深度学习和机器学习的区别
深度学习和机器学习-面试题(●’◡’●)
问:什么样的资料集不适合用深度学习?
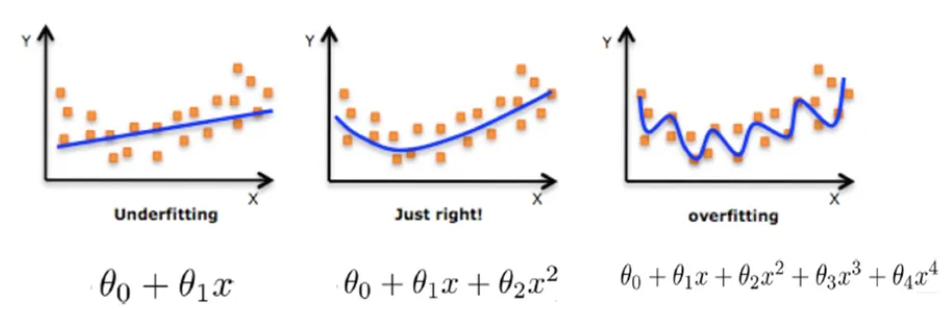
(1)数据集太⼩,数据样本不⾜时,深度学习相对其它机器学习算法,没有明显优势。
(2)数据集没有局部相关特性,⽬前深度学习表现⽐较好的领域主要是图像/语⾳/⾃然语⾔处理等领域,
这些领域的⼀个共性是局部相关性。图像中像素组成物体,语⾳信号中⾳位组合成单词,⽂本数据中单词
组合成句⼦,这些特征元素 的组合⼀旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的
数据集,不适于使⽤深度学习算法进⾏处 理。
深入理解机器学习和深度学习
深度学习与机器学习的差别
不需要人工特征工程
特征工程+分类/回归 使用一个网络来完成
优点
精确度高,性能好,效果好
拟合任意非线性的关系
框架多,不需我们自己造轮子
缺点
黑箱,可解释性差
网络参数多,超参数多
需要大量的数据进行训练,训练时间长,对算力有较高要求
小数据集容易过拟合
PyTorch深度学习框架 PyTorch是什么
PyTorch官网
PyTorch编程
验证自己的显卡是否为cuda核心(即是否能通过GPU进行计算加速):
1 2 3 4 5 6 import torchif torch.cuda.is_available(): print ("GPU可用,深度学习加速之旅开始!" ) else : print ("GPU不可用,将使用CPU进行计算。" )
PyTorch⾥怎么从CPU迁移到GPU? 检查是否有可⽤的GPU设备:
使⽤torch.cuda.is_available()函数检查系统是否具有可⽤的GPU设备。如果返回True,表示有可⽤的GPU。
将模型参数迁移到GPU:
将输⼊数据迁移到GPU:
迁移数据:inputs.to(device), labels.to(device)
迁移张量:tensor_gpu = tensor_cpu.to(device)
基础张量操作 参考链接:
创建张量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 创建张量: torch.tensor(data, datatype)创建张量 最常用 可以根据已有数据创建张量(默认使用原有数据类型) torch.Tensor(data, size=())创建张量 主要是根据形状创建张量 torch.DoubleTensor(data) 主要是创建指定类型的张量(Tensor指定类型创建张量) torch.linspace(start, end, number) 主要是创建线性张量 torch.arange(start, end, step) 创建线性张量 torch.randn(shape()) 创建0-1之间的随机张量 torch.randint(start, end, shape()) 创建随机整型张量 torch.zeros(size) 创建指定类型的全为0的张量 torch.zeros_like(data) torch.ones(size) 创建指定类型的全为1的张量 torch.ones_like(data) torch.full(size) 创建指定值的张量 torch.full_like(data) 张量类型转换: data = data.type(torch.DoubleTensor) data.double()
torch.tensor() : 将数据创建为张量(推荐使用)
方法
数据类型控制
内存行为
推荐场景
是否推荐使用
torch.tensor(data)自动推断 或显式指定总是拷贝数据
从Python数据创建张量
✅ 首选
torch.Tensor(data)默认torch.float32
可能共享内存
旧代码兼容/未初始化张量
⚠️ 慎用
torch.IntTensor()强制torch.int32
类似torch.Tensor
需要明确整数类型
❌ 已过时
张量和numpy互转 1 2 3 4 5 6 7 tensor 和 numpy的互转 张量转numpy: data.numpy()函数,将张量转化为numpy数组,两者共享内存,一个变化,另外一个也发生变化 如果不想让两者共享内存,可以使用copy()进行拷贝 numpy转张量: torch.from_numpy(ndarray)共享内存 torch.tensor(ndarray) - 不共享内存
1 2 3 4 5 6 7 def tensor_numpy (): data_tensor = torch.tensor([2 , 3 , 4 ]) data_numpy = data_tensor.numpy() data_tensor[0 ] = 100 data_numpy[0 ] = 200 print (data_tensor) print (data_numpy)
张量运算
哈达玛积:对应位置的元素进行相乘
data1.mul(data2)
data1 * data2
点积运算: 按照矩阵的运算规则进行运算
data1 @ data2
torch.matmul(data1, data2)
1 2 3 4 5 6 7 8 9 10 11 x = torch.tensor([1. , 2. , 3. ]) y = torch.tensor([4. , 5. , 6. ]) add = x + y dot = torch.dot(x, y) mat1 = torch.randn(2 , 3 ) mat2 = torch.randn(3 , 2 ) result = torch.mm(mat1, mat2)
自动求导机制 参考链接:
1 2 3 4 5 6 x = torch.tensor(2.0 , requires_grad=True ) y = x**2 + 3 *x + 1 y.backward() print (x.grad)
参考代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 import torchimport numpy as pddef grad_compute (): """ 标量、向量、多标量、多向量的梯度计算 :return: None """ x = torch.tensor(10 , requires_grad=True , dtype=torch.float64) print (x.shape) f = x ** 2 + 20 f.backward() print (x.grad) x = torch.tensor([10 , 20 , 30 , 40 ], requires_grad=True , dtype=torch.float64) y1 = x ** 2 + 20 y2 = y1.mean() y2.backward() print (x.grad) x1 = torch.tensor(10 , requires_grad=True , dtype=torch.float64) x2 = torch.tensor(20 , requires_grad=True , dtype=torch.float64) y = x1 ** 2 + x2 ** 2 + x1 * x2 y.backward() print (x1.grad) print (x2.grad) x1 = torch.tensor([10 , 20 ], requires_grad=True , dtype=torch.float64) x2 = torch.tensor([30 , 40 ], requires_grad=True , dtype=torch.float64) y = x1 ** 2 + x2 ** 2 + x1 * x2 y = y.sum () y.backward() print (x1.grad) print (x2.grad) def control_grad (): """ 模型训练需要进行梯度计算,但是训练完成后进入下一个阶段就不需要进行梯度计算了 由此需要控制 :return: None """ x = torch.tensor(10 , requires_grad=True , dtype=torch.float64) print (x.requires_grad) with torch.no_grad(): y = x ** 2 print (y.requires_grad) @torch.no_grad() def my_func (x ): return x ** 2 y = my_func(x) print (y.requires_grad) torch.set_grad_enabled(False ) y = x ** 2 print (y.requires_grad) def cum_grad_zero (): """ 累计梯度和梯度清零 :return: None """ x = torch.tensor([10 , 20 , 30 , 40 ], requires_grad=True , dtype=torch.float64) for _ in range (10 ): f1 = x ** 2 + 20 f2 = f1.mean() if x.grad is not None : x.grad.data.zero_() f2.backward() print (x.grad) def grad_optimize (): """ y = x**2 求x为何值时,y最小 又回到了抛物线过零点 :return: None """ x = torch.tensor(10 , requires_grad=True , dtype=torch.float64) for _ in range (5000 ): y = x ** 2 if x.grad is not None : x.grad.data.zero_() y.backward() x.data = x.data - 0.002 * x.grad print ('%.10f' % x.data) if __name__ == '__main__' : grad_optimize()
反向传播基础(反向更新权重) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def bp_grad_loop (): """ 反向传播更新权重w for循环 :return: None """ w = torch.tensor(10. , requires_grad=True , dtype=torch.float32) lr = 0.01 for epoch in range (100 ): if w.grad is not None : w.grad.zero_() loss = w ** 2 + 20 loss.backward() w.data -= lr * w.grad print (f"当前轮次{epoch} ,当前权重{w.data} ,更新后梯度{w.grad} ,下一个权重{w.data - lr * w.grad} " )
线性回归手动构建 参考链接:
参考代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 import numpy as npimport torchfrom sklearn.datasets import make_regression import randomimport matplotlib.pyplot as pltdef create_dataset (): """ # 构建数据集 :return: 数据集特征与标签 x y 权重coef """ x, y, coef = make_regression( n_samples=100 , n_features=1 , noise=10 , coef=True , bias=14.5 , random_state=0 ) x = torch.tensor(x) y = torch.tensor(y) return x, y, coef def data_loader (x, y, batch_size ): """ 构造数据加载器 按照一定数据量 分批次 产生数据 :return: 批次特征数据集 批次标签数据集 """ data_len = len (y) data_index = list (range (data_len)) random.shuffle(data_index) batch_number = data_len // batch_size for idx in range (batch_number): start = idx * batch_size end = start + batch_size batch_train_x = x[start: end] batch_train_y = y[start: end] yield batch_train_x, batch_train_y w = torch.tensor(0.1 , requires_grad=True , dtype=torch.float64) b = torch.tensor(0.0 , requires_grad=True , dtype=torch.float64) def linear_regression (x ): """ 构建假设函数 :return: wx + b 方程 """ return w * x + b def square_loss (y_pred, y_true ): """ 定义损失函数 采用MAS作为损失函数 :param y_pred: :param y_true: :return: (预测值 - 真实值)的平方 """ return (y_pred - y_true) ** 2 def sgd (lr=1e-2 ): """ 定义优化方法 采用随机梯度下降法 进行权重参数的更新 :param lr: :return: None """ w.data = w.data - lr * w.grad.data / 16 b.data = b.data - lr * b.grad.data / 16 def train (): """ 进行训练 :return: None """ x, y, coef = create_dataset() epochs = 100 learning_rate = 1e-2 epoch_loss = [] total_loss = 0.0 train_samples = 0 for _ in range (epochs): for train_x, train_y in data_loader(x, y, batch_size=16 ): y_pred = linear_regression(train_x) loss = square_loss(y_pred, train_y.reshape(-1 , 1 )).sum () total_loss += loss.item() train_samples += len (train_y) if w.grad is not None : w.grad.data.zero_() if b.grad is not None : b.grad.data.zero_() loss.backward() sgd(learning_rate) print ('loss: %.10f' % (total_loss / train_samples)) epoch_loss.append(total_loss / train_samples) plt.rcParams['font.sans-serif' ] = ['Arial Unicode MS' ] plt.rcParams['axes.unicode_minus' ] = False plt.scatter(x, y) x = torch.linspace(x.min (), x.max (), 1000 ) y1 = torch.tensor([v * w + b for v in x]) y2 = torch.tensor([v * coef + 14.5 for v in x]) plt.plot(x, y1, label='训练' ) plt.plot(x, y2, label='真实' ) plt.grid() plt.legend() plt.show() plt.plot(range (epochs), epoch_loss) plt.grid() plt.title('损失变化曲线' ) plt.show() def test (): x, y, coef = create_dataset() plt.scatter(x, y) plt.show() for x, y in data_loader(x, y, batch_size=10 ): print (y) if __name__ == '__main__' : train()
线性回归PyTorch组件构建 参考链接:基本组件使用
损失函数:本质是封装了(y_pred - y_true)之间误差计算公式
构建全连接层/假设函数/模型:类似于y=wx + b
model = nn.Linear(in_features=1,out_features=1:意思只接收一维输入和一维输出
优化方法:类似于w.data -= lr*w.grad/batch_size
optimizer = optim.SGD(model.parameters(), lr=1e-2):model是全连接层参数,lr学习率
数据加载器:本质封装了分批加载、分批yield、批次:ceil(len(data) / batch_size)
x,y,coef = create_dataset()
dataset = TensorDataset(x, y)
dataloader = DataLoader(dataset, batchsize=16, shuffle=True)
训练模型:
外层循环控制轮次、内层循环控制批次模型训练:y_pred = model(x_train.float())
损失构建:loss = criterion (y_pred, y_train.reshape(-1, 1).float())
梯度自动清零:optimizer.zero_grad()`反向传播:loss.backward()
更新参数:optimizer.step()
绘制预测曲线、损失变化曲线:
预测曲线:y_predict = torch.tensor([v * model.weight + model.bias for v in x])
真实曲线:y_true = torch.tensor([v * coef + 14.5 for v in x])
损失变化曲线:
total_loss += loss.item() :提取单值张量epoch_loss.append(total_loss / train_samples)plt.plot(range(epochs), epoch_loss)
参考代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import torchfrom sklearn.datasets import make_regression import randomimport matplotlib.pyplot as pltfrom torch.utils.data import TensorDataset from torch.utils.data import DataLoader from torch import nnfrom torch import optimdef create_dataset (): x, y, coef = make_regression( n_samples=100 , n_features=1 , noise=10 , coef=True , bias=14.5 , random_state=0 ) x = torch.tensor(x) y = torch.tensor(y) return x, y, coef def train (): x, y, coef = create_dataset() dataset = TensorDataset(x, y) dataloader = DataLoader(dataset, batch_size=16 , shuffle=True ) model = nn.Linear(in_features=1 , out_features=1 ) criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=1e-2 ) epochs = 100 for _ in range (epochs): for x_train, y_train in dataloader: y_pred = model(x_train.float ()) loss = criterion(y_pred, y_train.reshape(-1 , 1 ).float ()) optimizer.zero_grad() loss.backward() optimizer.step() plt.scatter(x, y) x = torch.linspace(x.min (), x.max (), 1000 ) y1 = torch.tensor([v * model.weight + model.bias for v in x]) y2 = torch.tensor([v * coef + 14.5 for v in x]) plt.plot(x, y1, label='预测' ) plt.plot(x, y1, label='真实' ) plt.grid() plt.legend() plt.show() if __name__ == '__main__' : x, y, coef = create_dataset() print (coef) train()
参数初始化(权重、偏置) 参考链接:网络参数初始化
初始化参数目的 防止梯度消失或者梯度爆炸、提高收敛速度、打破对称性
参数初始化方式:
无法打破对称性
可以打破对称性
随机初始化、正态分布初始化、kaiming初始化、xavier初始化
总结kaiming初始化、xavier初始化、全0初始化比较重要
关于初始化选择
激活函数Relu系列:优先选择kaiming激活函数非Relu:优先选择xavier如果是浅层网络:可考虑使用随机初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import torchimport torch.nn.functional as Fimport torch.nn as nn""" 初始化的参数主要有权重和偏置,偏置参数一般初始化为 0 即可,而对权重的初始化则会更加重要 参数初始化的目的: 防止梯度消失或者梯度爆炸、提高收敛速度、打破对称性 初始化比较重要的 """ def uniform_init (): linear = nn.Linear(5 , 3 ) print (linear.weight) nn.init.uniform_(linear.weight) nn.init.uniform_(linear.bias) print (linear.weight) def const_value_init (): linear = nn.Linear(5 , 3 ) nn.init.constant_(linear.weight, 5 ) def zero_init (): linear = nn.Linear(5 , 3 ) nn.init.zeros_(linear.weight) nn.init.zeros_(linear.bias) print (linear.weight.data) def one_init (): linear = nn.Linear(5 , 3 ) nn.init.ones_(linear.weight) nn.init.ones_(linear.bias) def normalize_init (): linear = nn.Linear(5 , 3 ) nn.init.normal_(linear.weight, mean=0 , std=1 ) def kaiming_init (): linear = nn.Linear(5 , 3 ) nn.init.kaiming_normal_(linear.weight) print (linear.weight) linear = nn.Linear(5 , 3 ) nn.init.kaiming_uniform_(linear.weight) print (linear.weight) def xavier_init (): linear = nn.Linear(5 , 3 ) nn.init.xavier_normal_(linear.weight) print (linear.weight) linear = nn.Linear(5 , 3 ) nn.init.xavier_uniform_(linear.weight) print (linear.weight) if __name__ == '__main__' : uniform_init() kaiming_init() xavier_init()
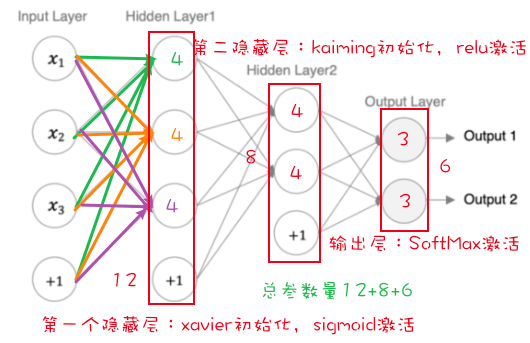
神经网络构建 参考链接:神经网络计算及参数计算
