什么是Ranger
Apache Ranger是一个Hadoop平台上的全方位数据安全管理框架,它可以为整个Hadoop生态系统提供全面的安全管理。
安装Apache的软件要注意一点,就是各个版本的兼容性问题。
Apache Sentry和Ranger优缺点
一般来说:CDH自带的是Sentry,HDP的是Ranger。
Sentry是由Cloudera公司内部开发而来的,所以Sentry对HDFS,Hive以及同样由Cloudera开发的Impala有着很好的支持性.
Ranger则是由于另一家公司Hortonworks所主导。相比较于Sentry而言,它能支持更丰富的组件,包括于 HDFS, Hive, HBase, Yarn, Storm, Knox, Kafka, Solr ,NiFi。
早期CDH版本只提供sentry的权限管理方案,后期新版本提供ranger作为替换方案,而CDH只有商业版本提供sentry升级ranger的服务,开源社区版并未提供这样的能力,可以说Ranger是Sentry的一个升级版。
两个组件的比较如下:
- Apache Ranger 拥有自己的 Web 用户界面 (Web UI)
- Ranger Web UI 也可用于安全密钥管理,使用 Ranger KMS 服务的密钥管理员可以单独登录。
- Apache Ranger 同时提供了Restful接口,就是用URI表示资源,用HTTP方法(GET, POST, PUT, DELETE)表征对这些资源的操作。
- Apache Ranger 还提供了非常需要的安全功能,例如开箱即用的列掩码和行过滤。
- Ranger 中的访问策略可以使用不同的属性(如地理区域、一天中的时间等)在动态上下文中进行自定义。下表给出了 Sentry 和 Ranger 之间功能的详细比较。
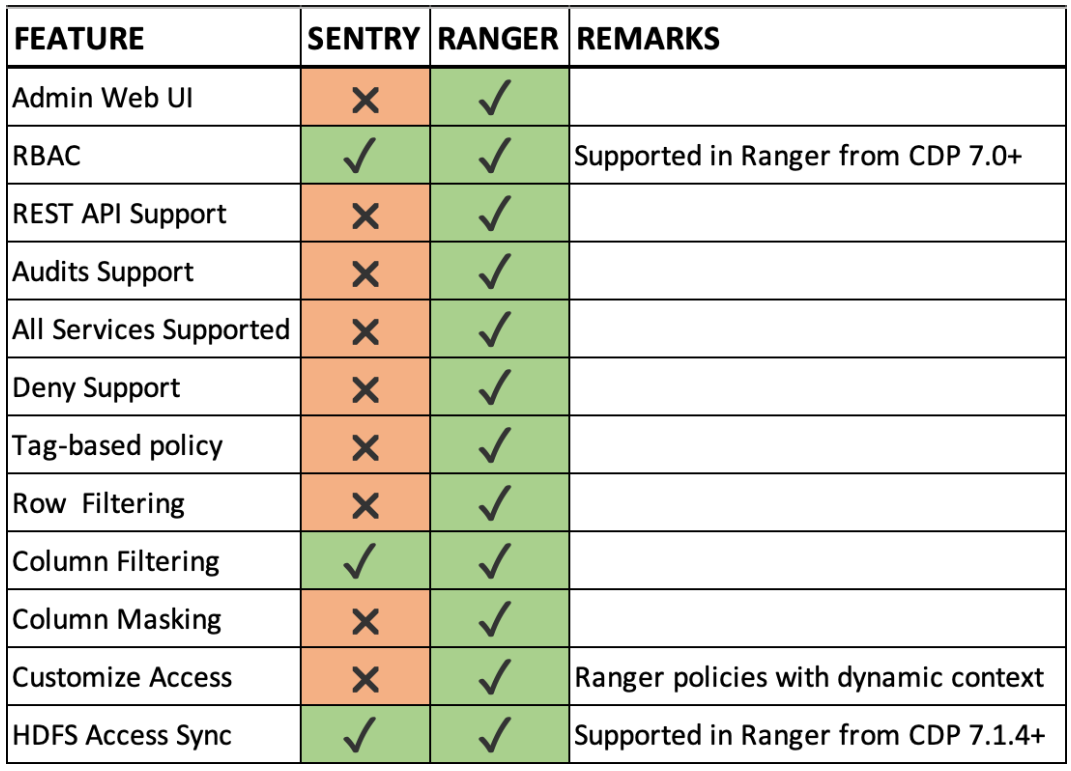
Apache Sentry和Ranger权限比较
Sentry权限控制
