数据结构算法
单链表
链表代码前置知识:
- cur.next = new_node:代表current的next指针指向新节点
- 链表有
数值域和链接域
代码实现:节点类
包含两个属性:
- item:数值域(元素域)
- next :地址域(链接域) 不是他的地址,而是他的下一个节点地址
1
2
3
4
5
6
|
class SingleNode:
def __init__(self, item):
self.item = item
self.next = None
|
代码实现:链表类
该部分代码包含一个属性
多个行为:
- is_empty(self) :链表是否为空
- length(self):判断链表长度
- traverse(self):遍历整个链表
- add(self,item) :给链表头部添加元素
- append(self,item):链表尾部添加元素
- insert(self,item):指定位置添加元素
- remove(self,item):删除节点
- search(self,item):查询节点是否存在
判断是否为空
1
2
3
4
5
6
7
8
9
10
11
12
|
def is_empty(self):
return self.head is None
|
判断链表长度
1
2
3
4
5
6
7
8
9
10
| def length(self):
cur = self.head
count = 0
while cur is not None:
count += 1
cur = cur.next
return count
|
遍历整个链表
1
2
3
4
5
6
7
| def traverse(self):
cur = self.head
while cur is not None:
print(f"数值域:{cur.item}", end="")
cur = cur.next
|
在链表头部添加元素
1
2
3
4
5
6
7
| def add(self, item):
new_node = SingleNode(item)
new_node.next = self.head
self.head = new_node
|
在链表尾部添加元素
1
2
3
4
5
6
7
8
9
10
11
12
13
| def append(self, item):
new_node = SingleNode(item)
if self.is_empty():
self.head = new_node
else:
cur = self.head
while cur.next is not None:
cur = cur.next
cur.next = new_node
|
在链表中间添加元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def insert(self, pos, item):
if pos <= 0:
self.add(item)
elif pos >= self.length():
self.append(item)
else:
cur = self.head
