 | ''' |
(2)梯度累积
梯度累积的作用:在显卡资源有限,不能训练大的batch_size时,可以使用梯度累积的方式,来实现大的batch_size效果。
比如显卡只能支持batch_size为2,如果想训练batch_size为8,则需要将梯度累积的步数设置为4。
具体使用的方式如下:
1 | ''' |
(3)梯度裁剪
1 | # 梯度裁剪 |
trian.py代码
注意点:需要将代码里的没有必要的print、break注释掉;需要将dataloader中,shuffle设置为True!!!
1 | import os.path |
补充知识点
1 | import torch |

functions_tools.py代码
1 | def calculate_acc(logits, labels, ignore_index=-100): |
5. 模型预测(人机交互)
- 使用训练好的模型,进行人机交互,输入Ctrl+Z结束对话之后,聊天记录将保存到sample目录下的sample.txt文件中。
思路:

代码位置:llm_tuning/Gpt2_Chatbot/interact.py
1 | import os |
6. 基于Flask框架web开发(了解)
- 对interact.py进行调整, 去除while无限循环,由前端保存history,只需要对传入的句子进行预测即可。
代码位置:llm_tuning/Gpt2_Chatbot/flask_predict.py
1 | import os |
- 基于Flask框架的web后端接口
这部分可以用大模型生成,写好提示词即可。
1 | 使用大模型生成web前后端代码, 描述如下: |
代码位置:llm_tuning/Gpt2_Chatbot/app.py
1 | from flask import Flask, request, jsonify, render_template |
- web前端代码
代码位置:llm_tuning/Gpt2_Chatbot/templates/index.html
1 |
|
- 运行app.py文件, 效果如下:
P03_新零售行业评价决策系统
一、项目介绍【理解】
1、项目背景
- 随着科技的迅速发展和智能设备的普及,AI技术在新零售行业中得到了广泛应用。其中 智能推荐系统 是AI技在新零售中最为常见且有效的应用之一。通过分析用户的购买历史、浏览行为以及喜好偏好,推荐系统可以根据个人特征给用户进行个性化商品推荐。这种个性化推荐不仅可以提高用户购买意愿,减少信息过载,还可以带来更高的用户满意度和销量。
- 在智能推荐系统中,文本分类的应用属于重要的应用环节。比如:某电商网站都允许用户为商品填写评论,这些文本评论能够体现出用户的偏好以及商品特征信息,是一种语义信息丰富的隐式特征。 相比于单纯的利用显式评分特征,文本信息一方面可以弥补评分稀疏性的问题,另一方面在推荐系统的可解释方面也能够做的更好。
- 因此,本次项目我们将 以”电商平台用户评论”为背景,基于深度学习方法实现评论文本的准确分类 ,这样做的目的是通过用户对不同商品或服务的评价,平台能够快速回应用户需求,改进产品和服务。同时,自动分类也为个性化推荐奠定基础,帮助用户更轻松地找到符合其偏好的商品。
2、评论文本分类实现方法
2.1 传统的深度学习方法
- 目前实现文本分类的方法很多,如经典的应用于文本的卷积神经网络(Text-CNN)、循环神经网络(Text-RNN)、基于BERT等预训练模型的fine-tuning等,但是这些方法多为建立在具有大量的标注数据下的有监督学习。在很多实际场景中,由于领域特殊性和标注成本高,导致标注训练数据缺乏,模型无法有效地学习参数,从而易出现过拟合现象。因此,如何 通过小样本数据训练得到一个性能较好的分类模型 是目前的研究热点。
2.2 模型微调方法
- 基于前面章节的介绍,我们可以借助Prompt-Tuning的技术,来实现模型部分参数的微调(当然如果模型参数较小比如BERT,也可以全量参数微调),相比传统技术方法,Prompt-Tuning方法可以实现在较少样本的训练上,就可以达到较好的结果。
- 在本次项目中,我们将分别基于 BERT+PET(硬模版)以及BERT+P-Tuning(软模版) 两种方式实现用户评论文本的分类。重点是理解prompt的构造方法,以及promt-tuning方法的实现原理。
二、BERT+PET方式介绍【理解】
1、PET回顾
- PET(PatternExploiting Training)的核心思想是:
根据先验知识人工定义模版,将目标分类任务转换为与MLM一致的完形填空,然后再去微调MLM任务参数。

图中示例1: 情感分类任务(好评还是差评),原始文本:这家店真不错,值得推荐。PET模板: [MASK]满意。Label:不/很。标签词映射(Label Word Verbalizer):例如如果
[MASK]预测的词是“不”,则认为是差评类,如果是“很”,则认为是好评类。图中示例2:新闻分类任务(多分类),原始文本:中国女排再夺冠!PET模版:下面是[MASK] [MASK]新闻,Label:体育/财经/时政/军事
- PET 方法的核心步骤
PET方法整体过程可以概括为:首先,将下游任务通过人工模板(pattern)转化为语言模型的填空任务,并通过verbalizer把预测的词映射到任务标签,从而用少量标注样本训练多个“子模型”;接着,这些子模型在大量未标注数据上生成伪标签,形成软标注数据;最后,通过知识蒸馏,训练一个单一的学生模型来学习多个子模型的预测分布,从而兼顾鲁棒性和泛化能力。在这里,我们只需要完成分类任务,所以只需要实现第一步即可。
具体步骤如下:
1)定义任务模式 (Task Patterns):
- 首先,你需要将下游任务的输入和输出,转换为一种 包含空白([MASK] 或其他特殊标记)的自然语言句子模板 。这些模板被称为“模式”。
- 示例 (情感分类):
- 原始输入:
这部电影太棒了!标签:积极 - POFT 模式:
这部电影太棒了!这是一部____的电影。(其中____是待填充的空白)
