NLP
NLP 的全称是N atuarl L anguage P rocessing,中文意思是自然语言处理,是人工智能领域的一个重要方向。
文本预处理
文本预处理,就是再数据送给模型之前,要做的工作。一般拿到数据,要根据任务组织样本$x$,$y$。比如对于分类任务,标签$y$是几分类、是否样本均衡、样本$x$长度分布如何。所以文本语料的数据分析一般是先要做的工作
文本预处理基本方法 分词
将连续的字序列按照一定的规范重新组合成词序列的过程
作用:词作为语言语义理解的最小单元, 是人类理解文本语言的基础
取决于你的解析器(interpreter)的位置.但最终应该离不开Anaconda这个工具包,所以要先切换虚拟环境.
1 2 conda activate ai pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple/
使用方式
模式
⭐️全模式:将句子中所有可以组成词的词语都扫描出来, 速度非常快,但可能会出现歧义
1 jieba.cut("语句" , cut_all=True )
⭐️⭐️⭐️精确模式:将句子最精确地按照语义切开,适合文本分析,提取语义中存在的每个词
1 jieba.cut("语句" , cut_all=False )
⭐️搜索引擎模式:在精确模式的基础上,对长词再次切分,适合用于搜索引擎分词
1 jieba.cut_for_search("语句" )
注意:
如果调用jieba.cut则只会返回生成器对象,需要通过迭代或转换为列表才能获取实际分词结果。
jieba支持繁体中文分词
jieba支持用户自定义词典
使用方式:jieba.load_userdict(“./userdict.txt”)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import jiebadef dm01_jiebacut ():sentence = 'jieba分词器是目前最好的 Python 中文分词组件,社区非常活跃,功能丰富,支持关键词提取、词性标注等。' myobj = jieba.cut(sentence, cut_all=False ) print ('myobj-->' , myobj) mydata = jieba.lcut(sentence, cut_all=False ) print ('mydata-->' , mydata) myobj2 = jieba.cut(sentence, cut_all=True ) print ('myobj2-->' , myobj2)mydata2 = jieba.lcut(sentence, cut_all=True ) print ('mydata2-->' , mydata2) myobj3 = jieba.cut_for_search(sentence) print ('myobj3-->' , myobj3)mydata3 = jieba.lcut_for_search(sentence) print ('mydata3-->' , mydata3)
词性标注
导包:
1 import jieba.posseg as pseg
返回的是一个列表,每个元素是 pair 对象
包含:
分词结果(word:如”我”)
词性标记(flag:如”r”)
1 2 3 4 5 6 7 8 import jieba.posseg as pseg def dm04_jieba_pos (): sentence = '我爱北京天安门' mydata = pseg.lcut(sentence) print ('mydata-->' , mydata)
命名实体识别
命名实体: 将人名, 地名, 机构名等专有名词统称命名实体。
命名实体识别:(Named Entity Recognition,简称NER),识别出一段文本中可能存在的命名实体。
作用:命名实体也是人类理解文本的基础单元,是AI解决NLP领域高阶任务的重要基础环节
参考链接:
举例:
1 2 鲁迅,浙江绍兴人,五四新文化运动的重要参与者,代表作朝花夕拾。 ==> 鲁迅(人名) / 浙江绍兴(地名)人 / 五四新文化运动(专有名词) / 重要参与者 / 代表作 / 朝花夕拾(专有名词)
Stanford NER
斯坦福大学开发的基于条件随机场的命名实体识别系统,该系统参数是基于CoNLL、MUC-6、MUC-7和ACE命名实体语料训练出来的。
地址:https://nlp.stanford.edu/software/CRF-NER.shtml
python实现的Github地址:https://github.com/Lynten/stanford-corenlp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from stanfordcorenlp import StanfordCoreNLPzh_model = StanfordCoreNLP(r'stanford-corenlp-full-2018-02-27' , lang='zh' ) s_zh = '我爱自然语言处理技术!' ner_zh = zh_model.ner(s_zh) s_zh1 = '我爱北京天安门!' ner_zh1 = zh_model.ner(s_zh1) print (ner_zh)print (ner_zh1)
Hanlp
HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。支持命名实体识别。 Github地址:https://github.com/hankcs/pyhanlp 官网:http://hanlp.linrunsoft.com/
1 2 3 4 5 6 7 8 9 10 from pyhanlp import *CRFnewSegment = HanLP.newSegment("crf" ) term_list = CRFnewSegment.seg("我爱北京天安门!" ) print (term_list)[我/r, 爱/v, 北京/ns, 天安门/ns, !/w]
NLTK
NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。
Github地址:https://github.com/nltk/nltk 官网:http://www.nltk.org/
1 2 3 4 5 6 7 8 import nltks = 'I love natural language processing technology!' s_token = nltk.word_tokenize(s) s_tagged = nltk.pos_tag(s_token) s_ner = nltk.chunk.ne_chunk(s_tagged) print (s_ner)
SpaCy
工业级的自然语言处理工具,遗憾的是不支持中文。 Gihub地址: https://github.com/explosion/spaCy 官网:https://spacy.io/
1 2 3 4 5 6 7 8 9 10 11 import spacyeng_model = spacy.load('en' ) s = 'I want to Beijing learning natural language processing technology!' s_ent = eng_model(s) for ent in s_ent.ents: print (ent, ent.label_, ent.label) Beijing GPE 382
Crfsuite
可以载入自己的数据集去训练CRF实体识别模型。
文档地址:https://sklearn-crfsuite.readthedocs.io/en/latest/?badge=latest
文本张量表示
定义:将一段文本使用张量进行表示这个过程就是文本张量表示;词表示成向量叫词向量,那么一句话构成词向量矩阵。
作用:将文本表示成张量(矩阵)形式,方便输入到计算机程序中进行解析
One-hot编码 案例引入:
在机器学习算法中,我们经常会遇到分类特征,例如:人的性别有男女,祖国有中国,美国,法国等。这些特征值并不是连续的,而是离散的,无序的。通常我们需要对其进行特征数字化才能送给机器进行处理。
例如对于如下特征:
性别特征:[“男”,”女”]
祖国特征:[“中国”,”美国,”法国”]
运动特征:[“足球”,”篮球”,”羽毛球”,”乒乓球”]
假如某个样本(某个人),他的特征是这样的[“男”,”中国”,”乒乓球”],我们可以用 [0,0,4] 来表示,但是这样的特征处理并不能直接放入机器学习算法中。因为类别之间是无序的(运动数据就是任意排序的)。
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
参考链接:
按照N位状态寄存器来对N个状态进行编码的原理,处理后:
祖国特征:[“中国”,”美国,”法国”](这里N=3):
中国 => 100、美国 => 010、法国 => 001
运动特征:[“足球”,”篮球”,”羽毛球”,”乒乓球”](这里N=4):
足球 => 1000、篮球 => 0100、羽毛球 => 0010、乒乓球 => 0001
所以,当一个样本为[“男”,”中国”,”乒乓球”]的时候,完整的特征数字化的结果为:
[1,0,1,0,0,0,0,0,1]
举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import jiebafrom tensorflow.keras.preprocessing.text import Tokenizerimport joblibdef dm01_onehot_gen (): vocabs = {“周杰伦”, “陈奕迅”, “王力宏”, “李宗盛”, “吴亦凡”, “鹿晗”} (内部生成 index_word word_index) mytokenizer = Tokenizer() mytokenizer.fit_on_texts(vocabs) for vocab in vocabs: zero_list = [0 ] * len (vocabs) idx = mytokenizer.word_index[vocab] - 1 zero_list[idx] = 1 print (vocab, ‘的onehot编码是’, zero_list) mypath = ‘./mytokenizer’ joblib.dump(mytokenizer, mypath) print (‘保存mytokenizer End’) print (mytokenizer.word_index) print (mytokenizer.index_word) {'周杰伦' : 1 , '吴亦凡' : 2 , '鹿晗' : 3 , '王力宏' : 4 , '李宗盛' : 5 , '陈奕迅' : 6 } {1 : '周杰伦' , 2 : '吴亦凡' , 3 : '鹿晗' , 4 : '王力宏' , 5 : '李宗盛' , 6 : '陈奕迅' } def dm02_onehot_use (): vocabs = {"周杰伦" , "陈奕迅" , "王力宏" , "李宗盛" , "吴亦凡" , "鹿晗" } mypath = './mytokenizer' mytokenizer = joblib.load(mypath) token = "李宗盛" zero_list = [0 ] * len (vocabs) idx = mytokenizer.word_index[token] - 1 zero_list[idx] = 1 print (token, '的onehot编码是' , zero_list)
那不得先看下独热编码的优缺点,就知道为什么要提word2vec和word embedding了
独热编码属于稀疏词向量表示,于是就有了稠密向量的表示方法: word2vec 和 word embedding
word2vec
Word2Vec是Google在2013年提出的一种词嵌入(Word Embedding)模型,其核心思想是将词语映射到一个连续的低维向量空间,使得语义相似的词在向量空间中距离更近。通过这种方式,词语的语义关系可以用向量之间的数学运算(如余弦相似度)来度量。
Word2Vec 的核心思想是基于 分布式假设 ,即“上下文相似的词语具有相似的语义”。通过大量语料库的训练,Word2Vec 学习到每个词语的向量表示,使得这些向量能够捕捉词语之间的语义关系。
参考链接:
Word2Vec 生成的词向量具有以下特点:
相似性捕捉: 语义相似的词语,其向量在空间中距离较近。
线性关系: 词向量之间的差异可以反映某些语义关系。
例如: $\vec{王国} - \vec{男人} + \vec{女人} \approx \vec{王后}$
聚类效果: 同一类别的词语在向量空间中往往形成聚类。
⭐️Word2Vec 主要有两种模型架构: ⭐️
参考代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 import fasttextdef dm01_fasttext_train_save_load (): mymodel = fasttext.train_unsupervised('./data/fil9' , epoch=1 ) mymodel.save_model("./data/mymodel3.bin" ) print ('保存词向量' ) pass def dm02_fasttext_get_word_vector (): mymodel = fasttext.load_model("./data/mymodel3.bin" ) wordvec = mymodel.get_word_vector('the' ) print ('wordvec--->' , wordvec.shape, '\n' , wordvec) wordvec = mymodel.get_word_vector('apple' ) print ('wordvec--->' , wordvec.shape, '\n' , wordvec) def dm03_fasttext_get_nearest_neighbors (): mymodel = fasttext.load_model("./data/mymodel3.bin" ) result = mymodel.get_nearest_neighbors('dog' ) print ('result--->' , result) pass ''' unsupervised_default = { 'model': "skipgram", # 1 选择词向量的训练方式 'lr': 0.05, # 2 学习率 'dim': 100, # 3 词向量特征数 'ws': 5, 'epoch': 5, # 4 训练轮次 'minCount': 5, 'minCountLabel': 0, 'minn': 3, 'maxn': 6, 'neg': 5, 'wordNgrams': 1, 'loss': "ns", 'bucket': 2000000, 'thread': multiprocessing.cpu_count() - 1, # 5 线程数 'lrUpdateRate': 100, 't': 1e-4, 'label': "__label__", 'verbose': 2, 'pretrainedVectors': "", 'seed': 0, 'autotuneValidationFile': "", 'autotuneMetric': "f1", 'autotunePredictions': 1, 'autotuneDuration': 60 * 5, # 5 minutes 'autotuneModelSize': "" } ''' def dm04_fasttext_parm (): ''' 训练词向量的参数设置''' mymodel = fasttext.train_unsupervised('./data/fil9' , epoch=1 , model='cbow' , lr=0.1 , dim=300 , thread=8 ) mymodel.save_model("./data/mymodel3.bin" ) print ('保存词向量' ) pass if __name__ == '__main__' : print ('词向量 End' )
$$
输出层: 通过 softmax 函数,预测上下文词的概率分布。
给定中心词 $w_{target}$,目标是最大化其上下文词 $w_{context}$ 的条件概率:
$$
$h$ 是中心词的嵌入向量
$v_{w_{context}}$ 是上下文词的输出向量
Word2Vec 训练方法
由于词汇表通常非常大,直接计算 softmax 的代价过高。为此,Word2Vec 引入了两种高效的近似训练方法:
负采样 (Negative Sampling)
负采样通过简化优化目标,减少计算量。它的核心思想是:与其每次计算所有类别的softmax分布,不如仅针对正样本和少量负样本进行计算。这些负样本通过随机采样获得,而正样本是实际存在于数据中的正确标签。
具体步骤如下:
正样本(Positive Sample):对于每个输入词语,模型会选择其上下文中的正确词语作为正样本。
负样本(Negative Samples):为了降低计算量,模型随机选择若干个错误的词语作为负样本。负样本来自词汇表中的其他词语,通常是无关词。
优化目标:模型不再优化整个词汇表的softmax概率分布,而是仅仅优化正样本与若干负样本的相对概率。
在传统的 Skip-Gram 模型中,目标是最大化每对词之间的共现概率:
$$
$v_{c}$ 和 $v_{w}$ 分别表示上下文词和目标词的词向量
$V$ 是词汇表
负采样优化目标如下:
$$
$\sigma(x)$ 是 sigmoid 函数,用于将输出限制在 (0,1) 之间
$v_{n_{i}}$ 是随机采样得到的负样本词向量
$k$ 是负采样的样本数量,通常取 5 到 20 之间
gensim库实现代码
实践步骤
语料预处理
分词: 将文本切分为单词序列。
去除停用词: 可根据需求去除常见但信息量低的词语。
建立词汇表: 统计词频,建立词语索引的映射关系。
模型训练
选择模型架构: CBOW 或 Skip-Gram。
设定超参数: 嵌入维度、窗口大小、负采样数量、学习率等。
训练参数: 使用优化算法(如 SGD)更新参数。
模型评估
相似度测试: 计算词向量之间的余弦相似度,验证相似词是否接近。
下游任务验证: 将词向量应用于具体任务,评估性能提升。
数据准备
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mkdir data wget -c :http://mattmahoney.net/dc/enwik9.zip -P data unzip data/enwik9 -d data head -10 ./data/envik9 perl wikifil.pl data/enwik9 > data/fil9 head -80 -c data/fil9
gensim库实现Word2vec代码案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from gensim.models import Word2Vecfrom gensim.models.word2vec import LineSentencesentences = LineSentence('corpus.txt' ) model = Word2Vec( sentences, vector_size=100 , window=5 , min_count=5 , workers=4 , sg=1 , negative=5 , sample=1e-3 , epochs=5 ) model.save('word2vec.model' ) model = Word2Vec.load('word2vec.model' ) vector = model.wv['苹果' ] print ('苹果的词向量:' )print (vector)similarity = model.wv.similarity('苹果' , '香蕉' ) print (f'苹果和香蕉的相似度:{similarity} ' )similar_words = model.wv.most_similar('苹果' , topn=5 ) print ('与苹果最相似的词:' )for word, score in similar_words: print (f'{word} : {score} ' ) result = model.wv.most_similar(positive=['王后' , '男人' ], negative=['女人' ], topn=1 ) print ('王后 + 男人 - 女人 = ' )print (result)
Fasttext库实现word2vec
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 import fasttextdef dm01_fasttext_train_save_load (): mymodel = fasttext.train_unsupervised('./data/fil9' , epoch=1 ) mymodel.save_model("./data/mymodel3.bin" ) print ('保存词向量' ) pass def dm02_fasttext_get_word_vector (): mymodel = fasttext.load_model("./data/mymodel3.bin" ) wordvec = mymodel.get_word_vector('the' ) print ('wordvec--->' , wordvec.shape, '\n' , wordvec) wordvec = mymodel.get_word_vector('apple' ) print ('wordvec--->' , wordvec.shape, '\n' , wordvec) def dm03_fasttext_get_nearest_neighbors (): mymodel = fasttext.load_model("./data/mymodel3.bin" ) result = mymodel.get_nearest_neighbors('dog' ) print ('result--->' , result) pass ''' unsupervised_default = { 'model': "skipgram", # 1 选择词向量的训练方式 'lr': 0.05, # 2 学习率 'dim': 100, # 3 词向量特征数 'ws': 5, 'epoch': 5, # 4 训练轮次 'minCount': 5, 'minCountLabel': 0, 'minn': 3, 'maxn': 6, 'neg': 5, 'wordNgrams': 1, 'loss': "ns", 'bucket': 2000000, 'thread': multiprocessing.cpu_count() - 1, # 5 线程数 'lrUpdateRate': 100, 't': 1e-4, 'label': "__label__", 'verbose': 2, 'pretrainedVectors': "", 'seed': 0, 'autotuneValidationFile': "", 'autotuneMetric': "f1", 'autotunePredictions': 1, 'autotuneDuration': 60 * 5, # 5 minutes 'autotuneModelSize': "" } ''' def dm04_fasttext_parm (): ''' 训练词向量的参数设置''' mymodel = fasttext.train_unsupervised('./data/fil9' , epoch=1 , model='cbow' , lr=0.1 , dim=300 , thread=8 ) mymodel.save_model("./data/mymodel3.bin" ) print ('保存词向量' ) pass if __name__ == '__main__' : print ('词向量 End' )
FastText
被应用在迁移学习中,下面有详细原理、代码剖析。
文本张量TensorBoard可视化案例
实现步骤
步骤1:环境准备(这里使用的是keras_preprocessing,需要pip install)
1 2 3 4 5 6 import torchfrom keras_preprocessing.text import Tokenizerfrom torch.utils.tensorboard import SummaryWriterimport jiebaimport torch.nn as nnimport tensorboard as tb
步骤2:分词与文本数值化(这里需要用到Tokenizer类,只需要知道这个玩意是将文本转为向量的类就可)
1 2 3 4 5 6 7 8 9 sentences = [sentence1, sentence2] word_list = [jieba.lcut(s) for s in sentences] tokenizer = Tokenizer() tokenizer.fit_on_texts(word_list) vocab_size = len (tokenizer.word_index)
步骤3:创建词嵌入层
1 2 3 embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=8 ) print (embedding.weight.data.shape)
步骤4:生成词向量矩阵
1 2 3 word_vectors = embedding.weight.data token_list = list (tokenizer.index_word.values())
步骤5:TensorBoard可视化
1 2 3 4 5 6 7 8 9 10 writer = SummaryWriter() writer.add_embedding( word_vectors, metadata=token_list, tag="word_embedding" ) writer.close()
步骤6:启动TensorBoard(这里看你的模型输出结果到哪了,然后把绝对路径放到命令行上)
1 tensorboard --logdir=/Users/xxx/xxx --host 0.0 .0 .0
浏览器访问 http://127.0.0.1:6006,选择 Projector 标签页查看词向量分布。
TensorBoard分词可视化展示
关键代码解析
(1) 分词与数值化
jieba.lcutTokenizer.fit_on_texts
(2) 词嵌入层
nn.Embedding:
num_embeddings:词汇表大小。embedding_dim:词向量维度(建议8-300)。权重矩阵形状为 [vocab_size, embedding_dim]。
(3) TensorBoard写入
add_embedding 参数:
word_vectors:词向量矩阵。metadata:单词标签列表(用于悬浮显示)。
常见问题解决
Q1:TensorBoard无法显示数据
检查日志路径:确保 --logdir 指向正确的 runs 目录。
重启TensorBoard:有时需强制 刷新浏览器缓存。
Q2:词向量分布不合理
调整 embedding_dim:增加维度可能提升语义表达能力。
扩展数据量:更多句子可改善词向量质量。
文本数据分析
常用的几种文本数据分析方法:标签数量分布、句子长度分布、词频统计与关键词词云
参考链接:
获取标签数量分布 概念 :统计数据集中每个标签(如0和1)出现的次数,用于检查数据集的类别平衡情况。
实现步骤 :
读取训练集/验证集数据
使用seaborn的countplot函数统计标签分组
可视化展示结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import seaborn as snsimport pandas as pdimport matplotlib.pyplot as pltplt.style.use('fivethirtyeight' ) train_data = pd.read_csv("./files/train.tsv" , sep="\t" ) valid_data = pd.read_csv("./files/dev.tsv" , sep="\t" ) sns.countplot("label" , data=train_data) plt.title("train_data" ) plt.show() sns.countplot("label" , data=valid_data) plt.title("valid_data" )
作用 :检查数据集是否类别平衡,如果正负样本比例不均衡(如不是1:1),需要进行数据增强或删减。
获取句子长度分布 概念 :统计数据集中不同长度的句子出现的频率,了解句子长度的分布情况。
实现步骤 :
读取数据
新增句子长度列
绘制柱状图或密度曲线图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import seaborn as snsimport pandas as pdimport matplotlib.pyplot as pltplt.style.use('fivethirtyeight' ) train_data = pd.read_csv('./files/train.tsv' , sep='\t' ) train_data['sentence_length' ] = list (map (lambda x: len (x), train_data['sentence' ])) print (train_data) sns.countplot(x='sentence_length' , data=train_data) plt.xticks([]) plt.show() sns.displot(x='sentence_length' , data=train_data) plt.yticks([]) plt.show()
作用 :了解句子长度分布范围,指导模型输入长度的设置(如截断或补齐操作)。
print(train_data)返回值
sentence
label
sentence_length
0
早餐不好,服务不到位,晚餐无西餐…
0
42
1
去的时候,酒店大厅和餐厅在装修…
1
65
2
有很长时间没有在西藏大厦住了…
1
58
获取正负样本长度散点分布
这里需要注意图片大小的调整方式:plt.figure(figsize=(10, 6)),在每次plt.show()之后,figsize会重置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import seaborn as snsimport pandas as pdimport matplotlib.pyplot as pltplt.style.use('fivethirtyeight' ) plt.figure(figsize=(10 , 6 )) train_data = pd.read_csv('./files/train.tsv' , sep='\t' ) valid_data = pd.read_csv("./files/dev.tsv" , sep="\t" ) train_data['sentence_length' ] = list (map (lambda x: len (x), train_data['sentence' ])) valid_data["sentence_length" ] = list (map (lambda x: len (x), valid_data["sentence" ])) sns.stripplot(y='sentence_length' ,x='label' ,data=train_data) plt.show() plt.figure(figsize=(10 , 6 )) sns.stripplot(y='sentence_length' , x='label' , data=valid_data) plt.show()
作用 :定位异常点的出现位置,帮助进行人工语料审查。例如,文档中提到的训练集正样本中出现了句子长度近3500的异常点。
统计单词总数
这里需要注意:chain(*map(...))
