
【Pandas】掌管数据挖掘的神
Pandas补充
为什么要补充?因为这篇文章总结的是23年左右的知识点,随着Pandas的不断更新以及更多业务场景的不断涌现,Pandas知识点就需要扩充了,而且重要的都标了⭐️,Respect!!
⭐️⭐️Pandas案例
1 | import pandas as pd |
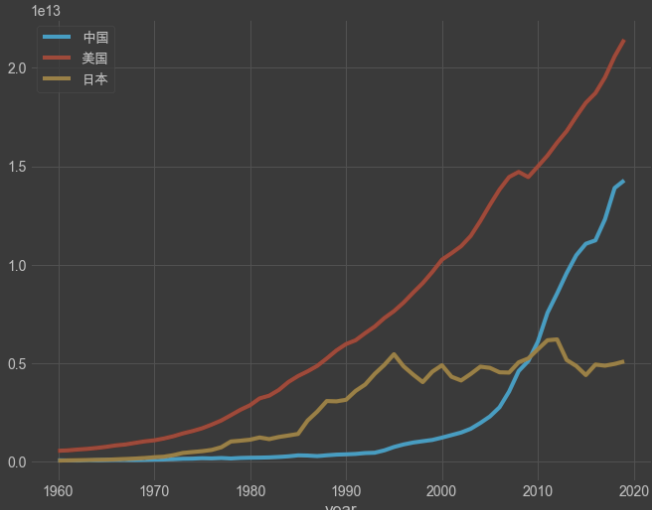
绘图展示 :
⭐️⭐️⭐️Series
创建
Series是什么?可以理解为向量
创建Series的方式呢?
- 通过列表、字典、元组都可以作为pd.Series()的数据输入
- 也可以使用numpy的arange函数也可以作为pd.Series()的数据输入
1 | import pandas as pd |
Series属性和方法
1 | # 练习Series的属性和方法(index, values, 根据索引获取value) |
⭐️⭐️⭐️DataFrame
创建DataFrame
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
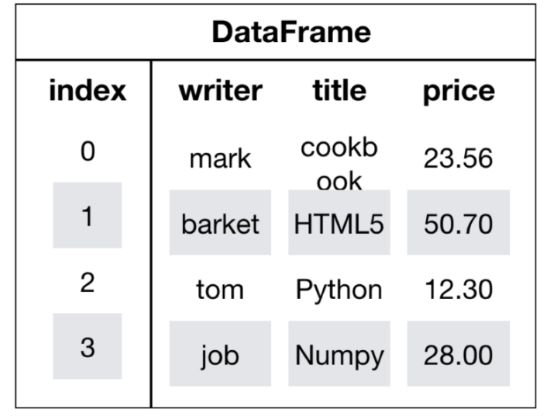
同Series一样,DataFrame也可以接收多种类型的数据并封装成DataFrame。
- 从文件中读取:pd.read_csv(‘csv格式数据文件路径’)
- 列表嵌套字典
- 列表嵌套元组
通过ndarray创建DataFrame
- 想想numpy的创建Ndarray方法?
1 | # 创建DataFrame的三种方式, |
DataFrame属性
查看shape属性
- data.shape
查看index属性
- data.index
查看 columns
- data.columns
查看values
- data.values
转置
- data.T
1 | import pandas as pd |
DataFrame对象方法
对于大型数据集,可以先查看部分数据
- large_data = pd.read_csv(‘big_dataset.csv’)
- print(large_data.head(10)) # 查看前10行了解数据结构
- print(large_data.tail(8)) # 查看后8行检查数据完整性
- 显示前n行内容
- head(n)
- 显示后n行内容(如果不补充参数,默认5行。填入参数n则显示后n行)
- data.tail(5)
1 | import pandas as pd |
DatatFrame索引的设置
需求:
- 1- 修改行列索引值
1 | stu = ["学生_" + str(i) for i in range(score_df.shape[0])] |
注意:以下修改方式是错误的
1 | # 错误修改方式 |
- 2- 重设索引
- reset_index(drop=False)
- 设置新的下标索引
- drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
- reset_index(drop=False)
1 | # 重置索引,drop=False |
- 以某列值设置为新的索引
- set_index(keys, drop=True)
- keys : 列索引名成或者列索引名称的列表
- drop : boolean, default True.当做新的索引,删除原来的列
- set_index(keys, drop=True)
1 | # 重置索引,drop=True |
代码
1 | df = pd.DataFrame({'month': [1, 4, 7, 10], |
Pandas数据类型
| Pandas数据类型 | 说明 | 对应的Python类型 |
|---|---|---|
| Object | 字符串类型 | string |
| int | 整数类型 | int |
| float | 浮点数类型 | float |
| datetime | 日期时间类型 | datetime包中的datetime类型 |
| timedelta | 时间差类型 | datetime包中的timedelta类型 |
| category | 分类类型 | 无原生类型,可以自定义 |
| bool | 布尔类型 | bool(True,False) |
| nan | 空值类型 | None |
- 可以通过下列API查看s对象或df对象中数据的类型
1 | s1.dtypes |
几个特殊类型演示
- datetime类型
1
2
3
4
5import pandas as pd
# 创建一个datetime类型的Series
dates = pd.to_datetime(['2024-09-01', '2024-09-02', '2024-09-03'])
print(dates)- timedelta类型
1
2
3
4
5
6
7import pandas as pd
# 计算两个日期之间的差值
start_date = pd.to_datetime('2024-09-01')
end_date = pd.to_datetime('2024-09-05')
delta = end_date - start_date
print(delta)- category类型
类型用于表示分类数据,通常用于有限集合中的数据类型,例如性别、颜色、产品类型等。这种类型的优点在于占用更少的内存,并且对分类数据的操作更快。
1
2
3
4
5import pandas as pd
# 创建一个category类型的Series
categories = pd.Series(['apple', 'banana', 'apple', 'orange'], dtype='category')
print(categories)
⭐️⭐️⭐️Pandas基本数据操作
读取、写入数据
获取数据方式有很多,包括去取CSV、MySQL、JSON、HDF5等等一些数据
MySQL建立连接需要install包
1 | pip install pymysql==1.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/ |
1 | import pandas as pd |

⭐️⭐️⭐️索引操作
- 直接索引方式(先列后行):
1 | # 直接使用行列索引名字的方式(先列后行) |
- 结合loc或者iloc使用索引
- loc后面是行列索引名称
- 而iloc后面写index,正如名称带了i(index)
1 | # 使用loc:只能指定行列索引的名字 |
⭐️⭐️赋值操作
- 会将close(收盘价)全部的值设置为1
1 | # 直接修改原来的值 |
⭐️⭐️排序操作
- dataframe
- 对象.sort_values()
- 对象.sort_index()
- series
- 对象.sort_values()
- 对象.sort_index()
- DataFrame排序
1 | # 按照开盘价大小进行排序 , 使用ascending指定按照大小排序 |
- Series排序
1 | data['p_change'].sort_values(ascending=True).head() |