- 原始输入:
- 示例 (问题回答 - 抽取式):
- 原始输入:
上下文:北京是中国的首都。问题:中国的首都是哪里?答案:北京 - POFT 模式:
根据上下文:北京是中国的首都。中国的首都是哪里?答案是____。
- 原始输入:
2) 定义标签映射 (Verbalizer):
- 对于任务的每个标签(或答案),你需要将其映射到 PLM(预训练语言模型) 词汇表中的一个或多个 具体词汇 。
- 示例 (情感分类):
积极→好,棒,优秀消极→差,烂,糟糕
- 示例 (问题回答): 答案本身就是模型需要生成的词语。
3) 构造训练样本:
- 将你的 所有有标签的训练数据 ,根据定义的模式和标签映射进行转换。
- 对于每个样本,输入变成模式化的句子,而模型的训练目标是在空白处生成正确的 Verbalizer 词汇(或答案词汇)。
4) 全量微调 PLM:
- 在这些 模式化 、 转换后的训练数据 上,对 整个预训练语言模型进行全量微调 。
- 微调的目标函数通常是 交叉熵损失 ,旨在最大化模型在空白处预测正确 Verbalizer 词汇的概率。这实际上是回归到 PLM 预训练时的 语言模型目标 (如掩码语言模型或文本生成)。
- 区别于 Prompt Engineering: PFT 在这里 更新模型的所有参数 ,而不仅仅是 Prompt 向量。
- 区别于传统 Fine-tuning: 传统 Fine-tuning 可能是在 PLM 上添加一个专门的分类头或抽取层进行微调。而 POFT 则是让 PLM 通过 预测词汇 来完成任务,更接近其预训练的方式。
5) 推理阶段:
- 对于新的输入,同样通过模式进行转换。
- 将转换后的输入送入微调后的 PLM。
- 模型会在空白处生成最可能的词汇。通过 Verbalizer,将这些预测的词汇反向映射回任务的原始标签或答案。
- 例如,如果模型预测
好的概率最高,就将其映射为积极。
- 例如,如果模型预测
2、 环境准备
本项目基于 torch+ transformers 实现,运行前请安装相关依赖包:
- python`3.10
- transformers`4.40.2
- torch`2.5.1+cu121
- datasets`3.6.0
- scikit-learn`1.7.0
3、项目架构
项目架构流程图:

项目整体代码介绍:

三、BERT+PET方式数据预处理【理解】
- 本项目中对数据部分的预处理步骤如下:
- 查看项目数据集
- 编写Config类项目文件配置代码
- 编写数据处理相关代码
1、查看项目数据集
数据存放位置:llm_tuning/prompt_tasks/PET/data
data文件夹里面包含4个txt文档,分别为:train.txt、dev.txt、prompt.txt、verbalizer.txt
1.1 train.txt
- train.txt为训练数据集,其部分数据展示如下:
1 | 水果 脆脆的,甜味可以,可能时间有点长了,水分不是很足。 |
train.txt一共包含63条样本数据,每一行用
\t分开,前半部分为标签(label),后半部分为原始输入 (用户评论)。如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
1.2 dev.txt
- dev.txt为验证数据集,其部分数据展示如下:
1 | 书籍 "一点都不好笑,很失望,内容也不是很实用" |
dev.txt一共包含590条样本数据,每一行用
\t分开,前半部分为标签(label),后半部分为原始输入 (用户评论)。如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
1.3 prompt.txt
- prompt.txt为人工设定提示模版,其数据展示如下:
1 | 这是一条{MASK}评论:{textA} |
其中,用大括号括起来的部分为「自定义参数」,可以自定义设置大括号内的值。
示例中 {MASK} 代表 [MASK] token 的位置,{textA} 代表评论数据的位置。
你可以改为自己想要的模板,例如想新增一个 {textB} 参数:
1.4 verbalizer.txt
verbalizer.txt 主要用于定义「真实标签」到「标签预测词」之间的映射。在有些情况下,将「真实标签」作为 [MASK] 去预测可能不具备很好的语义通顺性,因此,我们会对「真实标签」做一定的映射。
例如:
1 | "中国爆冷2-1战胜韩国"是一则[MASK][MASK]新闻。 体育 |
这句话中的标签为「体育」,但如果我们将标签设置为「足球」会更容易预测。
因此,我们可以对「体育」这个 label 构建许多个子标签,在推理时,只要预测到子标签最终推理出真实标签即可,如下:
1 | 体育 -> 足球,篮球,网球,棒球,乒乓,体育 |
- 项目中标签词映射数据展示如下:
1 | 电脑 电脑 |
verbalizer.txt 一共包含10个类别,上述数据中,我们使用了1对1的verbalizer, 如果想定义一对多的映射,只需要在后面用”,”分割即可, eg:
若想使用自定义数据训练,只需要仿照示例数据构建数据集
2、编写Config类项目文件配置代码
代码路径:llm_tuning/prompt_tasks/PET/pet_config.py
config文件目的:配置项目常用变量,一般这些变量属于不经常改变的,比如:训练文件路径、模型训练次数、模型超参数等等
具体代码实现:
1 | import torch |
3、编写数据处理相关代码
代码路径:llm_tuning/prompt_tasks/PET/data_handle/
data_handle文件夹中一共包含三个py脚本:template.py、data_preprocess.py、data_loader.py
3.1 template.py
- 目的:构建固定模版类,text2id的转换
- 思路:
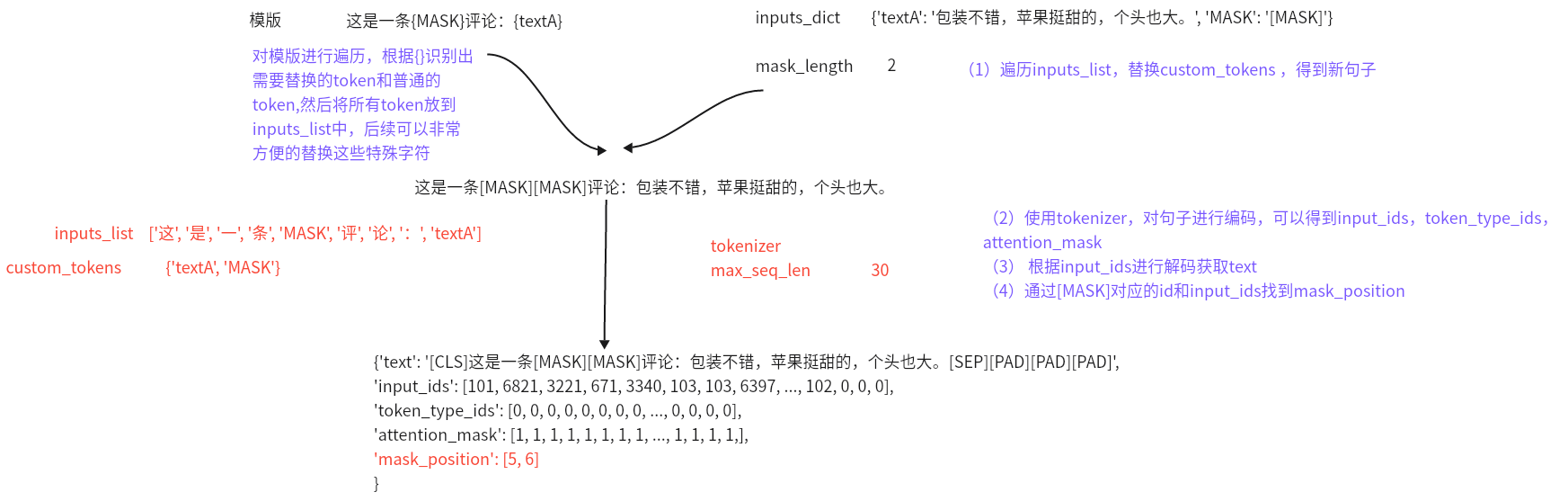
- 定义HardTemplate类代码如下:
1 | from transformers import AutoTokenizer |
3.2 data_preprocess.py
- 目的: 将样本数据转换为模型接受的输入数据。具体来说,就是将每行数据进行处理,获取数据的标签和评论信息,然后进行处理获取输入和标签。
- 定义数据转换方法convert_example(),代码如下:
1 | import numpy as np |
3.3 data_loader.py
- 目的:定义数据加载器
- 定义获取数据加载器的方法get_data(),代码如下:
1 | from functools import partial |
四、PET方式模型搭建与训练【实现】
- 本项目中完成BERT+PET模型搭建、训练及应用的步骤如下(注意:因为本项目中使用的是BERT预训练模型,所以直接加载即可,无需重复搭建模型架构):
- 1.实现模型工具类函数
- 2.实现模型训练函数,验证函数
- 3.实现模型预测函数
1、实现模型工具类函数
- 目的:模型在训练、验证、预测时需要的函数
- 代码路径:llm_tuning/prompt_tasks/PET/utils
- utils文件夹共包含3个py脚本:verbalizer.py、metirc_utils.py以及common_utils.py
1.1 verbalizer.py
- 目的:定义一个Verbalizer类,用于将一个主标签映射到子标签或者将子标签映射到主标签。
- 思路:

- 具体实现代码:
1 | # Union 是 typing 模块中定义的一个类,用于表示多个类型中的任意一种类型 |
1.2 common_utils.py
- 目的:定义损失函数、将mask_position位置的token logits转换为token的id。
损失计算思路:
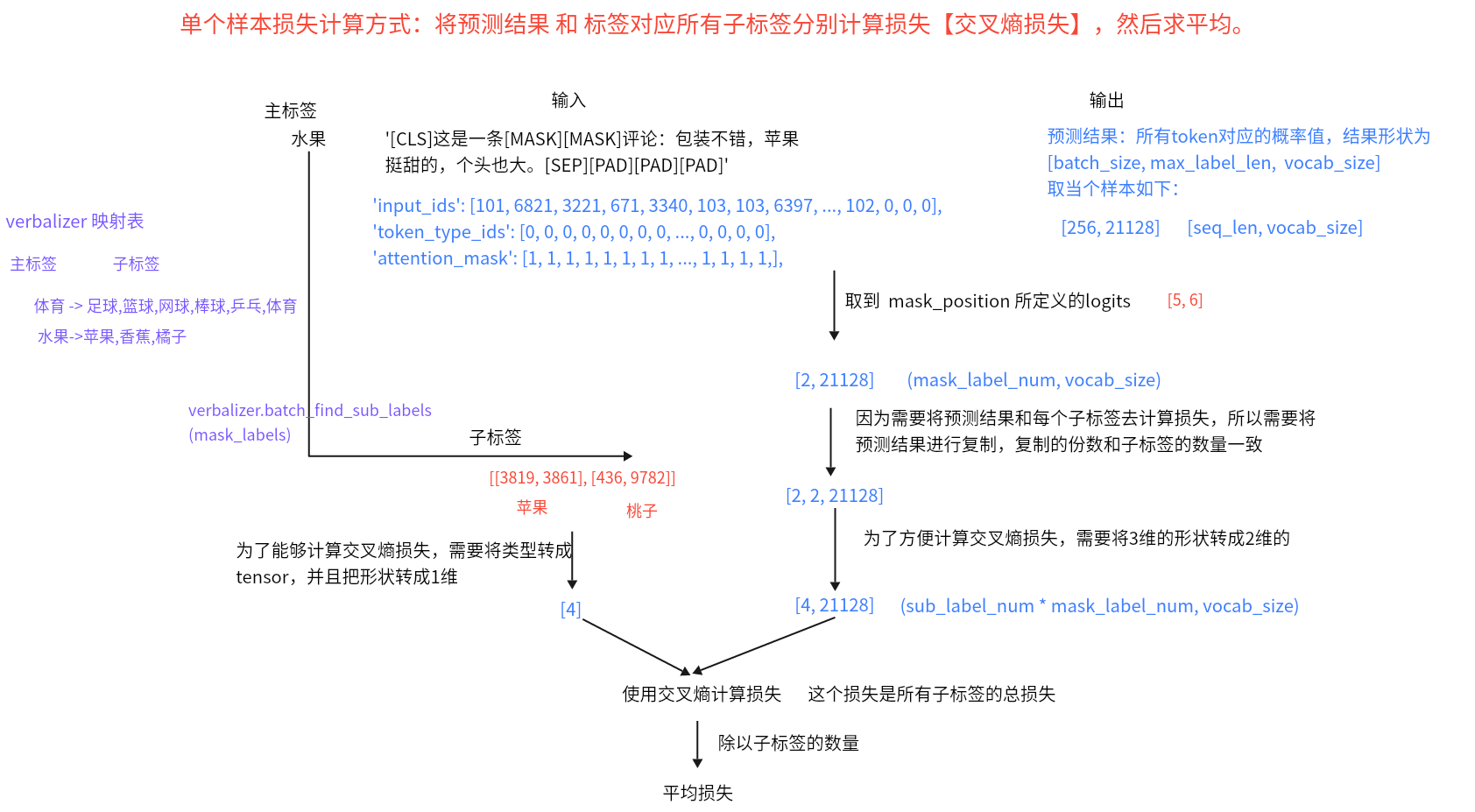
将logits获取id的思路:
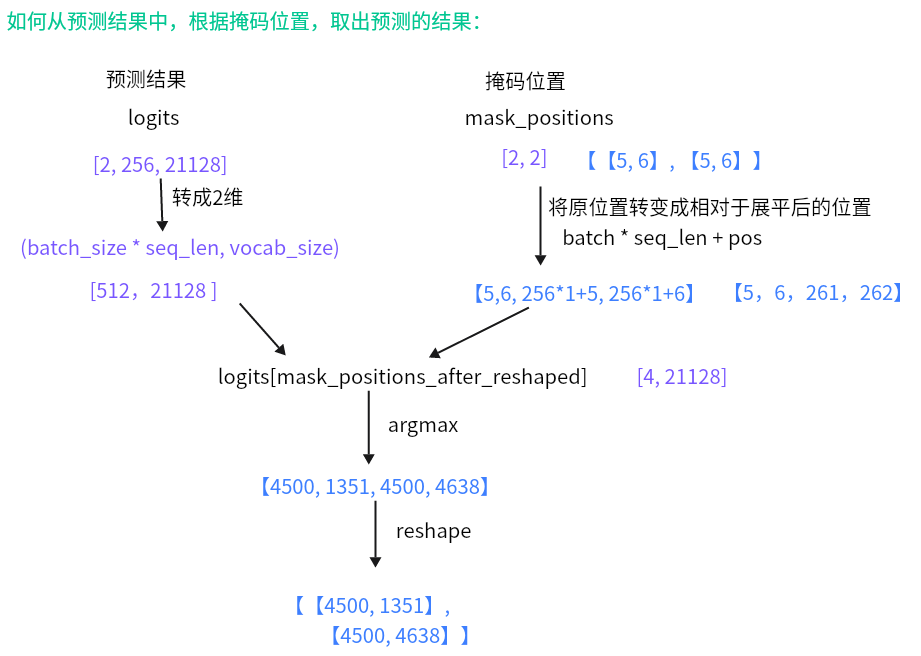
- 脚本里面包含两个函数:mlm_loss()以及convert_logits_to_ids()
- 代码如下:
1 | import torch |
1.3 metirc_utils.py
- 目的:定义(多)分类问题下的指标评估(acc, precision, recall, f1)。
- 定义ClassEvaluator类,代码如下:
1 | from typing import List |
2、实现模型训练函数,验证函数
目的:实现模型的训练和验证
脚本里面包含两个函数:model2train()和evaluate_model()
代码路径:llm_tuning/prompt_tasks/PET/train.py
代码如下:
1 | import os |
- 输出结果:
1 | ..... |
- 结论: BERT+PET模型在训练集上的表现是精确率=78%
- 注意:本项目中只用了60条样本,在接近600条样本上精确率就已经达到了78%,如果想让指标更高,可以扩增样本。
3、实现模型预测函数
目的:加载训练好的模型并测试效果
代码路径:llm_tuning/prompt_tasks/PET/inference.py
代码如下:
1 | import os |
- 结果展示
1 | { |
五、BERT+P-Tuning方式介绍【理解】
1、P-Tuning回顾
- P-Tuning(Pattern-Tuning)是一种连续空间可学习模板,PET的目的解决PET的缺点,使用可学习的向量作为伪模板,不再手动构建模板。

以新闻分类任务为例:原始文本:中国女排再夺冠!P-Tuning可学习模板:[u1] [u2] …[MASK]…[un], Label:体育/财经/时政/军事
- P-tuning 的核心思想是:用一个小的可训练模块把一组“连续提示向量”生成并插入到原始输入 embedding 中,令冻结的预训练模型在下游任务上产生正确输出,训练时仅更新 prompt encoder(或提示向量),从而实现低成本高效的调优。
2、环境准备
本项目基于 pytorch + transformers 实现,运行前请安装相关依赖包:
- python`3.10
- transformers`4.40.2
- torch`2.5.1+cu121
- datasets`3.6.0
- scikit-learn`1.7.0
3、项目架构
- 项目架构流程图:

- 项目整体代码介绍:
六、BERT+P-Tuning方式数据预处理【理解】
本项目中对数据部分的预处理步骤如下:
- 1.查看项目数据集
- 2.编写Config类项目文件配置代码
- 3.编写数据处理相关代码
1、查看项目数据集
数据存放位置:llm_tuning/prompt_tasks/P-Tuning/data
data文件夹里面包含3个txt文档,分别为:train.txt、dev.txt、verbalizer.txt
1.1 train.txt
- train.txt为训练数据集,其部分数据展示如下:
1 | 水果 脆脆的,甜味可以,可能时间有点长了,水分不是很足。 |
train.txt一共包含63条样本数据,每一行用
\t分开,前半部分为标签(label),后半部分为原始输入 (用户评论)。如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
1.2 dev.txt
- dev.txt为验证数据集,其部分数据展示如下:
1 | 书籍 "一点都不好笑,很失望,内容也不是很实用" |
dev.txt一共包含417条样本数据,每一行用
\t分开,前半部分为标签(label),后半部分为原始输入 (用户评论)。如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
1.3 verbalizer.txt