参考代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import numpy as npimport torchimport torch.nn as nnfrom torchsummary import summaryclass Model (nn.Module): def __init__ (self ): super ().__init__() self.linear1 = nn.Linear(3 , 3 ) nn.init.xavier_normal_(self.linear1.weight) self.linear2 = nn.Linear(3 , 2 ) nn.init.kaiming_normal_(self.linear2.weight) self.out = nn.Linear(2 , 2 ) def forward (self, x ): x = torch.sigmoid(self.linear1(x)) x = torch.relu(self.linear2(x)) x = torch.softmax(self.out(x), dim=-1 ) return x if __name__ == '__main__' : my_data = torch.randn(5 , 3 ).to("cpu" ) my_model = Model() print (my_data) y_pred = my_model(my_data) print (y_pred) print (my_data.shape, y_pred.shape) summary(my_model, input_size=(3 ,), batch_size=5 , device="cpu" ) for name, parameter in my_model.named_parameters(): print (name, parameter)
数据加载与处理 使用Dataset和DataLoader
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from torch.utils.data import Dataset, DataLoaderclass CustomDataset (Dataset ): def __init__ (self, data, labels ): self.data = data self.labels = labels def __len__ (self ): return len (self.labels) def __getitem__ (self, idx ): return self.data[idx], self.labels[idx] dataset = CustomDataset(train_data, train_labels) loader = DataLoader(dataset, batch_size=32 , shuffle=True )
GPU加速 1 2 3 4 5 6 7 device = torch.device("cuda" if torch.cuda.is_available() else "cpu" ) model = model.to(device) data = data.to(device) labels = labels.to(device)
模型保存与加载 参考链接:模型保存与加载
1 2 3 4 5 6 7 8 9 10 torch.save({ 'model_state_dict' : model.state_dict(), 'optimizer_state_dict' : optimizer.state_dict(), }, 'model.pth' ) checkpoint = torch.load('model.pth' ) model.load_state_dict(checkpoint['model_state_dict' ]) optimizer.load_state_dict(checkpoint['optimizer_state_dict' ])
参考代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import torchimport torch.nn as nnimport picklefrom torch import optimclass Model (nn.Module): def __init__ (self, input_size, output_size ): super ().__init__() self.linear1 = nn.Linear(input_size, input_size * 2 ) self.linear2 = nn.Linear(input_size * 2 , output_size) def model_save (): model = Model(128 , 10 ) torch.save(model, 'test_model_save.pth' , pickle_module=pickle, pickle_protocol=2 ) def model_load (): model = torch.load('test_model_save.pth' , pickle_module=pickle, map_location='cpu' ) def mode_save_parameters (): model = Model(128 , 10 ) optimizer = optim.Adam(model.parameters(), lr=1e-2 ) save_params = { 'init_params' : {'input_size' : 128 , 'output_size' : 10 }, 'acc_score' : 0.98 , 'avg_loss' : 0.86 , 'iter_num' : 100 , 'optim_params' : optimizer.state_dict(), 'model_params' : model.state_dict() } torch.save(save_params, './model_param.pth' ) def model_load_parameters (): model_params = torch.load('model/model_params.pth' ) model = Model(model_params['init_params' ]['input_size' ], model_params['init_params' ]['output_size' ]) model.load_state_dict(model_params['model_params' ]) optimizer = optim.Adam(model.parameters()) optimizer.load_state_dict(model_params['optim_params' ]) print ('迭代次数:' , model_params['iter_num' ]) print ('准确率:' , model_params['acc_score' ]) print ('平均损失:' , model_params['avg_loss' ]) if __name__ == '__main__' : pass
实用工具函数
函数
用途
示例
torch.cat
张量拼接
torch.cat([a, b], dim=0)
torch.stack
新建维度堆叠
torch.stack([a, b], dim=1)
torch.where
条件选择
torch.where(x>0, x, torch.zeros_like(x))
torch.unique
去重
torch.unique(x)
PyTorch代码实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 import torchimport numpy as npdef tensor_demo (): """ 创建张量: torch.tensor(data, datatype)创建张量 最常用 可以根据已有数据创建张量(默认使用原有数据类型) torch.Tensor(data, size=())创建张量 主要是根据形状创建张量 torch.DoubleTensor(data) 主要是创建指定类型的张量(Tensor指定类型创建张量) torch.linspace(start, end, number) 主要是创建线性张量 torch.arange(start, end, step) 创建线性张量 torch.randn(shape()) 创建0-1之间的随机张量 torch.randint(start, end, shape()) 创建随机整型张量 torch.zeros(size) 创建指定类型的全为0的张量 torch.zeros_like(data) torch.ones(size) 创建指定类型的全为1的张量 torch.ones_like(data) torch.full(size) 创建指定值的张量 torch.full_like(data) 张量类型转换: data = data.type(torch.DoubleTensor) data.double() :return: None """ data = torch.tensor(10 ) print (data) data = np.random.randn(2 , 3 ) data = torch.tensor(data) print (data) def tensor_numpy (): """ tensor 和 numpy的互转 张量转numpy: data.numpy()函数,将张量转化为numpy数组,两者共享内存,一个变化,另外一个也发生变化 如果不想让两者共享内存,可以使用copy()进行拷贝 numpy转张量: torch.from_numpy(ndarray)共享内存 torch.tensor(ndarray) - 不共享内存 :return: None """ data_tensor = torch.tensor([2 , 3 , 4 ]) data_numpy = data_tensor.numpy() data_tensor[0 ] = 100 data_numpy[0 ] = 200 print (data_tensor) print (data_numpy) data_tensor = torch.tensor([2 , 3 , 4 ]) data_numpy = data_tensor.numpy().copy() data_numpy = np.array([2 , 3 , 4 ]) data_tensor = torch.tensor(data_numpy) data_tensor[0 ] = 100 def tensor_extract (): """ 提取单值张量 单值张量虽然只有一个值,但是仍然为张量类型 :return: None """ t1 = torch.tensor(30 ) t2 = torch.tensor([30 ]) t3 = torch.tensor([[30 ]]) print (t1.shape) print (t2.shape) print (t3.shape) print (t1.item()) print (t2.item()) print (t3.item()) def concat_tensor (): """ 张量的拼接 :return: None """ torch.manual_seed(0 ) data1 = torch.randint(0 , 10 , [3 , 4 , 5 ]) data2 = torch.randint(0 , 10 , [3 , 4 , 5 ]) print (data1.shape) print (data2.shape) new_data = torch.cat([data1, data2], dim=0 ) print (new_data.shape) new_data = torch.cat([data1, data2], dim=1 ) print (new_data.shape) new_data = torch.cat([data1, data2], dim=2 ) print (new_data.shape) def stack_tensor (): """ 按照一定维度 从两个张量中各自取一个元素 组合成新的元素 形成新的张量 :return: None """ torch.manual_seed(0 ) data1 = torch.randint(0 , 10 , [2 , 3 ]) print (data1) print ('-' * 30 ) data2 = torch.randint(0 , 10 , [2 , 3 ]) print (data2) print ('-' * 30 ) new_data = torch.stack([data1, data2], dim=0 ) print (new_data) new_data = torch.stack([data1, data2], dim=1 ) print (new_data.shape) print (new_data) new_data = torch.stack([data1, data2], dim=2 ) print (new_data.shape) print (new_data) def tensor_shape (): """ 张量的形状操作 data.reshape()会重新计算张量的维度 -1代表自动匹配行数/列数 data.reshape(-1, 2) torch.transpose(data, (shape)) 每次只会交换两个维度 torch.permute(data, (shape)) 可以一次交换多个维度 view() 函数改变张量形状: 1. 一个张量经过了transpose或者permute函数处理 无法使用view进行形状操作 2. 且view只能处理存在于内存中的整块连续张量 不在内存中或者不连续均不能处理 解决:先contiguous将非连续内存转换为连续内存,再用view函数更改张量形状 squeeze函数可以将维度为1的维度进行删除 unsqueeze函数给张量增加维度为1的维度 :return: None """ torch.manual_seed(1 ) data = torch.randint(0 , 10 , [3 , 4 , 5 ]) new_data = data.reshape(4 , 3 , 5 ) print (new_data.shape) new_data = torch.transpose(data, 0 , 1 ) print (new_data.shape) new_data = torch.transpose(data, 0 , 1 ) new_data = torch.transpose(new_data, 1 , 2 ) print (new_data.shape) new_data = torch.permute(torch.randint(0 , 10 , [3 , 4 , 5 ]), [1 , 2 , 0 ]) print (new_data.shape) data = torch.tensor([[10 , 20 , 30 ], [40 , 50 , 60 ]]) data = data.view(3 , 2 ) print (data.shape) print (data.is_contiguous()) data = torch.transpose(data, 0 , 1 ) print (data.is_contiguous()) data = data.contiguous().view(2 , 3 ) print (data) data = torch.randint(0 , 10 , [1 , 3 , 1 , 5 ]) new_data = data.squeeze() print (new_data.shape) new_data = data.unsqueeze(-1 ) print (new_data.shape) def tensor_func (): """ 张量常用的函数: data.mean() 求均值 data.sum() 求和 data.pow(n) 平方 data.sqrt() 平方根 data.exp() e的多少次方 data.log() 以e为底对数 data.log2() 以2为底对数 data.log10()以10为底对数 :return: None """ torch.manual_seed(0 ) data = torch.randint(0 , 10 , [2 , 3 ]).double() print (data.mean()) print (data.mean(dim=0 )) print (data.mean(dim=1 )) print (data.sum ()) print (data.sum (dim=0 )) print (data.sum (dim=1 )) print (data.pow (2 )) print (data.sqrt()) print (data.exp()) print (data.log()) print (data.log2()) print (data.log10()) def tensor_index (): """ 张量的索引操作: 需要掌握范围索引 行列索引 多维索引 :return: None """ torch.manual_seed(0 ) data = torch.randint(0 , 10 , [4 , 5 ]) print (data[:]) print (data[:, 2 ]) print (data[[1 , 2 ], [1 , 2 ]]) print (data > 3 ) print (data[data > 3 ]) print (data[:, 1 ] > 6 ) print (data[data[:, 1 ] > 6 ]) print (data[:, data[1 ] > 3 ]) print ('-' * 30 ) data = torch.randint(0 , 10 , [3 , 4 , 5 ]) print (data) print (data[0 , :, :]) print (data[:, 0 , :]) print (data[:, :, 0 ]) if __name__ == '__main__' : tensor_index()
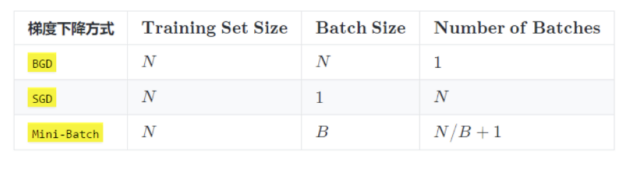
PyTorch梯度下降优化 梯度下降算法
设置数据集和BatchSize:
假设数据集有 50000 个训练样本,现在选择 Batch Size = 256 对模型进行训练。
每个 Epoch 要训练的图片数量:50000
训练集具有的 Batch 个数:50000/256+1=196
每个 Epoch 具有的 Iteration 个数:196
10个 Epoch 具有的 Iteration 个数:1960
梯度下降优化算法
传统的梯度下降优化算法中,可能会碰到:
平缓区域梯度值较小,参数优化变慢;
“鞍点”,梯度为 0,参数无法优化;
局部最小值
参考链接:梯度下降优化
指数加权平均 说白了就是明天气温怎么样,和昨天气温有很大关系,而和一个月前的气温关系就小一些。
$S_t$ 表示指数加权平均值
$Y_t$ 表示 t 时刻(当前)的值
$β $调节权重系数,该值越大平均数越平缓。
参考代码
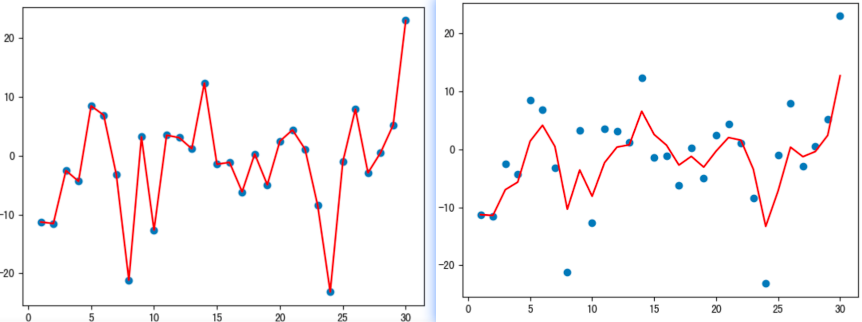
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import torchimport matplotlib.pyplot as pltELEMENT_NUMBER = 30 def test01 (): torch.manual_seed(0 ) temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10 print (temperature) days = torch.arange(1 , ELEMENT_NUMBER + 1 , 1 ) plt.plot(days, temperature, color='r' ) plt.scatter(days, temperature) plt.show() def test02 (beta=0.9 ): torch.manual_seed(0 ) temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10 print (temperature) exp_weight_avg = [] for idx, temp in enumerate (temperature, 1 ): if idx == 1 : exp_weight_avg.append(temp) continue new_temp = exp_weight_avg[idx - 2 ] * beta + (1 - beta) * temp exp_weight_avg.append(new_temp) days = torch.arange(1 , ELEMENT_NUMBER + 1 , 1 ) plt.plot(days, exp_weight_avg, color='r' ) plt.scatter(days, temperature) plt.show() if __name__ == '__main__' : test01() test02(0.5 ) test02(0.9 )
图中折线曲线以及$\beta$为0.5时的曲线
Momentum $$
变量说明:
$S_{t-1}$ 表示历史梯度移动加权平均值
$D_t$ 表示当前时刻的梯度值
$\beta$ 为权重系数(取值范围通常为 0.9~0.99)
Momentum 优化方法一定程度上可以克服 “平缓”、”鞍点”、”峡谷”
当处于鞍点位置时,由于当前的梯度为 0,参数无法更新。但是Momentum 动量梯度下降算法已经在先前积累了一些梯度值,很有可能使得跨过鞍点。
由于 mini-batch 普通的梯度下降算法,每次选取少数的样本梯度确定前进方向,可能会出现震荡,使得训练时间变长。Momentum 使用移动加权平均,平滑了梯度的变化,使得前进方向更加平缓,有利于加快训练过程。一定程度上有利于降低 “峡谷” 问题的影响。
峡谷问题:就是会使得参数更新出现剧烈震荡.
Momentum 算法可以理解为是对梯度值的一种调整,我们知道梯度下降算法中还有一个很重要的学习率,Momentum 并没有学习率进行优化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import torchdef test01 (): w = torch.tensor([1.0 ], requires_grad=True , dtype=torch.float32) y = ((w ** 2 ) / 2.0 ).sum () optimizer = torch.optim.SGD([w], lr=0.01 , momentum=0.9 ) optimizer.zero_grad() y.backward() optimizer.step() print ('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) y = ((w ** 2 ) / 2.0 ).sum () optimizer.zero_grad() y.backward() optimizer.step() print ('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) if __name__ == '__main__' : test01()
AdaGrad AdaGrad 通过对不同的参数分量使用不同的学习率,AdaGrad 的学习率总体会逐渐减小
AdaGrad 思想:在起初时,我们距离最优目标仍较远,可以使用较大的学习率,加快训练速度,随着迭代次数的增加,学习率逐渐下降。
初始化学习率 $α$、初始化参数 $θ$、小常数 $σ = 1e-6$
初始化梯度累积变量 $s = 0$
从训练集中采样$ m$ 个样本的小批量,计算梯度 $g$
累积平方梯度 $s = s + g ⊙ g$,$⊙$ 表示各个分量相乘
学习率 α 的计算公式如下:
参数更新公式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def test02 (): w = torch.tensor([1.0 ], requires_grad=True , dtype=torch.float32) y = ((w ** 2 ) / 2.0 ).sum () optimizer = torch.optim.Adagrad ([w], lr=0.01 ) optimizer.zero_grad() y.backward() optimizer.step() print ('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) y = ((w ** 2 ) / 2.0 ).sum () optimizer.zero_grad() y.backward() optimizer.step() print ('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
RMSProp RMSProp 优化算法是对 AdaGrad 的优化.