作用是将多层嵌套的列表展平为单层列表,比如
转换前:[ ["a","b"], ["c","d"] ]
转换后:["a","b","c","d"]
1 2 3 4 5 6 7 8 9 from itertools import chainimport jiebatrain_data = pd.read_csv('./cn_data/train.tsv' , sep='\t' ) train_vocab = set (chain(*map (lambda x: jieba.lcut(x), train_data['sentence' ]))) print ("训练集共包含不同词汇总数为:" , len (train_vocab))
关键语法 :使用set(chain(*map()))结构实现对分词结果的去重和合并。
获取训练集高频词云
这里有一些字体上的异常,不过大步骤不影响:
读取数据:train_data = pd.read_csv(‘./files/train.tsv’, sep=’\t’)
获取正样本的sentence:p_train_data = train_data[train_data[“label”]==1][“sentence”]
使用jieba获取形容词并拉平数据:train_p_a_vocab = chain(*map(lambda x: get_a_list(x), p_train_data))
绘制词云图:get_word_cloud(train_p_a_vocab)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import jieba.posseg as pseg from wordcloud import WordCloud from itertools import chain import pandas as pdimport matplotlib.pyplot as plt def get_a_list (text ): """用于获取形容词列表""" return [g.word for g in pseg.lcut(text) if g.flag == "a" ] def get_word_cloud (keywords_list ): wordcloud = WordCloud(font_path="./files/SimHei.ttf" , max_words=100 , background_color="white" ) keywords_string = " " .join(keywords_list) wordcloud.generate(keywords_string) plt.figure() plt.imshow(wordcloud, interpolation="bilinear" ) plt.axis("off" ) plt.show() train_data = pd.read_csv('./files/train.tsv' , sep='\t' ) p_train_data = train_data[train_data["label" ]==1 ]["sentence" ] train_p_a_vocab = chain(*map (lambda x: get_a_list(x), p_train_data)) n_train_data = train_data[train_data["label" ]==0 ]["sentence" ] train_n_a_vocab = chain(*map (lambda x: get_a_list(x), n_train_data)) get_word_cloud(train_p_a_vocab) get_word_cloud(train_n_a_vocab)
文本特征处理
主要有两种方法实现:
上面两种方法通过对原始文本数据进行转换和增强,使机器学习模型能够更有效地理解和处理文本信息。
n-gram特征处理 n-gram是指文本序列中n个相邻元素的共现组合 ,常用的有:
bi-gram (2-gram):相邻两个元素的组合tri-gram (3-gram):相邻三个元素的组合
1 2 3 4 5 input_list = [1 , 3 , 2 , 1 , 5 , 3 ] ngram_range = 2 res = set (zip (*[input_list[i:] for i in range (ngram_range)]))
应用示例 给定分词列表:[“是谁”,”敲动”,”我心”],对应的数值映射为[1,34,21]
添加”是谁”和”敲动”的bi-gram特征(假设编码为1000)
添加”敲动”和”我心”的bi-gram特征(假设编码为1001)
最终特征列表变为:[1, 34, 21, 1000, 1001]
文本长度规范处理
文本长度规范是指统一文本序列长度的处理过程 ,主要包括:
截断 (Truncating):对过长的文本进行截取补齐 (Padding):对过短的文本进行填充
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from tensorflow.keras.preprocessing import sequencecutlen = 10 x_train = [[1 , 23 , 5 , 32 , 55 , 63 , 2 , 21 , 78 , 32 , 23 , 1 ], [2 , 32 , 1 , 23 , 1 ]] res = sequence.pad_sequences(sequences=x_train, maxlen=cutlen, padding='post' , truncating='post' )
最佳实践
n-gram选择策略 :
短文本优先使用bi-gram
长文本可尝试tri-gram
结合具体任务调整n值
长度规范技巧 :
基于数据分析确定合适长度(覆盖90%样本)
对重要信息位置选择padding/truncating方式
特殊任务可使用动态padding
文本数据增强
文本数据增强是指通过人工方法扩充文本训练数据 的技术,主要目的包括:
解决数据稀疏问题
改善类别不平衡
增强模型泛化能力
提高模型鲁棒性
核心方法为:回译数据增强法即:原始文本 → 翻译为中间语言 → 回译至原语言 → 获得新样本
这里相当于使用某个数据结构,通过request方式获取某个词语的同义词。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import requestsurl = 'http://fanyi.youdao.com/translate' text1 = '样例文本' data1 = {'from' : 'zh-CHS' , 'to' : 'en' , 'i' : text1, 'doctype' : 'json' } response1 = requests.post(url=url, params=data1) res1 = response1.json() text2 = res1['translateResult' ][0 ][0 ]['tgt' ] data2 = {'from' : 'en' , 'to' : 'zh-CHS' , 'i' : text2, 'doctype' : 'json' } response2 = requests.post(url=url, params=data2) res2 = response2.json() print ("回译结果:" , res2['translateResult' ][0 ][0 ]['tgt' ])
谷歌翻译API 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 p_sample1 = "酒店设施非常不错" p_sample2 = "这家价格很便宜" n_sample1 = "拖鞋都发霉了, 太差了" n_sample2 = "电视不好用, 没有看到足球" from googletrans import Translatortranslator = Translator() translations = translator.translate([p_sample1, p_sample2, n_sample1, n_sample2], dest='ko' ) ko_res = list (map (lambda x: x.text, translations)) print ("中间翻译结果:" )print (ko_res) translations = translator.translate(ko_res, dest='zh-cn' ) cn_res = list (map (lambda x: x.text, translations)) print ("回译得到的增强数据:" )print (cn_res)
1 2 3 4 中间翻译结果 :['호텔 시설은 아주 좋다', '이 가격은 매우 저렴합니다', '슬리퍼 곰팡이가 핀이다, 나쁜', 'TV가 잘 작동하지 않습니다, 나는 축구를 볼 수 없습니다'] 回译得到的增强数据 :['酒店设施都非常好', '这个价格是非常实惠', '拖鞋都发霉了,坏', '电视不工作,我不能去看足球']
百度翻译API 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import http.clientimport hashlibimport urllibimport randomimport json appid = '' secretKey = '' httpClient = None myurl = '/api/trans/vip/translate' fromLang = 'auto' toLang = 'zh' salt = random.randint(32768 , 65536 ) q= 'apple' sign = appid + q + str (salt) + secretKey sign = hashlib.md5(sign.encode()).hexdigest() myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str ( salt) + '&sign=' + sign try : httpClient = http.client.HTTPConnection('api.fanyi.baidu.com' ) httpClient.request('GET' , myurl) response = httpClient.getresponse() result_all = response.read().decode("utf-8" ) result = json.loads(result_all) print (result) except Exception as e: print (e) finally : if httpClient: httpClient.close()
获取的案例:
原始:”服务很好”
增强:”服务非常周到”
增强:”服务质量令人满意”
局限性及解决方案
问题类型
具体表现
解决方案
短文本重复
新样本与原样本相似度高
采用多语言链条翻译
语义失真
关键信息丢失或改变
人工审核过滤
效率低下
多次翻译耗时
限制翻译次数(≤3次)
领域偏移
专业术语翻译不准
使用领域定制翻译模型
参考其他方法:
方法类型
优点
缺点
适用场景
回译法
语义丰富,质量高
依赖翻译API
通用文本
同义词替换
简单快速
可能改变语义
非关键术语
随机插入
增加多样性
可能破坏语法
长文本
随机交换
改变词序
影响语义连贯
语序灵活的语言
FastText Fasttext模型的主要创新点是这个模型非常简单,训练速度非常快,而且在准确率上能够匹敌复杂的深度学习模型。
Word2vec和FastText同根同源 。它们都是Thomas Mikolov大神的杰作。Thomas Mikolov在Google的时候,带领团队搞出来一个word2vec,很好地改进了传统词向量表示的问题。后来,Thomas Mikolov去了Fackbook,才有了FastText的诞生。
Fasttext与传统的词向量模型(如 Word2Vec)将每个词作为一个整体来学习词向量不同,FastText 将每个词看作是其子词(n-grams)的集合。通过这种方式,FastText 试图捕捉到更多的词汇信息,并能够更好地处理稀有词汇和未见过的词。
Fasttext其主要思想在一篇论文中有详细的阐述:Enriching Word Vectors with Subword Information
参考链接:
FastText及其他词向量模型
一开始写FastText有些潦草,文章脉络不清晰,这里重新整理了。
如下是词向量模型的演进,最先进的为BERT。标红的是后面需要深入理解掌握的,这里先了解一下FastText。
FastText: 将词语分解为字符 n-gram,能够处理未登录词和词语的内部结构。
GloVe (Global Vectors for Word Representation): 结合全局语料词共现信息,利用矩阵分解的方法生成词向量。
ELMo (Embeddings from Language Models): 基于词向量的语言模型,生成上下文敏感的词向量,解决词语的多义性问题。
BERT (Bidirectional Encoder Representations from Transformers): 利用 Transformer 架构,生成深度的上下文表示,可用于句子和段落级别的嵌入。
模型
类型
核心思想
是否上下文敏感
典型应用场景
FastText
静态词向量
字符 n-gram 子词嵌入
❌
形态复杂语言处理
GloVe
静态词向量
全局词共现矩阵分解
❌
通用词向量任务
ELMo
动态词向量
双向 LSTM 语言模型
✔️
一词多义场景
BERT
预训练语言模型
Transformer 双向编码
✔️
几乎所有 NLP 下游任务
所有词向量模型本质上都是为了解决 One-Hot Encoding 的缺陷 :
特性
One-Hot Encoding
Word2Vec/FastText/GloVe
ELMo/BERT
维度 高维稀疏(维度=词汇表大小)
低维稠密(如300维)
低维稠密(动态)
语义信息 无(仅符号表示)
捕捉语义相似性(如”猫≈狗”)
捕捉上下文相关语义(如”苹果”在不同句子中意义不同)
计算效率 低(矩阵稀疏)
高(向量稠密,适合计算相似度)
较高(需预训练模型)
未登录词(OOV) 无法处理
FastText 可处理
BERT 通过子词划分处理
FastText原理 基础理论
首先回顾一下CBOW以及Skip-Gram模型
CBOW模型:将其上下文简化为多个词向量,然后组成成词嵌入的sum。
对于多个上下文$c_{1:k}$ ,即 $c = \sum_{i=1}^{k} W_1^T \cdot c_i$
然后用这个上下文向量 $c$ 去预测目标单词,即 $y = softmax(W_2^T.sigmoid(c))$
正式剖析Fasttext架构,和CBOW以及Skip-Gram模型做了比较。
输入层:
隐藏层:
输出层:
既然使用的是神经网路做分类,那么就得有损失函数,即交叉熵损失函数:j)=-\sum {c=1}^{m}{y_{jc}log(y\ ̂_{jc})}
$$
可以看到,CBOW在计算词向量的时候丢失了上下文成分之间的顺序信息。
和CBOW以及Skip-Gram不同的是,FastText中增加了N-gram特征,这使得fastText可以关注到词序信息。
N-gram特征
N-gram指将文本内容按照顺序进行大小为N的窗口滑动操作,形成文本片段序列。
根据粒度的不同,N-gram可以分为字符粒度(用于英文等)、字或词粒度和词语粒度。
FastText中常用字符粒度和字粒度的N-gram。在英文文档分类中,使用字符粒度的N-gram是非常有帮助的。
先回顾自然语言处理中的一个基本问题: 如何计算一段文本序列在某种语言下出现的概率?
对于文本序列:
$$
当n=2(bigram)时只需计算$p(w_t|w_{t-1})$
当n=3(trigram)时计算$p(w_t|w_{t-2},w_{t-1})$
上述也就是N-gram的原理
举例: 对于单词”hello”,长度至少为3的字符粒度的N-gram有”hel”,”ell”,”llo”,”hell”,”ello”以及”hello”。
每个N-gram都可以用一个稠密向量(嵌入向量) $z_g$ 表示,于是整个单词”hello”就可以被表示为
$g_w$:单词$w$(如”hello”)的所有N-gram集合(例如 {“hel”, “ell”, “llo”, “hell”, “ello”, “hello”})
$z_g$:N-gram $g$ 的稠密嵌入向量(通过模型学习得到)
$w_v$:可训练的权重矩阵(将N-gram向量映射到上下文空间)
$c$:上下文向量(如句子中的其他词或目标标签的表示)
层次Softmax
FastText的另一功能就是进行文本分类。
由于FastText是分类问题,自然选择 $softmax$ 函数获得类别的概率分布。
因此,FastText的损失函数可使用多分类交叉熵损失。
$$
当目标类别数量比较少时,直接使用 $softmax$ 函数并没有效率问题
但当类别数量很大(设为 $K$ )时,因为需要对 $K$ 个数值进行归一化,$softmax$ 的计算就会占据大量时间。
为了加速训练,FastText采用与Word2vec类似的层次softmax 方法优化时间效率。
层次$softmax$ 的基本思想是根据类别的频率构造霍夫曼树来代替扁平化的标准Softmax。
通过层次$softmax$ ,获得概率分布的时间复杂度可以从 $O(K)$ 降至 $O(logK)$ .
通过Huffman(哈夫曼/霍夫曼)编码,构造Huffman树,要计算的是目标词w的概率,这个概率的具体含义,是指从root结点开始随机走,走到目标词w的概率。
到达非叶子节点n的时候往左边走和往右边走的概率分别是:
Sigmoid激活函数 传送门
向左走概率:
计算节点n的向量θₙ与隐藏层h的点积,通过Sigmoid转换为概率
值域(0,1),表示向左子树遍历的倾向性
向右走概率:
与向左概率互补,保证$p(n,left) + p(n,right) = 1$
负号来源于Sigmoid性质:$1-σ(x) = σ(-x)$
词$w_2$的条件概率计算过程:
$$
路径为:根节点 → n(w₂,1)(左) → n(w₂,2)(左) → n(w₂,3)(右) → w₂
目标词概率可表示为:
Sign阶跃函数传送门
参数解释:
符号
含义
$w_2$
目标词汇(叶子节点)
$n(w_2, k)$
$w_2$在Huffman树路径上的第$k$个非叶子节点
$\theta_{n(w_2, k)}$
非叶子节点$n(w_2, k)$的向量表示(模型参数)
$h$
隐藏层输出(上下文向量的聚合表示)
$\sigma(\cdot)$
Sigmoid函数:$\sigma(x) = \frac{1}{1+e^{-x}}$
left/right
在节点处向左/右子树遍历的决策方向
负采样
有一个中心词“eating”的句子,需要预测上下文词“am”和“food”。
首先,中心词的嵌入是通过对字符 n-gram 和整个词本身的向量求和来计算的。
对于实际的上下文词,我们直接从嵌入表中获取它们的词向量,而不添加字符 n-gram。
随机收集负样本,其概率与一元频率的平方根成比例。对于一个实际的上下文词,随机抽取 5 个否定词。然后在中心词和实际上下文词之间进行点积,并应用 sigmoid 函数来获得 0 到 1 之间的匹配分数。
基于损失,使用 SGD 优化器更新嵌入向量,以使实际上下文词更接近中心词,但增加与负样本的距离。
经过处理:
Fasttext总结 相比于Bert等方法,fastText具有如下优点:
训练速度快,精度相当;
不需要预训练的词向量;
N-gram特征关注了词序信息;
层次化Softmax优化了时间效率。
FastText最佳实践 安装FastText工具包 FastText是Facebook开源的NLP工具包,可用于训练Word2Vec词向量:
1 2 3 4 5 6 7 pip install fasttext git clone https://github.com/facebookresearch/fastText.git cd fastText pip install .
训练词向量 1 2 3 4 5 6 7 8 9 10 import fasttextmodel = fasttext.train_unsupervised('./data/fil9' ) model.save_model("./data/fil9.bin" ) model = fasttext.load_model('./data/fil9.bin' )
获取词向量 1 2 3 4 5 6 7 vector = model.get_word_vector('the' ) print (vector.shape) neighbors = model.get_nearest_neighbors('music' ) print (neighbors)
参数设置 1 2 3 4 5 6 model = fasttext.train_unsupervised('data/fil9' , model="skipgram" , dim=300 , epoch=5 , lr=0.1 , thread=8 )
FastText API
模型训练: model = fasttext.train_supervised(input=”data/cooking/cooking.train”)
模型预测: model.predict(“Which baking dish is best to bake a banana bread ?”)
模型测试: model.test(“data/cooking/cooking.valid”)
模型保存与重加载
增加训练轮数:
model1 = fasttext.train_supervised(input=”cooking.train”, epoch=25)
调整学习率
model2 = fasttext.train_supervised(input=”cooking.train”, lr=1.0, epoch=30)
增加n-gram特征
model3 = fasttext.train_supervised(input=”cooking.train”, lr=1.0, epoch=30, wordNgrams=2)
修改损失计算方式:
model4 = fasttext.train_supervised(input=”cooking.train”, lr=1.0, epoch=30, wordNgrams=2, loss=’hs’)
自动超参数调优
model5 = fasttext.train_supervised(input=’cooking.train’, autotuneValidationFile=’cooking.valid’, autotuneDuration=600)
实际生产中多标签多分类问题的损失计算方式:
model6 = fasttext.train_supervised(input=”cooking.train”, lr=0.2, epoch=30, wordNgrams=2, loss=’ova’)
FastText词向量迁移
词向量迁移是指利用预训练好的词向量模型,将其应用到新的NLP任务中。
FastText提供了多种语言的预训练词向量,可以直接下载使用,无需从头训练。
FastText官方提供了两类主要的词向量模型:
CommonCrawl和Wikipedia训练的词向量 :
Wikipedia训练的词向量 :
下载词向量模型 使用wget命令下载中文词向量模型:
1 wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.zh.300.bin.gz
解压模型文件 使用gunzip解压下载的压缩文件:
解压后会得到cc.zh.300.bin文件。
加载词向量模型 在Python中使用FastText加载模型:
1 2 3 4 import fasttextmodel = fasttext.load_model("cc.zh.300.bin" )
使用词向量 获取单个词的向量表示 1 2 3 music_vector = model.get_word_vector("音乐" ) print (music_vector)
查找相似词 1 2 3 similar_words = model.get_nearest_neighbors("音乐" ) print (similar_words)
输出示例:
1 2 3 4 5 6 7 8 9 10 [(0.6703276634216309 ,'乐曲' ), (0.6569967269897461 ,'音乐人' ), (0.6565821170806885 ,'声乐' ), (0.6557438373565674 ,'轻音乐' ), (0.6536258459091187 ,'音乐家' ), (0.6502416133880615 ,'配乐' ), (0.6501686573028564 ,'艺术' ), (0.6437276005744934 ,'音乐会' ), (0.639589250087738 ,'原声' ), (0.6368917226791382 ,'音响' )]
获取句子/文本的向量表示 1 2 3 4 sentence = "这是一首优美的音乐" words = sentence.split() sentence_vector = sum (model.get_word_vector(word) for word in words) / len (words)
注意力机制
Attention,也就是注意力机制,是2015年Bahdanau等人提出的,大概意思就是让Encoder编码出的c向量跟Decoder解码过程中的每一个输出进行加权运算,在解码的每一个过程中调整权重取到不一样的c向量,更通俗的讲就是c 就是包含“欢迎来北京”这句话的意思,翻译到第一个词“welcome”的时候,需要着重去看“欢迎”这个词。
Attention听上去就是一个很牛,不明觉厉的东西,实际实现起来就是,哦原来是这么回事。说白了Attention机制就是让编码器编码出来的向量根据解码器要解码的东西动态变化的一种机制,貌似来源灵感就是人类视觉在看某一个东西的时候会有选择的针对重要的地方看。
参考链接:
注意力机制的核心组件:
Q (Query):表示要查询的信息(如当前单词)。K (Key):表示被查询的信息(如上下文单词)。V (Value):表示实际要加权的信息(通常和 K 相同)。
类比档案柜查找文件:
Q相当于正在研究的课题(写在便利贴上)
K相当于文件夹上贴的标签(key#1 key#2)
V相当于正在查找的内容(文档、书籍资料)
面试题
说一说注意力机制QKV的含义和QKV的基本计算规则
说一说自注意力机制的计算过程
原理
比如在翻译过程中,需要将中文的”我”翻译成英文的”me”,这就需要”我”和”me”之间的注意力分数相对于"我"和其他英文单词的要高。
Query:将当前输入的特征,也就是”我”看作成 Query。
Key:可以将每个单词的重要特征表示 看作成 Key。
Key作为单词的”特征索引”,用于与Query进行匹配计算,在翻译任务中,Key会编码单词的:
语义特征(如词性、含义)
上下文关联特征(与其他词的潜在关系)
Value:每个单词本身的特征向量看作为 Value,一般和 Key成对出现,也就是”键-值”对。
具体操作 (1)先根据 Query,Key计算两者的相关性 ,然后再通过 softmax 函数得到 注意力分数 ,使用 softmax 函数是为了使得所有的注意力分数在 [0,1] 之间,并且和为1。Query,Key的相关性公式一般表示如下:
$$
$\alpha(q, k_i)$ 有很多变体,比如:加性注意力 、缩放点积注意力 等等。
在加性注意力 中,主要是将 Query,Key分别乘以对应的可训练矩阵,然后进行相加,具体如下:
其中, ,$W_q,W_k$ 分别是是 Query,Key对应的可训练矩阵, $w^T_v$ 是 Value对应的可训练矩阵,是为了后面方便和 Value 进行相乘。
在缩放点积注意力中,主要是直接将Query,Key进行相乘,具体如下:
从公式可以看出,这就需要 Query,Key的长度是一样的,都为 $d$ ;为什么要除以 $\sqrt{d}$ ?除以 $\sqrt{d}$ 的原因是防$q$ 和 $k$的点乘结果较大。防止点积结果过大导致softmax梯度消失。
(2)根据注意力分数进行加权求和,得到带注意力分数的 Value ,以方便进行下游任务。
在(1)中,我们得到了Query,Key的相关性,如果相关性越大,注意力分数就越高,反之越低;
然后将注意力分数乘以对应的 Value,再进行加权求和;比如:”我”和”me”的相关性较大,注意力分数就会越高;
这样可以让下游任务理解”我”和”me”是匹配程度高。
反之,如果直接将不带注意力分数的 V 进行输入到下游任务,下游任务可能会认为所有单词的重要性程度都是一样的,或者随机将不相关的单词与 Query 进行匹配。
代码实现
初始化函数:
attn线性层:将拼接后的Q和K映射到隐藏空间v参数:用于计算注意力得分的可学习向量
前向传播函数:
扩展隐藏状态维度以匹配编码器输出
计算能量值(energy)并应用tanh激活
使用可学习参数v计算注意力分数
返回softmax归一化的注意力权重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import torchimport torch.nn as nnimport torch.nn.functional as Fclass BasicAttention (nn.Module): def __init__ (self, hidden_size ): super ().__init__() self.attn = nn.Linear(hidden_size * 2 , hidden_size) self.v = nn.Parameter(torch.rand(hidden_size)) def forward (self, hidden, encoder_outputs ): seq_len = encoder_outputs.size(0 ) hidden = hidden.repeat(seq_len, 1 , 1 ) energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2 ))) energy = energy.permute(1 , 2 , 0 ) v = self.v.repeat(encoder_outputs.size(1 ), 1 ).unsqueeze(1 ) attention = torch.bmm(v, energy).squeeze(1 ) return F.softmax(attention, dim=1 )
$$
特性:
将$K$维向量$\mathbf{z}$压缩为概率分布
输出范围$(0,1)$,且所有元素和为1
重要恒等变形:
$$
自注意力机制
自注意力机制的基本思想是,在处理序列数据时,每个元素都可以与序列中的其他元素建立关联,而不仅仅是依赖于相邻位置的元素。它通过计算元素之间的相对重要性来自适应地捕捉元素之间的长程依赖关系。
QK操作 Embedding(转成词向量)操作后, $a^{1},a^{2},a^{3},a^{4}$ 将会作为注意力机制的 input data。
第一步 ,每个 $a^{1},a^{2},a^{3},a^{4}$ 都会分别乘以三个矩阵,分别是 $q, k, v$ (注意:矩阵 $q, k, v$ 在整个过程中是共享的)
公式如下:
$$
$$
$q$ (Query) 用来和其他单词进行匹配,更准确地说是用来计算当前单词或字与其他的单词或字之间的关联或者关系;(如下图)
$k$ (Key) 的含义则是被用来和 $q$ 进行匹配,也可理解为单词或者字的关键信息。
如下图所示,若需要计算 $a^1$ 和 $a^{2},a^{3},a^{4}$ 之间的关系(或关联),则需要用 $q^1$ 和 $k^{2},k^{3},k^{4}$ 进行匹配计算,计算公式如下:
其中, $d$ 表示 $q$ 和 $k$ 的矩阵维度,在 Self-Attention 中, $q$ 和 $k$ 的维度是一样的。这里除以 $\sqrt{d}$ 的原因是防$q$ 和 $k$的点乘结果较大。
经过 $q$ 和 $k$ 的点乘操作后,会得到
然后,就是对其进行 softmax 操作,得到
如上图的$exp$函数即 自然指数函数: $e^x$
V操作 $v$ 的含义主要是表示当前单词或字的重要信息表示,也可以理解为单词的重要特征,例如: $v^1$ 代表”你”这个字的重要信息。在 $v$ 操作中,会将 $q, k$ 操作后得到的
同理:$b^2$也是类似的机制,自注意力机制通过计算序列中不同位置之间的相关性( $q, k$ 操作),为每个位置分配一个权重,然后对序列进行加权求和( $v$ 操作)。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import torchimport torch.nn as nnclass SelfAttention (nn.Module): dim_in: int dim_k: int dim_v: int def __init__ (self, dim_in, dim_k, dim_v ): super (SelfAttention, self).__init__() self.dim_in = dim_in self.dim_k = dim_k self.dim_v = dim_v self.linear_q = nn.Linear(dim_in, dim_k, bias=False ) self.linear_k = nn.Linear(dim_in, dim_k, bias=False ) self.linear_v = nn.Linear(dim_in, dim_v, bias=False ) self._norm_fact = 1 / sqrt(dim_k) def forward (self, x ): batch, n, dim_in = x.shape assert dim_in == self.dim_in q = self.linear_q(x) k = self.linear_k(x) v = self.linear_v(x) dist = torch.bmm(q, k.transpose(1 , 2 )) * self._norm_fact dist = torch.softmax(dist, dim=-1 ) att = torch.bmm(dist, v) return att
多头自注意力机制
多头注意力机制是在自注意力机制的基础上发展起来的,是自注意力机制的变体,旨在增强模型的表达能力和泛化能力。该机制 使用多个独立的注意力头,分别计算注意力权重,并将它们的结果进行拼接或加权求和,从而获得更丰富的表示。
在自注意力机制中,每个单词或者字都仅仅只有一个 $q, k ,v$ 与其对应,
多头注意力机制则是在 $a^i$ 乘以一个 $q, k ,v$ 后,会再分配多个 $q, k, v$ ,这里以2个 $q, k, v$ 为例,如下图所示;
QK操作 在多头注意力机制中, $a^i$ 会先乘 $q$ 矩阵, $q^i=W^qa^i$ ;
其次,会为其多分配两个head,以 $q$ 为例,包括: $q^{i,1}, q^{i,2}$ ;
$$
同样地, $k$ 和 $v$ 也是一样的操作。
那么,下面就是 $q$ 和 $k$ 的点乘操作了,在多头注意力机制中,有多个$q$ 和 $k$,究竟应该选择哪个进行操作呢?
