
【Python爬虫(一)】爬虫前置问题总结
文章内容部分来自Chatgpt。
了解网站的访问限制
当您想要获取某个网站的数据的时候总要知道一些网站的规则吧,要不然(IP,账号)怎么被封的都不知道。
一般网站会限制什么
访问频率限制:就是控制服务器的负载,防止服务器崩掉
- 相应的测试:逐渐增加自己的访问频率,观察是否出现访问被限制的情况。最开始可以以较低的访问频率进行测试,例如每分钟只访问一次,然后逐渐增加访问频率。如果在某个阶段发生了访问限制,那么该阶段的访问频率就是网站的限制阈值。
- 解决方案:控制爬虫的访问频率。
IP地址限制:限制IP
- 测试:使用不同的IP地址进行访问,观察是否出现了访问被限制的情况。可以通过使用代理服务器或者虚拟专用网络(VPN)来切换IP地址,以模拟不同的访问来源。如果使用不同的IP地址进行访问时出现了访问限制,那么网站可能对IP地址进行了限制。
- 解决方案:使用proxy远程代理(VPN),或者使用虚拟机。
如何查看自己被ban了
- 访问错误提示:观察访问被限制时的错误提示信息。有些网站会返回特定的HTTP状态码或者错误信息来指示访问被限制,例如403 Forbidden、429 Too Many Requests等。通过观察返回的错误信息,可以推断出网站的限制策略。
解决方案:
- 观察网站是否对请求头中的特定字段进行检查,例如User-Agent、Referer等。可以尝试修改这些请求头字段的值,看是否能够绕过访问限制。
Python中常见的编码格式
- 应用场景:通常对于一个url都是有一定的规律的。比如你在百度或者什么搜索引擎上搜索某个东西,你写的汉字在URL一栏中就会变成对应的URL编码格式,虽然我也不知道这是什么编码格式,目前有专门的第三方库来处理这个编码。
- 比如如下的代码,就会将你搜索的关键字进行URL编码,然后通过URL拼接就可以得到目的地址。
1 | # 输入要搜索的关键词 |
- ASCII(American Standard Code for Information Interchange):ASCII是最早的字符编码,包含128个字符,用于表示基本的英文字母、数字和标点符号。ASCII编码只使用一个字节(8位)来表示一个字符。
- UTF-8(Unicode Transformation Format-8):UTF-8是一种可变长度的Unicode编码,它可以表示Unicode字符集中的任意字符。UTF-8编码使用1至4个字节来表示一个字符,适用于全球范围内的文本。
- UTF-16(Unicode Transformation Format-16):UTF-16是一种Unicode编码格式,使用16位(2个字节)来表示一个字符。UTF-16可以表示Unicode字符集中的所有字符。
- UTF-32(Unicode Transformation Format-32):UTF-32是一种Unicode编码格式,使用32位(4个字节)来表示一个字符。UTF-32同样可以表示Unicode字符集中的所有字符。
- GBK(GuoBiaoKuozhan):GBK是中国国家标准局发布的汉字字符集编码标准,支持简体中文和繁体中文。GBK编码使用1至2个字节来表示一个汉字字符。
- GB2312:GB2312是中国国家标准局发布的汉字字符集编码标准,是GBK的前身。GB2312编码使用1至2个字节来表示一个汉字字符。
除了以上列举的编码格式外,还有许多其他编码格式,如ISO-8859系列编码、Big5编码(主要用于繁体中文)、Shift-JIS编码(主要用于日语)等。每种编码格式都有其特定的应用场景和使用方式。