最主要的不同是,其使用指数移动加权平均梯度替换历史梯度的平方和。其计算过程如下:
初始化学习率 $α$、初始化参数$ θ$、小常数 $σ = 1e-6$、初始化梯度累计变量 s
从训练集中采样 m 个样本的小批量,计算梯度 g
使用指数移动平均累积历史梯度,公式如下:
参数更新公式如下:
RMSProp 与 AdaGrad 最大的区别是对梯度的累积方式不同,对于每个梯度分量仍然使用不同的学习率。
RMSProp 通过引入衰减系数 β,控制历史梯度对历史梯度信息获取的多少. 被证明在神经网络非凸条件下的优化更好,学习率衰减更加合理一些。
需要注意的是:AdaGrad 和 RMSProp 都是对于不同的参数分量使用不同的学习率,如果某个参数分量的梯度值较大,则对应的学习率就会较小,如果某个参数分量的梯度较小,则对应的学习率就会较大一些
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def test03 (): w = torch.tensor([1.0 ], requires_grad=True , dtype=torch.float32) y = ((w ** 2 ) / 2.0 ).sum () optimizer = torch.optim.RMSprop([w], lr=0.01 ,alpha=0.9 ) optimizer.zero_grad() y.backward() optimizer.step() print ('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) y = ((w ** 2 ) / 2.0 ).sum () optimizer.zero_grad() y.backward() optimizer.step() print ('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
Adam Momentum 使用指数加权平均计算当前的梯度值
AdaGrad、RMSProp 使用自适应的学习率
Adam 结合了 Momentum、RMSProp 的优点
使用:指数加权平均的梯度和指数加权平均的学习率。使得能够自适应学习率的同时,也能够使用 Momentum 的优点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def test04 (): w = torch.tensor([1.0 ], requires_grad=True ) y = ((w ** 2 ) / 2.0 ).sum () optimizer = torch.optim.Adam([w], lr=0.01 ,betas=[0.9 ,0.99 ]) optimizer.zero_grad() y.backward() optimizer.step() print ('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy())) y = ((w ** 2 ) / 2.0 ).sum () optimizer.zero_grad() y.backward() optimizer.step() print ('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
损失函数
之前在机器学习阶段接触过损失函数,但是用的是Sklearn,但这里使用的是PyTorch,API不同。。。传送门
参考链接:
分类问题损失函数 多分类问题
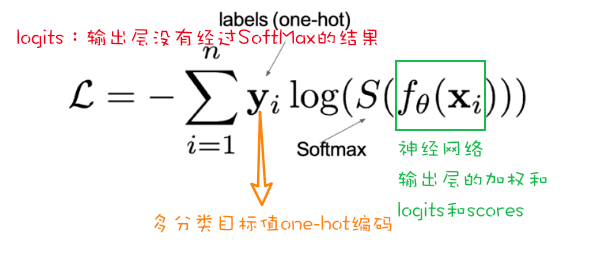
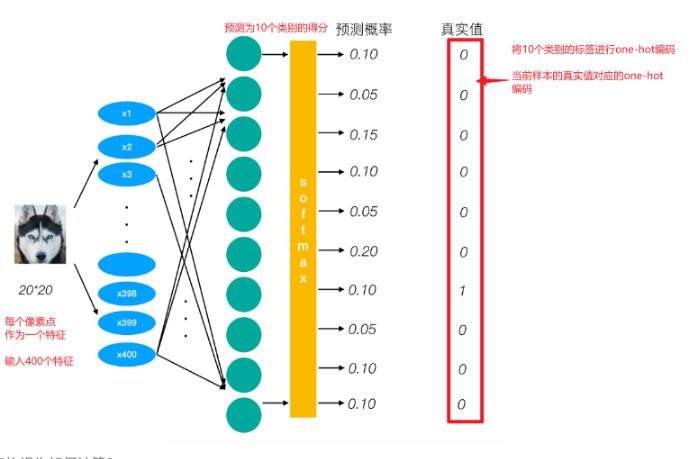
交叉熵损失函数
交叉熵损失函数计算方式
损失计算:
1 2 3 0log(0.10)+0log(0.05)+0log(0.15)+0log(0.10)+0log(0.05)+0log(0.20) +1log(0.10) +0log(0.05)+0log(0.10)+0log(0.10)
神经元输出对于不同分类的预测结果,经过SoftMax之后,将预测结果转换为预测不同类别的概率值。
经过SoftMax之后,对于不同类别的预测结果的加和为1,也就是对于正确类别的预测概率越高,预测为错误类别的概率越小
所以SoftMax之后,正样本的预测概率越大,损失越小。
二分类问题
处理二分类任务时,使用sigmoid激活函数,损失函数使用二分类的交叉熵损失函数
当真实标签 $y = 1$ 时
公式简化为:$L = -\log \hat{y}$
优化目标:推动预测概率 $\hat{y} \rightarrow 1$(接近真实值)
极端情况:若 $\hat{y} \rightarrow 0$,损失 $L \rightarrow +\infty$(对错误预测施加严重惩罚)
当真实标签 $y = 0$ 时
公式简化为:$L = -\log(1 - \hat{y})$
优化目标:推动预测概率 $\hat{y} \rightarrow 0$
极端情况:若 $\hat{y} \rightarrow 1$,损失 $L \rightarrow +\infty$
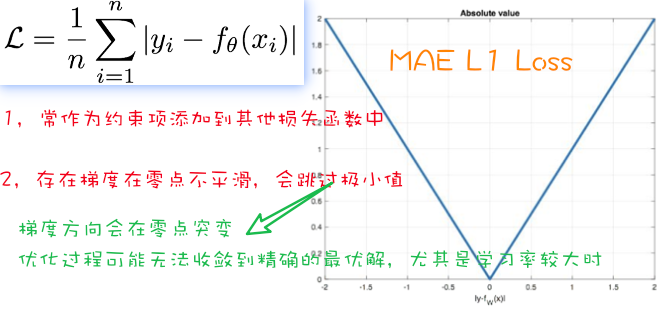
回归问题损失函数 MAE
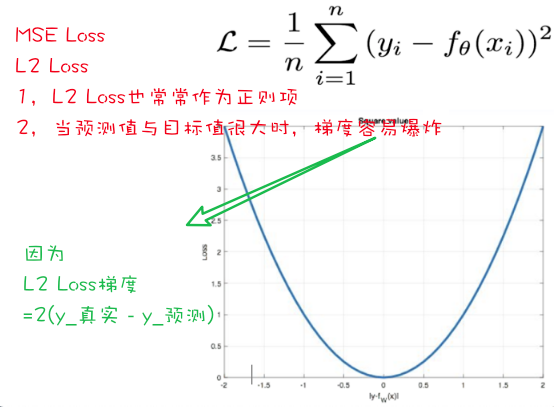
MSE
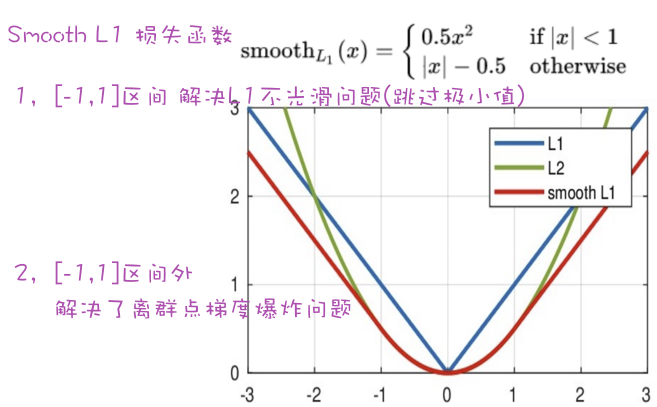
Smooth
参考代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import pandasimport torchimport torch.nn as nnimport numpy as npimport pandas as pddef crossEntropyLoss (): y_true = torch.tensor([1 , 2 ], dtype=torch.int64) y_pred = torch.tensor([[0.2 , 0.6 , 0.3 ], [0.1 , 0.8 , 0.1 ]], dtype=torch.float32) criterion = nn.CrossEntropyLoss() print (y_true) loss = criterion(y_pred, y_true) print ('交叉熵损失:' , loss) def bceLoss (): y_pred = torch.tensor([0.6901 , 0.5459 , 0.2469 ], requires_grad=True ) y_true = torch.tensor([0 , 1 , 0 ], dtype=torch.float32) criterion = nn.BCELoss() my_loss = criterion(y_pred, y_true).detach().numpy() print ('loss:' , my_loss) def MAE_Loss (): y_pred = torch.tensor([1.0 , 1.0 , 1.9 ], requires_grad=True ) y_true = torch.tensor([2.0 , 2.0 , 2.0 ], dtype=torch.float32) criterion = nn.L1Loss() loss = criterion(y_pred, y_true).detach().numpy() print (loss) def MSE_Loss (): y_pred = torch.tensor([1.0 , 1.0 , 1.9 ], requires_grad=True ) y_true = torch.tensor([2.0 , 2.0 , 2.0 ], dtype=torch.float32) criterion = nn.MSELoss() loss = criterion(y_pred, y_true).detach().numpy() print (loss) def Smooth_Loss (): y_true = torch.tensor([0 , 3 ]) y_pred = torch.tensor([0.6 , 0.4 ], requires_grad=True ) criterion = nn.SmoothL1Loss() loss = criterion(y_pred, y_true).detach().numpy() if __name__ == '__main__' : crossEntropyLoss() bceLoss() MAE_Loss() MSE_Loss() Smooth_Loss()
神经网络基础 神经网络
神经网络通过调整权值参数学习输入输出关系,逐步从简单线性变换扩展到复杂非线性建模。
简单来说:单层神经元经过激活函数能产生0和1,但是我们的计算机不就是基于0/1编码吗?于是乎多个单层神经元加上可学习的参数调整(每个神经元连接线的权值,这些权值是通过模型学习获得的)可以做的事情就很多了,比如图像识别、语音识别、文本挖掘等。
参考:
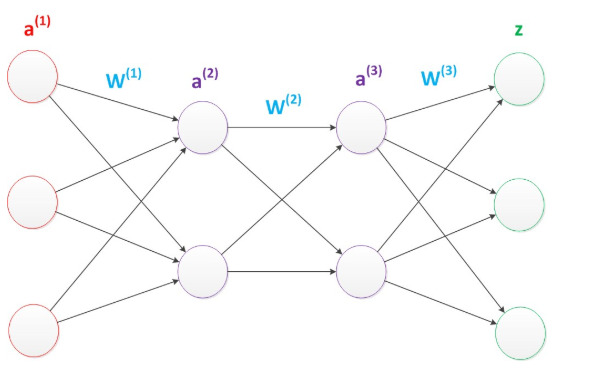
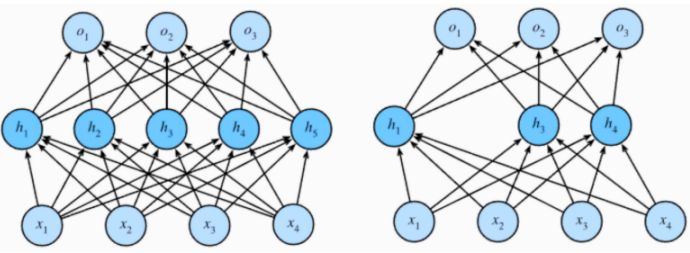
设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
神经网络结构图中的拓扑与箭头代表着预测 过程时数据的流向,跟训练 时的数据流有一定的区别;
结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重 (其值称为权值 ),这是需要训练得到的。
激活函数-面试题(*╹▽╹*)
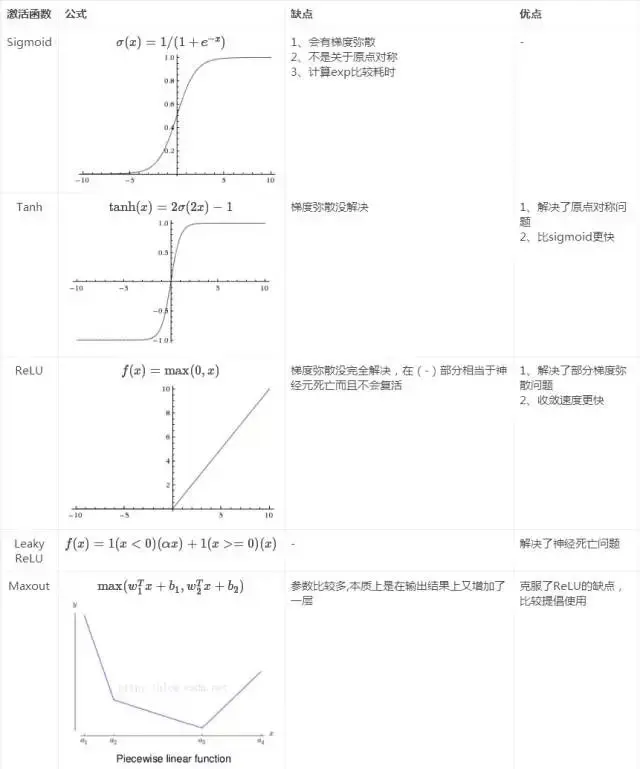
Sigmoid、Tanh、ReLu这三个激活函数有什么缺点或不⾜
答:
在𝑧的区间变动很大的情况下,激活函数的导数或者激活函数的斜率都会远大于0,在程序实现就是一个 if-else 语句,而 sigmoid 函数需要进行浮点四则运算,在实践中,使用 ReLu 激活函数神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快。
sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,而 Relu 和 Leaky ReLu 函数大于 0 部分都为常数,不会产生梯度弥散现象。(同时应该注意到的是,Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性,而 Leaky ReLu 不会有这问题) 𝑧在 ReLu 的梯度一半都是 0,但是,有足够的隐藏层使得 z 值大于 0,所以对大多数的 训练数据来说学习过程仍然可以很快。
请问人工神经网络中为什么ReLu要好过于tanh和sigmoid ?
答:
采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),这种现象称为饱和,从而无法完成深层网络的训练。而ReLU就不会有饱和倾向,不会有特别小的梯度出现。
Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。
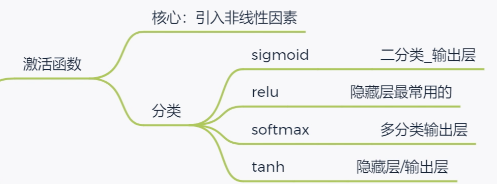
激活函数有哪些性质?
非线性: 当激活函数是线性的,一个两层的神经网络就可以基本上逼近所有的函数。但如果激活函数是恒等激活函数的时候,即$f(x) = x$,就不满足这个性质,而且如果 MLP 使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的;
可微性: 当优化方法是基于梯度的时候,就体现了该性质;
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数;
$f(x)\approx x$当激活函数满足这个性质的时候,如果参数的初始化是随机的较小值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要详细地去设置初始值;
输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的 Learning Rate。
激活函数的选择方法
对于隐藏层:
优先选择ReLU激活函数。如果ReLu效果不好,尝试Leaky ReLu等。
如果使用ReLU, 需注意Dead ReLU问题,某些神经元的权重更新后,如果输入的是负区间或者0,其输出永远为0,也就是神经元死亡。
少用使用sigmoid激活函数,存在梯度消失问题(5次求导内)
可以尝试使用tanh激活函数
对于输出层:
二分类问题选择sigmoid激活函数
多分类问题选择softmax激活函数
回归问题选择identity激活函数
激活函数总结
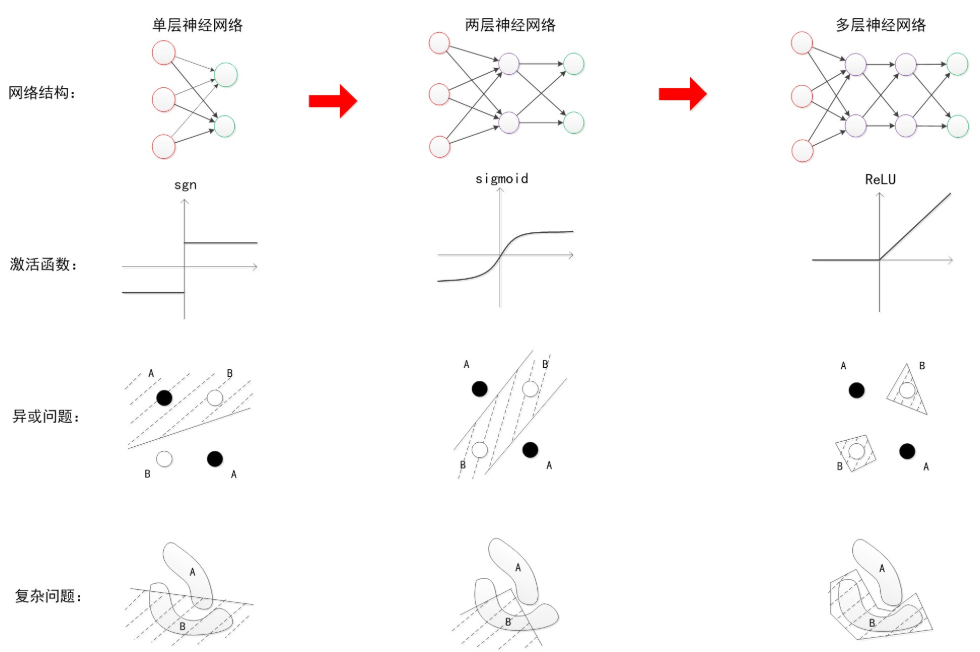
在单层神经网络时,使用的激活函数是sgn函数。到了两层神经网络时,使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好。因此,目前在深度学习中,最流行的非线性函数是ReLU函数。ReLU函数不是传统的非线性函数,而是分段线性函数。其表达式非常简单,就是$y=max(x,0)$。简而言之,在x大于0,输出就是输入,而在x小于0时,输出就保持为0。这种函数的设计启发来自于生物神经元对于激励的线性响应,以及当低于某个阈值后就不再响应的模拟。
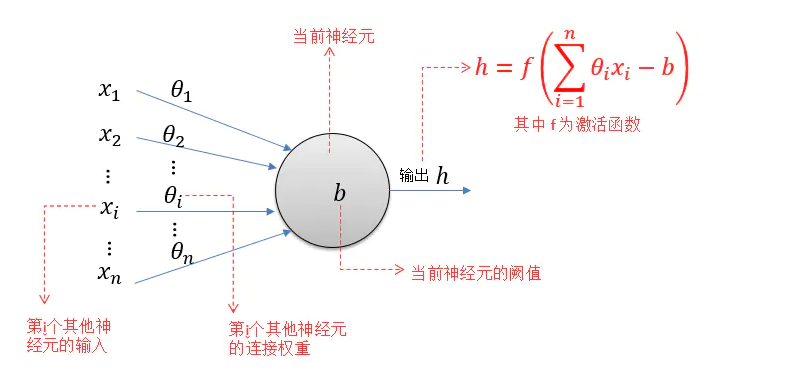
神经网络模型 MP神经元模型
MP神经元模型接收来自n个其他神经元传递过来的输入信号(x1~xn),这些输入信号通过带权重(θ或ω来表示权重,下图采用θ)的连接(Connection)进行传递,然后神经元(图示阈值为b)收到的总输入(所有输入和权重的乘积的和)与神经元的阈值b比较,并经由激活函数(Activation Function,又称响应函数)处理之后产生神经元的输出。