其实很简单,就是看下标,如下图所示。 $q^{i,1}$ 会和 $k^{i,1}$ 和 $k^{j,1}$ 进行点乘,再进行 softmax 操作。
V操作 多头注意力机制中 $v$ 操作和自注意力机制操作是类似的
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import torchimport torch.nn as nnclass MultiHeadSelfAttention (nn.Module): dim_in: int dim_k: int dim_v: int num_heads: int def __init__ (self, dim_in, dim_k, dim_v, num_heads=8 ): super (MultiHeadSelfAttention, self).__init__() assert dim_k % num_heads == 0 and dim_v % num_heads == 0 , "dim_k and dim_v must be multiple of num_heads" self.dim_in = dim_in self.dim_k = dim_k self.dim_v = dim_v self.num_heads = num_heads self.linear_q = nn.Linear(dim_in, dim_k, bias=False ) self.linear_k = nn.Linear(dim_in, dim_k, bias=False ) self.linear_v = nn.Linear(dim_in, dim_v, bias=False ) self._norm_fact = 1 / sqrt(dim_k // num_heads) def forward (self, x ): batch, n, dim_in = x.shape assert dim_in == self.dim_in nh = self.num_heads dk = self.dim_k // nh dv = self.dim_v // nh q = self.linear_q(x).reshape(batch, n, nh, dk).transpose(1 , 2 ) k = self.linear_k(x).reshape(batch, n, nh, dk).transpose(1 , 2 ) v = self.linear_v(x).reshape(batch, n, nh, dv).transpose(1 , 2 ) dist = torch.matmul(q, k.transpose(2 , 3 )) * self._norm_fact dist = torch.softmax(dist, dim=-1 ) att = torch.matmul(dist, v) att = att.transpose(1 , 2 ).reshape(batch, n, self.dim_v) return att
通道注意力机制
通道注意力机制(Channel Attention Mechanism)是深度学习中的一种重要注意力机制,主要用于处理卷积神经网络中的特征通道关系。
通道注意力机制的核心思想是通过学习每个通道的重要性程度,动态调整不同通道的权重,使网络能够更加关注那些对当前任务更有用的特征通道。这种机制模仿了人类视觉系统对信息的选择性关注能力。
SENet
通道注意力机制通过显式建模通道间的依赖关系,使网络能够自适应地重新校准通道维度的特征响应。SENet作为其典型代表,以极小的计算代价带来了显著的性能提升。
目前最经典的通道注意力机制实现是SENet(Squeeze-and-Excitation Networks),它通过以下三个主要步骤实现通道注意力:
Squeeze操作 :通过全局平均池化将每个通道的特征图压缩为一个标量值,得到一个1×1×C的矩阵。这一步的目的是获取每个通道的全局信息。Excitation操作 :通过一个包含两层全连接层的小型神经网络(中间有ReLU激活函数)学习通道间的非线性关系,输出每个通道的权重。Scale操作 :将学习到的通道权重与原始特征图相乘,实现对不同通道的特征进行重新校准。
如上图所示,数据$X$经过卷积操作后,得到 $U$ , $U$ 的通道数用 $C$ 表示, $H\times W$ 表示一个通道上的长和宽;此后,SENet引入了一个Squeeze模块 $F_{sq}(\cdot)$ 和一个Excitation模块 $F_{ex}(\cdot,W)$ 。
$F_{sq}(\cdot)$ 通过全局平均池化操作将每个通道的特征图转化为一个标量值,简单地说,就是用全局平均池化将每个通道上的数据进行压缩,压缩成一个标量值,即得到一个 $1\times1\times C$ 的矩阵。然后, $F_{ex}(\cdot,W)$ 通过激活函数(如sigmoid或ReLU)对$1\times1\times C$ 的矩阵进行操作, $W$ 表示的就是激活函数,得到带有颜色的$1\times1\times C$ 的矩阵,用来来学习每个通道的权重。最后,经过 $F_{scale}(\cdot,\cdot)$ 将这些权重应用于原始特征图上,将带有颜色的$1\times1\times C$ 的矩阵和 $U$进行点乘 ,以得到加权后的特征图。最后,将加权后的特征图输入到后续的卷积层进行分类或检测任务。
值得注意的是,SENet并不是一个单独的网络结构,而是可以与其他卷积神经网络结构(如ResNet、Inception等)相结合,以增强它们的表达能力。通过在现有网络结构中添加SENet模块,可以更容易地将SENet应用于现有的深度学习任务中。说的更加简答粗暴点,可以直接在每个卷积之后都可以添加SENet,当然这样也有可能会带来过拟合的问题。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import torch.nn as nnimport torch.nn.functional as Fclass SE (nn.Module): def __init__ (self, in_chnls, ratio ): super (SE, self).__init__() self.squeeze = nn.AdaptiveAvgPool2d((1 , 1 )) self.compress = nn.Conv2d(in_chnls, in_chnls // ratio, 1 , 1 , 0 ) self.excitation = nn.Conv2d(in_chnls // ratio, in_chnls, 1 , 1 , 0 ) def forward (self, x ): out = self.squeeze(x) out = self.compress(out) out = F.relu(out) out = self.excitation(out) return x*F.sigmoid(out)
空间注意力机制
空间注意力机制(Spatial Attention Mechanism)是一种让模型能够自动学习并关注输入数据中重要空间区域的技术。与通道注意力机制关注不同通道的重要性不同,空间注意力机制关注的是输入特征图中不同空间位置的重要性。
CBAM 在CBAM(Convolutional Block Attention Module)中,空间注意力模块的具体工作流程如下:
特征提取 :首先对输入特征图在通道维度上分别进行最大池化和平均池化操作,得到两个空间特征图:
最大池化:获取每个空间位置在所有通道上的最大值
平均池化:获取每个空间位置在所有通道上的平均值
特征拼接 :将这两个特征图在通道维度上进行拼接,形成一个两通道的特征图。卷积处理 :通过一个卷积层(通常使用7×7或3×3的卷积核)处理拼接后的特征图,生成空间注意力权重图。Sigmoid激活 :使用Sigmoid函数将权重归一化到0到1之间,表示每个空间位置的重要性。特征加权 :将生成的注意力权重图与原始输入特征图相乘,得到加权后的输出特征图。
CBAM模块由两个注意力模块组成:通道注意力模块(Channel Attention Module)和空间注意力模块(Spatial Attention Module)。
它使用全局平均池化和全局最大池 化分别来获取每个通道的全局统计信息(SENet仅使用全局平均池化),并通过两层全连接层来学习通道的权重。然后,会将处理后产生的两个结果进行相加,通过使用Sigmoid函数将权重归一化到0到1之间,对每个通道进行缩放。最后,将缩放后的通道特征与原始特征相乘,以产生具有增强通道重要性的特征。
CBAM中空间注意力模块是使用最大池化和平均池化来获取每个空间位置的最大值和平均值。具体地说,由于卷积之后会产生多个通道,CBAM中空间注意力会在每一个特征点的通道上进行最大池化和平均池化操作,得到两个matrix后,将两个matrix进行拼接,并通过一个卷积层和Sigmoid函数来学习每个空间位置的权重。最后,将权重应用于特征图上的每个空间位置,以产生具有增强空间重要性的特征。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 class SpatialAttention (nn.Module): def __init__ (self, kernel_size=7 ): super (SpatialAttention, self).__init__() assert kernel_size in (3 , 7 ), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2 , 1 , kernel_size, padding=padding, bias=False ) self.sigmoid = nn.Sigmoid() def forward (self, x ): avg_out = torch.mean(x, dim=1 , keepdim=True ) max_out, _ = torch.max (x, dim=1 , keepdim=True ) x = torch.cat([avg_out, max_out], dim=1 ) x = self.conv1(x) return self.sigmoid(x)
Seq2Seq架构中的注意力机制 seq中的注意力机制
注意力机制是一种通用思想 在不同的框架中有不同的表现形式 下面简单总结一下。
参考链接:Seq2Seq架构中的注意力机制
seq2seq模型架构 包括三部分,以及处理的部分,分别是
encoder(编码器)
1个时间步1个时间步的编码,每个时间步有隐藏层输出,最终组合成中间语义张量C
decoder(解码器):1个时间步1个时间步的解码
1 解码 :每个时间步输入:input和ht-1、输出output和ht
2 再接一个全连接层+Softmax做一个分类,从分类结果中找一个预测结果即可
中间语义张量C
seq2seq中QKV
q:经过词嵌入以后的张量,q查询谁就是谁的查询张量(input)
注意:q的查询目标是谁,就是谁的查询张量。这个目标感要建立起来
比如:输入welcome,想要查询to,那么welcome的词向量就是to的查询张量q
k:上一个时间步的隐藏层输出(hidden)
v:中间语义张量C(encoder_output)
注意力机制计算规则 $$ \text{Attention}(Q,K,V)=\text{Softmax}(\text{Linear}([Q,K]))*V $$
将 $Q$ 和 $K$ 在最后一个维度(特征层)拼接,做一次线性变换,再用 softmax 处理获得权重;最后与 $V$ 做张量乘法。
$$ \text{Attention}(Q,K,V)=\text{Softmax}(\text{sum}(\tanh(\text{Linear}([Q,K]))))*V $$
将 $Q$ 和 $K$ 在最后一个维度拼接
做一次线性变换后使用 $\tanh$ 函数激活
对激活结果进行内部求和
用 softmax 处理获得权重
最后与 $V$ 做张量乘法
缩放点积(Scaled Dot-Product)注意力机制
$$ \text{Attention}(Q,K,V)=\text{Softmax}\left(\frac{Q*K^T}{\sqrt{d_k}}\right)*V $$
将 $Q$ 与 $K$ 的转置做点积运算
除以缩放系数 $\sqrt{d_k}$($d_k$ 为 $K$ 的维度)
用 softmax 处理获得权重
最后与 $V$ 做张量乘法
最常用的就是1、3.
什么是Seq2Seq
所谓Seq2Seq(Sequence to Sequence),即序列到序列模型,就是一种能够根据给定的序列,通过特定的生成方法生成另一个序列的方法,同时这两个序列可以不等长。这种结构又叫Encoder-Decoder模型,即编码-解码模型,其是RNN的一个变种,为了解决RNN要求序列等长的问题。
比如在智能问答,你输入了一个问题,然后大模型给你返回了一个回答,这个就是seq2seq。
参考链接:
结构如上图所示,在编码过程中,输入序列通过Encoder,得到语义向量C,语义向量C作为Decoder的初始状态 h0,参与解码过程,生成输出序列。此处Encoder和Decoder都是RNN单元,C可以看作输入序列内容的一个集合,输入序列所有的语义信息都包含在C这个向量里面。详见第三部分原理解析。
同时,Seq2Seq使用的都是RNN单元,一般为LSTM和GRU。
如上图所示
在Encoder中,“欢迎/来/北京”这些词转换成词向量,也就是Embedding,用 $v_i$来表示,
与上一时刻的隐状态 $h_{t-1}$按照时间顺序进行输入,每一个时刻输出一个隐状态$h_{t}$ ,
可以用函数$f$ 表达RNN隐藏层的变换:
$c$就相当于从“欢迎/来/北京”这几个单词中提炼出来的大概意思一样,包含了这句话的含义。
Decoder的每一时刻的输入为Eecoder输出的$c$ 和Decoder前一时刻解码的输出$s_{t-1}$ ,还有前一时刻预测的词的向量$E_{t-1}$ (如果是预测第一个词的话,此时输入的词向量为“_GO”的词向量,标志着解码的开始),我们可以用函数$g$ 表达解码器隐藏层变换:
直到解码解出“_EOS”,标志着解码的结束。
Seq2Seq引入Attention机制 带注意力的解码器: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class AttnDecoderRNN (nn.Module): def __init__ (self, hidden_size, output_size, dropout_p=0.1 ): super ().__init__() self.hidden_size = hidden_size self.output_size = output_size self.dropout_p = dropout_p self.embedding = nn.Embedding(output_size, hidden_size) self.attn = BasicAttention(hidden_size) self.gru = nn.GRU(hidden_size * 2 , hidden_size) self.out = nn.Linear(hidden_size * 2 , output_size) self.dropout = nn.Dropout(dropout_p) def forward (self, input , hidden, encoder_outputs ): embedded = self.embedding(input ).view(1 , 1 , -1 ) embedded = self.dropout(embedded) attn_weights = self.attn(hidden, encoder_outputs) attn_applied = torch.bmm(attn_weights.unsqueeze(0 ), encoder_outputs.transpose(0 , 1 )) gru_input = torch.cat((embedded[0 ], attn_applied[0 ]), 1 ) gru_input = gru_input.unsqueeze(0 ) output, hidden = self.gru(gru_input, hidden) output = F.log_softmax(self.out(torch.cat((output[0 ], attn_applied[0 ]), 1 )), dim=1 ) return output, hidden, attn_weights
带注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class AttnDecoderRNN (nn.Module): def __init__ (self, hidden_size, output_size, dropout_p=0.1 ): super ().__init__() self.hidden_size = hidden_size self.output_size = output_size self.dropout_p = dropout_p self.embedding = nn.Embedding(output_size, hidden_size) self.attn = BasicAttention(hidden_size) self.gru = nn.GRU(hidden_size * 2 , hidden_size) self.out = nn.Linear(hidden_size * 2 , output_size) self.dropout = nn.Dropout(dropout_p) def forward (self, input , hidden, encoder_outputs ): embedded = self.embedding(input ).view(1 , 1 , -1 ) embedded = self.dropout(embedded) attn_weights = self.attn(hidden, encoder_outputs) attn_applied = torch.bmm(attn_weights.unsqueeze(0 ), encoder_outputs.transpose(0 , 1 )) gru_input = torch.cat((embedded[0 ], attn_applied[0 ]), 1 ) gru_input = gru_input.unsqueeze(0 ) output, hidden = self.gru(gru_input, hidden) output = F.log_softmax(self.out(torch.cat((output[0 ], attn_applied[0 ]), 1 )), dim=1 ) return output, hidden, attn_weights
缩放点积注意力机制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def scaled_dot_product_attention (Q, K, V, mask=None ): """ Q: [batch_size, seq_len_q, depth] K: [batch_size, seq_len_k, depth] V: [batch_size, seq_len_v, depth] """ matmul_qk = torch.matmul(Q, K.transpose(-2 , -1 )) dk = K.size(-1 ) scaled_attention_logits = matmul_qk / torch.sqrt(torch.tensor(dk, dtype=torch.float32)) if mask is not None : scaled_attention_logits += (mask * -1e9 ) attention_weights = F.softmax(scaled_attention_logits, dim=-1 ) output = torch.matmul(attention_weights, V) return output, attention_weights
多头注意力机制实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class MultiHeadAttention (nn.Module): def __init__ (self, d_model, num_heads ): super ().__init__() self.num_heads = num_heads self.d_model = d_model assert d_model % num_heads == 0 self.depth = d_model // num_heads self.wq = nn.Linear(d_model, d_model) self.wk = nn.Linear(d_model, d_model) self.wv = nn.Linear(d_model, d_model) self.dense = nn.Linear(d_model, d_model) def split_heads (self, x, batch_size ): x = x.view(batch_size, -1 , self.num_heads, self.depth) return x.permute(0 , 2 , 1 , 3 ) def forward (self, q, k, v, mask=None ): batch_size = q.size(0 ) q = self.wq(q) k = self.wk(k) v = self.wv(v) q = self.split_heads(q, batch_size) k = self.split_heads(k, batch_size) v = self.split_heads(v, batch_size) scaled_attention, attention_weights = scaled_dot_product_attention( q, k, v, mask) scaled_attention = scaled_attention.permute(0 , 2 , 1 , 3 ) concat_attention = scaled_attention.reshape(batch_size, -1 , self.d_model) output = self.dense(concat_attention) return output, attention_weights
带注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class MultiHeadAttention (nn.Module): def __init__ (self, d_model, num_heads ): super ().__init__() self.num_heads = num_heads self.d_model = d_model assert d_model % num_heads == 0 self.depth = d_model // num_heads self.wq = nn.Linear(d_model, d_model) self.wk = nn.Linear(d_model, d_model) self.wv = nn.Linear(d_model, d_model) self.dense = nn.Linear(d_model, d_model) def split_heads (self, x, batch_size ): x = x.view(batch_size, -1 , self.num_heads, self.depth) return x.permute(0 , 2 , 1 , 3 ) def forward (self, q, k, v, mask=None ): batch_size = q.size(0 ) q = self.wq(q) k = self.wk(k) v = self.wv(v) q = self.split_heads(q, batch_size) k = self.split_heads(k, batch_size) v = self.split_heads(v, batch_size) scaled_attention, attention_weights = scaled_dot_product_attention( q, k, v, mask) scaled_attention = scaled_attention.permute(0 , 2 , 1 , 3 ) concat_attention = scaled_attention.reshape(batch_size, -1 , self.d_model) output = self.dense(concat_attention) return output, attention_weights
线性变换(wq, wk, wv)
输入 q, k, v 经过线性层,生成 Q, K, V(维度不变,仍是 d_model)。
分割多头(split_heads)
将 Q, K, V 拆分成 num_heads 个头,每个头维度为 depth。
计算缩放点积注意力(scaled_dot_product_attention)
每个头独立计算注意力(并行计算)。
输出 scaled_attention:[batch_size, num_heads, seq_len_q, depth]。
输出 attention_weights:[batch_size, num_heads, seq_len_q, seq_len_k](可解释性)。
合并多头(concat_attention)
最终线性变换(dense)
注意力权重可视化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import matplotlib.pyplot as pltdef plot_attention (attention, sentence, predicted_sentence ): fig = plt.figure(figsize=(10 ,10 )) ax = fig.add_subplot(111 ) ax.matshow(attention, cmap='viridis' ) fontdict = {'fontsize' : 14 } ax.set_xticklabels(['' ] + sentence, fontdict=fontdict, rotation=90 ) ax.set_yticklabels(['' ] + predicted_sentence, fontdict=fontdict) plt.show()
1. 函数定义
1 def plot_attention (attention, sentence, predicted_sentence ):
输入参数:
attention:注意力权重矩阵(2D numpy 数组或 PyTorch/TensorFlow 张量),形状为:[target_len, source_len]
例如:attention.shape = (5, 7) 表示目标句子有 5 个词,源句子有 7 个词。
sentence:源句子(输入句子),是一个单词列表(如 ["I", "love", "Python"])。
predicted_sentence:目标句子(模型生成的句子),也是一个单词列表(如 ["我", "喜欢", "Python"])。
2. 创建画布
1 2 fig = plt.figure(figsize=(10 , 10 )) ax = fig.add_subplot(111 )
figsize=(10, 10):设置图像大小为 10x10 英寸(保证热力图清晰)。add_subplot(111):创建一个单子图(1行1列的第1个子图)。
3. 绘制热力图
1 ax.matshow(attention, cmap='viridis' )
matshow():绘制矩阵热力图。cmap='viridis':使用 viridis 颜色映射(从蓝到黄,适合科学可视化)。
4. 设置坐标轴标签
1 2 3 4 5 6 7 fontdict = {'fontsize' : 14 } ax.set_xticklabels(['' ] + sentence, fontdict=fontdict, rotation=90 ) ax.set_yticklabels(['' ] + predicted_sentence, fontdict=fontdict)
[''] + sentencerotation=90fontsize=14
5. 显示图像
Seq2Seq英译法案例 数据处理流程 读数据到内存 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import reimport torchimport torch.nn as nnfrom torch.utils.data import Dataset, DataLoaderdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu" ) SOS_token = 0 EOS_token = 1 MAX_LENGTH = 10 data_path = './data/eng-fra-v2.txt' def normalizeString (s ): """字符串规范化函数""" s = s.lower().strip() s = re.sub(r"([.!?])" , r" \1" , s) s = re.sub(r"[^a-zA-Z.!?]+" , r" " , s) return s def get_data (): """读取并处理数据""" lines = open (data_path, encoding='utf-8' ).read().strip().split('\n' ) pairs = [[normalizeString(s) for s in l.split('\t' )] for l in lines] eng_word2idx = {"SOS" : 0 , "EOS" : 1 } eng_idx2word = {0 : "SOS" , 1 : "EOS" } fra_word2idx = {"SOS" : 0 , "EOS" : 1 } fra_idx2word = {0 : "SOS" , 1 : "EOS" } eng_vocab_size = 2 fra_vocab_size = 2 for pair in pairs: for word in pair[0 ].split(): if word not in eng_word2idx: eng_word2idx[word] = eng_vocab_size eng_idx2word[eng_vocab_size] = word eng_vocab_size += 1 for word in pair[1 ].split(): if word not in fra_word2idx: fra_word2idx[word] = fra_vocab_size fra_idx2word[fra_vocab_size] = word fra_vocab_size += 1 return eng_word2idx, eng_idx2word, eng_vocab_size, \ fra_word2idx, fra_idx2word, fra_vocab_size, pairs eng_word2idx, eng_idx2word, eng_vocab_size, \ fra_word2idx, fra_idx2word, fra_vocab_size, pairs = get_data()