在Python中,可以使用字符串的
encode()方法对字符串进行编码,指定要使用的编码格式;使用decode()方法将编码后的字节流解码为字符串时,同样需要指定正确的编码格式。
查看网站对应的API接口
实话说,自从用过seleinum,自此都没看过前端的接口了。
这里给一个参考链接:Chrome查看API接口URL_查看网页api-CSDN博客
手动总结一下:
- request_url就是请求接口
- 然后请求的东西(比如说图片)Content-Type是image/jpeg;charset=UTF-8
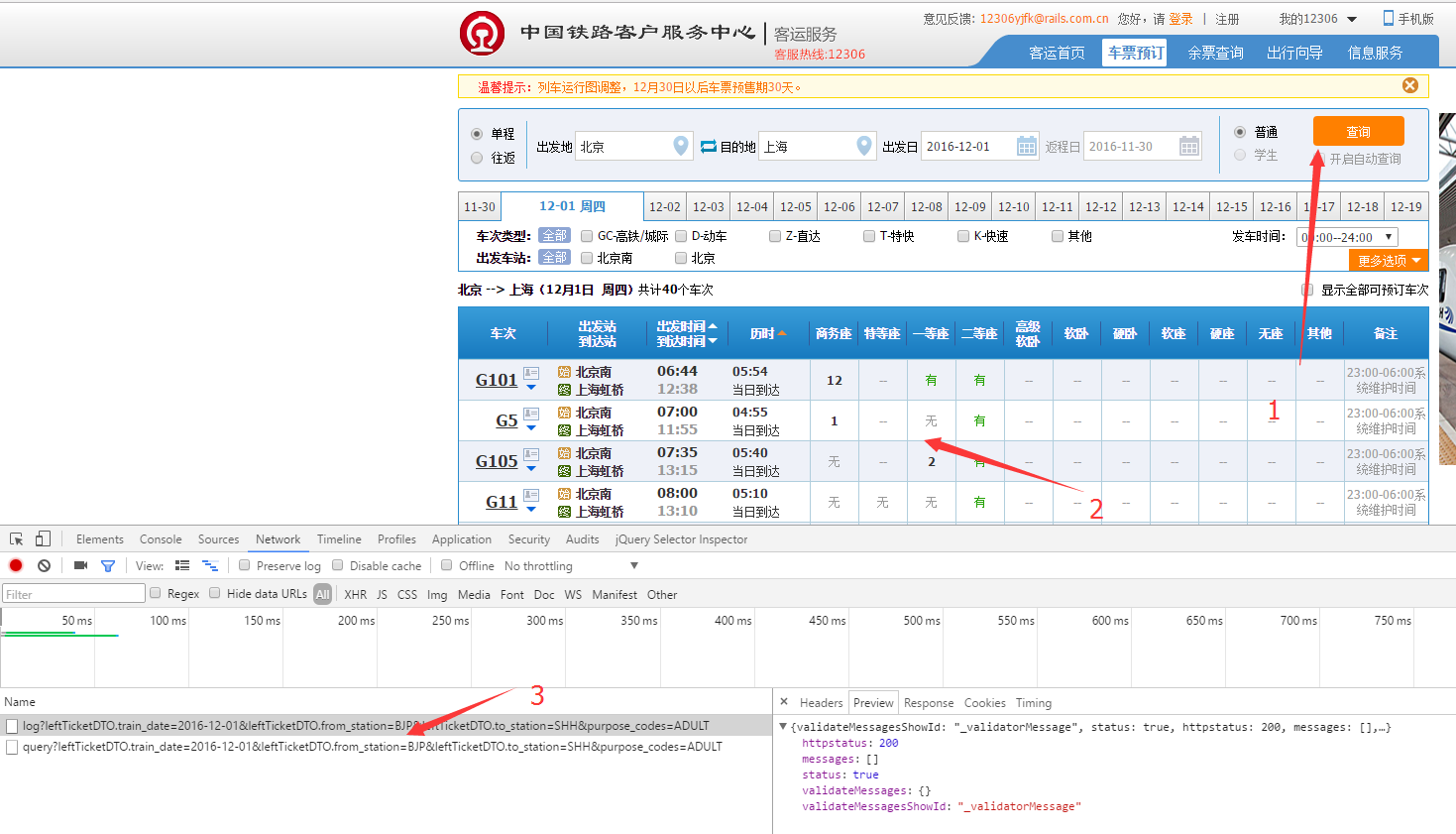
拿上面的链接内容举例:
- 第一个接口,名字叫log
1 | 协议:https: |
- 第二个接口,名字叫query
1 | 协议:https: |
新版seleinum食用方式
查找元素
最新版 Selenium 中,查找元素的方法主要通过
find_element()或find_elements()方法进行。之前的一些方式find_elements_by_css等方法就不能使用了。这两个方法在返回结果上有所区别:
find_element():返回匹配的第一个元素,如果未找到则抛出NoSuchElementException异常。find_elements():返回一个包含所有匹配元素的列表,如果未找到任何元素,则返回空列表。
用这些方法时,需要提供一种定位元素的策略,如 ID、class、XPath、CSS 选择器等。下面是几种常用的查找元素的方法及其用法示例:
- 通过 ID 查找元素:
1 | pythonCopy Codeelement = driver.find_element(By.ID, "element_id") |
- 通过 class 查找元素:
1 | pythonCopy Codeelement = driver.find_element(By.CLASS_NAME, "element_class") |
- 通过 XPath 查找元素:
1 | pythonCopy Codeelement = driver.find_element(By.XPATH, "//tagname[@attribute='value']") |
- 通过 CSS 选择器查找元素:
1 | pythonCopy Codeelement = driver.find_element(By.CSS_SELECTOR, "tagname[attribute='value']") |
- 通过名称查找元素:
1 | pythonCopy Codeelement = driver.find_element(By.NAME, "element_name") |
以上仅是一些常用的查找元素的方式,Selenium 还提供了其他几种定位元素的方法,如链接文本、标签名等。
在上述示例中,driver 是 WebDriver 的实例,可以是 Chrome、Firefox 等浏览器驱动的实例。另外,需要导入 By 类来使用其中的定位策略常量。如果无法导入 By,可以尝试使用 selenium.webdriver.common.by.By。
注意:根据具体情况,可能需要等待页面加载或元素出现后再进行元素查找操作。可以使用 WebDriverWait 类等待元素出现,并结合使用 ExpectedConditions 类指定等待条件。
示例代码:
1 | from selenium.webdriver.common.by import By |
Seleinum加载页面非常慢
- 可能的原因
