特殊文件的读取
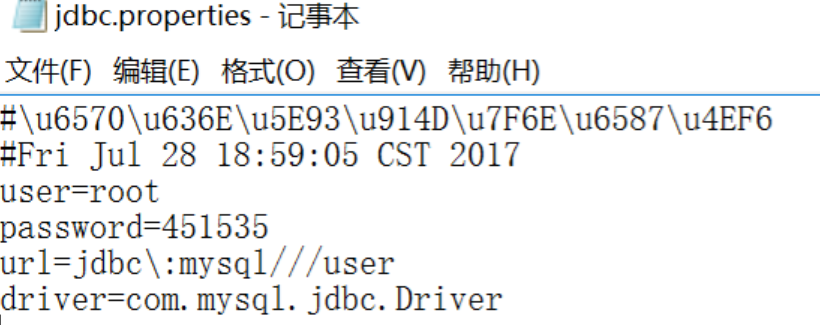
properties
Properties 是代表属性的意思,在Java中常常用这种后缀类型的文件作为配置文件。
配置文件出来了,那必然是需要我们去读取的,如果用字符流读取可以但是没必要,用读取properties常用的方法往往无往而不利。
概述
类似于:


参考代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public class myProperties {
public static void main(String[] args) throws Exception {
Properties p = new Properties();
p.setProperty("aa", "11");
p.setProperty("bb", "22");
p.setProperty("cc", "33");
System.out.println(p);
FileInputStream fr = new FileInputStream("C:\\Users\\admin\\Desktop\\opt\\Java\\day11\\files\\2.properties");
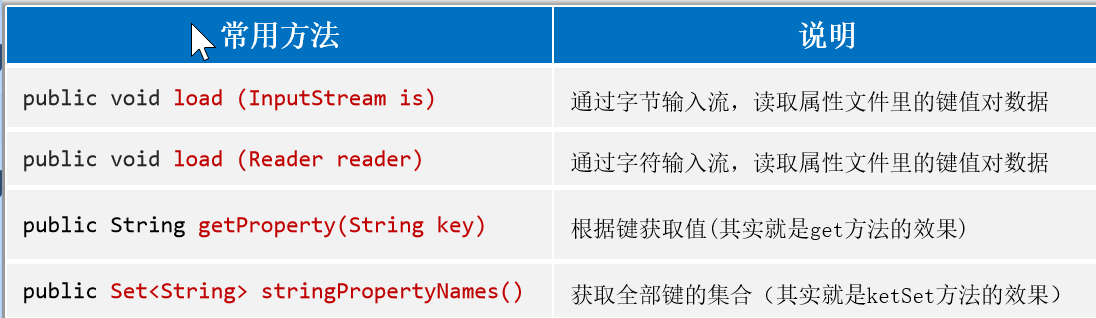
p.load(fr);
System.out.println(p);
System.out.println(p.getProperty("name"));
Set<String> set = p.stringPropertyNames();
for (String s : set) {
System.out.println(s + "---->" + p.getProperty(s));
}
}
}
|
xml
概述
是一门可扩展的标记语言;
作用
- 通过自定义的标记,存储或表示数据用的;通过开发中会使用xml文件当成系统的配置文件(存储着如何让程序运行的信息)使用;
语法
注释
1
2
| <!-- 注释 -->
如果有大量的转义字符,可以使用 CDATA区存;
|
xml文件演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| <?xml version="1.0" encoding="utf-8" ?>
<!-- 这是注释 -->
<abcd>
<aaa>
<b>
</b>
<b name ="嘿嘿">
<为所欲为 >
</b>
<![CDATA[
<水浒传>
<红楼梦>
<<<
>>>
'
""
]]>
<bbb id="345" />
</aaa>
<b>
</b>
</abcd>
|
xml解析
利用dom4j工具完成;
使用步骤