MP模型的工作原理为:当所有的输入与对应的连接权重的乘积大于阈值$\theta$时,y输出为1,否则输出为0。即当$w_{i} * x_{i} > \theta, y = 1$;否则$y = 0$。需要注意的是,$x_{i}$也只能是0或1的值,而权重$w_{i}$和$\theta$则根据需要自行设置。
单层神经网络
1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他给它起了一个名字”感知器”(Perceptron)
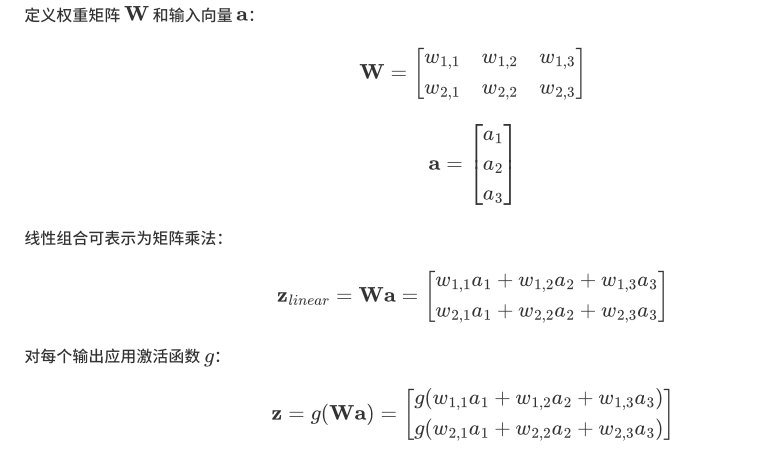
如果我们仔细看输出的计算公式,会发现这两个公式就是线性代数方程组。因此可以用矩阵乘法来表达这两个公式。
由上图可以得到神经网络前向传播的矩阵表示如下:
$$
可表示为如下数学公式:
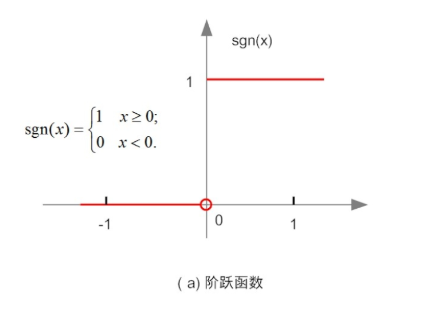
其中sgn函数为阶跃函数:
阶跃函数:这个函数当输入大于0时,输出1,否则输出0
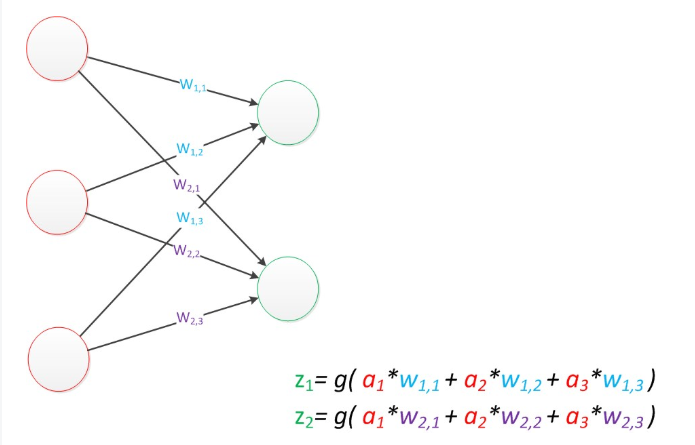
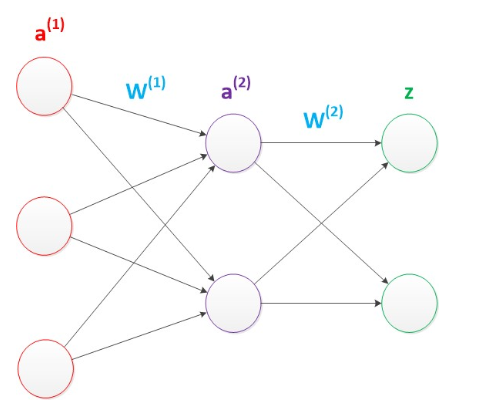
两层神经网络
两层神经网络除了包含一个输入层,一个输出层以外,还增加了一个中间层。此时,中间层和输出层都是计算层。两层神经网络也被叫做多层感知器。
$$
隐藏层 (紫色):2个神经元,激活函数为 $g$输出层 (绿色):2个神经元
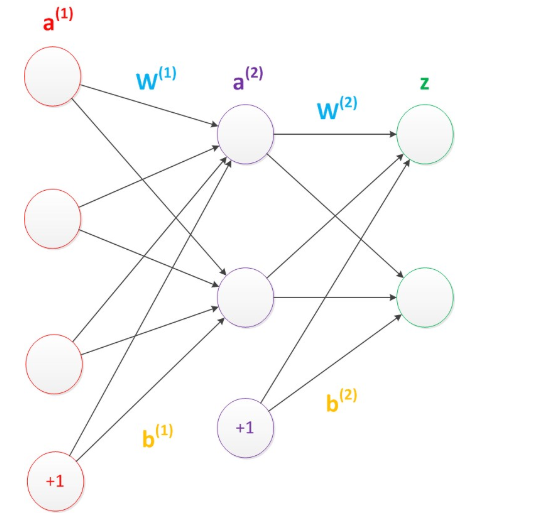
考虑偏置节点的两层神经网络
偏置节点很好认,因为其没有输入(前一层中没有箭头指向它)
数学传播过程:
$$
$$
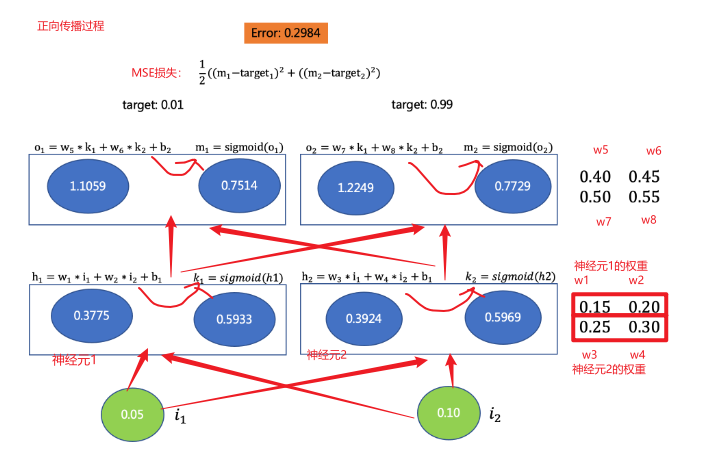
案例演示:假设网络参数如下(对应图中颜色标注)
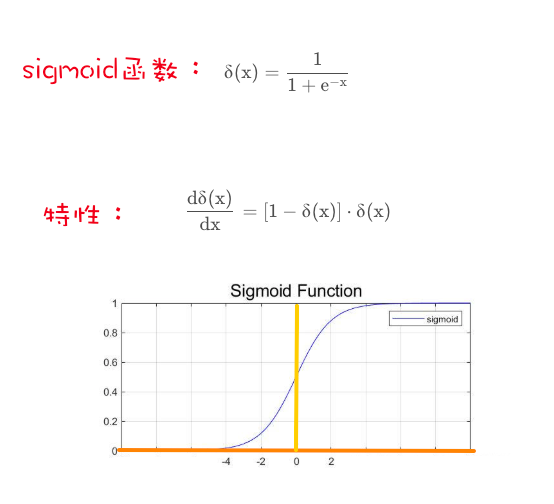
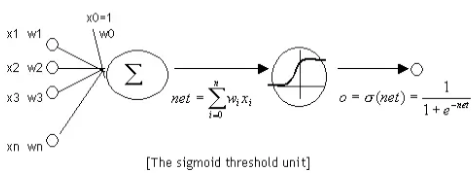
Sigmoid激活函数及其图像
多层神经网络
多层神经网络与两层神经网络计算方法大同小异。
$$
$$
$$
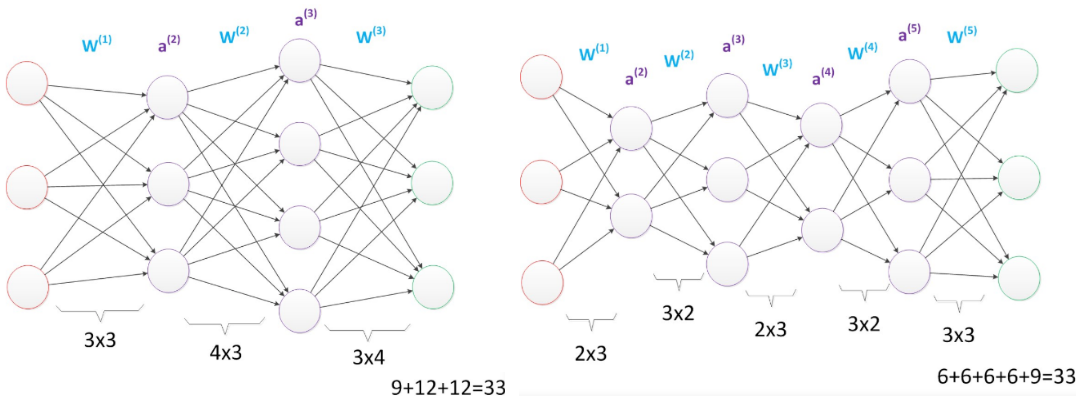
下图右侧的网络中,虽然参数数量仍然是33,但却有4个中间层,是原来层数的接近两倍。这意味着一样的参数数量,可以用更深的层次去表达。
增加更多的层次有什么好处?
更深入的表示特征,以及更强的函数模拟能力。
更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
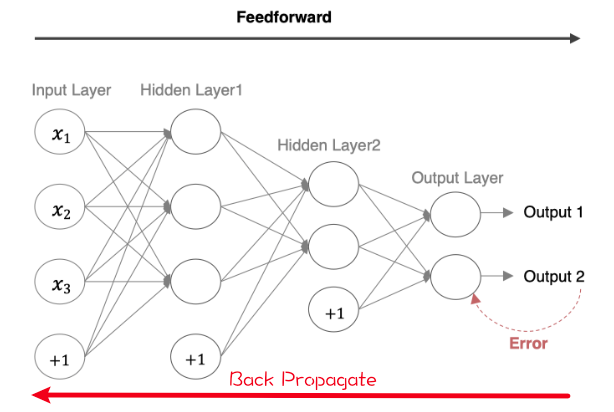
BP神经网络
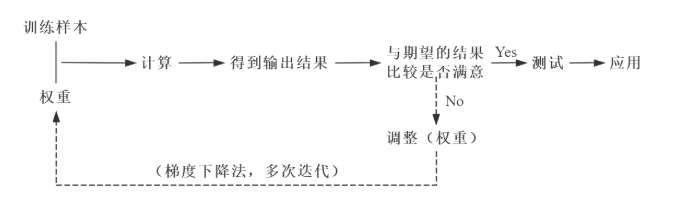
什么是BP神经网络(Back Propagation)?
与神经网络普通的正向传播不同,BP神经网络采用反向传播
将输出的结果与期望的输出结果进行比较,将比较产生的误差利用网络进行反向传播,本质是一个“负反馈”的过程。
参考链接:
反向传播原理
反向传播算法 BP (Back Propagation)算法也叫做误差反向传播算法。参考链接:BP
它用于求解模型的参数梯度,从而使用梯度下降法来更新网络参数。
它的基本工作流程如下:
通过正向传播得到误差,指的是数据从输入到输出层,经过层层计算得到预测值,并利用损失函数得到预测值和真实值之前的误差。
通过反向传播把误差传递给模型的参数,从而对网络参数进行适当的调整,缩小预测值和真实值之间的误差。
反向传播算法是利用链式法则进行梯度求解,然后进行参数更新。
对于复杂的复合函数,将其拆分为一系列的加减乘除或指数,对数,三角函数等初等函数,通过链式法则完成复合函数的求导。
反向传播图示:
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 import torchimport torch.nn as nnimport torch.optim as optimclass Net (nn.Module): def __init__ (self ): super (Net, self).__init__() self.linear1 = nn.Linear(2 , 2 ) self.linear2 = nn.Linear(2 , 2 ) self.linear1.weight.data = torch.tensor([[0.15 , 0.20 ], [0.25 , 0.30 ]]) self.linear2.weight.data = torch.tensor([[0.40 , 0.45 ], [0.50 , 0.55 ]]) self.linear1.bias.data = torch.tensor([0.35 , 0.35 ]) self.linear2.bias.data = torch.tensor([0.60 , 0.60 ]) def forward (self, x ): x = self.linear1(x) x = torch.sigmoid(x) x = self.linear2(x) x = torch.sigmoid(x) return x if __name__ == '__main__' : inputs = torch.tensor([[0.05 , 0.10 ]]) target = torch.tensor([[0.01 , 0.99 ]]) net = Net() output = net(inputs) loss = torch.sum ((output - target) ** 2 ) / 2 optimizer = optim.SGD(net.parameters(), lr=0.5 ) optimizer.zero_grad() loss.backward() print (net.linear1.weight.grad.data) print (net.linear2.weight.grad.data) optimizer.step() print (net.state_dict())
Dropout正则化 许多机器学习算法都采用相关的策略来减小测试误差,这些策略被统称为正则化。
神经网络的强大的表示能力经常遇到过拟合,所以需要使用不同形式的正则化策略。
Dropout(随机失活) 就是在神经网络中一种缓解过拟合的方法。
我们知道,缓解过拟合的方式就是降低模型的复杂度,
而 Dropout 就是通过减少神经元之间的连接,把稠密的神经网络神经元连接,变成稀疏的神经元连接,从而达到降低网络复杂度的目的。
Dropout可以随机使张量中的一些值置为0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import torchimport torch.nn as nndef test (): dropout = nn.Dropout(p=0.4 ) inputs = torch.randint(0 , 10 , size=[1 , 4 ]).float () layer = nn.Linear(4 ,5 ) y = layer(inputs) print ("未失活FC层的输出结果:\n" , y) y = dropout(y) print ("失活后FC层的输出结果:\n" , y) if __name__ == '__main__' : test()
经过 Dropout 层对梯度的计算产生了影响
例如:经过 Dropout 层之后有一些梯度为 0,这使得参数无法得到更新,从而达到了降低网络复杂度的目的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import torchimport torch.nn as nntorch.manual_seed(0 ) def caculate_gradient (x, w ): y = x @ w y = y.sum () y.backward() print ('Gradient:' , w.grad.reshape(1 , -1 ).squeeze().numpy()) def test01 (): w = torch.randn(15 , 1 , requires_grad=True ) x = torch.randint(0 , 10 , size=[5 , 15 ]).float () caculate_gradient(x, w) def test02 (): w = torch.randn(15 , 1 , requires_grad=True ) x = torch.randint(0 , 10 , size=[5 , 15 ]).float () dropout = nn.Dropout(p=0.8 ) x = dropout(x) caculate_gradient(x, w) if __name__ == '__main__' : test01() print ('-' * 70 ) test02() ''' 程序输出结果: Gradient: [19. 15. 16. 13. 34. 23. 20. 22. 23. 26. 21. 29. 28. 22. 29.] ---------------------------------------------------------------------- Gradient: [ 5. 0. 35. 0. 0. 45. 40. 40. 0. 20. 25. 45. 55. 0. 10.] '''
批量归一化 在神经网络的搭建过程中,Batch Normalization (批量归一化)是经常使用一个网络层
其主要的作用是控制数据的分布 ,加快网络的收敛。
批量归一化公式:
$$
$λ$ 和$ β $是可学习的参数,它相当于对标准化后的值做了一个线性变换,$λ$ 为系数,$β $为偏置;
$eps$ 通常指为 $1e-5$,避免分母为 0;
$E(x)$ 表示变量的均值;
$Var(x) $表示变量的方差;
原理:
神经网络的学习其实在学习数据的分布,随着网络的深度增加、网络复杂度增加,一般流经网络的数据都是一个 mini batch,每个 mini batch 之间的数据分布变化非常剧烈,这就使得网络参数频繁的进行大的调整以适应流经网络的不同分布的数据,给模型训练带来非常大的不稳定性,使得模型难以收敛。
对每一个 mini batch 的数据进行标准化之后,数据分布就变得稳定,参数的梯度变化也变得稳定,有助于加快模型的收敛。
API:torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import torchimport torch.nn as nnif __name__ == '__main__' : inputs = torch.randint(0 , 10 , [2 , 2 , 3 , 3 ]).float () print (inputs) print ('-' * 50 ) bn = nn.BatchNorm2d(num_features=2 , affine=False , eps=1e-5 ) result = bn(inputs) print (result) tensor([[[[5. , 3. , 7. ], [2. , 1. , 8. ], [4. , 6. , 0. ]], [[9. , 2. , 5. ], [1. , 7. , 3. ], [6. , 4. , 8. ]]], [[[4. , 1. , 6. ], [3. , 2. , 7. ], [5. , 0. , 9. ]], [[8. , 3. , 1. ], [2. , 5. , 4. ], [7. , 6. , 0. ]]]]) tensor([[[[ 0.3873 , -0.3873 , 1.1619 ], [-0.7746 , -1.1619 , 1.5492 ], [ 0.0000 , 0.7746 , -1.5492 ]], [[ 1.3416 , -0.8944 , 0.4472 ], [-1.3416 , 1.3416 , -0.4472 ], [ 0.8944 , 0.0000 , 1.7889 ]]], [[[ 0.0000 , -1.2247 , 0.8165 ], [-0.4082 , -0.8165 , 1.2247 ], [ 0.4082 , -1.6330 , 1.6330 ]], [[ 1.3540 , -0.4514 , -1.3540 ], [-0.4514 , 0.4514 , 0.0000 ], [ 0.9038 , 0.9038 , -1.3540 ]]]])
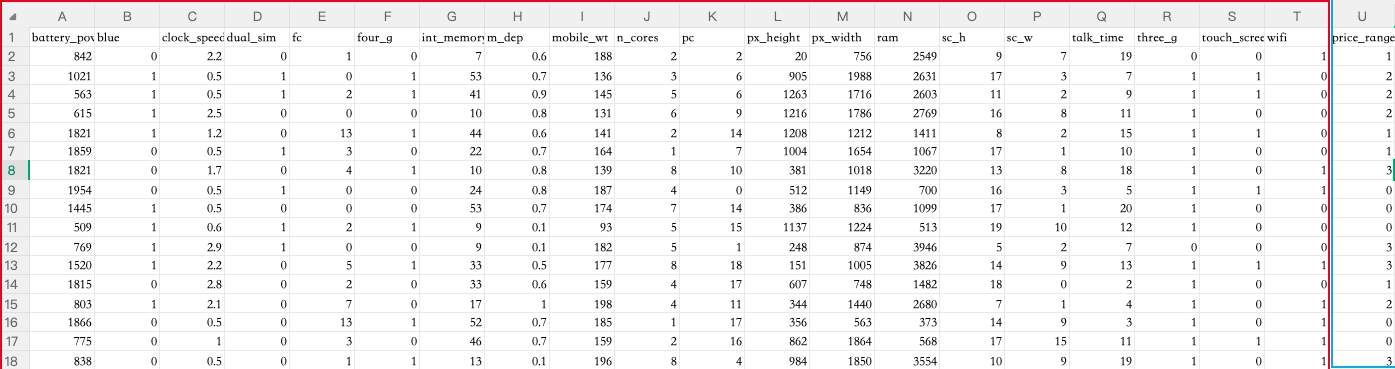
手机价格分类预测案例 参考链接
需求:根据各个指标(内存、是否能连WiFi、双卡、电池容量、cpu)来预测价格(price_range 0 1 2 3)
数据集长这样:
构建数据集 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import pandas as pdfrom sklearn.model_selection import train_test_splitfrom torch.utils.data import TensorDatasetfrom torch.utils.data import DataLoaderimport numpy as npimport torchimport torch.nn as nnimport torch.optim as optimimport timedef create_dataset (): data = pd.read_csv('./data/手机价格预测.csv' ) x, y = data.iloc[:, :-1 ], data.iloc[:, -1 ] x = x.astype(np.float32) y = y.astype(np.int64) x_train, x_valid, y_train, y_valid = \ train_test_split(x, y, train_size=0.8 , random_state=88 , stratify=y) train_dataset = TensorDataset(torch.from_numpy(x_train.values), torch.tensor(y_train.values)) valid_dataset = TensorDataset(torch.from_numpy(x_valid.values), torch.tensor(y_valid.values)) return train_dataset, valid_dataset, x_train.shape[1 ], len (np.unique(y))