Sentry是典型的RABC权限管理系统,通过用户-用户组-角色关联,最终通过role来进行赋权,一般只用于表级授权,存在三种权限类型:select/insert/all(*)。
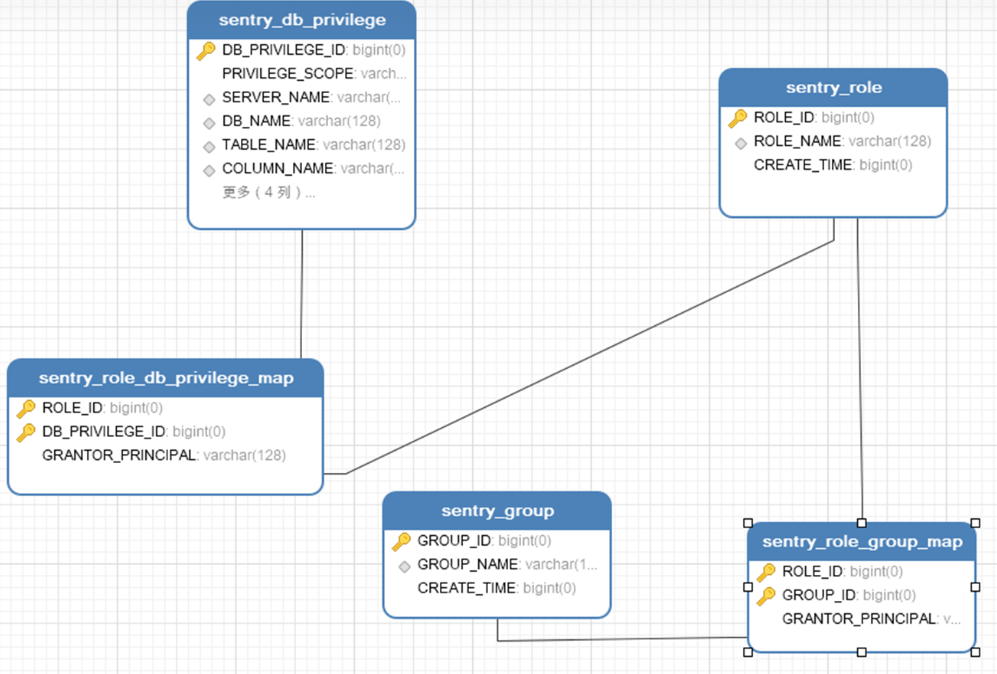
- sentry_role: 角色列表
- sentry_group;用户组列表
- sentry_role_group_map;角色、用户映射关系表
- sentry_db_privilege: 表权限信息表
- sentry_role_db_privilege_map: 权限、角色映射关系表
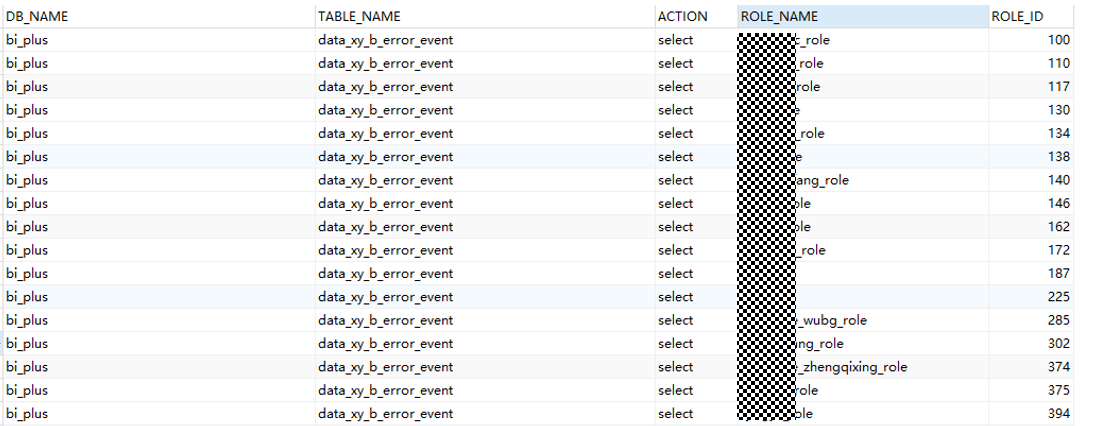
举例:
表bi_plus.data_xy_b_error_event赋予了XX用户select权限,数据模型如下:
Ranger权限控制
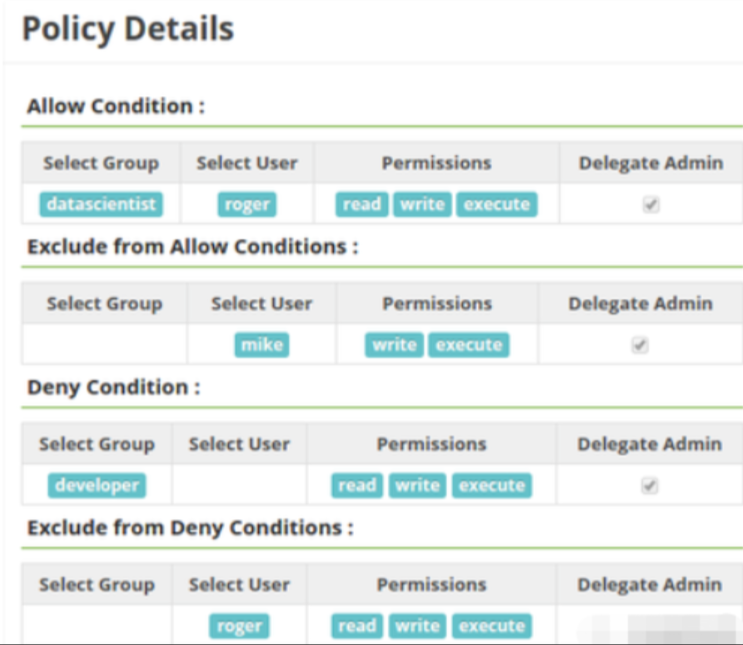
- 对于用户权限的控制
- 最简单的,对于用户的访问控制,我们可以设置用户对于选定的路径有哪些权限,策略细节如下:
假设有一张hive表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| +----+------------+-----------+--------------+---------------+----------------+
| id | name_first | name_last | addr_country | date_of_birth | phone_num |
+----+------------+-----------+--------------+---------------+----------------+
| 1 | Mackenzy | Smith | US | 1993-12-18 | 123-456-7890 |
| 2 | Sherlyn | Miller | US | 1975-03-22 | 234-567-8901 |