带详细注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import reimport torchimport torch.nn as nnfrom torch.utils.data import Dataset, DataLoaderdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu" ) SOS_token = 0 EOS_token = 1 MAX_LENGTH = 10 data_path = './data/eng-fra-v2.txt' def normalizeString (s ): """字符串规范化函数""" s = s.lower().strip() s = re.sub(r"([.!?])" , r" \1" , s) s = re.sub(r"[^a-zA-Z.!?]+" , r" " , s) return s def get_data (): """读取并处理数据""" lines = open (data_path, encoding='utf-8' ).read().strip().split('\n' ) "Hello\tBonjour" , "Good morning\tBon matin" , "How are you?\tComment ça va?" , pairs = [[normalizeString(s) for s in l.split('\t' )] for l in lines] ["hello" , "bonjour" ], ["good morning" , "bon matin" ], ["how are you ?" , "comment ca va ?" ], eng_word2idx = {"SOS" : 0 , "EOS" : 1 } eng_idx2word = {0 : "SOS" , 1 : "EOS" } fra_word2idx = {"SOS" : 0 , "EOS" : 1 } fra_idx2word = {0 : "SOS" , 1 : "EOS" } eng_vocab_size = 2 fra_vocab_size = 2 for pair in pairs: for word in pair[0 ].split(): if word not in eng_word2idx: eng_word2idx[word] = eng_vocab_size eng_idx2word[eng_vocab_size] = word eng_vocab_size += 1 for word in pair[1 ].split(): if word not in fra_word2idx: fra_word2idx[word] = fra_vocab_size fra_idx2word[fra_vocab_size] = word fra_vocab_size += 1 return eng_word2idx, eng_idx2word, eng_vocab_size, \ fra_word2idx, fra_idx2word, fra_vocab_size, pairs eng_word2idx, eng_idx2word, eng_vocab_size, \ fra_word2idx, fra_idx2word, fra_vocab_size, pairs = get_data()
构建Dataset类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class TranslationDataset (Dataset ): def __init__ (self, pairs, eng_word2idx, fra_word2idx ): self.pairs = pairs self.eng_word2idx = eng_word2idx self.fra_word2idx = fra_word2idx def __len__ (self ): return len (self.pairs) def __getitem__ (self, idx ): eng_sentence = self.pairs[idx][0 ] eng_indices = [self.eng_word2idx[word] for word in eng_sentence.split()] eng_indices.append(EOS_token) fra_sentence = self.pairs[idx][1 ] fra_indices = [self.fra_word2idx[word] for word in fra_sentence.split()] fra_indices.append(EOS_token) return torch.tensor(eng_indices, dtype=torch.long, device=device), \ torch.tensor(fra_indices, dtype=torch.long, device=device)
构建DataLoader 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 创建Dataset实例 dataset = TranslationDataset(pairs, eng_word2idx, fra_word2idx) # 创建DataLoader batch_size = 32 shuffle = True dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle) # 测试DataLoader for i, (eng, fra) in enumerate(dataloader): print(f"英文句子索引形状: {eng.shape}") print(f"法文句子索引形状: {fra.shape}") if i == 0: # 只查看第一个batch break
模型构建 编码器实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class EncoderRNN (nn.Module): def __init__ (self, input_size, hidden_size ): """ 编码器初始化 Args: input_size: 输入词汇表大小 hidden_size: 隐藏层维度 """ super (EncoderRNN, self).__init__() self.hidden_size = hidden_size self.embedding = nn.Embedding(input_size, hidden_size) self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True ) def forward (self, input , hidden ): """ 前向传播 Args: input: 输入序列 [batch_size, seq_len] hidden: 初始隐藏状态 [1, batch_size, hidden_size] Returns: output: GRU输出 [batch_size, seq_len, hidden_size] hidden: 最终隐藏状态 [1, batch_size, hidden_size] """ embedded = self.embedding(input ) output, hidden = self.gru(embedded, hidden) return output, hidden def initHidden (self, batch_size=1 ): """初始化隐藏状态""" return torch.zeros(1 , batch_size, self.hidden_size, device=device)
解码器实现(带注意力机制) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 class AttnDecoderRNN (nn.Module): def __init__ (self, output_size, hidden_size, dropout_p=0.1 , max_length=MAX_LENGTH ): """ 带注意力机制的解码器 Args: output_size: 输出词汇表大小 hidden_size: 隐藏层维度 dropout_p: dropout概率 max_length: 最大序列长度 """ super (AttnDecoderRNN, self).__init__() self.hidden_size = hidden_size self.output_size = output_size self.dropout_p = dropout_p self.max_length = max_length self.embedding = nn.Embedding(output_size, hidden_size) self.attn = nn.Linear(hidden_size * 2 , max_length) self.attn_combine = nn.Linear(hidden_size * 2 , hidden_size) self.dropout = nn.Dropout(dropout_p) self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True ) self.out = nn.Linear(hidden_size, output_size) def forward (self, input , hidden, encoder_outputs ): """ 前向传播 Args: input: 当前输入token [batch_size, 1] hidden: 上一个隐藏状态 [1, batch_size, hidden_size] encoder_outputs: 编码器输出 [batch_size, seq_len, hidden_size] Returns: output: 预测输出 [batch_size, output_size] hidden: 当前隐藏状态 [1, batch_size, hidden_size] attn_weights: 注意力权重 [batch_size, 1, seq_len] """ embedded = self.embedding(input ) embedded = self.dropout(embedded) attn_weights = F.softmax( self.attn(torch.cat((embedded[:, 0 ], hidden[0 ]), 1 )), dim=1 ) attn_applied = torch.bmm(attn_weights.unsqueeze(1 ), encoder_outputs) output = torch.cat((embedded[:, 0 ], attn_applied[:, 0 ]), 1 ) output = self.attn_combine(output).unsqueeze(1 ) output = F.relu(output) output, hidden = self.gru(output, hidden) output = F.log_softmax(self.out(output[:, 0 ]), dim=1 ) return output, hidden, attn_weights def initHidden (self, batch_size=1 ): """初始化隐藏状态""" return torch.zeros(1 , batch_size, self.hidden_size, device=device)
模型训练 训练函数实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 def train (input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH, teacher_forcing_ratio=0.5 ): """ 单次训练函数 Args: input_tensor: 输入张量 [batch_size, seq_len] target_tensor: 目标张量 [batch_size, seq_len] encoder: 编码器实例 decoder: 解码器实例 encoder_optimizer: 编码器优化器 decoder_optimizer: 解码器优化器 criterion: 损失函数 max_length: 最大序列长度 teacher_forcing_ratio: 使用teacher forcing的概率 Returns: 平均损失 """ batch_size = input_tensor.size(0 ) encoder_hidden = encoder.initHidden(batch_size) encoder_optimizer.zero_grad() decoder_optimizer.zero_grad() encoder_outputs, encoder_hidden = encoder(input_tensor, encoder_hidden) decoder_input = torch.tensor([[SOS_token]]*batch_size, device=device) decoder_hidden = encoder_hidden loss = 0 use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False if use_teacher_forcing: for di in range (target_tensor.size(1 )): decoder_output, decoder_hidden, decoder_attention = decoder( decoder_input, decoder_hidden, encoder_outputs) loss += criterion(decoder_output, target_tensor[:, di]) decoder_input = target_tensor[:, di].unsqueeze(1 ) else : for di in range (target_tensor.size(1 )): decoder_output, decoder_hidden, decoder_attention = decoder( decoder_input, decoder_hidden, encoder_outputs) topv, topi = decoder_output.topk(1 ) decoder_input = topi.detach() loss += criterion(decoder_output, target_tensor[:, di]) if decoder_input.item() == EOS_token: break loss.backward() encoder_optimizer.step() decoder_optimizer.step() return loss.item() / target_tensor.size(1 )
完整训练流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 def trainIters (encoder, decoder, dataloader, n_iters, learning_rate=0.01 , print_every=100 , plot_every=100 ): """ 完整训练流程 Args: encoder: 编码器实例 decoder: 解码器实例 dataloader: 数据加载器 n_iters: 训练迭代次数 learning_rate: 学习率 print_every: 每隔多少次打印一次信息 plot_every: 每隔多少次记录一次损失用于绘图 """ start = time.time() plot_losses = [] print_loss_total = 0 plot_loss_total = 0 encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate) decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate) criterion = nn.NLLLoss() iter_num = 0 while iter_num < n_iters: for input_tensor, target_tensor in dataloader: iter_num += 1 if iter_num > n_iters: break loss = train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion) print_loss_total += loss plot_loss_total += loss if iter_num % print_every == 0 : print_loss_avg = print_loss_total / print_every print_loss_total = 0 print ('%s (%d %d%%) %.4f' % (timeSince(start), iter_num, iter_num / n_iters * 100 , print_loss_avg)) if iter_num % plot_every == 0 : plot_loss_avg = plot_loss_total / plot_every plot_losses.append(plot_loss_avg) plot_loss_total = 0 plt.figure() plt.plot(plot_losses) plt.savefig('loss.png' ) plt.show() return plot_losses hidden_size = 256 encoder = EncoderRNN(eng_vocab_size, hidden_size).to(device) decoder = AttnDecoderRNN(fra_vocab_size, hidden_size).to(device) trainIters(encoder, decoder, dataloader, n_iters=7500 , print_every=100 )
模型预测与评估 评估函数实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 def evaluate (encoder, decoder, sentence, eng_word2idx, fra_idx2word, max_length=MAX_LENGTH ): """ 评估函数 Args: encoder: 编码器实例 decoder: 解码器实例 sentence: 输入句子字符串 eng_word2idx: 英文词汇表 fra_idx2word: 法文词汇表 max_length: 最大序列长度 Returns: 解码的单词列表 注意力权重 """ with torch.no_grad(): words = normalizeString(sentence).split() indices = [eng_word2idx[word] for word in words] indices.append(EOS_token) input_tensor = torch.tensor(indices, dtype=torch.long, device=device).view(1 , -1 ) encoder_hidden = encoder.initHidden() encoder_outputs, encoder_hidden = encoder(input_tensor, encoder_hidden) decoder_input = torch.tensor([[SOS_token]], device=device) decoder_hidden = encoder_hidden decoded_words = [] decoder_attentions = torch.zeros(max_length, max_length) for di in range (max_length): decoder_output, decoder_hidden, decoder_attention = decoder( decoder_input, decoder_hidden, encoder_outputs) decoder_attentions[di] = decoder_attention.data topv, topi = decoder_output.data.topk(1 ) if topi.item() == EOS_token: decoded_words.append('<EOS>' ) break else : decoded_words.append(fra_idx2word[topi.item()]) decoder_input = topi.detach() return decoded_words, decoder_attentions[:di+1 ]
可视化注意力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def showAttention (input_sentence, output_words, attentions ): """可视化注意力权重""" fig = plt.figure(figsize=(10 ,10 )) ax = fig.add_subplot(111 ) cax = ax.matshow(attentions.numpy(), cmap='bone' ) fig.colorbar(cax) ax.set_xticklabels(['' ] + input_sentence.split() + ['<EOS>' ], rotation=90 ) ax.set_yticklabels(['' ] + output_words) ax.xaxis.set_major_locator(ticker.MultipleLocator(1 )) ax.yaxis.set_major_locator(ticker.MultipleLocator(1 )) plt.show() def evaluateRandomly (encoder, decoder, eng_word2idx, fra_idx2word, n=10 ): """随机评估n个样本""" for i in range (n): pair = random.choice(pairs) print ('>' , pair[0 ]) print ('=' , pair[1 ]) output_words, attentions = evaluate(encoder, decoder, pair[0 ], eng_word2idx, fra_idx2word) output_sentence = ' ' .join(output_words) print ('<' , output_sentence) print ('' ) showAttention(pair[0 ], output_words, attentions) evaluateRandomly(encoder, decoder, eng_word2idx, fra_idx2word)
首先: 来一篇2017年的论文保命:Attention is all you need (经典咏流传)
针对RNN等序列模型不能并行运行,利用完全基于自注意力机制的自编码器去训练于是有了上述论文。
论文创新点包括:
利用LayerNormal:缓解梯度消失,提高模型的稳定性。
缩放点积注意力机制:对自注意力机制中 除以$Q{K}^T 除以 \sqrt{d^k}$ ,以防止乘积过大。
位置编码:由于 Transformer 不使用递归或卷积,它通过位置编码来加入序列中元素的位置信息。
自注意力机制:它允许模型在处理序列的每个元素时同时考虑序列中的所有其他元素,从而捕捉元素之间的关系。
多头注意力:Transformer 通过并行的多头注意力机制来捕获序列中不同位置的信息,增强模型的学习能力。
代码能够并行处理。
参考链接:
缩放点积注意力机制(Scaled Dot-Product Attention)公式:
Encoder Encoder部分主要包括:
将输入的单词或者符号转换成固定维度的向量表示,使其能够被模型处理。
Positional Encoding(位置编码)
词向量嵌入完成后,还要加上位置信息,因为在LSTM中,每个隐含层的节点,都是要接收上一个隐含层的输出,所以他是有天然的时序顺序在里面的。但是Transformer中,我们没有使用RNN,所以就需要我们给他的词向量中加入位置信息。
位置编码函数是如下定义的:
$$
其中, $d_{model}$ 是 input Embedding嵌入向量的维度,$pos$ 是单词在序列中的位置,$i$ 是嵌入向量中的维度索引。
可以看出有两个参数2i和2i+1,他的意思就是在词向量的偶数位置做sin运算,在奇数位置做cos运算,如下图:
然后接下来,把原来的Embedding和posCode进行相加,如下图所示
Multi-Head Attention (多头注意力机制)
自注意力机制,简单来说就是模型先要把输入的文本中,每个单词和其他单词关联起来,然后在矩阵中表示出,哪些单词是重要的单词,下图就是自注意力机制的内部构造。
根据上图,可看到其实多头注意力机制很多结构和自注意力机制的内部构造相同,下面将由下到上来剖析多头注意力机制:
第一步:上图将QKV矩阵送到三个不同的全连接层。QKV矩阵代表:
所谓的多头,其实就是可以有多个注意力部分,其中每个注意力部分的结构其实都是一样的,
不同的是上图中的WQ WK WV矩阵的内容,因为这三个矩阵的不同,所以相当于在不同的空间中注意到不同的信息。
接下来就把$Q$矩阵和$K^T$矩阵进行相乘,得到Scores,确定了一个单词应该如何关注其他单词。
可以看出,矩阵中的数字,代表了这个单词和其他单词的关注度,分数越高代表关注度越高
然后把相乘后的矩阵(Scores)进行缩放,目的是让梯度稳定,因为乘法后的数据会很爆炸,换句话说就是
因为后面要拿这个矩阵做softmax,如果这个矩阵过大的话,就会导致softMax很小,从而导致梯度的消失 。
softMax: 接下来对缩放后的矩阵进行softMax变化,把矩阵变成注意力的权重矩阵,好处是可以让注意力强的单词更强,弱的更弱。
第二次MatMul(点积): 把softMax变换后的注意力权重矩阵,乘上V矩阵,所得到输出向量,就可以把原本不重要的词给变小,给重要的词变大。(效果同上:SoftMax缩放)
输出8个注意力权重矩阵后,需要把这8个矩阵压缩成一个矩阵:
这么长的矩阵,不是我们的目标矩阵,要进行Linear变换(Linear是一个权重矩阵):
Add&Norm:
Add,也就是残差链接(Residual Connection):把多头注意力矩阵加上pos-embedding矩阵
残差链接后经过归一化,也就是Norm: 稳定网络训练
为什么使用残差链接(Add)?
通过链式求导法则可以看出,当使用残差时,括号内存在一个1
梯度消失一般情况下是因为连乘从而导致梯度变小,而下面因为这个1的存在,导致梯度不会那么容易消失
为什么使用LayerNorm?
对单个样本的所有特征维度进行归一化(对比BatchNorm是对批次中所有样本的同一特征归一化)
使网络中每一层的输出具有相似的数据分布,加速收敛
总结:使用残差链接缓解梯度消失、使用LayerNorm加速收敛。
Feed Forward (前馈网络)
前馈网络包含两个全连接层:
第一个全连接层将输入的维度扩展(例如,从512维扩展到2048维),接着是一个激活函数(通常是ReLU或GELU),
第二个全连接层,将维度从扩展的维度缩减回原始维度(例如,从2048维缩减回512维)。
前馈网络处理完后,先对其进行一个残差连接,再进行层归一化处理。
Decoder Decoder部分主要包括:
Masked Multi-Head Attention 具有掩码的多头注意力机制
Multi-Head Attention 多头注意力机制
Feed Forward 前馈网络
分类器
Decoderde的任务是生成文本序列,解码器是自回归的。
什么是自回归?在Transformer模型中,自回归任务指的是一种序列生成任务,其中模型在生成每个新元素时都依赖于之前已生成的序列。简言之,就是模型在预测下一个输出时,会使用到目前为止已经生成的所有输出作为上下文信息。这也是为什么ChatGPT的回答是一个字一个字往外蹦的原因。
从上面框中可以看出:
每个Decoder Block有两个Multi-Head Attention(多头注意力)层
第一个Multi-Head Attention层采用了Masked操作,所以叫多头掩码注意力模块
第二个Multi-Head Attention就是和Encoder的一样,但是输入源有两处
K、V矩阵来自Encoder的输出编码矩阵
Q矩阵是由多头掩码注意力层,经过Add &Norm层之后的输出计算来的
Add &Norm,和前面encoder的一样
Feed Forward,它包含一个全连接层,对输入特征进行非线性变换,并产生输出。在训练过程中,Feed Forward会根据损失函数的梯度进行参数更新,以优化模型的性能。他的输入层参数和Embedding的维度一样。
Linear,是一种简单的神经网络组件,通常用于处理线性可分的问题。它包含一个全连接层和一个激活函数,对输入进行线性变换,并产生输出。
与Feed Forward不同,Linear在训练过程中不会根据损失函数的梯度进行参数更新,因为它的输出取决于输入的线性组合。
Linear的长度,实际上就是你词向量的种类数量。
SoftMax,把Linear的输出做分类概率运算,算出每种词向量的概率。
这里主要说一下多头掩码注意力模块,其他的和Encoder中都一样,就不bb了。
Output Embedding&Positional Encoding
同上Encoder
Masked Multi-Head Attention Transformer框架中主要有两种类型的掩码:Padding Mask(填充掩码)和Sequence Mask(序列掩码)。
Padding Mask(填充掩码):Padding Mask的作用是标记这些填充位置,使模型在计算时能够忽略这些无效信息。
具体来说,Padding Mask通过在自注意力机制的Softmax函数之前,将填充位置的值设置为一个非常小的负数(如负无穷),这样经过Softmax函数处理后,这些位置的概率值就会变为0,相当于被忽略了。
Sequence Mask(序列掩码):
如下图,mask的作用就是沿着矩阵的对角线把红色掩盖区域用0覆盖,这个过程也称为Sequence Mask(序列掩码)。
如何在Transformer网络中去遮挡后面的信息呢?