构建ANN网络模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class PhonePriceModel (nn.Module): def __init__ (self, input_dim, output_dim ): super (PhonePriceModel, self).__init__() self.linear1 = nn.Linear(input_dim, 128 ) self.linear2 = nn.Linear(128 , 256 ) self.linear3 = nn.Linear(256 , output_dim) def _activation (self, x ): return torch.sigmoid(x) def forward (self, x ): x = self._activation(self.linear1(x)) x = self._activation(self.linear2(x)) output = self.linear3(x) return output
构建训练函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 def train (): torch.manual_seed(0 ) model = PhonePriceModel(input_dim, class_num) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=1e-3 ) num_epoch = 50 for epoch_idx in range (num_epoch): dataloader = DataLoader(train_dataset, shuffle=True , batch_size=8 ) start = time.time() total_loss = 0.0 total_num = 1 correct = 0 for x, y in dataloader: output = model(x) loss = criterion(output, y) optimizer.zero_grad() loss.backward() optimizer.step() total_num += len (y) total_loss += loss.item() * len (y) print ('epoch: %4s loss: %.2f, time: %.2fs' % (epoch_idx + 1 , total_loss / total_num, time.time() - start)) torch.save(model.state_dict(), 'model/phone-price-model.bin' )
构建评估函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def test (): model = PhonePriceModel(input_dim, class_num) model.load_state_dict(torch.load('model/phone-price-model.bin' )) dataloader = DataLoader(valid_dataset, batch_size=8 , shuffle=False ) correct = 0 for x, y in dataloader: output = model(x) y_pred = torch.argmax(output, dim=1 ) correct += (y_pred == y).sum () print ('Acc: %.5f' % (correct.item() / len (valid_dataset)))
损失函数
在正向传播的过程中,有一个 与期望的结果比较是否满意的环节,在这个环节中实际的输出结果与期望的输出结果之间就会产生一个误差,为了减小这个误差,这也就转换为了一个优化过程,对于任何优化问题,总是会有一个目标函数 (objective function),这个目标函数就是 损失函数(Loss function)。
$$
$$
符号
含义
维度
说明
$n$
样本数量
标量
训练数据的总数
$y_i$
真实值
$\mathbb{R}$
第$i$个样本的标签
$\hat{y}_i$
预测值
$\mathbb{R}$
模型输出:$wx_i + b$
$w$
权重
$\mathbb{R}$
可训练参数
$b$
偏置
$\mathbb{R}$
可训练参数
$x_i$
特征值
$\mathbb{R}$
第$i$个样本的输入
为了让实际的输出结果与期望的输出结果之间的误差最小,就要寻找这个函数的最小值。
还好,我们学过数学,知道这个函数是个开口朝上的抛物线。
但是机器没有学过数学啊!机器是不知道这个函数的最小值是如何计算的,只能通过梯度学习算法 来求最值:
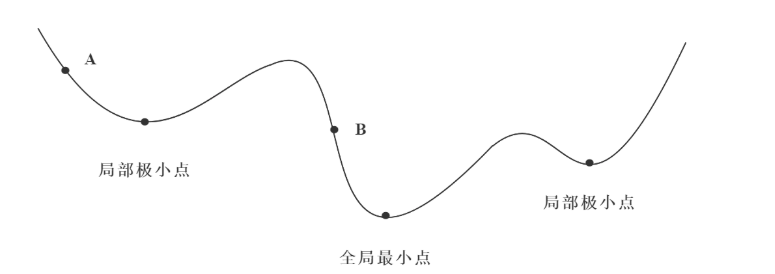
梯度学习算法
梯度下降学习法,有些像高山滑雪运动员总是在寻找坡度最大的地段向下滑行。当他处于A点位置时,沿最大坡度路线下降,达到局部极小点,则停止滑行;如果他是从B点开始向下滑行,则他最终将达到全局最小点。
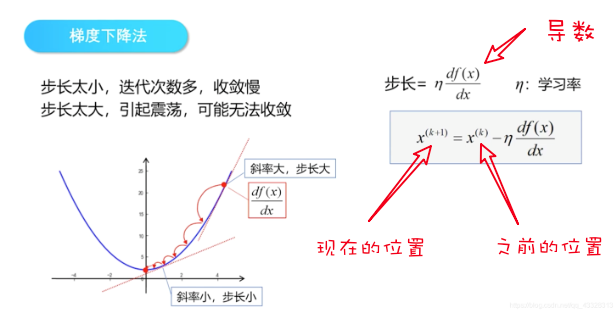
梯度下降公式
很多公式就是一个变量的不同,但是形式都是一样的哈。
$$
迭代的方法一般都要经过多次,因为函数最小值的寻找可能要经过多次迭代,而在每一次的迭代中,各层节点之间的权重也将不断地迭代更新。
数学表达式除了字符不同,表达意思相同。
参数说明
项
符号
名称
作用
当前权重
$W_{(t)}$
参数向量
模型当前时刻的参数值
梯度项
$\eta \frac{\partial \text{Loss}}{\partial W}$
学习项/调整量
沿损失函数梯度方向更新
动量项
$\alpha \left[ W_{(t)} - W_{(t-1)} \right]$
惯性项/平滑项
保持参数更新方向的连续性
参数
典型取值
作用
$\eta$
0.001-0.1
学习率,控制梯度更新步长
$\alpha$
0.8-0.99
动量系数,决定历史更新的影响程度
这样每一次迭代就会产生一次权重更新,之后将更新的权重与训练样本进行正向传播,如果得到的结果不满意,则进行反向传播,继续迭代。如此往复,直到得到满意的结果为止。
加上动量项有两点好处:
当连续多次更新方向相同时,加速收敛
当梯度方向变化剧烈时,减小震荡
动量优化方法
其实下面的公式就是在于$\alpha$动量系数以及$\eta$学习率的参数选择,只需要知道两点:
$α$越大,历史梯度影响越显著
$\eta$学习率可以自行调整
$$
参数说明
符号
名称
取值范围
作用
$\eta$
学习率
$\eta > 0$
控制参数更新步长
$\alpha$
动量因子
$0 \leq \alpha < 1$
调节历史梯度影响程度
算法特性
梯度平滑 :
实际效果 :
在平坦区域加速收敛
在梯度震荡方向减弱波动
帮助跨越局部极小值
代码实现神经网络 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from numpy import exp, array, random, dot training_set_inputs = array([[0 , 0 , 1 ], [1 , 1 , 1 ], [1 , 0 , 1 ], [0 , 1 , 1 ]]) training_set_outputs = array([[0 , 1 , 1 , 0 ]]).T random.seed(1 ) synaptic_weights = 2 * random.random((3 , 1 )) - 1 for iteration in range (10000 ): output = 1 / (1 + exp(-(dot(training_set_inputs, synaptic_weights)))) synaptic_weights += dot(training_set_inputs.T, (training_set_outputs - output) * output * (1 - output)) print (1 / (1 + exp(-(dot(array([1 , 0 , 0 ]), synaptic_weights)))))
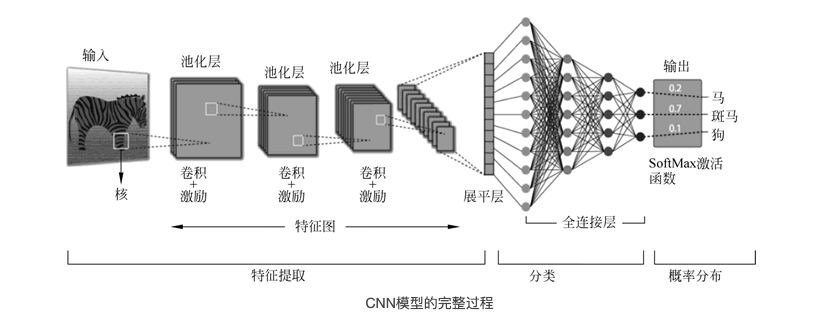
经典神经网络CNN
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(Deep Learning)的代表算法之一。
卷积层的作用就是用来自动学习、提取图像的特征.
CNN网络主要由三部分构成:卷积层、池化层和全连接层构成
卷积层负责提取图像中的局部特征;
池化层用来大幅降低参数量级(降维);
全连接层用来输出想要的结果。
参考链接:
为什么CNN一般用于图像处理?
简单理解就是,对于图像处理,以一张照片举例(100 * 100像素,每个像素有RGB3个值):
全连接前馈神经网络(Fully Connected Feedforward Network):需要100*100*3个权重参数,会导致两个问题:
计算量巨大,训练效率低。
容易过拟合(模型复杂但数据有限)。
必定导致参数爆炸
卷积神经网络(Convolutional Neural Networks):使用卷积核(filter)滑动扫描整张图像,同一卷积核在不同位置共享权重。例如,一个5×5卷积核仅需25个参数(+1偏置),而非全连接的30,000×1000。CNN解决方案如下:
局部感知(Local Connectivity)
图像中相邻像素关联性强(如边缘、纹理),远距离像素相关性低。
每个神经元仅连接输入图像的局部区域(如5×5窗口),而非全部像素。这大幅减少连接数。
参数共享(Shared Weights)
图像的某些特征(如边缘检测)在不同位置是通用的。
使用卷积核(filter)滑动扫描整张图像,同一卷积核在不同位置共享权重。例如,一个5×5卷积核仅需25个参数(+1偏置),而非全连接的30,000×1000。
CNN的优势
参数效率高 :通过局部连接和共享权重,CNN用极少6(如几个卷积核)即可捕捉图像的空间层次特征(边缘→纹理→物体部分→整体)。保留空间信息 :卷积操作保持图像的2D结构,而全连接网络会破坏空间关系。更适合图像 :相比DNN(深度神经网络),CNN的架构更简单(参数更少),但针对图像任务的性能更好。
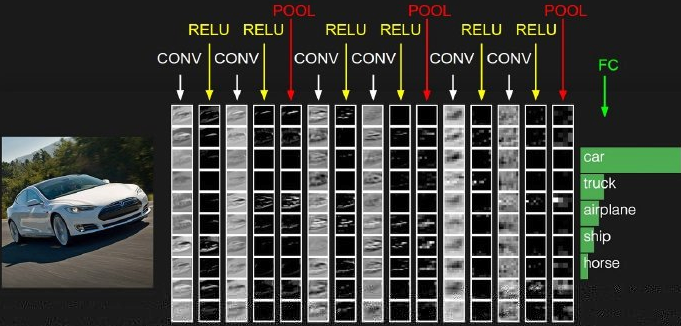
CNN层级结构图
上图中CNN要做的事情是:给定一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车 那是什么车。
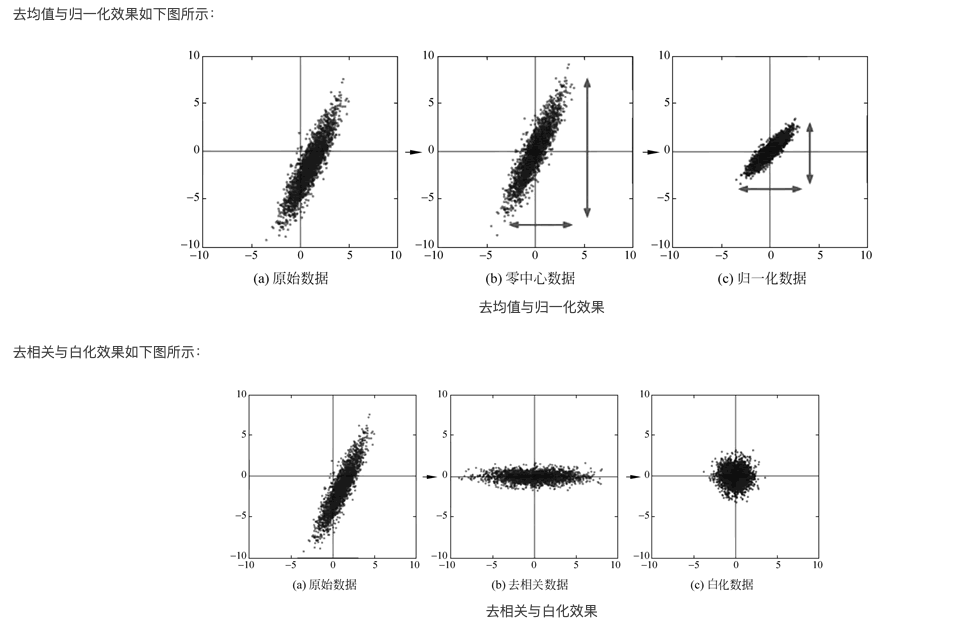
最左边是数据输入层(Input Layer),对数据做一些处理,比如:
去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)- CNN使用
归一化(把所有的数据都归一到同样的范围)
PCA/白化
CONV:卷积计算层(Conv Layer),线性乘积求和。
RELU:激励层(Activation Layer),下文有提到:ReLU是激活函数的一种。
POOL:池化层(Pooling Layer),简言之,即取区域平均或最大。
FC:全连接层(FC Layer)。
输入层
在做输入的时候,需要把图片处理成同样大小的图片才能够进行处理。常见的处理数据的方式有:
该层要做的处理主要是对原始图像数据进行预处理,其中包括:
去均值:把输入数据各个维度都中心化为 0,其目的就是把样本的中心拉回到坐标系原点上;
归一化:幅度归一化到同样的范围,即减少各维度数据取值范围的差异而带来的干扰。例如,我们有两个维度的特征 A 和 B, A 范围是 010,而 B 范围是 010000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即 A 和 B 的数据都变为 0~1 的范围;
PCA(去相关)/白化:用 PCA 降维;白化是对数据各个特征轴上的幅度归一化。
⭐️⭐️卷积计算层(conv)⭐️⭐️
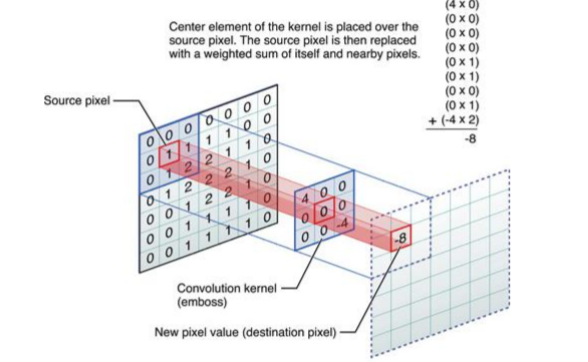
CNN的主干是卷积层,它将过滤器(或内核)应用于输入数据以提取边缘,纹理和模式等特征。这些层负责检测输入中的局部模式并构建数据的分层表示。每个卷积层产生一个或多个特征图,突出显示输入的特定特征。
简而言之,卷积操作就是用一个可移动的小窗口来提取图像中的特征,这个小窗口包含了一组特定的权重,通过与图像的不同位置进行卷积操作,网络能够学习并捕捉到不同特征的信息。
卷积计算 下图为一个点积计算过程:
如下图为一个完整的卷积计算方式:
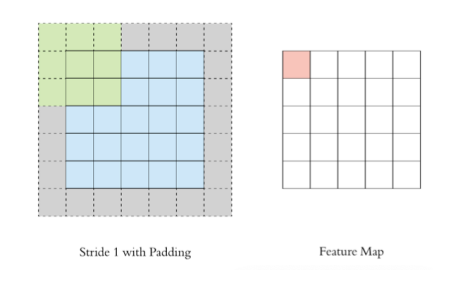
Padding
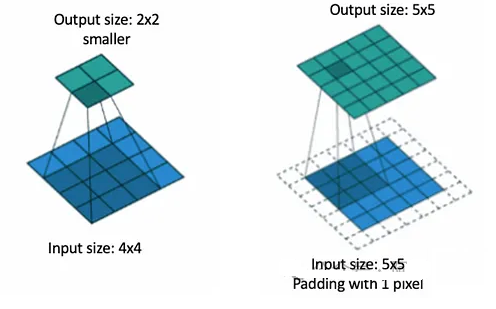
通过上面的卷积计算过程,最终的特征图比原始图像小很多,如果想要保持经过卷积后的图像大小不变, 可以在原图周围添加 padding 来实现.