verbalizer.txt 主要用于定义「真实标签」到「标签预测词」之间的映射。在有些情况下,将「真实标签」作为 [MASK] 去预测可能不具备很好的语义通顺性,因此,我们会对「真实标签」做一定的映射。
例如:
1 | "中国爆冷2-1战胜韩国"是一则[MASK][MASK]新闻。 体育 |
这句话中的标签为「体育」,但如果我们将标签设置为「足球」会更容易预测。
因此,我们可以对「体育」这个 label 构建许多个子标签,在推理时,只要预测到子标签最终推理出真实标签即可,如下:
1 | 体育 -> 足球,篮球,网球,棒球,乒乓,体育 |
- 项目中标签词映射数据展示如下:
1 | 电脑 电脑 |
verbalizer.txt 一共包含10个类别,上述数据中,我们使用了1对1的verbalizer, 如果想定义一对多的映射,只需要在后面用”,”分割即可, eg:
若想使用自定义数据训练,只需要仿照示例数据构建数据集
2、编写Config类项目文件配置代码
代码路径:llm_tuning/prompt_tasks/P-Tuning/ptune_config.py
config文件目的:配置项目常用变量,一般这些变量属于不经常改变的,比如:训练文件路径、模型训练次数、模型超参数等等
具体代码实现:
1 | import torch |
3、编写数据处理相关代码
代码路径:llm_tuning/prompt_tasks/P-Tuning/data_handle/
data_handle文件夹中一共包含两个py脚本:data_preprocess.py、data_loader.py
3.1 data_preprocess.py
- 目的: 将模板与原始输入文本进行拼接,构造模型接受的输入数据
- 代码如下:
1 | import torch |
打印结果展示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
[ 1, 2, 3, ..., 3300, 5741, 102],
[ 1, 2, 3, ..., 6574, 7030, 0],
...,
[ 1, 2, 3, ..., 8024, 2571, 0],
[ 1, 2, 3, ..., 3221, 3175, 102],
[ 1, 2, 3, ..., 5277, 3688, 102]]),
'attention_mask': array([[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 0],
...,
[1, 1, 1, ..., 1, 1, 0],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1]]),
'mask_positions': array([[7, 8],
[7, 8],
[7, 8],
...,
[7, 8],
[7, 8],
[7, 8]]),
'mask_labels': array([[4510, 5554],
[3717, 3362],
[2398, 3352],
...,
[3819, 3861],
[6983, 2421],
[3819, 3861]]),
'token_type_ids': array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])}
3.2 data_loader.py
目的:定义数据加载器
代码如下:
1 | from functools import partial |
打印结果展示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
[1, 2, 3, ..., 0, 0, 0],
[1, 2, 3, ..., 0, 0, 0],
...,
[1, 2, 3, ..., 0, 0, 0],
[1, 2, 3, ..., 0, 0, 0],
[1, 2, 3, ..., 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]]),
'mask_positions': tensor([[7, 8],
[7, 8],
[7, 8],
[7, 8],
[7, 8],
[7, 8],
[7, 8],
[7, 8]]),
'mask_labels': tensor([[6132, 3302],
[3717, 3362],
[6132, 3302],
[6983, 2421],
[6983, 2421],
[6132, 3302],
[3717, 3362],
[2398, 3352]]),
'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])}
torch.int64
七、BERT+P-Tuning方式模型搭建与训练【实现】
本项目中完成BERT+P-Tuning模型搭建、训练及应用的步骤如下(注意:因为本项目中使用的是BERT预训练模型,所以直接加载即可,无需重复搭建模型架构):
- 1.实现模型工具类函数
- 2.实现模型训练函数,验证函数
- 3.实现模型预测函数
1、实现模型工具类函数
- 目的:模型在训练、验证、预测时需要的函数
- 代码路径:llm_tuning/prompt_tasks/P_Tuning/utils
- utils文件夹共包含3个py脚本:verbalizer.py、metirc_utils.py以及common_utils.py
1.1 verbalizer.py
- 目的:定义一个Verbalizer类,用于将一个Label对应到其子Label的映射。
- 具体代码如下:
1 | # Union 是 typing 模块中定义的一个类,用于表示多个类型中的任意一种类型 |
print结果显示:
2
3
4
5
6
7
8
ret-->{'sub_labels': ['电脑'], 'token_ids': [[4510, 5554]]}