count = 0
while count < pos - 1:
cur = cur.next
count += 1
new_node = SingleNode(item)
new_node.next = cur.next
cur.next = new_node
|
根据数值域删除元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| def remove(self, item):
cur = self.head
pre = None
while cur is not None:
if cur.item == item:
if cur == self.head:
self.head = cur.next
else:
pre.next = cur.next
cur.next = None
return
else:
pre = cur
cur = cur.next
|
查找元素
1
2
3
4
5
6
7
8
9
10
11
| def search(self, item):
cur = self.head
while cur is not None:
if cur.item == item:
return True
cur = cur.next
return False
|
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
|
class SingleLinkList:
def __init__(self, node=None):
self.head = node
def is_empty(self):
return self.head is None
def length(self):
cur = self.head
count = 0
while cur is not None:
count += 1
cur = cur.next
return count
def traverse(self):
cur = self.head
while cur is not None:
print(f"数值域:{cur.item}", end="")
cur = cur.next
def add(self, item):
new_node = SingleNode(item)
new_node.next = self.head
self.head = new_node
def append(self, item):
new_node = SingleNode(item)
if self.is_empty():
self.head = new_node
else:
cur = self.head
while cur.next is not None:
cur = cur.next
cur.next = new_node
def insert(self, pos, item):
if pos <= 0:
self.add(item)
elif pos >= self.length():
self.append(item)
else:
cur = self.head