⭐️⭐️DataFrame运算
算术运算
- add(other)
比如进行数学运算加上具体的一个数字
1 | data['open'].add(1) |
- sub(other)
比如进行数学运算减去具体的一个数字
1 | data['open'].sub(1) |
⭐️⭐️逻辑运算
1 | data[(data["open"] > 23) & (data["open"] < 24)].head() |
- query(expr)
- expr:查询字符串
通过query使得刚才的过程更加方便简单
1 | data.query("open<24 & open>23").head() |
- isin(values)
例如判断’open’是否为23.53和23.85
1 | # 可以指定值进行一个判断,从而进行筛选操作 |
统计运算
1 | # 计算平均值、标准差、最大值、最小值 |
累计统计
1 | ### 累计统计 ### |
apply自定义函数
1 | # 定义一个对列,最大值-最小值的函数 |
⭐️⭐️⭐️DataFrame数据的增删改查操作
增加
1 | # 一列数据都是固定值 |
- 使用assign函数增加
1 | # 通过assign增加一列 |
删除与去重
1- df.drop删除行数据
1 | df3.drop([0]) # 默认删除行 |
2- df.drop删除列数据1
- df.drop默认删除指定索引值的行;如果添加参数
axis=1,则删除指定列名的列
1 | df3.drop(['new col 3'], axis=1) |
3- 使用del删除指定的列
- 注意区别:
- del是直接永久删除原df中的列【慎重使用】
- drop是返回删除后的df或seires,原df或seires没有被修改
1 | del df3['new col 3'] |
4- Dataframe数据去重
1 | # 添加一部分重复的数据 |
5- series去重
1 | 方式一: |
修改
1 | df5 = df5.assign(GDP=66) # 可以接收单变量或列表、数组 |
查询
- 1- 从前从后取多行数据
head()
1 | # 导包 |
tail()
1 | # 默认取后5行数据 |
2- 获取一列或多列数据
- 获取一列数据
df[col_name]等同于df.col_name
1 | df2['country'] |
获取多列数据df[[col_name1,col_name2,...]]
1 | df2[['country', 'GDP']] # 返回新的df |
3- 索引下标切片取行
df[start:stop:step]:
df[start:stop:step]==df[起始行下标:结束行下标:步长], 遵循顾头不顾尾原则(包含起始行,不包含结束行),步长默认为1
1 | df4 = df.head(10) # 取原df前10行数据作为df4,默认自增索引由0到9 |
4- 查询函数获取子集: df.query()
df.query(判断表达式)可以依据判断表达式返回的符合条件的df子集- 与
df[布尔值向量]效果相同- 特别注意
df.query()中传入的字符串格式
1 | df3.query('country=="帕劳"') |
1 | # 查询中国, 美国 日本 三国 2015年至2019年的数据 |
5- 排序函数
- sort_values函数: 按照指定的一列或多列的值进行排序
1 | # 按GDP列的数值由小到大进行排序 |
rank函数:
- rank函数用法:
DataFrame.rank()或Series.rank()- rank函数返回值:以Series或者DataFrame的类型返回数据的排名(哪个类型调用返回哪个类型)
- rank函数包含有6个参数:
- axis:设置沿着哪个轴计算排名(0或者1),默认为0按纵轴计算排名
- numeric_only:是否仅仅计算数字型的columns,默认为False
- na_option :NaN值是否参与排序及如何排序,固定参数:keep top bottom
- keep: NaN值保留原有位置
- top: NaN值全部放在前边
- bottom: NaN值全部放在最后
- ascending:设定升序排还是降序排,默认True升序
- pct:是否以排名的百分比显示排名(所有排名与最大排名的百分比),默认False
- method:排名评分的计算方式,固定值参数,常用固定值如下:
- average : 默认值,排名评分不连续;数值相同的评分一致,都为平均值
- min : 排名评分不连续;数值相同的评分一致,都为最小值
- max : 排名评分不连续;数值相同的评分一致,都为最大值
- dense : 排名评分是连续的;数值相同的评分一致
1 | df7 = pd.DataFrame({ |
⭐️⭐️⭐️缺失值处理
缺失值为NAN
删除
1 | # 不修改原数据 |
替换/填充
1 | # 替换存在缺失值的样本的两列 |
缺失值是特殊字符
1 | wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data") |
以上数据在读取时,可能会报如下错误:
1 | URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:833)> |
解决办法:
1 | # 全局取消证书验证 |
数据合并
- pd.concat实现数据的合并 => union
- pd.merge实现数据的合并 => join
concat
pd.concat([data1, data2], axis=1)
- 按照行或列进行合并,axis=0为列索引,axis=1为行索引
1 | import pandas as pd |
merge
pd.merge(left, right, how=’inner’, on=None)
- 可以指定按照两组数据的共同键值对合并或者左右各自
left: DataFrameright: 另一个DataFrameon: 指定的共同键- how:按照什么方式连接
数据分组
分组
1 | # 导包 加载数据集 |
分组聚合
1 | # 按城市和线上线下划分,分别计算销售金额的平均值、成本的总和 |
分组过滤
1 | # 按城市分组,查询每组销售金额平均值大于200的全部数据 |
交叉表与透视表
交叉表:
交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表)
- pd.crosstab(value1, value2)
透视表:
透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数
- data.pivot_table()
- DataFrame.pivot_table([], index=[])
交叉表
1 | import pandas as pd |
透视表
1 | import pandas as pd |
案例分析
数据准备
- 准备两列数据,星期数据以及涨跌幅是好是坏数据
- 进行交叉表计算
1 | # 寻找星期几跟股票张得的关系 |
但是我们看到count只是每个星期日子的好坏天数,并没有得到比例,该怎么去做?