- 网络连接问题:慢速的网络连接可能导致页面加载缓慢。您可以尝试改善网络连接,例如使用更稳定的网络或尝试在较快的网络环境下运行测试。
- 页面元素过多或复杂:如果页面包含大量元素或复杂的 DOM 结构,加载速度可能会减慢。您可以优化页面,简化 DOM 结构,减少不必要的元素和样式,以提高页面加载速度。
- 页面中存在大量的资源请求:页面中的 JavaScript、CSS 文件和图像等资源的数量和大小也会影响加载速度。您可以优化资源加载,合并和压缩文件,使用 CDN 加速,或者延迟加载某些资源,以减少页面加载时间。
- 代码层面解决(设置一些参数)
2
3
4
5
6
7
8
options = webdriver.ChromeOptions()
options.page_load_strategy = 'eager' # 设置页面立即加载
options.add_argument('--disable-gpu') # 禁用 GPU 加速
options.add_argument('--headless') # 使用无界面模式
driver = webdriver.Chrome(options=options)
按钮点击后没反应
- 总的来说就是按钮的元素没有找到,请检查自己写的代码,并选择合适的selector来找到login_button
- 其次就是点击流有可能绑定了动态的JS代码,加载也是需要时间的
time.sleep(3) - 如果还不能解决,那就设置一个等待条件:
1 | # 等待特定元素出现 |
- 页面上没有找到名为 “login_button” 的元素:请确保
login_button是正确的按钮元素的变量名,并且确保在调用click()方法之前已经成功地找到了该元素。可以使用开发者工具检查页面结构和元素的属性。- 按钮元素不可见或被其他元素遮挡:如果按钮元素设置了
display: none;或visibility: hidden;,或者被其他元素(如覆盖的图层或弹出窗口)遮挡,那么调用click()方法也不会产生任何效果。确保按钮元素可见且没有被其他元素遮挡。- 按钮元素绑定的事件无效或未正确触发:如果按钮元素绑定了 JavaScript 的点击事件处理程序,但事件处理程序有语法错误或逻辑错误,可能会导致浏览器没有正确响应按钮点击操作。请检查事件处理程序代码是否正确、完整,并确保它们能够正常执行。
- 浏览器或页面存在其他错误:可能存在其他导致浏览器没有反应的问题,如网络连接问题、浏览器插件冲突、页面加载错误等。尝试重新加载页面,检查网络连接,禁用或卸载浏览器插件,或尝试在不同的浏览器中运行代码,看看是否能够解决问题。
附录
Seleinum的ChromeOptions
常用参数:
- 禁用拓展–disable-extensions。
- 禁用图片:–disable-images
- 禁用GPU加速:chrome_options.add_argument(‘–disable-gpu’)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
--allow-running-insecure-content 默认情况下,https 页面不允许从 http 链接引用 javascript/css/plug-ins。添加这一参数会放行这些内容。
--allow-scripting-gallery 允许拓展脚本在官方应用中心生效。默认情况下,出于安全因素考虑这些脚本都会被阻止。
--disable-accelerated-video 停用 GPU 加速视频。
--disable-dart 停用 Dart。