count = 0
while count < pos - 1:
cur = cur.next
count += 1
new_node = SingleNode(item)
new_node.next = cur.next
cur.next = new_node
def remove(self, item):
cur = self.head
pre = None
while cur is not None:
if cur.item == item:
if cur == self.head:
self.head = cur.next
else:
pre.next = cur.next
cur.next = None
return
else:
pre = cur
cur = cur.next
def search(self, item):
cur = self.head
while cur is not None:
if cur.item == item:
return True
cur = cur.next
return False
if __name__ == '__main__':
node1 = SingleNode(10)
print(f"元素域(数值域):{node1.item}")
print(f"链接域(地址域):{node1.next}")
print(f"node1对象{node1}")
print(f"node1类型{type(node1)}")
print("---------------测试链接类-------------------")
my_linklist = SingleLinkList(node1)
print(f"头结点:{my_linklist}")
print(f"头节点的元素域{my_linklist.head.item}")
print(f"头节点的地址域{my_linklist.head.next}")
print("---------------测试链表是否为空-------------------")
print(my_linklist.is_empty())
print("---------------测试头插-------------------")
my_linklist.add(20)
my_linklist.add(30)
print("---------------测试尾插-------------------")
my_linklist.append(40)
my_linklist.append(50)
print("---------------测试任意位置插入-------------------")
my_linklist.insert(-1, 2)
my_linklist.insert(8, 55)
my_linklist.insert(2, 32)
print("---------------测试删除-------------------")
my_linklist.remove(2)
my_linklist.remove(30)
my_linklist.remove(60)