- 对于每个星期一等的总天数求和,运用除法运算求出比例
1 | # 算数运算,先求和 |
查看效果
使用plot画出这个比例,使用stacked的柱状图
1 | pro.plot(kind='bar', stacked=True) |
使用pivot_table(透视表)实现
使用透视表,刚才的过程更加简单
1 | # 通过透视表,将整个过程变成更简单一些 |
⭐️⭐️Pandas综合案例⭐️⭐️
两个案例对接实际业务场景,算是Pandas的入门经典案例了。
题目

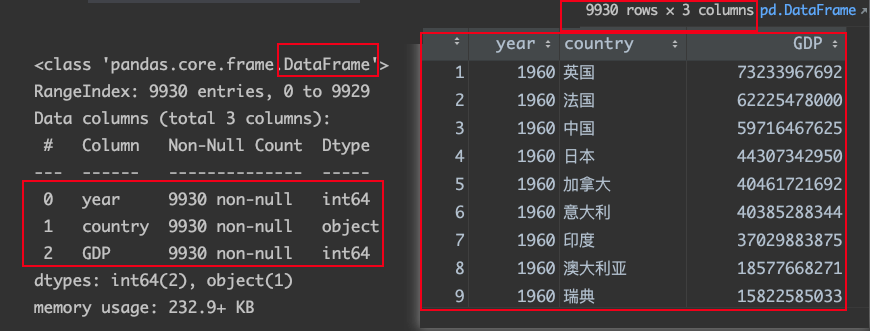
GDP案例
源数据长这样
1 | import pandas as pd |
优衣库案例
算是很经典的案例了吧,网上有很多demo。
1 | import pandas as pd |
⭐️RFM案例⭐️
RFM是什么?
Recency:最近一次购买时间
Frequency:购买频率
Monetary:购买金额
需求说明:

原始数据长这样:
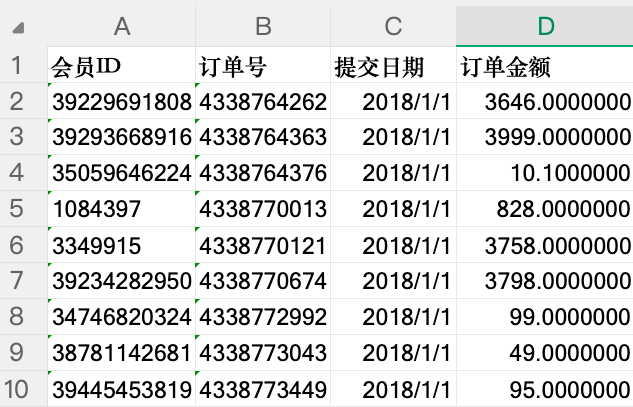
注意事项
- 如果Excel有多个Sheet,则pd.read_excel会生成字典:{‘Sheet名称’: ‘Sheet对应的DataFrame’}
- 多个DataFrame进行Concat会上下拼接(类似Union all)但注意设置ignore_redex=False
- pd[‘提交日期’].dt.year会获取日期的年(类似还有:dt.month、dt.days)
- 重命名DataFrame中的Column:
- df.columns = [‘year’, ‘会员ID’, ‘r’, ‘f’, ‘m’]
- pd.cut(column,bins列表,labels=[3, 2, 1])会根据bins划分的区间对DataFrame中的column列进行打标,标签为labels中对应的数据,如:
- df[‘r_lable’] = pd.cut(df[‘r’], bins=r_bins, labels=[3, 2, 1])
代码
1 | import pandas as pd |
代码带详细注释
1 | import time #:用来记录插入数据库时的当前日期 |
引言
为什么使用Pandas:
- 以Numpy为基础,借力Numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
- 读取文件方便
- 封装了Matplotlib、Numpy的画图和计算
举例论证
增强图表可读性
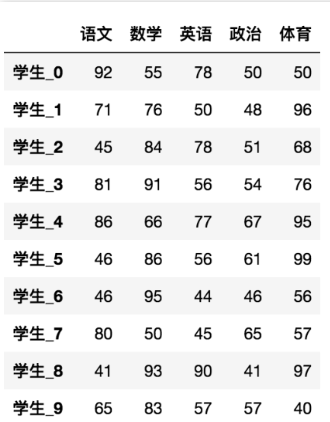
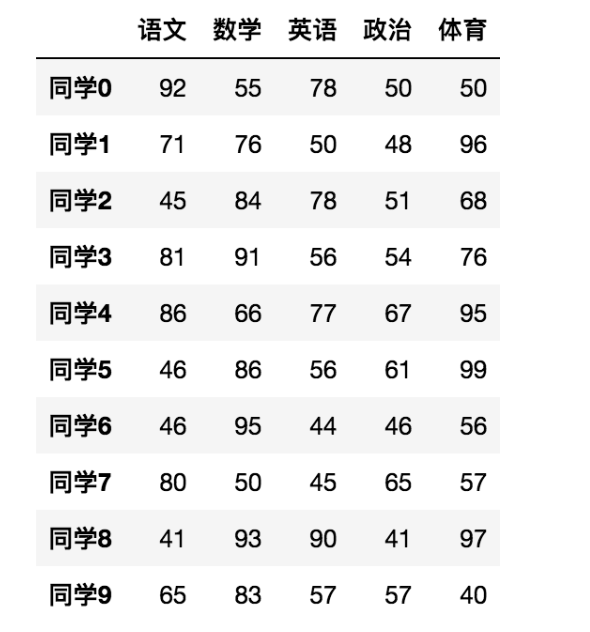
- 在numpy当中创建学生成绩表样式:
返回结果:
1 | array([[92, 55, 78, 50, 50], |
如果数据展示为这样,可读性就会更友好:
Pandas数据结构
Pandas中一共有三种数据类型,分别为:Series、DataFrame和MultiIndex(老版本中叫Panel )。
其中Series是一维数据类型,DataFrame是二维的表格型数据类型,MultiIndex是三维的数据类型。
Series
Pandas中的Series类似于线性代数中的列向量(补充:也可以是行向量)。
- pd.Series(data, index, dtype):创建一个列向量
- 注意:data可以为数组,也可以为字典
- 同时,在如果是一个数组的时候可以指定索引,也就是index前面的data每一个数字的索引位置
- Series.index:获取该列向量的全部索引index
- Series.values:获取该列向量所有的数值data
1 | import pandas as pd |
DataFrame
DataFrame相当于线性代数中的矩阵。
除了注意DataFrame中的数据,DataFrame中的行列索引也是比较重要的东西。
怕弄混,这里搞个图片标记一下。
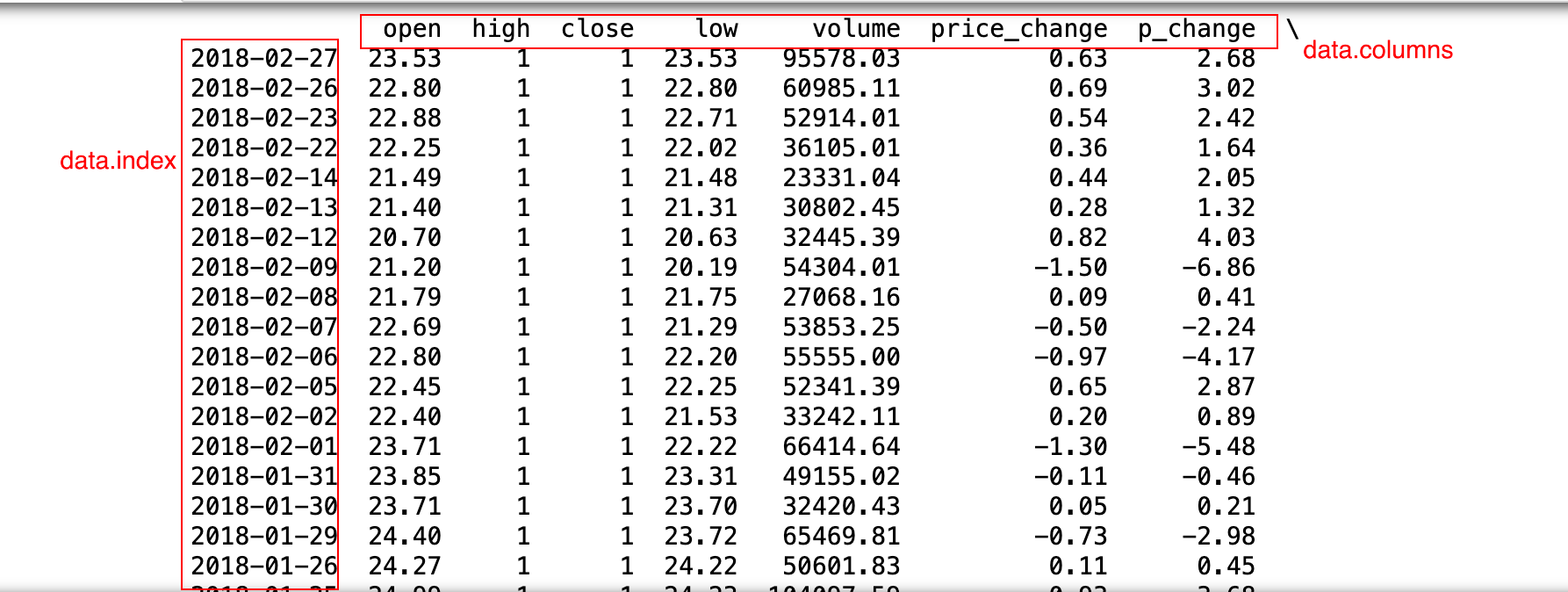
- pd.DataFrame(data, index, colunms):创建一个DataFrame
- 注意:传入的Data必须为二维数组
- pd.DataFrame(df, column, index):给一个已知的DataFrame重新添加索引
- 注意:column是横的,index是竖的就行了
- df.shape:输出当前DataFrame(df)的形状
- 下面的data就是DataFrame