参考代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| <?xml version="1.0" encoding="utf-8" ?>
<!-- 这是注释 -->
<stus>
<student id="1">
<name>张三</name>
<age>18</age>
</student>
<student id="2">
<name>李四</name>
<age>19</age>
</student>
</stus>
public class xmlParse {
public static void main(String[] args) throws Exception {
SAXReader reader = new SAXReader();
Document d = reader.read("C:\\Users\\admin\\Desktop\\opt\\Java\\day11\\files\\stu.xml");
Element root = d.getRootElement();
List<Element> stus = root.elements();
for (Element stu : stus) {
String id = stu.attribute("id").getValue();
System.out.println("id" + id);
List<Element> prop = stu.elements();
for (Element name_age : prop) {
String text = name_age.getText();
String name = name_age.getName();
System.out.println(name + "标签下的内容是" + text);
}
}
}
}
|
约束
概述
定义:可以对xml文件的内容进行限制的技术;
作用
- dtd文件,可以对xml文件的内容进行粗粒度的限制;
- xsd文件可以对xml文件的内容进行细粒度的限制;
分类
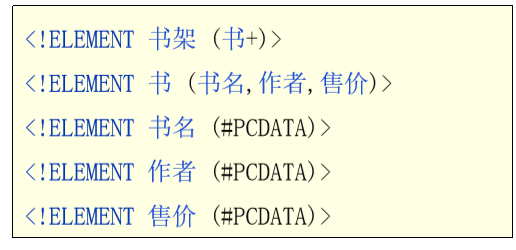
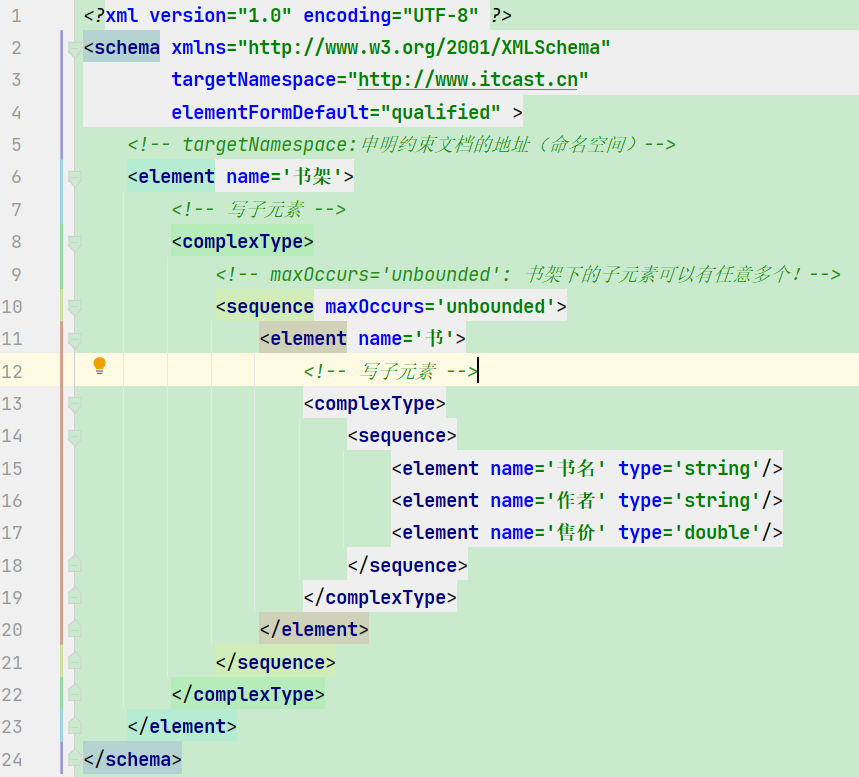
dtd约束,老的约束,粒度粗;
schema约束,新的约束技术,粒度细致;
语法
xml和约束文件的引入方式
dtd引入:
1
| <!DOCTYPE 书架 SYSTEM "data.dtd">
|
xsd引入:
1
2
3
| <书架 xmlns="http://www.itcast.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn data.xsd">
|
xml的内容,按照约束的提示写即可;

 微信
微信 支付宝
支付宝