print("---------------测试查找-------------------")
print(my_linklist.search(2))
print(my_linklist.search(32))
print("---------------测试链表长度-------------------")
print(f"当前链表长度为:{my_linklist.length()}")
print("---------------测试遍历-------------------")
my_linklist.traverse()
|
排序
时间复杂度:
- 冒泡排序:
- 最优的时间复杂度$O(n)$
- 最坏的时间复杂度$O(n²)$
- 选择排序:
算法是否稳定:
- 稳定的排序算法有:插入排序、冒泡排序、鸡尾酒排序、归并排序、二叉树排序、基数排序等;
- 不稳定排序算法包括:希尔排序、堆排序、快速排序、选择排序等。
下是常见排序算法的时间复杂度、空间复杂度及稳定性总结,按平均时间复杂度排序:
| 排序算法 |
平均时间复杂度 |
最坏时间复杂度 |
最好时间复杂度 |
空间复杂度 |
是否稳定 |
备注 |
| 冒泡排序 |
O(n²) |
O(n²) |
O(n) |
O(1) |
稳定 |
优化后可提前终止(无交换时停止)。 |
| 选择排序 |
O(n²) |
O(n²) |
O(n²) |
O(1) |
不稳定 |
每次选最小元素交换,可能破坏相同元素相对位置(如 [5, 5, 2])。 |
| 插入排序 |
O(n²) |
O(n²) |
O(n) |
O(1) |
稳定 |
对小规模或基本有序数据效率高。 |
| 希尔排序 |
O(n log n) |
O(n²) |
O(n log n) |
O(1) |
不稳定 |
插入排序的改进版,依赖步长序列。 |
| 归并排序 |
O(n log n) |
O(n log n) |
O(n log n) |
O(n) |
稳定 |
需额外空间合并,适合外部排序(如大数据文件)。 |
| 快速排序 |
O(n log n) |
O(n²) |
O(n log n) |
O(log n) |
不稳定 |
平均最快,但最坏情况(如已排序)退化为O(n²),递归栈空间消耗。 |
| 堆排序 |
O(n log n) |
O(n log n) |
O(n log n) |
O(1) |
不稳定 |
原地排序,但跳跃交换可能破坏稳定性(如 [5, 5, 2])。 |
| 计数排序 |
O(n + k) |
O(n + k) |
O(n + k) |
O(n + k) |
稳定 |
非比较排序,k为数据范围,适合小范围整数。 |
| 桶排序 |
O(n + k) |
O(n²) |
O(n) |
O(n + k) |
稳定 |
数据需均匀分布到桶中,否则退化为O(n²)。 |
| 基数排序 |
O(n × k) |
O(n × k) |
O(n × k) |
O(n + k) |
稳定 |
k为数字位数,需稳定子排序(如计数排序)。 |
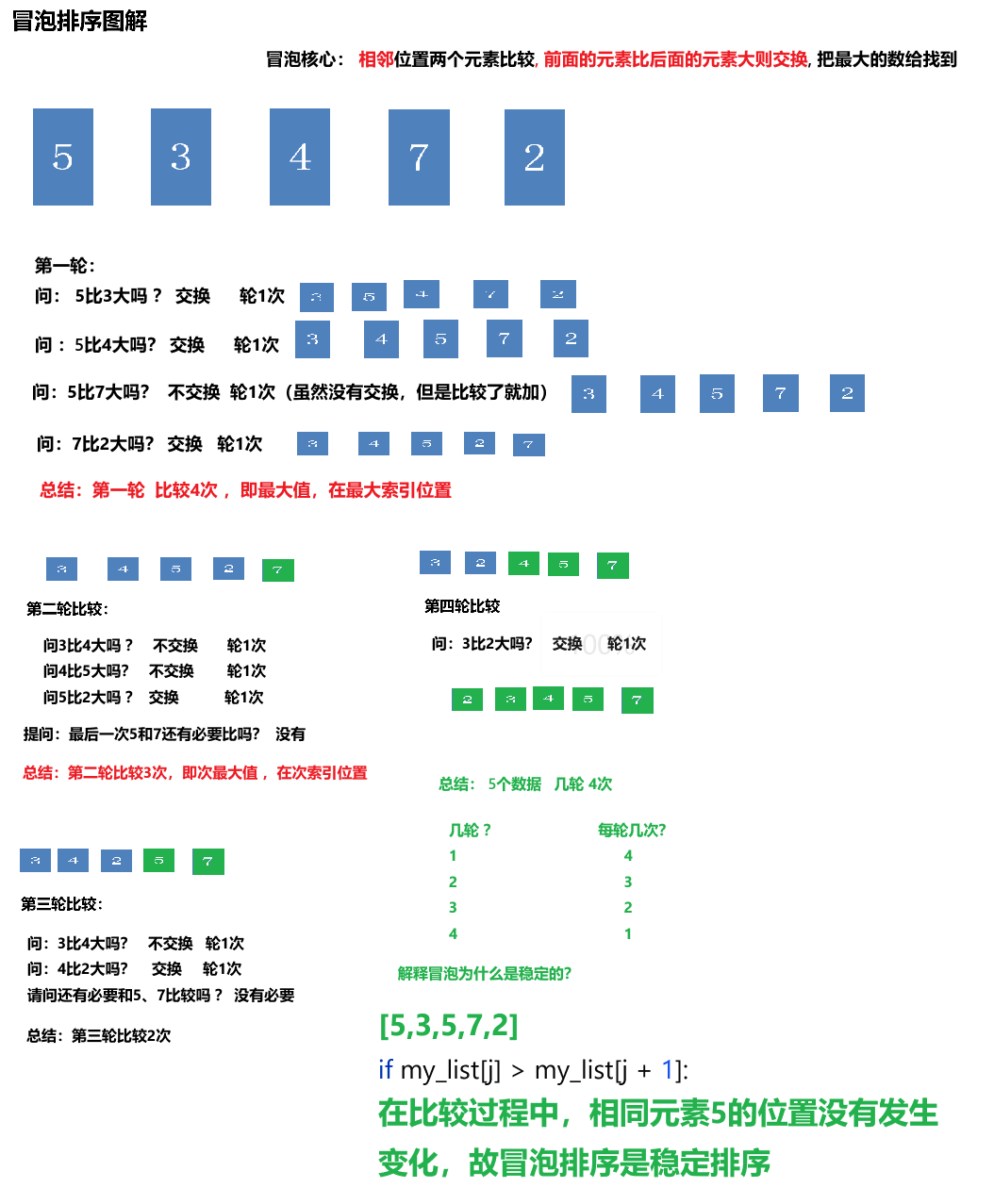