- data.index : 行索引列表
- data.columns : 列索引列表
- data.values : 取其中array的值,类似于numpy的原始数据类型
- data.T : 将data进行转置(10, 5) -> (5, 10)
- data.head(5): 只显示data前五行的内容
- data.tail(5) : 只显示data后五行的内容
- df.index = [列表]:修改列索引(也就是修改竖的的那个索引
- df.reset_index(drop=True/False):重新设置新的索引
- df.set_index(‘month’):设置月份为当前DataFrame的索引
- 注意:一个DataFrame可以设置多个字段为索引,但是需要用[]列表的形式表示
- 如:df.set_index([‘year’, ‘month’])
1 | import numpy as np |
MultiIndex与Panel
MultiIndex是三维的数据类型;
多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。
其实简单理解就是多级索引,想象一张成绩表,张三学生下面有很多的学科,每一门学科都有各自的成绩。
再比如将数据分为1和2组,下面是pandas跑出来的结果:

1 | import pandas as pd |
Pandas的索引、切片基操
首先引入文件操作,Pandas支持读取的文件为CSV、SQL、XLS、JSON、HDF5。
注:最常用的HDF5和CSV文件
1 | # 读取文件 |
索引操作
- df[‘字段名称’]:取出某个DataFrame中的某一列
- df[‘列索引’][‘行索引’]:精确找到列索引+行索引所确定的某个值
- df.drop([‘字段1’, ‘字段2’….]):裁剪DataFrame,使列表里面的字段全部不显示or生成新的DataFrame
- df.loc[行,列]:这个是先行后列,也都是字段名称,跟上面第二个相反
- df.iloc[行索引下标,列索引下标]:这个iloc跟loc最大的区别就是iloc可以通过索引下标操作
- df.ix[行,列索引下标]:这个ix’就是将上面loc和iloc混在一块了,然后导致后面也用的比较少,就过时了
- 最重要的还是loc和iloc的组合操作
- df.index[下标切片]:获取DataFrame指定下标的索引,返回的是具体数字
- df.columns().get_indexer([字段1,字段2]):获取字段的列下标,返回的是下标
1 | import pandas as pd |
赋值操作
- df[‘字段’] = 固定数值:改变DataFrame中某一列的全部值
- df.字段 = 固定值:这个效果和上面的效果相同
1 | # 对DataFrame中的close列重新赋值为1 |
排序操作
DataFrame排序操作分两种,一种是对内容进行排序,另一种是对索引进行排序
- 对内容排序:
- df.sort_values(by=’字段名称’, ascending=True/False):按照某个字段(股价),升序/降序对数据排列
- 注意:这里的by是排序的依据,也可以是一个列表,如by=[‘open’, ‘high’]
- 对索引排序:
- df.sort_index()
Series的排序操作:排序之前需要搞到一个Series,所以Series = DataFrame[‘列名’]
- 对内容排序:
- Series.sort_values(ascending=True/False):因为只有一列,所以不需要排序依据by
- 对索引排序:
- Series.sort_index():不指定ascending的话默认为升序排序
1 | # 排序操作分为DataFrame排序和Series排序操作 |
DataFrame运算
算术运算&逻辑运算
一般用的比较少:
- Series.add(常数):DataFrame中的一个Series(某一列)加上一个常数。
- Series.sub(常数):同上,不想写了。
- df[‘字段’] > Integer:逻辑运算,满足上述逻辑的会输出为True
- df.isin([列表]):条件判断,DataFrame中存在列表中的数据就会标记为True
- 同样可以使用嵌套进行筛选,比如:data[data[‘open’].isin([23.53, 23.85])]
df[df['字段'] > Integer & df['字段'] < Integer]:嵌套逻辑,可以筛选数据
- 注意:这里的与是只有一个