| 3 | Khiana | Wilson | US | 1989-08-14 | 345-678-9012 |
| 4 | Jack | Thompson | US | 1962-10-28 | 456-789-0123 |
| 5 | Audrey | Taylor | UK | 1985-01-11 | 12-3456-7890 |
| 6 | Ruford | Walker | UK | 1976-05-19 | 23-4567-8901 |
| 7 | Marta | Lloyd | UK | 1981-07-23 | 34-5678-9012 |
| 8 | Derick | Schneider | DE | 1982-04-17 | 12-345-67890 |
| 9 | Anna | Richter | DE | 1995-09-07 | 23-456-78901 |
| 10 | Raina | Graf | DE | 1999-02-06 | 34-567-89012 |
| 11 | Felix | Lee | CA | 1982-04-17 | 321-654-0987 |
| 12 | Adam | Brown | CA | 1995-09-07 | 432-765-1098 |
| 13 | Lucas | Jones | CA | 1999-02-06 | 543-876-2109 |
| 14 | Yvonne | Dupont | FR | 1982-04-17 | 01-23-45-67-89 |
| 15 | Pascal | Fournier | FR | 1995-09-07 | 23-45-67-89-01 |
| 16 | Ariel | Simon | FR | 1999-02-06 | 34-56-78-90-12 |
+----+------------+-----------+--------------+---------------+----------------+
|