冒泡排序
Bubble Sort核心思想:(带指针)
😌首先,遍历整个数组,找到最小的元素。
😜当遍历完整个数组后,将找到的最小元素与数组的第一个元素交换位置。
- 此时,数组的第一个元素就是最小的,已经处于正确的位置。
😛接着,在剩下的未排序元素(从第二个元素开始到最后一个元素)中重复上述步骤。
- 再次遍历剩余元素,找到其中最小的元素,并与剩余元素中的第一个元素(即数组的第二个元素)交换位置。
😝不断重复这个过程
- 每次都将剩余未排序元素中的最小元素放置在已排序部分的末尾,直到整个数组都被排序。
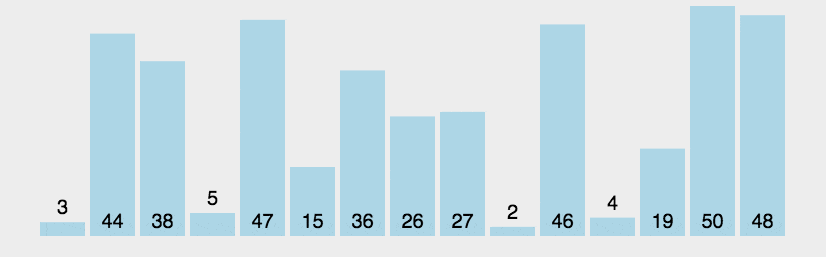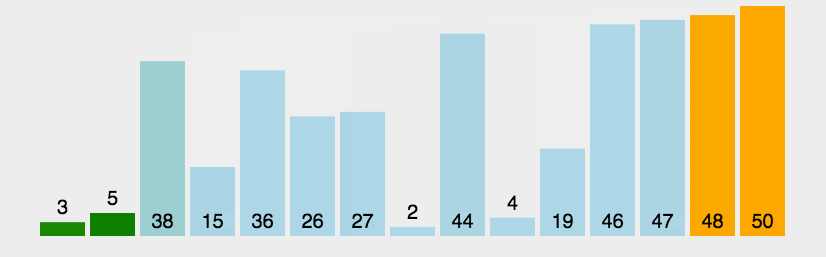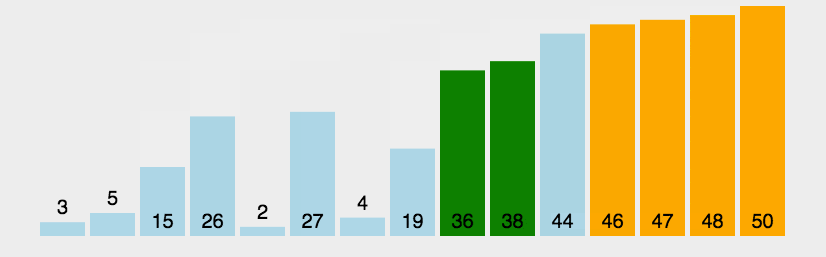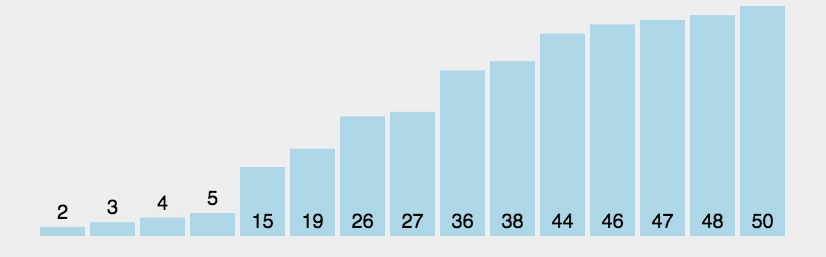
Python实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def bubble_sort(my_list):
n = len(my_list)
for i in range(n - 1):
for j in range(n - 1 - i):
if my_list[j] > my_list[j + 1]:
my_list[j], my_list[j + 1] = my_list[j + 1], my_list[j]
my_list=[5,3,4,7,2]
print(f"排序前:{my_list}")
bubble_sort(my_list)
print(f"排序后:{my_list}")
|
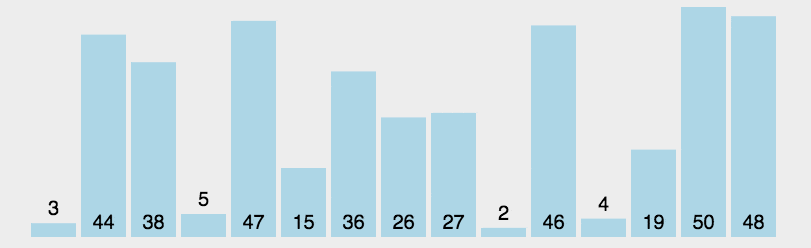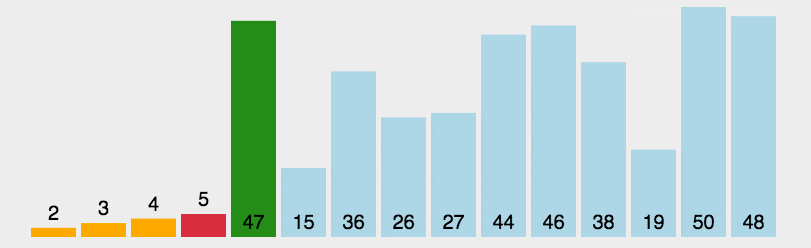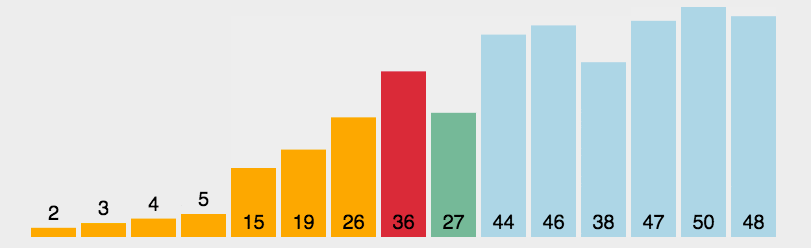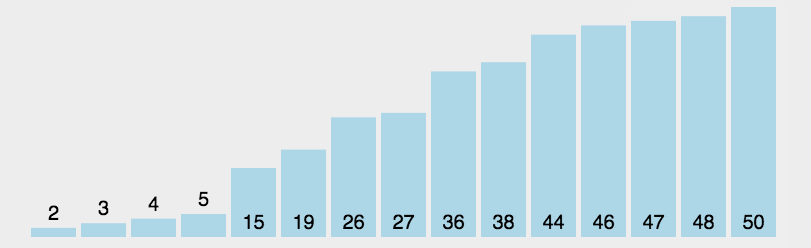
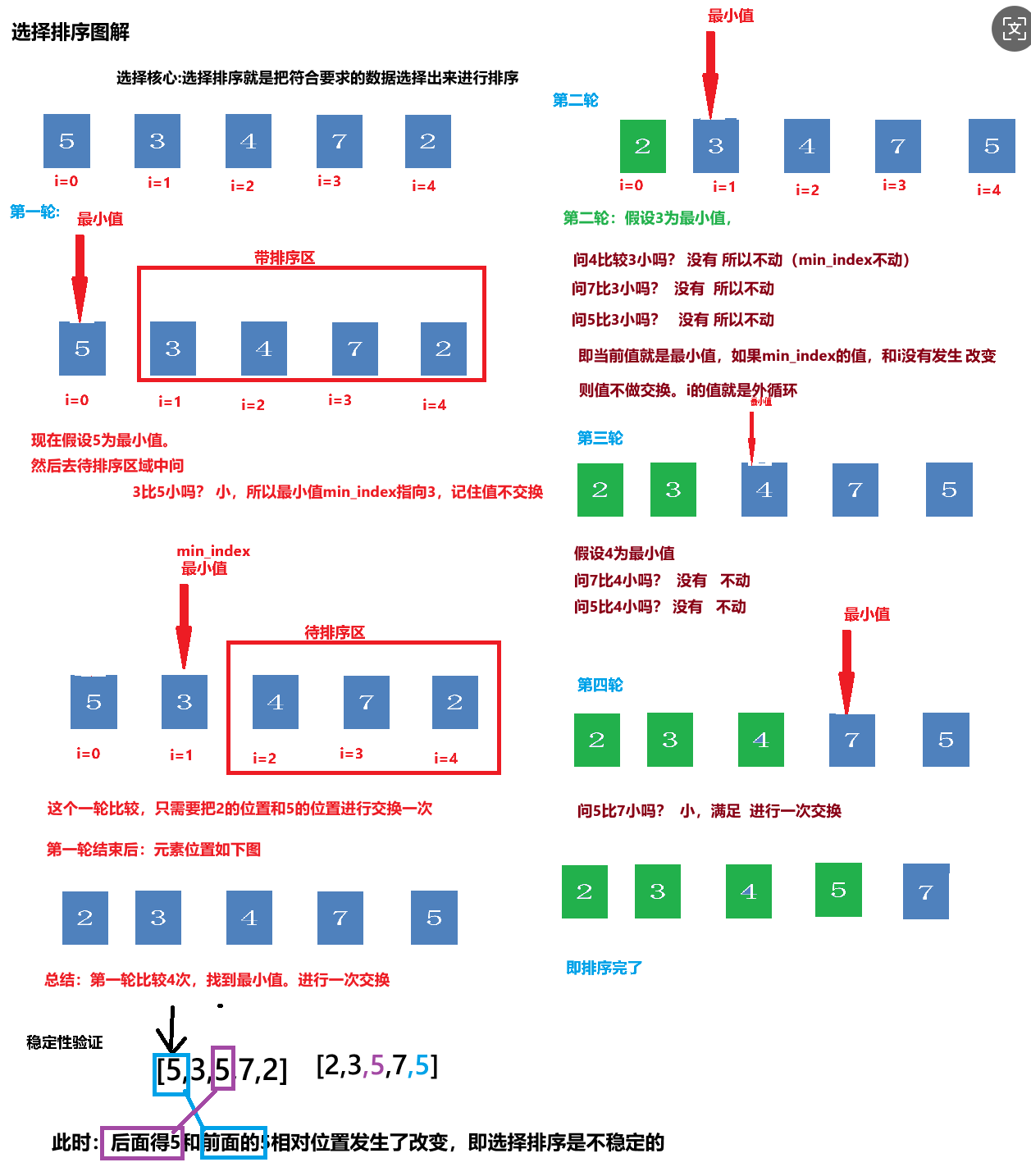
选择排序
Selection Sort核心思想:
- 初始化:将列表分为已排序部分和未排序部分。初始时,已排序部分为空,未排序部分为整个列表。
- 查找最小值:在未排序部分中查找最小的元素。
- 交换位置:将找到的最小元素与未排序部分的第一个元素交换位置。
- 更新范围:将未排序部分的起始位置向后移动一位,扩大已排序部分的范围。
- 重复步骤:重复上述步骤,直到未排序部分为空,列表完全有序。
Python 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def select_sort(my_list):
n = len(my_list)
for i in range(n - 1):
min_index = i
for j in range(i + 1, n):
if my_list[j] < my_list[min_index]:
min_index = j