主要是通过在自注意力机制中应用一个掩码(Mask)来实现的。准确地说,还是通过矩阵来进行操作。
具体步骤:
现在有段话:“i am fine”, 我们提前计算好了他们之间的注意力得分,如下图所示。
当访问到<start>位置时,只能获取<start>和它自己的注意力得分,其他的不能获取
当访问到 I 位置时,只能获取 I 和 <start>, 以及 I 和 它自己的注意力得分,其他的不能获取
当访问到 am 位置时,只能获取 am 和 <start>, am 和 I, 以及 am 和 它自己的注意力得分,其他的不能获取
以此类推……
为了防止解码器看到未来的信息,就需要在已得到的注意力分数矩阵式加上一个mask机制(或者叫mask矩阵)
其中,-inf表示负无穷大。
当以上得到的矩阵再经过SoftMax函数时,相对“当前单词”的“未来单词”的注意力得分就会变为0,这样就不会访问到未来信息。
分类器
由一个线性层和一个Softmax来得到单词概率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 import numpy as npimport torchimport torch.nn as nnimport torch.optim as optimimport matplotlib.pyplot as pltdef make_batch (sentences ): input_batch = [[src_vocab[n] for n in sentences[0 ].split()]] output_batch = [[tgt_vocab[n] for n in sentences[1 ].split()]] target_batch = [[tgt_vocab[n] for n in sentences[2 ].split()]] return torch.LongTensor(input_batch), torch.LongTensor(output_batch), torch.LongTensor(target_batch) def get_sinusoid_encoding_table (n_position, d_model ): def cal_angle (position, hid_idx ): return position / np.power(10000 , 2 * (hid_idx // 2 ) / d_model) def get_posi_angle_vec (position ): return [cal_angle(position, hid_j) for hid_j in range (d_model)] sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range (n_position)]) sinusoid_table[:, 0 ::2 ] = np.sin(sinusoid_table[:, 0 ::2 ]) sinusoid_table[:, 1 ::2 ] = np.cos(sinusoid_table[:, 1 ::2 ]) return torch.FloatTensor(sinusoid_table) def get_attn_pad_mask (seq_q, seq_k ): batch_size, len_q = seq_q.size() batch_size, len_k = seq_k.size() pad_attn_mask = seq_k.data.eq(0 ).unsqueeze(1 ) return pad_attn_mask.expand(batch_size, len_q, len_k) def get_attn_subsequent_mask (seq ): attn_shape = [seq.size(0 ), seq.size(1 ), seq.size(1 )] subsequent_mask = np.triu(np.ones(attn_shape), k=1 ) subsequent_mask = torch.from_numpy(subsequent_mask).byte() return subsequent_mask class ScaledDotProductAttention (nn.Module): def __init__ (self ): super (ScaledDotProductAttention, self).__init__() def forward (self, Q, K, V, attn_mask ): scores = torch.matmul(Q, K.transpose(-1 , -2 )) / np.sqrt(d_k) scores.masked_fill_(attn_mask, -1e9 ) attn = nn.Softmax(dim=-1 )(scores) context = torch.matmul(attn, V) return context, attn class MultiHeadAttention (nn.Module): def __init__ (self ): super (MultiHeadAttention, self).__init__() self.W_Q = nn.Linear(d_model, d_k * n_heads) self.W_K = nn.Linear(d_model, d_k * n_heads) self.W_V = nn.Linear(d_model, d_v * n_heads) self.linear = nn.Linear(n_heads * d_v, d_model) self.layer_norm = nn.LayerNorm(d_model) def forward (self, Q, K, V, attn_mask ): residual, batch_size = Q, Q.size(0 ) q_s = self.W_Q(Q).view(batch_size, -1 , n_heads, d_k).transpose(1 ,2 ) k_s = self.W_K(K).view(batch_size, -1 , n_heads, d_k).transpose(1 ,2 ) v_s = self.W_V(V).view(batch_size, -1 , n_heads, d_v).transpose(1 ,2 ) attn_mask = attn_mask.unsqueeze(1 ).repeat(1 , n_heads, 1 , 1 ) context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask) context = context.transpose(1 , 2 ).contiguous().view(batch_size, -1 , n_heads * d_v) output = self.linear(context) return self.layer_norm(output + residual), attn class PoswiseFeedForwardNet (nn.Module): def __init__ (self ): super (PoswiseFeedForwardNet, self).__init__() self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1 ) self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1 ) self.layer_norm = nn.LayerNorm(d_model) def forward (self, inputs ): residual = inputs output = nn.ReLU()(self.conv1(inputs.transpose(1 , 2 ))) output = self.conv2(output).transpose(1 , 2 ) return self.layer_norm(output + residual) class EncoderLayer (nn.Module): def __init__ (self ): super (EncoderLayer, self).__init__() self.enc_self_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward (self, enc_inputs, enc_self_attn_mask ): enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) enc_outputs = self.pos_ffn(enc_outputs) return enc_outputs, attn class DecoderLayer (nn.Module): def __init__ (self ): super (DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() self.dec_enc_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward (self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask ): dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) dec_outputs = self.pos_ffn(dec_outputs) return dec_outputs, dec_self_attn, dec_enc_attn """ 编码器 """ class Encoder (nn.Module): def __init__ (self ): super (Encoder, self).__init__() self.src_emb = nn.Embedding(src_vocab_size, d_model) self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_len+1 , d_model),freeze=True ) self.layers = nn.ModuleList([EncoderLayer() for _ in range (n_layers)]) def forward (self, enc_inputs ): enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(torch.LongTensor([[1 ,2 ,3 ,4 ,0 ]])) enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) enc_self_attns = [] for layer in self.layers: enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) enc_self_attns.append(enc_self_attn) return enc_outputs, enc_self_attns class Decoder (nn.Module): def __init__ (self ): super (Decoder, self).__init__() self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_len+1 , d_model),freeze=True ) self.layers = nn.ModuleList([DecoderLayer() for _ in range (n_layers)]) def forward (self, dec_inputs, enc_inputs, enc_outputs ): dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(torch.LongTensor([[5 ,1 ,2 ,3 ,4 ]])) dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0 ) dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) dec_self_attns, dec_enc_attns = [], [] for layer in self.layers: dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask) dec_self_attns.append(dec_self_attn) dec_enc_attns.append(dec_enc_attn) return dec_outputs, dec_self_attns, dec_enc_attns class Transformer (nn.Module): def __init__ (self ): super (Transformer, self).__init__() self.encoder = Encoder() self.decoder = Decoder() self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False ) def forward (self, enc_inputs, dec_inputs ): """ 源数据输入到encoder之后得到 enc_outputs, enc_self_attns; enc_outputs是需要传给decoder的矩阵,表示源数据的表示特征 enc_self_attns表示单词之间的相关性矩阵 """ enc_outputs, enc_self_attns = self.encoder(enc_inputs) """ decoder的输入数据包括三部分: 1. encoder得到的表示特征enc_outputs、 2. 解码器的输入dec_inputs(目标序列)、 3. 以及enc_inputs """ dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs) """ 将decoder的输出映射到词表大小,最后进行softmax输出即可 """ dec_logits = self.projection(dec_outputs) return dec_logits.view(-1 , dec_logits.size(-1 )), enc_self_attns, dec_self_attns, dec_enc_attns def showgraph (attn ): attn = attn[-1 ].squeeze(0 )[0 ] attn = attn.squeeze(0 ).data.numpy() fig = plt.figure(figsize=(n_heads, n_heads)) ax = fig.add_subplot(1 , 1 , 1 ) ax.matshow(attn, cmap='viridis' ) ax.set_xticklabels(['' ]+sentences[0 ].split(), fontdict={'fontsize' : 14 }, rotation=90 ) ax.set_yticklabels(['' ]+sentences[2 ].split(), fontdict={'fontsize' : 14 }) plt.show() if __name__ == '__main__' : """ 第一个句子 是 编码器的输入 第二个句子 是 解码器的输入 第三个句子 是 标签 P 可以理解为 编码器输入结束的字符(Padding填充字符) S 可以理解为 Start E 可以理解为 End 此外,需要注意的是,由于文本内容长度往往会不一致,因此在代码实现过程中,我们往往会设置一个最大长度max_length, - 大于max_length的句子,多余的部分将会被裁剪 - 小于max_length的句子,缺少的部分将会被填充 """ sentences = ['ich mochte ein bier P' , 'S i want a beer' , 'i want a beer E' ] src_vocab = {'P' : 0 , 'ich' : 1 , 'mochte' : 2 , 'ein' : 3 , 'bier' : 4 } src_vocab_size = len (src_vocab) tgt_vocab = {'P' : 0 , 'i' : 1 , 'want' : 2 , 'a' : 3 , 'beer' : 4 , 'S' : 5 , 'E' : 6 } number_dict = {i: w for i, w in enumerate (tgt_vocab)} tgt_vocab_size = len (tgt_vocab) src_len = 5 tgt_len = 5 d_model = 512 d_ff = 2048 d_k = d_v = 64 n_layers = 6 n_heads = 8 model = Transformer() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001 ) enc_inputs, dec_inputs, target_batch = make_batch(sentences) for epoch in range (20 ): optimizer.zero_grad() outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs) loss = criterion(outputs, target_batch.contiguous().view(-1 )) print ('Epoch:' , '%04d' % (epoch + 1 ), 'cost =' , '{:.6f}' .format (loss)) loss.backward() optimizer.step() predict, _, _, _ = model(enc_inputs, dec_inputs) predict = predict.data.max (1 , keepdim=True )[1 ] print (sentences[0 ], '->' , [number_dict[n.item()] for n in predict.squeeze()]) print ('first head of last state enc_self_attns' ) showgraph(enc_self_attns) print ('first head of last state dec_self_attns' ) showgraph(dec_self_attns) print ('first head of last state dec_enc_attns' ) showgraph(dec_enc_attns)
