Jason Working Note
(从文件切分 → 数据集标注/微调数据集构建 → 模型选型 → 模型微调 →Agent Workflow架构 → Agent自动生成报告)
1 MarkDown语义分段 切分 数据清洗 不一定要用Dify 可以使用LangChain框架来处理
2 检索召回 Prompt 技术细节
3 微调模型应用场景:写报告 评估报告的分数(先搞语料 搞完后再去决定用大or小模型)
4 爬虫最好用Firecrawl去抓取 否则法律 服务器IP被封
数据/语料标注
根据具体任务选择合适的数据格式:
1 | 简单任务:使用基础的instruction-input-target格式 |
数据集如何构建的?
首先是文本提取,通过对多源异构数据进行文本解析,然后对提取到的文本内容进行清洗与预处理(提取错了直接扔掉,或者编写一些特定的逻辑进行文本清洗),然后对语义进行切分,最后通过自动标注(基于规则/模型)进行辅助标注,或者借助Doccano平台人工进行标注。
然后使用大模型对测试样本进行质量审核,确保数据具备清晰性和可溯源性。
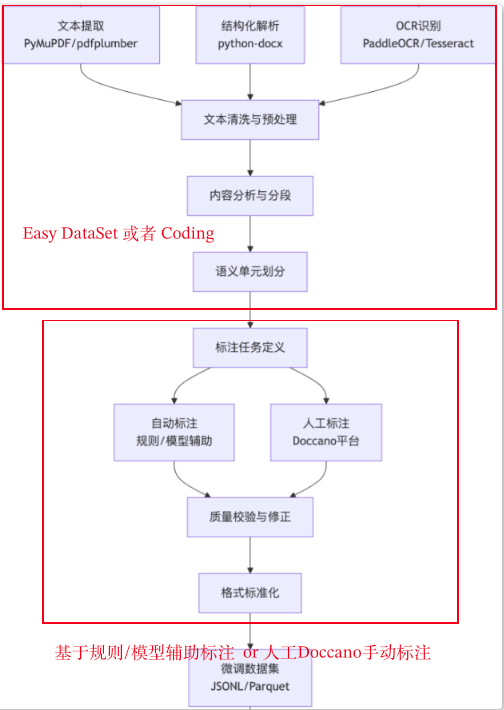
文本怎么切分的?
什么是OCR?项目中用的哪个框架?
OCR 技术,全称是光学字符识别(Optical Character Recognition),是一种将图像中的文字内容进行识别并提取的技术。
我们项目使用的是PaddleOCR,它是由百度飞桨(PaddlePaddle)团队基于其深度学习框架 PaddlePaddle 开发并开源的一个全流程、超轻量、高精度的 OCR 工具库。
百度飞桨(PaddlePaddle)团队在今年10月中旬开源了PaddleOCR-VL,在GitHub上是中国唯一一个Star数超过50k的OCR项目
你们项目是如何来加载pdf的?
主要思路:
- 继承LangChain中的BaseLoader类,实现init方法和lazy_load方法,将整个 pdf 的提取结果加上元数据信息作为一个 Document yield 出去。
- 内容提取的核心逻辑是:使用PyMuPDF模块中的fitz加载PDF,用来提取文字和图片元数据信息,对于图片信息使用PaddleORC(使用的rapidocr_paddle 模块下的 RapidOCR类)识别图片中的文字,最终将结果拼接到一起。
主要流程:
- 使用
fitz.open()打开 PDF。 - 逐页 (
page) 处理。 - 使用
page.get_text()提取原生文本。 - 使用
page.get_image_info(xrefs=True)获取页面上的图片信息。 - OCR 应用: 对获取到的图片,检查其尺寸是否超过预设阈值
PDF_OCR_THRESHOLD(默认为页面宽高的 60%)。仅对大于阈值的图片执行 OCR。 - 处理页面旋转 (
page.rotation),确保 OCR 时图像方向正确。 - 调用
get_ocr()获取的 OCR 实例识别图片文字。 - 合并原生文本和 OCR 结果。
你们项目是如何来加载doc的?