if min_index != i:
my_list[min_index], my_list[i] = my_list[i], my_list[min_index]
|
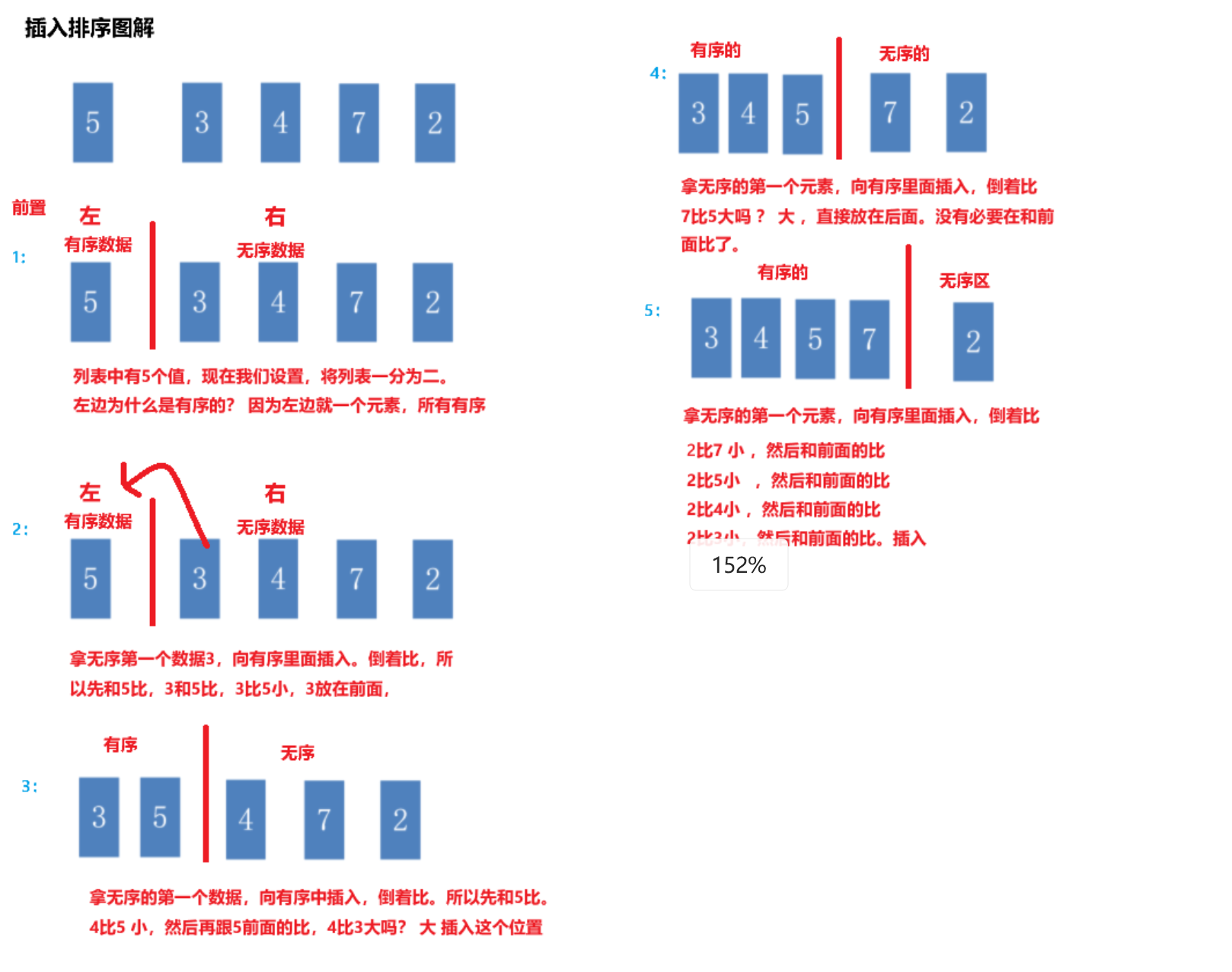
插入排序
入排序(Insertion Sort)原理:
- 把列表分为两个部分,假设第一个元素是有序的,剩下的是无序的。
- 每次都从无序的中获取一个元素。和有序前面的元素进行比较
- 决定出他的位置,进行插入。直至无序列表的元素操作完毕。剩下的列表就是:有序的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def insert_sort(my_list):
n = len(my_list)
for i in range(1, n):
for j in range(i, 0, -1):
if my_list[j] < my_list[j - 1]:
my_list[j], my_list[j - 1] = my_list[j - 1], my_list[j]
else:
break
if __name__ == '__main__':
my_list = [5, 3, 4, 7, 2]
print(f"排序前:{my_list}")
insert_sort(my_list)
print(f"排序后:{my_list}")
|
查找
二分查找法
折半搜索,也称二分查找算法、二分搜索,是一种在有序数组中查找某一特定元素的搜索算法。搜素过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
递归二分查找
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| """
二分(折半)查找:
概述:
属于查找类的算法,相对来说效率比较高。时间复杂度 o(log n)
前提:
列表必须有序
原理:
1:比较 要查找元素和列表中的值,如果一样则返回True。程序结束
2:如果 要查找的元素比中值小,去前半段(中值前)查找。
3:如果 要查找的元素比中值大,去后半段(中值后)查找。
4:重复上述动作,直至找完。如果找完了,还找不到。就返回False
"""
def binary_search_re(my_list, target):
n = len(my_list)
if n == 0:
return False
mid = n // 2
if my_list[mid] == target:
return True
elif target < my_list[mid]:
return binary_search_re(my_list[:mid], target)
else:
return binary_search_re(my_list[mid + 1:], target)
return False
if __name__ == '__main__':
my_list = [2, 3, 5, 6, 8, 10, 16, 18, 20]