&,而不是通常的双与符号&&df.query('字段 > Integer & 字段 < Integer '):通过query进行条件筛选,常用
1 | import pandas as pd |
统计运算
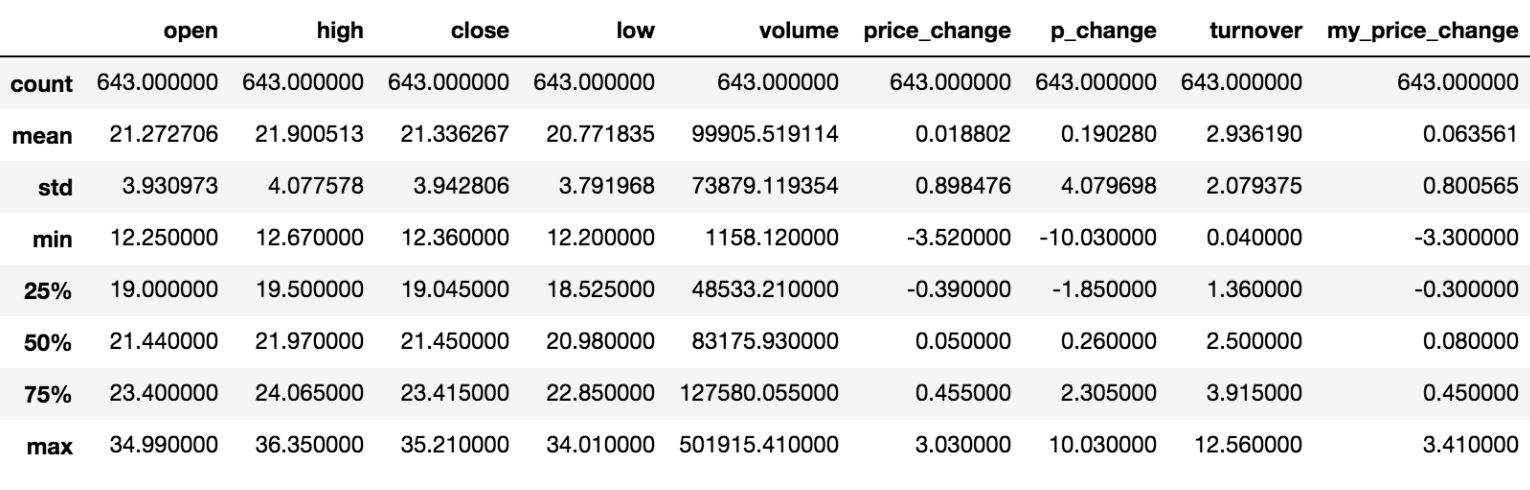
Numpy当中已经详细介绍,在这里主要有如下的函数需要了解:
min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差),mode(众数)
DataFram.describe(): 综合分析函数,能够得出很多结果,如平均值,标准差,最大值,最小值
DataFram.max(0/1):求DataFram中的最大值,使用位置参数axis,0代表按照列统计,1按照行统计
DataFrame.var(0/1):方差
DataFrame.std(0/1):标准差
DataFrame.median(0/1):中位数
DataFream.idxmax(0/1):最大值的下标
DataFrame.idxmin(0/1):最小值的下标
cum系列函数,在 Pandas 中,
cumsum()是一个用于计算累积和(cumulative sum)的方法。它可以对Series或DataFrame对象中的数据进行逐步累加,返回一个新的Series或DataFrame,其中每个元素是原始数据的累积和。
- Series.cumsum():对Series中的数值进行累加
cum系列函数
函数 作用 cumsum计算前1/2/3/…/n个数的和 cummax计算前1/2/3/…/n个数的最大值 cummin计算前1/2/3/…/n个数的最小值 cumprod计算前1/2/3/…/n个数的积
1 | import pandas as pd |
自定义运算apply
- apply(func, axis=0)
- func:自定义函数
- axis=0:默认是列,axis=1为行进行运算
- 定义一个对列,最大值-最小值的函数
1 | # 使用apply接口,通过编写匿名函数Lambda作为apply接口的参数 |
Pandas绘图
由于之前搞了Matplotlib的画图,但是没有说Pandas本身也能绘图,类似的还有Seaborn绘图,Pyecharts绘图
DataFrame绘图
DataFrame.plot(kind=’line’)
kind : str,需要绘制图形的种类
‘line’ : line plot (default)
‘bar’ : vertical bar plot
‘barh’ : horizontal bar plot
‘hist’ : histogram
‘pie’ : pie plot
‘scatter’ : scatter plot
更多信息:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.html
Series绘图
更多信息:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.plot.html
文件读取与存储
Pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5
csv、tsv文件
csv文件就是字段之间comma(逗号)分割,每条数据\n换行的格式文件;而tsv文件则是以\t作为字段之间分割,每条数据\n换行的格式文件。
- pandas.read_csv(filepath_or_buffer, sep =’,’, usecols )
- pandas可以简写为pd(前提是import pandas as pd)
- DataFrame.to_csv(path_or_buf=None, sep=’, ’, columns=None, header=True, index=True, mode=’w’, encoding=None)
- header :boolean or list of string, default True,是否写进列索引值
- index:是否写进行索引
- mode:’w’:重写, ‘a’ 追加
1 | import pandas as pd |
Json文件
JSON是我们常用的一种数据交换格式,前面在前后端的交互经常用到,也会在存储的时候选择这种格式。所以我们需要知道Pandas如何进行读取和存储JSON格式。
pandas.read_json(path_or_buf=None, orient=None, typ='frame', lines=False)
orient : string,Indication of expected JSON string format.