主要思路:
- 继承LangChain中的BaseLoader类,实现init方法和lazy_load方法,将整个 word文档 的提取结果加上元数据信息作为一个 Document yield 出去。
- 内容提取的核心逻辑是:使用python-docx模块加载word文档,然后获取该文档的块信息(Paragraph或Table),接下来去处理每一个块。如果是段落,先把段落中的文字提取出来,然后段落中的图片使用PaddleORC(使用的rapidocr_paddle 模块下的 RapidOCR类)识别其中的文字;如果是表格,则直接遍历获取表格单元格中的信息。最终将结果拼接到一起。
主要流程:
- 使用
docx.Document()打开 DOCX 文件。 - 定义
iter_block_items辅助函数,用于统一遍历文档中的段落 (Paragraph) 和表格 (Table) 块。 - 遍历所有块:
- 如果是段落,提取
block.text。同时,使用 XPath (.//pic:pic,.//a:blip/@r:embed) 查找并提取段落内嵌入的图片。对提取的图片执行 OCR。 - 如果是表格,遍历所有单元格 (
cell),提取单元格内段落的文本。 - 合并所有提取的文本和 OCR 结果。
你们项目ppt加载器怎么做的?
主要思路:
- 继承LangChain中的BaseLoader类,实现init方法和lazy_load方法,将整个 ppt 的提取结果加上元数据信息作为一个 Document yield 出去。
- 内容提取的核心逻辑是:使用python-pptx模块加载ppt,然后逐张处理PPT。在处理PPT时,首先将PPT上的形状 (
shape) 按视觉顺序(top,left坐标)排序,排序完后依次去处理每个形状。在处理形状时,如果是文本框 ,则直接提取文本;如果是表格,则直接遍历获取表格单元格中的信息;如果是图片,则使用PaddleORC(使用的rapidocr_paddle 模块下的 RapidOCR类)识别其中的文字;如果是组合形状,则进行递归调用。最终将结果拼接到一起。
主要流程:
- 使用
pptx.Presentation()打开演示文稿。 - 逐张幻灯片 (
slide) 处理。 - 顺序处理: 将幻灯片上的形状 (
shape) 按视觉顺序(top,left坐标)排序。 - 定义 extract_text 递归函数处理单个形状:
- 提取文本框 (
shape.has_text_frame) 的文本。 - 提取表格 (
shape.has_table) 内所有单元格的文本。 - 如果形状是图片 (
shape.shape_type13),提取图片数据 (shape.image.blob`),执行 OCR。 - 如果形状是组合 (
shape.shape_type6),递归调用extract_text` 处理其包含的子形状。
- 提取文本框 (
- 遍历排序后的形状,调用
extract_text。 - 合并所有提取的文本和 OCR 结果。
你们项目图片加载器怎么做的?
主要思路:
- 继承LangChain中的BaseLoader类,实现init方法和lazy_load方法,将整个图片的提取结果加上元数据信息作为一个 Document yield 出去。
- 内容提取的核心逻辑是:使用PaddleORC(使用的rapidocr_paddle 模块下的 RapidOCR类)识别其中的文字。
主要流程:
- 接收图像文件路径
img_path。 - 调用
get_ocr()获取 OCR 实例。 - 直接对图像文件执行 OCR。
- 将 OCR 结果(所有识别出的文本行)合并成一个字符串。
为什么自定义基于模型的语义切分器?怎么做的?
原因:通过达摩院开源的文档语义分割模型实现对文本的切分,准确度高并且效率高
主要实现逻辑:继承langchain.text_splitter.CharacterTextSplitter,对split_text方法进行了修改。修改的方式就是利用预训练的文档语义分割模型对文本进行切分。具体的切分方式调用 modelscope.pipeline 加载指定的文档分割模型(nlp_bert_document-segmentation_chinese-base,达摩院开源的文档语义分割模型)模型,将输入文本传递给模型 pipeline 进行处理,最后解析模型输出,得到分块的结果。
为什么选用这个模型?