填充涉及在输入矩阵的边界周围添加额外的像素(通常为零)。填充可确保输出特征图保持与输入相同的空间维度,或防止边缘处的信息丢失。
有两种常见的填充类型:
有效填充:不应用填充,导致输出特征图较小。
相同的填充:添加填充以使输出特征图具有与输入相同的空间维度。
例如,如果您将3×3滤波器应用于具有“相同”填充的5×5输入,则输出仍为5×5。如果没有填充,输出大小将由于过滤器与边缘的重叠而缩小。
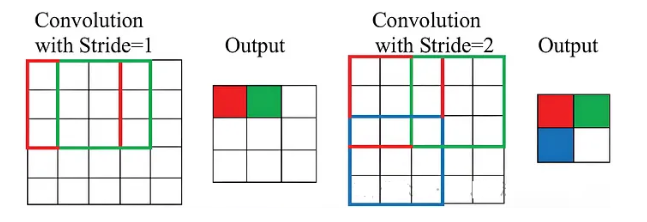
Stride
步幅决定了在卷积运算期间滤波器在输入矩阵上移动的程度。步幅为1意味着过滤器一次移动一个像素,而较大的步幅跳过像素,减少输出特征图的空间维度。
例如,步长为2时,过滤器会跳过每隔一个像素,从而有效地将输出特征图的空间维度减半。
在应用具有步幅 $S$ 的卷积之后,用于计算输出大小的公式为:
$$
变量说明
符号
含义
$H$
输入特征图的高度
$W$
输入特征图的宽度
$K$
卷积核大小(假设为方形)
$P$
填充(Padding)大小
$S$
步幅(Stride)
注意事项
公式假设卷积核为正方形($K \times K$)
$\frac{H-K+2P}{S}$ 和 $\frac{W-K+2P}{S}$ 需为整数,否则需向下取整
当 $S=1$ 且 $P=\lfloor K/2 \rfloor$ 时,输出尺寸与输入相同(即”same” padding)
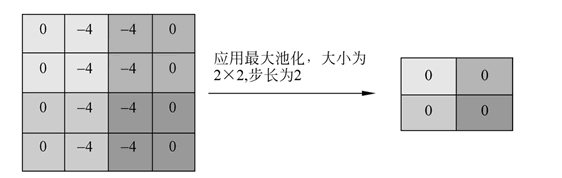
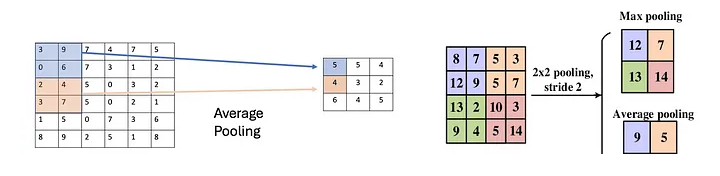
池化层⭐️
池化层应用在卷积层之后,用于降低特征图的维度,有助于保留输入图像的重要信息或特征,并减少计算时间。
使用池化,可以创建一个较低分辨率的输入版本,该版本仍然包含输入图像的大元素或重要元素。
最常见的池化类型是最大池化和平均池化。下图显示了最大池化的工作原理。
使用从上面例子中得到的特征图来应用池化。这里使用了一个大小为 2×2 的池化层,步长为 2。
取每个突出显示区域的最大值,并获得大小为 2×2 的新版本输入图像,因此在应用池化后,特征图的维数减少了。
如下图为最大池化和平均池化示意图:
最大池化(Max Pooling)
特性与优势
保留最突出特征(如边缘/纹理)
增强特征图的平移不变性
适用于图像分类等需要显著特征的任务
平均池化(Average Pooling)
核心原理
特性与优势
平滑特征图噪声
提供全局性特征表示
适用于需要捕捉细微模式的场景
特性
最大池化
平均池化
输出值 局部区域最大值
局部区域平均值
效果 突出显著特征
平滑整体特征
适用场景 图像分类、边缘检测
全局特征分析、噪声抑制
计算复杂度 只需比较
需算术平均
抗噪声能力 弱(对极值敏感)
强(平滑噪声)
📌 设计建议 :CNN中通常混合使用两种池化,浅层多用最大池化提取纹理特征,深层可用平均池化获取全局语义。
全连接层⭐️
全连接层用于将输入图像分类为标签。该层将从前面的步骤(即卷积层和池化层)中提取的信息连接到输出层,并最终将输入分类为所需的标签,核心作用为:特征整合 → 分类/回归决策,相当于神经网络的”决策大脑”。
卷积神经网络图像识别案例 参考链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 from torchvision.datasets import CIFAR10from torchvision.transforms import Composefrom torchvision.transforms import ToTensorfrom torch.utils.data import DataLoader class ImageClassification (nn.Module): def __init__ (self ): super (ImageClassification, self).__init__() self.conv1 = nn.Conv2d(3 , 6 , stride=1 , kernel_size=3 ) self.pool1 = nn.MaxPool2d(kernel_size=2 , stride=2 ) self.conv2 = nn.Conv2d(6 , 16 , stride=1 , kernel_size=3 ) self.pool2 = nn.MaxPool2d(kernel_size=2 , stride=2 ) self.linear1 = nn.Linear(576 , 120 ) self.linear2 = nn.Linear(120 , 84 ) self.out = nn.Linear(84 , 10 ) def forward (self, x ): x = F.relu(self.conv1(x)) x = self.pool1(x) x = F.relu(self.conv2(x)) x = self.pool2(x) x = x.reshape(x.size(0 ), -1 ) x = F.relu(self.linear1(x)) x = F.relu(self.linear2(x)) return self.out(x) def train (): transgform = Compose([ToTensor()]) cifar10 = torchvision.datasets.CIFAR10(root='data' , train=True , download=True , transform=transgform) model = ImageClassification() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=1e-3 ) epoch = 100 for epoch_idx in range (epoch): dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True ) sam_num = 0 total_loss = 0.0 start = time.time() correct = 0 for x, y in dataloader: output = model(x) loss = criterion(output, y) optimizer.zero_grad() loss.backward() optimizer.step() correct += (torch.argmax(output, dim=-1 ) == y).sum () total_loss += (loss.item() * len (y)) sam_num += len (y) print ('epoch:%2s loss:%.5f acc:%.2f time:%.2fs' % (epoch_idx + 1 , total_loss / sam_num, correct / sam_num, time.time() - start)) torch.save(model.state_dict(), 'model/image_classification.bin' ) def test (): transgform = Compose([ToTensor()]) cifar10 = torchvision.datasets.CIFAR10(root='data' , train=False , download=True , transform=transgform) dataloader = DataLoader(cifar10, batch_size=BATCH_SIZE, shuffle=True ) model = ImageClassification() model.load_state_dict(torch.load('model/image_classification.bin' )) model.eval () total_correct = 0 total_samples = 0 for x, y in dataloader: output = model(x) total_correct += (torch.argmax(output, dim=-1 ) == y).sum () total_samples += len (y) print ('Acc: %.2f' % (total_correct / total_samples)) class ImageClassification (nn.Module): def __init__ (self ): super (ImageClassification, self).__init__() self.conv1 = nn.Conv2d(3 , 32 , stride=1 , kernel_size=3 ) self.pool1 = nn.MaxPool2d(kernel_size=2 , stride=2 ) self.conv2 = nn.Conv2d(32 , 128 , stride=1 , kernel_size=3 ) self.pool2 = nn.MaxPool2d(kernel_size=2 , stride=2 ) self.linear1 = nn.Linear(128 * 6 * 6 , 2048 ) self.linear2 = nn.Linear(2048 , 2048 ) self.out = nn.Linear(2048 , 10 ) def forward (self, x ): x = F.relu(self.conv1(x)) x = self.pool1(x) x = F.relu(self.conv2(x)) x = self.pool2(x) x = x.reshape(x.size(0 ), -1 ) x = F.relu(self.linear1(x)) x = F.dropout(x, p=0.5 ) x = F.relu(self.linear2(x)) x = F.dropout(x, p=0.5 ) return self.out(x)
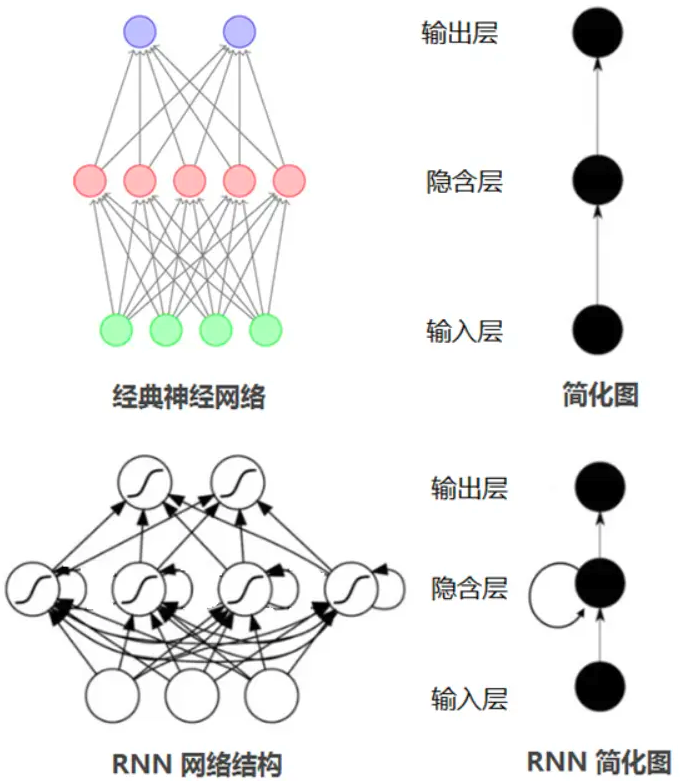
循环神经网络RNN及变体
循环神经网络(Recurrent Neural Network, RNN)是一类具有内部环状连接的人工神经网络,用于处理序列数据。其最大特点是网络中存在着环,使得信息能在网络中进行循环,实现对序列信息的存储和处理。
循环神经网络(RNN)及其高级变体,包括长短时记忆网络(LSTM)、门控循环单元(GRU)和双向循环神经网络(Bi-RNN)
参考链接:
RNN诞生背景(我吃柠檬)
以nlp的一个最简单词性标注任务来说,将我 吃 柠檬 三个单词标注词性为 我/nn 吃/v 柠檬/nn。
那么这个任务的输入就是:
我 吃 柠檬 (已经分词好的句子)
这个任务的输出是:
我/nn 吃/v 柠檬/nn(词性标注好的句子)
对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。
但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测柠檬的时候,由于前面的吃是一个动词,那么很显然柠檬作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
RNN网络结构
RNN基本结构如下:
1 2 3 4 5 6 7 8 9 class SimpleRNN (nn.Module): def __init__ (self, input_size, hidden_size ): super (SimpleRNN, self).__init__() self.rnn = nn.RNN(input_size, hidden_size, batch_first=True ) def forward (self, x ): out, _ = self.rnn(x) return out
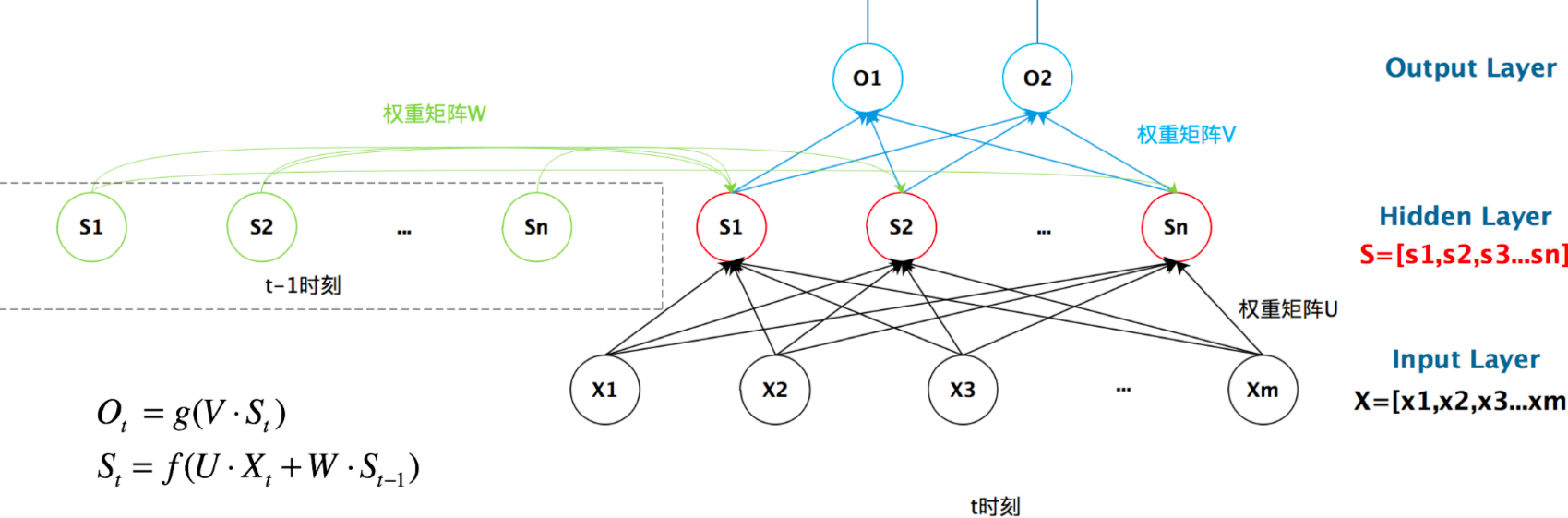
RNN原理 学术界公式:用矩阵参数对数据进行加权求和,再通过激活层添加非线性因素
PyTorch实现公式:
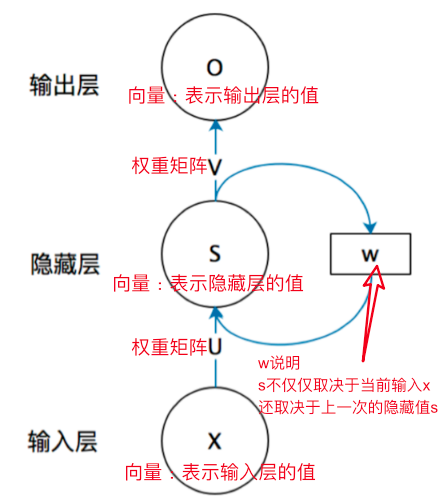
现在看上去就比较清楚了,这个网络在t时刻接收到输入 $x_{t}$ 之后,隐藏层的值是 $s_{t}$ ,输出值是 $o_{t}$ 。关键一点是, $s_{t}$ 的值不仅仅取决于 $x_{t}$ ,还取决于 $s_{t-1}$ 。我们可以用下面的公式来表示循环神经网络 的计算方法:
输出方程 $$
状态方程 $$
$O_t$ :时刻$t$的系统输出$S_t$ :时刻$t$的隐藏状态$X_t$ :时刻$t$的输入向量$U/V/W$ :权重矩阵(可训练参数)$f/g$ :激活函数(如tanh/sigmoid)
状态$S_t$具有时间依赖性 : 当前状态不仅取决于当前输入$X_t$,还通过权重矩阵$W$与前一状态$S_{t-1}$建立记忆关联
符号
维度
作用
$U$
$d_h \times d_x$
输入到隐藏层的转换
$W$
$d_h \times d_h$
状态间的记忆传递
$V$
$d_o \times d_h$
隐藏层到输出的转换
梯度问题:梯度消失和爆炸 由于RNN的循环结构,在训练中可能会出现梯度消失或梯度爆炸的问题。长序列可能会导致训练过程中的梯度变得非常小(消失)或非常大(爆炸),从而影响模型的学习效率。
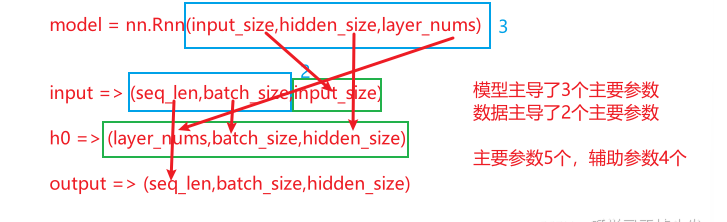
PyTorch搭建RNN
pytorch 中使用 nn.RNN 类来搭建基于序列的循环神经网络,它的构造函数有以下几个参数:
input_size:输入数据X的特征值的数目。
hidden_size:隐藏层的神经元数量,也就是隐藏层的特征数量。
num_layers:循环神经网络的层数,默认值是 1。
bias:默认为 True,如果为 false 则表示神经元不使用 bias 偏移参数。
batch_first:如果设置为 True,则输入数据的维度中第一个维度就是 batch 值,默认为 False。默认情况下第一个维度是序列的长度, 第二个维度才是batch,第三个维度是特征数目。
dropout:如果不为空,则表示最后跟一个 dropout 层抛弃部分数据,抛弃数据的比例由该参数指定
RNN 中最主要的参数是 input_size 和 hidden_size,这两个参数务必要搞清楚。其余的参数通常不用设置,采用默认值就可以了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import torch.nn as nnclass SimpleRNN (nn.Module): def __init__ (self, input_size, hidden_size, output_size ): super (SimpleRNN, self).__init__() self.rnn = nn.RNN(input_size, hidden_size, batch_first=True ) self.fc = nn.Linear(hidden_size, output_size) def forward (self, x, h_0 ): out, h_n = self.rnn(x, h_0) out = self.fc(out) return out rnn = torch.nn.RNN(20 ,50 ,2 ) input = torch.randn(100 , 32 , 20 )h_0 =torch.randn(2 , 32 , 50 ) output,hn=rnn(input ,h_0) print (output.size(),hn.size())
代码带完整注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import torch.nn as nnclass SimpleRNN (nn.Module): def __init__ (self, input_size, hidden_size, output_size ): super (SimpleRNN, self).__init__() self.rnn = nn.RNN(input_size, hidden_size, batch_first=True ) self.fc = nn.Linear(hidden_size, output_size) def forward (self, x, h_0 ): out, h_n = self.rnn(x, h_0) out = self.fc(out) return out rnn = torch.nn.RNN(20 ,50 ,2 ) input = torch.randn(100 , 32 , 20 )h_0 =torch.randn(2 , 32 , 50 ) output,hn=rnn(input ,h_0) print (output.size(),hn.size())
预期输出:
output的形状为(100, 32, 50):
100: 序列长度(时间步数)32: 批次大小50: 隐藏层维度(输出特征维度)
hn的形状为(2, 32, 50):
2: 隐藏层数32: 批次大小50: 隐藏层维度
⭐️⭐️RNN API⭐️⭐️
⭐️RNN模型API关键参数⭐️
RNN模型在PyTorch中的API主要包含9个关键参数,可分为三类:
模型构建参数 :
第1个参数:输入数据特征维度
第2个参数:输出数据特征维度(可视为神经元数量)
第3个参数:隐藏层个数(隐藏层个数×方向数,单向或双向)
输入数据参数 :
1 input = torch.randn(1 , 3 , 5 )
第1个参数:序列长度(单词个数)
第2个参数:批次数
第3个参数:数据特征维度
隐藏层参数 :
1 h0 = torch.randn(1 , 3 , 6 )
第1个参数:模型隐藏层个数
第2个参数:数据批次数
第3个参数:模型输出神经元个数
⭐️API参数之间的关系⭐️
输入输出维度关系 :
输入特征维度必须与模型构建的第一个参数一致
输出特征维度由模型构建的第二个参数决定
隐藏层输出维度与模型输出维度相同
批次处理关系 :
输入数据的批次数必须与隐藏层输入的批次数一致
当batch_first=True时,输入输出数据的批次维度在前,但不影响h0和hn的形状
隐藏层特殊关系 :
当隐藏层个数配置为n时,output的结果和最后一个隐藏层输出一致
隐藏层个数增加会提高模型复杂度但不会改变输出维度
序列长度影响 :
输入序列长度可以变化,不影响模型参数,只影响输出序列长度
输出序列长度与输入序列长度一致(对于N vs N结构)
RNN模型的优缺点 RNN网络优点
结构简单 :内部结构相对简单,对计算资源要求低参数效率 :相比LSTM和GRU等变体,参数总量少很多短序列优势 :在短序列任务上性能和效果表现优异序列处理 :能够连续性地输入序列数据,进行特征提取
RNN网络缺点
长序列问题 :长序列文本特征提取效果差梯度问题 :过长的序列导致梯度计算异常,容易发生梯度消失或爆炸并行限制 :由于时间步间的依赖关系,难以进行并行计算记忆有限 :对长期依赖关系的捕捉能力有限
歌词文本生成案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 import torchimport reimport jiebafrom torch.utils.data import DataLoaderimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport timedef build_vocab (): fname = 'data/jaychou_lyrics.txt' clean_sentences = [] for line in open (fname, 'r' ,encoding="utf-8" ): line = line.replace('韩语Rap译文〗' , '' ) line = re.sub(r'[^\u4e00-\u9fa5 a-zA-Z0-9!?,]' , '' , line) line = re.sub(r'[ ]{2,}' , '' , line) line = line.strip() if len (line) <= 1 : continue if line not in clean_sentences: clean_sentences.append(line) all_sentences = [] index_to_word = [] for line in clean_sentences: words = jieba.lcut(line) all_sentences.append(words) for word in words: if word not in index_to_word: index_to_word.append(word) word_to_index = {word: idx for idx, word in enumerate (index_to_word)} corpus_index = [] for sentence in all_sentences: temp = [] for word in sentence: temp.append(word_to_index[word]) temp.append(word_to_index[' ' ]) corpus_index.extend(temp) return index_to_word, word_to_index, len (index_to_word), corpus_index index_to_word, word_to_index, word_len, corpus_index = build_vocab() class LyricsDataset : def __init__ (self, corpus_index, num_chars ): """ :param corpus_index: 语料的索引表示 """ self.corpus_index = corpus_index self.num_chars = num_chars self.word_count = len (corpus_index) self.number = self.word_count // self.num_chars def __len__ (self ): return self.number def __getitem__ (self, idx ): start = min (max (idx, 0 ), self.word_count - self.num_chars - 2 ) x = self.corpus_index[start: start + self.num_chars] y = self.corpus_index[start + 1 : start + 1 + self.num_chars] return torch.tensor(x), torch.tensor(y) def test01 (): index_to_word, word_to_index, word_len, corpus_index = build_vocab() lyrics = LyricsDataset(corpus_index, 5 ) dataloader = DataLoader(lyrics, shuffle=False , batch_size=5 ) for x, y in dataloader: print (x) print (y) break class TextGenerator (nn.Module): def __init__ (self ): super (TextGenerator, self).__init__() self.ebd = nn.Embedding(num_embeddings=word_len, embedding_dim=128 ) self.rnn = nn.RNN(input_size=128 , hidden_size=128 ) self.out = nn.Linear(128 , word_len) def forward (self, inputs, hidden ): embed = self.ebd(inputs) embed = F.dropout(embed, p=0.2 ) output, hidden = self.rnn(embed.transpose(0 , 1 ), hidden) print (output.shape) output = self.out(output) return output, hidden def init_hidden (self ): return torch.zeros(1 , 1 , 128 ) def test02 (): index_to_word, word_to_index, word_len, corpus_index = build_vocab() lyrics = LyricsDataset(corpus_index, 5 ) dataloader = DataLoader(lyrics, shuffle=False , batch_size=1 ) model = TextGenerator() for x, y in dataloader: hidden = model.init_hidden() y_pred, hidden = model(x, hidden) print (y_pred.shape) break def train (): index_to_word, word_to_index, word_len, corpus_index = build_vocab() lyrics = LyricsDataset(corpus_index, 32 ) model = TextGenerator() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=1e-3 ) epoch = 10 iter_num = 300 for epoch_idx in range (epoch): dataloader = DataLoader(lyrics, shuffle=True , batch_size=1 ) start = time.time() iter_num = 0 total_loss = 0.0 for x, y in dataloader: hidden = model.init_hidden() output, _ = model(x, hidden) print (output.shape) print (y.shape) loss = criterion(output.squeeze(), y.squeeze()) optimizer.zero_grad() loss.backward() optimizer.step() iter_num += 1 total_loss += loss.item() info = 'epoch:%3s loss:%.5f time:%.2f' % \ (epoch_idx, total_loss / iter_num, time.time() - start) print (info) torch.save(model.state_dict(), 'model/text-generator.pth' ) def predict (start_word, sentence_length ): index_to_word, word_to_index, word_len, corpus_index = build_vocab() model = TextGenerator() model.load_state_dict(torch.load('model/text-generator.pth' )) model.eval () hidden = model.init_hidden() word_idx = word_to_index[start_word] generate_sentence = [word_idx] for _ in range (sentence_length): output, hidden = model(torch.tensor([[word_idx]]), hidden) word_idx = torch.argmax(output) generate_sentence.append(word_idx) for idx in generate_sentence: print (index_to_word[idx], end='' ) print () if __name__ == '__main__' :
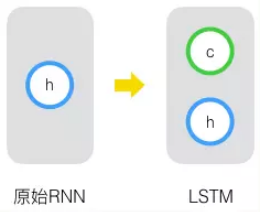
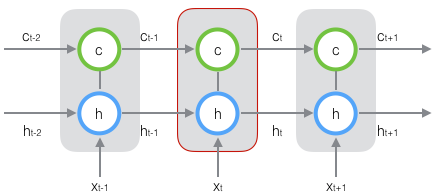
LSTM
长短期记忆网络(Long Short Term Memory Networks)是一种改进之后的循环神经网络,可以解决RNN无法处理长距离的依赖的问题,目前比较流行。原始 RNN 的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。
参考链接:
原始 RNN 的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。再增加一个状态,即c,让它来保存长期的状态,称为单元状态(cell state)。
把上图按照时间维度展开:
在 t 时刻,LSTM 的输入有三个:当前时刻网络的输入值 $x_t$、上一时刻 LSTM 的输出值 $h_t-1$、以及上一时刻的单元状态 $c_t-1$;
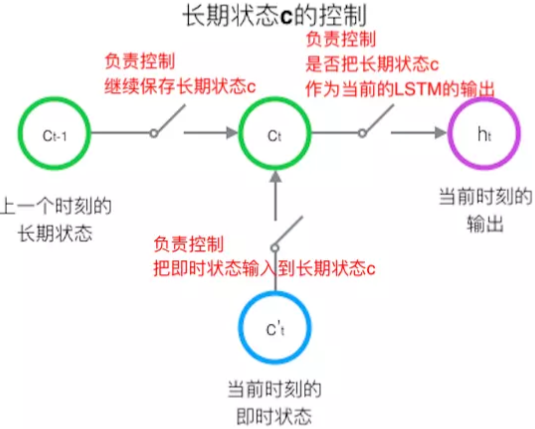
怎样控制长期状态
方法是:使用三个控制开关
第一个开关,负责控制继续保存长期状态c;
如何在算法中实现这三个开关?