********************************************************************************
result-->[{'sub_labels': ['电脑'], 'token_ids': [[4510, 5554]]}, {'sub_labels': ['衣服'], 'token_ids': [[6132, 3302]]}]
********************************************************************************
ret-->{'label': '电器', 'token_ids': [4510, 1690]}
********************************************************************************
ret-->[{'label': '衣服', 'token_ids': [6132, 3302]}, {'label': '蒙牛', 'token_ids': [5885, 4281]}]
1.2 common_utils.py
- 目的:定义损失函数、将mask_position位置的token logits转换为token的id。
- 脚本里面包含两个函数:mlm_loss()以及convert_logits_to_ids()
- 代码如下:
1 | import torch |
1.3 metirc_utils.py
- 目的:定义(多)分类问题下的指标评估(acc, precision, recall, f1)。
- 代码如下:
1 | from typing import List |
print代码结果:
2
3
4
5
6
7
8
9
'precision': 0.7,
'recall': 0.6,
'f1': 0.6,
'class_metrics':
{'体育': {'precision': np.float64(0.5), 'recall': np.float64(0.5), 'f1': np.float64(0.5)},
'计算机': {'precision': np.float64(1.0), 'recall': np.float64(0.5), 'f1': np.float64(0.67)},
'财经': {'precision': np.float64(0.5), 'recall': np.float64(1.0), 'f1': np.float64(0.67)}
}}
2、实现模型训练函数,验证函数
目的:实现模型的训练和验证,脚本里面包含两个函数:model2train()和evaluate_model()
代码路径:llm_tuning/prompt_tasks/P_Tuning/train.py
代码如下:
1 | import os |
- 输出结果:
1 | ... |
- 结论: BERT+P-Tuning模型在训练集上的表现是Precion: 76%
- 注意:本项目中只用了60条样本,在接近400条样本上精确率就已经达到了76%,如果想让指标更高,可以扩增样本。
提升模型性能:
增加训练数据集(100条左右的数据):
1 | 手机 外观时尚新潮,适合年轻人展现个性。 |
修改验证集脏数据
1 | # 原始标签和评论文本内容不符 |
模型表现:
Evaluation precision: 0.79000, recall: 0.70000, F1: 0.71000
3、实现模型预测函数
- 目的:加载训练好的模型并测试效果
- 代码路径:llm_tuning/prompt_tasks/P_Tuning/inference.py
代码如下:
1 | import os |
- 结果展示
1 | { |
P04_基于ChatGLM微调多任务实战
1. 项目介绍【理解】
1.1. 项目简介
LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能。但,想要直接利用 LLM 完成一些任务会存在一些答案解析上的困难,如规范化输出格式,严格服从输入信息等。因此,在这个项目中我们对大模型 ChatGLM-6B 进行 Finetune,使其能够更好的对齐我们所需要的输出格式。
1.2. ChatGLM-6B模型
1.2.1 模型介绍
ChatGLM-6B 是清华大学提出的一个开源、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。该模型使用了和 ChatGPT 相似的技术,经过约 1T 标识符的中英双语训练(中英文比例为 1:1),辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答(目前中文支持最好)。
相比原始Decoder模块,ChatGLM-6B模型结构有如下改动点:
- embedding 层梯度缩减:为了提升训练稳定性,减小了 embedding 层的梯度。梯度缩减的效果相当于把 embedding 层的梯度缩小了 10 倍,减小了梯度的范数。
- layer normalization:采用了基于 Deep Norm 的 post layer norm。
- 激活函数:替换ReLU激活函数采用了 GeGLU 激活函数。
- 位置编码:去除了绝对位置编码,采用了旋转位置编码 RoPE。
1.2.2 模型配置(6B)
| 配置 | 数据 |
|---|---|
| 参数 | 6.2B |
| 隐藏层维度 | 4096 |
| 层数 | 28 |
| 注意力头数 | 32 |
| 训练数据 | 1T |
| 词表大小 | 130528 |
| 最大长度 | 2048 |
1.2.3 硬件要求(官网介绍)
| 量化等级 | 最低GPU显存(推理) | 最低GPU显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13GB | 14GB |
| INT8 | 10GB | 9GB |
| INT4 | 6GB | 7GB |
注意:显存的占用除了跟模型参数大小有关系外,还和文本支持最大长度有关
1.2.4 模型特点
- 优点