--disable-desktop-notifications 禁用桌面通知,在 Windows 中桌面通知默认是启用的。
--disable-extensions 禁用拓展。
--disable-file-system 停用 FileSystem API。
--disable-preconnect 停用 TCP/IP 预连接。
--disable-remote-fonts 关闭远程字体支持。SVG 中字体不受此参数影响。
--disable-speech-input 停用语音输入。
--disable-web-security 不遵守同源策略。
--disk-cache-dir 将缓存设置在给定的路径。
--disk-cache-size 设置缓存大小上限,以字节为单位。
--dns-prefetch-disable 停用DNS预读。
--enable-print-preview 启用打印预览。
--extensions-update-frequency 设定拓展自动更新频率,以秒为单位。
--incognito 让浏览器直接以隐身模式启动。
--keep-alive-for-test 最后一个标签关闭后仍保持浏览器进程。(某种意义上可以提高热启动速度,不过你最好得有充足的内存)
--kiosk 启用kiosk模式。(一种类似于全屏的浏览模式)
--lang 使用指定的语言。
--no-displaying-insecure-content 默认情况下,https 页面允许从 http 链接引用图片/字体/框架。添加这一参数会阻止这些内容。
--no-first-run 跳过 Chromium 首次运行检查。
--no-referrers 不发送 Http-Referer 头。
--no-sandbox 彻底停用沙箱。
--no-startup-window 启动时不建立窗口。
--proxy-pac-url 使用给定 URL 的 pac 代理脚本。(也可以使用本地文件,如 --proxy-pac-url="file:\\\c:\proxy.pac")
--proxy-server 使用给定的代理服务器,这个参数只对 http 和 https 有效。(例如 --proxy-server=127.0.0.1:8087 )
--single-process 以单进程模式运行 Chromium。(启动时浏览器会给出不安全警告)
--start-maximized 启动时最大化。
--user-agent 使用给定的 User-Agent 字符串
参数:--user-data-dir=UserDataDir
用途:自订使用者帐户资料夹(如:–user-data-dir="D:\temp\Chrome User Data")
参数:--process-per-tab
用途:每个分页使用单独进程
参数:--process-per-site
用途:每个站点使用单独进程
参数:--in-process-plugins
用途:插件不启用单独进程
参数:--disable-popup-blocking
用途:禁用弹出拦截
参数:--disable-javascript
用途:禁用JavaScript
参数:--disable-java
用途:禁用Java
参数:--disable-plugins
用途:禁用插件
参数:–disable-images
用途:禁用图像
参数:--omnibox-popup-count=”num”
用途:将网址列弹出的提示选单数量改为num个
参数:--enable-vertical-tabs
用途:调整chrome游览器标签存放在左边,非顶部
 微信
微信 支付宝
支付宝