因为 nlp_bert_document-segmentation_chinese-base 是 达摩院开源的文档语义分割模型,通过自适应滑动窗口的序列模型,对输入文本进行语义层面的段落分割。它先将整个文本作为序列输入,然后使用使用 BERT 基础模型预测每个 token 是否是段落边界,通过自适应滑动窗口动态调整处理窗口大小,提高准确性和效率。
Easy Dataset
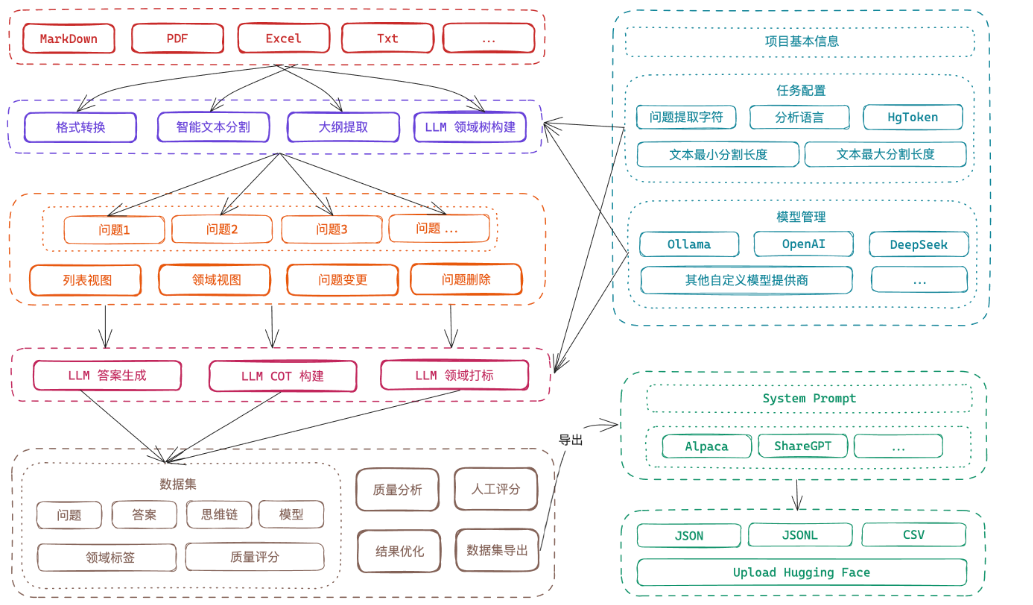
语料标注工具
Doccano平台 or 规则/模型自动标注
1 | 标准格式Json格式: |
为什么用Doccano平台?
Doccano是documment anotation的缩写,是一个开源的文本标注工具,我们可以用它为NLP任务的语料库进行打标。支持**情感分析,命名实体识别,文本摘要等任务。**操作非常便捷,在小型语料库上,只要数小时就能完成全部的打标工作。

**Doccano 本身不直接支持评分机制,但可以通过多种方式实现标签评分功能。**比如序列标注+属性评分
1 | { |
自动语音分段
为什么选择VAD?
应用场景宽泛,主要有如下应用场景:
实时通信:视频会议静音检测、VoIP通话质量优化
语音助手:降低误唤醒率(如唤醒词前的语音过滤)
音频预处理:语音识别(ASR)前的噪音过滤
边缘计算:嵌入式设备(如智能音箱、车载系统)
数据分析:通话录音自动分段、客服语音质检
VAD 模型本身非常小(10MB以下),资源消耗占用少,甚至可以在cpu上运行,同时具备超实时的音频处理速度,天然适合高并发场景(负载低,服务器可以提供高并发)
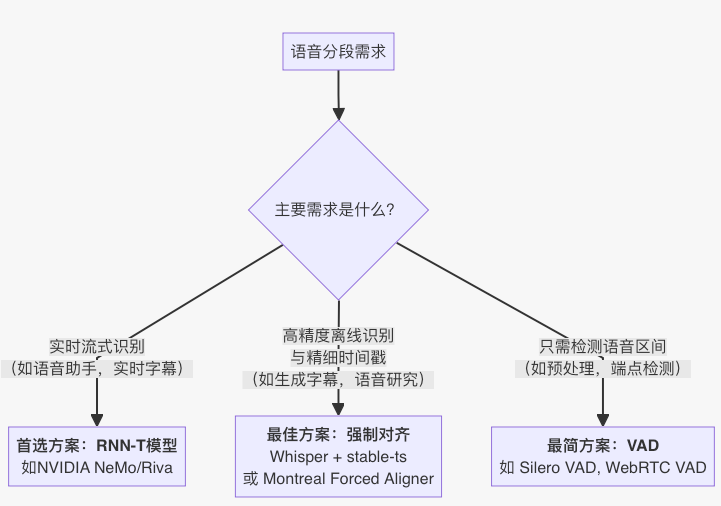
两种ASR中的VAD开源模型
第一种就是FSMN-VAD,这个是达摩院语音团队提出的高效语音端点检测模型,用于检测输入音频中有效语音的起止时间点信息。它使用了一种称为Feedforward Sequential Memory Networks(FSMN)的神经网络结构,该结构能够有效地建模长期依赖关系。FSMN-VAD将输入的音频信号转换为时频表示,并通过FSMN网络对时频特征进行建模和分类,以决定每一帧是否包含有声音。该算法还利用了前后文语境信息,以提高语音活动检测的准确性。
FSMN-Monophone VAD模型结构如下图所示:模型结构层面,FSMN模型结构建模时可考虑上下文信息,训练和推理速度快,且时延可控;同时根据VAD模型size以及低时延的要求,对FSMN的网络结构、右看帧数进行了适配。在建模单元层面,speech信息比较丰富,仅用单类来表征学习能力有限,我们将单一speech类升级为Monophone。建模单元细分,可以避免参数平均,抽象学习能力增强,区分性更好。
Silero-VAD是另一种用于语音活动检测的算法,它是由Silero AI团队开发的。该算法是基于深度学习的,使用了一种称为VGGish的卷积神经网络结构。Silero-VAD首先将输入的音频信号转换为时频表示,并将其作为输入提供给VGGish网络,以进行特征提取和分类。通过训练大量的语音数据,Silero-VAD能够准确地识别出声音活动的存在与否。