- 1.较低的部署门槛: INT4 精度下,只需6GB显存,使得 ChatGLM-6B 可以部署在消费级显卡上进行推理。
- 2.更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM2-6B 序列长度达32K,支持更长对话和应用。
- 人类类意图对齐训练
- 缺点:
- 模型容量小,相对较弱的模型记忆和语言能力。
- 较弱的多轮对话能力。
1.3. 环境配置
1.3.1 基础环境配置:
本次环境依赖于AutoDL算力:https://www.autodl.com/home
- 操作系统: ubuntu22.04
- CPUs: 14 core(s),内存:100G
- GPUs: 1卡, A800, 80GB GPUs
- Python: 3.10
- Pytorh: 2.5.1
- Cuda: 12.4
- 价格:5.98元/小时
1.3.2 安装依赖包:
- 创建一个虚拟环境,您可以把
llm_env修改为任意你想要新建的环境名称:
1 | conda create -n llm_env python=3.10 |
- 激活新建虚拟环境
1 | conda activate llm_env |
注意: 如果激活失败,则先运行 conda init,然后退出终端,重新打开一个终端。
- 安装相应的依赖包:
1 | -- 成功切换到llm_env后安装 |
2
3
4
5
6
7
8
9
10
11
12
transformers`4.33
icetk
cpm_kernels
streamlit`1.18.0
matplotlib
datasets
accelerate>=0.20.3
packaging>=20.0
psutil
pyyaml
peft`0.3.0requirements.txt文件内容如上所示
1.3.3 预训练模型下载:
- 创建目录
1 | mkdir -p /root/autodl-tmp/llm_tuning/THUDM/chatglm-6b |
- 安装modelscope
1 | pip install modelscope |
- 下载chatglm-6b
1 | modelscope download --model ZhipuAI/ChatGLM-6B --local_dir ./ |
- python文件下载
如果configuration_chatglm.py、modeling_chatglm.py、quantization.py、tokenization_chatglm.py文件没有下载成功,则手动下载,然后添加到chatglm-6b的文件夹中。
下载位置:https://modelscope.cn/models/ZhipuAI/ChatGLM-6B/files
1.4. 项目架构
项目架构流程图:

项目代码架构图:

2.数据预处理【掌握】
- 本项目中对数据部分的预处理步骤如下:
- 查看项目数据集
- 编写Config类项目文件配置代码
- 编写数据处理相关代码
2.1 查看项目数据集
数据存放位置:llm_tuning/ptune_chatglm/data
data文件夹里面包含3个jsonl文档,分别为:mixed_train_dataset.jsonl、mixed_dev_dataset.jsonl、dataset.jsonl
2.1.1 train.jsonl
mixed_train_dataset.jsonl为训练数据集,因为我们本次项目同时进行「信息抽取+文本分类」两项任务,因此数据中混合了两种任务数据类型。举例展示如下:
- 信息抽取数据示例
- Instruction 部分告诉模型现在需要做「阅读理解」任务,Input 部分告知模型要抽取的句子以及输出的格式。
1
2
3
4{
"context": "Instruction: 你现在是一个很厉害的阅读理解器,严格按照人类指令进行回答。\nInput: 找到句子中的三元组信息并输出成json给我:\n\n九玄珠是在纵横中文网连载的一部小说,作者是龙马。\nAnswer: ",
"target": "```json\n[{\"predicate\": \"连载网站\", \"object_type\": \"网站\", \"subject_type\": \"网络小说\", \"object\": \"纵横中文网\", \"subject\": \"九玄珠\"}, {\"predicate\": \"作者\", \"object_type\": \"人物\", \"subject_type\": \"图书作品\", \"object\": \"龙马\", \"subject\": \"九玄珠\"}]\n```"
}- 文本数据示例
- Instruction 部分告诉模型现在需要做「阅读理解」任务,Input 部分告知模型要抽取的句子以及输出的格式。
1
2
3
4{
"context": "Instruction: 你现在是一个很厉害的阅读理解器,严格按照人类指令进行回答。\nInput: 下面句子可能是一条关于什么的评论,用列表形式回答:\n\n很不错,很新鲜,快递小哥服务很好,水果也挺甜挺脆的\nAnswer: ",
"target": "[\"水果\"]"
}
训练集中一共包含902条数据,每一条数据都分为
context和target两部分:
context部分是接受用户的输入。2.target部分用于指定模型的输出。在
context中又包括 2 个部分:
- Instruction:用于告知模型的具体指令,当需要一个模型同时解决多个任务时可以设定不同的 Instruction 来帮助模型判别当前应当做什么任务。
- Input:当前用户的输入。
2.1.2 dev.jsonl
- mixed_dev_dataset.jsonl为验证数据集,数据格式同train.jsonl。
如果想使用自定义数据训练,只需要仿照上述示例数据构建数据集即可。
2.2 编写项目Config类配置文件
代码路径:llm_tuning/ptune_chatglm/glm_config.py