假设此时我们执行以下查询语句,我们肯定能查到所有表数据,如果此时我们加一个用户归属地的判断,要求是限制用户只能访问位于用户工作的同一国家的客户的记录。例如,美国用户只能访问美国客户记录;英国用户只能访问英国的客户记录。用户属于LDAP/AD中维护的特定国家/地区的组之一,如下例所示:
1
2
3
4
5
6
7
| +--------------+---------------+
| Group name | Users |
+--------------+---------------+
| us-employees | john,scott |
| uk-employees | mary,adam |
| de-employees | drew,alice |
+--------------+---------------+
|
在Ranger的页面配置效果如下图所示:

接着
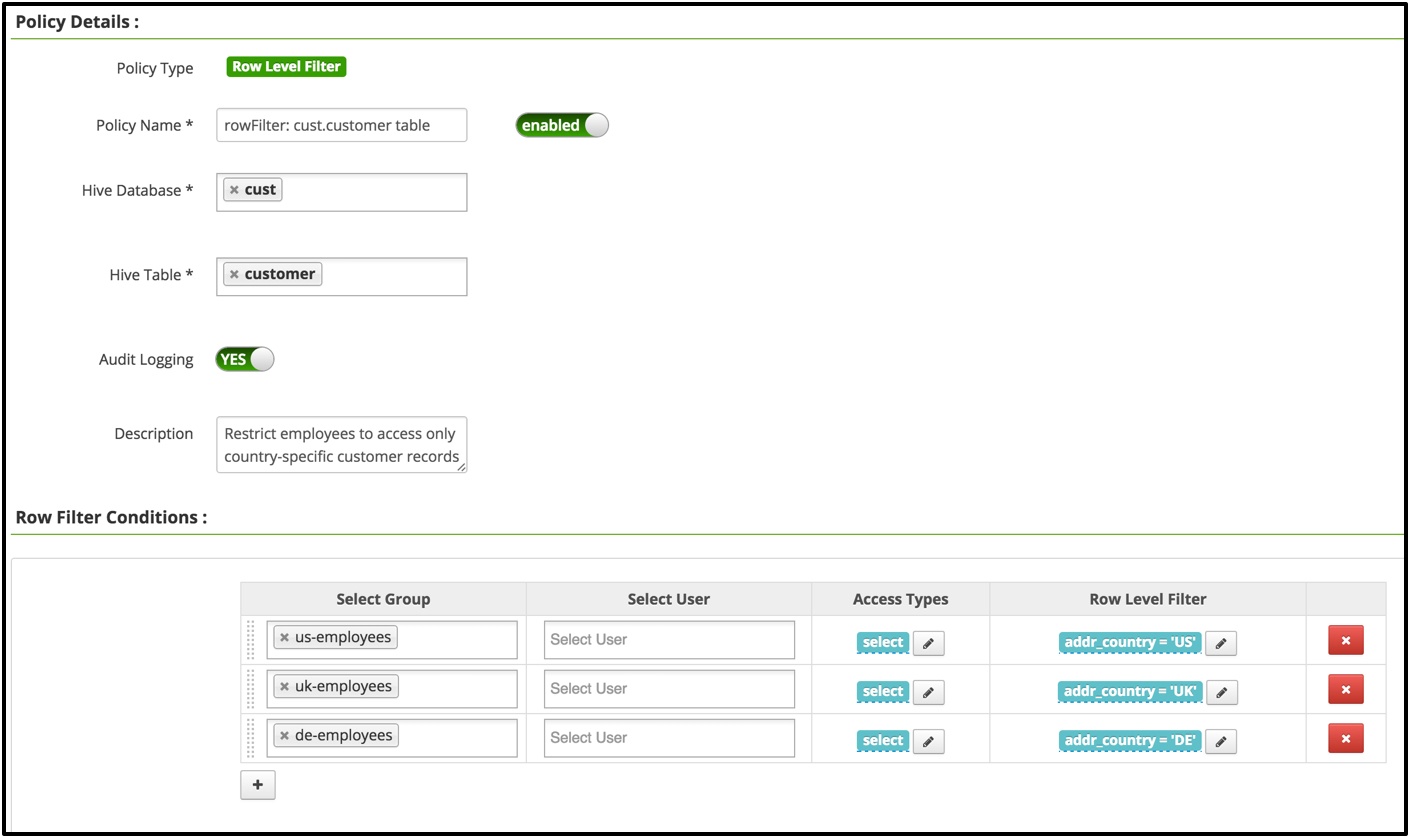
然后我们以john用户身份去查,查出的记录所属地域就只会是US上的了,不会查到全部的数据了。而是只能查看到自己区域内的客户信息,这样就作了一个对应数据的控制。
1
2
3
4
5
6
7
8
9
| [mary@localhost ~]$ beeline -u jdbc:hive2://localhost.localdomain:10000/cust
0: jdbc:hive2://localhost.localdomain:10000> select * from cust.customer;
+-----+-------------+------------+---------------+----------------+--------------+
| id | name_first | name_last | addr_country | date_of_birth | phone_num |
+-----+-------------+------------+---------------+----------------+--------------+