Silero VAD 是预训练的企业级语音端点检测模型,一个音频块 (30+ 毫秒) 在单个 CPU 线程上处理的时间不到 1 毫秒。使用批处理或 GPU 也可以显著提高性能。在某些情况下,ONNX 的运行速度甚至可以提高 4-5 倍。Silero VAD 在包含 6000 多种语言的庞大语料库上进行了训练,它在具有不同背景噪音和质量水平的不同领域的音频上表现良好,且Silero VAD 支持 8000 Hz 和 16000 Hz采样率。
FSMN-VAD和Silero-VAD都是用于语音活动检测的先进算法,它们在准确性和效率方面都取得了很好的表现。这些算法在语音识别、音频分类和语音分割等领域都有广泛的应用潜力。
如何使用fsmn-vad
输入音频文件(格式可以为:.mp3, .wav, .pcm),输出内容
有两种框架可供选择分别是阿里的funasr、开源的modelscope
1 | from funasr import AutoModel |
输出结果res:
1 | # [ |
使用modelscpoe框架加载模型,进行处理:
1 | from modelscope.pipelines import pipeline |
如果输入音频为pcm格式,需要给定采样率fs:
1 | segments_result = inference_pipeline(input='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.pcm', fs=16000) |
silero-vad使用
使用
1 | import torch |
议题评分逻辑

为什么是RFM?
RFM模型是一种用于客户价值分析的模型,通过对客户的消费行为进行分析,将客户分为不同的类别,以便企业更好地了解客户、制定更有效的营销策略和提高客户满意度。
RFM模型也叫RFM分析,对于三个维度进行评分,分别为最近一次购买时间(Recency)、购买频率(Frequency)和消费金额(Monetary)
- 最近一次购买时间(Recency)指客户最近一次购买产品或服务的时间,购买时间越近,说明客户越活跃,对企业的贡献也越大。
- 购买频率(Frequency)指客户在一段时间内购买产品或服务的次数,购买频率越高,说明客户对企业的忠诚度和购买意愿越强。
- 消费金额(Monetary)指客户在一段时间内购买产品或服务的金额,消费金额越高,说明客户的购买能力和对企业的贡献越大。
通过借鉴企业中常用的RFM模型,我们可以避免一些人为的主观判断对数据造成评分忽高忽低,数据质量不稳定的影响。
解决方案是什么?
第一种:使用jieba分词,将文章中的内容进行分词,然后针对披露框架、披露内容、语言表达分别搞一些采分点,如果文本中的语句包含这些采分点,那么就算一分,最终通过计算比例将三个维度的评分标准归一化在0-10分之间。
第二种:使用大模型进行评分,通过给一些few shot 和提示词的方式,让大模型去自动打分。
1 | SYSTEM_PROMPT = """你是一个专业的文档质量评估专家,专门评估企业披露文档的质量。请根据以下评分标准对文档进行客观评估: |
数据处理步骤是什么?