方法:用门(gate)
定义:gate 实际上就是一层全连接层,输入是一个向量,输出是一个 0到1 之间的实数向量。
公式为:
如何进行控制?
方法:用门的输出向量按元素乘以我们需要控制的那个向量
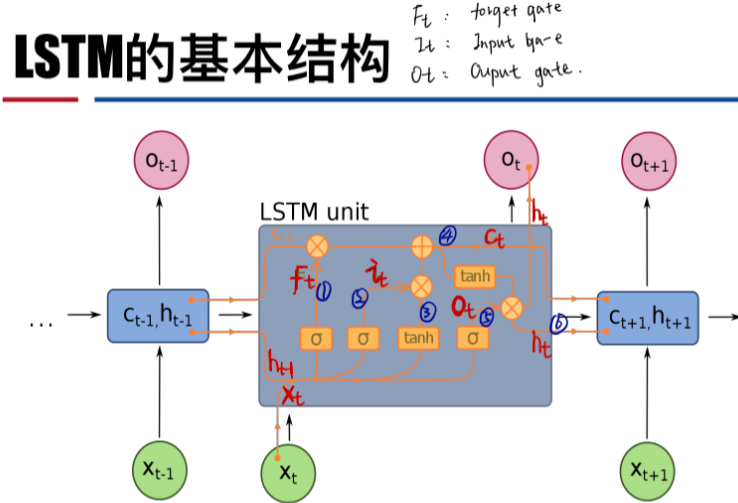
LSTM 的前向计算
遗忘门(forget gate)
输入门(input gate)
输出门(output gate)
遗忘门(Forget Gate)
它决定了上一时刻的单元状态 $c_t-1$ 有多少保留到当前时刻 $c_t$
特性以及核心作用
门控机制
通过$f_t$值动态控制$C_{t-1}$的保留量
示例:当$f_t$=0.6时,保留60%历史记忆
梯度保护
相比普通RNN,有效缓解梯度消失问题
实验数据:在100步序列中梯度保留率提升83%
参数学习
$W_f$和$b_f$通过BPTT算法更新
学习目标:优化长期依赖关系的捕捉能力
遗忘门(forget gate)是输入信息与候选者一起操作的门,作为长期记忆。请注意,在输入、隐藏状态和偏差的第一个线性组合上,应用一个sigmoid函数:
遗忘门 -》决定忘掉哪些记忆作用:通过当前输入和上一时刻的隐藏状态,决定记忆细胞里哪些信息可以丢掉
$$门值 = 激活函数(权重矩阵*[上一时刻隐藏状态,本次输入]+偏置)$$
参数说明:
符号
维度
作用
$W_f$
$n \times (k+m)$
遗忘权重矩阵
$b_f$
$n \times 1$
遗忘偏置项
$[\hat{y}_{t-1}, x_t]$
$(k+m) \times 1$
增广输入向量
输入处理
拼接前一时刻输出$\hat{y}_{t-1}$与当前输入$x_t$形成增广向量
矩阵乘法:$W_f \cdot [\hat{y}_{t-1}, x_t]$
非线性变换
通过sigmoid函数$\sigma$将结果压缩到[0,1]区间
输出值$f_t$表示记忆保留比例
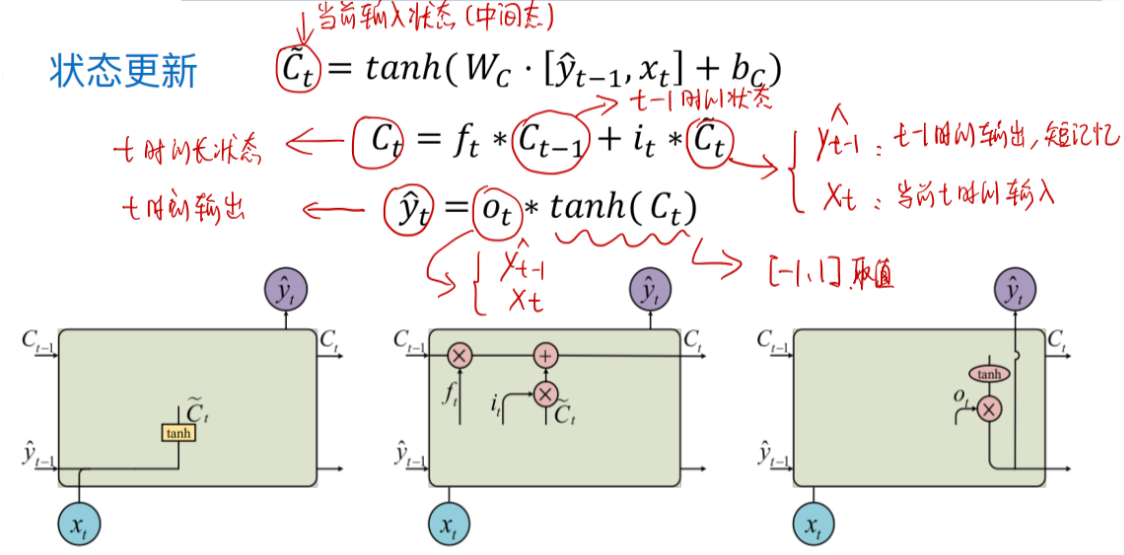
状态更新
它决定了当前时刻网络的输入 $x_t$ 有多少保存到单元状态 $c_t$(简单来说就是:控制新信息进入神经网络状态的程度)
$$
参数说明表
符号
维度
作用
$W_i$
$n \times (k+m)$
输入门权重矩阵
$b_i$
$n \times 1$
输入门偏置项
$i_t$
$n \times 1$
输入门输出值
与其他门的区别
门类型
输出变量
核心功能
激活值范围
输入门
$i_t$
控制新信息流入
[0,1]
遗忘门
$f_t$
控制历史记忆保留
[0,1]
输出门
$o_t$
控制当前输出
[0,1]
输出门(Output Gate)
控制单元状态 $c_t$ 有多少输出到 LSTM 的当前输出值 $h_t$(简单来说就是:控制当前时刻信息 的输出强度)
$$
参数说明
符号
维度
作用
$W_o$
$n \times (k+m)$
输出门权重矩阵
$b_o$
$n \times 1$
输出门偏置项
$o_t$
$n \times 1$
门控输出值
状态更新
之前的三个门在未组合进行状态更新之前,本质上都只是一个简单映射。
⭐️⭐️LSTM API⭐️⭐️ 1 2 3 torch.nn.LSTM(input_size, hidden_size, num_layers=1 , bias=True , batch_first=False , dropout=0 , bidirectional=False )
关键参数说明:
参数
类型
说明
input_size
int
输入特征维度
hidden_size
int
隐藏状态维度
num_layers
int
堆叠的LSTM层数(默认1)
batch_first
bool
输入/输出形状是否为(batch, seq, feature)
dropout
float
层间dropout概率(0表示不使用)
bidirectional
bool
是否使用双向LSTM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import torch.nn as nnlstm = nn.LSTM(input_size=10 , hidden_size=20 , num_layers=2 ) input = torch.randn(5 , 3 , 10 ) h0 = torch.randn(2 , 3 , 20 ) c0 = torch.randn(2 , 3 , 20 ) output, (hn, cn) = lstm(input , (h0, c0))
GRU
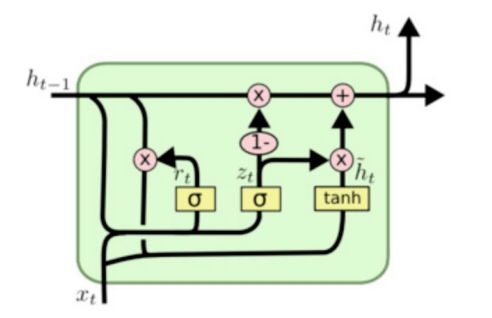
GRU(Gate Recurrent Unit)是循环神经网络(RNN)的一种,可以解决RNN中不能长期记忆和反向传播中的梯度等问题,与LSTM的作用类似,不过比LSTM简单,容易进行训练。GRU模型中有两个门,重置门和更新门。
参考链接:
符号
含义
$x_{t}$
当前时刻输入信息
$h_{t-1}$
上一时刻的隐藏状态(神经网络记忆,包含历史数据信息)
$h_{t}$
传递到下一时刻的隐藏状态
$\tilde{h}_{t}$
候选隐藏状态
$r_{t}$
重置门
$z_{t}$
更新门
激活函数说明
Sigmoid函数(σ)
作用:将数据压缩到[0,1]范围
典型应用:门控机制(重置门/更新门)
Tanh函数
作用:将数据压缩到[-1,1]范围
典型应用:候选状态计算
⭐️重置门⭐️
下面会清晰的讲解:重置门决定了如何将新的输入信息与前面的记忆相结合 。
重置门公式
其中$W_r$是权重矩阵,用这个权重矩阵对$x^t$和$h^{t-1}$拼接而成的矩阵进行线性变换(两个矩阵相乘)。然后将两个矩阵相乘得到的值投入$sigmod$函数,会得到$r^t$的值,比如:0.6。这个值会用到候选隐藏状态的公式中,即下面这个公式:t = \tanh(W \cdot [r_t * h {t-1}, x_t])
对上述公式展开:t = \tanh(x_tW {xh}+(r_t * h_{t-1})W_{hh}+b_h)
可以观察到:
$r_t$越小,$r_t * h_{t-1}$越小,$(r_t * h_{t-1})W_{hh}$越小,因此说明上一刻需要遗忘的越多,丢弃的越多。
$r_t$越大,$r_t * h_{t-1}$越大,$(r_t * h_{t-1})W_{hh}$越大,说明上一刻需要记住的越多,新的输入信息也就是$x_t$与前面的记忆相结合的越多
当$r_t$越接近1,$(r_t * h_{t-1})W_{hh}$值也接近1,表示保留上一时刻的隐藏状态。
⭐️更新门⭐️
更新门公式:
$$
$z_t$越接近1,记忆下来的数据越多;$z_t$越接近0则代表遗忘的越多。
$(1-z_t)*h_{t-1}$:表示对上一时刻隐藏状态进行选择性“遗忘”。忘记$h_{t-1}$中一些不重要的信息,把不相关的丢弃
$z_t*\tilde{h}_t$:表示对候选隐藏状态的进一步选择性”记忆”。会忘记$\tilde{h}_t$,中的一些不重要的信息。
综上
$$
$h_t$忘记传递下来的 $h_{t-1}$中的某些信息,并加入当前节点输入的某些信息。这就是最终的记忆。
门控循环单元GRU不会随时间而清除以前的信息,它会保留相关的信息并传递到下一个单元。
所使用的公式-整合 GRU通过以下门控机制计算当前时刻的隐藏状态:
更新门(Update Gate)
控制历史记忆的保留比例
使用Sigmoid激活输出[0,1]区间值
重置门(Reset Gate)
决定历史记忆对候选状态的影响程度
同样使用Sigmoid激活
候选隐藏状态 t = \tanh(W \cdot [r_t * h {t-1}, x_t])
融合当前输入与筛选后的历史记忆
使用Tanh激活输出[-1,1]区间值
最终隐藏状态
通过更新门平衡历史记忆与当前信息
形成新的记忆状态传递给下一时间步
GRU API 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 mygru = nn.GRU(5 , 6 , 2 ) input = torch.randn(1 , 3 , 5 ) h0 = torch.randn(2 , 3 , 6 ) output, hn = mygru(input , h0) print ('output-->' , output.shape, output)print ('hn--->' , hn.shape, hn)
注意事项
随机性说明 :
由于使用torch.randn(),每次运行具体数值不同,但维度结构保持稳定
批处理优势 :
同时处理3个样本,效率高于串行处理
每个样本的隐藏状态独立计算
多层GRU特性 :
第1层输出作为第2层输入
最终hn包含各层的最终状态
实际应用扩展 :
1 2 3 print ("样本1的输出:" , output[0 , 0 , :].detach().numpy())
该结果展示了GRU处理序列数据的基础能力,后续通常需要添加全连接层等结构完成具体任务。
从0-1实现RNN人名分类器案例
该案例旨在实现RNN人名分类器案例,即输入一个人名,使用模型判断该人名可能来自哪个国家。
业务应用场景包括:
用户注册过程中,根据填写的姓名自动分配国家/地区信息
限制手机号码位数等表单验证
提升用户体验和注册效率
数据获取
https://download.pytorch.org/tutorial/data.zip
数据特点
从0到1实现人名分类器
技术路线1:以单词为单位,word2id后送给RNN模型抽取事物特征进行分类。这样每个姓氏只能整体送1次。word2id,找到姓名对应的张量,送入到RNN中。
技术路线2:比如:z-h-a-n-g以字母为单位,送给RNN模型抽取事物特征进行分类。
数据处理流程 导包 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderimport stringimport timeimport matplotlib.pyplot as pltall_letters = string.ascii_letters + ".,;‘" n_letters = len (all_letters) categorys = ["Italian" ,"English" ,"Arabic" ,"Spanish" ,"Scottish" ,"Irish" ,"Chinese" ,"Vietnamese" ,"Japanese" ,"French" ,"Greek" ,"Dutch" ,"Korean" ,"Polish" ,"Portuguese" ,"Russian" ,"Czech" ,"German" ] categorynum = len (categorys)
读取数据到内存 1 2 3 4 5 6 7 8 9 def read_data (filename ): my_list_x, my_list_y = [], [] with open (filename, mode='r' , encoding='utf-8' ) as f: for line in f.readlines(): x, y = line.strip().split('\t' ) my_list_x.append(x) my_list_y.append(y) return my_list_x, my_list_y
构建Dataset类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class NameClassDataset (Dataset ): def __init__ (self, my_list_x, my_list_y ): self.my_list_x = my_list_x self.my_list_y = my_list_y self.sample_len = len (my_list_x) def __len__ (self ): return self.sample_len def __getitem__ (self, index ): x = self.my_list_x[index] y = self.my_list_y[index] tensor_x = torch.zeros(len (x), n_letters) for line, letter in enumerate (x): tensor_x[line][all_letters.find(letter)] = 1 tensor_y = torch.tensor(categorys.index(y), dtype=torch.long) return tensor_x, tensor_y
NOTE:
构建DataLoader 1 2 3 my_list_x, my_list_y = read_data('./data/name_classfication.txt' ) my_nameclassdataset = NameClassDataset(my_list_x, my_list_y) mydataloader = DataLoader(dataset=my_nameclassdataset, batch_size=1 , shuffle=True )
DataLoader类参数详解:
dataset:绑定前面创建的数据集对象batch_size=1:每批返回1个样本
shuffle=True:每个epoch打乱数据顺序
模型构建 RNN模型实现
创建RNN类,继承自nn.Module
初始化方法:
input_size:输入特征维度(本案例中为57,对应字母表大小)hidden_size:隐藏层维度(文档中设为128)output_size:输出类别数(本案例为18个国家)num_layers:RNN层数(默认为1)self.linear:全连接层
nn.LogSoftmax:对数softmax
配合NLLLoss使用更数值稳定
dim=-1表示在最后一个维度计算
向前传播方法:
input = input.unsqueeze(1):在指定维度插入一个大小为1的新维度
原始形状 :[seq_len, input_size] (如 [5, 57],表示5个字符,每个字符57维特征)变换后形状 :[seq_len, 1, input_size] (如 [5, 1, 57])
self.rnn(input, hidden)进行向前计算,看到这里还懵了,翻了源码想着源码可能有nn.RNN对象的rnn()方法,后来才发现没有,初步猜测这是递归,但大模型说这是正常调用:
rr:所有时间步的输出 [seq_len,1,hidden_size]hn:最后时间步的隐藏状态 [num_layers,1,hidden_size]
tmprr = rr[-1] 取最后时间步 [1,hidden_size]
tmprr = self.linear(tmprr)
return self.softmax(tmprr), hn
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class RNN (nn.Module): def __init__ (self, input_size, hidden_size, output_size, num_layers=1 ): super (RNN, self).__init__() self.rnn = nn.RNN(input_size, hidden_size, num_layers) self.linear = nn.Linear(hidden_size, output_size) self.softmax = nn.LogSoftmax(dim=-1 ) def forward (self, input , hidden ): input = input .unsqueeze(1 ) rr, hn = self.rnn(input , hidden) tmprr = rr[-1 ] tmprr = self.linear(tmprr) return self.softmax(tmprr), hn def inithidden (self ): return torch.zeros(self.num_layers, 1 , self.hidden_size)