‘split’ : dict like {index -> [index], columns -> [columns], data -> [values]}
- split 将索引总结到索引,列名到列名,数据到数据。将三部分都分开了
‘records’ : list like [{column -> value}, … , {column -> value}]
- records 以
columns:values的形式输出‘index’ : dict like {index -> {column -> value}}
- index 以
index:{columns:values}...的形式输出‘columns’ : dict like {column -> {index -> value}}
,默认该格式
- colums 以
columns:{index:values}的形式输出‘values’ : just the values array
- values 直接输出值
lines : boolean, default False
- 按照每行读取json对象
typ : default ‘frame’, 指定转换成的对象类型series或者dataframe
DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
- 将Pandas 对象存储为json格式
- path_or_buf=None:文件地址
- orient:存储的json形式,{‘split’,’records’,’index’,’columns’,’values’}
- lines:一个对象存储为一行
1 | # 将JSON格式准换成默认的Pandas DataFrame格式 |
HDF5文件
Python跟HDF5文件交互需要使用到一个Tables依赖包,如果没有的话pip install tables
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
- pandas.read_hdf(path_or_buf,key =None,** kwargs)
- path_or_buffer:文件路径
- key:读取的键
- return:Theselected object
- DataFrame.to_hdf(path_or_buf, key, ***kwargs*)
1 |