| 5 | Audrey | Taylor | UK | 1985-01-11 | 12-3456-7890 |
| 6 | Ruford | Walker | UK | 1976-05-19 | 23-4567-8901 |
| 7 | Marta | Lloyd | UK | 1981-07-23 | 34-5678-9012 |
+-----+-------------+------------+---------------+----------------+--------------+
|
- 数据脱敏:比如只保留用户的后4位手机号,可以作如下配置:
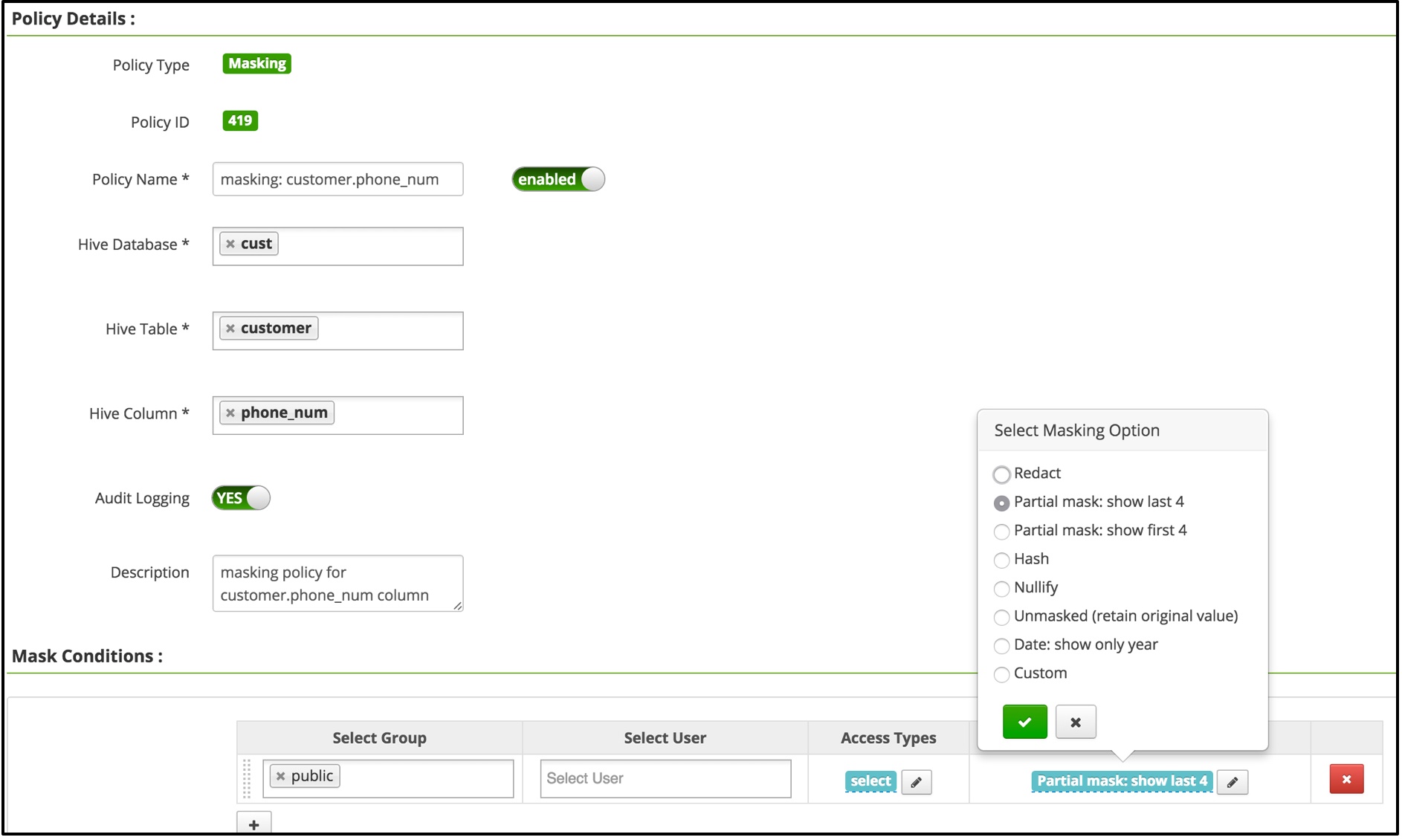
效果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| [john@localhost ~]# beeline -u jdbc:hive2://localhost.localdomain:10000/cust
0: jdbc:hive2://localhost.localdomain:10000> select * from cust.customer;
+-----+-------------+------------+---------------+----------------+--------------+
| id | name_first | name_last | addr_country | date_of_birth | phone_num |
+-----+-------------+------------+---------------+----------------+--------------+
| 1 | Mackenzy | Smith | US | 1993-12-18 | xxx-xxx-7890 |