使用PyMUPDF加载PDF, 对文档进行切分,按照标点符号进行切块,然后循环遍历分块,有踩分点会打上标记,最后通过归一化处理,得到0-30之间的数字。
1 | r_bins = [-1, 79, 255,365] |
公众号推文智能体
数据源输入:
- 公众号(知识最全,附件最多,但是附件的格式可能是链接或者图片)- 效果最好,但是技术实现比较困难
- 网站ZAKER、其他网站(知识比较一般,可能不会很稳定,附件很少见到)
数据输出:
- 大模型整理好的文档
Firecrawl 四种抓取方式对比
| 抓取方式 | 核心目标 | 工作方式 | 适用场景 | 简单比喻 |
|---|---|---|---|---|
| Scrape(抓取单个页面) | 获取单个指定网页的纯净内容 | 输入一个具体的URL,Firecrawl 会抓取该页面,并提取正文文本,清除广告、导航栏等无关内容。 | - 快速提取一篇新闻文章、一篇博客帖子或一个产品页面的内容。 - 分析某个特定网页的信息。 | 单页阅读器:精准地阅读并总结一本书(单个网页)的核心内容。 |
| Crawl(爬取整个网站) | 系统地抓取整个网站的所有可用页面 | 输入网站的根域名(如 example.com),Firecrawl 会像搜索引擎一样,跟随站内链接,尽可能多地抓取该域名下的所有页面。 |
- 为某个公司官网建立知识库。 - 批量下载整个文档网站的所有手册。 - 进行全面的网站内容分析。 | 网站复印机:遍历整栋大楼(整个网站)的每个房间(每个页面),并复印所有文件。 |
| Map(生成网站地图) | 探索和发现网站的结构,而不提取详细内容 | 输入一个URL,Firecrawl 会探索该页面所能链接到的所有页面,并生成一个清晰的、层次化的结构图(sitemap),显示页面之间的关联。 | - 在全面抓取前,先了解网站的规模和信息架构。 - 快速发现一个网站有哪些主要栏目和内容。 - 进行SEO分析或信息架构研究。 | 建筑蓝图:不关心房间里具体放什么(不提取内容),只绘制出整栋大楼的房间布局和走廊连接(页面结构)。 |
| Crawl Job(爬取任务) | 执行大规模、可排队和管理的批量爬取任务 | 这是“Crawl”模式的企业级或高级版本。允许你提交大量、复杂的爬取任务,系统会将其加入队列依次处理,并提供任务状态、管理和结果回调等功能。 | - 需要爬取成百上千个网站。 - 任务执行时间较长,需要稳定的异步处理和进度监控。 - 集成到自动化工作流中,需要接收任务完成的通知。 | 工业生产线:不是单次复印,而是管理一条有排队、调度、状态监控的自动化复印流水线,用于处理海量任务。 |
Agent Workflow架构
议题Agent搭建
RAG知识库构建:首先对文档进行解析 → 语义切分or字符切分 → Embedding嵌入 →存储到向量数据库中
dify本地化部署知识库,文件上传大小限制15MB,文件个数没有限制
dify在线部署知识库,文件上传大小限制15MB,文件个数最多5个
议题Agent流程是什么样的?
将用户的Excel类型问卷转成Json,然后解析问题和答案为KV键值对,循环获取问题,使用大模型进行查询改写,将问题进行扩写。对每一个问题生成假设答案,针对假设答案进行知识库检索,将检索到的结果进行整理,然后和原始文件一起拼接送入到大模型中进行报告的生成(这一块还有个提示词一块拼接)。
文档不经过解析直接上传到Dify不行,如何解决?
对文档先进行加载,然后解析,针对不同的文档类型使用不同的解析方式,然后拼接成文本
- 数据增强(分词、停用词过滤,序列长度统一)
- 元数据信息提取(目录、页面大小标题、文件名称、文件大小、文档字符数量)
1 | try: |
- 内容数据清洗(标点符号规范化,移除多余空白字符)

 微信
微信 支付宝
支付宝