config文件目的:配置项目常用变量,一般这些变量属于不经常改变的,比如:训练文件路径、模型训练次数、模型超参数等等
具体代码实现:
1 | import os.path |
2.3 编写数据处理相关代码
- 代码路径:llm_tuning/ptune_chatglm/data_handle
- data_handle文件夹中一共包含两个py脚本:data_preprocess.py、data_loader.py
2.3.1 data_preprocess.py
- 模型输入和标签的构建思路:
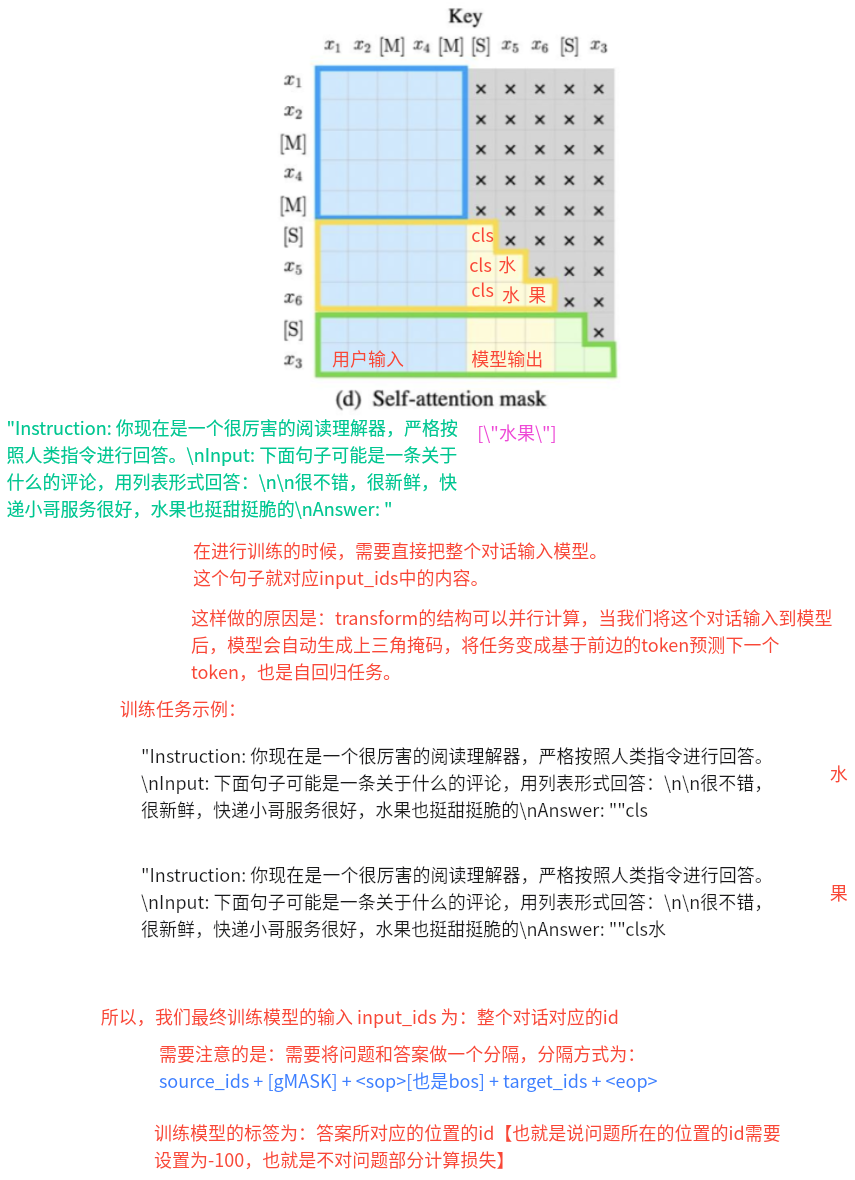
- 目的: 将样本数据转换为模型接受的输入数据
- 定义数据转换方法convert_example()
- 定义获取训练或验证数据最大长度方法get_max_length()
代码如下:
1 | import sys |
2.3.2 data_loader.py
目的:定义数据加载器
代码如下:
1 | from datasets import load_dataset |
- 打印结果:
1 | 902 |
2.3.3 代码上传
将写好的代码 ptune_chatglm 文件夹直接打包成zip文件。然后上传到autodl平台的 llm_tuning 文件夹下。
然后解压缩。
1 | cd /root/autodl-tmp/llm_tuning/ |
然后使用python xx.py的方式运行文件即可。
3.模型搭建与训练【掌握】
本项目中完成ChatGLM+LoRA模型搭建、训练及应用的步骤如下(注意:因为本项目中使用的是ChatGLM预训练模型,所以直接加载即可,无需重复搭建模型架构):
- 1.实现模型工具类函数
- 2.实现模型训练函数,验证函数
- 3.实现模型预测函数
3.0 前置知识
lora模型配置:
1 | # 如果使用lora方法微调 |
lora调用:
1 | loss = model( |
lora模型保存:
1 | def save_model(model, cur_save_dir: str): |
ptuning的用法:
1 | # 加载预训练模型的配置 |
3.1. 实现模型工具类函数
- 目的:模型在训练、验证、预测时需要的函数
- 代码路径:llm_tuning/ptune_chatglm/utils
- utils文件夹共包含1个py脚本:common_utils.py
3.1.1 common_utils.py
目的:定义数据类型转换类、分秒时之间转换以及模型保存函数。
脚本里面包含一个类以及两个函数:CastOutputToFloat、second2time()以及save_model()
- 定义CastOutputToFloat类
- 定义second2time()函数
- 定义save_model()
代码路径:llm_tuning/ptune_chatglm/utils/common_utils.py
代码如下:
1 | import torch |
3.2. 实现模型训练函数,验证函数
- 目的:实现模型的训练和验证
优化点:
优化点1:
model.config.use_cache = False
含义:关闭模型使用 past key/values(也叫 KV cache、attention cache)来重用之前层的注意力键值对。
效果:在训练时通常将其设为 False(尤其在启用 gradient checkpointing 时),因为缓存与 checkpointing 在某些实现上不兼容,会导致错误或额外内存/计算问题。把它设为 False 可以避免相关冲突。并且现在不再进行缓存,可以降低显存的占用。
在训练结束、用于部署/推理时应把 use_cache 恢复为 True 以利用 KV 缓存加速。
优化点2:
model.gradient_checkpointing_enable()
含义:开启梯度检查点。这是一个以牺牲计算时间换取显存的优化:前向时只保存一部分激活(checkpoints),在反向传播时对未保存的部分重新做一次(或多次)前向计算以得到梯度。
效果:显存减低,训练速度变慢。
优化点3:
model.enable_input_require_grads()
含义:允许把梯度“传到”输入层或做对输入嵌入的直接优化(例如 prompt tuning、微调 embedding、或某些 adapter/PEFT 的实现里需要)。
优化点4:
直接降低预训练模型的精度:
1 | # model.half()将模型数据类型从默认的float32精度转换为更低的float16精度,减少内存 |
混合精度训练:
1 | # autocast是PyTorch中一种混合精度的技术,可在保持数值精度的情况下提高训练速度和减少显存占用。 |
代码:
代码路径:llm_tuning/ptune_chatglm/train.py
脚本里面包含两个函数:model2train()和evaluate_model()
代码如下:
1 | import sys |
- 输出结果:

3.3. 实现模型预测函数
- 目的:加载训练好的模型并测试效果
优化点:
- 优化点:
model.generate()与model()的区别
1 | out = model.generate( |
1 | model() |
是一次前向(forward)调用,返回
logits(和past_key_values、隐藏态等),不会自动做循环解码。适合:你想自定义解码策略(自写采样、温度、惩罚、约束),或做单步推理 / 获取中间 logits / 做梯度计算(训练)时。
需要你自己管理:循环、
past_key_values(KV cache)、终止条件、token 拼接等。
1 | model.generate() |
是 Hugging Face Transformers 提供的高层生成接口:它会自动运行解码循环(greedy / beam / top-k / top-p / sampling 等),管理