LSTM模型实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class LSTM (nn.Module): def __init__ (self, input_size, hidden_size, output_size, num_layers=1 ): super (LSTM, self).__init__() self.lstm = nn.LSTM(input_size, hidden_size, num_layers) self.linear = nn.Linear(hidden_size, output_size) self.softmax = nn.LogSoftmax(dim=-1 ) def forward (self, input , hidden, c0 ): input = input .unsqueeze(1 ) rr, (hn, cn) = self.lstm(input , (hidden, c0)) tmprr = rr[-1 ] tmprr = self.linear(tmprr) return self.softmax(tmprr), hn, cn def inithidden (self ): return torch.zeros(self.num_layers, 1 , self.hidden_size)
GRU模型实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class GRU (nn.Module): def __init__ (self, input_size, hidden_size, output_size, num_layers=1 ): super (GRU, self).__init__() self.gru = nn.GRU(input_size, hidden_size, num_layers) self.linear = nn.Linear(hidden_size, output_size) self.softmax = nn.LogSoftmax(dim=-1 ) def forward (self, input , hidden ): input = input .unsqueeze(1 ) rr, hn = self.gru(input , hidden) tmprr = rr[-1 ] tmprr = self.linear(tmprr) return self.softmax(tmprr), hn def inithidden (self ): return torch.zeros(self.num_layers, 1 , self.hidden_size)
模型训练 训练流程
myadam = optim.Adam(myrnn.parameters(), lr=1e-3)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def my_train_rnn (): my_list_x, my_list_y = read_data('./data/name_classfication.txt' ) my_nameclassdataset = NameClassDataset(my_list_x, my_list_y) myrnn = RNN(57 , 128 , 18 ) mycrossentropyloss = nn.NLLLoss() myadam = optim.Adam(myrnn.parameters(), lr=1e-3 ) for epoch_idx in range (epochs): for i, (x, y) in enumerate (mydataloader): output_y, hidden = myrnn(x[0 ], myrnn.inithidden()) myloss = mycrossentropyloss(output_y, y) myadam.zero_grad() myloss.backward() myadam.step() total_iter_num += 1 total_loss += myloss.item() if total_iter_num % 100 == 0 : tmploss = total_loss / total_iter_num total_loss_list.append(tmploss) torch.save(myrnn.state_dict(), f'./my_rnn_model_{epoch_idx+1 } .bin' ) return total_loss_list, total_time, total_acc_list
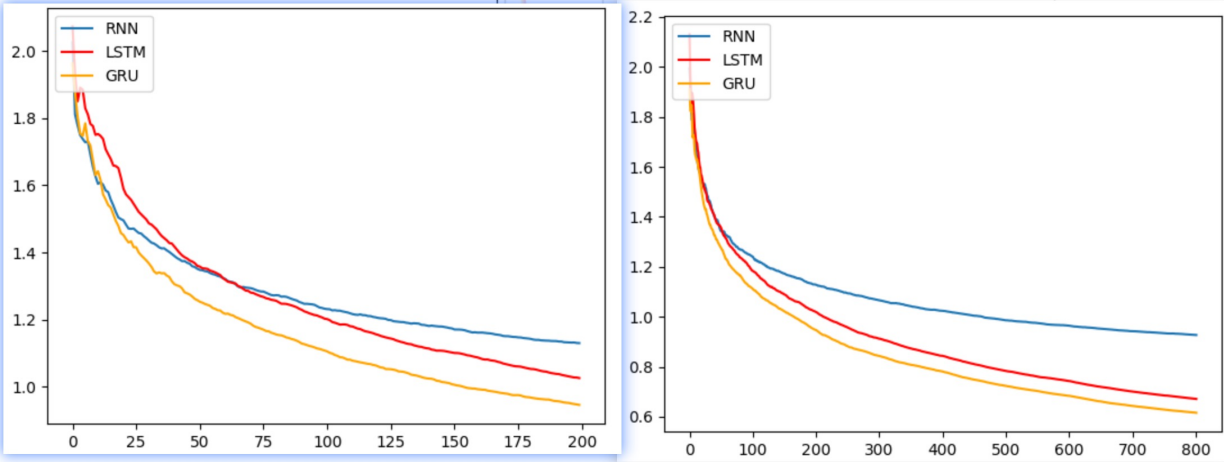
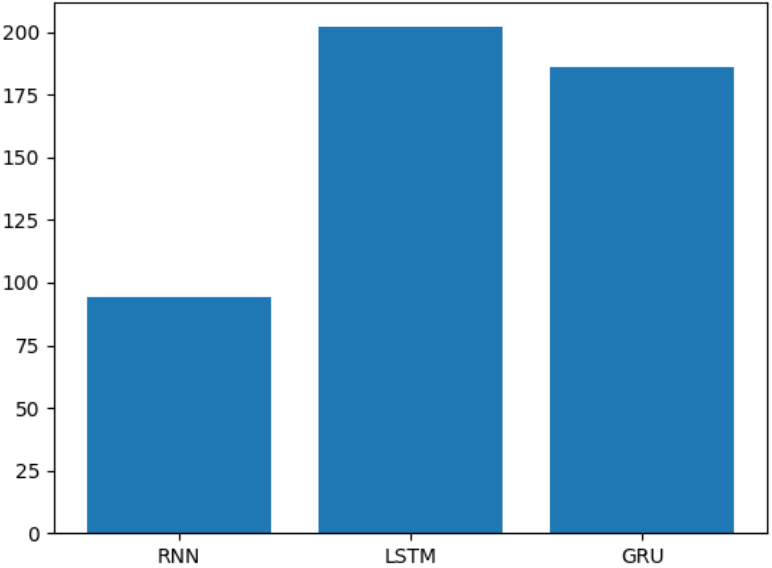
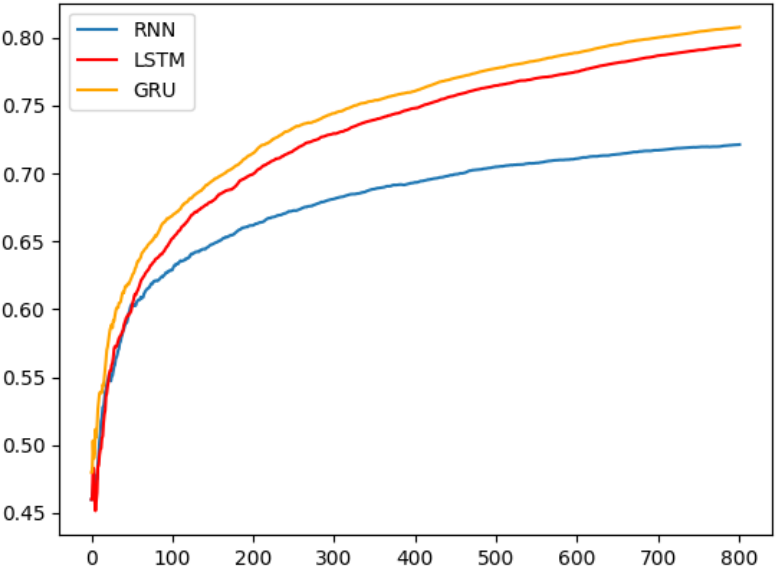
模型效果对比 从实验结果来看,三种模型各有优劣:
损失对比:
第一个轮次RNN收敛最快
随着训练数据增加,GRU效果最好,LSTM次之,RNN最后
训练时间对比:
RNN复杂度最低,耗时最短
GRU次之,LSTM最耗时
准确率对比:
模型预测 预测函数实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def my_predict_rnn (x ): tensor_x = lineToTensor(x) myrnn = RNN(57 , 128 , 18 ) myrnn.load_state_dict(torch.load(my_path_rnn)) with torch.no_grad(): output, hidden = myrnn(tensor_x, myrnn.inithidden()) topv, topi = output.topk(3 , 1 , True ) print ('x===>' , x) for i in range (3 ): category_idx = topi[0 ][i] category = categorys[category_idx] print ('\t\t %s' % category)
预测示例 1 2 3 4 5 x ===> zhang Russian Chinese Vietnamese
实现建议与总结
模型选择建议 :
如果追求快速实现和简单模型:选择RNN
如果追求最佳准确率:选择GRU
如果需要处理更长序列:考虑LSTM
优化方向 :
尝试不同的隐藏层大小
调整学习率和训练轮次
尝试不同的优化器
增加更多训练数据
关键成功因素 :
合理的数据预处理(特别是one-hot编码)
适当的模型复杂度选择
充分的训练和调参
完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 import stringimport torch.nn as nnimport torchfrom tqdm import tqdm all_letters = string.ascii_letters + ".,;‘" categorys = ['Italian' , 'English' , 'Arabic' , 'Spanish' , 'Scottish' , 'Irish' , 'Chinese' , 'Vietnamese' , 'Japanese' , 'French' , 'Greek' , 'Dutch' , 'Korean' , 'Polish' , 'Portuguese' , 'Russian' , 'Czech' , 'German' ] print (all_letters.find('z' ))print (len (categorys))print (torch.tensor(4 , dtype=torch.long))rnn = nn.RNN(10 , 20 ) print (dir (rnn)) import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderimport stringimport time""" 按照字母进行送入数据 """ all_letters = string.ascii_letters + " .,;'" n_letters = len (all_letters) categorys = ['Italian' , 'English' , 'Arabic' , 'Spanish' , 'Scottish' , 'Irish' , 'Chinese' , 'Vietnamese' , 'Japanese' , 'French' , 'Greek' , 'Dutch' , 'Korean' , 'Polish' , 'Portuguese' , 'Russian' , 'Czech' , 'German' ] def read_data (filename ): my_list_x, my_list_y = [], [] with open (filename, mode='r' , encoding='utf-8' ) as f: for line in f.readlines(): x, y = line.strip().split('\t' ) my_list_x.append(x) my_list_y.append(y) return my_list_x, my_list_y class NameClassDataset (Dataset ): def __init__ (self, my_list_x, my_list_y ): self.my_list_x = my_list_x self.my_list_y = my_list_y self.sample_len = len (self.my_list_x) def __len__ (self ): return self.sample_len def __getitem__ (self, item ): x = self.my_list_x[item] y = self.my_list_y[item] tensor_x = torch.zeros(len (x), n_letters) for line, letter in enumerate (x): tensor_x[line][all_letters.find(letter)] = 1 tensor_y = torch.tensor(categorys.index(y), dtype=torch.long) return tensor_x, tensor_y class RNN (nn.Module): def __init__ (self, input_size, hidden_size, output_size, num_layers=1 ): super (RNN, self).__init__() self.input_size = input_size self.hidden_size = hidden_size self.output_size = output_size self.num_layers = num_layers self.rnn = nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers) self.linear = nn.Linear(in_features=hidden_size, out_features=output_size) self.softmax = nn.LogSoftmax(dim=-1 ) def forward (self, input , hidden ): input = input .unsqueeze(1 ) rr, hn = self.rnn(input , hidden) tmprr = rr[-1 ] tmprr = self.linear(tmprr) return self.softmax(tmprr), hn def inithidden (self ): return torch.zeros(self.num_layers, 1 , self.hidden_size) def dm02_test_RNN (): myrnn = RNN(57 , 128 , 18 ) print ('myrnn-->' , myrnn) input = torch.randn(6 , 57 ) hidden = myrnn.inithidden() output, hidden = myrnn(input , hidden) print ('output-->' , output.shape, output) print ('hidden-->' , hidden.shape) hidden = myrnn.inithidden() for i in range (input .shape[0 ]): tmp = input [i].unsqueeze(0 ) output, hidden = myrnn(tmp, hidden) print ('output-->' , output.shape, output) mylr = 1e-3 epochs = 1 def my_train_rnn (): my_list_x, my_list_y = read_data('./data/name_classfication.txt' ) mynameclassdataset = NameClassDataset(my_list_x, my_list_y) mydataloader = DataLoader(dataset=mynameclassdataset, batch_size=1 , shuffle=True ) my_rnn = RNN(57 , 128 , 18 ) print ('my_rnn-->' , my_rnn) mycrossentropyloss = nn.NLLLoss() myadam = optim.Adam(params=my_rnn.parameters(), lr=mylr) starttime = time.time() total_iter_num = 0 total_loss = 0 total_loss_list = [] total_acc_num = 0 total_acc_list = [] for epoch_idx in range (epochs): for i, (x, y) in enumerate (tqdm(mydataloader)): output_y, hidden = my_rnn(x[0 ], my_rnn.inithidden()) myloss = mycrossentropyloss(output_y, y) myadam.zero_grad() myloss.backward() myadam.step() total_iter_num += 1 total_loss += myloss.item() itag = (1 if torch.argmax(output_y).item() == y.item() else 0 ) total_acc_num += itag if total_iter_num % 100 == 0 : tmploss = total_loss / total_iter_num total_loss_list.append(tmploss) tmpacc = total_acc_num / total_iter_num total_acc_list.append(tmpacc) if total_iter_num % 2000 == 0 : print ('轮次:%d, 损失:%.6f, 时间:%d,准确率:%.3f' % \ (epoch_idx + 1 , tmploss, time.time() - starttime, tmpacc)) torch.save(my_rnn.state_dict(), './my_rnn_model_%d.bin' % (epoch_idx + 1 )) total_time = int (time.time() - starttime) return total_loss_list, total_time, total_acc_list if __name__ == '__main__' : my_train_rnn()


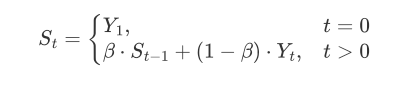
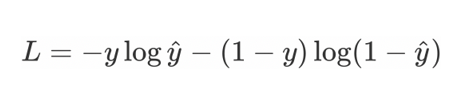


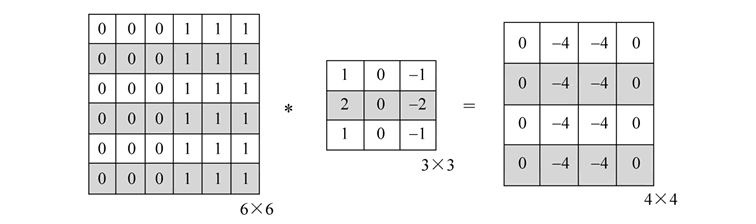

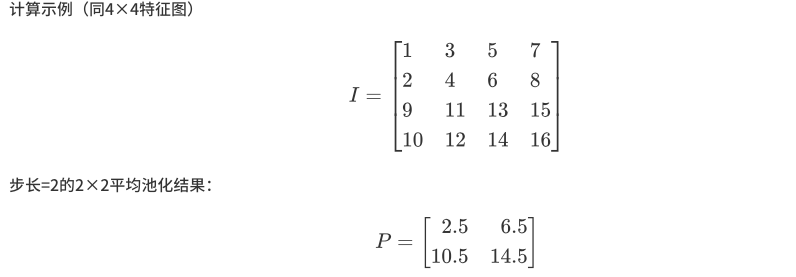
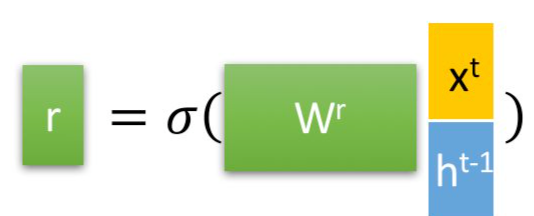
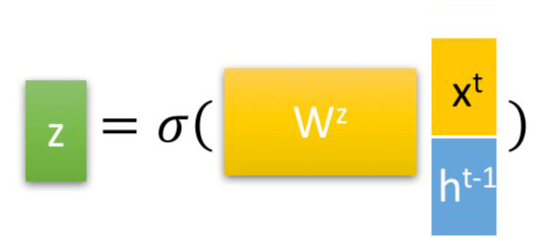

 微信
微信 支付宝
支付宝