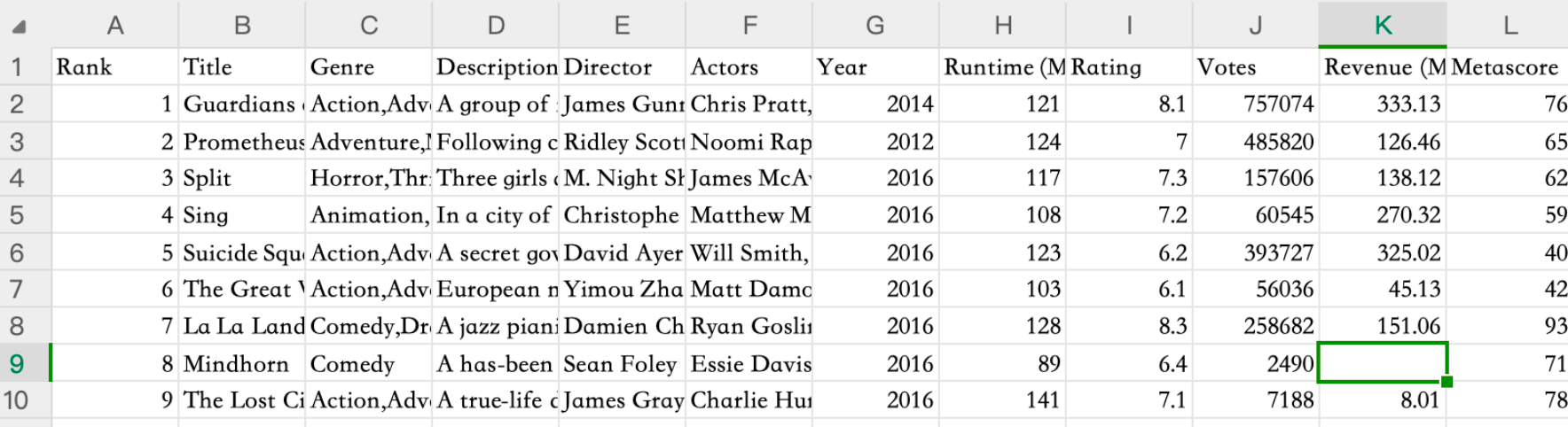
缺失值处理
对于缺失值处理,需要掌握的东西:
- 应用isnull判断是否有缺失数据NaN
- pd.notnull(movie)
- 标记DataFrame(movie)中不是Nan的为True,为Nan(空值)的为False
pd.isnull(movie)
- 跟notnull相反
应用fillna实现缺失值的填充
- movie[‘Revenue (Millions)’].fillna(movie[‘Revenue (Millions)’].mean(), inplace=True)
- 给税收这一列的所有nan值填充中位数
替换所有的缺失值,有三步很重要的步骤
- movie.columns
- if np.all(pd.notnull(movie[i])) == False
- movie[i].fillna(movie[i].mean(), inplace=True)
应用dropna实现缺失值的删除
- DataFrame.dropna():会直接删除Nan值所在的行
- 应用replace实现数据的替换
- wis = wis.replace(to_replace=”?”, value=np.nan):先将?替换成nan类型的空值
- wis = wis.dropna():删除nan类型的空值

1 | import pandas as pd |
数据离散化
数据离散化:连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。
举个例子:我们一般会将2000年出生到2009年出生的叫00后,1990-1999年生人为90后,就是聚类的问题。
- qcut = pd.qcut(p_change, 10)
- 对p_change这个DataFrame进行分组,分10个组,这个程序自己根据数据来分类的,每类数据都差不多
- qcut.value_counts():
- 计算分到每个组的数据个数
- pd.cut(p_change, bins)
- 根据前面那自定的bins区间进行分组(以bins作为分组依据),bins是一个列表,两两为一组
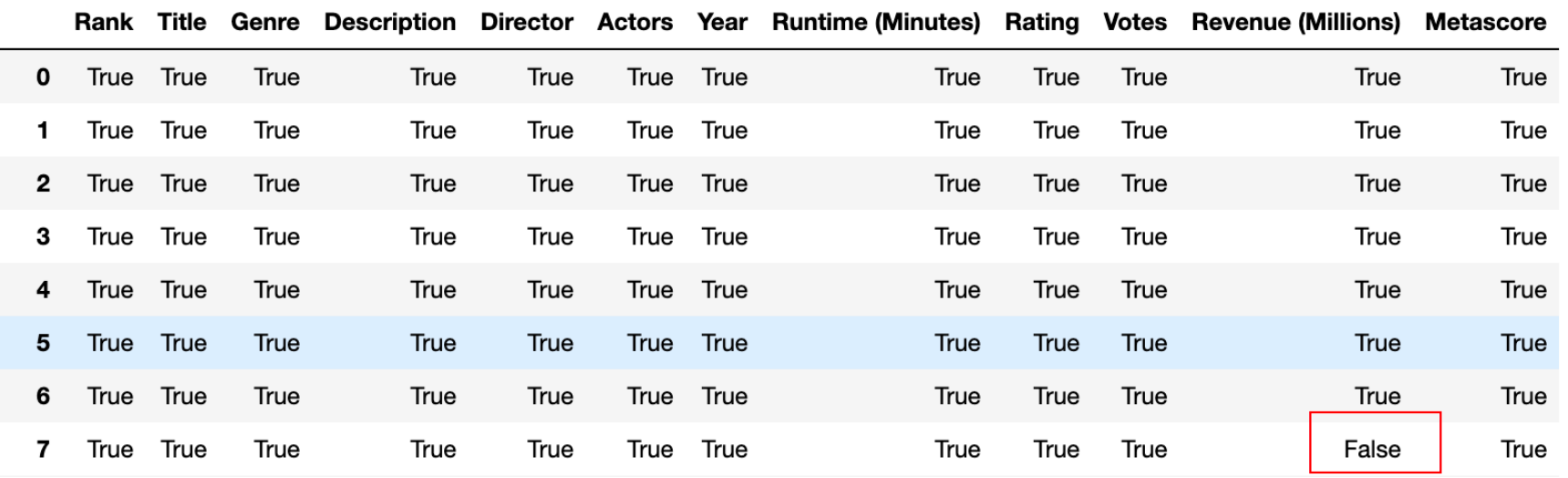
独热编码
- pandas.get_dummies(data, prefix=None)
- 对DataFrame(data)获取独热编码,prefix前缀其实就是分组名称