print(binary_search_re(my_list,60))
|
非递归二分查找
计算中间位置时不应该使用(high+ low) / 2的方式,因为加法运算可能导致整数越界,最好使用整除法(high+ low) // 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def bisearch_search(my_list, target):
start = 0
end = len(my_list) - 1
while start <= end:
mid = (start + end) // 2
if my_list[mid] == target:
return True
elif target < my_list[mid]:
end = mid - 1
else:
start = mid + 1
return False
if __name__ == '__main__':
my_list = [8, 22, 31, 32, 44, 55, 56, 70, 78]
print(bisearch_search(my_list, -1))
|
树
之前整理的一篇文章:https://liamjohnson-w.github.io/2023/07/03/2023.07.03/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
|
class Node:
def __init__(self, item):
self.item = item
self.lchild = None
self.rchild = None
class BinaryTree:
def __init__(self, node=None):
self.root = node
def add(self, item):
new_node = Node(item)
if self.root is None:
self.root = new_node
return
queue = []
queue.append(self.root)
while True:
node = queue.pop(0)
if node.lchild is None:
node.lchild = new_node
return
else:
queue.append(node.lchild)
if node.rchild is None:
node.rchild = new_node
return
else:
queue.append(node.rchild)
def breadth(self):
if self.root is None:
return
queue = []
queue.append(self.root)
while len(queue) != 0:
node = queue.pop(0)
print(node.item, end=" ")
if node.lchild is not None:
queue.append(node.lchild)
if node.rchild is not None:
queue.append(node.rchild)