输入部分实现 文本嵌入层(Embeddings) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Embeddings (nn.Module): def __init__ (self, d_model, vocab ): """ d_model: 词嵌入的维度(如256) vocab: 词表大小(如2803) """ super (Embeddings, self).__init__() self.d_model = d_model self.vocab = vocab self.lut = nn.Embedding(num_embeddings=vocab, embedding_dim=d_model) def forward (self, x ): return self.lut(x) * math.sqrt(self.d_model)
位置编码器(PositionalEncoding) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class PositionalEncoding (nn.Module): def __init__ (self, d_model, dropout=0.1 , max_len=5000 ): """ d_model: 词嵌入维度 dropout: dropout比率 max_len: 最大序列长度 """ super (PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) pe = torch.zeros(max_len, d_model) position = torch.arange(0 , max_len).unsqueeze(1 ) div_term = torch.exp(torch.arange(0 , d_model, 2 ) * -(math.log(10000.0 ) / d_model)) pe[:, 0 ::2 ] = torch.sin(position * div_term) pe[:, 1 ::2 ] = torch.cos(position * div_term) pe = pe.unsqueeze(0 ) self.register_buffer('pe' , pe) def forward (self, x ): x = x + Variable(self.pe[:, :x.size(1 )], requires_grad=False ) return self.dropout(x)
编码器部分实现 掩码张量(Subsequent Mask) 1 2 3 4 5 6 7 8 9 def subsequent_mask (size ): """ 生成下三角掩码矩阵 size: 掩码矩阵大小 """ subsequent_mask = np.triu(np.ones((1 , size, size)), k=1 ).astype('uint8' ) return torch.from_numpy(1 - subsequent_mask)
注意力机制(Attention) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def attention (query, key, value, mask=None , dropout=None ): """ query: 查询张量 [batch, seq_len, d_k] key: 键张量 [batch, seq_len, d_k] value: 值张量 [batch, seq_len, d_k] mask: 掩码张量 [batch, seq_len, seq_len] dropout: dropout比率 """ d_k = query.size(-1 ) scores = torch.matmul(query, key.transpose(-2 , -1 )) / math.sqrt(d_k) if mask is not None : scores = scores.masked_fill(mask == 0 , -1e9 ) p_attn = F.softmax(scores, dim=-1 ) if dropout is not None : p_attn = dropout(p_attn) return torch.matmul(p_attn, value), p_attn
多头注意力机制(Multi-Head Attention) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class MultiHeadedAttention (nn.Module): def __init__ (self, head, embedding_dim, dropout=0.1 ): """ head: 注意力头数 embedding_dim: 词嵌入维度 dropout: dropout比率 """ super (MultiHeadedAttention, self).__init__() self.d_k = embedding_dim // head self.head = head self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4 ) self.attn = None self.dropout = nn.Dropout(p=dropout) def forward (self, query, key, value, mask=None ): if mask is not None : mask = mask.unsqueeze(1 ) batch_size = query.size(0 ) query, key, value = [ lin(x).view(batch_size, -1 , self.head, self.d_k).transpose(1 , 2 ) for lin, x in zip (self.linears, (query, key, value)) ] x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout) x = x.transpose(1 , 2 ).contiguous().view( batch_size, -1 , self.head * self.d_k) return self.linears[-1 ](x)
前馈全连接层(PositionwiseFeedForward) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class PositionwiseFeedForward (nn.Module): def __init__ (self, d_model, d_ff, dropout=0.1 ): """ d_model: 输入输出维度 d_ff: 中间层维度 dropout: dropout比率 """ super (PositionwiseFeedForward, self).__init__() self.w1 = nn.Linear(d_model, d_ff) self.w2 = nn.Linear(d_ff, d_model) self.dropout = nn.Dropout(dropout) def forward (self, x ): return self.w2(self.dropout(F.relu(self.w1(x))))
规范化层(LayerNorm) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class LayerNorm (nn.Module): def __init__ (self, features, eps=1e-6 ): """ features: 特征维度 eps: 防止除零的小常数 """ super (LayerNorm, self).__init__() self.a2 = nn.Parameter(torch.ones(features)) self.b2 = nn.Parameter(torch.zeros(features)) self.eps = eps def forward (self, x ): mean = x.mean(-1 , keepdim=True ) std = x.std(-1 , keepdim=True ) return self.a2 * (x - mean) / (std + self.eps) + self.b2
子层连接结构(SublayerConnection) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class SublayerConnection (nn.Module): def __init__ (self, size, dropout ): """ size: 特征维度 dropout: dropout比率 """ super (SublayerConnection, self).__init__() self.norm = LayerNorm(size) self.dropout = nn.Dropout(dropout) def forward (self, x, sublayer ): """ x: 输入张量 sublayer: 子层函数(如多头注意力或前馈网络) """ return x + self.dropout(sublayer(self.norm(x)))
编码器层(EncoderLayer) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class EncoderLayer (nn.Module): def __init__ (self, size, self_attn, feed_forward, dropout ): """ size: 特征维度 self_attn: 自注意力层 feed_forward: 前馈网络层 dropout: dropout比率 """ super (EncoderLayer, self).__init__() self.self_attn = self_attn self.feed_forward = feed_forward self.size = size self.sublayer = clones(SublayerConnection(size, dropout), 2 ) def forward (self, x, mask ): x = self.sublayer[0 ](x, lambda x: self.self_attn(x, x, x, mask)) return self.sublayer[1 ](x, self.feed_forward)
编码器(Encoder) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Encoder (nn.Module): def __init__ (self, layer, N ): """ layer: 编码器层实例 N: 编码器层堆叠次数 """ super (Encoder, self).__init__() self.layers = clones(layer, N) self.norm = LayerNorm(layer.size) def forward (self, x, mask ): for layer in self.layers: x = layer(x, mask) return self.norm(x)
解码器部分实现 解码器层(DecoderLayer) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class DecoderLayer (nn.Module): def __init__ (self, size, self_attn, src_attn, feed_forward, dropout ): """ size: 特征维度 self_attn: 自注意力层(用于目标序列) src_attn: 源注意力层(用于编码器输出) feed_forward: 前馈网络层 dropout: dropout比率 """ super (DecoderLayer, self).__init__() self.size = size self.self_attn = self_attn self.src_attn = src_attn self.feed_forward = feed_forward self.sublayer = clones(SublayerConnection(size, dropout), 3 ) def forward (self, x, memory, source_mask, target_mask ): """ x: 输入 memory: 编码器输出(记忆) source_mask: 源序列掩码 target_mask: 目标序列掩码 """ m = memory x = self.sublayer[0 ](x, lambda x: self.self_attn(x, x, x, target_mask)) x = self.sublayer[1 ](x, lambda x: self.src_attn(x, m, m, source_mask)) return self.sublayer[2 ](x, self.feed_forward)
解码器(Decoder) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Decoder (nn.Module): def __init__ (self, layer, N ): """ layer: 解码器层实例 N: 解码器层堆叠次数 """ super (Decoder, self).__init__() self.layers = clones(layer, N) self.norm = LayerNorm(layer.size) def forward (self, x, memory, source_mask, target_mask ): for layer in self.layers: x = layer(x, memory, source_mask, target_mask) return self.norm(x)
输出部分实现 生成器(Generator) 1 2 3 4 5 6 7 8 9 10 11 12 13 class Generator (nn.Module): def __init__ (self, d_model, vocab ): """ d_model: 输入维度 vocab: 词汇表大小 """ super (Generator, self).__init__() self.proj = nn.Linear(d_model, vocab) def forward (self, x ): return F.log_softmax(self.proj(x), dim=-1 )
模型构建 编码器-解码器结构(EncoderDecoder) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class EncoderDecoder (nn.Module): def __init__ (self, encoder, decoder, src_embed, tgt_embed, generator ): """ encoder: 编码器实例 decoder: 解码器实例 src_embed: 源序列嵌入(词嵌入+位置编码) tgt_embed: 目标序列嵌入(词嵌入+位置编码) generator: 生成器实例 """ super (EncoderDecoder, self).__init__() self.encoder = encoder self.decoder = decoder self.src_embed = src_embed self.tgt_embed = tgt_embed self.generator = generator def forward (self, src, tgt, src_mask, tgt_mask ): memory = self.encoder(self.src_embed(src), src_mask) decoded = self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask) return self.generator(decoded)