| 2 | Sherlyn | Miller | US | 1975-03-22 | xxx-xxx-8901 |
| 3 | Khiana | Wilson | US | 1989-08-14 | xxx-xxx-9012 |
| 4 | Jack | Thompson | US | 1962-10-28 | xxx-xxx-0123 |
| 11 | Felix | Lee | CA | 1982-04-17 | xxx-xxx-0987 |
| 12 | Adam | Brown | CA | 1995-09-07 | xxx-xxx-1098 |
| 13 | Lucas | Jones | CA | 1999-02-06 | xxx-xxx-2109 |
+-----+-------------+------------+---------------+----------------+--------------+
|
- 对字段进行控制:隐藏掉某个字段(将客户名称name_last隐藏)。可以在web界面作如下配置
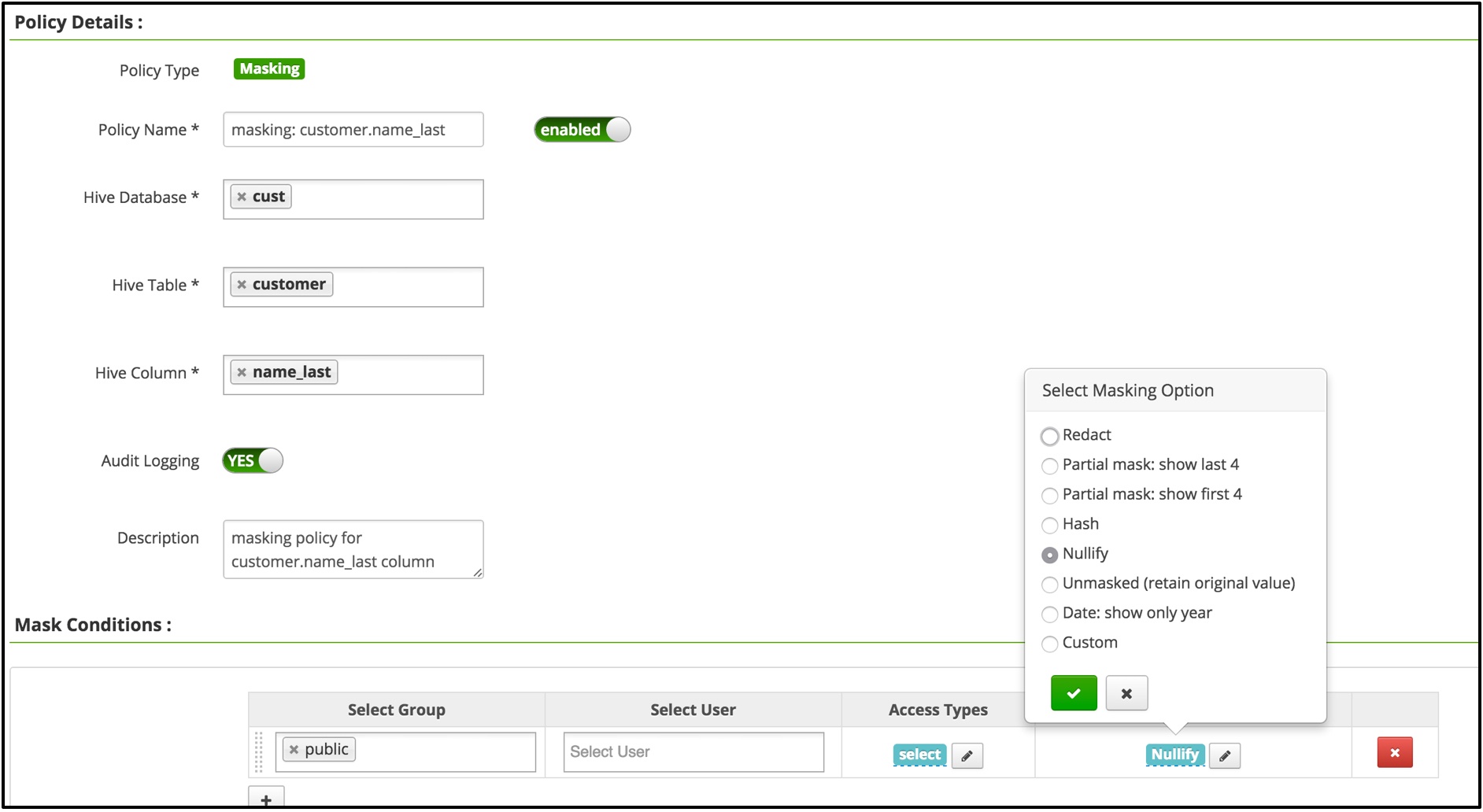
查询结果如下
1
2
3
4
5
6
7
8
9
10
11
12
13
| [john@localhost ~]# beeline -u jdbc:hive2://localhost.localdomain:10000/cust
0: jdbc:hive2://localhost.localdomain:10000> select * from cust.customer;
+-----+-------------+------------+---------------+----------------+--------------+
| id | name_first | name_last | addr_country | date_of_birth | phone_num |
+-----+-------------+------------+---------------+----------------+--------------+