- 自己总结:
- 独热编码其实你有多少个类别的数据,就会有多少个列去唯一标识这些类别(慢慢体会吧,后面忘了再回顾
1 | import pandas as pd |
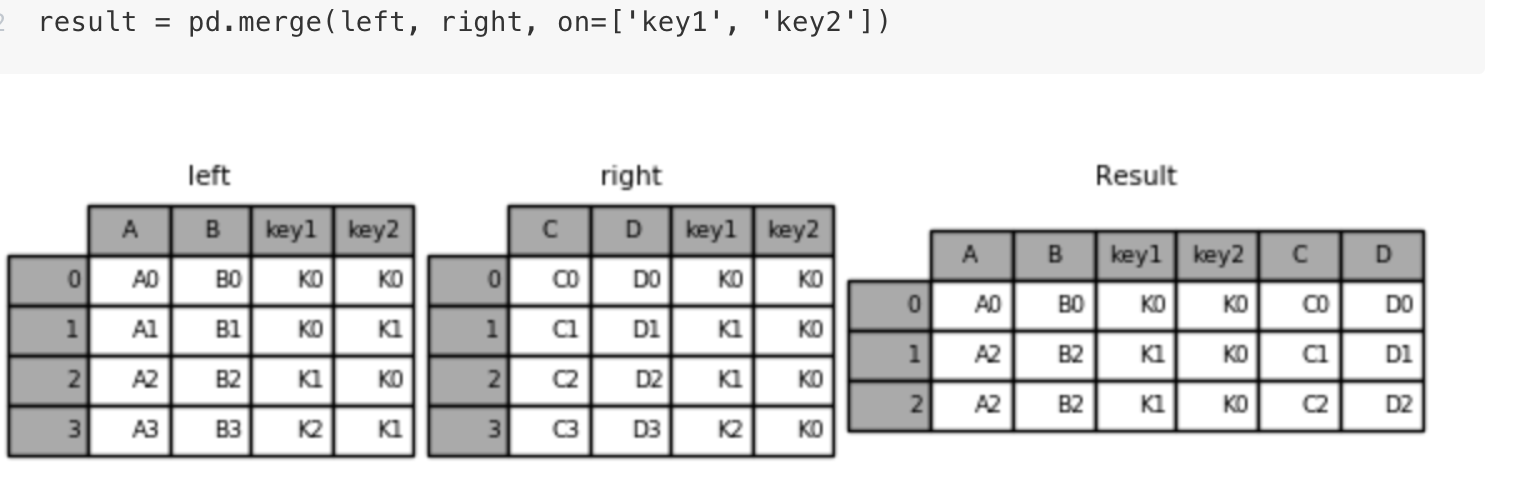
数据处理-合并
- pd.concat([df1, df2], axis = 0/1)
- 这种就是对两个DataFrame进行简单的拼接,axis中0为列索引,1为行索引
- pd.merge(left, right, how=”inner”, on=None)
- 可以按照两组数据的共同键值对合并或者左右各自,how可以进行内连接,左外,右外,on为外键
内连接:
左连接:
右连接:
外连接:
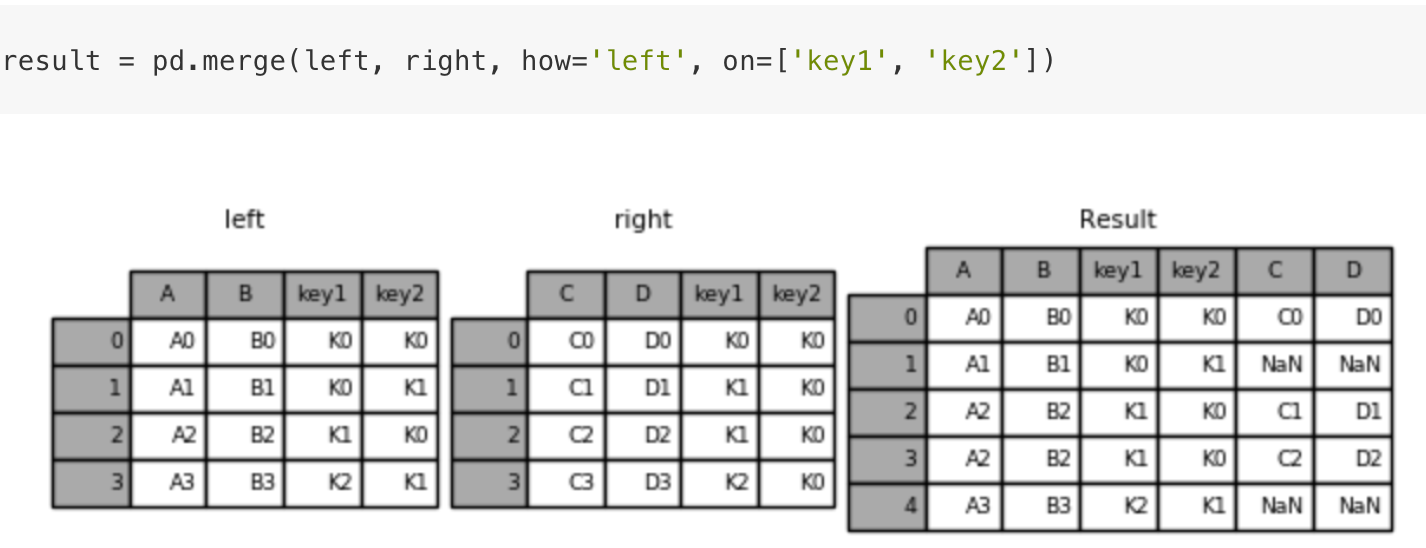
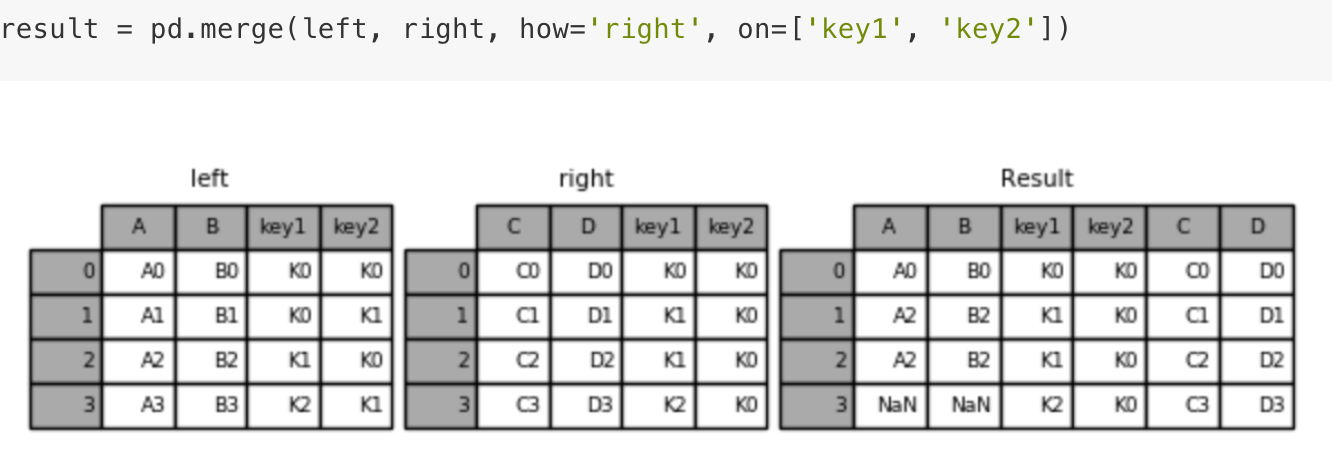
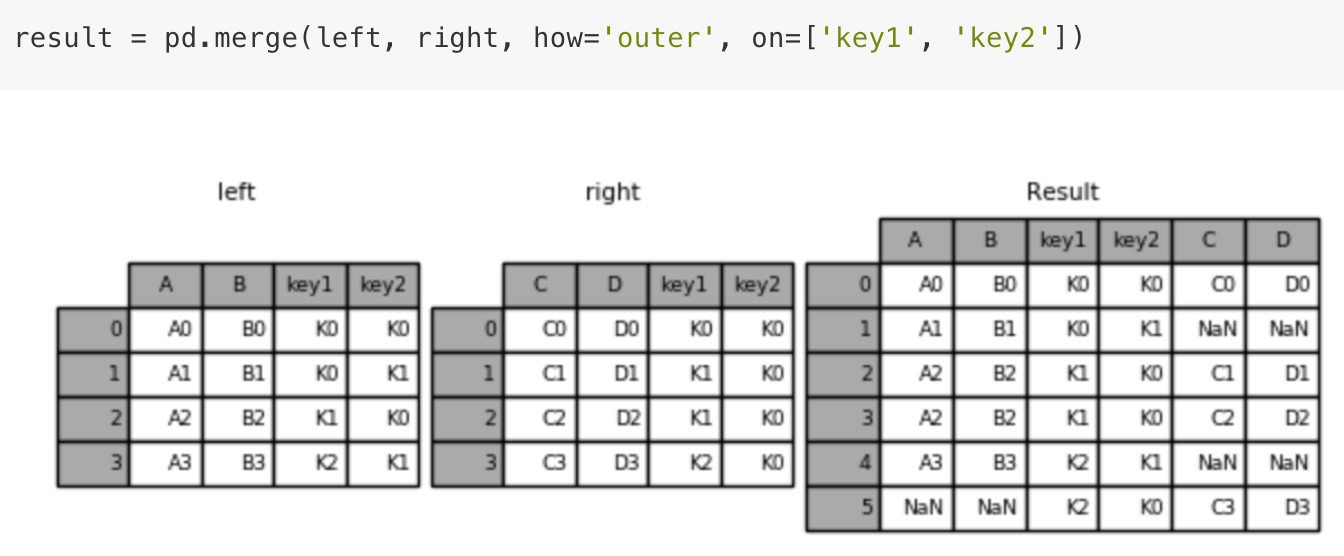
1 | import pandas as pd |
交叉表与透视表
应用crosstab和pivot_table实现交叉表与透视表
交叉表:
交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表)
- pd.crosstab(value1, value2)
透视表:
透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数
- data.pivot_table()
- DataFrame.pivot_table([], index=[])
1 | import matplotlib.pyplot as plt |
分组与聚合
应用groupby和聚合函数实现数据的分组与聚合
- DataFrame.groupby(key, as_index=False)
- key:分组的列数据,可以多个
- 案例:不同颜色的不同笔的价格数据
1 | col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]}) |
- 进行分组,对颜色分组,price进行聚合
1 | # 分组,求平均值 |
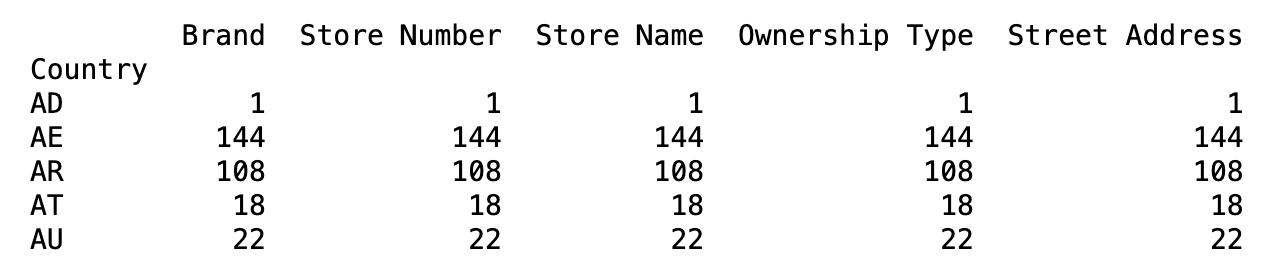
案例
1 | # 导入星巴克数据 |
End.
 微信
微信 支付宝
支付宝
.png)