def preorder(self, root):
if root is not None:
print(root.item, end=" ")
self.preorder(root.lchild)
self.preorder(root.rchild)
def inorder(self, root):
if root is not None:
self.inorder(root.lchild)
print(root.item, end=" ")
self.inorder(root.rchild)
def postorder(self,root):
if root is not None:
self.postorder(root.lchild)
self.postorder(root.rchild)
print(root.item,end=" ")
def dm1_1_测试节点和二叉树类():
node1 = Node("A")
print(node1.item)
print(node1.lchild)
print(node1.rchild)
print("--------二叉树类----------")
print("--------测试二叉树----------")
bt = BinaryTree(node1)
print(bt.root)
print(bt.root.item)
print(bt.root.lchild)
print(bt.root.rchild)
def dm2_2_测试添加节点():
bt = BinaryTree()
bt.add("A")
bt.add("B")
bt.add("C")
bt.add("D")
bt.add("E")
bt.add("F")
bt.add("G")
bt.add("H")
bt.add("I")
bt.add("J")
def dm3_3_测试添加_遍历节点():
bt = BinaryTree()
bt.add("A")
bt.add("B")
bt.add("C")
bt.add("D")
bt.add("E")
bt.add("F")
bt.add("G")
bt.add("H")
bt.add("I")
bt.add("J")
bt.breadth()
def dm4_4_测试深度优先_先序遍历节点():
bt = BinaryTree()
bt.add("A")
bt.add("B")
bt.add("C")
bt.add("D")
bt.add("E")
bt.add("F")
bt.add("G")
bt.add("H")
bt.add("I")
bt.add("J")
print("先序遍历(根左右)")
bt.preorder(bt.root)
print()
print("中序遍历(左根右)")
bt.inorder(bt.root)
print()
print("后序遍历(左右根)")
bt.postorder(bt.root)
if __name__ == '__main__':
dm4_4_测试深度优先_先序遍历节点()
|

 微信
微信 支付宝
支付宝