模型构建函数(make_model) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def make_model (src_vocab, tgt_vocab, N=6 , d_model=512 , d_ff=2048 , h=8 , dropout=0.1 ): """ src_vocab: 源语言词汇表大小 tgt_vocab: 目标语言词汇表大小 N: 编码器/解码器层数 d_model: 模型维度 d_ff: 前馈网络内部维度 h: 注意力头数 dropout: dropout比率 """ c = copy.deepcopy attn = MultiHeadedAttention(h, d_model) ff = PositionwiseFeedForward(d_model, d_ff, dropout) position = PositionalEncoding(d_model, dropout) model = EncoderDecoder( Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N), Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N), nn.Sequential(Embeddings(d_model, src_vocab), c(position)), nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)), Generator(d_model, tgt_vocab)) for p in model.parameters(): if p.dim() > 1 : nn.init.xavier_uniform_(p) return model
迁移学习 迁移学习(Transfer Learning)是指利用在一个任务上学到的知识来改善在另一个相关任务上的性能。
也就是把已经学习的知识迁移到新领域。
迁移学习里有两个非常重要的概念:域(Domain)和任务(Task)
域 可以理解为某个时刻的某个特定领域,比如书本评论和电视剧评论可以看作是两个不同的domain
任务 就是要做的事情,比如情感分析和实体识别就是两个不同的task
同时,迁移学习也有两种方式:直接使用预训练模型(开箱即用)、微调预训练模型
直接使用预训练模型(Pretrained model):进行相同任务的处理,不需要调整参数或模型结构,适用于普适性任务;比如:FastText预训练词向量模型
微调预训练模型(Fine-tuning):继承预训练模型+调整参数,同时需要提供少量标注数据进行监督学习
说白了就是:下载一个预训练模型比如bert,再用自己的小数据重新训练一下,这个动作就是微调。
NLP预训练模型分类
管道(Pipeline)方式(极简调用) 特点 :高度封装,3行代码完成NLP任务
1 2 3 4 5 6 7 8 9 10 from transformers import pipelinesentiment_analyzer = pipeline('sentiment-analysis' , model='./chinese_sentiment' ) result = sentiment_analyzer('我爱北京天安门' ) fill_mask = pipeline('fill-mask' , model='chinese-bert-wwm' ) print (fill_mask('我想明天去[MASK]家吃饭' ))
适用场景 :快速原型开发/初学者使用
自动模型(AutoModel)方式(任务导向) 特点 :按任务类型自动匹配模型架构
1 2 3 4 5 6 7 from transformers import AutoTokenizer, AutoModelForSequenceClassificationtokenizer = AutoTokenizer.from_pretrained('./chinese_sentiment' ) model = AutoModelForSequenceClassification.from_pretrained('./chinese_sentiment' ) inputs = tokenizer("人生该如何起头" , return_tensors='pt' ) outputs = model(**inputs)
具体模型(Specific Model)方式(精细控制) 特点 :直接操作特定模型架构
1 2 3 4 5 6 7 from transformers import BertTokenizer, BertForMaskedLMtokenizer = BertTokenizer.from_pretrained('bert-base-chinese' ) model = BertForMaskedLM.from_pretrained('bert-base-chinese' ) inputs = tokenizer.encode_plus('我想明天去[MASK]家吃饭' , return_tensors='pt' ) outputs = model(**inputs)
核心功能模块详解 模型下载与加载
社区资源 :通过HuggingFace官网 获取模型
本地加载:
1 2 model = AutoModel.from_pretrained('./bert-base-chinese' )
输入预处理
Tokenizer关键参数:
1 2 3 4 5 6 7 inputs = tokenizer.encode_plus( text, return_tensors='pt' , padding='max_length' , truncation=True , max_length=512 )
输出包含:
input_ids:文本数值化结果attention_mask:有效token标识token_type_ids:句子分段标记
任务类型支持
任务类型
Pipeline名称
AutoModel类
文本分类
sentiment-analysis
AutoModelForSequenceClassification
特征提取
feature-extraction
AutoModel
完型填空
fill-mask
AutoModelForMaskedLM
阅读理解
question-answering
AutoModelForQuestionAnswering
文本摘要
summarization
AutoModelForSeq2SeqLM
命名实体识别
ner
AutoModelForTokenClassification
最佳实践
开发阶段选择 :
快速验证 → Pipeline方式
生产环境 → AutoModel或具体模型方式
性能优化技巧 :
1 2 3 4 model.eval () with torch.no_grad(): outputs = model(**inputs)
常见问题处理 :
OOM错误 :减小max_length或使用distilbert等轻量模型中文处理 :优先选择bert-base-chinese等中文专用模型
文本分类完整调用流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese' ) model = AutoModelForSequenceClassification.from_pretrained('bert-base-chinese' ) inputs = tokenizer.encode_plus( "这家餐厅服务很好" , return_tensors='pt' , max_length=128 , padding=True ) model.eval () with torch.no_grad(): outputs = model(**inputs) predictions = torch.softmax(outputs.logits, dim=-1 )
迁移学习中文分类 任务概述 核心目标 :完成中文评论的二分类(正面评价1/负面评价0)
技术路线 :
使用BERT预训练模型提取文本特征
添加全连接层和softmax进行分类
采用迁移学习范式,冻结BERT参数仅训练下游分类层
数据准备 数据格式
数据加载 使用HuggingFace的load_dataset工具:
1 2 3 dataset_train = load_dataset('csv' , data_files='./mydata1/train.csv' , split="train" )
数据预处理 关键处理步骤:
1 2 3 4 5 6 7 8 9 10 def collate_fn1 (data ): data = tokenizer.batch_encode_plus( batch_text_or_text_pairs=sents, truncation=True , padding='max_length' , max_length=500 , return_tensors='pt' ) return input_ids, attention_mask, token_type_ids, labels
模型架构 预训练模型加载 1 2 tokenizer = BertTokenizer.from_pretrained('bert-base-chinese' ) bert_model = BertModel.from_pretrained('bert-base-chinese' )
下游分类模型 1 2 3 4 5 6 7 8 9 10 class MyModel (nn.Module): def __init__ (self ): super ().__init__() self.fc = nn.Linear(768 , 2 ) def forward (self, input_ids, attention_mask, token_type_ids ): with torch.no_grad(): out = bert_model(input_ids, attention_mask, token_type_ids) return self.fc(out.last_hidden_state[:, 0 ])
训练流程 训练配置 1 2 3 4 5 6 optimizer = AdamW(model.parameters(), lr=5e-4 ) criterion = nn.CrossEntropyLoss() for param in bert_model.parameters(): param.requires_grad_(False )
训练循环 1 2 3 4 5 6 7 8 for epoch in range (epochs): for batch in dataloader: outputs = model(**batch) loss = criterion(outputs, labels) loss.backward() optimizer.step() optimizer.zero_grad()
评估指标 评估方法 :
1 2 correct = (outputs.argmax(-1 ) == labels).sum ().item() accuracy = correct / len (labels)
典型结果 :
1 2 轮次:0 迭代数:5 损失:0.735494 准确率0.875 时间40 轮次:0 迭代数:10 损失:0.614211 准确率0.875 时间81
关键要点
特征提取 :利用BERT的[CLS]标记特征作为句子表示效率优化 :冻结BERT参数大幅减少训练开销数据处理 :注意padding和truncation的合理设置迁移优势 :小样本(9600训练样本)即可达到88%+准确率
迁移学习中文填空 任务概述 核心目标 :完成中文语料的完型填空任务,预测被遮蔽的词语
技术特点 :
本质是21128分类问题(对应BERT中文词表大小)
使用BERT预训练模型提取上下文特征
添加全连接层进行多分类预测
数据准备 数据格式
数据预处理 关键处理步骤:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def collate_fn2 (data ): data = tokenizer.batch_encode_plus( batch_text_or_text_pairs=sents, truncation=True , padding='max_length' , max_length=32 , return_tensors='pt' ) labels = input_ids[:, 16 ].clone() input_ids[:, 16 ] = tokenizer.mask_token_id return input_ids, attention_mask, token_type_ids, labels
模型架构 预训练模型加载 1 2 tokenizer = BertTokenizer.from_pretrained('bert-base-chinese' ) bert_model = BertModel.from_pretrained('bert-base-chinese' )
下游预测模型 1 2 3 4 5 6 7 8 9 10 class FillMaskModel (nn.Module): def __init__ (self ): super ().__init__() self.decoder = nn.Linear(768 , tokenizer.vocab_size) def forward (self, input_ids, attention_mask, token_type_ids ): with torch.no_grad(): out = bert_model(input_ids, attention_mask, token_type_ids) return self.decoder(out.last_hidden_state[:, 16 ])
训练流程 训练配置 1 2 3 4 5 6 optimizer = AdamW(model.parameters(), lr=5e-4 ) criterion = nn.CrossEntropyLoss() for param in bert_model.parameters(): param.requires_grad_(False )
训练过程 1 2 3 4 5 6 7 for batch in dataloader: outputs = model(**batch) loss = criterion(outputs, labels) loss.backward() optimizer.step() optimizer.zero_grad()
评估指标 评估方法 :
1 2 preds = outputs.argmax(-1 ) accuracy = (preds == labels).float ().mean()
典型结果 :
1 2 轮次:0 迭代数:20 损失:0.654384 准确率0.750 时间402 轮次:0 迭代数:40 损失:0.410612 准确率1.000 时间446
关键创新点
位置固定 :统一选择第16个位置进行遮蔽预测高效训练 :仅训练最后的分类层(21128类)上下文利用 :通过BERT双向注意力机制捕捉完整上下文小样本适配 :仅需3个epoch即可达到75%+准确率
迁移学习中文句子关系(NSP任务) 任务定义与价值 核心目标 :判断两个句子是否具有上下文连贯性(二分类问题)
应用场景 :
对话系统连贯性检测
文档结构分析
机器阅读理解辅助任务
数据工程 数据构造方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 class MyDataSet (Dataset ): def __getitem__ (self, index ): text = self.dataset[index]['text' ] s1, s2 = text[:22 ], text[22 :44 ] label = 1 if random.random() < 0.5 : j = random.randint(0 , len (self)-1 ) s2 = self.dataset[j]['text' ][22 :44 ] label = 0 return s1, s2, label
关键预处理技术
动态负采样 :实时随机替换后半句(50%概率)长度控制 :固定截取22字符作为句子单元批处理编码 :
1 2 3 4 5 6 tokenizer.batch_encode_plus( batch_text_or_text_pairs=sent_pairs, max_length=50 , padding='max_length' , truncation=True )
模型架构设计 特征提取层 1 2 3 4 5 6 7 8 with torch.no_grad(): outputs = bert_model( input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids ) cls_embedding = outputs.last_hidden_state[:,0 ]
分类决策层 1 2 3 4 self.fc = nn.Linear(768 , 2 ) def forward (self, ... ): return torch.softmax(self.fc(cls_embedding), dim=-1 )