| 1 | Mackenzy | NULL | US | 1993-01-01 | xxx-xxx-7890 |
| 2 | Sherlyn | NULL | US | 1975-01-01 | xxx-xxx-8901 |
| 3 | Khiana | NULL | US | 1989-01-01 | xxx-xxx-9012 |
| 4 | Jack | NULL | US | 1962-01-01 | xxx-xxx-0123 |
| 11 | Felix | NULL | CA | 1982-01-01 | xxx-xxx-0987 |
| 12 | Adam | NULL | CA | 1995-01-01 | xxx-xxx-1098 |
| 13 | Lucas | NULL | CA | 1999-01-01 | xxx-xxx-2109 |
+-----+-------------+------------+---------------+----------------+--------------+
|
通过的Policy策略还有许多灵活的特性,包括它还能支持基于Tag的策略控制,有了Tag后,就无需考虑组件的差别了。另外还有condition的条件的添加控制,这些也都是由管理员用户人工控制的。
同样的,Ranger Plugin程序会拉取策略数据在本地,如果说Ranger admin server临时不可用了,也不会影响策略实际的执行认证。
总结及给出建议
- Sentry在于它对于Hive等相关组件支持集成的比较好(跟CDH同根同源)。
- 一般通过用户角色进行权限的控制,通常能控制在表级。
- Ranger在于它更通用化的支持和更加丰富的策略控制。
总结:Apache Ranger提供了Apache Sentry在CDH中提供的所有功能。Ranger是一个全面的解决方案。它还提供了额外的安全功能,如数据过滤和屏蔽,增强了数据安全策略。

 微信
微信 支付宝
支付宝