past_key_values、attention_mask、eos停止、重复惩罚、长度限制等。适合:你要快速得到文本输出,且常见的生成选项(temperature、max_new_tokens、do_sample、num_beams…)已经够用。
其中在
generate(..., temperature=0)下,transformers 会把采样方式切为贪心(greedy),即每步取概率最大的 token(等同于argmax)。如果你用model()自己实现,也需要在 logits 上做argmax来实现相同行为;若temperature>0,你需要做 softmax + multinomial 来采样。更简洁、安全、通常更快(内部有优化),并且处理好很多边界情况。
代码:
- 代码路径:llm_tuning/prompt_tasks/ptune_chatglm/inference.py
具体代码:
1 | import sys |
P05_文本摘要模型
1 项目说明
1.1 项目内容
文本摘要项目
1.2 项目技术
模型选型:Qwen
模型微调:DeepSpeed + LoRA
模型量化:QLora + GPTQ
模型部署:vLLM推理引擎
2 DeepSpeed使用
2.1 并行化策略
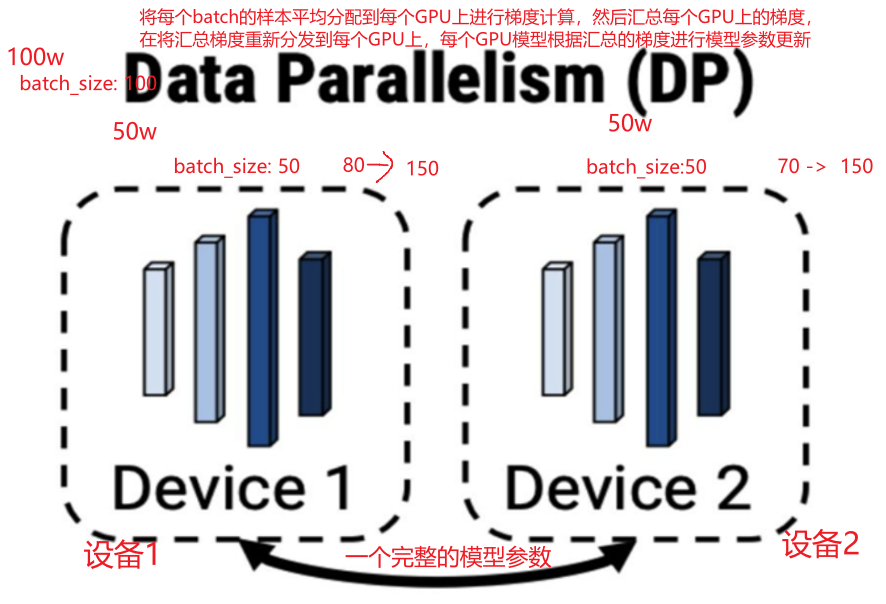
(1)数据并行
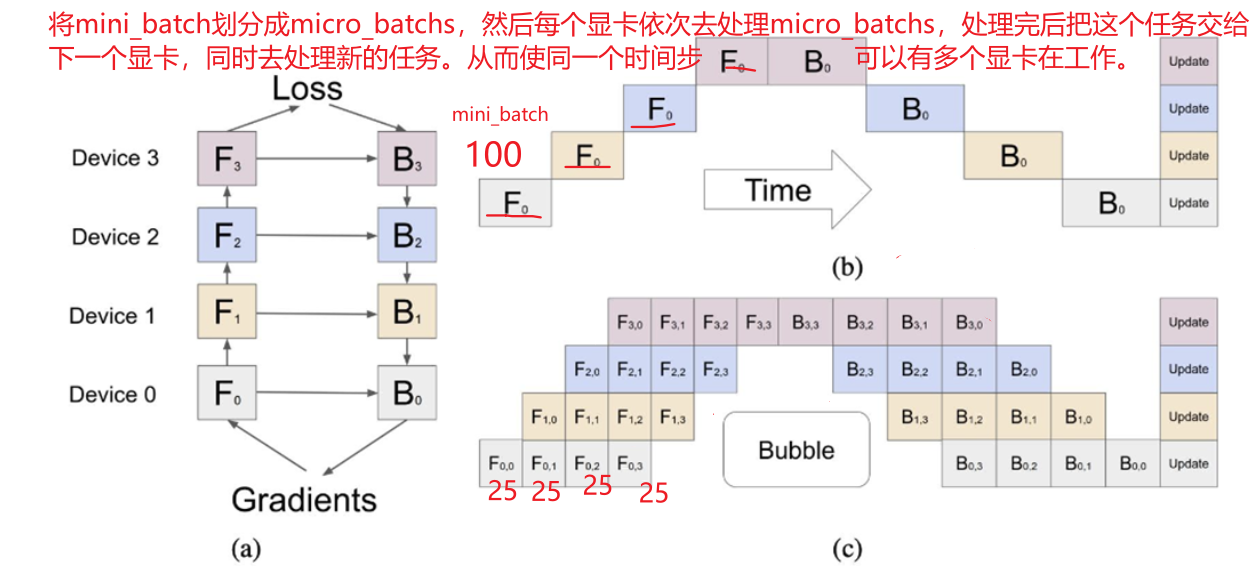
(2)模型并行-流水线并行
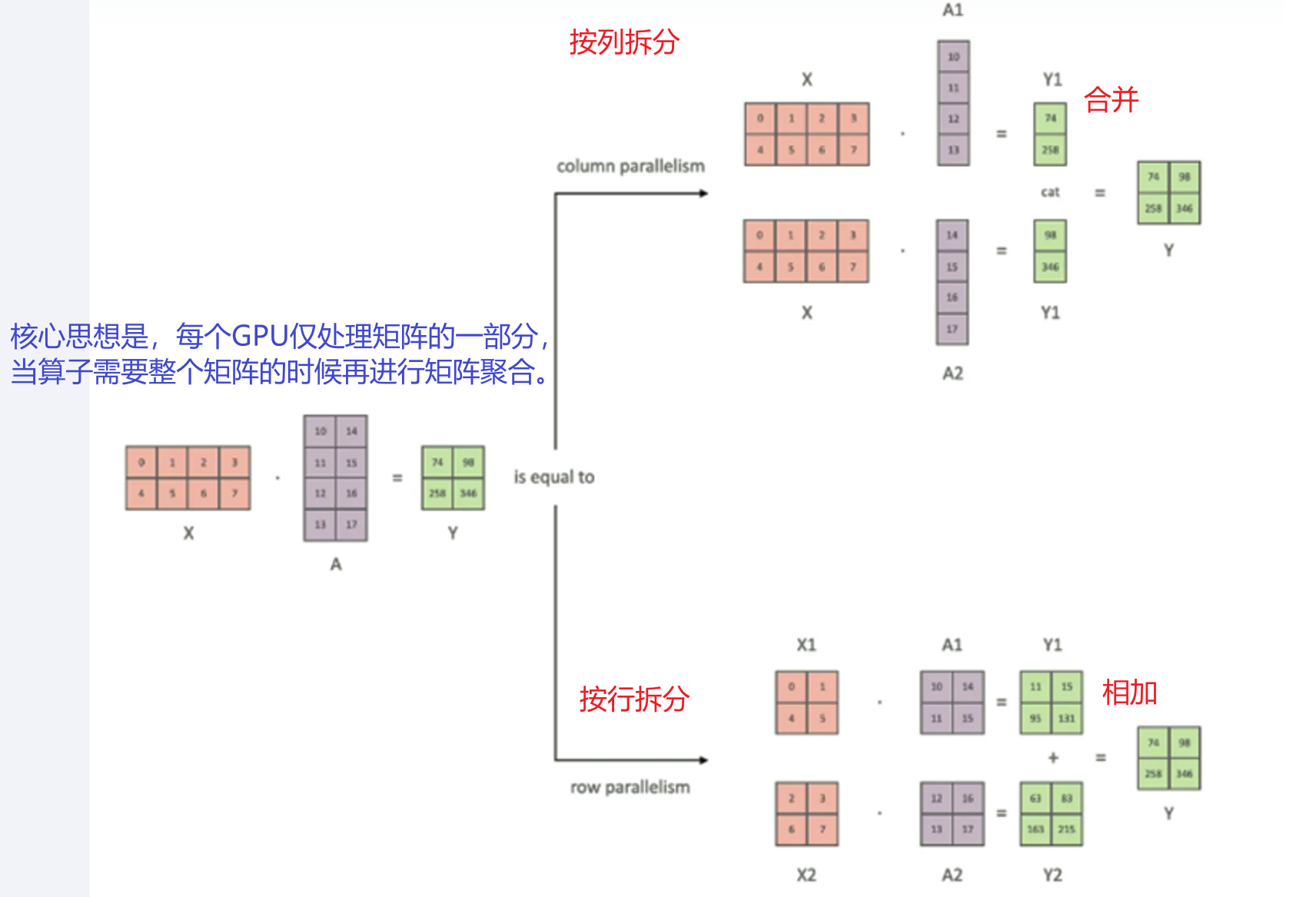
(3)模型并行-张量并行
2.2 内存优化技术
ZeRO原理:将参数、梯度和优化器状态拆分存储到每个显卡上,不再进行冗余存储,从而降低每个显卡上的显存占用大小。然后在使用时,使用到相应的数据时再去对应显卡上拉取数据。
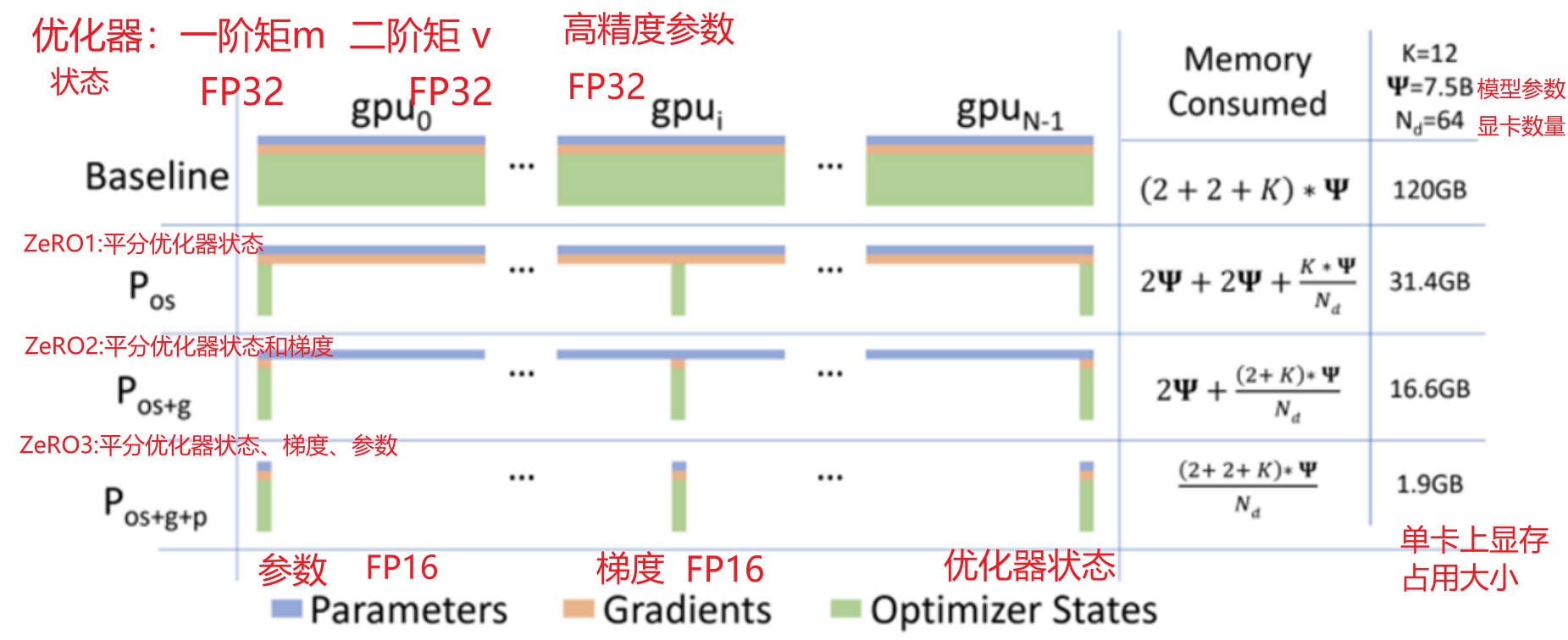
注意:ZeRO级别越高,显存占用就越少,此时在计算时数据传输成本就越高。所以,官方推荐的级别是ZeRO2,用于平衡显存占用以及数据传输成本。
Offload原理:核心是将优化器状态和梯度卸到CPU内存中,从而能够同时利用 CPU 和 GPU 内存来训练大型模型。
2.3 混合精度训练
定义:混合精度训练是一种同时使用不同精度的浮点数进行训练的方法,通常结合单精度(FP32)和半精度(FP16)浮点数。
效果:使用混合精度可以显著减少内存占用和计算时间,同时还能降低能耗。
2.4 deepspeed实践
核心流程如下:
1)配置DeepSpeed: 创建一个DeepSpeed的配置文件(通常为JSON格式),在其中指定模型的大小、优化器类型、学习率调度器等参数。
ds.json
1 | { |
2)包装模型: 使用DeepSpeed提供的deepspeed.initialize()函数来包装原有的模型。这个函数将应用DeepSpeed的优化策略和技术。
1 | # deepspeed初始化(自动处理分布式设置) |
3)训练模型: 替换原有的训练循环,通过调用model.backward()和optimizer.step()来执行反向传播和参数更新。DeepSpeed会自动处理梯度累积、梯度压缩等技术,以提高训练效率。
1 | # 训练循环 |
4)提交任务并训练
1 | deepspeed train.py --epoch 2 --deepspeed --deepspeed_config ds.json |
5)评估结果,调整超参数和配置
3 LLaMA-Factory使用
1、LLaMA-Factory简介
LLaMA-Factory是一个简单易用且高效的大模型训练框架,支持上百种大模型的训练,也支持模型的推理。
2、使用方式
需要配置yaml 配置文件,如果需要使用deepspeed,也可以进行配置。
在使用lora进行微调时,配置微调方法的方式如下:
1 | ### 训练方法 |
训练启动的命令:
1 | llamafactory-cli : 主程序入口 |
如果使用的是Qlora量化,只需要在训练方法中,添加量化方式即可。
1 | # 量化位数(4-bit量化) |
4 GPTQ模型量化
1、量化的使用场景

2、主要思想
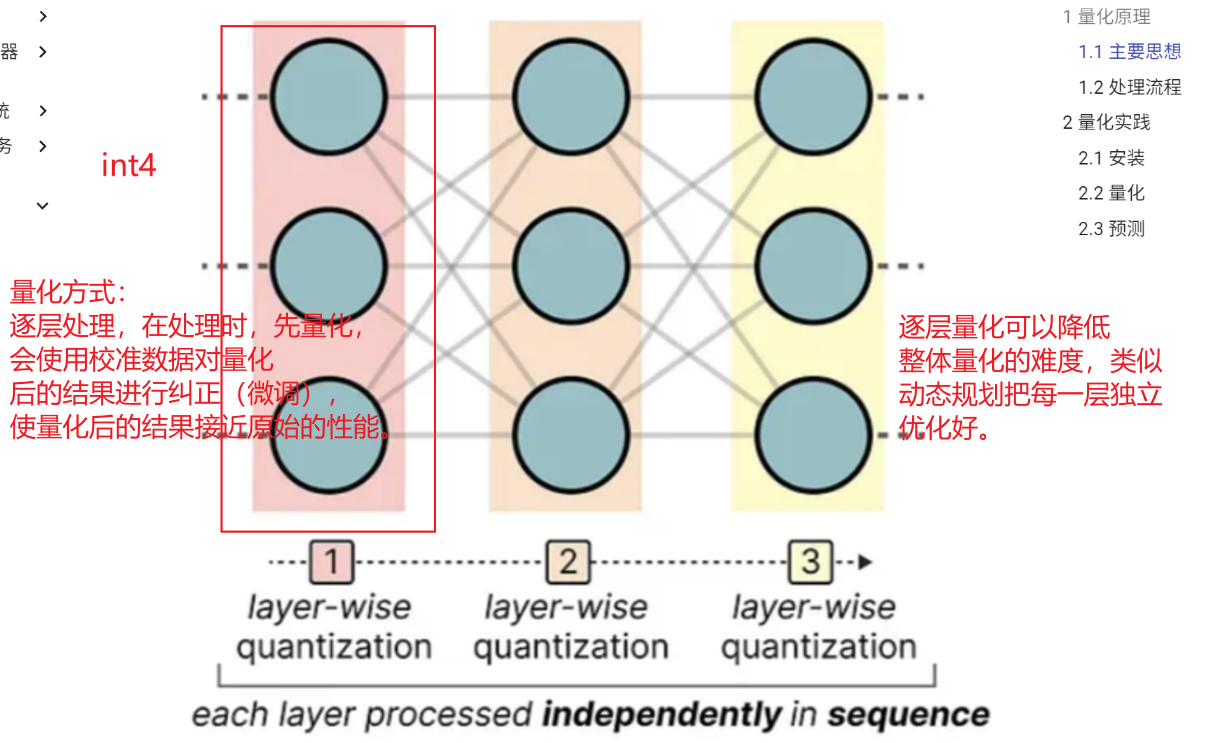
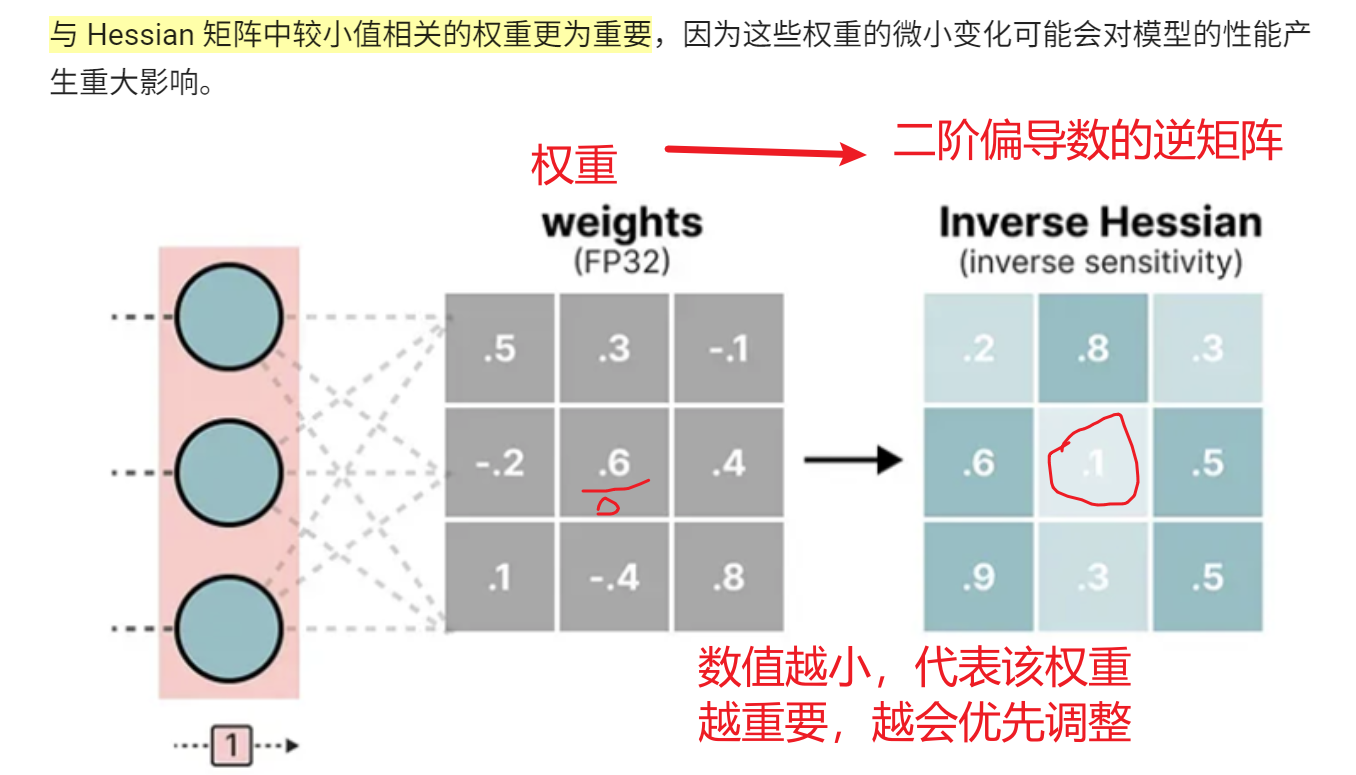
3、算法的基本步骤如下:
- 收集校准数据:从训练数据或相关数据集中抽取一小部分样本,作为校准数据;
- 逐层处理:对模型的每一层进行独立量化,避免全局优化的复杂度;
- 最小化输出误差:对于每一层,寻找最佳的量化权重,使得在校准数据上的输出误差最小;
- 更新权重:将量化后的权重替换原始权重
4、使用过程
- 对数据进行预处理
- 配置量化的参数
- 加载模型
- 将量化的配置放到模型加载过程中
- 调用模型的quantize进行量化
- 将量化结果进行保存
5 vLLM使用
1、vllm的核心原理
使用PageAttention去优化缓存
在显存上分配一块固定大小的连续空间(vllm中默认为16),类似于内存页;然后多个进程运行时,可以每个进程分配自己的虚拟内存,虚拟内存通过块表(block table)关联到内存页。因为写到内存页是动态选择的过程,和传统的预先开辟显存空间不同,可以极大降低浪费;内存页的长度比较小,也可以降低内存碎片的产生。
批量任务优化:vllm不再要求所有并行任务处于同一阶段,当其他推理任务进行时,只要资源充足,可以随时开始新推理任务,减少了任务批次间的等待。
vllm能够同时加载多个LoRA,随时可以指定使用其中的任意一个
2、使用
启动
1 | CUDA_VISIBLE_DEVICES=0 API_PORT=8000 vllm serve /workspace/deepseekDistllation/models/Qwen/Qwen2.5-3B-Instruct-GPTQ-Int4 \ |
启动会暴露出一个api,然后调用这个api完成预测即可。
 微信
微信 支付宝
支付宝