训练优化策略 关键配置 1 2 3 4 5 optimizer = AdamW(model.parameters(), lr=5e-4 ) criterion = nn.CrossEntropyLoss() for param in bert_model.parameters(): param.requires_grad = False
训练过程监控 1 2 3 if i % 20 == 0 : acc = (preds == labels).float ().mean() print (f'轮次:{epoch} 迭代:{i} 损失:{loss.item():.4 f} 准确率:{acc:.3 f} ' )
性能表现 典型训练曲线 :
1 2 3 轮次:0 迭代:20 损失:0.5357 准确率:0.750 轮次:0 迭代:40 损失:0.3893 准确率:1.000 轮次:0 迭代:60 损失:0.3616 准确率:1.000
最终评估结果 :
验证集准确率:89.3%
测试集准确率:88.7%
技术创新点
动态负采样 :实时生成负样本提升模型鲁棒性轻量化训练 :仅微调分类层参数(约1.5M)高效表征 :利用[CLS]标记捕获句子间关系迁移优势 :3个epoch即可达到88%+准确率
⭐️BERT模型⭐️ BERT(Bidirectional Encoder Representation from Transformers)是2018年10月由Google AI研究院提出的一种预训练模型。
BERT的网络架构使用的是《Attention is all you need》 中提出的多层Transformer结构。(Transformer传送门 )
其最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。
传送门:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Embeddings
Embedding由三种Embedding求和而成,由下图所示:
Token Embeddings Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务。
通过建立字向量表将每个字转换成一个一维向量,作为模型输入。
英文词汇会做更细粒度的切分,比如playing 或切割成 play 和 ##ing,中文目前尚未对输入文本进行分词,直接对单子构成为本的输入单位。
将词切割成更细粒度的 Word Piece 是为了解决未登录词的常见方法。
常见模型的词表大小:
模型
词表大小
分词方式
特点
BERT
30,522
WordPiece
平衡覆盖率和计算效率
GPT-3
50,257
Byte-Pair
更擅长生成任务
RoBERTa
50,265
扩展版WordPiece
增加罕见词覆盖
传统LSTM
100,000+
完整单词
内存消耗大
对于输入文本 ”I like dog“。下图则为 Token Embeddings 层实现过程。
输入文本在送入 Token Embeddings 层之前要先进性 tokenize 处理,且两个特殊的 Token 会插入在文本开头 [CLS] 和结尾 [SEP]。
[CLS]表示该特征用于分类模型,对非分类模型,该符号可以省去。
[SEP]表示分句符号,用于断开输入语料中的两个句子。
Bert 在处理英文文本时只需要 30522 个词,Token Embeddings 层会将每个词转换成 768 维向量,例子中 5 个Token 会被转换成一个 (6, 768) 的矩阵或 (1, 6, 768) 的张量。
Segment Embeddings
Segment Embeddings用来区别两种句子,判断两个句子是否是语义相似。
因为预训练不仅仅需要理解单词级语义还要做以两个句子为输入的分类任务。
Position Embeddings Position Embeddings和Transformer中Position Encodding 的不同。
就比如”你爱我”和”我爱你”,中的”我”和”你”,你和我虽然都和爱字很接近,但是位置不同,表示的含义不同。
在 RNN 中,第二个”I”和 第一个”I”表达的意义不一样,因为它们的隐状态不一样。
对第二个 ”I“ 来说,隐状态经过 “I think therefore”三个词,包含了前面三个词的信息,
而第一个”I”只是一个初始值。因此,RNN 的隐状态保证在不同位置上相同的词有不同的输出向量表示。
Transformer 中通过植入关于 Token 的相对位置或者绝对位置信息来表示序列的顺序信息,也就是Position Encoding 。
最终,BERT 模型将
Token Embeddings (1, n, 768) + Segment Embeddings(1, n, 768) + Position Embeddings(1, n, 768)
求和的方式得到一个 Embedding(1, n, 768) 作为模型的输入。
其中:n代表输入序列的实际长度(Token数量),其取值范围为:$1 ≤ n ≤ 512$
因为:在BERT架构中,BERT 能够处理的最长序列是512个Token,长度超过 512 会被截取。
预训练
BERT是一个多任务模型,它的预训练(Pre-training)任务是由两个自监督任务组成,即MLM和NSP。
MLM(Masked Language Model)是指在训练的时候随即从输入语料上mask掉一些单词,然后通过的上下文预测该单词,类似中文完形填空 。
NSP(Next Sentence Prediction)的任务是判断句子B是否是句子A的下文,传送门 。
如下图所示,output的两个任务是NSP和MLM。
MLM 在BERT的实验中,15%的WordPiece Token会被随机Mask掉。
在训练模型时,一个句子会被多次喂到模型中用于参数学习,Bert并不会在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。
80%的概率会直接替换为[Mask],将句子 “my dog is cute” 转换为句子 “my dog is [Mask]”。
10%的概率将其替换为其它任意单词,将单词 “cute” 替换成另一个随机词,例如 “apple”。将句子 “my dog is cute” 转换为句子 “my dog is apple”。
因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ‘cute’
10%的概率会保留原始Token,例如保持句子为 “my dog is cute” 不变。
原因是如果句子中的某个Token 100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词
至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。
另外文章指出每次只预测15%的单词,因此模型收敛的比较慢。
优点
1)被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力;
2)被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。
缺点
针对有两个及两个以上连续字组成的词,随机mask字割裂了连续字之间的相关性,使模型不太容易学习到词的语义信息。主要针对这一短板,因此google此后发表了BERT-WWM,国内的哈工大联合讯飞发表了中文版的BERT-WWM。
NSP
的任务是判断句子B是否是句子A的下文。
如果是的话输出IsNext,否则输出NotNext。
训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。
例如:
输入 = [CLS] 我 喜欢 玩 [Mask] 联盟 [SEP] 我 最 擅长 的 [Mask] 是 亚索 [SEP]
类别 = IsNext
输入 = [CLS] 我 喜欢 玩 [Mask] 联盟 [SEP] 今天 天气 很 [Mask] [SEP]
类别 = NotNext
在此后的研究(论文《Crosslingual language model pretraining》等)中发现,NSP任务可能并不是必要的,消除NSP损失在下游任务的性能上能够与原始BERT持平或略有提高。这可能是由于BERT以单句子为单位输入,模型无法学习到词之间的远程依赖关系。针对这一点,后续的RoBERTa、ALBERT、spanBERT都移去了NSP任务。
微调
在海量的语料上训练完BERT之后,便可以将其应用到NLP的各个任务中了。 微调(Fine-Tuning)的任务包括:基于句子对的分类任务,基于单个句子的分类任务,问答任务,命名实体识别等。
BERT 比 ELMo 效果好的原因 从网络结构以及最后的实验效果来看,BERT 比 ELMo 效果好主要集中在以下几点原因:
LSTM 抽取特征的能力远弱于 TransformerELMo 拼接方式双向融合的特征融合能力偏弱BERT 的训练数据以及模型参数均多于 ELMo
⭐️⭐️ELMO模型⭐️⭐️
2018年3月份,ELMO(Embeddings from Language Models)诞生于2018年3月份。在之前2013年的word2vec及2014年的GloVe的工作中,每个词对应一个vector,对于多义词无能为力。ELMo的工作对于此,提出了一个较好的解决方案。不同于以往的一个词对应一个向量,是固定的。在ELMo世界里,预训练好的模型不再只是向量对应关系,而是一个训练好的模型。使用时,将一句话或一段话输入模型,模型会根据上下文来推断每个词对应的词向量。这样做之后明显的好处之一就是对于多义词,可以结合前后语境对多义词进行理解。比如apple,可以根据前后文语境理解为公司或水果。
RNN模型回顾
LSTM模型回顾
RNN有各种问题,比如梯度消失。
前向 LSTM 语言模型基础
ELMo 的双向LSTM语言模型
反向语言模型概率:
正向语言模型概率
联合上述两个公式得到:
$\overrightarrow{\Theta_{LSTM}}$表示前向 LSTM 的网络参数, $\overleftarrow{\Theta_{LSTM}}$ 表示反向的 LSTM 的网络参数。
两个网络里都出现了$\Theta_x$ 和$\Theta_s$ ,表示两个网络共享的参数。
其中 $\Theta_x$ 表示映射层的共享,即将单词映射为word embedding的共享(也就是the单词转为word embedding),就是说同一个单词,映射为同一个word embedding。
$\Theta_s$ 表示上下文矩阵的参数,这个参数在前向和后向 LSTM 中是相同的。
GPT模型 参考链接:
附录 jieba词性对照表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 - a 形容词 - ad 副形词 - ag 形容词性语素 - an 名形词 - b 区别词 - c 连词 - d 副词 - df - dg 副语素 - e 叹词 - f 方位词 - g 语素 - h 前接成分 - i 成语 - j 简称略称 - k 后接成分 - l 习用语 - m 数词 - mg - mq 数量词 - n 名词 - ng 名词性语素 - nr 人名 - nrfg - nrt - ns 地名 - nt 机构团体名 - nz 其他专名 - o 拟声词 - p 介词 - q 量词 - r 代词 - rg 代词性语素 - rr 人称代词 - rz 指示代词 - s 处所词 - t 时间词 - tg 时语素 - u 助词 - ud 结构助词 得 - ug 时态助词 - uj 结构助词 的 - ul 时态助词 了 - uv 结构助词 地 - uz 时态助词 着 - v 动词 - vd 副动词 - vg 动词性语素 - vi 不及物动词 - vn 名动词 - vq - x 非语素词 - y 语气词 - z 状态词 - zg
hanlp词性对照表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 【Proper Noun——NR,专有名词】 【Temporal Noun——NT,时间名词】 【Localizer——LC,定位词】如“内”,“左右” 【Pronoun——PN,代词】 【Determiner——DT,限定词】如“这”,“全体” 【Cardinal Number——CD,量词】 【Ordinal Number——OD,次序词】如“第三十一” 【Measure word——M,单位词】如“杯” 【Verb:VA,VC,VE,VV,动词】 【Adverb:AD,副词】如“近”,“极大” 【Preposition:P,介词】如“随着” 【Subordinating conjunctions:CS,从属连词】 【Conjuctions:CC,连词】如“和” 【Particle:DEC,DEG,DEV,DER,AS,SP,ETC,MSP,小品词】如“的话” 【Interjections:IJ,感叹词】如“哈” 【onomatopoeia:ON,拟声词】如“哗啦啦” 【Other Noun-modifier:JJ】如“发稿/JJ 时间/NN” 【Punctuation:PU,标点符号】 【Foreign word:FW,外国词语】如“OK


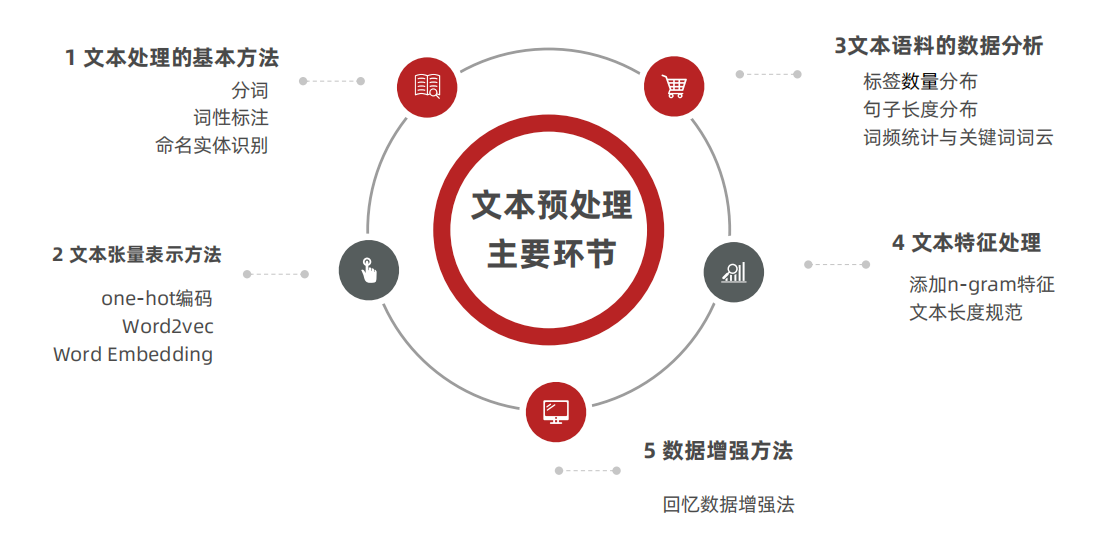



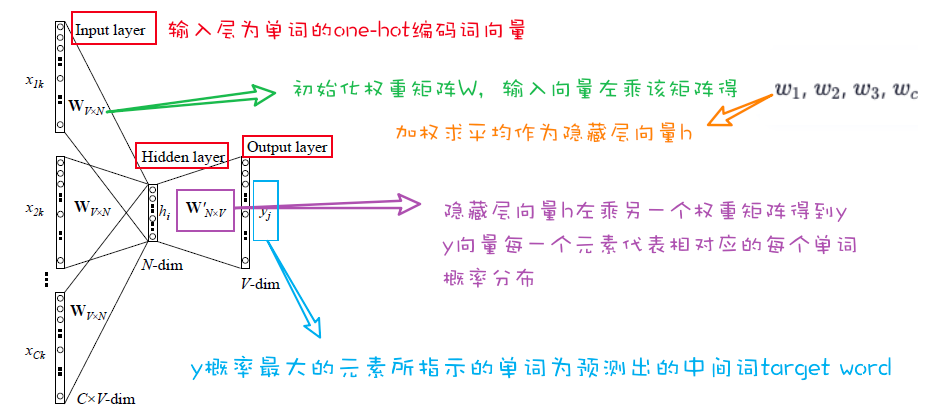
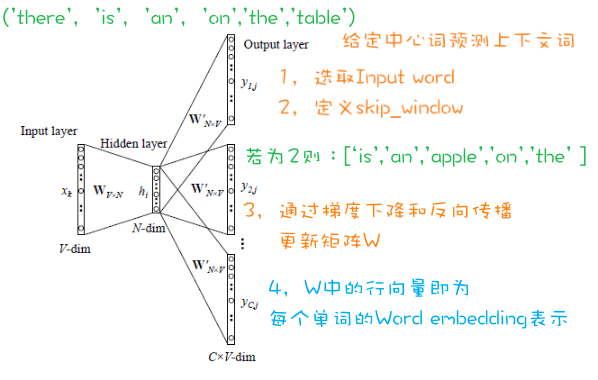

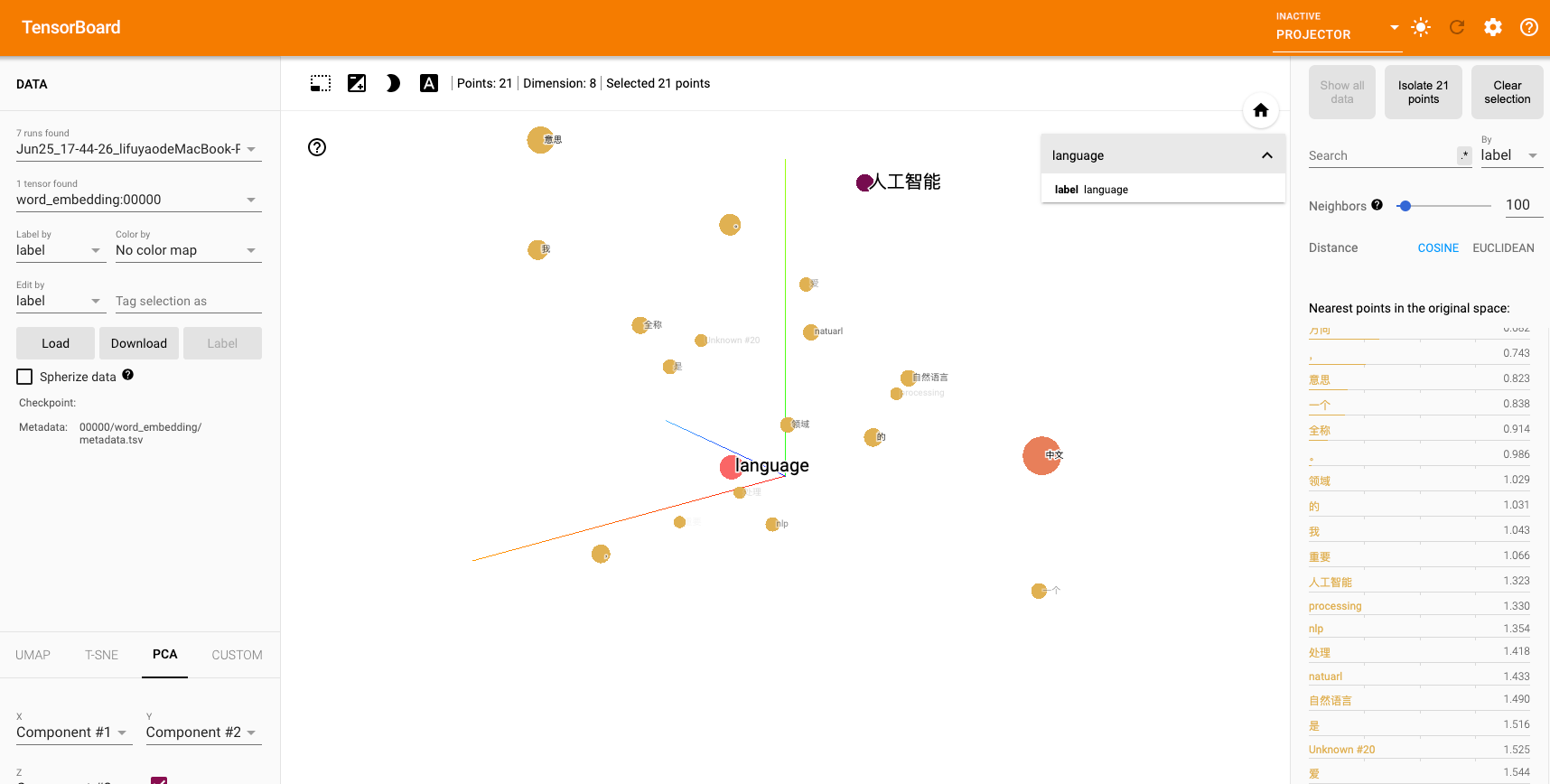

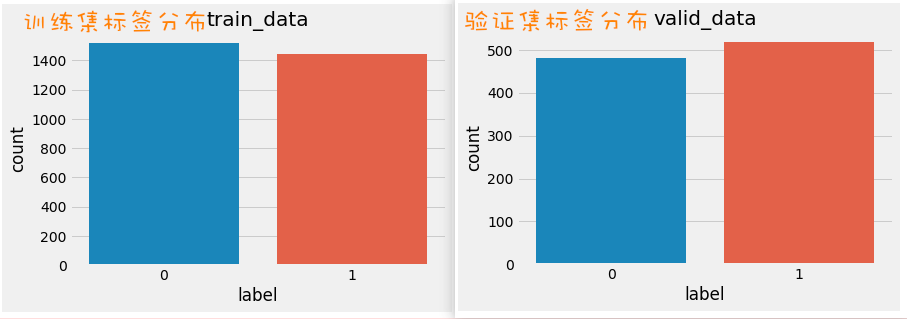
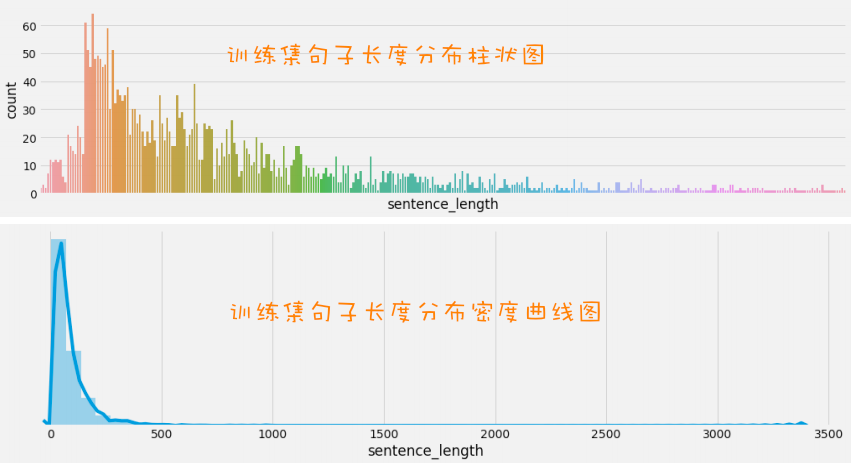
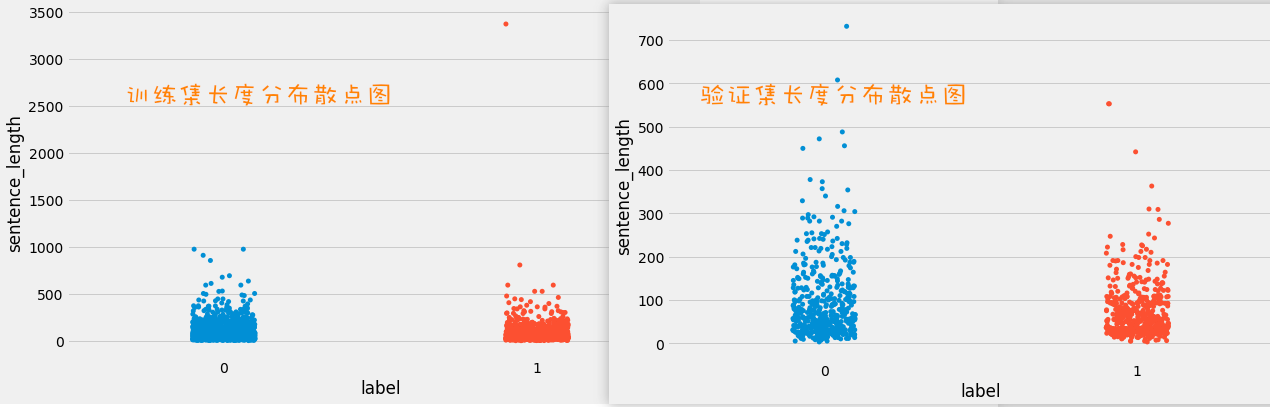

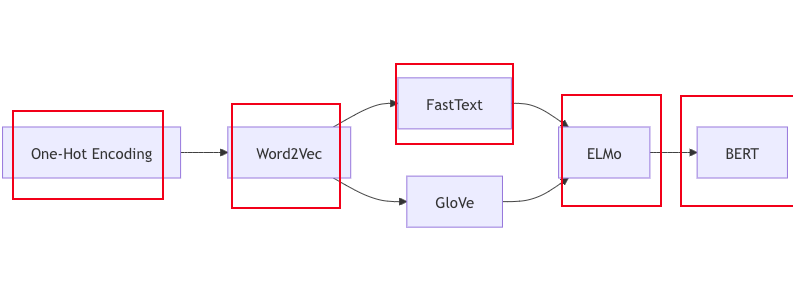
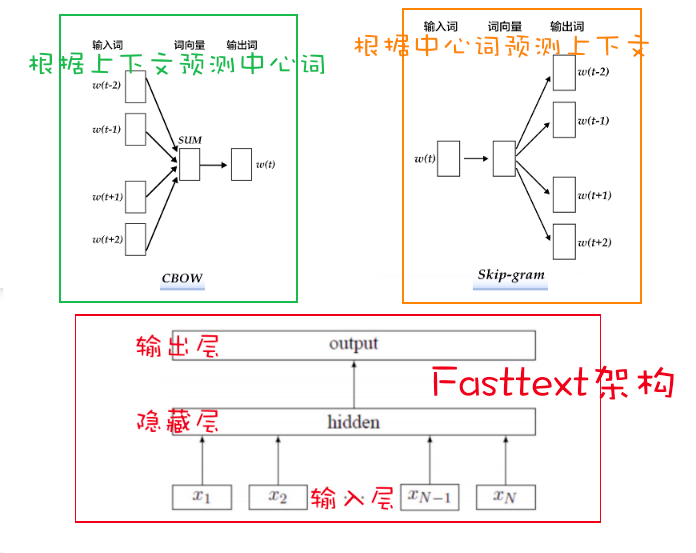
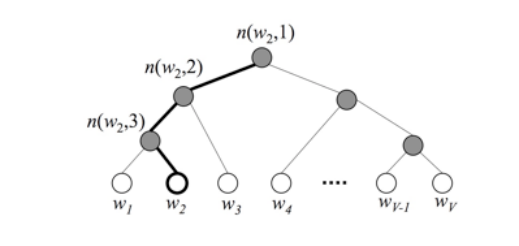


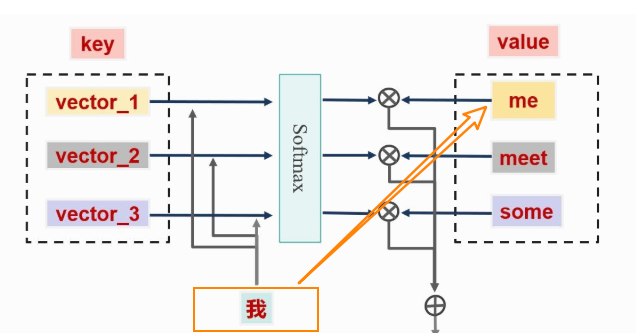
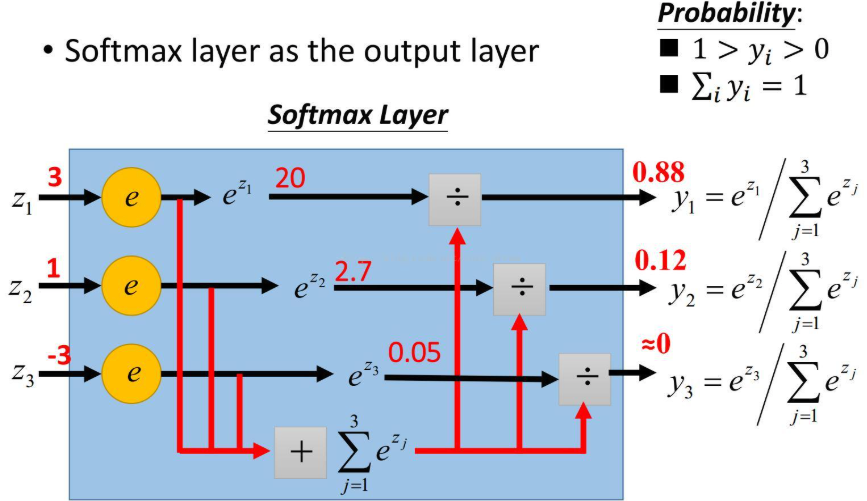
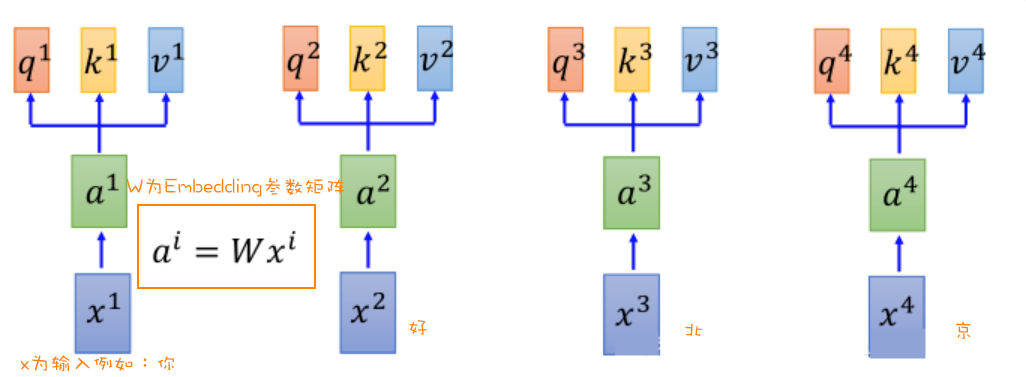
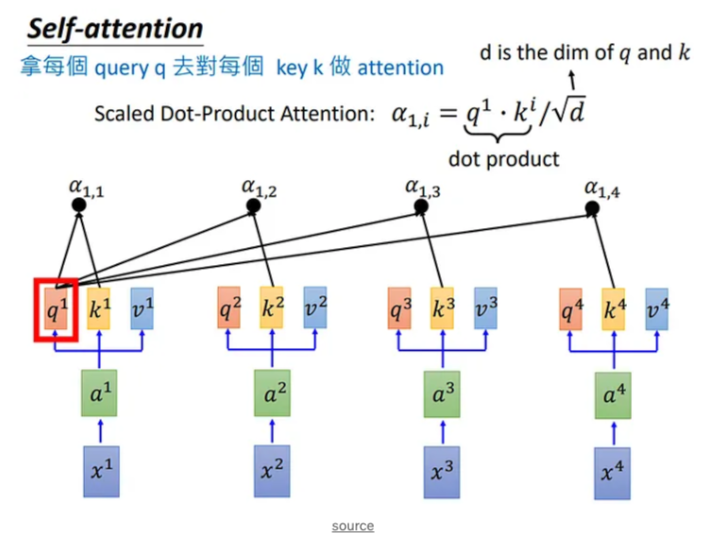
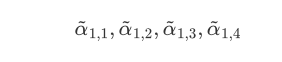
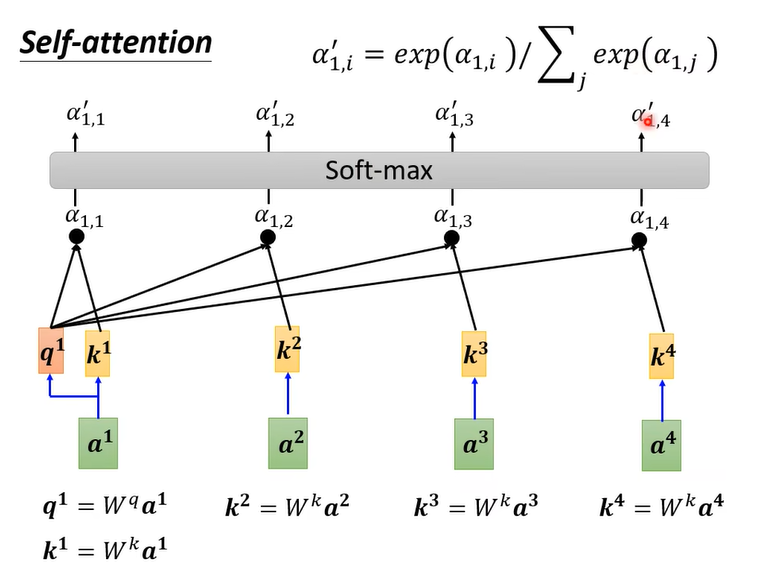
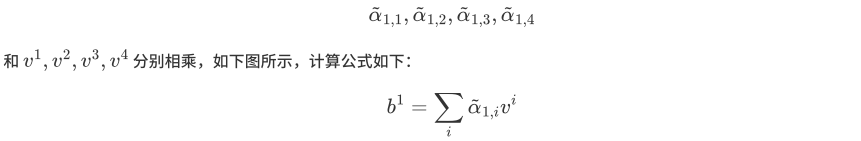
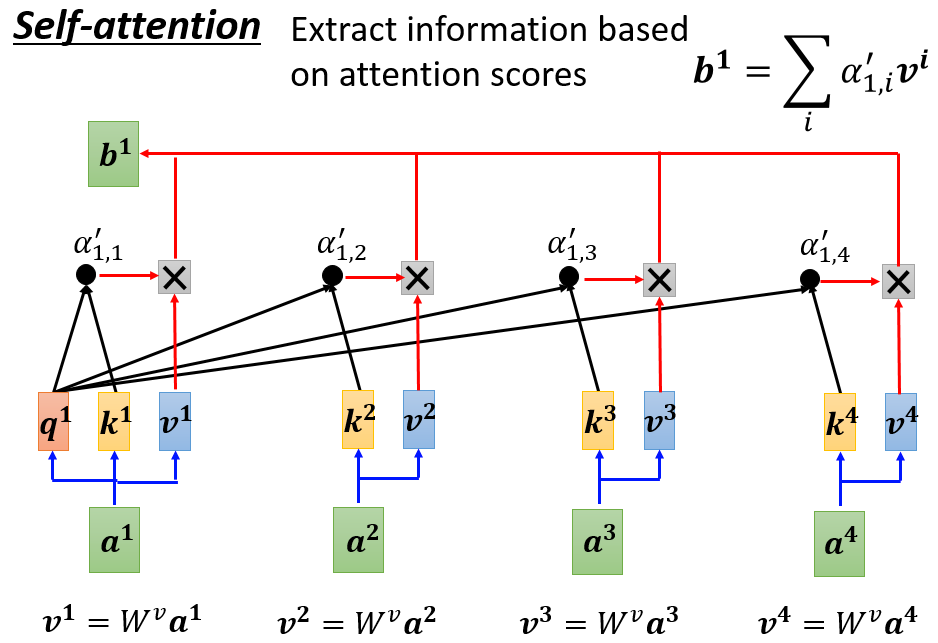
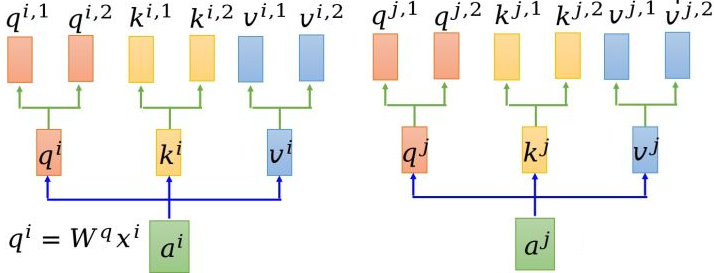
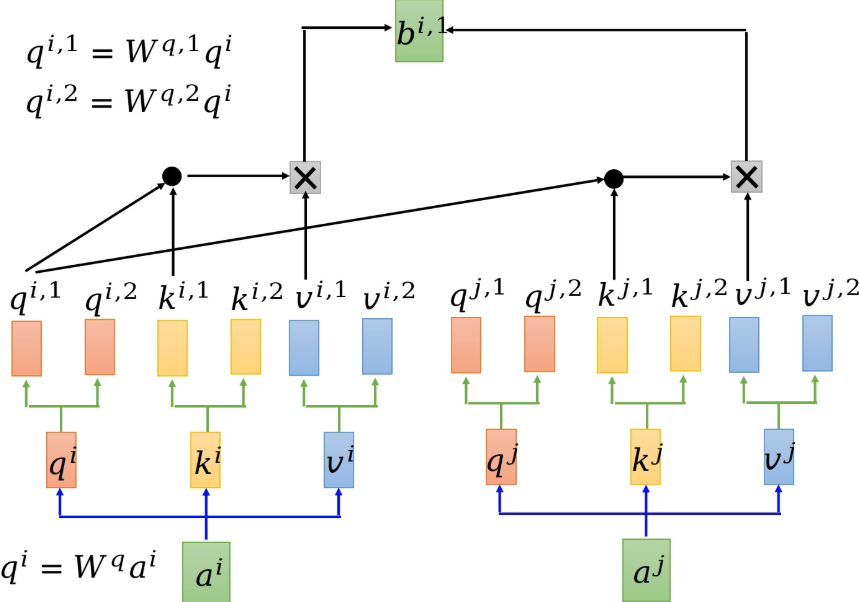
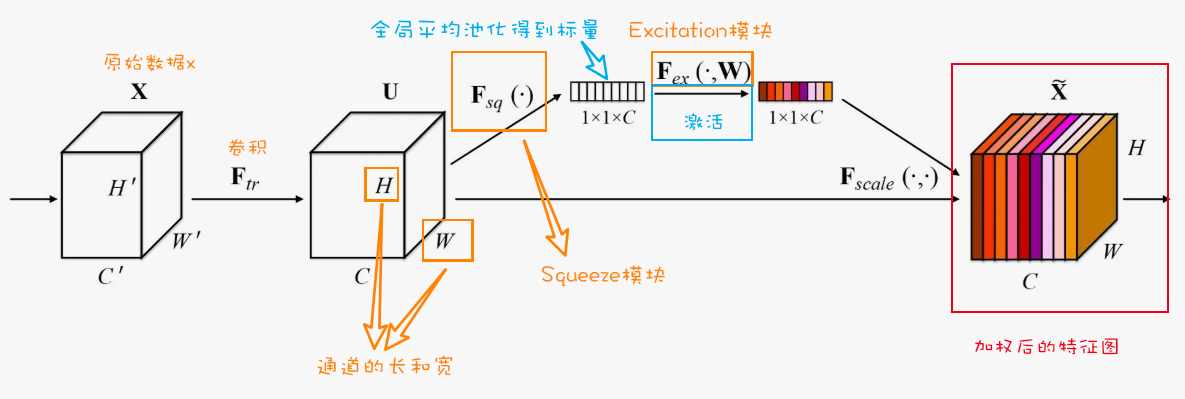
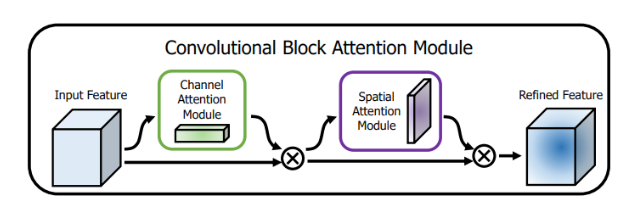
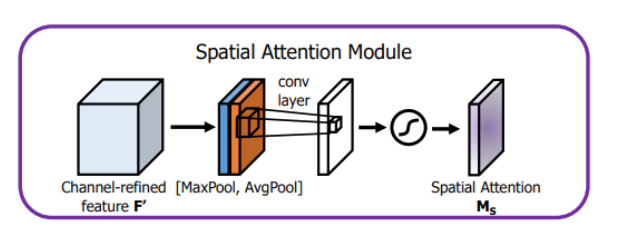
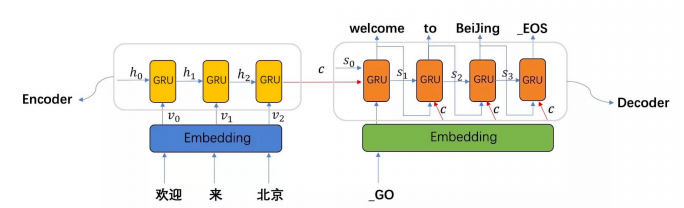
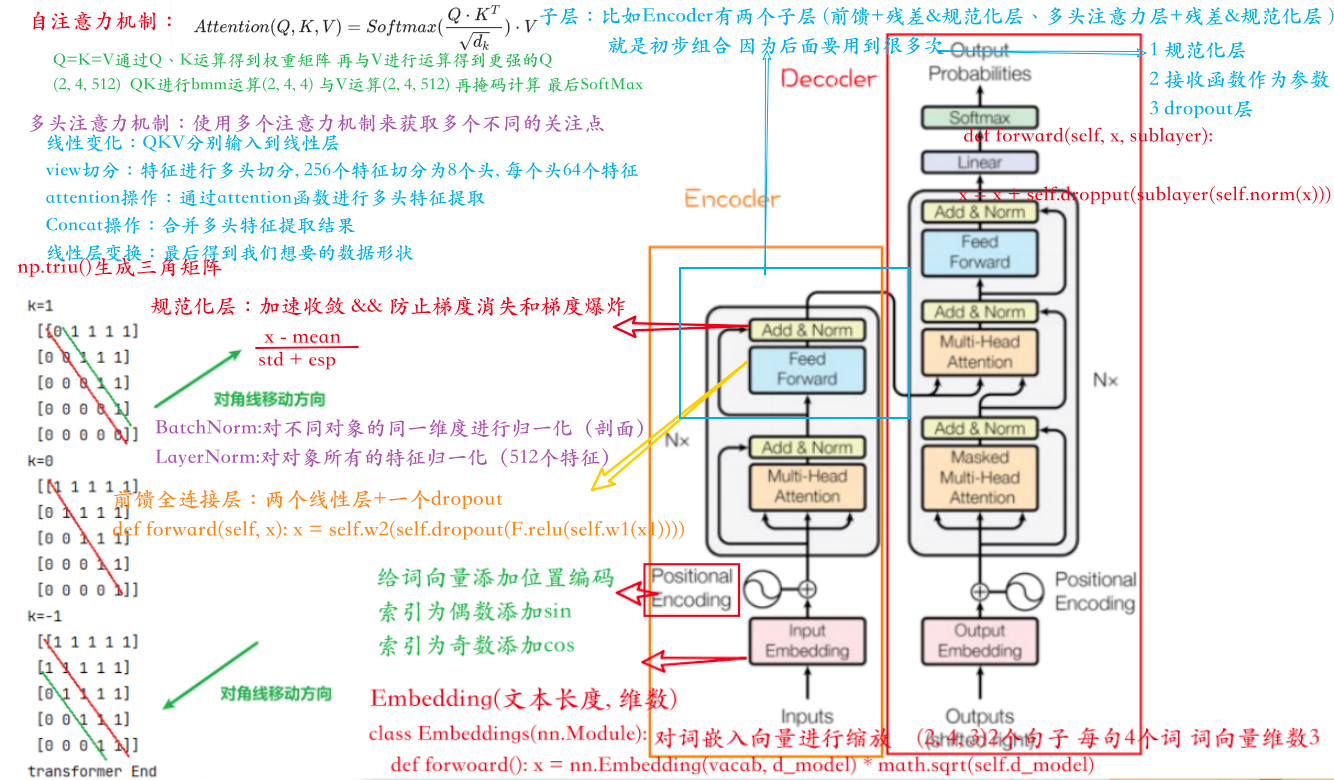
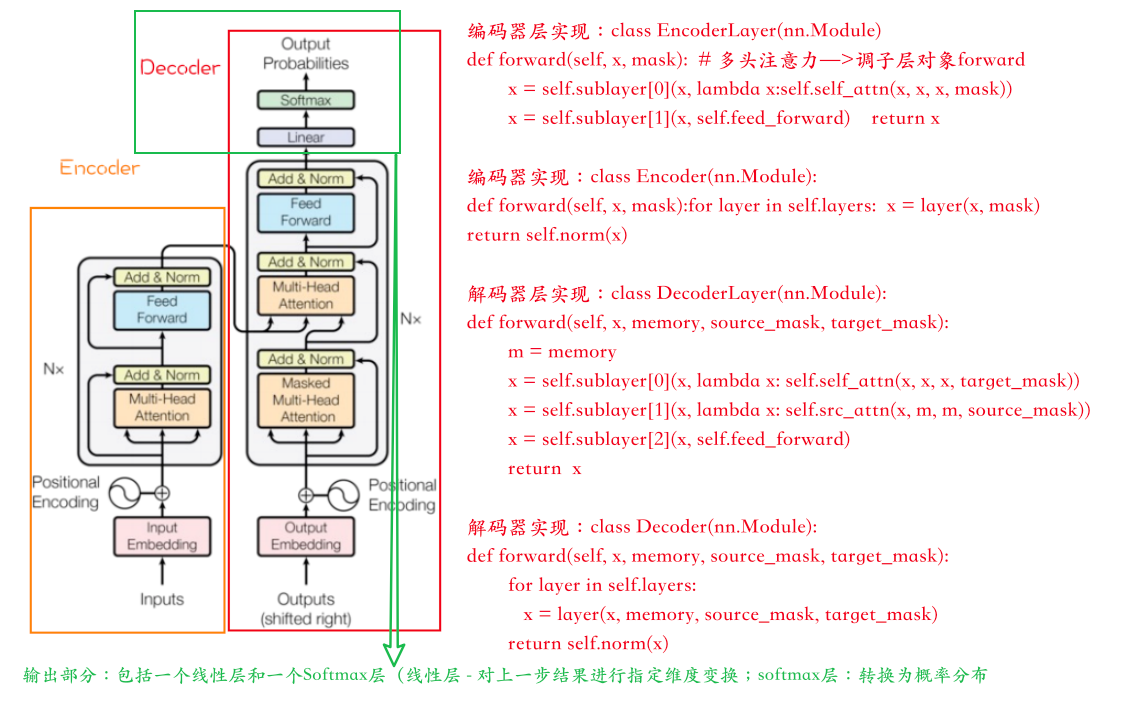
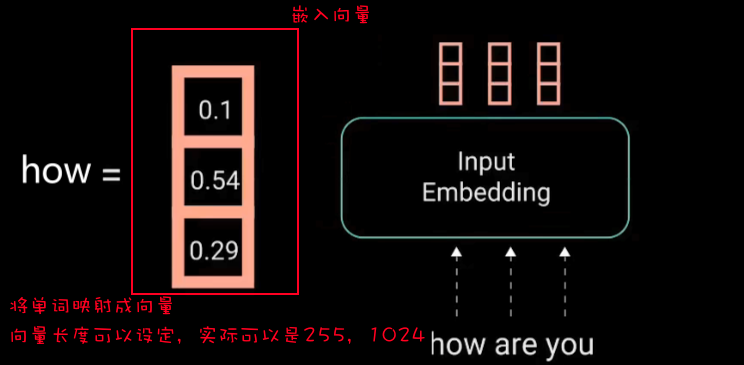
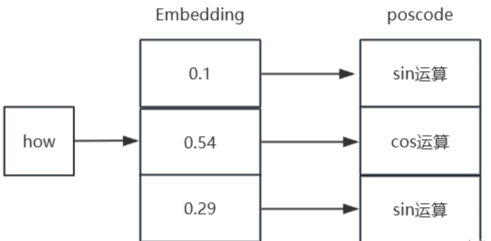
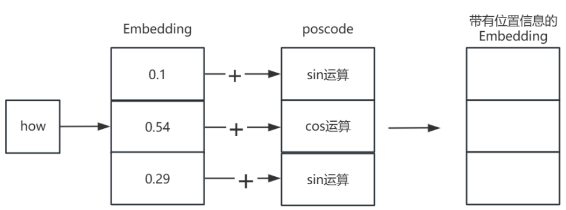
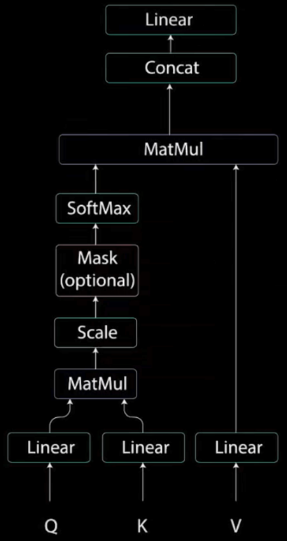
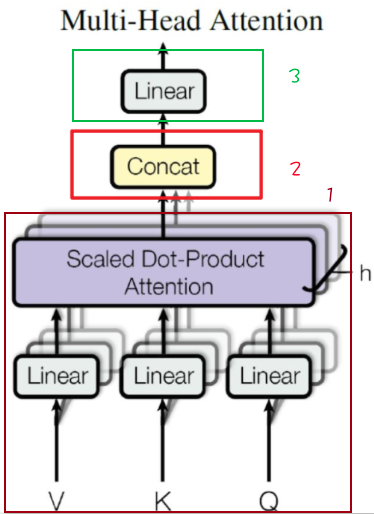
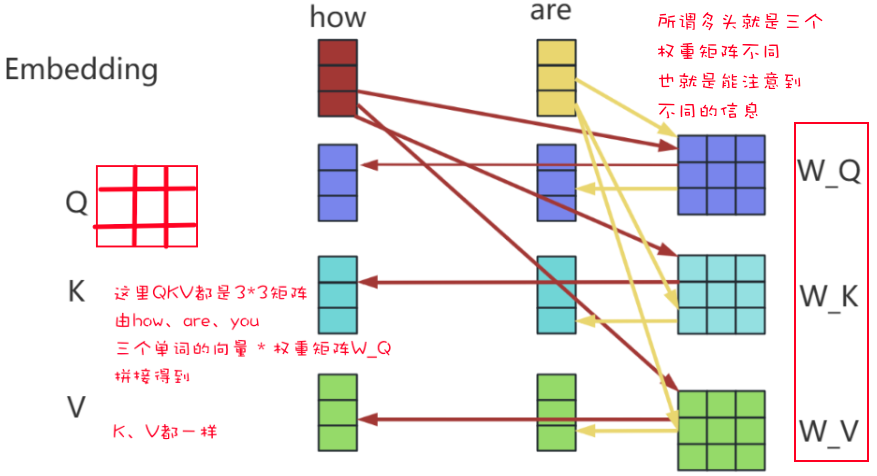
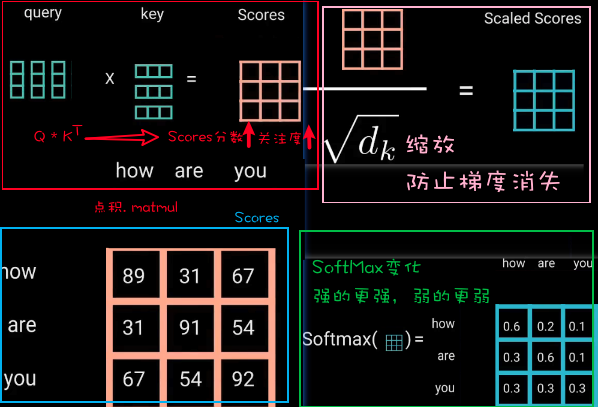
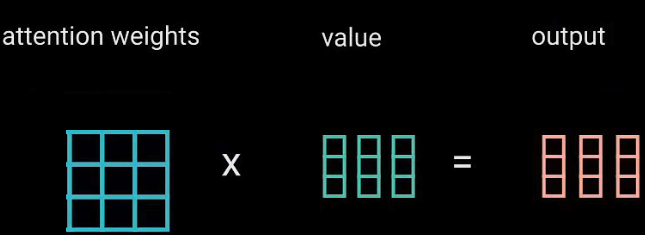
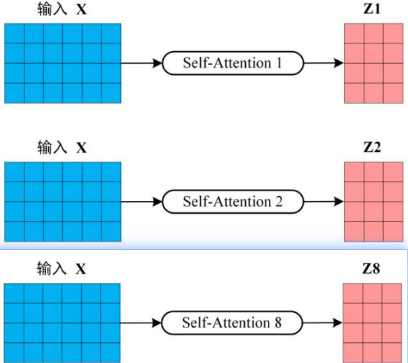
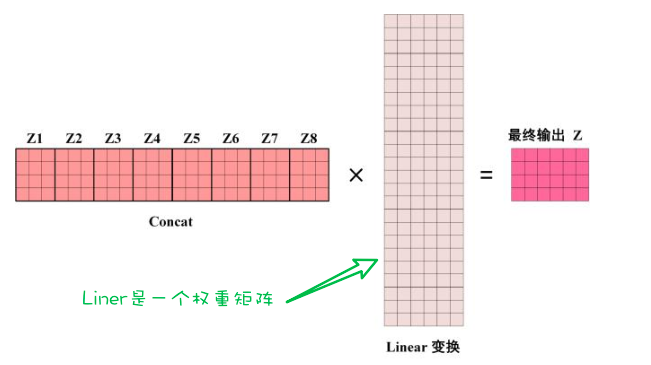

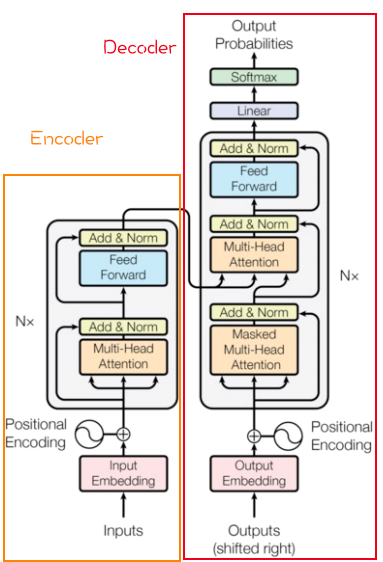
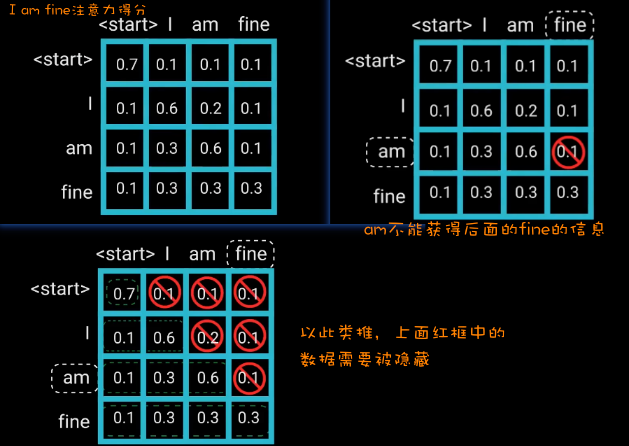
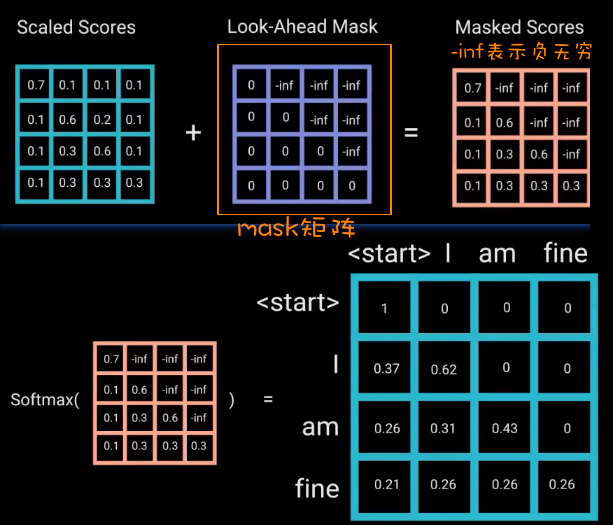
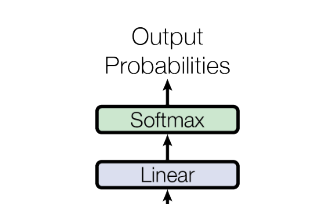

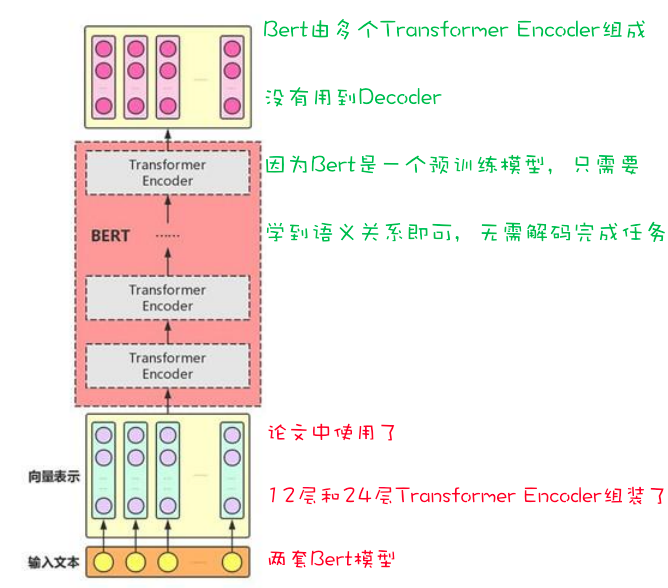
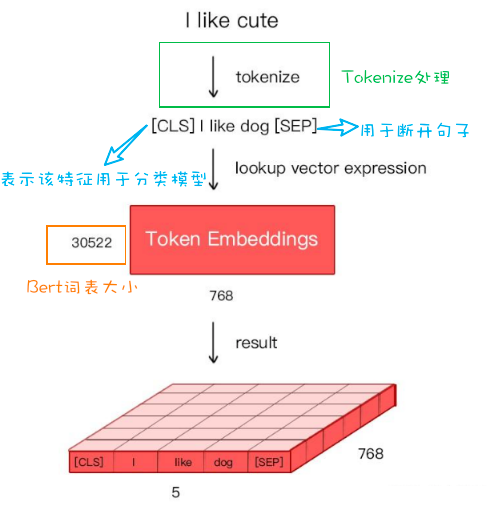
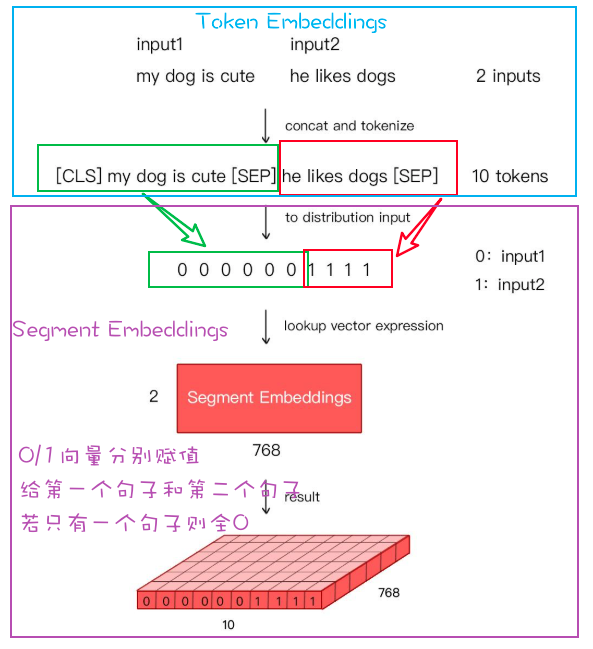
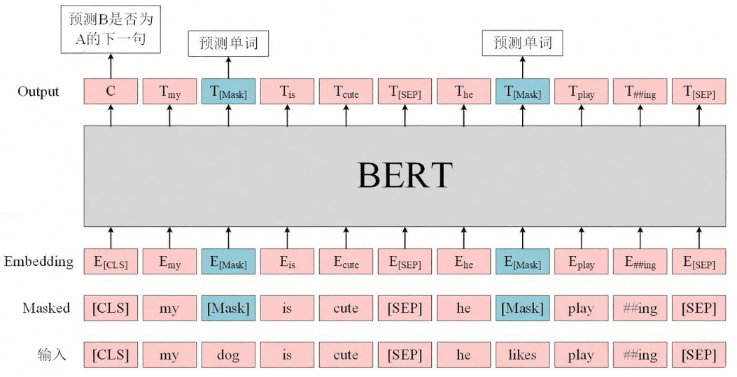
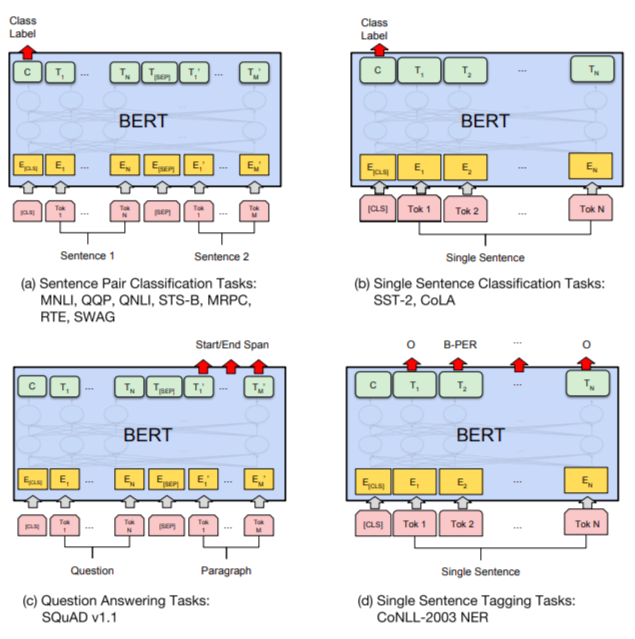
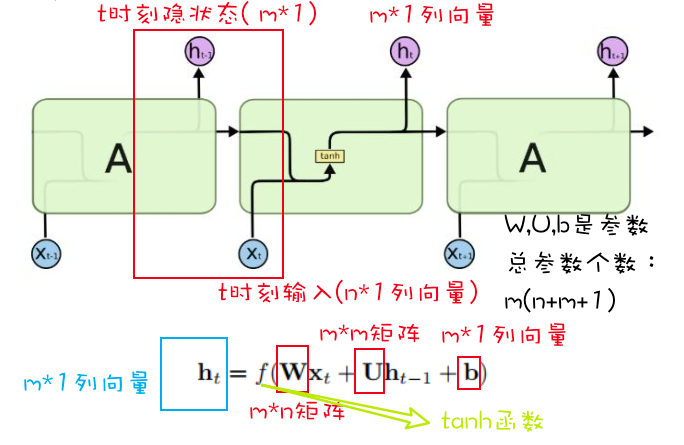
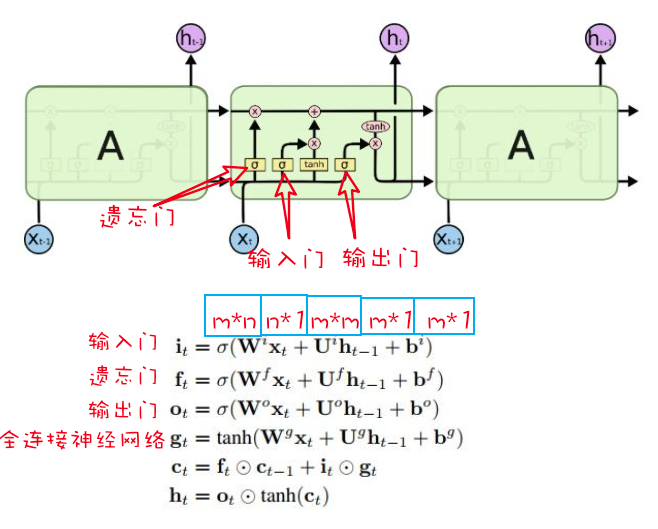
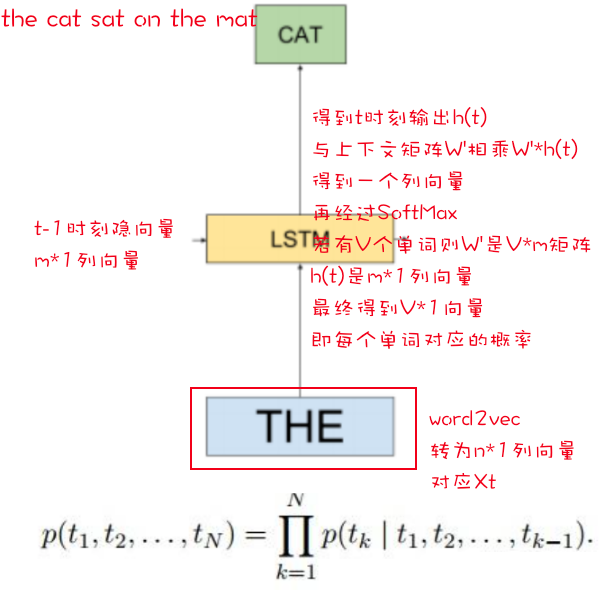
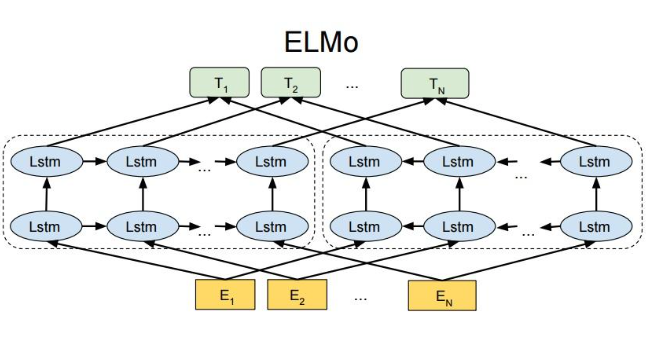
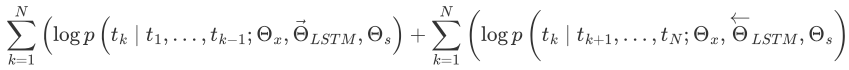
 微信
微信 支付宝
支付宝